136 results
Detecting linguistic variation with geographic sampling
-
- Journal:
- Journal of Linguistic Geography , First View
- Published online by Cambridge University Press:
- 06 May 2024, pp. 1-8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Dialectometry-based classification of the Central–Southern Italian dialects
-
- Journal:
- Journal of Linguistic Geography , First View
- Published online by Cambridge University Press:
- 29 April 2024, pp. 1-11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Joint multitemporal SAR and optical mapping of urban changes
-
- Journal:
- International Journal of Microwave and Wireless Technologies , First View
- Published online by Cambridge University Press:
- 22 March 2024, pp. 1-12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
9 - RIO as a Gateway to Field Theory
- from Part III - RIO as a Gateway
-
- Book:
- Regression Inside Out
- Published online:
- 21 March 2024
- Print publication:
- 22 February 2024, pp 202-219
-
- Chapter
- Export citation
6 - Interaction Detection
- from Part II - Action and Interaction
-
- Book:
- Regression Inside Out
- Published online:
- 21 March 2024
- Print publication:
- 22 February 2024, pp 113-124
-
- Chapter
- Export citation
The beer garden state: Neolocalism and clustering of craft breweries in New Jersey
-
- Journal:
- Journal of Wine Economics / Volume 19 / Issue 2 / May 2024
- Published online by Cambridge University Press:
- 05 February 2024, pp. 133-155
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
On clustering levels of a hierarchical categorical risk factor
-
- Journal:
- Annals of Actuarial Science , First View
- Published online by Cambridge University Press:
- 01 February 2024, pp. 1-39
-
- Article
- Export citation
Automated detection of edge clusters via an overfitted mixture prior
-
- Journal:
- Network Science / Volume 12 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 19 January 2024, pp. 88-106
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Cladistics groupings of the active breeding cocoa genetic resources of Nigeria for physicochemical and nutraceutical traits
-
- Journal:
- Plant Genetic Resources / Volume 21 / Issue 5 / October 2023
- Published online by Cambridge University Press:
- 30 November 2023, pp. 454-462
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Visualising flight regimes using self-organising maps
-
- Journal:
- The Aeronautical Journal / Volume 127 / Issue 1316 / October 2023
- Published online by Cambridge University Press:
- 04 September 2023, pp. 1817-1831
-
- Article
- Export citation
Normal and stable approximation to subgraph counts in superpositions of Bernoulli random graphs
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 18 August 2023, pp. 401-419
- Print publication:
- June 2024
-
- Article
- Export citation
-
Real networks often exhibit clustering, the tendency to form relatively small groups of nodes with high edge densities. This clustering property can cause large numbers of small and dense subgraphs to emerge in otherwise sparse networks. Subgraph counts are an important and commonly used source of information about the network structure and function. We study probability distributions of subgraph counts in a community affiliation graph. This is a random graph generated as an overlay of m partly overlapping independent Bernoulli random graphs (layers)
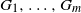 $G_1,\dots,G_m$ with variable sizes and densities. The model is parameterised by a joint distribution of layer sizes and densities. When m grows linearly in the number of nodes n, the model generates sparse random graphs with a rich statistical structure, admitting a nonvanishing clustering coefficient and a power-law limiting degree distribution. In this paper we establish the normal and
$G_1,\dots,G_m$ with variable sizes and densities. The model is parameterised by a joint distribution of layer sizes and densities. When m grows linearly in the number of nodes n, the model generates sparse random graphs with a rich statistical structure, admitting a nonvanishing clustering coefficient and a power-law limiting degree distribution. In this paper we establish the normal and  $\alpha$-stable approximations to the numbers of small cliques, cycles, and more general 2-connected subgraphs of a community affiliation graph.
$\alpha$-stable approximations to the numbers of small cliques, cycles, and more general 2-connected subgraphs of a community affiliation graph.

