


For more than three decades, the Netherlands Twin Register (NTR) has invited twins and their family members to take part in research studies of development, health and behavior. The recruitment has mostly included two-generation extended families. The NTR has created a rich resource of data to assess genetic and nongenetic (cultural) transmission, and to contribute to gene-finding studies for complex human phenotypes. In this article we describe, by necessity in broad strokes, our recruitment procedures, the number of participants, the phenotyping through surveys and other data collection methods, and the collection of genotype and other omics data. We also summarize how we are constructing a data warehouse to archive the numerous datasets and make them optimally accessible for researchers, even when data were collected two or more decades ago.
This paper is incremental in a series of earlier papers on NTR resources (Bartels et al., Reference Bartels, van Beijsterveldt, Derks, Stroet, Polderman, Hudziak and Boomsma2007; Boomsma et al., Reference Boomsma, Orlebeke and Van Baal1992, Reference Boomsma, Vink, Van Beijsterveldt, de Geus, Beem, Mulder and Bartels2002, 2006, Reference Boomsma, Willemsen, Vink, Bartels, Groot, Hottenga and Wertheim2008; Hoekstra et al., Reference Hoekstra, Meijer, Kluft, Heutink, Smit, de Geus and Boomsma2004; van Beijsterveldt et al., Reference van Beijsterveldt, Groen-Blokhuis, Hottenga, Franić, Hudziak, Lamb and Schutte2013; Willemsen et al., Reference Willemsen, De Geus, Bartels, van Beijsterveldt, Brooks, Estourgie-van Burk and Kluft2010, Reference Willemsen, Vink, Abdellaoui, den Braber, van Beek, Draisma and van Lien2013), and aims to give an overview from the first twin-family studies in the 1980s, via the formal establishment of the Young and Adult NTR and the NTR biobank to our latest projects. Participants who register with NTR are invited for research projects entailing surveys, interviews and other phenotyping studies, biomarker and omics research projects, and are also asked for permission for record linkage. Since the first twin-family studies were carried out for cardiovascular risk factors in the early 1980s on several hundreds of participants, data have been collected on tens of thousands of children and adults, and across a wide range of phenotypes.
Recruitment
Starting around 1986, NTR systematically started to approach parents to register their newborn twins in the Young NTR (YNTR) with the help of a commercial ‘birth felicitation’ service. Additional recruitment of newborn twins and triplets and their parents is done with the support of the Dutch Society of Parents of Multiples (Nederlandse Vereniging van Ouders van Meerlingen: NVOM; https://www.nvom.nl). After parents return an informed consent form, the family is registered with the NTR and mothers receive a first survey with items on pre- and perinatal variables. When the twins are 2 years of age, a survey on growth, health, developmental and motor milestones is sent. At ages 3, 5, 7, 9/10 and 12 years, both parents receive additional surveys addressing a broader set of behavioral and health-related traits. At ages 7, 9/10 and 12 years, we also ask parents for permission to approach the twins’ teachers. At that same moment, we ask if there are any additional siblings in the family who are in elementary school and whose teachers may be approached. From age 14 onward, adolescent twins and their siblings are invited to provide self-reports (after their parents give permission), largely substituting parental for self-report form this age onward. Once they become adults, the YNTR twins can opt to join the Adult NTR (ANTR).
Apart from the YNTR influx, ANTR twins have been recruited through city councils, starting in 1985 with smaller numbers of twin families in and around Amsterdam. In 1990–1993, a nationwide appeal to city councils for permission to approach adolescent and young adult twins and multiples and their parents was successful and created the basis for the ANTR, with the first surveys collected in 1991. Additional means of recruitment are the yearly NTR newsletter Twinfo, the NTR website and national events organized by, for example, the Dutch Twin Society. Surveys have been sent to ANTR participants about every 2–3 years since 1991. In total, 13 large-scale surveys have been collected. In contrast to the YNTR, where data collection is based on birth cohort and age, the ANTR data collection is independent of age and includes all adult participants.
As a result of the recruitment efforts described above, the NTR has registered about 52% of all Dutch twin-pairs born between 1987 and 2017, based on data from Statistics Netherlands (CBS; https://www.cbs.nl/nl-nl/nieuws/2016/39/minder-tweelingen-geboren). Most of these twin-pairs were recruited shortly after birth. The birth cohorts between 1970 and 1981 are also well represented (29%). For other birth cohorts, coverage is considerably lower due to lack of systematic recruitment.
Number of Participants
Using the twin-pair as the probands, recruitment in both ANTR and YTNR initially included parents, and in later years also siblings, spouses and offspring of twins. This has resulted in a database with roughly equal proportions of participants who are and who are not twins. Over the years, a total of 280,569 participants were registered at the NTR, 231,088 of whom are still contactable. The total group of participants includes 255,785 members of twin families and 24,784 participants contributing as a teacher of a child registered at the NTR. Table 1 provides information about the age distribution in twins, parents, siblings and other groups of participants. Until now, the NTR has collected phenotypic data on 70% of all registered twin-family participants (i.e., excluding teachers). This includes self-report data, survey data supplied by parents or teachers, and data collected in dedicated projects such as cardiovascular and magnetic resonance imaging (MRI) studies.
Table 1. Number of registered participants as of 2019 by role and age group
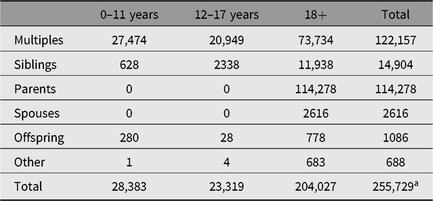
a Due to unknown age, 56 participants are not listed in this table.
Zygosity
Most NTR surveys contain a standard series of items for zygosity assessment, addressing several aspects of physical resemblance and the degree to which the twins are confused by parents, other relatives and strangers. In YNTR and ANTR data, a series of discriminant analyses was performed to assess the accuracy of zygosity classification based on survey items, using information from blood group and DNA polymorphisms as the index of true zygosity. In the YNTR, the accuracy of classification at age 3 years and older was 97.2%, based on a set of 10 questionnaire items. In the ANTR, where a set of eight items is used, the correspondence was 95.9%. For more details on the zygosity classification, see the Appendix. Table 2 shows the numbers of monozygotic (MZ) and dizygotic (DZ) twins within the NTR, stratified by age and sex.
Table 2. Number of MZ and DZ twins by sex and age group
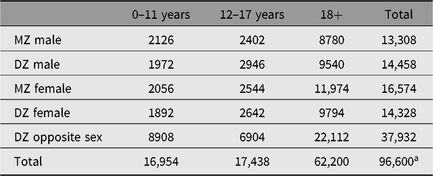
a Numbers represent individuals, not pairs, and only include twins, not higher order multiples. Zygosity is not known for all registered twins; however, in the case of an opposite sex pair, no survey or DNA information is needed to determine zygosity. Therefore, this group is relatively large compared to the other zygosity groups.
YNTR and ANTR: Longitudinal Survey Collection
Tables 3 and 4 summarize the numbers of twins and family members who have participated in YNTR and ANTR survey research as of April 2019. Separate columns indicate for how many participants the phenotypic data from the surveys were enriched by DNA collection and genomewide single nucleotide polymorphism (SNP) genotyping.
