
217 results in 62Exx
A remark on exact simulation of tempered stable Ornstein–Uhlenbeck processes
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 02 May 2024, pp. 1-3
-
- Article
-
- You have access
- HTML
- Export citation
ON THE CUMULATIVE DISTRIBUTION FUNCTION OF THE VARIANCE-GAMMA DISTRIBUTION
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society , First View
- Published online by Cambridge University Press:
- 29 January 2024, pp. 1-9
-
- Article
- Export citation
Normal approximation in total variation for statistics in geometric probability
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 56 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 03 July 2023, pp. 106-155
- Print publication:
- March 2024
-
- Article
- Export citation
-
We use Stein’s method to establish the rates of normal approximation in terms of the total variation distance for a large class of sums of score functions of samples arising from random events driven by a marked Poisson point process on
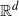 $\mathbb{R}^d$. As in the study under the weaker Kolmogorov distance, the score functions are assumed to satisfy stabilisation and moment conditions. At the cost of an additional non-singularity condition, we show that the rates are in line with those under the Kolmogorov distance. We demonstrate the use of the theorems in four applications: Voronoi tessellations, k-nearest-neighbours graphs, timber volume, and maximal layers.
$\mathbb{R}^d$. As in the study under the weaker Kolmogorov distance, the score functions are assumed to satisfy stabilisation and moment conditions. At the cost of an additional non-singularity condition, we show that the rates are in line with those under the Kolmogorov distance. We demonstrate the use of the theorems in four applications: Voronoi tessellations, k-nearest-neighbours graphs, timber volume, and maximal layers.
Distribution and moments of the error term in the lattice point counting problem for three-dimensional Cygan–Korányi balls
- Part of
-
- Journal:
- Proceedings of the Royal Society of Edinburgh. Section A: Mathematics / Volume 154 / Issue 3 / June 2024
- Published online by Cambridge University Press:
- 19 May 2023, pp. 830-861
- Print publication:
- June 2024
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Distributions of random variables involved in discrete censored δ-shock models
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 55 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 19 May 2023, pp. 1144-1170
- Print publication:
- December 2023
-
- Article
- Export citation
-
Suppose that a system is affected by a sequence of random shocks that occur over certain time periods. In this paper we study the discrete censored
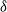 $\delta$-shock model,
$\delta$-shock model, 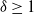 $\delta \ge 1$, for which the system fails whenever no shock occurs within a
$\delta \ge 1$, for which the system fails whenever no shock occurs within a 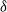 $\delta$-length time period from the last shock, by supposing that the interarrival times between consecutive shocks are described by a first-order Markov chain (as well as under the binomial shock process, i.e., when the interarrival times between successive shocks have a geometric distribution). Using the Markov chain embedding technique introduced by Chadjiconstantinidis et al. (Adv. Appl. Prob. 32, 2000), we study the joint and marginal distributions of the system’s lifetime, the number of shocks, and the number of periods in which no shocks occur, up to the failure of the system. The joint and marginal probability generating functions of these random variables are obtained, and several recursions and exact formulae are given for the evaluation of their probability mass functions and moments. It is shown that the system’s lifetime follows a Markov geometric distribution of order
$\delta$-length time period from the last shock, by supposing that the interarrival times between consecutive shocks are described by a first-order Markov chain (as well as under the binomial shock process, i.e., when the interarrival times between successive shocks have a geometric distribution). Using the Markov chain embedding technique introduced by Chadjiconstantinidis et al. (Adv. Appl. Prob. 32, 2000), we study the joint and marginal distributions of the system’s lifetime, the number of shocks, and the number of periods in which no shocks occur, up to the failure of the system. The joint and marginal probability generating functions of these random variables are obtained, and several recursions and exact formulae are given for the evaluation of their probability mass functions and moments. It is shown that the system’s lifetime follows a Markov geometric distribution of order 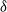 $\delta$ (a geometric distribution of order
$\delta$ (a geometric distribution of order 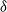 $\delta$ under the binomial setup) and also that it follows a matrix-geometric distribution. Some reliability properties are also given under the binomial shock process, by showing that a shift of the system’s lifetime random variable follows a compound geometric distribution. Finally, we introduce a new mixed discrete censored
$\delta$ under the binomial setup) and also that it follows a matrix-geometric distribution. Some reliability properties are also given under the binomial shock process, by showing that a shift of the system’s lifetime random variable follows a compound geometric distribution. Finally, we introduce a new mixed discrete censored 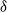 $\delta$-shock model, for which the system fails when no shock occurs within a
$\delta$-shock model, for which the system fails when no shock occurs within a 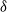 $\delta$-length time period from the last shock, or the magnitude of the shock is larger than a given critical threshold
$\delta$-length time period from the last shock, or the magnitude of the shock is larger than a given critical threshold 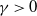 $\gamma >0$. Similarly, for this mixed model, we study the joint and marginal distributions of the system’s lifetime, the number of shocks, and the number of periods in which no shocks occur, up to the failure of the system, under the binomial shock process.
