This paper studies the joint tail asymptotics of extrema of the multi-dimensional Gaussian process over random intervals defined as 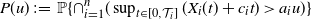 $P(u)\;:\!=\; \mathbb{P}\{\cap_{i=1}^n (\sup_{t\in[0,\mathcal{T}_i]} ( X_{i}(t) +c_i t )>a_i u )\}$
,
$P(u)\;:\!=\; \mathbb{P}\{\cap_{i=1}^n (\sup_{t\in[0,\mathcal{T}_i]} ( X_{i}(t) +c_i t )>a_i u )\}$
, 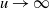 $u\rightarrow\infty$
, where
$u\rightarrow\infty$
, where 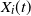 $X_i(t)$
,
$X_i(t)$
, 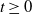 $t\ge0$
,
$t\ge0$
, 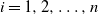 $i=1,2,\ldots,n$
, are independent centered Gaussian processes with stationary increments,
$i=1,2,\ldots,n$
, are independent centered Gaussian processes with stationary increments, 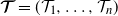 $\boldsymbol{\mathcal{T}}=(\mathcal{T}_1, \ldots, \mathcal{T}_n)$
is a regularly varying random vector with positive components, which is independent of the Gaussian processes, and
$\boldsymbol{\mathcal{T}}=(\mathcal{T}_1, \ldots, \mathcal{T}_n)$
is a regularly varying random vector with positive components, which is independent of the Gaussian processes, and 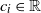 $c_i\in \mathbb{R}$
,
$c_i\in \mathbb{R}$
, 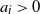 $a_i>0$
,
$a_i>0$
, 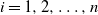 $i=1,2,\ldots,n$
. Our result shows that the structure of the asymptotics of P(u) is determined by the signs of the drifts
$i=1,2,\ldots,n$
. Our result shows that the structure of the asymptotics of P(u) is determined by the signs of the drifts 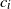 $c_i$
. We also discuss a relevant multi-dimensional regenerative model and derive the corresponding ruin probability.
$c_i$
. We also discuss a relevant multi-dimensional regenerative model and derive the corresponding ruin probability.
For a zero-mean, unit-variance stationary univariate Gaussian process we derive the probability that a record at the time n, say 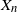 $X_n$
, takes place, and derive its distribution function. We study the joint distribution of the arrival time process of records and the distribution of the increments between records. We compute the expected number of records. We also consider two consecutive and non-consecutive records, one at time j and one at time n, and we derive the probability that the joint records
$X_n$
, takes place, and derive its distribution function. We study the joint distribution of the arrival time process of records and the distribution of the increments between records. We compute the expected number of records. We also consider two consecutive and non-consecutive records, one at time j and one at time n, and we derive the probability that the joint records 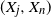 $(X_j,X_n)$
occur, as well as their distribution function. The probability that the records
$(X_j,X_n)$
occur, as well as their distribution function. The probability that the records 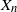 $X_n$
and
$X_n$
and 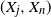 $(X_j,X_n)$
take place and the arrival time of the nth record are independent of the marginal distribution function, provided that it is continuous. These results actually hold for a strictly stationary process with Gaussian copulas.
$(X_j,X_n)$
take place and the arrival time of the nth record are independent of the marginal distribution function, provided that it is continuous. These results actually hold for a strictly stationary process with Gaussian copulas.