Table 3. Numbers of available surveys per type of rater for young multiples and siblings (YNTR)
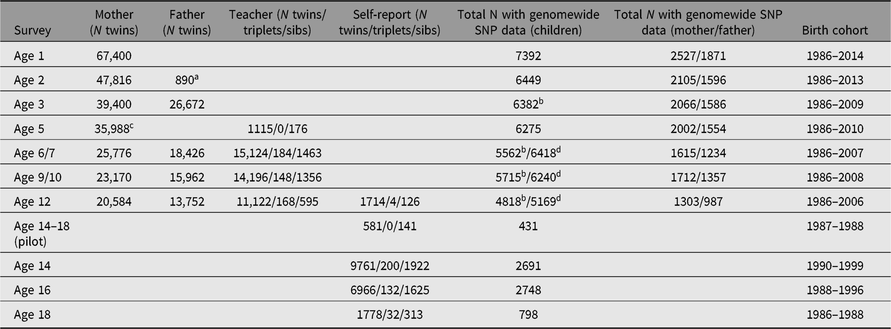
YNTR = Young Netherlands Twin Register.
a Data collection in fathers started in 2016.
b Mother or father report.
c Survey includes a father report.
d Mother or father or teacher report.
Table 4. Numbers of completed surveys for adult participants (multiples, siblings, parents, spouses and offspring)
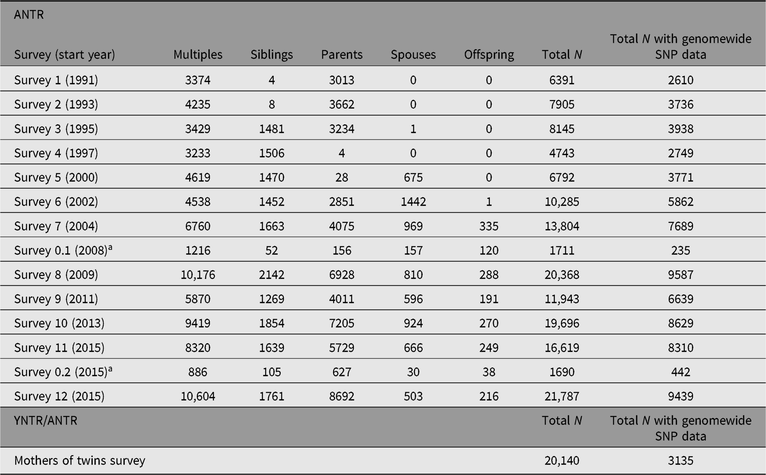
ANTR = Adult Netherlands Twin Register.
a The surveys numbered 0.x run over longer periods and are sent to new ANTR participants; survey 0.2 is currently ongoing.
Longitudinal data collection by surveys began by paper and pencil and has now been replaced by online survey collection. The YNTR surveys focus on growth and physical development, wellbeing, health status and health behaviors, and behavioral and emotional problems as rated by parents and at ages 7, 9/10 and 12 years by teachers. Over time, surveys have been kept as similar as possible, relying on standardized inventories such as the Achenbach System of Empirically Based Assessment (ASEBA; Achenbach et al., Reference Achenbach, Ivanova and Rescorla2017) which allows for multi-informant assessment at ages 1½ through 90+ years (i.e., parents, teacher and self-assessment), and the Conners’ Teacher Rating Scales-Revised for teachers (Conners et al., Reference Conners, Sitarenios, Parker and Epstein1998b), the Conners’ Parent Rating Scale-Revised (Conners et al., Reference Conners, Sitarenios, Parker and Epstein1998a) for parents of young twins and the Conners’ Adult ADHD Rating Scales for adults (Conners et al., Reference Conners, Erhardt, Epstein, Parker, Sitarenios and Sparrow1999). New instruments have been added in recent years, e.g. the Child Behavior Questionnaire (CBQ; Rothbart et al., Reference Rothbart, Ahadi, Hershey and Fisher2001), for assessment of behavioral control at age 5 by parents, and the Social Skills Rating System (SSRS; Gresham & Elliott, Reference Gresham and Elliott1990) for assessment of social competence at ages 7, 9 and 12 by teachers and wellbeing (Cantril Ladder; Cantril, Reference Cantril1965). Other topics addressed in the YNTR surveys include the use of assisted reproduction techniques in the first survey, motor milestones at age 2 years, and academic performance and sharing the same school and/or classroom at ages 7 through 12 years.
ANTR surveys have focused on demographics, health and health behaviors, personality and wellbeing, as well as a broad range of behavioral and emotional problems as assessed by ASEBA, Beck Depression Inventory, Personality Assessment Inventory — Borderline (PAI-BOR) scale, NEO Five-Factor Inventory and other instruments (Achenbach et al., Reference Achenbach, Ivanova and Rescorla2017; Bouman et al., Reference Bouman, Luteijn, Albersnagel and Van der Ploeg1985; Costa & McCrae, Reference Costa and McCrae1989; Morey, Reference Morey2003). ANTR survey studies all address the general theme of individual differences of mental and physical health but often have a specific focus, for example, survey 9 was focused on pain, survey 11 mainly included a large food preference assessment and survey 12 was developed for online phenotyping of major depressive disorder (BIONIC; Bot et al., Reference Bot, Middeldorp, De Geus, Lau, Sinke, Van Nieuwenhuizen and Penninx2017). At the same time, we try to maintain continuity for topics such as substance use, sports and exercise behavior, personality and wellbeing, in order to facilitate longitudinal comparisons. Tables 5 and 6 show the longitudinal survey participation in YNTR and ANTR: the number of participations of any single individual across studies. Please note that these tables are snapshots of the current numbers, as data collection and data entry are ongoing processes. A distinction is made between self-reports (YNTR and ANTR) and parent and teacher reports (YNTR only).
Table 5. Number of children with longitudinal parent and teacher reports (YNTR)

YNTR = Young Netherlands Twin Register.
Table 6. Number of participants with longitudinal self-reports (YNTR and ANTR)
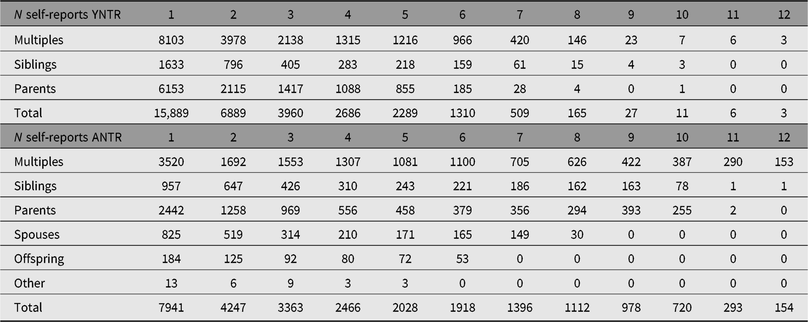
YNTR = Young Netherlands Twin Register; ANTR = Adult Netherlands Twin Register.
Note: The top part of the table, (‘YNTR’) includes self-reports from YNTR twins and siblings at ages 14, 16 and 18 years, as well as self-reports by these participants after they enrolled in the ANTR as adults. In the bottom part of the table, (‘ANTR’) are the participants who registered as adolescents between 1991 and 1995, and adults.
Triplets are a unique group of multiples within the NTR. The NTR has registered a total of 871 complete sets of triplets. ANTR triplets complete the regular surveys sent to all NTR participants. In the YNTR, dedicated triplet surveys are used, which follow the line of the twin data collection.
