We study the community detection problem on a Gaussian mixture model, in which vertices are divided into  $k\geq 2$ distinct communities. The major difference in our model is that the intensities for Gaussian perturbations are different for different entries in the observation matrix, and we do not assume that every community has the same number of vertices. We explicitly find the necessary and sufficient conditions for the exact recovery of the maximum likelihood estimation, which can give a sharp phase transition for the exact recovery even though the Gaussian perturbations are not identically distributed; see Section 7. Applications include the community detection on hypergraphs.
$k\geq 2$ distinct communities. The major difference in our model is that the intensities for Gaussian perturbations are different for different entries in the observation matrix, and we do not assume that every community has the same number of vertices. We explicitly find the necessary and sufficient conditions for the exact recovery of the maximum likelihood estimation, which can give a sharp phase transition for the exact recovery even though the Gaussian perturbations are not identically distributed; see Section 7. Applications include the community detection on hypergraphs.
The French mathematician Bertillon reasoned that the number of dizygotic (DZ) pairs would equal twice the number of twin pairs of unlike sexes. The remaining twin pairs in a sample would presumably be monozygotic (MZ). Weinberg restated this idea and the calculation has come to be known as Weinberg's differential rule (WDR). The keystone of WDR is that DZ twin pairs should be equally likely to be of the same or the opposite sex. Although the probability of a male birth is greater than .5, the reliability of WDR's assumptions has never been conclusively verified or rejected. Let the probability for an opposite-sex (OS) twin maternity be pO, for a same-sex (SS) twin maternity pS and, consequently, the probability for other maternities 1 − pS − pO. The parameter estimates 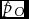 $\hat p_O$ and
$\hat p_O$ and 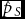 $\hat p_S$ are relative frequencies. Applying WDR, the MZ rate is m = pS − pO and the DZ rate is d = 2pO, but the estimates
$\hat p_S$ are relative frequencies. Applying WDR, the MZ rate is m = pS − pO and the DZ rate is d = 2pO, but the estimates  $\hat m$ and
$\hat m$ and  $\hat d$ are not relative frequencies. The maximum likelihood estimators
$\hat d$ are not relative frequencies. The maximum likelihood estimators 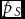 $\hat p_S$ and
$\hat p_S$ and 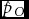 $\hat p_O$ are unbiased, efficient, and asymptotically normal. The linear transformations
$\hat p_O$ are unbiased, efficient, and asymptotically normal. The linear transformations 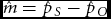 $\hat m = \hat p_S - \hat p_O$ and
$\hat m = \hat p_S - \hat p_O$ and 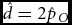 ${\skew6\hat d} = 2\hat p_O$ are efficient and asymptotically normal. If WDR holds they are also unbiased. For the tests of a set of m and d rates, contingency tables cannot be used. Alternative tests are presented and the models are applied on published data.
${\skew6\hat d} = 2\hat p_O$ are efficient and asymptotically normal. If WDR holds they are also unbiased. For the tests of a set of m and d rates, contingency tables cannot be used. Alternative tests are presented and the models are applied on published data.