2 - Multivariate Analysis
-
- Book:
- Data Science for the Geosciences
- Published online:
- 25 August 2023
- Print publication:
- 17 August 2023, pp 43-104
-
- Chapter
- Export citation
Genetic variation in Bambara ground nuts as revealed by agro-morphological and DArTseq markers and selection for improved yield performance
-
- Journal:
- Plant Genetic Resources / Volume 21 / Issue 2 / April 2023
- Published online by Cambridge University Press:
- 01 August 2023, pp. 123-130
-
- Article
- Export citation
Clustering of causal graphs to explore drivers of river discharge
-
- Journal:
- Environmental Data Science / Volume 2 / 2023
- Published online by Cambridge University Press:
- 04 July 2023, e25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Chapter 8 - Winners Take All
- from Section 2 - The Financial Determinants of Discovery
-
- Book:
- The Trajectory of Discovery
- Published online:
- 06 April 2023
- Print publication:
- 13 April 2023, pp 43-50
-
- Chapter
- Export citation
10 - Unsupervised Learning
-
- Book:
- Introduction to Environmental Data Science
- Published online:
- 23 March 2023
- Print publication:
- 23 March 2023, pp 330-371
-
- Chapter
- Export citation
A clustering-based method for estimating pennation angle from B-mode ultrasound images
- Part of
-
- Journal:
- Wearable Technologies / Volume 4 / 2023
- Published online by Cambridge University Press:
- 01 March 2023, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Multiphase segmentation of digital material images
-
- Journal:
- Data-Centric Engineering / Volume 4 / 2023
- Published online by Cambridge University Press:
- 02 February 2023, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Multiphase segmentation of pore-scale features and identification of mineralogy from digital images of materials is critical for many applications in the natural resources sector. However, the materials involved (rocks, catalyst pellets, and synthetic alloys) have complex and unpredictable composition. Algorithms that can be extended for multiphase segmentation of images of these materials are relatively few and very human-intensive. Challenges lie in designing algorithms that are context free, can function with less training data, and can handle the unpredictability of material composition. Semisupervised algorithms have shown success in classification in situations characterized by limited training data; they use unlabeled data in addition to labeled data to produce classification. The segmentation obtained can be more accurate than fully supervised learning approaches. This work proposes using a semisupervised clustering algorithm named Continuous Iterative Guided Spectral Class Rejection (CIGSCR) toward multiphase segmentation of digital scans of materials. CIGSCR harnesses spectral cohesion, splitting the intensity histogram of the input image down into clusters. This splitting provides the foundation for classification strategies that can be implemented as postprocessing steps to get the final segmentation. One classification strategy is presented. Micro-computed tomography scans of rocks are used to present the results. It is demonstrated that CIGSCR successfully enables distinguishing features up to the uniqueness of grayscale values, and extracting features present in full image stacks (3D), including features not presented in the training data. Results including instances of success and limitations are presented. Scalability to data sizes
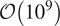 $ \mathcal{O}\left({10}^9\right) $
voxels is briefly discussed.
$ \mathcal{O}\left({10}^9\right) $
voxels is briefly discussed.
Secondary sexual dimorphism in biomass production of Ilex paraguariensis progenies associated with their provenances and morphotypes
-
- Journal:
- Experimental Agriculture / Volume 59 / 2023
- Published online by Cambridge University Press:
- 26 January 2023, e3
-
- Article
- Export citation
Toward random walk-based clustering of variable-order networks
-
- Journal:
- Network Science / Volume 10 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 22 December 2022, pp. 381-399
-
- Article
- Export citation
-
Higher-order networks aim at improving the classical network representation of trajectories data as memory-less order
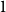 $1$
Markov models. To do so, locations are associated with different representations or “memory nodes” representing indirect dependencies between visited places as direct relations. One promising area of investigation in this context is variable-order network models as it was suggested by Xu et al. that random walk-based mining tools can be directly applied on such networks. In this paper, we focus on clustering algorithms and show that doing so leads to biases due to the number of nodes representing each location. To address them, we introduce a representation aggregation algorithm that produces smaller yet still accurate network models of the input sequences. We empirically compare the clustering found with multiple network representations of real-world mobility datasets. As our model is limited to a maximum order of
$1$
Markov models. To do so, locations are associated with different representations or “memory nodes” representing indirect dependencies between visited places as direct relations. One promising area of investigation in this context is variable-order network models as it was suggested by Xu et al. that random walk-based mining tools can be directly applied on such networks. In this paper, we focus on clustering algorithms and show that doing so leads to biases due to the number of nodes representing each location. To address them, we introduce a representation aggregation algorithm that produces smaller yet still accurate network models of the input sequences. We empirically compare the clustering found with multiple network representations of real-world mobility datasets. As our model is limited to a maximum order of
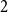 $2$
, we discuss further generalizations of our method to higher orders.
$2$
, we discuss further generalizations of our method to higher orders.