
444 results
Bivariate tempered space-fractional Poisson process and shock models
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 23 May 2024, pp. 1-17
-
- Article
- Export citation
-
We introduce a bivariate tempered space-fractional Poisson process (BTSFPP) by time-changing the bivariate Poisson process with an independent tempered
 $\alpha$-stable subordinator. We study its distributional properties and its connection to differential equations. The Lévy measure for the BTSFPP is also derived. A bivariate competing risks and shock model based on the BTSFPP for predicting the failure times of items that undergo two random shocks is also explored. The system is supposed to break when the sum of two types of shock reaches a certain random threshold. Various results related to reliability, such as reliability function, hazard rates, failure density, and the probability that failure occurs due to a certain type of shock, are studied. We show that for a general Lévy subordinator, the failure time of the system is exponentially distributed with mean depending on the Laplace exponent of the Lévy subordinator when the threshold has a geometric distribution. Some special cases and several typical examples are also demonstrated.
$\alpha$-stable subordinator. We study its distributional properties and its connection to differential equations. The Lévy measure for the BTSFPP is also derived. A bivariate competing risks and shock model based on the BTSFPP for predicting the failure times of items that undergo two random shocks is also explored. The system is supposed to break when the sum of two types of shock reaches a certain random threshold. Various results related to reliability, such as reliability function, hazard rates, failure density, and the probability that failure occurs due to a certain type of shock, are studied. We show that for a general Lévy subordinator, the failure time of the system is exponentially distributed with mean depending on the Laplace exponent of the Lévy subordinator when the threshold has a geometric distribution. Some special cases and several typical examples are also demonstrated.

Replication studies in engineering design – a feasibility study
-
- Journal:
- Proceedings of the Design Society / Volume 4 / May 2024
- Published online by Cambridge University Press:
- 16 May 2024, pp. 115-124
-
- Article
-
- You have access
- Open access
- Export citation
Durability as a techno-socio-economic concept
-
- Journal:
- Proceedings of the Design Society / Volume 4 / May 2024
- Published online by Cambridge University Press:
- 16 May 2024, pp. 1219-1228
-
- Article
-
- You have access
- Open access
- Export citation
Validation of the Spanish translation Sheffield Profile for Assessment and Referral for Care (SPARC-Sp) at the Hospital Universitario San Jose of Popayan, Colombia
-
- Journal:
- Palliative & Supportive Care , First View
- Published online by Cambridge University Press:
- 27 March 2024, pp. 1-12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The Free-Riding Issue in Contemporary Organizations: Lessons from the Common Good Perspective
-
- Journal:
- Business Ethics Quarterly , First View
- Published online by Cambridge University Press:
- 25 March 2024, pp. 1-26
-
- Article
-
- You have access
- HTML
- Export citation
Development of Flood Preparedness Behavior Scale: A Methodological Validity and Reliability Study
-
- Journal:
- Prehospital and Disaster Medicine / Volume 39 / Issue 2 / April 2024
- Published online by Cambridge University Press:
- 25 March 2024, pp. 123-130
- Print publication:
- April 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Validation of the Japanese version of the Social Functioning in Dementia scale and COVID-19 pandemic’s impact on social function in mild cognitive impairment and mild dementia
-
- Journal:
- International Psychogeriatrics , First View
- Published online by Cambridge University Press:
- 11 March 2024, pp. 1-14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Reliability assessment of off-policy deep reinforcement learning: A benchmark for aerodynamics
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 25 January 2024, e2
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Turkish adaptation, validation and reliability of the US Adult Food Security Survey Module in university students
-
- Journal:
- Public Health Nutrition / Volume 27 / Issue 1 / 2024
- Published online by Cambridge University Press:
- 22 January 2024, e45
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Chapter 1 - Introduction
-
- Book:
- Applying Benford's Law for Assessing the Validity of Social Science Data
- Published online:
- 09 November 2023
- Print publication:
- 23 November 2023, pp 1-10
-
- Chapter
-
- You have access
- HTML
- Export citation
Palliative care and spiritual care competency measurement among Turkish Nurses: A scale adaptation study
-
- Journal:
- Palliative & Supportive Care / Volume 21 / Issue 6 / December 2023
- Published online by Cambridge University Press:
- 06 November 2023, pp. 1048-1058
-
- Article
- Export citation
Postpartum family planning attitudes among Turkish women: development of a reliable and valid scale
-
- Journal:
- Primary Health Care Research & Development / Volume 24 / 2023
- Published online by Cambridge University Press:
- 18 October 2023, e59
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Safe and valid? A systematic review of the psychometric properties of culturally adapted depression scales for use among Indigenous populations
-
- Journal:
- Cambridge Prisms: Global Mental Health / Volume 10 / 2023
- Published online by Cambridge University Press:
- 14 September 2023, e60
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Reliability analyses of linear two-dimensional consecutive k-type systems
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 14 August 2023, pp. 439-464
- Print publication:
- June 2024
-
- Article
- Export citation
-
In this paper, several linear two-dimensional consecutive k-type systems are studied, which include the linear connected-(k, r)-out-of-
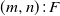 $(m,n)\colon\! F$ system and the linear l-connected-(k, r)-out-of-
$(m,n)\colon\! F$ system and the linear l-connected-(k, r)-out-of-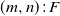 $(m,n)\colon\! F$ system without/with overlapping. Reliabilities of these systems are studied via the finite Markov chain imbedding approach (FMCIA) in a novel way. Some numerical examples are provided to illustrate the theoretical results established here and also to demonstrate the efficiency of the developed method. Finally, some possible applications and generalizations of the developed results are pointed out.
$(m,n)\colon\! F$ system without/with overlapping. Reliabilities of these systems are studied via the finite Markov chain imbedding approach (FMCIA) in a novel way. Some numerical examples are provided to illustrate the theoretical results established here and also to demonstrate the efficiency of the developed method. Finally, some possible applications and generalizations of the developed results are pointed out.
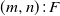
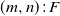
Asymptotic behaviors of aggregated Markov processes
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 2 / April 2024
- Published online by Cambridge University Press:
- 25 July 2023, pp. 299-317
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The future of diagnosis in clinical neurosciences: Comparing multiple sclerosis and schizophrenia
-
- Journal:
- European Psychiatry / Volume 66 / Issue 1 / 2023
- Published online by Cambridge University Press:
- 21 July 2023, e58
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Darwin's doubt or Plantinga's conviction? Some failures in Plantinga's attempt to debunk naturalistic evolution
-
- Journal:
- Religious Studies , First View
- Published online by Cambridge University Press:
- 12 July 2023, pp. 1-16
-
- Article
- Export citation
8 - Moral Perception and Singular Moral Judgment
- from Part III - Moral Knowledge and Normative Realism
-
- Book:
- Of Moral Conduct
- Published online:
- 08 June 2023
- Print publication:
- 22 June 2023, pp 170-184
-
- Chapter
- Export citation
RELIABILITY ANALYSIS FOR SENSOR NETWORKS AND THEIR DATA ACQUISITION: A SYSTEMATIC LITERATURE REVIEW
-
- Journal:
- Proceedings of the Design Society / Volume 3 / July 2023
- Published online by Cambridge University Press:
- 19 June 2023, pp. 3065-3074
-
- Article
-
- You have access
- Open access
- Export citation
Chapter 2 - The History of Shaken Baby Syndrome
- from Section 1 - Prologue
-
-
- Book:
- Shaken Baby Syndrome
- Published online:
- 07 June 2023
- Print publication:
- 08 June 2023, pp 11-32
-
- Chapter
- Export citation
