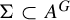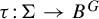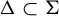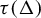102 results in 68Qxx
Binary pattern retrieval with Kuramoto-type oscillators via a least orthogonal lift of three patterns
- Part of
-
- Journal:
- European Journal of Applied Mathematics , First View
- Published online by Cambridge University Press:
- 16 May 2024, pp. 1-16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ON THE FRAGILITY OF INTERPOLATION
- Part of
-
- Journal:
- The Journal of Symbolic Logic , First View
- Published online by Cambridge University Press:
- 21 March 2024, pp. 1-38
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Invariant sets and nilpotency of endomorphisms of algebraic sofic shifts
- Part of
-
- Journal:
- Ergodic Theory and Dynamical Systems , First View
- Published online by Cambridge University Press:
- 15 February 2024, pp. 1-42
-
- Article
- Export citation
-
Let G be a group and let V be an algebraic variety over an algebraically closed field K. Let A denote the set of K-points of V. We introduce algebraic sofic subshifts
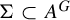 ${\Sigma \subset A^G}$ and study endomorphisms
${\Sigma \subset A^G}$ and study endomorphisms 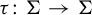 $\tau \colon \Sigma \to \Sigma $. We generalize several results for dynamical invariant sets and nilpotency of
$\tau \colon \Sigma \to \Sigma $. We generalize several results for dynamical invariant sets and nilpotency of 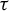 $\tau $ that are well known for finite alphabet cellular automata. Under mild assumptions, we prove that
$\tau $ that are well known for finite alphabet cellular automata. Under mild assumptions, we prove that 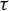 $\tau $ is nilpotent if and only if its limit set, that is, the intersection of the images of its iterates, is a singleton. If moreover G is infinite, finitely generated and
$\tau $ is nilpotent if and only if its limit set, that is, the intersection of the images of its iterates, is a singleton. If moreover G is infinite, finitely generated and 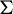 $\Sigma $ is topologically mixing, we show that
$\Sigma $ is topologically mixing, we show that 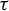 $\tau $ is nilpotent if and only if its limit set consists of periodic configurations and has a finite set of alphabet values.
$\tau $ is nilpotent if and only if its limit set consists of periodic configurations and has a finite set of alphabet values.
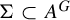
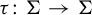
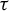
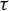
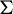
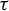
REGAININGLY APPROXIMABLE NUMBERS AND SETS
- Part of
-
- Journal:
- The Journal of Symbolic Logic , First View
- Published online by Cambridge University Press:
- 22 January 2024, pp. 1-31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We call an
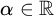 $\alpha \in \mathbb {R}$ regainingly approximable if there exists a computable nondecreasing sequence
$\alpha \in \mathbb {R}$ regainingly approximable if there exists a computable nondecreasing sequence 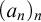 $(a_n)_n$ of rational numbers converging to
$(a_n)_n$ of rational numbers converging to 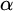 $\alpha $ with
$\alpha $ with 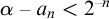 $\alpha - a_n < 2^{-n}$ for infinitely many
$\alpha - a_n < 2^{-n}$ for infinitely many 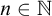 ${n \in \mathbb {N}}$. We also call a set
${n \in \mathbb {N}}$. We also call a set 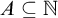 $A\subseteq \mathbb {N}$ regainingly approximable if it is c.e. and the strongly left-computable number
$A\subseteq \mathbb {N}$ regainingly approximable if it is c.e. and the strongly left-computable number 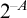 $2^{-A}$ is regainingly approximable. We show that the set of regainingly approximable sets is neither closed under union nor intersection and that every c.e. Turing degree contains such a set. Furthermore, the regainingly approximable numbers lie properly between the computable and the left-computable numbers and are not closed under addition. While regainingly approximable numbers are easily seen to be i.o. K-trivial, we construct such an
$2^{-A}$ is regainingly approximable. We show that the set of regainingly approximable sets is neither closed under union nor intersection and that every c.e. Turing degree contains such a set. Furthermore, the regainingly approximable numbers lie properly between the computable and the left-computable numbers and are not closed under addition. While regainingly approximable numbers are easily seen to be i.o. K-trivial, we construct such an 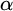 $\alpha $ such that
$\alpha $ such that 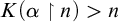 ${K(\alpha \restriction n)>n}$ for infinitely many n. Similarly, there exist regainingly approximable sets whose initial segment complexity infinitely often reaches the maximum possible for c.e. sets. Finally, there is a uniform algorithm splitting regular real numbers into two regainingly approximable numbers that are still regular.
