
38 results
NOTES ON SACKS’ SPLITTING THEOREM
- Part of
-
- Journal:
- The Journal of Symbolic Logic , First View
- Published online by Cambridge University Press:
- 26 October 2023, pp. 1-30
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We explore the complexity of Sacks’ Splitting Theorem in terms of the mind change functions associated with the members of the splits. We prove that, for any c.e. set A, there are low computably enumerable sets
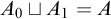 $A_0\sqcup A_1=A$ splitting A with
$A_0\sqcup A_1=A$ splitting A with 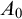 $A_0$ and
$A_0$ and 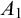 $A_1$ both totally
$A_1$ both totally 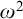 $\omega ^2$-c.a. in terms of the Downey–Greenberg hierarchy, and this result cannot be improved to totally
$\omega ^2$-c.a. in terms of the Downey–Greenberg hierarchy, and this result cannot be improved to totally 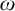 $\omega $-c.a. as shown in [9]. We also show that if cone avoidance is added then there is no level below
$\omega $-c.a. as shown in [9]. We also show that if cone avoidance is added then there is no level below 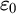 $\varepsilon _0$ which can be used to characterize the complexity of
$\varepsilon _0$ which can be used to characterize the complexity of  $A_1$ and
$A_1$ and 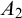 $A_2$.
$A_2$.
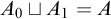
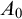
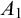
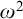
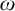
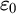

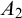
ON THE C.E. DEGREES REALIZABLE IN
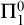 $\Pi ^0_1$ CLASSES
$\Pi ^0_1$ CLASSES
- Part of
-
- Journal:
- The Journal of Symbolic Logic , First View
- Published online by Cambridge University Press:
- 24 April 2023, pp. 1-26
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We study for each computably bounded
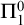 $\Pi ^0_1$ class P the set of degrees of c.e. paths in P. We show, amongst other results, that for every c.e. degree a there is a perfect
$\Pi ^0_1$ class P the set of degrees of c.e. paths in P. We show, amongst other results, that for every c.e. degree a there is a perfect 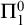 $\Pi ^0_1$ class where all c.e. members have degree a. We also show that every
$\Pi ^0_1$ class where all c.e. members have degree a. We also show that every 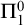 $\Pi ^0_1$ set of c.e. indices is realized in some perfect
$\Pi ^0_1$ set of c.e. indices is realized in some perfect 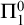 $\Pi ^0_1$ class, and classify the sets of c.e. degrees which can be realized in some
$\Pi ^0_1$ class, and classify the sets of c.e. degrees which can be realized in some 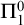 $\Pi ^0_1$ class as exactly those with a computable representation.
$\Pi ^0_1$ class as exactly those with a computable representation.
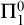
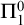
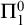
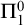
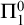
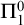
A MINIMAL SET LOW FOR SPEED
- Part of
-
- Journal:
- The Journal of Symbolic Logic / Volume 87 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 03 January 2022, pp. 1693-1728
- Print publication:
- December 2022
-
- Article
- Export citation
-
An oracle A is low-for-speed if it is unable to speed up the computation of a set which is already computable: if a decidable language can be decided in time
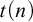 $t(n)$
using A as an oracle, then it can be decided without an oracle in time
$t(n)$
using A as an oracle, then it can be decided without an oracle in time 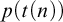 $p(t(n))$
for some polynomial p. The existence of a set which is low-for-speed was first shown by Bayer and Slaman who constructed a non-computable computably enumerable set which is low-for-speed. In this paper we answer a question previously raised by Bienvenu and Downey, who asked whether there is a minimal degree which is low-for-speed. The standard method of constructing a set of minimal degree via forcing is incompatible with making the set low-for-speed; but we are able to use an interesting new combination of forcing and full approximation to construct a set which is both of minimal degree and low-for-speed.