Nonsurvey-Based Phenotyping
In addition to participating in the longitudinal surveys, subgroups of twins and their family members are invited to take part in dedicated studies of, for example, autonomic nervous system functioning and cardiovascular risk, brain structure and function, neurocognitive test performance and IQ, or (an)aerobic fitness and daily physical activity. A second approach to phenotyping has been to conduct large-scale telephone interviews. These included monthly interviews on motor development and psychopathology with mothers about their young twins (Langendonk et al., Reference Langendonk, Van Beijsterveldt, Brouwer, Stroet, Hudziak and Boomsma2007) and interviews to assess clinical diagnoses of ADHD (Derks et al., Reference Derks, Hudziak, Dolan, van Beijsterveldt, Verhulst and Boomsma2008). In ANTR participants, a series of Composite International Diagnostic Interviews (Wittchen, Reference Wittchen1994) were conducted to obtain DSM-IV diagnoses of mental disorders, including major depressive disorder (Middeldorp et al., Reference Middeldorp, Birley, Cath, Gillespie, Willemsen, Statham and Beem2005).
A subset of these studies is presented in Table 7. The table indicates the type of data collected per study, categorized into broad domains and a primary reference for each study. The same study domains are listed in Table 8, where the overlap with other data collections is shown. Selection for participation in nonsurvey studies may be random, but can also be based on survey data, demographic information, or the availability of, for example, omics data. Examples are studies that included twins from specific age or birth cohorts (Bartels et al., Reference Bartels, Rietveld, Van Baal and Boomsma2002b; Hoekstra et al., Reference Hoekstra, Bartels and Boomsma2007; Polderman, Posthuma et al., Reference Polderman, Posthuma, De Sonneville, Verhulst and Boomsma2006; Rietveld et al., Reference Rietveld, Dolan, Van Baal and Boomsma2003; van Baal et al., Reference van Baal, de Geus and Boomsma1998), twins with an older sibling (van Leeuwen et al., Reference van Leeuwen, van den Berg, Peper, Pol and Boomsma2009; van Soelen et al., Reference van Soelen, Brouwer, Peper, van Beijsterveldt, van Leeuwen, de Vries and Boomsma2010) or twin-pairs concordant or discordant for a specific phenotype, such as anaesthesia (Bartels et al., Reference Bartels, Althoff and Boomsma2009), attention problems (Derks et al., Reference Derks, Hudziak, Dolan, van Beijsterveldt, Verhulst and Boomsma2008; Polderman, Posthuma et al., Reference Polderman, Posthuma, De Sonneville, Verhulst and Boomsma2006; van‘t Ent et al., Reference van‘t Ent, Lehn, Derks, Hudziak, Van Strien, Veltman and Boomsma2007), depression (de Geus et al., Reference de Geus, van’t Ent, Wolfensberger, Heutink, Hoogendijk, Boomsma and Veltman2007), obsessive-compulsive symptoms (den Braber et al., Reference den Braber, van’t Ent, Blokland, van Grootheest, Cath, Veltman and Boomsma2008) and body mass index (Doornweerd et al., Reference Doornweerd, IJzerman, van der Eijk, Neter, van Dongen, van der Ploeg and de Geus2016).
Table 7. Overview of nonsurvey projects
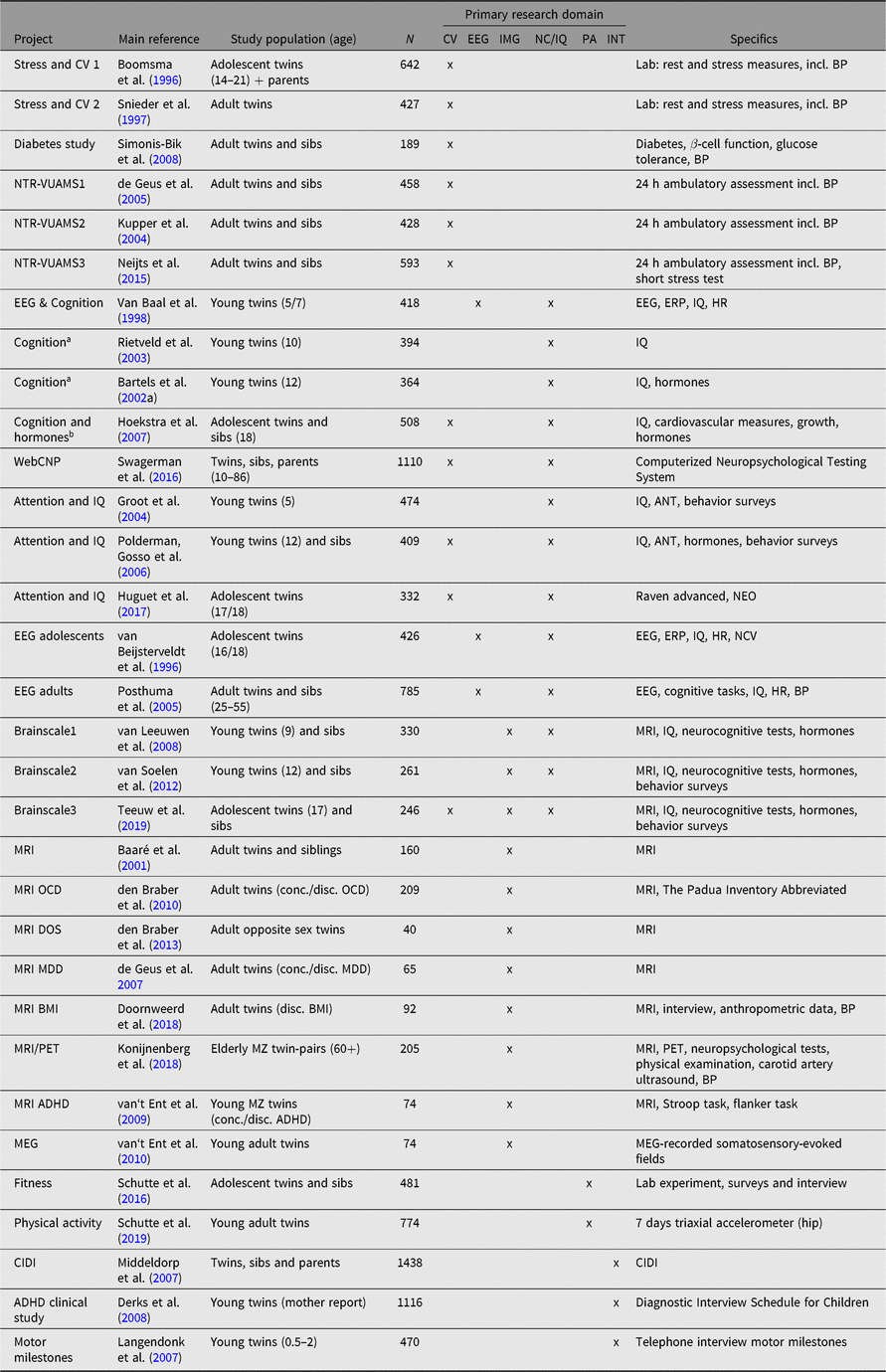
CV = cardiovascular/(ambulatory) autonomic nervous system; EEG = EEG/ERP; IMG = imaging; NC/IQ = neurocognitive testing/IQ; PA = fitness/physical exercise; INT = interview; BP = blood pressure; HR = heart rate; ANT = Amsterdam Neuropsychological Tasks; NCV = nerve conduction velocity; conc. = concordant; disc. = discordant; OCD = obsessive-compulsive disorder; MDD = major depressive disorder; BMI = body mass index; CIDI = composite international diagnostic interview; NTR-VUAMS = NTR Vrije Universiteit Ambulatory Monitoring System; ERP = Event related potential; WebCNP = The (web-based) University of Pennsylvania Computerized Neuropsychological Test Battery; MRI = magnetic resonance imaging; DOS = dizygotic opposite sex twins; PET = Positron emission tomography; ADHD = Attention deficit hyperactivity disorder; MEG = Magnetoencephalography.
a EEG & Cognition sample.
b EEG & Cognition sample plus additional participants.
