
141 results
Properties of Iron Oxides in Two Finnish Lakes in Relation to the Environment of Their Formation
-
- Journal:
- Clays and Clay Minerals / Volume 35 / Issue 4 / August 1987
- Published online by Cambridge University Press:
- 02 April 2024, pp. 297-304
-
- Article
- Export citation
All sawfish now Critically Endangered but sustained conservation efforts can lead to recovery
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A practical guide to adopting Bayesian analyses in clinical research
-
- Journal:
- Journal of Clinical and Translational Science / Volume 8 / Issue 1 / 2024
- Published online by Cambridge University Press:
- 07 December 2023, e3
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
History of Native American land and natural resource policy in the United States: impacts on the field of paleontology
-
- Journal:
- Paleobiology / Volume 49 / Issue 2 / May 2023
- Published online by Cambridge University Press:
- 09 January 2023, pp. 191-203
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Elastohydrodynamics of contact in adherent sheets
-
- Journal:
- Journal of Fluid Mechanics / Volume 947 / 25 September 2022
- Published online by Cambridge University Press:
- 22 August 2022, A16
-
- Article
- Export citation
The two extinctions of the Carolina Parakeet Conuropsis carolinensis
-
- Journal:
- Bird Conservation International / Volume 32 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 21 July 2021, pp. 498-505
-
- Article
- Export citation
Universal masking to control healthcare-associated transmission of severe acute respiratory coronavirus virus 2 (SARS-CoV-2)
- Part of
-
- Journal:
- Infection Control & Hospital Epidemiology / Volume 43 / Issue 3 / March 2022
- Published online by Cambridge University Press:
- 29 March 2021, pp. 344-350
- Print publication:
- March 2022
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Diagonal Interventions in Infection Prevention: Successful Collaboratives to Decrease CLABSI at a VA Health Care System
-
- Journal:
- Infection Control & Hospital Epidemiology / Volume 41 / Issue S1 / October 2020
- Published online by Cambridge University Press:
- 02 November 2020, pp. s191-s192
- Print publication:
- October 2020
-
- Article
-
- You have access
- Export citation
Imaging Developmental and Interventional Plasticity Following Perinatal Stroke
- Part of
-
- Journal:
- Canadian Journal of Neurological Sciences / Volume 48 / Issue 2 / March 2021
- Published online by Cambridge University Press:
- 30 July 2020, pp. 157-171
-
- Article
-
- You have access
- HTML
- Export citation
Changes in prolactin in olanzapine-treated adolescents with schizophrenia or bipolar mania: A pooled analysis of 4 studies
-
- Journal:
- European Psychiatry / Volume 22 / Issue S1 / March 2007
- Published online by Cambridge University Press:
- 16 April 2020, p. S149
-
- Article
-
- You have access
- Export citation
Changes in metabolic parameters in olanzapine-treated adolescents with schizophrenia or bipolar I disorder: A pooled analysis of 4 studies
-
- Journal:
- European Psychiatry / Volume 22 / Issue S1 / March 2007
- Published online by Cambridge University Press:
- 16 April 2020, pp. S149-S150
-
- Article
-
- You have access
- Export citation
Microstructure of the Corpus Callosum Long after Pediatric Concussion
-
- Journal:
- Journal of the International Neuropsychological Society / Volume 26 / Issue 8 / September 2020
- Published online by Cambridge University Press:
- 18 March 2020, pp. 763-775
-
- Article
- Export citation
Developmental pathways from preschool irritability to multifinality in early adolescence: the role of diurnal cortisol
-
- Journal:
- Psychological Medicine / Volume 51 / Issue 5 / April 2021
- Published online by Cambridge University Press:
- 20 December 2019, pp. 761-769
-
- Article
- Export citation
If I [Take] Leave, Will You Stay? Paternity Leave and Relationship Stability
-
- Journal:
- Journal of Social Policy / Volume 49 / Issue 4 / October 2020
- Published online by Cambridge University Press:
- 14 November 2019, pp. 829-849
- Print publication:
- October 2020
-
- Article
- Export citation