$\gamma >0$. Similarly, for this mixed model, we study the joint and marginal distributions of the system’s lifetime, the number of shocks, and the number of periods in which no shocks occur, up to the failure of the system, under the binomial shock process.
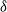
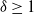
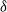
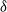
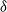
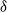
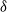
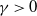
On Bayesian credibility mean for finite mixture distributions
- Part of
-
- Journal:
- Annals of Actuarial Science / Volume 18 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 29 March 2023, pp. 5-29
-
- Article
- Export citation
-
Consider the problem of determining the Bayesian credibility mean
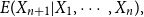 $E(X_{n+1}|X_1,\cdots, X_n),$ whenever the random claims
$E(X_{n+1}|X_1,\cdots, X_n),$ whenever the random claims 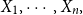 $X_1,\cdots, X_n,$ given parameter vector
$X_1,\cdots, X_n,$ given parameter vector 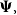 $\boldsymbol{\Psi},$ are sampled from the K-component mixture family of distributions, whose members are the union of different families of distributions. This article begins by deriving a recursive formula for such a Bayesian credibility mean. Moreover, under the assumption that using additional information
$\boldsymbol{\Psi},$ are sampled from the K-component mixture family of distributions, whose members are the union of different families of distributions. This article begins by deriving a recursive formula for such a Bayesian credibility mean. Moreover, under the assumption that using additional information 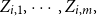 $Z_{i,1},\cdots,Z_{i,m},$ one may probabilistically determine a random claim
$Z_{i,1},\cdots,Z_{i,m},$ one may probabilistically determine a random claim 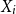 $X_i$ belongs to a given population (or a distribution), the above recursive formula simplifies to an exact Bayesian credibility mean whenever all components of the mixture distribution belong to the exponential families of distributions. For a situation where a 2-component mixture family of distributions is an appropriate choice for data modelling, using the logistic regression model, it shows that: how one may employ such additional information to derive the Bayesian credibility model, say Logistic Regression Credibility model, for a finite mixture of distributions. A comparison between the Logistic Regression Credibility (LRC) model and its competitor, the Regression Tree Credibility (RTC) model, has been given. More precisely, it shows that under the squared error loss function, it shows the LRC’s risk function dominates the RTC’s risk function at least in an interval which about
$X_i$ belongs to a given population (or a distribution), the above recursive formula simplifies to an exact Bayesian credibility mean whenever all components of the mixture distribution belong to the exponential families of distributions. For a situation where a 2-component mixture family of distributions is an appropriate choice for data modelling, using the logistic regression model, it shows that: how one may employ such additional information to derive the Bayesian credibility model, say Logistic Regression Credibility model, for a finite mixture of distributions. A comparison between the Logistic Regression Credibility (LRC) model and its competitor, the Regression Tree Credibility (RTC) model, has been given. More precisely, it shows that under the squared error loss function, it shows the LRC’s risk function dominates the RTC’s risk function at least in an interval which about 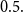 $0.5.$ Several examples have been given to illustrate the practical application of our findings.
$0.5.$ Several examples have been given to illustrate the practical application of our findings.
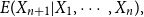
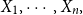
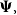
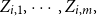
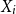
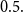
Exactly solvable urn models under random replacement schemes and their applications
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 14 February 2023, pp. 835-854
- Print publication:
- September 2023
-
- Article
- Export citation
A negative binomial approximation in group testing
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 4 / October 2023
- Published online by Cambridge University Press:
- 28 October 2022, pp. 973-996
-
- Article
- Export citation
Multivariate Poisson and Poisson process approximations with applications to Bernoulli sums and
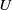 $U$
-statistics
$U$
-statistics
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 1 / March 2023
- Published online by Cambridge University Press:
- 30 September 2022, pp. 223-240
- Print publication:
- March 2023
-
- Article
- Export citation
-
This article derives quantitative limit theorems for multivariate Poisson and Poisson process approximations. Employing the solution of the Stein equation for Poisson random variables, we obtain an explicit bound for the multivariate Poisson approximation of random vectors in the Wasserstein distance. The bound is then utilized in the context of point processes to provide a Poisson process approximation result in terms of a new metric called
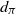 $d_\pi$
, stronger than the total variation distance, defined as the supremum over all Wasserstein distances between random vectors obtained by evaluating the point processes on arbitrary collections of disjoint sets. As applications, the multivariate Poisson approximation of the sum of m-dependent Bernoulli random vectors, the Poisson process approximation of point processes of U-statistic structure, and the Poisson process approximation of point processes with Papangelou intensity are considered. Our bounds in
$d_\pi$
, stronger than the total variation distance, defined as the supremum over all Wasserstein distances between random vectors obtained by evaluating the point processes on arbitrary collections of disjoint sets. As applications, the multivariate Poisson approximation of the sum of m-dependent Bernoulli random vectors, the Poisson process approximation of point processes of U-statistic structure, and the Poisson process approximation of point processes with Papangelou intensity are considered. Our bounds in
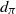 $d_\pi$
are as good as those already available in the literature.