${K(\alpha \restriction n)>n}$ for infinitely many n. Similarly, there exist regainingly approximable sets whose initial segment complexity infinitely often reaches the maximum possible for c.e. sets. Finally, there is a uniform algorithm splitting regular real numbers into two regainingly approximable numbers that are still regular.
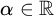
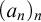
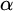
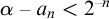
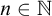
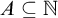
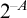
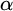
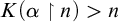
Zeros, chaotic ratios and the computational complexity of approximating the independence polynomial
- Part of
-
- Journal:
- Mathematical Proceedings of the Cambridge Philosophical Society / Volume 176 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 24 November 2023, pp. 459-494
- Print publication:
- March 2024
-
- Article
- Export citation
ON THE EXISTENCE OF STRONG PROOF COMPLEXITY GENERATORS
- Part of
-
- Journal:
- Bulletin of Symbolic Logic / Volume 30 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 22 November 2023, pp. 20-40
- Print publication:
- March 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Cook and Reckhow [5] pointed out that
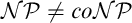 $\mathcal {N}\mathcal {P} \neq co\mathcal {N}\mathcal {P}$ iff there is no propositional proof system that admits polynomial size proofs of all tautologies. The theory of proof complexity generators aims at constructing sets of tautologies hard for strong and possibly for all proof systems. We focus on a conjecture from [16] in foundations of the theory that there is a proof complexity generator hard for all proof systems. This can be equivalently formulated (for p-time generators) without a reference to proof complexity notions as follows:
$\mathcal {N}\mathcal {P} \neq co\mathcal {N}\mathcal {P}$ iff there is no propositional proof system that admits polynomial size proofs of all tautologies. The theory of proof complexity generators aims at constructing sets of tautologies hard for strong and possibly for all proof systems. We focus on a conjecture from [16] in foundations of the theory that there is a proof complexity generator hard for all proof systems. This can be equivalently formulated (for p-time generators) without a reference to proof complexity notions as follows:• There exists a p-time function g stretching each input by one bit such that its range
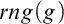 $rng(g)$ intersects all infinite
$rng(g)$ intersects all infinite 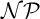 $\mathcal {N}\mathcal {P}$ sets.
$\mathcal {N}\mathcal {P}$ sets.
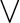 $\bigvee $-hardness, and show that one specific gadget generator is the
$\bigvee $-hardness, and show that one specific gadget generator is the 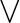 $\bigvee $-hardest (w.r.t. any sufficiently strong proof system). We define the class of feasibly infinite
$\bigvee $-hardest (w.r.t. any sufficiently strong proof system). We define the class of feasibly infinite 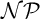 $\mathcal {N}\mathcal {P}$ sets and show, assuming a hypothesis from circuit complexity, that the conjecture holds for all feasibly infinite
$\mathcal {N}\mathcal {P}$ sets and show, assuming a hypothesis from circuit complexity, that the conjecture holds for all feasibly infinite 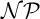 $\mathcal {N}\mathcal {P}$ sets.
$\mathcal {N}\mathcal {P}$ sets.
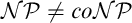
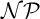
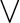
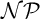
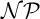
A PROOF COMPLEXITY CONJECTURE AND THE INCOMPLETENESS THEOREM
- Part of
-
- Journal:
- The Journal of Symbolic Logic , First View
- Published online by Cambridge University Press:
- 19 September 2023, pp. 1-5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Given a sound first-order p-time theory T capable of formalizing syntax of first-order logic we define a p-time function
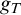 $g_T$ that stretches all inputs by one bit and we use its properties to show that T must be incomplete. We leave it as an open problem whether for some T the range of
$g_T$ that stretches all inputs by one bit and we use its properties to show that T must be incomplete. We leave it as an open problem whether for some T the range of 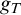 $g_T$ intersects all infinite
$g_T$ intersects all infinite 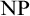 ${\mbox {NP}}$ sets (i.e., whether it is a proof complexity generator hard for all proof systems).
${\mbox {NP}}$ sets (i.e., whether it is a proof complexity generator hard for all proof systems).A propositional version of the construction shows that at least one of the following three statements is true:
1. There is no p-optimal propositional proof system (this is equivalent to the non-existence of a time-optimal propositional proof search algorithm).
2.
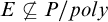 $E \not \subseteq P/poly$.
$E \not \subseteq P/poly$.3. There exists function h that stretches all inputs by one bit, is computable in sub-exponential time, and its range
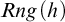 $Rng(h)$ intersects all infinite
$Rng(h)$ intersects all infinite 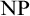 ${\text {NP}}$ sets.
${\text {NP}}$ sets.
