
31 results
6 - Time Series Models
-
- Book:
- A Practical Guide to Data Analysis Using R
- Published online:
- 11 May 2024
- Print publication:
- 30 May 2024, pp 292-317
-
- Chapter
- Export citation
Limited evidence of autocorrelation signaling upcoming affective episodes: a 12-month e-diary study in patients with bipolar disorder
-
- Journal:
- Psychological Medicine , First View
- Published online by Cambridge University Press:
- 29 January 2024, pp. 1-9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Day-to-day affect fluctuations in adults with childhood trauma history: a two-week ecological momentary assessment study
-
- Journal:
- Psychological Medicine / Volume 54 / Issue 6 / April 2024
- Published online by Cambridge University Press:
- 09 October 2023, pp. 1160-1171
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Chapter 20 - An Introduction to Psychologically Plausible Sampling Schemes for Approximating Bayesian Inference
- from Part VI - Computational Approaches
-
-
- Book:
- Sampling in Judgment and Decision Making
- Published online:
- 01 June 2023
- Print publication:
- 15 June 2023, pp 467-489
-
- Chapter
- Export citation
9 - Solute Transport in Field-Scale Aquifers
-
- Book:
- An Introduction to Solute Transport in Heterogeneous Geologic Media
- Published online:
- 02 February 2023
- Print publication:
- 09 February 2023, pp 222-253
-
- Chapter
- Export citation
1 - Fundamental Concepts
-
- Book:
- An Introduction to Solute Transport in Heterogeneous Geologic Media
- Published online:
- 02 February 2023
- Print publication:
- 09 February 2023, pp 1-32
-
- Chapter
- Export citation
8 - Cybersecurity through Time Series and Spatial Data
-
- Book:
- Data Analytics for Cybersecurity
- Published online:
- 10 August 2022
- Print publication:
- 21 July 2022, pp 112-127
-
- Chapter
- Export citation
4 - Deterministic and Random Functions
-
- Book:
- Time Series Data Analysis in Oceanography
- Published online:
- 21 April 2022
- Print publication:
- 05 May 2022, pp 78-89
-
- Chapter
- Export citation
4 - Overview of Mathematical Tools
- from Part I - Fundamentals
-
- Book:
- Electronic Sensor Design Principles
- Published online:
- 23 December 2021
- Print publication:
- 06 January 2022, pp 189-235
-
- Chapter
- Export citation
Semi-automated counting of complex varves through image autocorrelation
-
- Journal:
- Quaternary Research / Volume 104 / November 2021
- Published online by Cambridge University Press:
- 14 April 2021, pp. 89-100
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
12 - Psychological Assessment In and Over Time: Challenges of Assessing Psychological Constructs and Processes in Cultural Dynamics
- from Part 3 - Culture and Assessment
-
-
- Book:
- Methods and Assessment in Culture and Psychology
- Published online:
- 21 January 2021
- Print publication:
- 18 February 2021, pp 255-270
-
- Chapter
- Export citation
EXTENSIONS OF AUTOCORRELATION INEQUALITIES WITH APPLICATIONS TO ADDITIVE COMBINATORICS
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 102 / Issue 3 / December 2020
- Published online by Cambridge University Press:
- 08 April 2020, pp. 451-461
- Print publication:
- December 2020
-
- Article
- Export citation
-
Barnard and Steinerberger [‘Three convolution inequalities on the real line with connections to additive combinatorics’, Preprint, 2019, arXiv:1903.08731] established the autocorrelation inequality
where the constant $$\begin{eqnarray}\min _{0\leq t\leq 1}\int _{\mathbb{R}}f(x)f(x+t)\,dx\leq 0.411||f||_{L^{1}}^{2}\quad \text{for}~f\in L^{1}(\mathbf{R}),\end{eqnarray}$$
$$\begin{eqnarray}\min _{0\leq t\leq 1}\int _{\mathbb{R}}f(x)f(x+t)\,dx\leq 0.411||f||_{L^{1}}^{2}\quad \text{for}~f\in L^{1}(\mathbf{R}),\end{eqnarray}$$ $0.411$ cannot be replaced by
$0.411$ cannot be replaced by  $0.37$. In addition to being interesting and important in their own right, inequalities such as these have applications in additive combinatorics. We show that for
$0.37$. In addition to being interesting and important in their own right, inequalities such as these have applications in additive combinatorics. We show that for  $f$ to be extremal for this inequality, we must have Our central technique for deriving this result is local perturbation of
$f$ to be extremal for this inequality, we must have Our central technique for deriving this result is local perturbation of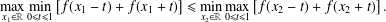 $$\begin{eqnarray}\max _{x_{1}\in \mathbb{R}}\min _{0\leq t\leq 1}\left[f(x_{1}-t)+f(x_{1}+t)\right]\leq \min _{x_{2}\in \mathbb{R}}\max _{0\leq t\leq 1}\left[f(x_{2}-t)+f(x_{2}+t)\right].\end{eqnarray}$$