Table 8. Sample sizes biological and nonsurvey data, and overlap with surveys

YNTR = Young Netherlands Twin Register; ANTR = Adult Netherlands Twin Register; LPS = Lipopolysaccharide; HDL = high-density lipoprotein; LDL = low-density lipoprotein; ANS = autonomic nervous system; EEG = electroencephalography; MRI = magnetic resonance imaging; MEG = Magnetoencephalography; PET = Positron emission tomography; IQ = Intelligence Quotient.
a Count includes children whose parents and teachers reported about them as well as parents reporting about themselves and each other.
b Limited selection; not all measured biomarkers are listed.
c See also Table 7.
The academic achievement tests administered by Dutch schools are another important resource for phenotype information. Data are obtained from a standardized test administered in Grade 6, and the Pupil Monitoring System (PMS; Grades 1–6). In addition, the regular surveys to parents and teachers during the elementary school years include items on children’s school grades (van Bergen et al., Reference van Bergen, Snowling, de Zeeuw, van Beijsterveldt, Dolan and Boomsma2018). NTR started to collect information on standardized educational achievement tests in 2000 (Bartels et al., Reference Bartels, Rietveld, Van Baal and Boomsma2002b). The test is administered nationwide over a period of 3 days in the last grade of elementary school at ~12 year (Eindtoets Basisonderwijs 2002; www.cito.nl). Initially, these scores were obtained from teachers. Because results become available near the very end of the school year, we later asked parents and twins to report these scores. The correlation between scores provided by parents and twins is 0.96 (N = 3314) and between teachers and twins the correlation is 0.93 (N = 922).
In 2008, the NTR started to collect PMS data, providing information on academic achievement throughout elementary school. Since 2014/2015, all elementary schools are required to use a PMS. The PMS consists of grade appropriate tests, independent of teaching methods, which are administered at fixed time points (i.e., beginning, halfway and/or end of the school year) in each grade. The PMS has tests on all important educational domains, for example, reading, mathematics and spelling (de Zeeuw et al., Reference de Zeeuw, van Beijsterveldt, Glasner, de Geus and Boomsma2016). Currently, around one-third of the teachers who fill out a survey also send us a student report with the results from the PMS tests of the current and previous grades.
Twinning
A phenotype of special interest for which nearly every NTR participant is informative is the trait ‘being a twin’ or ‘being a parent of twins’. Among the earliest NTR projects was a study on the inheritance of twinning. In the early 1990s, telephone interviews were held with the mothers of DZ twins (Meulemans et al., Reference Meulemans, Lewis, Boomsma, Derom, Van den Berghe, Orlebeke and Derom1996) to collect information on twinning in their extended pedigree for segregation analyses, and to assess zygosity in the proband twins and any additional twins in the pedigree. These pedigree data formed the basis for several blood collection projects in ‘twinning pedigrees’, initially with the purpose of linkage studies in sister-pairs (Painter et al., Reference Painter, Willemsen, Nyholt, Hoekstra, Duffy, Henders and Skolnick2010) and later for genomewide association studies (Mbarek et al., Reference Mbarek, Steinberg, Nyholt, Gordon, Miller, McRae and De Geus2016). A large survey study collected information on risk factors for twinning in both mothers from the YNTR/ANTR and the ANTR (Hoekstra et al., Reference Hoekstra, Willemsen, van Beijsterveldt, Lambalk, Montgomery and Boomsma2008, Reference Hoekstra, Willemsen, van Beijsterveldt, Montgomery and Boomsma2010). Table 9 describes the characteristics of the pedigrees within NTR, including special groups of participants relevant to twinning research, such as families with more than one twin-pair.
Table 9. The NTR Pedigree as of April 2019
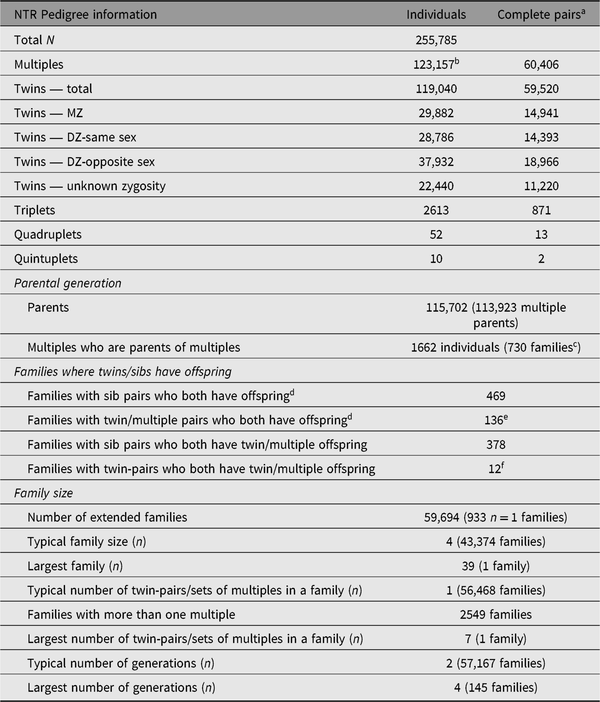
NTR = Netherlands Twin Register.
a A pair indicates a complete set of multiples, that is, two twins, three triplets, four quadruplets or five quintuplets.
b Number includes 1442 multiples who are registered without a co-twin. These are often individuals who registered because they are a parent or spouse of a twin. They are not included in counts of twins, triplets, and so on.
c Families where both parent and offspring are multiples, and the parent’s co-twin is also registered.
d This includes multiple offspring as well as singleton offspring.
e Number includes 21 families in which one or more siblings and both members of a twin-pair all have offspring.
f Number includes two families in which one or more siblings and both members of a twin-pair all have twin/multiple offspring.
Record Linkage/Cross-Referencing the NTR Database to Other National Databases
Starting with ANTR survey 6, participants were asked for permission for record linkage with other databases in the Netherlands. Across surveys, on average 81% of participants agreed with record linkage, 14% did not agree and 5% did not answer the question. Subjects who did not agree or did not answer the question are excluded from record linkage.