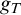
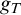
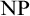
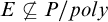
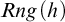
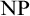
Phase transition for the generalized two-community stochastic block model
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 31 July 2023, pp. 385-400
- Print publication:
- June 2024
-
- Article
- Export citation
Polarised random
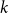 $k$-SAT
$k$-SAT
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 32 / Issue 6 / November 2023
- Published online by Cambridge University Press:
- 20 July 2023, pp. 885-899
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In this paper we study a variation of the random
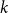 $k$-SAT problem, called polarised random
$k$-SAT problem, called polarised random 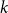 $k$-SAT, which contains both the classical random
$k$-SAT, which contains both the classical random 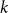 $k$-SAT model and the random version of monotone
$k$-SAT model and the random version of monotone 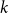 $k$-SAT another well-known NP-complete version of SAT. In this model there is a polarisation parameter
$k$-SAT another well-known NP-complete version of SAT. In this model there is a polarisation parameter 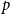 $p$, and in half of the clauses each variable occurs negated with probability
$p$, and in half of the clauses each variable occurs negated with probability 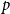 $p$ and pure otherwise, while in the other half the probabilities are interchanged. For
$p$ and pure otherwise, while in the other half the probabilities are interchanged. For 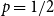 $p=1/2$ we get the classical random
$p=1/2$ we get the classical random 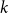 $k$-SAT model, and at the other extreme we have the fully polarised model where
$k$-SAT model, and at the other extreme we have the fully polarised model where 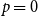 $p=0$, or 1. Here there are only two types of clauses: clauses where all
$p=0$, or 1. Here there are only two types of clauses: clauses where all 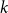 $k$ variables occur pure, and clauses where all
$k$ variables occur pure, and clauses where all 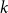 $k$ variables occur negated. That is, for
$k$ variables occur negated. That is, for 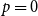 $p=0$, and
$p=0$, and 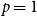 $p=1$, we get an instance of random monotone
$p=1$, we get an instance of random monotone 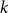 $k$-SAT.
$k$-SAT.We show that the threshold of satisfiability does not decrease as
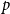 $p$ moves away from
$p$ moves away from 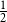 $\frac{1}{2}$ and thus that the satisfiability threshold for polarised random
$\frac{1}{2}$ and thus that the satisfiability threshold for polarised random 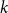 $k$-SAT with
$k$-SAT with 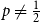 $p\neq \frac{1}{2}$ is an upper bound on the threshold for random
$p\neq \frac{1}{2}$ is an upper bound on the threshold for random 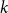 $k$-SAT. Hence the satisfiability threshold for random monotone
$k$-SAT. Hence the satisfiability threshold for random monotone 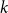 $k$-SAT is at least as large as for random
$k$-SAT is at least as large as for random 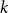 $k$-SAT, and we conjecture that asymptotically, for a fixed
$k$-SAT, and we conjecture that asymptotically, for a fixed 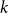 $k$, the two thresholds coincide.
$k$, the two thresholds coincide.
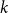
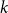
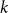
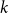
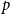
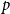
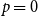
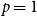
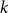
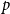
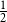
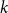
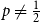
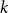
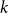
New lower bounds for matrix multiplication and
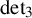 $\operatorname {det}_3$
$\operatorname {det}_3$
- Part of
-
- Journal:
- Forum of Mathematics, Pi / Volume 11 / 2023
- Published online by Cambridge University Press:
- 29 May 2023, e17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Let
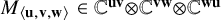 $M_{\langle \mathbf {u},\mathbf {v},\mathbf {w}\rangle }\in \mathbb C^{\mathbf {u}\mathbf {v}}{\mathord { \otimes } } \mathbb C^{\mathbf {v}\mathbf {w}}{\mathord { \otimes } } \mathbb C^{\mathbf {w}\mathbf {u}}$
denote the matrix multiplication tensor (and write
