
275 results
544 Interleukin-6 protects renal dysfunction in mouse models of hypertension and salt-sensitive hypertension
- Part of
-
- Journal:
- Journal of Clinical and Translational Science / Volume 8 / Issue s1 / April 2024
- Published online by Cambridge University Press:
- 03 April 2024, p. 162
-
- Article
-
- You have access
- Open access
- Export citation
Temporal trends of carbonated soft-drink consumption among adolescents aged 12–15 years from eighteen countries in Africa, Asia and the Americas
-
- Journal:
- British Journal of Nutrition / Volume 131 / Issue 9 / 14 May 2024
- Published online by Cambridge University Press:
- 16 January 2024, pp. 1633-1640
- Print publication:
- 14 May 2024
-
- Article
- Export citation
30 Item response theory and differential item functioning of the AD8: The High School & Beyond Study
-
- Journal:
- Journal of the International Neuropsychological Society / Volume 29 / Issue s1 / November 2023
- Published online by Cambridge University Press:
- 21 December 2023, p. 240
-
- Article
-
- You have access
- Export citation
OP85 Cost Effectiveness Of Prednisolone To Treat Bell’s Palsy In Children: An Economic Evaluation Alongside A Randomized Controlled Trial
-
- Journal:
- International Journal of Technology Assessment in Health Care / Volume 39 / Issue S1 / December 2023
- Published online by Cambridge University Press:
- 14 December 2023, p. S23
-
- Article
-
- You have access
- Export citation
PP07 Vaccine Decision-making In Canada: Processes And Guidelines For Using Economic Evidence
-
- Journal:
- International Journal of Technology Assessment in Health Care / Volume 39 / Issue S1 / December 2023
- Published online by Cambridge University Press:
- 14 December 2023, p. S53
-
- Article
-
- You have access
- Export citation
A causal roadmap for generating high-quality real-world evidence
-
- Journal:
- Journal of Clinical and Translational Science / Volume 7 / Issue 1 / 2023
- Published online by Cambridge University Press:
- 22 September 2023, e212
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Managing the clinical encounter with patients with personality disorder in a general psychiatry setting: key contributions from neuropsychoanalysis
-
- Journal:
- BJPsych Advances , FirstView
- Published online by Cambridge University Press:
- 09 August 2023, pp. 1-8
-
- Article
- Export citation
Clinical index to quantify the 1-year risk for common postpartum mental disorders at the time of delivery (PMH CAREPLAN): development and internal validation
-
- Journal:
- The British Journal of Psychiatry / Volume 223 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 21 June 2023, pp. 422-429
- Print publication:
- September 2023
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A HIERARCHICAL MACHINE LEARNING WORKFLOW FOR OBJECT DETECTION OF ENGINEERING COMPONENTS
-
- Journal:
- Proceedings of the Design Society / Volume 3 / July 2023
- Published online by Cambridge University Press:
