
39 results
Localisation of gamma-ray bursts from the combined SpIRIT+HERMES-TP/SP nano-satellite constellation – CORRIGENDUM
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 01 April 2024, e017
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Boredom, emotional dysregulation and avoidance coping strategies: Which is their role in youth mood disorders?
-
- Journal:
- European Psychiatry / Volume 66 / Issue S1 / March 2023
- Published online by Cambridge University Press:
- 19 July 2023, pp. S716-S717
-
- Article
-
- You have access
- Open access
- Export citation
Psychopathological characterization of modern-type depression in subjects with Internet Gaming Disorder
-
- Journal:
- European Psychiatry / Volume 66 / Issue S1 / March 2023
- Published online by Cambridge University Press:
- 19 July 2023, p. S1001
-
- Article
-
- You have access
- Open access
- Export citation
The mediating role of the boredom and loneliness dimensions in the development of Problematic Internet Use
-
- Journal:
- European Psychiatry / Volume 66 / Issue S1 / March 2023
- Published online by Cambridge University Press:
- 19 July 2023, pp. S623-S624
-
- Article
-
- You have access
- Open access
- Export citation
Localisation of gamma-ray bursts from the combined SpIRIT+HERMES-TP/SP nano-satellite constellation
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 40 / 2023
- Published online by Cambridge University Press:
- 08 February 2023, e008
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Multi-messenger observations of the transient sky to detect cosmic explosions and counterparts of gravitational wave mergers critically rely on orbiting wide-FoV telescopes to cover the wide range of wavelengths where atmospheric absorption and emission limit the use of ground facilities. Thanks to continuing technological improvements, miniaturised space instruments operating as distributed-aperture constellations are offering new capabilities for the study of high-energy transients to complement ageing existing satellites. In this paper we characterise the performance of the upcoming joint SpIRIT and HERMES-TP/SP constellation for the localisation of high-energy transients through triangulation of signal arrival times. SpIRIT is an Australian technology and science demonstrator satellite designed to operate in a low-Earth Sun-synchronous Polar orbit that will augment the science operations for the equatorial HERMES-TP/SP constellation. In this work we simulate the improvement to the localisation capabilities of the HERMES-TP/SP constellation when SpIRIT is included in an orbital plane nearly perpendicular (inclination = 97.6°) to the HERMES-TP/SP orbits. For the fraction of GRBs detected by three of the HERMES satellites plus SpIRIT, we find that the combined constellation is capable of localising 60% of long GRBs to within
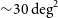 ${\sim}30\,\textrm{deg}^{2}$ on the sky, and 60% of short GRBs within
${\sim}30\,\textrm{deg}^{2}$ on the sky, and 60% of short GRBs within 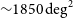 ${\sim}1850\,\textrm{deg}^{2}$ (
${\sim}1850\,\textrm{deg}^{2}$ (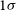 $1\sigma$ confidence regions), though it is beyond the scope of this work to characterise or rule out systematic uncertainty of the same order of magnitude. Based purely on statistical GRB localisation capabilities (i.e., excluding systematic uncertainties and sky coverage), these figures for long GRBs are comparable to those reported by the Fermi Gamma Burst Monitor instrument. These localisation statistics represents a reduction of the uncertainty for the burst localisation region for both long and short GRBs by a factor of
$1\sigma$ confidence regions), though it is beyond the scope of this work to characterise or rule out systematic uncertainty of the same order of magnitude. Based purely on statistical GRB localisation capabilities (i.e., excluding systematic uncertainties and sky coverage), these figures for long GRBs are comparable to those reported by the Fermi Gamma Burst Monitor instrument. These localisation statistics represents a reduction of the uncertainty for the burst localisation region for both long and short GRBs by a factor of 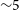 ${\sim}5$ compared to the HERMES-TP/SP alone. Further improvements by an additional factor of 2 (or 4) can be achieved by launching an additional 4 (or 6) SpIRIT-like satellites into a Polar orbit, respectively, which would both increase the fraction of sky covered by multiple satellite elements, and also enable localisation of
${\sim}5$ compared to the HERMES-TP/SP alone. Further improvements by an additional factor of 2 (or 4) can be achieved by launching an additional 4 (or 6) SpIRIT-like satellites into a Polar orbit, respectively, which would both increase the fraction of sky covered by multiple satellite elements, and also enable localisation of 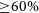 ${\geq} 60\%$ of long GRBs to within a radius of
${\geq} 60\%$ of long GRBs to within a radius of  ${\sim}1.5^{\circ}$ (statistical uncertainty) on the sky, clearly demonstrating the value of a distributed all-sky high-energy transient monitor composed of nano-satellites.
${\sim}1.5^{\circ}$ (statistical uncertainty) on the sky, clearly demonstrating the value of a distributed all-sky high-energy transient monitor composed of nano-satellites.