$M_{\langle \mathbf {u},\mathbf {v},\mathbf {w}\rangle }\in \mathbb C^{\mathbf {u}\mathbf {v}}{\mathord { \otimes } } \mathbb C^{\mathbf {v}\mathbf {w}}{\mathord { \otimes } } \mathbb C^{\mathbf {w}\mathbf {u}}$
denote the matrix multiplication tensor (and write
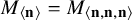 $M_{\langle \mathbf {n} \rangle }=M_{\langle \mathbf {n},\mathbf {n},\mathbf {n}\rangle }$
), and let
$M_{\langle \mathbf {n} \rangle }=M_{\langle \mathbf {n},\mathbf {n},\mathbf {n}\rangle }$
), and let
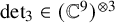 $\operatorname {det}_3\in (\mathbb C^9)^{{\mathord { \otimes } } 3}$
denote the determinant polynomial considered as a tensor. For a tensor T, let
$\operatorname {det}_3\in (\mathbb C^9)^{{\mathord { \otimes } } 3}$
denote the determinant polynomial considered as a tensor. For a tensor T, let
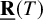 $\underline {\mathbf {R}}(T)$
denote its border rank. We (i) give the first hand-checkable algebraic proof that
$\underline {\mathbf {R}}(T)$
denote its border rank. We (i) give the first hand-checkable algebraic proof that
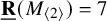 $\underline {\mathbf {R}}(M_{\langle 2\rangle })=7$
, (ii) prove
$\underline {\mathbf {R}}(M_{\langle 2\rangle })=7$
, (ii) prove
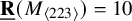 $\underline {\mathbf {R}}(M_{\langle 223\rangle })=10$
and
$\underline {\mathbf {R}}(M_{\langle 223\rangle })=10$
and
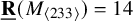 $\underline {\mathbf {R}}(M_{\langle 233\rangle })=14$
, where previously the only nontrivial matrix multiplication tensor whose border rank had been determined was
$\underline {\mathbf {R}}(M_{\langle 233\rangle })=14$
, where previously the only nontrivial matrix multiplication tensor whose border rank had been determined was
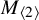 $M_{\langle 2\rangle }$
, (iii) prove
$M_{\langle 2\rangle }$
, (iii) prove
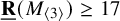 $\underline {\mathbf {R}}( M_{\langle 3\rangle })\geq 17$
, (iv) prove
$\underline {\mathbf {R}}( M_{\langle 3\rangle })\geq 17$
, (iv) prove
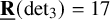 $\underline {\mathbf {R}}(\operatorname {det}_3)=17$
, improving the previous lower bound of
$\underline {\mathbf {R}}(\operatorname {det}_3)=17$
, improving the previous lower bound of
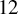 $12$
, (v) prove
$12$
, (v) prove
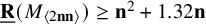 $\underline {\mathbf {R}}(M_{\langle 2\mathbf {n}\mathbf {n}\rangle })\geq \mathbf {n}^2+1.32\mathbf {n}$
for all
$\underline {\mathbf {R}}(M_{\langle 2\mathbf {n}\mathbf {n}\rangle })\geq \mathbf {n}^2+1.32\mathbf {n}$
for all
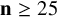 $\mathbf {n}\geq 25$
, where previously only
$\mathbf {n}\geq 25$
, where previously only
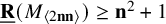 $\underline {\mathbf {R}}(M_{\langle 2\mathbf {n}\mathbf {n}\rangle })\geq \mathbf {n}^2+1$
was known, as well as lower bounds for
$\underline {\mathbf {R}}(M_{\langle 2\mathbf {n}\mathbf {n}\rangle })\geq \mathbf {n}^2+1$
was known, as well as lower bounds for
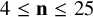 $4\leq \mathbf {n}\leq 25$
, and (vi) prove
$4\leq \mathbf {n}\leq 25$
, and (vi) prove
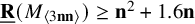 $\underline {\mathbf {R}}(M_{\langle 3\mathbf {n}\mathbf {n}\rangle })\geq \mathbf {n}^2+1.6\mathbf {n}$
for all
$\underline {\mathbf {R}}(M_{\langle 3\mathbf {n}\mathbf {n}\rangle })\geq \mathbf {n}^2+1.6\mathbf {n}$
for all
 $\mathbf {n} \ge 18$
, where previously only
$\mathbf {n} \ge 18$
, where previously only
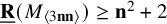 $\underline {\mathbf {R}}(M_{\langle 3\mathbf {n}\mathbf {n}\rangle })\geq \mathbf {n}^2+2$
was known. The last two results are significant for two reasons: (i) they are essentially the first nontrivial lower bounds for tensors in an “unbalanced” ambient space and (ii) they demonstrate that the methods we use (border apolarity) may be applied to sequences of tensors.
$\underline {\mathbf {R}}(M_{\langle 3\mathbf {n}\mathbf {n}\rangle })\geq \mathbf {n}^2+2$
was known. The last two results are significant for two reasons: (i) they are essentially the first nontrivial lower bounds for tensors in an “unbalanced” ambient space and (ii) they demonstrate that the methods we use (border apolarity) may be applied to sequences of tensors.The methods used to obtain the results are new and “nonnatural” in the sense of Razborov and Rudich, in that the results are obtained via an algorithm that cannot be effectively applied to generic tensors. We utilize a new technique, called border apolarity developed by Buczyńska and Buczyński in the general context of toric varieties. We apply this technique to develop an algorithm that, given a tensor T and an integer r, in a finite number of steps, either outputs that there is no border rank r decomposition for T or produces a list of all normalized ideals which could potentially result from a border rank decomposition. The algorithm is effectively implementable when T has a large symmetry group, in which case it outputs potential decompositions in a natural normal form. The algorithm is based on algebraic geometry and representation theory.