$p(t(n))$
for some polynomial p. The existence of a set which is low-for-speed was first shown by Bayer and Slaman who constructed a non-computable computably enumerable set which is low-for-speed. In this paper we answer a question previously raised by Bienvenu and Downey, who asked whether there is a minimal degree which is low-for-speed. The standard method of constructing a set of minimal degree via forcing is incompatible with making the set low-for-speed; but we are able to use an interesting new combination of forcing and full approximation to construct a set which is both of minimal degree and low-for-speed.
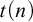
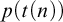
ON SUPERSETS OF NON-LOW
 $_2$
SETS
$_2$
SETS
- Part of
-
- Journal:
- The Journal of Symbolic Logic / Volume 86 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 13 September 2021, pp. 1282-1292
- Print publication:
- September 2021
-
- Article
- Export citation
-
We solve a longstanding question of Soare by showing that if
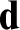 ${\mathbf d}$
is a non-low
${\mathbf d}$
is a non-low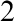 $_2$
computably enumerable degree then
$_2$
computably enumerable degree then 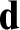 ${\mathbf d}$
contains a c.e. set with no r-maximal c.e. superset.
${\mathbf d}$
contains a c.e. set with no r-maximal c.e. superset.
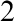
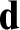
PUNCTUAL CATEGORICITY AND UNIVERSALITY
- Part of
-
- Journal:
- The Journal of Symbolic Logic / Volume 85 / Issue 4 / December 2020
- Published online by Cambridge University Press:
- 22 October 2020, pp. 1427-1466
- Print publication:
- December 2020
-
- Article
- Export citation
-
We describe punctual categoricity in several natural classes, including binary relational structures and mono-unary functional structures. We prove that every punctually categorical structure in a finite unary language is
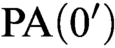 ${\text {PA}}(0')$-categorical, and we show that this upper bound is tight. We also construct an example of a punctually categorical structure whose degree of categoricity is
${\text {PA}}(0')$-categorical, and we show that this upper bound is tight. We also construct an example of a punctually categorical structure whose degree of categoricity is 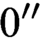 $0''$. We also prove that, with a bit of work, the latter result can be pushed beyond
$0''$. We also prove that, with a bit of work, the latter result can be pushed beyond 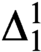 $\Delta ^1_1$, thus showing that punctually categorical structures can possess arbitrarily complex automorphism orbits.
$\Delta ^1_1$, thus showing that punctually categorical structures can possess arbitrarily complex automorphism orbits.As a consequence, it follows that binary relational structures and unary structures are not universal with respect to primitive recursive interpretations; equivalently, in these classes every rich enough interpretation technique must necessarily involve unbounded existential quantification or infinite disjunction. In contrast, it is well-known that both classes are universal for Turing computability.
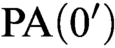
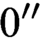
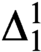
RELATIONSHIPS BETWEEN COMPUTABILITY-THEORETIC PROPERTIES OF PROBLEMS
- Part of
-
- Journal:
- The Journal of Symbolic Logic / Volume 87 / Issue 1 / March 2022
- Published online by Cambridge University Press:
- 05 October 2020, pp. 47-71
- Print publication:
- March 2022
-
- Article
- Export citation
-
A problem is a multivalued function from a set of instances to a set of solutions. We consider only instances and solutions coded by sets of integers. A problem admits preservation of some computability-theoretic weakness property if every computable instance of the problem admits a solution relative to which the property holds. For example, cone avoidance is the ability, given a noncomputable set A and a computable instance of a problem
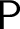 ${\mathsf {P}}$
, to find a solution relative to which A is still noncomputable.
${\mathsf {P}}$
, to find a solution relative to which A is still noncomputable.In this article, we compare relativized versions of computability-theoretic notions of preservation which have been studied in reverse mathematics, and prove that the ones which were not already separated by natural statements in the literature actually coincide. In particular, we prove that it is equivalent to admit avoidance of one cone, of
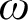 $\omega $
cones, of one hyperimmunity or of one non-
$\omega $
cones, of one hyperimmunity or of one non-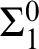 $\Sigma ^{0}_1$
definition. We also prove that the hierarchies of preservation of hyperimmunity and non-
$\Sigma ^{0}_1$
definition. We also prove that the hierarchies of preservation of hyperimmunity and non-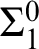 $\Sigma ^{0}_1$
definitions coincide. On the other hand, none of these notions coincide in a nonrelativized setting.