$d_\pi$
are as good as those already available in the literature.
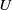
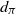
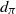
Bounds for the chi-square approximation of the power divergence family of statistics
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 09 August 2022, pp. 1059-1080
- Print publication:
- December 2022
-
- Article
- Export citation
-
It is well known that each statistic in the family of power divergence statistics, across n trials and r classifications with index parameter
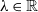 $\lambda\in\mathbb{R}$
(the Pearson, likelihood ratio, and Freeman–Tukey statistics correspond to
$\lambda\in\mathbb{R}$
(the Pearson, likelihood ratio, and Freeman–Tukey statistics correspond to 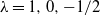 $\lambda=1,0,-1/2$
, respectively), is asymptotically chi-square distributed as the sample size tends to infinity. We obtain explicit bounds on this distributional approximation, measured using smooth test functions, that hold for a given finite sample n, and all index parameters (
$\lambda=1,0,-1/2$
, respectively), is asymptotically chi-square distributed as the sample size tends to infinity. We obtain explicit bounds on this distributional approximation, measured using smooth test functions, that hold for a given finite sample n, and all index parameters (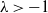 $\lambda>-1$
) for which such finite-sample bounds are meaningful. We obtain bounds that are of the optimal order
$\lambda>-1$
) for which such finite-sample bounds are meaningful. We obtain bounds that are of the optimal order 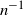 $n^{-1}$
. The dependence of our bounds on the index parameter
$n^{-1}$
. The dependence of our bounds on the index parameter 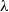 $\lambda$
and the cell classification probabilities is also optimal, and the dependence on the number of cells is also respectable. Our bounds generalise, complement, and improve on recent results from the literature.
$\lambda$
and the cell classification probabilities is also optimal, and the dependence on the number of cells is also respectable. Our bounds generalise, complement, and improve on recent results from the literature.
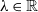
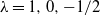
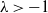
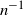
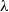
Community detection and percolation of information in a geometric setting
- Part of
-
- Journal:
- Combinatorics, Probability and Computing / Volume 31 / Issue 6 / November 2022
- Published online by Cambridge University Press:
- 31 May 2022, pp. 1048-1069
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
ELECTRICAL IMPEDANCE TOMOGRAPHY USING NONCONFORMING MESH AND POSTERIOR APPROXIMATED REGRESSION
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 105 / Issue 3 / June 2022
- Published online by Cambridge University Press:
- 03 March 2022, pp. 520-522
- Print publication:
- June 2022
-
- Article
-
- You have access
- HTML
- Export citation
On reconsidering entropies and divergences and their cumulative counterparts: Csiszár's, DPD's and Fisher's type cumulative and survival measures
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 37 / Issue 1 / January 2023
- Published online by Cambridge University Press:
- 21 February 2022, pp. 294-321
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
How a probabilistic analogue of the mean value theorem yields stein-type covariance identities
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 2 / June 2022
- Published online by Cambridge University Press:
- 18 January 2022, pp. 350-365
- Print publication:
- June 2022
-
- Article
- Export citation
A generalised Dickman distribution and the number of species in a negative binomial process model
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 53 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 01 July 2021, pp. 370-399
- Print publication:
- June 2021
-
- Article
- Export citation
-
We derive the large-sample distribution of the number of species in a version of Kingman’s Poisson–Dirichlet model constructed from an
 $\alpha$
-stable subordinator but with an underlying negative binomial process instead of a Poisson process. Thus it depends on parameters
$\alpha$
-stable subordinator but with an underlying negative binomial process instead of a Poisson process. Thus it depends on parameters 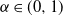 $\alpha\in (0,1)$
from the subordinator and
$\alpha\in (0,1)$
from the subordinator and 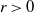 $r>0$
from the negative binomial process. The large-sample distribution of the number of species is derived as sample size
$r>0$
from the negative binomial process. The large-sample distribution of the number of species is derived as sample size 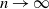 $n\to\infty$
. An important component in the derivation is the introduction of a two-parameter version of the Dickman distribution, generalising the existing one-parameter version. Our analysis adds to the range of Poisson–Dirichlet-related distributions available for modeling purposes.