- 19 June 2023, pp. 201-210
-
- Article
-
- You have access
- Open access
- Export citation
378 Regulation of renal function by the peroxisome proliferator-activated receptor-alpha: A novel target for treating hypertension
- Part of
-
- Journal:
- Journal of Clinical and Translational Science / Volume 7 / Issue s1 / April 2023
- Published online by Cambridge University Press:
- 24 April 2023, p. 112
-
- Article
-
- You have access
- Open access
- Export citation
A SARS-CoV-2 outbreak due to vaccine breakthrough in an acute-care hospital
-
- Journal:
- Antimicrobial Stewardship & Healthcare Epidemiology / Volume 2 / Issue S1 / July 2022
- Published online by Cambridge University Press:
- 16 May 2022, p. s83
-
- Article
-
- You have access
- Open access
- Export citation
-
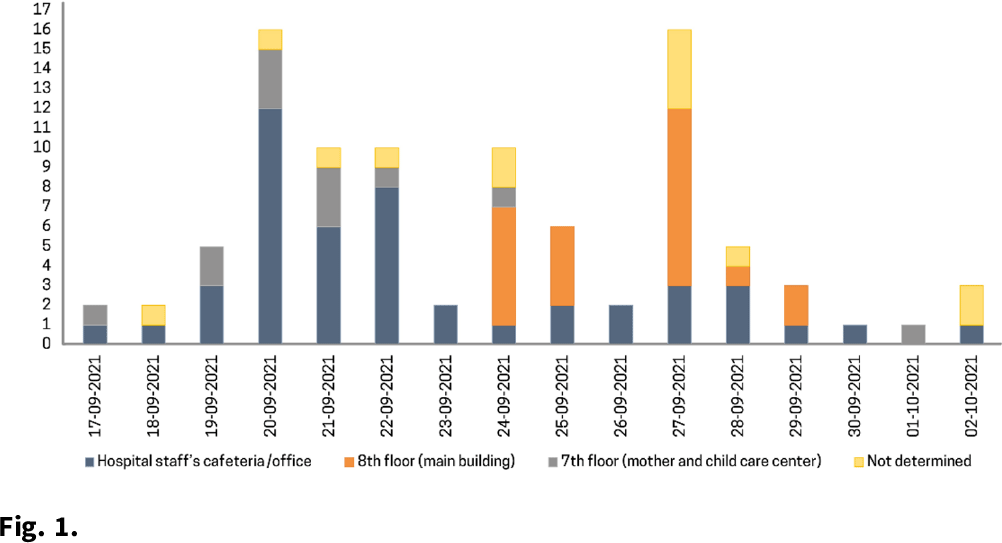
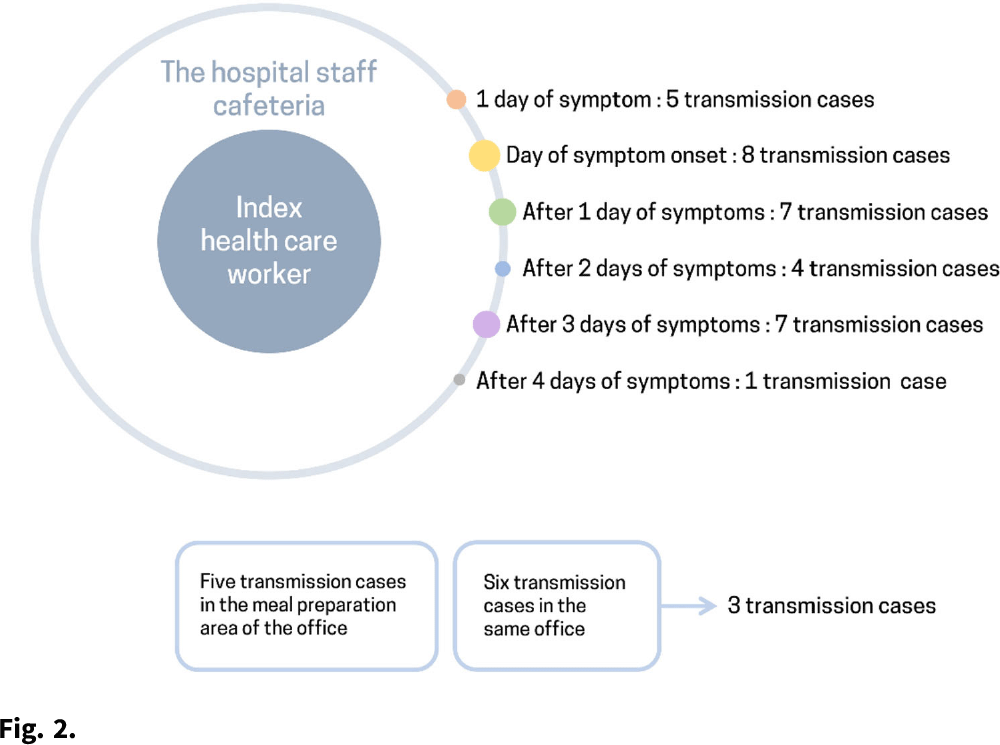
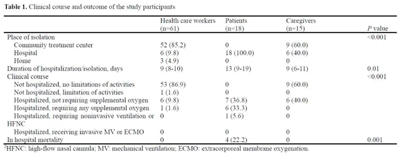
Background: The δ (delta) variant has spread rapidly worldwide and has become the predominant strain of SARS-CoV-2. We analyzed an outbreak caused by a vaccine breakthrough infection in a hospital with an active infection control program where 91.9% of healthcare workers were vaccinated. Methods: We investigated a SARS-CoV-2 outbreak between September 9 and October 2, 2021, in a referral teaching hospital in Korea. We retrospectively collected data on demographics, vaccination history, transmission, and clinical features of confirmed COVID-19 in patients, healthcare workers, and caregivers. Results: During the outbreak, 94 individuals tested positive for SARS-CoV-2 using reverse transcription-polymerase chain reaction (rtPCR) testing. Testing identified infections in 61 health care workers, 18 patients, and 15 caregivers, and 70 (74.5%) of 94 cases were vaccine breakthrough infections. We detected 3 superspreading events: in the hospital staff cafeteria and offices (n = 47 cases, 50%), the 8th floor of the main building (n = 22 cases, 23.4%), and the 7th floor in the maternal and child healthcare center (n = 12 cases, 12.8%). These superspreading events accounted for 81 (86.2%) of 94 transmissions (Fig. 1, 2). The median interval between completion of vaccination and COVID-19 infection was 117 days (range, 18–187). There was no significant difference in the mean Ct value of the RdRp/ORF1ab gene between fully vaccinated individuals (mean 20.87, SD±6.28) and unvaccinated individuals (mean 19.94, SD±5.37, P = .52) at the time of diagnosis. Among healthcare workers and caregivers, only 1 required oxygen supplementation. In contrast, among 18 patients, there were 4 fatal cases (22.2%), 3 of whom were unvaccinated (Table 1). Conclusions: Superspreading infection among fully vaccinated individuals occurred in an acute-care hospital while the δ (delta) variant was dominant. Given the potential for severe complications, as this outbreak demonstrated, preventive measures including adequate ventilation should be emphasized to minimize transmission in hospitals.
