
73 results
Effects of neighborhood disadvantage and peer deviance on adolescent antisocial behavior: Testing potential interactions with age-of-onset
-
- Journal:
- Development and Psychopathology , First View
- Published online by Cambridge University Press:
- 11 December 2023, pp. 1-12
-
- Article
- Export citation
Proactive and reactive aggression: Developmental trajectories and longitudinal associations with callous–unemotional traits, impulsivity, and internalizing emotions
-
- Journal:
- Development and Psychopathology , First View
- Published online by Cambridge University Press:
- 03 April 2023, pp. 1-9
-
- Article
- Export citation
A mycoprotein-based high-protein vegan diet supports equivalent daily myofibrillar protein synthesis rates compared with an isonitrogenous omnivorous diet in older adults: a randomised controlled trial
-
- Journal:
- British Journal of Nutrition / Volume 126 / Issue 5 / 14 September 2021
- Published online by Cambridge University Press:
- 11 November 2020, pp. 674-684
- Print publication:
- 14 September 2021
-
- Article
-
- You have access
- HTML
- Export citation
Ecandrewsite, the zinc analogue of ilmenite, from Little Broken Hill, New South Wales, Australia, and the San Valentin Mine, Sierra de Cartegena, Spain
-
- Journal:
- Mineralogical Magazine / Volume 52 / Issue 365 / April 1988
- Published online by Cambridge University Press:
- 05 July 2018, pp. 237-240
-
- Article
- Export citation
-
Ecandrewsite, the zinc analogue of ilmenite, is a new mineral which was first described from the Broken Hill lode in 1970 and discovered subsequently in ores from Little Broken Hill (New South Wales) and the San Valentin Mine, Spain. The name ‘ecandrewsite’ was used in a partial description of the mineral in ‘Minerals of Broken Hill’ (1982), thereby establishing the Little Broken Hill locality, specifically the Melbourne Rockwell Mine, as the type locality. Microprobe analysis of ecandrewsite from the type locality gave ZnO 30.42 (wt.%), FeO (total Fe) 11.37, MnO 7.64, TiO2 50.12, total 99.6%, yielding an empirical formula of (Zn0.59Fe0.24Mn0.17)1.00Ti0.99O3 based on 3 oxygen atoms. All compositions from Little Broken Hill and the San Valentin Mine are ferroan manganoan ecandrewsite. The strongest lines in the X-ray powder diffraction data are (d in Å, (hkil), I/Io):2.746, (10
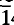 4), 100; 2.545, (11
4), 100; 2.545, (11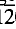 0), 80; 1.867, (024), 40; 3.734, (012), 30; 1.470, (3030), 30; 1.723, (116), 25. Ecandrewsite is hexagonal, space group RR3¯ assigned from a structural study, with a = 5.090(1), c = 14.036(2)Å, V = 314.6(3)Å3, Z = 6, D(calc.) = 4.99. The mineral is opaque, dark brown to black with a similar streak, and a submetallic lustre. In plane polarized light the reflection colour is greyish white with a pinkish tinge. Reflection pleochroism is weak, but anisotropism is strong with colours from greenish grey to dark brownish grey. Reflectance data in air between 470 and 650 nm are given. At the type locality, ecandrewsite forms disseminated tabular euhedral grains up to 250 × 50 µm, in quartz-rich metasediments. Associated minerals include almandine-spessartine, ferroan gahnite and rutile. The name is for E. C. Andrews, pioneering geologist in the Broken Hill region of New South Wales. Type material consisting of one grain is preserved in the Museum of Victoria (M35700). The mineral and name were approved by the IMA Commission on New Minerals and Mineral Names in 1979.
0), 80; 1.867, (024), 40; 3.734, (012), 30; 1.470, (3030), 30; 1.723, (116), 25. Ecandrewsite is hexagonal, space group RR3¯ assigned from a structural study, with a = 5.090(1), c = 14.036(2)Å, V = 314.6(3)Å3, Z = 6, D(calc.) = 4.99. The mineral is opaque, dark brown to black with a similar streak, and a submetallic lustre. In plane polarized light the reflection colour is greyish white with a pinkish tinge. Reflection pleochroism is weak, but anisotropism is strong with colours from greenish grey to dark brownish grey. Reflectance data in air between 470 and 650 nm are given. At the type locality, ecandrewsite forms disseminated tabular euhedral grains up to 250 × 50 µm, in quartz-rich metasediments. Associated minerals include almandine-spessartine, ferroan gahnite and rutile. The name is for E. C. Andrews, pioneering geologist in the Broken Hill region of New South Wales. Type material consisting of one grain is preserved in the Museum of Victoria (M35700). The mineral and name were approved by the IMA Commission on New Minerals and Mineral Names in 1979.