$n\to\infty$
. An important component in the derivation is the introduction of a two-parameter version of the Dickman distribution, generalising the existing one-parameter version. Our analysis adds to the range of Poisson–Dirichlet-related distributions available for modeling purposes.

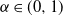
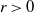
Exact simulation of Ornstein–Uhlenbeck tempered stable processes
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 23 June 2021, pp. 347-371
- Print publication:
- June 2021
-
- Article
- Export citation
Normal approximation for mixtures of normal distributions and the evolution of phenotypic traits
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 53 / Issue 1 / March 2021
- Published online by Cambridge University Press:
- 17 March 2021, pp. 162-188
- Print publication:
- March 2021
-
- Article
- Export citation
-
Explicit bounds are given for the Kolmogorov and Wasserstein distances between a mixture of normal distributions, by which we mean that the conditional distribution given some
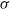 $\sigma$
-algebra is normal, and a normal distribution with properly chosen parameter values. The bounds depend only on the first two moments of the first two conditional moments given the
$\sigma$
-algebra is normal, and a normal distribution with properly chosen parameter values. The bounds depend only on the first two moments of the first two conditional moments given the 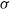 $\sigma$
-algebra. The proof is based on Stein’s method. As an application, we consider the Yule–Ornstein–Uhlenbeck model, used in the field of phylogenetic comparative methods. We obtain bounds for both distances between the distribution of the average value of a phenotypic trait over n related species, and a normal distribution. The bounds imply and extend earlier limit theorems by Bartoszek and Sagitov.
$\sigma$
-algebra. The proof is based on Stein’s method. As an application, we consider the Yule–Ornstein–Uhlenbeck model, used in the field of phylogenetic comparative methods. We obtain bounds for both distances between the distribution of the average value of a phenotypic trait over n related species, and a normal distribution. The bounds imply and extend earlier limit theorems by Bartoszek and Sagitov.
Asymptotic normality in t-stack sortable permutations
- Part of
-
- Journal:
- Proceedings of the Edinburgh Mathematical Society / Volume 63 / Issue 4 / November 2020
- Published online by Cambridge University Press:
- 04 November 2020, pp. 1062-1070
-
- Article
- Export citation
Explicit results on conditional distributions of generalized exponential mixtures
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 57 / Issue 3 / September 2020
- Published online by Cambridge University Press:
- 04 September 2020, pp. 760-774
- Print publication:
- September 2020
-
- Article
- Export citation
-
For independent exponentially distributed random variables
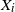 $X_i$
,
$X_i$
, 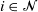 $i\in {\mathcal{N}}$
, with distinct rates
$i\in {\mathcal{N}}$
, with distinct rates 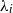 ${\lambda}_i$
we consider sums
${\lambda}_i$
we consider sums 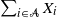 $\sum_{i\in\mathcal{A}} X_i$
for
$\sum_{i\in\mathcal{A}} X_i$
for 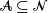 $\mathcal{A}\subseteq {\mathcal{N}}$
which follow generalized exponential mixture distributions. We provide novel explicit results on the conditional distribution of the total sum
$\mathcal{A}\subseteq {\mathcal{N}}$
which follow generalized exponential mixture distributions. We provide novel explicit results on the conditional distribution of the total sum 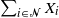 $\sum_{i\in {\mathcal{N}}}X_i$
given that a subset sum
$\sum_{i\in {\mathcal{N}}}X_i$
given that a subset sum 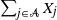 $\sum_{j\in \mathcal{A}}X_j$
exceeds a certain threshold value
$\sum_{j\in \mathcal{A}}X_j$
exceeds a certain threshold value 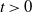 $t>0$
, and vice versa. Moreover, we investigate the characteristic tail behavior of these conditional distributions for
$t>0$
, and vice versa. Moreover, we investigate the characteristic tail behavior of these conditional distributions for 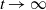 $t\to\infty$
. Finally, we illustrate how our probabilistic results can be applied in practice by providing examples from both reliability theory and risk management.
$t\to\infty$
. Finally, we illustrate how our probabilistic results can be applied in practice by providing examples from both reliability theory and risk management.
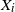
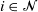
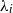
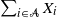
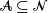
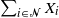
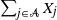
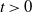
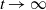
Explicit asymptotics on first passage times of diffusion processes
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 52 / Issue 2 / June 2020
- Published online by Cambridge University Press:
- 15 July 2020, pp. 681-704
- Print publication:
- June 2020
-
- Article
- Export citation
