A key objective for upcoming surveys, and when re-analysing archival data, is the identification of variable stellar sources. However, the selection of these sources is often complicated by the unavailability of light curve data. Utilising a self-organising map (SOM), we demonstrate the selection of diverse variable source types from a catalogue of variable and non-variable SDSS Stripe 82 sources whilst employing only the median 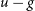 $u-g$,
$u-g$, 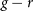 $g-r$,
$g-r$, 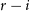 $r-i$, and
$r-i$, and 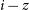 $i-z$ photometric colours for each source as input, without using source magnitudes. This includes the separation of main sequence variable stars that are otherwise degenerate with non-variable sources (
$i-z$ photometric colours for each source as input, without using source magnitudes. This includes the separation of main sequence variable stars that are otherwise degenerate with non-variable sources (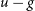 $u-g$,
$u-g$,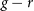 $g-r$) and (
$g-r$) and (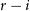 $r-i$,
$r-i$,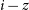 $i-z$) colour-spaces. We separate variable sources on the main sequence from all other variable and non-variable sources with a purity of
$i-z$) colour-spaces. We separate variable sources on the main sequence from all other variable and non-variable sources with a purity of  $80.0\%$ and completeness of
$80.0\%$ and completeness of 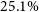 $25.1\%$, figures which can be modified depending on the application. We also explore the varying ability of the same method to simultaneously select other types of variable sources from the heterogeneous sample, including variable quasars and RR-Lyrae stars. The demonstrated ability of this method to select variable main sequence stars in colour-space holds promise for application in future survey reduction pipelines and for the analysis of archival data, where light curves may not be available or may be prohibitively expensive to obtain.
$25.1\%$, figures which can be modified depending on the application. We also explore the varying ability of the same method to simultaneously select other types of variable sources from the heterogeneous sample, including variable quasars and RR-Lyrae stars. The demonstrated ability of this method to select variable main sequence stars in colour-space holds promise for application in future survey reduction pipelines and for the analysis of archival data, where light curves may not be available or may be prohibitively expensive to obtain.

The Australian SKA Pathfinder (ASKAP) has surveyed the sky at multiple frequencies as part of the Rapid ASKAP Continuum Survey (RACS). The first two RACS observing epochs, at 887.5 (RACS-low) and 1 367.5 (RACS-mid) MHz, have been released (McConnell, et al. 2020, PASA, 37, e048; Duchesne, et al. 2023, PASA, 40, e034). A catalogue of radio sources from RACS-low has also been released, covering the sky south of declination 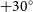 $+30^{\circ}$ (Hale, et al., 2021, PASA, 38, e058). With this paper, we describe and release the first set of catalogues from RACS-mid, covering the sky below declination
$+30^{\circ}$ (Hale, et al., 2021, PASA, 38, e058). With this paper, we describe and release the first set of catalogues from RACS-mid, covering the sky below declination 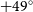 $+49^{\circ}$. The catalogues are created in a similar manner to the RACS-low catalogue, and we discuss this process and highlight additional changes. The general purpose primary catalogue covering 36 200 deg
$+49^{\circ}$. The catalogues are created in a similar manner to the RACS-low catalogue, and we discuss this process and highlight additional changes. The general purpose primary catalogue covering 36 200 deg $^2$ features a variable angular resolution to maximise sensitivity and sky coverage across the catalogued area, with a median angular resolution of
$^2$ features a variable angular resolution to maximise sensitivity and sky coverage across the catalogued area, with a median angular resolution of 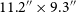 $11.2^{\prime\prime} \times 9.3^{\prime\prime}$. The primary catalogue comprises 3 105 668 radio sources, including those in the Galactic Plane (2 861 923 excluding Galactic latitudes of
$11.2^{\prime\prime} \times 9.3^{\prime\prime}$. The primary catalogue comprises 3 105 668 radio sources, including those in the Galactic Plane (2 861 923 excluding Galactic latitudes of 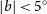 $|b|<5^{\circ}$), and we estimate the catalogue to be 95% complete for sources above 2 mJy. With the primary catalogue, we also provide two auxiliary catalogues. The first is a fixed-resolution, 25-arcsec catalogue approximately matching the sky coverage of the RACS-low catalogue. This 25-arcsec catalogue is constructed identically to the primary catalogue, except images are convolved to a less-sensitive 25-arcsec angular resolution. The second auxiliary catalogue is designed for time-domain science and is the concatenation of source lists from the original RACS-mid images with no additional convolution, mosaicking, or de-duplication of source entries to avoid losing time-variable signals. All three RACS-mid catalogues, and all RACS data products, are available through the CSIRO ASKAP Science Data Archive (https://research.csiro.au/casda/).