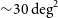
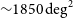
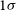
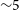
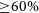

Boredom, loneliness and modern type depression in a cohort of Italian university students
-
- Journal:
- European Psychiatry / Volume 65 / Issue S1 / June 2022
- Published online by Cambridge University Press:
- 01 September 2022, p. S866
-
- Article
-
- You have access
- Open access
- Export citation
Modern-type depression and web-based psychopathology in a cohort of Italian university students
-
- Journal:
- European Psychiatry / Volume 65 / Issue S1 / June 2022
- Published online by Cambridge University Press:
- 01 September 2022, p. S243
-
- Article
-
- You have access
- Open access
- Export citation
Suicidality in post-traumatic stress disorder (PTSD) and complex PTSD (CPTSD)
-
- Journal:
- European Psychiatry / Volume 64 / Issue S1 / April 2021
- Published online by Cambridge University Press:
- 13 August 2021, p. S142
-
- Article
-
- You have access
- Open access
- Export citation
Cognitive function and metabolic syndrome in unipolar and bipolar depression: A pilot study
-
- Journal:
- European Psychiatry / Volume 64 / Issue S1 / April 2021
- Published online by Cambridge University Press:
- 13 August 2021, p. S82
-
- Article
-
- You have access
- Open access
- Export citation
Suicidality and relation with dissociation and alexithymia in PNES and conversion disorder
-
- Journal:
- European Psychiatry / Volume 64 / Issue S1 / April 2021
- Published online by Cambridge University Press:
- 13 August 2021, p. S591
-
- Article
-
- You have access
- Open access
- Export citation
Polyunsaturated fatty acid in treatment resistant depression: A pilot study
-
- Journal:
- European Psychiatry / Volume 64 / Issue S1 / April 2021
- Published online by Cambridge University Press:
- 13 August 2021, pp. S323-S324
-
- Article
-
- You have access
- Open access
- Export citation
1748 – Electroconvulsive Treatment In Schizophrenia: a Systematic Review
-
- Journal:
- European Psychiatry / Volume 28 / Issue S1 / 2013
- Published online by Cambridge University Press:
- 15 April 2020, 28-E1015
-
- Article
-
- You have access
- Export citation
1109 – Sleep Disorders And Suicidal Behavior In Patients Admitted To The Emergency Department
-
- Journal:
- European Psychiatry / Volume 28 / Issue S1 / 2013
- Published online by Cambridge University Press:
- 15 April 2020, 28-E502
-
- Article
-
- You have access
- Export citation
Body image and eating disorders are common in professional and amateur athletes using performance and image-enhancing drugs (pieds). A cross-sectional study
-
- Journal:
- European Psychiatry / Volume 33 / Issue S1 / March 2016
- Published online by Cambridge University Press:
- 23 March 2020, p. S144
-
- Article
-
- You have access
- Export citation
Unique Structural Characteristics of Catalytic Palladium/Gold Nanoparticles on Graphene
-
- Journal:
- Microscopy and Microanalysis / Volume 25 / Issue 1 / February 2019
- Published online by Cambridge University Press:
- 30 January 2019, pp. 80-91
- Print publication:
- February 2019
-
- Article
- Export citation
Atomic-resolution Imaging and Spectroscopy of Iron Oxide Epitaxial Thin Films
-
- Journal:
- Microscopy and Microanalysis / Volume 24 / Issue S1 / August 2018
- Published online by Cambridge University Press:
- 01 August 2018, pp. 1614-1615
- Print publication:
- August 2018
-
- Article
-
- You have access
- Export citation
Evaluation of CaSO4 micrograins in the context of organic matter delivery: thermochemistry and atmospheric entry
-
- Journal:
- International Journal of Astrobiology / Volume 18 / Issue 4 / August 2019
- Published online by Cambridge University Press:
- 23 July 2018, pp. 345-352
-
- Article
- Export citation
Ni-sepiolite-falcondoite in garnierite mineralization from the Falcondo Ni-laterite deposit, Dominican Republic
-
- Journal:
- Clay Minerals / Volume 44 / Issue 4 / December 2009
- Published online by Cambridge University Press:
- 09 July 2018, pp. 435-454
-
- Article
- Export citation
Effect of Branched Broomrape (Orobanche ramosa) Infection on the Growth and Photosynthesis of Tomato
-
- Journal:
- Weed Science / Volume 56 / Issue 4 / August 2008
- Published online by Cambridge University Press:
- 20 January 2017, pp. 574-581
-
- Article
- Export citation
Soil solarization, a nonchemical method to control branched broomrape (Orobanche ramosa) and improve the yield of greenhouse tomato
-
- Journal:
- Weed Science / Volume 53 / Issue 6 / December 2005
- Published online by Cambridge University Press:
- 20 January 2017, pp. 877-883
-
- Article
- Export citation
