
26 results
Genomics Research of Lifetime Depression in the Netherlands: The BIObanks Netherlands Internet Collaboration (BIONIC) Project
-
- Journal:
- Twin Research and Human Genetics , First View
- Published online by Cambridge University Press:
- 18 March 2024, pp. 1-11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Safe Linkage of Cohort and Population-Based Register Data in a Genomewide Association Study on Health Care Expenditure
-
- Journal:
- Twin Research and Human Genetics / Volume 24 / Issue 2 / April 2021
- Published online by Cambridge University Press:
- 02 July 2021, pp. 103-109
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Measurement and genetic architecture of lifetime depression in the Netherlands as assessed by LIDAS (Lifetime Depression Assessment Self-report)
-
- Journal:
- Psychological Medicine / Volume 51 / Issue 8 / June 2021
- Published online by Cambridge University Press:
- 27 February 2020, pp. 1345-1354
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The Nigerian Twin and Sibling Registry: An Update
-
- Journal:
- Twin Research and Human Genetics / Volume 22 / Issue 6 / December 2019
- Published online by Cambridge University Press:
- 03 December 2019, pp. 637-640
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The Netherlands Twin Register: Longitudinal Research Based on Twin and Twin-Family Designs
-
- Journal:
- Twin Research and Human Genetics / Volume 22 / Issue 6 / December 2019
- Published online by Cambridge University Press:
- 31 October 2019, pp. 623-636
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Genetic Similarity Assessment of Twin-Family Populations by Custom-Designed Genotyping Array
-
- Journal:
- Twin Research and Human Genetics / Volume 22 / Issue 4 / August 2019
- Published online by Cambridge University Press:
- 05 August 2019, pp. 210-219
-
- Article
-
- You have access
- HTML
- Export citation
Establishing a Twin Register: An Invaluable Resource for (Behavior) Genetic, Epidemiological, Biomarker, and ‘Omics’ Studies
-
- Journal:
- Twin Research and Human Genetics / Volume 21 / Issue 3 / June 2018
- Published online by Cambridge University Press:
- 10 May 2018, pp. 239-252
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Interaction between the FTO gene, body mass index and depression: meta-analysis of 13701 individuals
-
- Journal:
- The British Journal of Psychiatry / Volume 211 / Issue 2 / August 2017
- Published online by Cambridge University Press:
- 02 January 2018, pp. 70-76
- Print publication:
- August 2017
-
- Article
-
- You have access
- HTML
- Export citation
Genome-Wide Significance for PCLO as a Gene for Major Depressive Disorder
-
- Journal:
- Twin Research and Human Genetics / Volume 20 / Issue 4 / August 2017
- Published online by Cambridge University Press:
- 25 May 2017, pp. 267-270
-
- Article
-
- You have access
- HTML
- Export citation
Personality Polygenes, Positive Affect, and Life Satisfaction
-
- Journal:
- Twin Research and Human Genetics / Volume 19 / Issue 5 / October 2016
- Published online by Cambridge University Press:
- 22 August 2016, pp. 407-417
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A Genomewide Association Study of Nicotine and Alcohol Dependence in Australian and Dutch Populations
-
- Journal:
- Twin Research and Human Genetics / Volume 13 / Issue 1 / February 2010
- Published online by Cambridge University Press:
- 21 January 2016, pp. 11-29
-
- Article
-
- You have access
- Export citation
CNV Concordance in 1,097 MZ Twin Pairs
-
- Journal:
- Twin Research and Human Genetics / Volume 18 / Issue 1 / February 2015
- Published online by Cambridge University Press:
- 12 January 2015, pp. 1-12
-
- Article
-
- You have access
- HTML
- Export citation
The Young Netherlands Twin Register (YNTR): Longitudinal Twin and Family Studies in Over 70,000 Children
-
- Journal:
- Twin Research and Human Genetics / Volume 16 / Issue 1 / February 2013
- Published online by Cambridge University Press:
- 28 November 2012, pp. 252-267
-
- Article
-
- You have access
- HTML
- Export citation
Twins, Tissue, and Time: An Assessment of SNPs and CNVs
-
- Journal:
- Twin Research and Human Genetics / Volume 15 / Issue 6 / December 2012
- Published online by Cambridge University Press:
- 28 September 2012, pp. 737-745
-
- Article
-
- You have access
- HTML
- Export citation
Genome-Wide Linkage Scan for Athlete Status in 700 British Female DZ Twin Pairs
-
- Journal:
- Twin Research and Human Genetics / Volume 10 / Issue 6 / 01 December 2007
- Published online by Cambridge University Press:
- 21 February 2012, pp. 812-820
-
- Article
-
- You have access
- Export citation
-