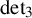
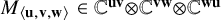
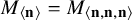
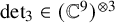
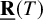
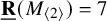
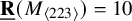
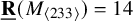
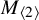
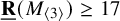
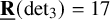
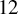
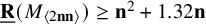
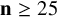
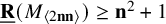
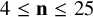
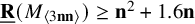

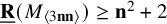
The first-order theory of binary overlap-free words is decidable
- Part of
-
- Journal:
- Canadian Journal of Mathematics , First View
- Published online by Cambridge University Press:
- 26 May 2023, pp. 1-19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We show that the first-order logical theory of the binary overlap-free words (and, more generally, the
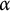 $\alpha $-free words for rational
$\alpha $-free words for rational 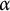 $\alpha $,
$\alpha $, 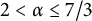 $2 < \alpha \leq 7/3$), is decidable. As a consequence, many results previously obtained about this class through tedious case-based proofs can now be proved “automatically,” using a decision procedure, and new claims can be proved or disproved simply by restating them as logical formulas.
$2 < \alpha \leq 7/3$), is decidable. As a consequence, many results previously obtained about this class through tedious case-based proofs can now be proved “automatically,” using a decision procedure, and new claims can be proved or disproved simply by restating them as logical formulas.
Stable finiteness of twisted group rings and noisy linear cellular automata
- Part of
-
- Journal:
- Canadian Journal of Mathematics , First View
- Published online by Cambridge University Press:
- 22 May 2023, pp. 1-20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
For linear nonuniform cellular automata (NUCA) which are local perturbations of linear CA over a group universe G and a finite-dimensional vector space alphabet V over an arbitrary field k, we investigate their Dedekind finiteness property, also known as the direct finiteness property, i.e., left or right invertibility implies invertibility. We say that the group G is
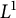 $L^1$-surjunctive, resp. finitely
$L^1$-surjunctive, resp. finitely 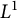 $L^1$-surjunctive, if all such linear NUCA are automatically surjective whenever they are stably injective, resp. when in addition k is finite. In parallel, we introduce the ring
$L^1$-surjunctive, if all such linear NUCA are automatically surjective whenever they are stably injective, resp. when in addition k is finite. In parallel, we introduce the ring 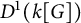 $D^1(k[G])$ which is the Cartesian product
$D^1(k[G])$ which is the Cartesian product 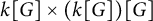 $k[G] \times (k[G])[G]$ as an additive group but the multiplication is twisted in the second component. The ring
$k[G] \times (k[G])[G]$ as an additive group but the multiplication is twisted in the second component. The ring 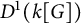 $D^1(k[G])$ contains naturally the group ring
$D^1(k[G])$ contains naturally the group ring 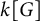 $k[G]$ and we obtain a dynamical characterization of its stable finiteness for every field k in terms of the finite
$k[G]$ and we obtain a dynamical characterization of its stable finiteness for every field k in terms of the finite 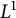 $L^1$-surjunctivity of the group G, which holds, for example, when G is residually finite or initially subamenable. Our results extend known results in the case of CA.
$L^1$-surjunctivity of the group G, which holds, for example, when G is residually finite or initially subamenable. Our results extend known results in the case of CA.
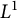
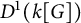
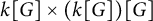
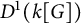
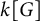
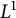
SOME CONSEQUENCES OF
 ${\mathrm {TD}}$ AND
${\mathrm {TD}}$ AND 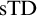 ${\mathrm {sTD}}$
${\mathrm {sTD}}$
- Part of
-
- Journal:
- The Journal of Symbolic Logic / Volume 88 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 15 May 2023, pp. 1573-1589
- Print publication:
- December 2023
-
- Article
- Export citation
-
Strong Turing Determinacy, or
 ${\mathrm {sTD}}$, is the statement that for every set A of reals, if
${\mathrm {sTD}}$, is the statement that for every set A of reals, if 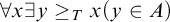 $\forall x\exists y\geq _T x (y\in A)$, then there is a pointed set
$\forall x\exists y\geq _T x (y\in A)$, then there is a pointed set 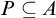 $P\subseteq A$. We prove the following consequences of Turing Determinacy (
$P\subseteq A$. We prove the following consequences of Turing Determinacy ( ${\mathrm {TD}}$) and
${\mathrm {TD}}$) and  ${\mathrm {sTD}}$ over
${\mathrm {sTD}}$ over 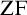 ${\mathrm {ZF}}$—the Zermelo–Fraenkel axiomatic set theory without the Axiom of Choice:
${\mathrm {ZF}}$—the Zermelo–Fraenkel axiomatic set theory without the Axiom of Choice: (1)
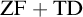 ${\mathrm {ZF}}+{\mathrm {TD}}$ implies
${\mathrm {ZF}}+{\mathrm {TD}}$ implies 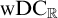 $\mathrm {wDC}_{\mathbb {R}}$—a weaker version of
$\mathrm {wDC}_{\mathbb {R}}$—a weaker version of 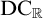 $\mathrm {DC}_{\mathbb {R}}$.