Projects that have made use of record linkage include a large study of chorionicity (van Beijsterveldt et al., Reference van Beijsterveldt, Overbeek, Rozendaal, McMaster, Glasner, Bartels and Boomsma2016). Information on chorionicity through record linkage as well as access to tissue samples was available from in the Pathological Anatomy National Automatic Archive (PALGA), a nationwide network and register of histopathology and cytopathology database and biobank. Other projects that made use of the PALGA database include studies on triplets and a study of cervix smear abnormalities (Lamb et al., Reference Lamb, Vink, Middeldorp, van Beijsterveldt, Haak, Overbeek and Boomsma2012; van Beijsterveldt et al., Reference van Beijsterveldt, Overbeek, Rozendaal, McMaster, Glasner, Bartels and Boomsma2016; Vink et al., Reference Vink, Van Kemenade, Meijer, Casparie, Meijer and Boomsma2011). Valuable information can also be obtained by linking the NTR databases to national population-based registers such as the cancer registration in the Netherlands. A facility has been created in collaboration with Statistics Netherlands (https://www.cbs.nl/en-gb), to combine data from multiple databases for analysis. This ‘ODISSEI Data Facility (ODF)’ (www.odissei-data.nl) enables, for example, the analysis of NTR genotype information with phenotype information from Statistics Netherlands.
Harmonization and Data Repository
Given the large amount of data collected over the last decades, and the diversity in research topics and data collections that have evolved over the years, the need arose for the NTR to harmonize the data collected across multiple projects and to bring all these resources together. This should ensure that the large amount of data collected since the beginning of the NTR becomes accessible under Findable, Accessible, Interoperable, Reusable (FAIR) data stewardship principles and can be optimally used in research on behavior and health. For this purpose, we are building a new data repository for the phenotype data, as well as an online data showcase, in collaboration with IT company The Hyve (https://thehyve.nl/).
NTR Data Showcase
The NTR Data Showcase was designed to facilitate data requests from NTR and affiliated researchers, by allowing them to see what data are available in the NTR. The NTR Data Showcase does not contain the actual research data, only metadata. Users can search items by keyword, project or research domain. The research domains are based on the domain structure as used by Maelstrom Research (https://www.maelstrom-research.org), supplemented with NTR-specific subdomains (e.g., twin-specific variables such as zygosity) where necessary. Researchers can view properties of the available variables, including the item name, keywords, a brief description of the measure, the original phrasing of survey questions in Dutch and English, the data type (string/numeric/categorical), labels and subject counts. Once a set of variables is identified, the items can be collected in a ‘shopping cart’ and exported to a.JSON (JavaScript Object Notation) file, to become part of a data request.
NTR Data Repository
The phenotypic research data are stored in a TranSMART data warehouse (https://transmartfoundation.org/), which can be accessed by the NTR data managers using the Glowing Bear application (https://glowingbear.app/). All data for a participant, which may have been collected in many separate research projects, are stored under the same numeric person ID. TranSMART also implements the use of ‘concepts’: if the same variable was collected in many different projects (e.g., a certain personality questionnaire that was included in many different projects), and was measured and coded in the same way across all projects, these variables can be linked to a single concept, after which all of them can be extracted at once with a simple query. Once a researcher has applied for a dataset and the request has been approved by the NTR data access committee, a JSON file exported from the NTR Data Showcase can be uploaded in the Glowing Bear application by a data manager to extract the requested dataset. In addition to importing these JSON files, which contain the variable selection, cohort selections can be specified by the data managers, based on, for example, participation in a particular research project, person characteristics (e.g., age or sex), availability of genotype data or family relationships (e.g., ‘all individuals who are a mother of twins’). The queries used to extract a specific dataset can be stored and reused in case an update of the dataset is necessary.
Contact information of all participants is stored in the Person Administration of the Netherlands Twin Register (PANTER) database (Boomsma et al., Reference Boomsma, Willemsen, Vink, Bartels, Groot, Hottenga and Wertheim2008). This person-oriented database stores contact details and family relationships between persons (Boomsma et al., Reference Boomsma, Helmer, Nieuwboer, Hottenga, de Moor, van Den Berg and Dolan2018) in a secure environment that is not connected to the internet. In the PANTER database, participants are stored under an administrative ID which is different from the IDs used for research data (e.g., phenotype and omics data), so that personal and research data remain separated.
NTR Biomarker and Omics Projects
The first two large-scale NTR studies (N = 936) on cardiovascular risk factors in twin families included assessment of biomarkers such as lipid levels, plant sterols, Lp(a) glucose and other biomarkers (Kempen et al., Reference Kempen, De Knijff, Boomsma, Van Der Voort, Leuven and Havekes1991; Snieder et al., Reference Snieder, Van Doornen and Boomsma1997). Of note, 20 years later nearly half of the participants in the early 90s projects (N = 510) also took part in the NTR biobank studies as described below, creating possibilities for longitudinal biomarker studies. In 2004, the NTR started a large biological sample collection in nearly 10,000 participants to create a resource for future omics and biomarker studies as well as the creation of immortalized cell lines: the NTR biobank (Willemsen et al., Reference Willemsen, De Geus, Bartels, van Beijsterveldt, Brooks, Estourgie-van Burk and Kluft2010). We first carried out a large pilot project (Hoekstra et al., Reference Hoekstra, Meijer, Kluft, Heutink, Smit, de Geus and Boomsma2004) in which we established the feasibility of, for example, drawing blood from fertile women on day 2–4 of the menstrual cycle, or in their pill-free week. Between 2004 and 2008, a group of adult participants from NTR research projects was invited for the NTR biobank study, of which 69% participated. A comparison of nonparticipants with participants showed that nonparticipants were less often female (52% vs. 64%), were slightly younger (average birth year 1963 vs. 1960 in men, 1964 vs. 1962 in the women) and had less often received higher education (27% vs. 39% in men, 22% vs. 33% in women). During a morning home visit, eight tubes of fasting blood and a morning urine sample were collected along with phenotypic information on health, medication use, body composition and smoking. A second project between 2008 and 2010 added collection of stool samples in mainly MZ twin-pairs (Sirota et al., Reference Sirota, Willemsen, Sundar, Pitts, Potluri, Prifti and Boomsma2015). In both projects, extensive cell counts were realized in fresh blood samples (Lin et al., Reference Lin, Carnero-Montoro, Bell, Boomsma, de Geus, Jansen and Hottenga2017). These data on cell counts serve as important covariates in transcriptomics (e.g., Jansen et al., Reference Jansen, Batista, Brooks, Tischfield, Willemsen, Van Grootheest and Madar2014) and epigenomics studies (van Dongen et al., Reference van Dongen, Nivard, Willemsen, Hottenga, Helmer, Dolan and Boomsma2016). Biomarkers assessed for all NTR biobank participants include lipids, glucose, insulin, HbA1c, liver enzymes (van Beek et al., Reference van Beek, Lubke, de Moor, Willemsen, de Geus, Hottenga and Boomsma2015), C-reactive protein, fibrinogen, interleukin (IL)-6, TNF-α and soluble IL-6 receptor (van Dongen et al., Reference van Dongen, Willemsen, Heijmans, Neuteboom, Kluft, Jansen and Boomsma2015). Other biomarkers collected in (large) subsets of samples include cotinine in blood (Bot et al., Reference Bot, Vink, Willemsen, Smit, Neuteboom, Kluft and Penninx2013), telomere length (Broer et al., Reference Broer, Codd, Nyholt, Deelen, Mangino, Willemsen and De Geus2013) and microbiome datasets (Finnicum et al., Reference Finnicum, Doornweerd, Dolan, Luningham, Beck, Willemsen and Davies2018).