$|b|<5^{\circ}$), and we estimate the catalogue to be 95% complete for sources above 2 mJy. With the primary catalogue, we also provide two auxiliary catalogues. The first is a fixed-resolution, 25-arcsec catalogue approximately matching the sky coverage of the RACS-low catalogue. This 25-arcsec catalogue is constructed identically to the primary catalogue, except images are convolved to a less-sensitive 25-arcsec angular resolution. The second auxiliary catalogue is designed for time-domain science and is the concatenation of source lists from the original RACS-mid images with no additional convolution, mosaicking, or de-duplication of source entries to avoid losing time-variable signals. All three RACS-mid catalogues, and all RACS data products, are available through the CSIRO ASKAP Science Data Archive (https://research.csiro.au/casda/).
We present observations of the Mopra carbon monoxide (CO) survey of the Southern Galactic Plane, covering Galactic longitudes spanning 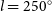 $l = 250^{\circ}$ (
$l = 250^{\circ}$ (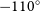 $-110^{\circ}$) to
$-110^{\circ}$) to 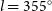 $l = 355^{\circ}$ (
$l = 355^{\circ}$ (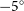 $-5^{\circ}$), with a latitudinal coverage of at least
$-5^{\circ}$), with a latitudinal coverage of at least 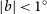 $|b|<1^\circ$, totalling an area of
$|b|<1^\circ$, totalling an area of 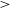 $>$210 deg
$>$210 deg $^{2}$. These data have been taken at 0.6 arcmin spatial resolution and 0.1 km s
$^{2}$. These data have been taken at 0.6 arcmin spatial resolution and 0.1 km s $^{-1}$ spectral resolution, providing an unprecedented view of the molecular gas clouds of the Southern Galactic Plane in the 109–115 GHz
$^{-1}$ spectral resolution, providing an unprecedented view of the molecular gas clouds of the Southern Galactic Plane in the 109–115 GHz 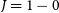 $J = 1-0$ transitions of
$J = 1-0$ transitions of  $^{12}$CO,
$^{12}$CO,  $^{13}$CO, C
$^{13}$CO, C $^{18}$O, and C
$^{18}$O, and C $^{17}$O.
$^{17}$O.
The Australian SKA Pathfinder (ASKAP) is being used to undertake a campaign to rapidly survey the sky in three frequency bands across its operational spectral range. The first pass of the Rapid ASKAP Continuum Survey (RACS) at 887.5 MHz in the low band has already been completed, with images, visibility datasets, and catalogues made available to the wider astronomical community through the CSIRO ASKAP Science Data Archive (CASDA). This work presents details of the second observing pass in the mid band at 1367.5 MHz, RACS-mid, and associated data release comprising images and visibility datasets covering the whole sky south of 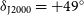 $\delta_{\text{J2000}}=+49^\circ$. This data release incorporates selective peeling to reduce artefacts around bright sources, as well as accurately modelled primary beam responses. The Stokes I images reach a median noise of 198
$\delta_{\text{J2000}}=+49^\circ$. This data release incorporates selective peeling to reduce artefacts around bright sources, as well as accurately modelled primary beam responses. The Stokes I images reach a median noise of 198 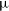 $\mu$Jy PSF
$\mu$Jy PSF $^{-1}$ with a declination-dependent angular resolution of 8.1–47.5 arcsec that fills a niche in the existing ecosystem of large-area astronomical surveys. We also supply Stokes V images after application of a widefield leakage correction, with a median noise of 165
$^{-1}$ with a declination-dependent angular resolution of 8.1–47.5 arcsec that fills a niche in the existing ecosystem of large-area astronomical surveys. We also supply Stokes V images after application of a widefield leakage correction, with a median noise of 165 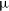 $\mu$Jy PSF
$\mu$Jy PSF $^{-1}$. We find the residual leakage of Stokes I into V to be
$^{-1}$. We find the residual leakage of Stokes I into V to be 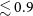 $\lesssim 0.9$–
$\lesssim 0.9$–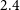 $2.4$% over the survey. This initial RACS-mid data release will be complemented by a future release comprising catalogues of the survey region. As with other RACS data releases, data products from this release will be made available through CASDA.