$\mathrm {DC}_{\mathbb {R}}$.(2)
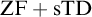 ${\mathrm {ZF}}+{\mathrm {sTD}}$ implies that every set of reals is measurable and has Baire property.
${\mathrm {ZF}}+{\mathrm {sTD}}$ implies that every set of reals is measurable and has Baire property.(3)
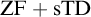 ${\mathrm {ZF}}+{\mathrm {sTD}}$ implies that every uncountable set of reals has a perfect subset.
${\mathrm {ZF}}+{\mathrm {sTD}}$ implies that every uncountable set of reals has a perfect subset.(4)
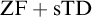 ${\mathrm {ZF}}+{\mathrm {sTD}}$ implies that for every set of reals A and every
${\mathrm {ZF}}+{\mathrm {sTD}}$ implies that for every set of reals A and every 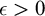 $\epsilon>0$:
$\epsilon>0$:(a) There is a closed set
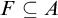 $F\subseteq A$ such that
$F\subseteq A$ such that 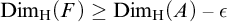 $\mathrm {Dim_H}(F)\geq \mathrm {Dim_H}(A)-\epsilon $, where
$\mathrm {Dim_H}(F)\geq \mathrm {Dim_H}(A)-\epsilon $, where 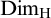 $\mathrm {Dim_H}$ is the Hausdorff dimension.
$\mathrm {Dim_H}$ is the Hausdorff dimension.(b) There is a closed set
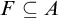 $F\subseteq A$ such that
$F\subseteq A$ such that 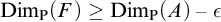 $\mathrm {Dim_P}(F)\geq \mathrm {Dim_P}(A)-\epsilon $, where
$\mathrm {Dim_P}(F)\geq \mathrm {Dim_P}(A)-\epsilon $, where 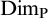 $\mathrm {Dim_P}$ is the packing dimension.
$\mathrm {Dim_P}$ is the packing dimension.

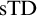

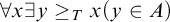
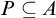


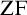
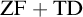
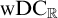
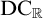
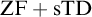
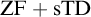
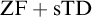
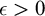
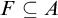
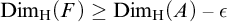
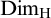
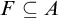
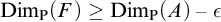
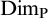
Rigid continuation paths II. structured polynomial systems
- Part of
-
- Journal:
- Forum of Mathematics, Pi / Volume 11 / 2023
- Published online by Cambridge University Press:
- 14 April 2023, e12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This work studies the average complexity of solving structured polynomial systems that are characterised by a low evaluation cost, as opposed to the dense random model previously used. Firstly, we design a continuation algorithm that computes, with high probability, an approximate zero of a polynomial system given only as black-box evaluation program. Secondly, we introduce a universal model of random polynomial systems with prescribed evaluation complexity L. Combining both, we show that we can compute an approximate zero of a random structured polynomial system with n equations of degree at most
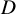 ${D}$
in n variables with only
${D}$
in n variables with only
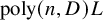 $\operatorname {poly}(n, {D}) L$
operations with high probability. This exceeds the expectations implicit in Smale’s 17th problem.
$\operatorname {poly}(n, {D}) L$
operations with high probability. This exceeds the expectations implicit in Smale’s 17th problem.
Asymptotic normality for
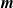 $\boldsymbol{m}$-dependent and constrained
$\boldsymbol{m}$-dependent and constrained 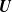 $\boldsymbol{U}$-statistics, with applications to pattern matching in random strings and permutations
$\boldsymbol{U}$-statistics, with applications to pattern matching in random strings and permutations
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 28 March 2023, pp. 841-894
- Print publication:
- September 2023
-
- Article
- Export citation
-
We study (asymmetric)
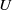 $U$-statistics based on a stationary sequence of
$U$-statistics based on a stationary sequence of 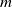 $m$-dependent variables; moreover, we consider constrained
$m$-dependent variables; moreover, we consider constrained 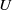 $U$-statistics, where the defining multiple sum only includes terms satisfying some restrictions on the gaps between indices. Results include a law of large numbers and a central limit theorem, together with results on rate of convergence, moment convergence, functional convergence, and a renewal theory version.