DNA collection constituted an important element of the biobanking project, continuing the effort in many earlier NTR studies that also collected DNA samples from twin families, for instance, as part of linkage studies into depression and anxiety (Boomsma et al., Reference Boomsma, Beem, Van den Berg, Dolan, Koopmans, Vink and Slagboom2000), asthma (Wu et al., Reference Wu, Boezen, Postma, Los, Postmus, Snieder and Boomsma2010) and twinning pedigrees (Painter et al., Reference Painter, Willemsen, Nyholt, Hoekstra, Duffy, Henders and Skolnick2010), or as part of the nonsurvey projects listed in Table 7. DNA collection continues for participants who provided phenotype information, for example, as part of a large transatlantic collaboration with the Avera Institute of Human Genetics (Ehli et al., Reference Ehli, Abdellaoui, Fedko, Grieser, Nohzadeh-Malakshah, Willemsen and Hottenga2017). DNA has been collected from whole blood for the majority of the ANTR subjects and by buccal swabs in the majority of YNTR families. Our buccal swab procedures yield high-quality DNA amenable to multiple omics arrays (Meulenbelt et al., Reference Meulenbelt, Droog, Trommelen, Boomsma and Slagboom1995; Min et al., Reference Min, Lakenberg, Bakker-Verweij, Suchiman, Boomsma, Slagboom and Meulenbelt2006). For twins, we aim to always collect buccal DNA, often in addition to DNA from whole blood.
In the DNA and RNA resources in the NTR biobank, substantial progress was made in assessing epigenetic, transcriptomics and metabolomics data. Epigenetic and RNA expression data have been measured in MZ and DZ twin-pairs (van Dongen et al., Reference van Dongen, Nivard, Willemsen, Hottenga, Helmer, Dolan and Boomsma2016; Wright et al., Reference Wright, Sullivan, Brooks, Zou, Sun, Xia and Boomsma2014). Analyses of these data, making use of the classical twin design, showed significant heritability for both the transcriptome and the epigenome. Figure 1 summarizes the metabolomics data that have been measured in blood for adults and in urine for 9-year-old twins. In adults, for over 5100 individuals, metabolomics data have been realized from 4 metabolomics platforms: the Nightingale Health 1H-NMR platform (previously referred to as Brainshake), a UPLC-MS Lipidomics platform, the LUMC 1H-NMR platform and the Biocrates Absolute-IDQTM p150 platform (Draisma et al., Reference Draisma, Beekman, Pool, van Ommen, Adamski, Prehn and Boomsma2013; Hagenbeek et al., Reference Hagenbeek, Pool, Van Dongen, Draisma, Hottenga, Willemsen and Boomsma2019). In children, metabolomics data were assessed across three platforms for amines, organic acids and steroid hormones. The NTR biobank, combined with the extensive phenotypic information available within the NTR, provides a valuable resource for the study of genetic influences on individual differences in mental and physical health (see Table 8).
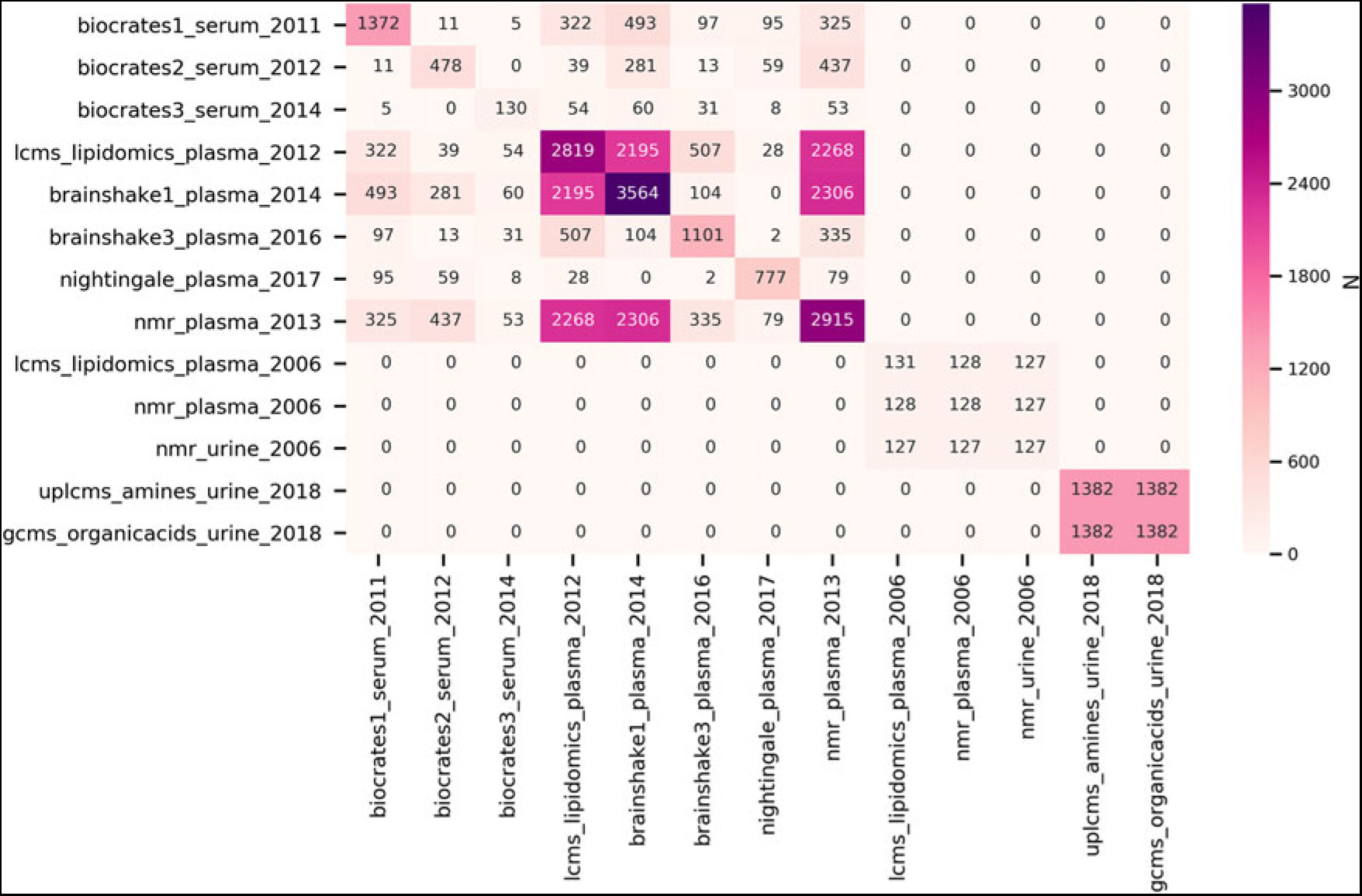
Fig. 1. Subject overlap between the NTR metabolomics datasets. The datasets are denoted by metabolomics platform, sample material/tissue and year of measurement. Note that the values on the diagonal represent the sample size of the individual datasets. All data assessed before 2018 are from adults, all data assessed in 2018 are from 9-year-olds.