Association studies, comparing elite athletes with sedentary controls, have reported a number of genes that may be related to athlete status. The present study reports the first genome wide linkage scan for athlete status. Subjects were 4488 adult female twins from the TwinsUK Adult Twin Registry (793 monozygotic [MZ] and 1000 dizygotic [DZ] complete twin pairs, and single twins). Athlete status was measured by asking the twins whether they had ever competed in sports and what was the highest level obtained. Twins who had competed at the county or national level were considered elite athletes. Using structural equation modeling in Mx, the heritability of athlete status was estimated at 66%. Seven hundred DZ twin pairs that were successfully genotyped for 1946 markers (736 microsatellites and 1210 SNPs) were included in the linkage analysis. Identical-by-descent probabilities were estimated in Merlin for a 1 cM grid, taking into account the linkage disequilibrium of correlated SNPs. The linkage scan was carried out in Mx using the
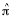 -approach. Suggestive linkages were found on chromosomes 3q22-q24 and 4q31-q34. Both areas converge with findings from previous studies using exercise phenotypes. The peak on 3q22-q24 was found at the SLC9A9 gene. The region 4q31-q34 overlaps with the region for which suggestive linkages were found in two previous linkage studies for physical fitness (FABP2 gene; Bouchard et al., 2000) and physical activity (UCP1 gene; Simonen et al., 2003). Future association studies should further clarify the possible role of these genes in athlete status.
-approach. Suggestive linkages were found on chromosomes 3q22-q24 and 4q31-q34. Both areas converge with findings from previous studies using exercise phenotypes. The peak on 3q22-q24 was found at the SLC9A9 gene. The region 4q31-q34 overlaps with the region for which suggestive linkages were found in two previous linkage studies for physical fitness (FABP2 gene; Bouchard et al., 2000) and physical activity (UCP1 gene; Simonen et al., 2003). Future association studies should further clarify the possible role of these genes in athlete status.
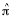 -approach. Suggestive linkages were found on chromosomes 3q22-q24 and 4q31-q34. Both areas converge with findings from previous studies using exercise phenotypes. The peak on 3q22-q24 was found at the SLC9A9 gene. The region 4q31-q34 overlaps with the region for which suggestive linkages were found in two previous linkage studies for physical fitness (FABP2 gene; Bouchard et al., 2000) and physical activity (UCP1 gene; Simonen et al., 2003). Future association studies should further clarify the possible role of these genes in athlete status.
-approach. Suggestive linkages were found on chromosomes 3q22-q24 and 4q31-q34. Both areas converge with findings from previous studies using exercise phenotypes. The peak on 3q22-q24 was found at the SLC9A9 gene. The region 4q31-q34 overlaps with the region for which suggestive linkages were found in two previous linkage studies for physical fitness (FABP2 gene; Bouchard et al., 2000) and physical activity (UCP1 gene; Simonen et al., 2003). Future association studies should further clarify the possible role of these genes in athlete status.Heritability and Stability of Resting Blood Pressure in Australian Twins
-
- Journal:
- Twin Research and Human Genetics / Volume 9 / Issue 2 / 01 April 2006
- Published online by Cambridge University Press:
- 21 February 2012, pp. 205-209
-
- Article
-
- You have access
- Export citation
Netherlands Twin Register: From Twins to Twin Families
-
- Journal:
- Twin Research and Human Genetics / Volume 9 / Issue 6 / 01 December 2006
- Published online by Cambridge University Press:
- 21 February 2012, pp. 849-857
-
- Article
-
- You have access
- Export citation
Associations Between ADH Gene Variants and Alcohol Phenotypes in Dutch Adults
-
- Journal:
- Twin Research and Human Genetics / Volume 13 / Issue 1 / February 2010
- Published online by Cambridge University Press:
- 21 February 2012, pp. 30-42
-
- Article
-
- You have access
- Export citation
Design and Implementation of a Twin-Family Database for Behavior Genetics and Genomics Studies
-
- Journal:
- Twin Research and Human Genetics / Volume 11 / Issue 3 / 01 June 2008
- Published online by Cambridge University Press:
- 21 February 2012, pp. 342-348
-
- Article
-
- You have access
- Export citation
The Netherlands Twin Register Biobank: A Resource for Genetic Epidemiological Studies
-
- Journal:
- Twin Research and Human Genetics / Volume 13 / Issue 3 / 01 June 2010
- Published online by Cambridge University Press:
- 21 February 2012, pp. 231-245
-
- Article
-
- You have access
- Export citation