$U$-statistics, where the defining multiple sum only includes terms satisfying some restrictions on the gaps between indices. Results include a law of large numbers and a central limit theorem, together with results on rate of convergence, moment convergence, functional convergence, and a renewal theory version.Special attention is paid to degenerate cases where, after the standard normalization, the asymptotic variance vanishes; in these cases non-normal limits occur after a different normalization.
The results are motivated by applications to pattern matching in random strings and permutations. We obtain both new results and new proofs of old results.
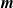
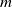
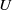
MULTIPLICATION TABLES AND WORD-HYPERBOLICITY IN FREE PRODUCTS OF SEMIGROUPS, MONOIDS AND GROUPS
- Part of
-
- Journal:
- Journal of the Australian Mathematical Society / Volume 115 / Issue 3 / December 2023
- Published online by Cambridge University Press:
- 17 March 2023, pp. 396-430
- Print publication:
- December 2023
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This article studies the properties of word-hyperbolic semigroups and monoids, that is, those having context-free multiplication tables with respect to a regular combing, as defined by Duncan and Gilman [‘Word hyperbolic semigroups’, Math. Proc. Cambridge Philos. Soc. 136(3) (2004), 513–524]. In particular, the preservation of word-hyperbolicity under taking free products is considered. Under mild conditions on the semigroups involved, satisfied, for example, by monoids or regular semigroups, we prove that the semigroup free product of two word-hyperbolic semigroups is again word-hyperbolic. Analogously, with a mild condition on the uniqueness of representation for the identity element, satisfied, for example, by groups, we prove that the monoid free product of two word-hyperbolic monoids is word-hyperbolic. The methods are language-theoretically general, and apply equally well to semigroups, monoids or groups with a
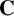 $\mathbf {C}$-multiplication table, where
$\mathbf {C}$-multiplication table, where 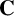 $\mathbf {C}$ is any reversal-closed super-
$\mathbf {C}$ is any reversal-closed super-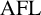 $\operatorname {\mathrm {AFL}}$. In particular, we deduce that the free product of two groups with
$\operatorname {\mathrm {AFL}}$. In particular, we deduce that the free product of two groups with 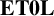 $\mathbf {ET0L}$ with respect to indexed multiplication tables again has an
$\mathbf {ET0L}$ with respect to indexed multiplication tables again has an 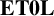 $\mathbf {ET0L}$ with respect to an indexed multiplication table.
$\mathbf {ET0L}$ with respect to an indexed multiplication table.
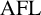
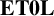
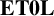
An efficient method for generating a discrete uniform distribution using a biased random source
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 07 March 2023, pp. 1069-1078
- Print publication:
- September 2023
-
- Article
- Export citation
-
We present an efficient algorithm to generate a discrete uniform distribution on a set of p elements using a biased random source for p prime. The algorithm generalizes Von Neumann’s method and improves the computational efficiency of Dijkstra’s method. In addition, the algorithm is extended to generate a discrete uniform distribution on any finite set based on the prime factorization of integers. The average running time of the proposed algorithm is overall sublinear:
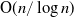 $\operatorname{O}\!(n/\log n)$.
$\operatorname{O}\!(n/\log n)$.