Communication with Participants
We observe that families that do not participate at one of more waves of data collection often participate again in subsequent waves (‘drop-in’). Reasons for this include true changes in motivation and availability, but also participants moving to new addresses, which may be traced only after data collection for the current wave is closed. To bolster the motivation to stay involved, we have a website (http://www.tweelingenregister.org/) and a yearly newsletter, Twinfo, that is mailed to all families and also published on the website (http://www.tweelingenregister.org/twinfo/). Two social media outlets are Facebook (https://www.facebook.com/NederlandsTweelingenRegister/) and Twitter (https://twitter.com/NTR_VU; https://twitter.com/NTRscience). In addition, within a national collaboration of cohorts/biobanks (https://www.bbmri.nl/), the NTR has pioneered building a portal for participants. This ‘My NTR’ portal (https://www.mijnntr.nl/) provides selected personalized feedback on data provided by the participants (e.g., personality profile), in addition to general information on the outcomes of the research participants have contributed to (Bovenberg et al., Reference Bovenberg, Kattenberg, Baselmans, Sinke, Hoekstra, Boomsma and Willemsen2016).
Discussion
We conclude this paper on the NTR by considering some exciting developments which we believe illustrate the continued value of twin-family data across multiple domains of research.
Polygenic Risk Scores to Detect the Effects of Nurture
Two papers published last year (Bates et al., Reference Bates, Maher, Medland, McAloney, Wright, Hansell and Gillespie2018; Kong et al., Reference Kong, Thorleifsson, Frigge, Vilhjalmsson, Young, Thorgeirsson and Masson2018) detailed an innovative method to measure intergenerational transmission in families where whole-genome genotyping is available in both parents and in their offspring. Parents transmit only one copy of each chromosome (~50% of genome) to each offspring, but shape an environment for their offspring that is influenced by their own genome. The aggregate effect of an individual’s genome on a trait can be summarized in a polygenic risk score (PRS). The PRS for the transmitted and nontransmitted parental genotypes can be separately associated with outcome traits. The nontransmitted genotypic effects on offspring’s outcome traits can be interpreted as a direct measure of parenting behaviors and environments, unconfounded by the genomes transmitted to the offspring. This is also referred to as ‘genetic nurturing’. Large genomewide association studies are required to estimate the transmitted and nontransmitted PRS, but these are increasingly becoming available. The second requirement is that offspring and parents are all genotyped (however, note that the phenotype information is only needed in the offspring). The NTR has nearly always aimed to collected DNA samples in extended twin families, that is, the index twins, their parents and siblings. In these NTR families, it is possible to construct PRS based on the transmitted and nontransmitted parental genomes for all traits with published summary statistics. These have now been calculated for 5902 offspring within NTR. We recently employed this design to seek evidence of genetic nurturing in adults’ educational attainment and children’s academic achievement and ADHD (de Zeeuw et al., Reference de Zeeuw, Hottenga, Ouwens, Dolan, Ehli, Davies, Boomsma and van Bergen2019).
Phenotypic Reference Panels
When phenotyping for a trait, or a series of traits, has been carried out with different instruments, data integration methods for phenotype harmonization across instruments require or can greatly benefit from datasets where the different instruments have been administered to the same subjects (van Den Berg et al., Reference van Den Berg, De Moor, McGue, Pettersson, Terracciano, Verweij and Van Grootheest2014). In YNTR, we collected such a reference panel for phenotype data to harmonize multiple measures of aggression and other behavioral problems in schoolchildren as part of the ACTION project (Aggression in Children: Unraveling gene-environment interplay to inform Treatment and interventION strategies Consortium; http://www.action-euproject.eu/; Bartels et al., Reference Bartels, Hendriks, Mauri, Krapohl, Whipp, Bolhuis and Hagenbeek2018; Luningham et al., Reference Luningham, McArtor, Bartels, Boomsma and Lubke2017). Throughout 2016, the Child Behavior Check List (CBCL; Achenbach et al., Reference Achenbach, Ivanova and Rescorla2017), the complete Strengths and Difficulties Questionnaire ( Goodman, Reference Goodman1997) plus a selection of A-TAC items (Autism-Tics, ADHD, and other Comorbidities inventory; Larson et al., Reference Larson, Anckarsäter, Gillberg, Ståhlberg, Carlström, Kadesjö and Gillberg2010) were completed by both parents of twins born between September 2005 and October 2008. Hendriks et al. (Reference Hendriks, Ip, Nivard, Finkenauer, Van Beijsterveldt, Bartels and Boomsma2019) analyzed aggression data across these different instruments. Although agreement with respect to phenotypic diagnoses and correlations between continuous scores were moderate, genetic correlations indicated that the underlying construct of childhood aggression was consistent across measures.
Children-of-Twins Design/Numbers for Exceptional Families
Infant twins who were enrolled by their parents and for whom we have data since infancy are now becoming parents themselves. The NTR has started collecting multigenerational data in this unique group. Other interesting groups include multigenerational families where both parent and offspring are twins, as well as families where two siblings are both parents of twins, that is, the twin offspring are cousins. These data enable application of the Children-of-Twins (CoT) design (D’Onofrio et al., Reference D’Onofrio, Turkheimer, Eaves, Corey, Berg, Solaas and Emery2003), to disentangle the genetic and environmental transmission from parents to their offspring and give more insight into the causal role of the home environment on the development of children. The CoT design is based on the fact that offspring of MZ twins are as genetically related to the co-twin of their parent (uncle/aunt) as they are to their own parent, but only share a home environment with their own parents. For more details on the composition of the pedigrees within NTR, see Table 9.
Mendelian Randomization Combined With the Twin Design
One of the greatest challenges in the social, behavioral and medical sciences is to determine the causality underlying associations between a (putative) risk factor and a behavioral or disease outcome. Simple regression analysis cannot properly address this question. The correlation between two variables can reflect reverse causation or unobserved factors that influence both (confounding). Mendelian randomization (MR) is a method based on instrumental variable analysis in econometrics that can be used to estimate the causal effect of a risk factor on a behavioral or health outcome, provided that genetic variants are known that influence the risk factor (Davey Smith & Hemani, Reference Davey Smith and Hemani2014; Palmer et al., Reference Palmer, Sterne, Harbord, Lawlor, Sheehan, Meng and Didelez2011; Pierce et al., Reference Pierce, Ahsan and VanderWeele2010). However, many genetic variants derived from genomewide association (GWA) meta-analyses have small effects, and so, when used as instrumental variables, render MR liable to weak instrument bias. PRS have the advantage of larger effects, but may be characterized by horizontal pleiotropy, which violates a central assumption of MR (Pickrell et al., Reference Pickrell, Berisa, Liu, Segurel, Tung and Hinds2016). We recently developed the MR-DoC twin model, which allows one to test causal hypotheses and to obtain unbiased estimates of the causal effect given strong but pleiotropic instruments (like PRS) by controlling for genetic and environmental influences common to the outcome and exposure (Minica et al., Reference Minica, Dolan, Boomsma, de Geus and Neale2018). This method greatly increases the value of the large twin-family cohorts like the NTR and many others in this special issue.
In conclusion, we believe that twin studies and twin-family studies will continue to blossom into the next decades, and with the new data repository and data showcase under development, the NTR should be well prepared for the future.
Detailed background information on the NTR may also be found on the website http://www.tweelingenregister.org/. This website originated as an information resource for participants and also includes the nearly complete list of publications.
Acknowledgments
We warmly thank all twin families who participated in the research projects described in this paper.