$\Sigma ^{0}_1$
definitions coincide. On the other hand, none of these notions coincide in a nonrelativized setting.
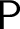
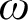
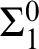
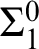
FOUNDATIONS OF ONLINE STRUCTURE THEORY
-
- Journal:
- Bulletin of Symbolic Logic / Volume 25 / Issue 2 / June 2019
- Published online by Cambridge University Press:
- 15 April 2019, pp. 141-181
- Print publication:
- June 2019
-
- Article
- Export citation
AVOIDING EFFECTIVE PACKING DIMENSION 1 BELOW ARRAY NONCOMPUTABLE C.E. DEGREES
-
- Journal:
- The Journal of Symbolic Logic / Volume 83 / Issue 2 / June 2018
- Published online by Cambridge University Press:
- 01 August 2018, pp. 717-739
- Print publication:
- June 2018
-
- Article
- Export citation
A HIERARCHY OF COMPUTABLY ENUMERABLE DEGREES
-
- Journal:
- Bulletin of Symbolic Logic / Volume 24 / Issue 1 / March 2018
- Published online by Cambridge University Press:
- 26 April 2018, pp. 53-89
- Print publication:
- March 2018
-
- Article
- Export citation
-
We introduce a new hierarchy of computably enumerable degrees. This hierarchy is based on computable ordinal notations measuring complexity of approximation of
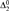 ${\rm{\Delta }}_2^0$ functions. The hierarchy unifies and classifies the combinatorics of a number of diverse constructions in computability theory. It does so along the lines of the high degrees (Martin) and the array noncomputable degrees (Downey, Jockusch, and Stob). The hierarchy also gives a number of natural definability results in the c.e. degrees, including a definable antichain.
${\rm{\Delta }}_2^0$ functions. The hierarchy unifies and classifies the combinatorics of a number of diverse constructions in computability theory. It does so along the lines of the high degrees (Martin) and the array noncomputable degrees (Downey, Jockusch, and Stob). The hierarchy also gives a number of natural definability results in the c.e. degrees, including a definable antichain.
The finite intersection principle and genericity
-
- Journal:
- Mathematical Proceedings of the Cambridge Philosophical Society / Volume 160 / Issue 2 / March 2016
- Published online by Cambridge University Press:
- 26 November 2015, pp. 279-297
- Print publication:
- March 2016
-
- Article
- Export citation
EXACT PAIRS FOR THE IDEAL OF THE K-TRIVIAL SEQUENCES IN THE TURING DEGREES
-
- Journal:
- The Journal of Symbolic Logic / Volume 79 / Issue 3 / September 2014
- Published online by Cambridge University Press:
- 18 August 2014, pp. 676-692
- Print publication:
- September 2014
-
- Article
- Export citation
CHARACTERIZING LOWNESS FOR DEMUTH RANDOMNESS
-
- Journal:
- The Journal of Symbolic Logic / Volume 79 / Issue 2 / June 2014
- Published online by Cambridge University Press:
- 25 June 2014, pp. 526-560
- Print publication:
- June 2014
-
- Article
- Export citation
Turing's legacy: developments from Turing's ideas in logic
-
-
- Book:
- Turing's Legacy
- Published online:
- 05 June 2014
- Print publication:
- 01 May 2014, pp vii-x
-
- Chapter
- Export citation
Frontmatter
-
- Book:
- Turing's Legacy
- Published online:
- 05 June 2014
- Print publication:
- 01 May 2014, pp i-iv
-
- Chapter
- Export citation

Turing's Legacy
- Developments from Turing's Ideas in Logic
-
- Published online:
- 05 June 2014
- Print publication:
- 01 May 2014
Computability theory, algorithmic randomness and Turing's anticipation
-
-
- Book:
- Turing's Legacy
- Published online:
- 05 June 2014
- Print publication:
- 01 May 2014, pp 90-123
-
- Chapter
- Export citation
Contents
-
- Book:
- Turing's Legacy
- Published online:
- 05 June 2014
- Print publication:
- 01 May 2014, pp v-vi