Funding: None
Disclosures: None



18 - On the Coproduct in Affine Schubert Calculus
-
-
- Book:
- Facets of Algebraic Geometry
- Published online:
- 14 March 2022
- Print publication:
- 07 April 2022, pp 115-146
-
- Chapter
- Export citation
Chapter 25 - Laser Interstitial Thermal Therapy (LITT) for Insular Epilepsy
- from Section 5 - Surgical Management of Insular Epilepsy
-
-
- Book:
- Insular Epilepsies
- Published online:
- 09 June 2022
- Print publication:
- 24 March 2022, pp 287-298
-
- Chapter
- Export citation
Gestational weight gain is associated with childhood height, weight and BMI in the Peri/Postnatal Epigenetic Twins Study
-
- Journal:
- Journal of Developmental Origins of Health and Disease / Volume 13 / Issue 6 / December 2022
- Published online by Cambridge University Press:
- 24 March 2022, pp. 757-765
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Real-world monitoring progress towards the elimination of hepatitis C virus in Australia using sentinel surveillance of primary care clinics; an ecological study of hepatitis C virus antibody tests from 2009 to 2019 – CORRIGENDUM
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 04 March 2022, e44
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Real-world monitoring progress towards the elimination of hepatitis C virus in Australia using sentinel surveillance of primary care clinics; an ecological study of hepatitis C virus antibody tests from 2009 to 2019
-
- Journal:
- Epidemiology & Infection / Volume 150 / 2022
- Published online by Cambridge University Press:
- 06 December 2021, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Evolvability in the fossil record
-
- Journal:
- Paleobiology / Volume 48 / Issue 2 / May 2022
- Published online by Cambridge University Press:
- 09 November 2021, pp. 186-209
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Back stable Schubert calculus
- Part of
-
- Journal:
- Compositio Mathematica / Volume 157 / Issue 5 / May 2021
- Published online by Cambridge University Press:
- 30 April 2021, pp. 883-962
- Print publication:
- May 2021
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Food insecurity (hunger) and fast-food consumption among 180 164 adolescents aged 12–15 years from sixty-eight countries
-
- Journal:
- British Journal of Nutrition / Volume 127 / Issue 3 / 14 February 2022
- Published online by Cambridge University Press:
- 05 April 2021, pp. 470-477
- Print publication:
- 14 February 2022
-
- Article
-
- You have access
- HTML
- Export citation
Household and schooling rather than diet offset the adverse associations of height with school competence and emotional disturbance among Taiwanese girls
-
- Journal:
- Public Health Nutrition / Volume 24 / Issue 8 / June 2021
- Published online by Cambridge University Press:
- 22 March 2021, pp. 2238-2247
-
- Article
-
- You have access
- HTML
- Export citation