$$\begin{eqnarray}\max _{x_{1}\in \mathbb{R}}\min _{0\leq t\leq 1}\left[f(x_{1}-t)+f(x_{1}+t)\right]\leq \min _{x_{2}\in \mathbb{R}}\max _{0\leq t\leq 1}\left[f(x_{2}-t)+f(x_{2}+t)\right].\end{eqnarray}$$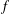 $f$ to increase the value of the autocorrelation, while leaving
$f$ to increase the value of the autocorrelation, while leaving 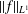 $||f||_{L^{1}}$ unchanged. These perturbation methods can be extended to examine a more general notion of autocorrelation. Let
$||f||_{L^{1}}$ unchanged. These perturbation methods can be extended to examine a more general notion of autocorrelation. Let 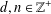 $d,n\in \mathbb{Z}^{+}$,
$d,n\in \mathbb{Z}^{+}$, 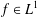 $f\in L^{1}$,
$f\in L^{1}$, 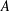 $A$ be a
$A$ be a 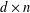 $d\times n$ matrix with real entries and columns
$d\times n$ matrix with real entries and columns 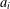 $a_{i}$ for
$a_{i}$ for 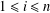 $1\leq i\leq n$ and
$1\leq i\leq n$ and 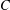 $C$ be a constant. For a broad class of matrices
$C$ be a constant. For a broad class of matrices 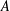 $A$, we prove necessary conditions for
$A$, we prove necessary conditions for 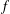 $f$ to extremise autocorrelation inequalities of the form
$f$ to extremise autocorrelation inequalities of the form 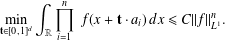 $$\begin{eqnarray}\min _{\mathbf{t}\in [0,1]^{d}}\int _{\mathbb{R}}\mathop{\prod }_{i=1}^{n}~f(x+\mathbf{t}\cdot a_{i})\,dx\leq C||f||_{L^{1}}^{n}.\end{eqnarray}$$
$$\begin{eqnarray}\min _{\mathbf{t}\in [0,1]^{d}}\int _{\mathbb{R}}\mathop{\prod }_{i=1}^{n}~f(x+\mathbf{t}\cdot a_{i})\,dx\leq C||f||_{L^{1}}^{n}.\end{eqnarray}$$
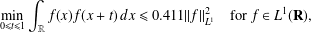
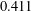
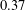
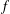
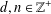
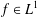
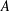
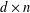
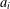
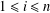
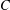
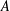
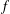
Autoregressive repeatability model for genetic evaluation of longitudinal reproductive traits in dairy cattle
-
- Journal:
- Journal of Dairy Research / Volume 87 / Issue 1 / February 2020
- Published online by Cambridge University Press:
- 21 January 2020, pp. 37-44
- Print publication:
- February 2020
-
- Article
- Export citation
2 - Covariance-Based Approaches
-
- Book:
- A Primer on Fourier Analysis for the Geosciences
- Published online:
- 01 February 2019
- Print publication:
- 14 February 2019, pp 9-30
-
- Chapter
- Export citation
8 - Noise in Time-Series
-
- Book:
- A Primer on Fourier Analysis for the Geosciences
- Published online:
- 01 February 2019
- Print publication:
- 14 February 2019, pp 123-136
-
- Chapter
- Export citation
LO05: A statistical analysis to estimate the spatial dynamics of opioid-related emergency medical services responses in the city of Calgary 2017
-
- Journal:
- Canadian Journal of Emergency Medicine / Volume 20 / Issue S1 / May 2018
- Published online by Cambridge University Press:
- 11 May 2018, p. S8
- Print publication:
- May 2018
-
- Article
-
- You have access
- Export citation
Spatial Relationships Between Seedbank and Seedling Populations of Common Lambsquarters (Chenopodium album) and Annual Grasses
-
- Journal:
- Weed Science / Volume 44 / Issue 2 / June 1996
- Published online by Cambridge University Press:
- 12 June 2017, pp. 298-308
-
- Article
- Export citation
Stacked Crop Rotations Exploit Weed-Weed Competition for Sustainable Weed Management
-
- Journal:
- Weed Science / Volume 62 / Issue 1 / March 2014
- Published online by Cambridge University Press:
- 20 January 2017, pp. 166-176
-
- Article
- Export citation
Parametric Modeling and Simulation of Joint Price-Production Distributions under Non-Normality, Autocorrelation and Heteroscedasticity: A Tool for Assessing Risk in Agriculture
-
- Journal:
- Journal of Agricultural and Applied Economics / Volume 32 / Issue 2 / August 2000
- Published online by Cambridge University Press:
- 28 April 2015, pp. 283-297
-
- Article
- Export citation
Estimating a Demand System with Seasonally Differenced Data
-
- Journal:
- Journal of Agricultural and Applied Economics / Volume 42 / Issue 2 / May 2010
- Published online by Cambridge University Press:
- 26 January 2015, pp. 321-335
-
- Article
- Export citation