$2.4$% over the survey. This initial RACS-mid data release will be complemented by a future release comprising catalogues of the survey region. As with other RACS data releases, data products from this release will be made available through CASDA.
We present a systematic search for radio counterparts of novae using the Australian Square Kilometer Array Pathfinder (ASKAP). Our search used the Rapid ASKAP Continuum Survey, which covered the entire sky south of declination 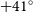 $+41^{\circ}$ (
$+41^{\circ}$ (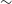 $\sim$
$\sim$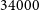 $34000$ square degrees) at a central frequency of 887.5 MHz, the Variables and Slow Transients Pilot Survey, which covered
$34000$ square degrees) at a central frequency of 887.5 MHz, the Variables and Slow Transients Pilot Survey, which covered  $\sim$
$\sim$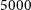 $5000$ square degrees per epoch (887.5 MHz), and other ASKAP pilot surveys, which covered
$5000$ square degrees per epoch (887.5 MHz), and other ASKAP pilot surveys, which covered  $\sim$200–2000 square degrees with 2–12 h integration times. We crossmatched radio sources found in these surveys over a two–year period, from 2019 April to 2021 August, with 440 previously identified optical novae, and found radio counterparts for four novae: V5668 Sgr, V1369 Cen, YZ Ret, and RR Tel. Follow-up observations with the Australian Telescope Compact Array confirm the ejecta thinning across all observed bands with spectral analysis indicative of synchrotron emission in V1369 Cen and YZ Ret. Our light-curve fit with the Hubble Flow model yields a value of
$\sim$200–2000 square degrees with 2–12 h integration times. We crossmatched radio sources found in these surveys over a two–year period, from 2019 April to 2021 August, with 440 previously identified optical novae, and found radio counterparts for four novae: V5668 Sgr, V1369 Cen, YZ Ret, and RR Tel. Follow-up observations with the Australian Telescope Compact Array confirm the ejecta thinning across all observed bands with spectral analysis indicative of synchrotron emission in V1369 Cen and YZ Ret. Our light-curve fit with the Hubble Flow model yields a value of 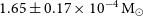 $1.65\pm 0.17 \times 10^{-4} \rm \:M_\odot$ for the mass ejected in V1369 Cen. We also derive a peak surface brightness temperature of
$1.65\pm 0.17 \times 10^{-4} \rm \:M_\odot$ for the mass ejected in V1369 Cen. We also derive a peak surface brightness temperature of 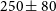 $250\pm80$ K for YZ Ret. Using Hubble Flow model simulated radio lightcurves for novae, we demonstrate that with a 5
$250\pm80$ K for YZ Ret. Using Hubble Flow model simulated radio lightcurves for novae, we demonstrate that with a 5 $\sigma$ sensitivity limit of 1.5 mJy in 15-min survey observations, we can detect radio emission up to a distance of 4 kpc if ejecta mass is in the range
$\sigma$ sensitivity limit of 1.5 mJy in 15-min survey observations, we can detect radio emission up to a distance of 4 kpc if ejecta mass is in the range 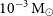 $10^{-3}\rm \:M_\odot$, and upto 1 kpc if ejecta mass is in the range
$10^{-3}\rm \:M_\odot$, and upto 1 kpc if ejecta mass is in the range 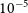 $10^{-5}$–
$10^{-5}$–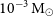 $10^{-3}\rm \:M_\odot$. Our study highlights ASKAP’s ability to contribute to future radio observations for novae within a distance of 1 kpc hosted on white dwarfs with masses
$10^{-3}\rm \:M_\odot$. Our study highlights ASKAP’s ability to contribute to future radio observations for novae within a distance of 1 kpc hosted on white dwarfs with masses 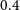 $0.4$–
$0.4$–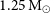 $1.25\:\rm M_\odot$, and within a distance of 4 kpc hosted on white dwarfs with masses
$1.25\:\rm M_\odot$, and within a distance of 4 kpc hosted on white dwarfs with masses 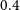 $0.4$–
$0.4$–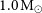 $1.0\:\rm M_\odot$.
$1.0\:\rm M_\odot$.