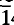 4), 100; 2.545, (11
4), 100; 2.545, (11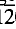 0), 80; 1.867, (02
0), 80; 1.867, (02Understanding the link between exposure to violence and aggression in justice-involved adolescents
-
- Journal:
- Development and Psychopathology / Volume 30 / Issue 2 / May 2018
- Published online by Cambridge University Press:
- 25 April 2018, pp. 593-603
-
- Article
- Export citation
Mycoprotein represents a bioavailable and insulinotropic non-animal-derived dietary protein source: a dose–response study
-
- Journal:
- British Journal of Nutrition / Volume 118 / Issue 9 / 14 November 2017
- Published online by Cambridge University Press:
- 11 October 2017, pp. 673-685
- Print publication:
- 14 November 2017
-
- Article
-
- You have access
- HTML
- Export citation
Optical Observations of Extragalactic Radio Sources
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 1 / Issue 1 / January 1967
- Published online by Cambridge University Press:
- 25 April 2016, p. 23
-
- Article
- Export citation
The Parkes 2700 MHz Survey—On-Line Reduction
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 2 / Issue 4 / October 1973
- Published online by Cambridge University Press:
- 25 April 2016, pp. 195-197
-
- Article
- Export citation
Contributors
-
-
- Book:
- The Cambridge Dictionary of Philosophy
- Published online:
- 05 August 2015
- Print publication:
- 27 April 2015, pp ix-xxx
-
- Chapter
- Export citation
Teaching for the Transition: the Canadian PGY-1 Neurosurgery ‘Rookie Camp’
-
- Journal:
- Canadian Journal of Neurological Sciences / Volume 42 / Issue 1 / January 2015
- Published online by Cambridge University Press:
- 09 January 2015, pp. 25-33
-
- Article
-
- You have access
- HTML
- Export citation
A roadmap for Antarctic and Southern Ocean science for the next two decades and beyond
-
- Journal:
- Antarctic Science / Volume 27 / Issue 1 / February 2015
- Published online by Cambridge University Press:
- 18 September 2014, pp. 3-18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Science with the Australian Square Kilometre Array Pathfinder
- Part of
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 24 / Issue 4 / 2007
- Published online by Cambridge University Press:
- 05 March 2013, pp. 174-188
-
- Article
-
- You have access
- Export citation
EMU: Evolutionary Map of the Universe
- Part of
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 28 / Issue 3 / 2011
- Published online by Cambridge University Press:
- 02 January 2013, pp. 215-248
-
- Article
-
- You have access
- Export citation
Attitudes towards carnivores: the views of emerging commercial farmers in Namibia
-
- Article
-
- You have access
- HTML
- Export citation
11 - Epilogue: statistics and our Universe
-
- Book:
- Practical Statistics for Astronomers
- Published online:
- 05 June 2012
- Print publication:
- 26 April 2012, pp 291-315
-
- Chapter
- Export citation
Foreword to first edition
-
- Book:
- Practical Statistics for Astronomers
- Published online:
- 05 June 2012
- Print publication:
- 26 April 2012, pp xiii-xiv
-
- Chapter
- Export citation
Foreword to second edition
-
- Book:
- Practical Statistics for Astronomers
- Published online:
- 05 June 2012
- Print publication:
- 26 April 2012, pp xv-xvi
-
- Chapter
- Export citation
7 - Data modelling and parameter estimation: advanced topics
-
- Book:
- Practical Statistics for Astronomers
- Published online:
- 05 June 2012
- Print publication:
- 26 April 2012, pp 151-181
-
- Chapter
- Export citation
Note on notation
-
- Book:
- Practical Statistics for Astronomers
- Published online:
- 05 June 2012
- Print publication:
- 26 April 2012, pp xvii-xx
-
- Chapter
- Export citation