-
- Chapter
- Export citation
Twelfth Asian Logic Conference, Victoria University of Wellington, Wellington, New Zealand, December 15–20, 2011
-
- Journal:
- Bulletin of Symbolic Logic / Volume 19 / Issue 2 / June 2013
- Published online by Cambridge University Press:
- 05 September 2014, pp. 257-283
- Print publication:
- June 2013
-
- Article
- Export citation
Limits on jump inversion for strong reducibilities
-
- Journal:
- The Journal of Symbolic Logic / Volume 76 / Issue 4 / December 2011
- Published online by Cambridge University Press:
- 12 March 2014, pp. 1287-1296
- Print publication:
- December 2011
-
- Article
- Export citation
Jump inversions inside effectively closed sets and applications to randomness
-
- Journal:
- The Journal of Symbolic Logic / Volume 76 / Issue 2 / June 2011
- Published online by Cambridge University Press:
- 12 March 2014, pp. 491-518
- Print publication:
- June 2011
-
- Article
- Export citation
-
We study inversions of the jump operator on
 classes, combined with certain basis theorems. These jump inversions have implications for the study of the jump operator on the random degrees—for various notions of randomness. For example, we characterize the jumps of the weakly 2-random sets which are not 2-random, and the jumps of the weakly 1-random relative to 0′ sets which are not 2-random. Both of the classes coincide with the degrees above 0′ which are not 0′-dominated. A further application is the complete solution of [24, Problem 3.6.9]: one direction of van Lambalgen's theorem holds for weak 2-randomness, while the other fails.
classes, combined with certain basis theorems. These jump inversions have implications for the study of the jump operator on the random degrees—for various notions of randomness. For example, we characterize the jumps of the weakly 2-random sets which are not 2-random, and the jumps of the weakly 1-random relative to 0′ sets which are not 2-random. Both of the classes coincide with the degrees above 0′ which are not 0′-dominated. A further application is the complete solution of [24, Problem 3.6.9]: one direction of van Lambalgen's theorem holds for weak 2-randomness, while the other fails.Finally we discuss various techniques for coding information into incomplete randoms. Using these techniques we give a negative answer to [24, Problem 8.2.14]: not all weakly 2-random sets are array computable. In fact, given any oracle X, there is a weakly 2-random which is not array computable relative to X. This contrasts with the fact that all 2-random sets are array computable.
 classes, combined with certain basis theorems. These jump inversions have implications for the study of the jump operator on the random degrees—for various notions of randomness. For example, we characterize the jumps of the weakly 2-random sets which are not 2-random, and the jumps of the weakly 1-random relative to 0′ sets which are not 2-random. Both of the classes coincide with the degrees above 0′ which are not 0′-dominated. A further application is the complete solution of [24, Problem 3.6.9]: one direction of van Lambalgen's theorem holds for weak 2-randomness, while the other fails.
classes, combined with certain basis theorems. These jump inversions have implications for the study of the jump operator on the random degrees—for various notions of randomness. For example, we characterize the jumps of the weakly 2-random sets which are not 2-random, and the jumps of the weakly 1-random relative to 0′ sets which are not 2-random. Both of the classes coincide with the degrees above 0′ which are not 0′-dominated. A further application is the complete solution of [24, Problem 3.6.9]: one direction of van Lambalgen's theorem holds for weak 2-randomness, while the other fails.