
Contents
Stochastic Geometry and Statistical Applications
A more comprehensive complementary theorem for the analysis of Poisson point processes
- Part of:
-
- Published online by Cambridge University Press:
- 01 July 2016, pp. 581-601
-
- Article
-
- You have access
- Export citation
Stationary partitions and Palm probabilities
- Part of:
-
- Published online by Cambridge University Press:
- 01 July 2016, pp. 602-620
-
- Article
-
- You have access
- Export citation
General Applied Probability
Dynamic load balancing with flexible workers
- Part of:
-
- Published online by Cambridge University Press:
- 01 July 2016, pp. 621-642
-
- Article
-
- You have access
- Export citation
Some indexable families of restless bandit problems
- Part of:
-
- Published online by Cambridge University Press:
- 01 July 2016, pp. 643-672
-
- Article
-
- You have access
- Export citation
A note on long-term optimal portfolios under drawdown constraints
- Part of:
-
- Published online by Cambridge University Press:
- 01 July 2016, pp. 673-692
-
- Article
-
- You have access
- Export citation
Normal approximation for random sums
- Part of:
-
- Published online by Cambridge University Press:
- 01 July 2016, pp. 693-728
-
- Article
-
- You have access
- Export citation
An iterative method for multiple stopping: convergence and stability
- Part of:
-
- Published online by Cambridge University Press:
- 01 July 2016, pp. 729-749
-
- Article
-
- You have access
- Export citation
On the number of segregating sites for populations with large family sizes
- Part of:
-
- Published online by Cambridge University Press:
- 01 July 2016, pp. 750-767
-
- Article
-
- You have access
- Export citation
-
We present recursions for the total number, Sn, of mutations in a sample of n individuals, when the underlying genealogical tree of the sample is modelled by a coalescent process with mutation rate r>0. The coalescent is allowed to have simultaneous multiple collisions of ancestral lineages, which corresponds to the existence of large families in the underlying population model. For the subclass of Λ-coalescent processes allowing for multiple collisions, such that the measure Λ(dx)/x is finite, we prove that Sn/(nr) converges in distribution to a limiting variable, S, characterized via an exponential integral of a certain subordinator. When the measure Λ(dx)/x2 is finite, the distribution of S coincides with the stationary distribution of an autoregressive process of order 1 and is uniquely determined via a stochastic fixed-point equation of the form
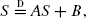 with specific independent random coefficients A and B. Examples are presented in which explicit representations for (the density of) S are available. We conjecture that Sn/E(Sn)→1 in probability if the measure Λ(dx)/x is infinite.
with specific independent random coefficients A and B. Examples are presented in which explicit representations for (the density of) S are available. We conjecture that Sn/E(Sn)→1 in probability if the measure Λ(dx)/x is infinite.
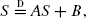 with specific independent random coefficients
with specific independent random coefficients Applications of factorization embeddings for Lévy processes
- Part of:
-
- Published online by Cambridge University Press:
- 01 July 2016, pp. 768-791
-
- Article
-
- You have access
- Export citation
On the exact asymptotics of the busy period in GI/G/1 queues
- Part of:
-
- Published online by Cambridge University Press:
- 01 July 2016, pp. 792-803
-
- Article
-
- You have access
- Export citation
Parallel matching for ranking all teams in a tournament
- Part of:
-
- Published online by Cambridge University Press:
- 01 July 2016, pp. 804-826
-
- Article
-
- You have access
- Export citation
Large deviations-based upper bounds on the expected relative length of longest common subsequences
- Part of:
-
- Published online by Cambridge University Press:
- 01 July 2016, pp. 827-852
-
- Article
-
- You have access
- Export citation
Front Matter
AAP volume 38 issue 3 Cover and Front matter
-
- Published online by Cambridge University Press:
- 01 July 2016, pp. f1-f2
-
- Article
-
- You have access
- Export citation
Back Matter
AAP volume 38 issue 3 Cover and Back matter
-
- Published online by Cambridge University Press:
- 01 July 2016, pp. b1-b2
-
- Article
-
- You have access
- Export citation