Funding
Funding was obtained from the Netherlands Organization for Scientific Research (NWO) and The Netherlands Organisation for Health Research and Development (ZonMW) grants 904-61-090, 985-10-002, 912-10-020, 904-61-193,480-04-004, 463-06-001, 451-04-034, 400-05-717, Addiction-31160008, 016-115-035, 481-08-011, 056-32-010, Middelgroot-911-09-032, OCW_NWO Gravity program-024.001.003, NWO-Groot 480-15-001/674, NWO Veni 451-15-017, Center for Medical Systems Biology (CSMB, NWO Genomics), NBIC/BioAssist/RK(2008.024), Biobanking and Biomolecular Resources Research Infrastructure (BBMRI-NL, 184.021.007 and 184.033.111); Spinozapremie (NWO-56-464-14192), KNAW Academy Professor Award (PAH/6635) and University Research Fellow grant (URF) to DIB; Amsterdam Public Health research institute (former EMGO+), Neuroscience Amsterdam research institute (former NCA); the European Science Foundation (ESF, EU/QLRT-2001-01254), the European Community’s Seventh Framework Program (FP7-HEALTH-F4-2007-2013, grant 01413: ENGAGE and grant 602768: ACTION); the European Research Council (ERC Starting 284167, ERC Consolidator 771057, ERC Advanced 230374), Rutgers University Cell and DNA Repository (NIMH U24 MH068457-06), the National Institutes of Health (NIH, R01D0042157-01A1, R01MH58799-03, MH081802, DA018673, R01 DK092127-04, Grand Opportunity grants 1RC2 MH089951 and 1RC2 MH089995); the Avera Institute for Human Genetics, Sioux Falls, South Dakota (USA). Part of the genotyping and analyses were funded by the Genetic Association Information Network (GAIN) of the Foundation for the National Institutes of Health. Computing was supported by NWO through grant 2018/EW/00408559, BiG Grid, the Dutch e-Science Grid and SURFSARA.
Appendix. Zygosity
Methods
To determine the accuracy of zygosity determination in children aged 0–16 years, the agreement between zygosity based on a blood group or DNA tests and zygosity based on discriminant analysis of survey items on resemblance was investigated. In earlier research, prediction accuracy of zygosity was around 93% in children (Rietveld et al., Reference Rietveld, van Der Valk, Bongers, Stroet, Slagboom and Boomsma2000). Since then, an additional item was added to the NTR questionnaires and substantially more DNA data have become available. We reevaluated zygosity assignments, based on surveys obtained at ages 3, 5, 7, 10, 12, 14 and 16 years. These contain 10 zygosity items about resemblance between the twins (6 items about physical similarities and 4 items about confusion by parents and others). At ages 3–12 years, mothers and fathers and at ages 14–16 years the twins themselves filled out the questions. In adults aged 18–99 years, multiple surveys contain eight zygosity items (five items about resemblance and three items about confusion by parents and others). Here, the questions were answered by the twins.
Because knowledge of the result of a zygosity test may affect responses, we only included data from same-sex twins whose survey information had been completed before they, or their parents, received the results of the DNA tests. For the children, this resulted in a sample of 5776 twins and for adults in a sample of 3512 twins.
For children, the data were randomly divided into a training set (60%) and a testing set (40%). In the training set, linear discriminant analysis was applied to survey data from each informant (mother, father and self) and ages 3–16 years. Linear discriminant analysis determines the axes that maximize the separation of different classes, in our case MZ and DZ. This analysis generated a linear function of the weighted sum of the items, in which the weights were optimized to distinguish between MZ and DZ twin-pairs. The outcomes then were applied to the data from the testing set (N = 2260). If multiple surveys were available (either multiple ages, multiple informants or both), the most frequently predicted zygosity was chosen as the assigned zygosity. If an equal number of MZ and DZ outcomes was observed, the mean probability of being MZ determined by the discriminant analyses was used (MZ: probability > .5 and DZ: probability < .5). To determine the accuracy of our zygosity classification by the questionnaire items, we determined the proportion in which the true zygosity and the assigned zygosity corresponded. If there was no childhood survey after age 2 years, the item about resemblance from the questionnaire collected at age 2 years was used (MZ: ‘yes, but barely different’ or ‘yes, but well distinguishable’ and DZ: ‘no, not a lot’ or ‘no, not at all’). If there also was no information at age 2 years, the item from the questionnaire at age 1 year was used (MZ: ‘MZ twins’ and DZ: ‘DZ twins’).
For adults a similar scheme was used: 60% of the data were randomly assigned to be in the training set and 40% to be in the testing set. The first available survey with zygosity items was analyzed. The outcomes of the linear discriminant analysis of the training set were used to predict zygosity in the testing set (N = 1362).
Results
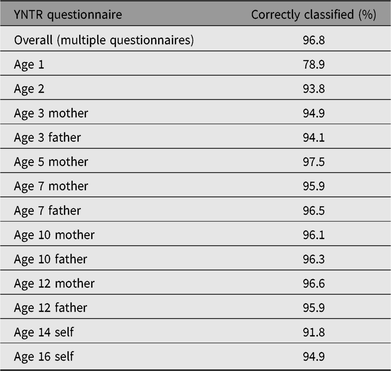
In children, results indicate that the entire procedure of zygosity prediction by the 10-item zygosity questionnaires correctly classified zygosity in 96.8%. Prediction accuracy for all YNTR questionnaires separately can be found in Table A1. For 95.8% of this sample, data on the 10-item zygosity list included in the questionnaires at ages 3–16 years were available. If only these participants were considered, the accuracy of zygosity classification was 97.2%. In the remaining sample, only surveys at earlier ages, when twins are 1 and 2 years, were available. These were completed by mothers and included one question at age 1 year (‘According to you, the twins are’, with answer options ‘DZ twins’ and ‘MZ twins’) and one question at age 2 years (‘Do the children resemble each other’ — with answer options ‘yes, they are barely different’, ‘yes, but well distinguishable’, ‘no, not a lot’ and ‘no, not at all’). If only the questionnaire at age 2 years is used, zygosity prediction is accurate in 93.8% of the cases. When only the questionnaire at age 1 year is used, prediction accuracy of zygosity drops to 78.9%. Participants with data at age 1 or 2 years only are underrepresented in the sample, (N = 96).
Table A1. Zygosity prediction accuracy of YNTR questionnaire items compared to DNA
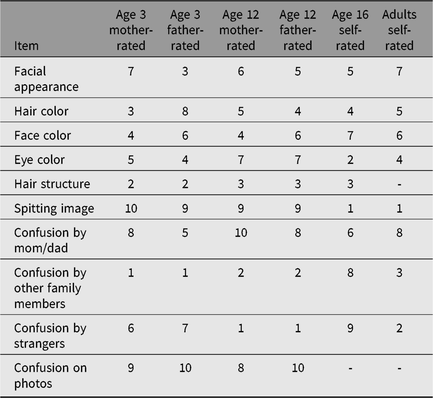
In adults, zygosity prediction based on survey items was accurate in 95.9%. In Table A2, the results of the linear discriminant analysis are displayed. In adults, the item that distinguishes best between MZ and DZ twins was ‘Were you each other’s spitting image as children?’, whereas the item ‘Did mother and father mix you up when you were young’ does not distinguish well. In parent-reports on children, confusion by other family members than parents was a well-distinguishing item.
Table A2. Ranks for the predictive value of the zygosity items in YNTR and ANTR surveys
YNTR = Young Netherlands Twin Register; ANTR = Adult Netherlands Twin Register.
Note: 1 = most predictive item; 10 = least predictive item.













 Open access
Open access