
96 results
Multipronged strategy for protection and motivation of healthcare workers during the COVID-19 pandemic: a real-life study
-
- Journal:
- Antimicrobial Stewardship & Healthcare Epidemiology / Volume 4 / Issue 1 / 2024
- Published online by Cambridge University Press:
- 25 July 2024, e101
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Efficacy and safety of transcranial magnetic stimulation on cognition in mild cognitive impairment, Alzheimer’s disease, Alzheimer’s disease-related dementias, and other cognitive disorders: a systematic review and meta-analysis
-
- Journal:
- International Psychogeriatrics , First View
- Published online by Cambridge University Press:
- 08 February 2024, pp. 1-49
-
- Article
- Export citation
FC24: Transcranial Magnetic Stimulation (TMS) as a Treatment for Dementia due to non-Alzheimer’s disease (non-AD): What is the Evidence?
-
- Journal:
- International Psychogeriatrics / Volume 35 / Issue S1 / December 2023
- Published online by Cambridge University Press:
- 02 February 2024, pp. 85-86
-
- Article
-
- You have access
- Export citation
Nitrogen fertilizer and landscape position affect soil aggregate size distribution, and intra-aggregate carbon and nitrogen under switchgrass in a marginal cropland
-
- Journal:
- The Journal of Agricultural Science / Volume 161 / Issue 4 / August 2023
- Published online by Cambridge University Press:
- 13 July 2023, pp. 512-520
-
- Article
- Export citation
Temporal variabilities of soil carbon dioxide fluxes from cornfield impacted by temperature and precipitation changes through high-frequent measurement and DAYCENT modelling
-
- Journal:
- The Journal of Agricultural Science / Volume 160 / Issue 3-4 / June 2022
- Published online by Cambridge University Press:
- 31 March 2022, pp. 138-151
-
- Article
- Export citation
Genetic evidence indicates the occurrence of the Endangered Kashmir musk deer Moschus cupreus in Uttarakhand, India
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
COUNTING HECKE EIGENFORMS WITH NONVANISHING
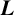 $\boldsymbol {L}$
-VALUE
$\boldsymbol {L}$
-VALUE
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 106 / Issue 1 / August 2022
- Published online by Cambridge University Press:
- 24 January 2022, pp. 28-47
- Print publication:
- August 2022
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We develop some asymptotics for a kernel function introduced by Kohnen and use them to estimate the number of normalised Hecke eigenforms in
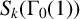 $S_k(\Gamma _0(1))$
whose L-values are simultaneously nonvanishing at a given pair of points each of which lies inside the critical strip.
$S_k(\Gamma _0(1))$
whose L-values are simultaneously nonvanishing at a given pair of points each of which lies inside the critical strip.
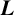
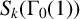
On-farm assessment of cover cropping effects on soil C and N pools, enzyme activities, and microbial community structure
- Part of
-
- Journal:
- The Journal of Agricultural Science / Volume 159 / Issue 3-4 / April 2021
- Published online by Cambridge University Press:
- 08 June 2021, pp. 216-226
-
- Article
-
- You have access
- HTML
- Export citation
Evolution of magnetic field in a weakly relativistic counterstreaming inhomogeneous e−/e+ plasmas
-
- Journal:
- Laser and Particle Beams / Volume 38 / Issue 3 / September 2020
- Published online by Cambridge University Press:
- 24 July 2020, pp. 181-187
-
- Article
- Export citation
Multigeneration solution-processed method for silver nanotriangles exhibiting narrow linewidth (∼170 nm) absorption in near-infrared
-
- Journal:
- Journal of Materials Research / Volume 34 / Issue 20 / 28 October 2019
- Published online by Cambridge University Press:
- 16 September 2019, pp. 3420-3427
- Print publication:
- 28 October 2019
-
- Article
- Export citation
Can bars erode cuspy halos?
-
- Journal:
- Proceedings of the International Astronomical Union / Volume 14 / Issue S353 / June 2019
- Published online by Cambridge University Press:
- 14 May 2020, pp. 184-185
- Print publication:
- June 2019
-
- Article
-
- You have access
- Export citation
The evolution of bulges of galaxies in minor fly-by interactions
-
- Journal:
- Proceedings of the International Astronomical Union / Volume 14 / Issue S353 / June 2019
- Published online by Cambridge University Press:
- 14 May 2020, pp. 166-167
- Print publication:
- June 2019
-
- Article
-
- You have access
- Export citation
Dedication
-
- Book:
- Design and Analysis of Algorithms
- Published online:
- 27 April 2019
- Print publication:
- 16 May 2019, pp v-vi
-
- Chapter
- Export citation
List of Figures
-
- Book:
- Design and Analysis of Algorithms
- Published online:
- 27 April 2019
- Print publication:
- 16 May 2019, pp xv-xviii
-
- Chapter
- Export citation
4 - Optimization I: Brute Force and Greedy Strategy
-
- Book:
- Design and Analysis of Algorithms
- Published online:
- 27 April 2019
- Print publication:
- 16 May 2019, pp 54-91
-
- Chapter
- Export citation
7 - Multidimensional Searching and Geometric Algorithms
-
- Book:
- Design and Analysis of Algorithms
- Published online:
- 27 April 2019
- Print publication:
- 16 May 2019, pp 128-156
-
- Chapter
- Export citation
10 - Graph Algorithms
-
- Book:
- Design and Analysis of Algorithms
- Published online:
- 27 April 2019
- Print publication:
- 16 May 2019, pp 184-207
-
- Chapter
- Export citation