THE ZHOU ORDINAL OF LABELLED MARKOV PROCESSES OVER SEPARABLE SPACES
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 16 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 27 February 2023, pp. 1011-1032
- Print publication:
- December 2023
-
- Article
- Export citation
-
There exist two notions of equivalence of behavior between states of a Labelled Markov Process (LMP): state bisimilarity and event bisimilarity. The first one can be considered as an appropriate generalization to continuous spaces of Larsen and Skou’s probabilistic bisimilarity, whereas the second one is characterized by a natural logic. C. Zhou expressed state bisimilarity as the greatest fixed point of an operator
 $\mathcal {O}$, and thus introduced an ordinal measure of the discrepancy between it and event bisimilarity. We call this ordinal the Zhou ordinal of
$\mathcal {O}$, and thus introduced an ordinal measure of the discrepancy between it and event bisimilarity. We call this ordinal the Zhou ordinal of 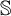 $\mathbb {S}$,
$\mathbb {S}$, 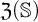 $\mathfrak {Z}(\mathbb {S})$. When
$\mathfrak {Z}(\mathbb {S})$. When 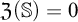 $\mathfrak {Z}(\mathbb {S})=0$,
$\mathfrak {Z}(\mathbb {S})=0$, 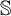 $\mathbb {S}$ satisfies the Hennessy–Milner property. The second author proved the existence of an LMP
$\mathbb {S}$ satisfies the Hennessy–Milner property. The second author proved the existence of an LMP 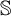 $\mathbb {S}$ with
$\mathbb {S}$ with 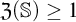 $\mathfrak {Z}(\mathbb {S}) \geq 1$ and Zhou showed that there are LMPs having an infinite Zhou ordinal. In this paper we show that there are LMPs
$\mathfrak {Z}(\mathbb {S}) \geq 1$ and Zhou showed that there are LMPs having an infinite Zhou ordinal. In this paper we show that there are LMPs 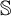 $\mathbb {S}$ over separable metrizable spaces having arbitrary large countable
$\mathbb {S}$ over separable metrizable spaces having arbitrary large countable 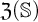 $\mathfrak {Z}(\mathbb {S})$ and that it is consistent with the axioms of
$\mathfrak {Z}(\mathbb {S})$ and that it is consistent with the axioms of 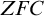 $\mathit {ZFC}$ that there is such a process with an uncountable Zhou ordinal.
$\mathit {ZFC}$ that there is such a process with an uncountable Zhou ordinal.

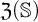
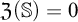
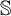
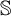
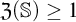
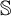
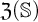
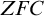
Functional norms, condition numbers and numerical algorithms in algebraic geometry
- Part of
-
- Journal:
- Forum of Mathematics, Sigma / Volume 10 / 2022
- Published online by Cambridge University Press:
- 22 November 2022, e103
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In numerical linear algebra, a well-established practice is to choose a norm that exploits the structure of the problem at hand to optimise accuracy or computational complexity. In numerical polynomial algebra, a single norm (attributed to Weyl) dominates the literature. This article initiates the use of
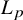 $L_p$
norms for numerical algebraic geometry, with an emphasis on
$L_p$
norms for numerical algebraic geometry, with an emphasis on
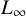 $L_{\infty }$
. This classical idea yields strong improvements in the analysis of the number of steps performed by numerous iterative algorithms. In particular, we exhibit three algorithms where, despite the complexity of computing
$L_{\infty }$
. This classical idea yields strong improvements in the analysis of the number of steps performed by numerous iterative algorithms. In particular, we exhibit three algorithms where, despite the complexity of computing
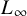 $L_{\infty }$
-norm, the use of
$L_{\infty }$
-norm, the use of
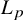 $L_p$
-norms substantially reduces computational complexity: a subdivision-based algorithm in real algebraic geometry for computing the homology of semialgebraic sets, a well-known meshing algorithm in computational geometry and the computation of zeros of systems of complex quadratic polynomials (a particular case of Smale’s 17th problem).
$L_p$
-norms substantially reduces computational complexity: a subdivision-based algorithm in real algebraic geometry for computing the homology of semialgebraic sets, a well-known meshing algorithm in computational geometry and the computation of zeros of systems of complex quadratic polynomials (a particular case of Smale’s 17th problem).
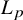
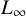
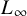
On images of subshifts under embeddings of symbolic varieties
- Part of
-
- Journal:
- Ergodic Theory and Dynamical Systems / Volume 43 / Issue 9 / September 2023
- Published online by Cambridge University Press:
- 01 August 2022, pp. 3131-3149
- Print publication:
- September 2023
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We show that the image of a subshift X under various injective morphisms of symbolic algebraic varieties over monoid universes with algebraic variety alphabets is a subshift of finite type, respectively a sofic subshift, if and only if so is X. Similarly, let G be a countable monoid and let A, B be Artinian modules over a ring. We prove that for every closed subshift submodule
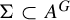 $\Sigma \subset A^G$ and every injective G-equivariant uniformly continuous module homomorphism
$\Sigma \subset A^G$ and every injective G-equivariant uniformly continuous module homomorphism 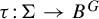 $\tau \colon \! \Sigma \to B^G$, a subshift
$\tau \colon \! \Sigma \to B^G$, a subshift 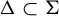 $\Delta \subset \Sigma $ is of finite type, respectively sofic, if and only if so is the image
$\Delta \subset \Sigma $ is of finite type, respectively sofic, if and only if so is the image 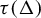 $\tau (\Delta )$. Generalizations for admissible group cellular automata over admissible Artinian group structure alphabets are also obtained.
$\tau (\Delta )$. Generalizations for admissible group cellular automata over admissible Artinian group structure alphabets are also obtained.