Sugarbeet tolerance when dimethenamid-P follows soil-applied ethofumesate and S-metolachlor
-
- Journal:
- Weed Technology / Volume 33 / Issue 3 / June 2019
- Published online by Cambridge University Press:
- 27 May 2019, pp. 431-440
-
- Article
- Export citation
3092 Measuring Fluid Compartments Before and After Rapid Saline Infusion
-
- Journal:
- Journal of Clinical and Translational Science / Volume 3 / Issue s1 / March 2019
- Published online by Cambridge University Press:
- 26 March 2019, pp. 48-49
-
- Article
-
- You have access
- Open access
- Export citation
Minding the Baby®: Enhancing parental reflective functioning and infant attachment in an attachment-based, interdisciplinary home visiting program
-
- Journal:
- Development and Psychopathology / Volume 32 / Issue 1 / February 2020
- Published online by Cambridge University Press:
- 14 January 2019, pp. 123-137
-
- Article
- Export citation
2450 Delirium and catatonia: Age matters
-
- Journal:
- Journal of Clinical and Translational Science / Volume 2 / Issue S1 / June 2018
- Published online by Cambridge University Press:
- 21 November 2018, p. 39
-
- Article
-
- You have access
- Open access
- Export citation
The effect of CO2 and oxidation rate on the formation of goethite versus lepidocrocite from an Fe(II) system at pH 6 and 7
-
- Journal:
- Clay Minerals / Volume 25 / Issue 1 / March 1990
- Published online by Cambridge University Press:
- 09 July 2018, pp. 65-71
-
- Article
- Export citation
-
To investigate the influence of carbonate on the formation of goethite and lepidocrocite, ∼200 samples were synthesized by oxidizing FeCl2 solutions with air/CO2 gas mixtures at ambient temperature and pH 6 and 7. The proportion of lepidocrocite in the lepidocrocite/goethite mixtures (Lp/(Lp + Gt)) decreased from 100 to 0% with increasing
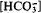 in solution and with decreasing average oxidation rate (AOR). These two parameters explained 81% of the variation of Lp/(Lp + Gt)). At a given , more goethite was formed at pH 6 than at pH 7. The Lp + Gt mixtures contained 0–8 mg g−1 carbon (Ct) which could not be removed by washing. Ct reached apparent saturation at a equilibrium concentration of ∼6–8 and 60–80 mmol l−1 at pH 6 and pH 7, respectively. In a plot of Ct vs. Lp/(Lp + Gt) all data fell on the same line irrespective of oxidation parameters (pH, AOR). IR spectra showed two broad bands at ∼1300 and 1500 cm−1 which can be assigned to distorted carbonate adsorbed at the goethite surface. Identical bands were also found in a young, poorly crystalline goethite formed from coal mine drainage in Ohio. It is suggested that carbonate anions direct the polymerization of the double bands of FeO3(OH)3 octahedra common to both minerals toward a corner sharing arrangement, and thereby to goethite, whereas chloride permits edge-sharing as in lepidocrocite.
in solution and with decreasing average oxidation rate (AOR). These two parameters explained 81% of the variation of Lp/(Lp + Gt)). At a given , more goethite was formed at pH 6 than at pH 7. The Lp + Gt mixtures contained 0–8 mg g−1 carbon (Ct) which could not be removed by washing. Ct reached apparent saturation at a equilibrium concentration of ∼6–8 and 60–80 mmol l−1 at pH 6 and pH 7, respectively. In a plot of Ct vs. Lp/(Lp + Gt) all data fell on the same line irrespective of oxidation parameters (pH, AOR). IR spectra showed two broad bands at ∼1300 and 1500 cm−1 which can be assigned to distorted carbonate adsorbed at the goethite surface. Identical bands were also found in a young, poorly crystalline goethite formed from coal mine drainage in Ohio. It is suggested that carbonate anions direct the polymerization of the double bands of FeO3(OH)3 octahedra common to both minerals toward a corner sharing arrangement, and thereby to goethite, whereas chloride permits edge-sharing as in lepidocrocite.
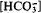 in solution and with decreasing average oxidation rate (AOR). These two parameters explained 81% of the variation of Lp/(Lp + Gt)). At a given
in solution and with decreasing average oxidation rate (AOR). These two parameters explained 81% of the variation of Lp/(Lp + Gt)). At a given 