
FirstView articles
Contents
Article
Anisotropic span embeddings and the negative impact of higher-order inference for coreference resolution: An empirical analysis
-
- Published online by Cambridge University Press:
- 25 January 2024, pp. 1-22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Automated annotation of parallel bible corpora with cross-lingual semantic concordance
-
- Published online by Cambridge University Press:
- 25 January 2024, pp. 1-24
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
How do control tokens affect natural language generation tasks like text simplification
-
- Published online by Cambridge University Press:
- 23 January 2024, pp. 1-28
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Lightweight transformers for clinical natural language processing
-
- Published online by Cambridge University Press:
- 12 January 2024, pp. 1-28
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Specialised pre-trained language models are becoming more frequent in Natural language Processing (NLP) since they can potentially outperform models trained on generic texts. BioBERT (Sanh et al., Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. arXiv preprint arXiv: 1910.01108, 2019) and BioClinicalBERT (Alsentzer et al., Publicly available clinical bert embeddings. In Proceedings of the 2nd Clinical Natural Language Processing Workshop, pp. 72–78, 2019) are two examples of such models that have shown promise in medical NLP tasks. Many of these models are overparametrised and resource-intensive, but thanks to techniques like knowledge distillation, it is possible to create smaller versions that perform almost as well as their larger counterparts. In this work, we specifically focus on development of compact language models for processing clinical texts (i.e. progress notes, discharge summaries, etc). We developed a number of efficient lightweight clinical transformers using knowledge distillation and continual learning, with the number of parameters ranging from
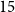 $15$ million to
$15$ million to 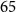 $65$ million. These models performed comparably to larger models such as BioBERT and ClinicalBioBERT and significantly outperformed other compact models trained on general or biomedical data. Our extensive evaluation was done across several standard datasets and covered a wide range of clinical text-mining tasks, including natural language inference, relation extraction, named entity recognition and sequence classification. To our knowledge, this is the first comprehensive study specifically focused on creating efficient and compact transformers for clinical NLP tasks. The models and code used in this study can be found on our Huggingface profile at https://huggingface.co/nlpie and Github page at https://github.com/nlpie-research/Lightweight-Clinical-Transformers, respectively, promoting reproducibility of our results.
$65$ million. These models performed comparably to larger models such as BioBERT and ClinicalBioBERT and significantly outperformed other compact models trained on general or biomedical data. Our extensive evaluation was done across several standard datasets and covered a wide range of clinical text-mining tasks, including natural language inference, relation extraction, named entity recognition and sequence classification. To our knowledge, this is the first comprehensive study specifically focused on creating efficient and compact transformers for clinical NLP tasks. The models and code used in this study can be found on our Huggingface profile at https://huggingface.co/nlpie and Github page at https://github.com/nlpie-research/Lightweight-Clinical-Transformers, respectively, promoting reproducibility of our results.
Actionable conversational quality indicators for improving task-oriented dialog systems
-
- Published online by Cambridge University Press:
- 09 January 2024, pp. 1-26
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Data-to-text generation using conditional generative adversarial with enhanced transformer
-
- Published online by Cambridge University Press:
- 28 November 2023, pp. 1-26
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Neural Arabic singular-to-plural conversion using a pretrained Character-BERT and a fused transformer
-
- Published online by Cambridge University Press:
- 11 October 2023, pp. 1-25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Perceptional and actional enrichment for metaphor detection with sensorimotor norms
-
- Published online by Cambridge University Press:
- 20 September 2023, pp. 1-29
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Improved conversational recommender system based on dialog context
-
- Published online by Cambridge University Press:
- 08 September 2023, pp. 1-19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Improving short text classification with augmented data using GPT-3
-
- Published online by Cambridge University Press:
- 25 August 2023, pp. 1-30
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Creating a large-scale diachronic corpus resource: Automated parsing in the Greek papyri (and beyond)
-
- Published online by Cambridge University Press:
- 15 August 2023, pp. 1-30
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
PGST: A Persian gender style transfer method
-
- Published online by Cambridge University Press:
- 15 August 2023, pp. 1-26
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Toward a shallow discourse parser for Turkish
-
- Published online by Cambridge University Press:
- 11 August 2023, pp. 1-26
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
How you describe procurement calls matters: Predicting outcome of public procurement using call descriptions
-
- Published online by Cambridge University Press:
- 10 August 2023, pp. 1-22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
SSL-GAN-RoBERTa: A robust semi-supervised model for detecting Anti-Asian COVID-19 hate speech on social media
-
- Published online by Cambridge University Press:
- 03 August 2023, pp. 1-20
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Masked transformer through knowledge distillation for unsupervised text style transfer
-
- Published online by Cambridge University Press:
- 25 July 2023, pp. 1-36
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Assessment of the E3C corpus for the recognition of disorders in clinical texts
-
- Published online by Cambridge University Press:
- 18 July 2023, pp. 1-19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Describe the house and I will tell you the price: House price prediction with textual description data
-
- Published online by Cambridge University Press:
- 18 July 2023, pp. 1-35
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
House price prediction is an important problem that could benefit home buyers and sellers. Traditional models for house price prediction use numerical attributes such as the number of rooms but disregard the house description text. The recent developments in text processing suggest these can be valuable attributes, which motivated us to use house descriptions. This paper focuses on the house asking/advertising price and studies the impact of using house description texts to predict the final house price. To achieve this, we collected a large and diverse set of attributes on house postings, including the house advertising price. Then, we compare the performance of three scenarios: using only the house description, only numeric attributes, or both. We processed the description text through three word embedding techniques: TF-IDF, Word2Vec, and BERT. Four regression algorithms are trained using only textual data, non-textual data, or both. Our results show that by using exclusively the description data with Word2Vec and a Deep Learning model, we can achieve good performance. However, the best overall performance is obtained when using both textual and non-textual features. An
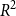 $R^2$ of 0.7904 is achieved by the deep learning model using only description data on the testing data. This clearly indicates that using the house description text alone is a strong predictor for the house price. However, when observing the RMSE on the test data, the best model was gradient boosting using both numeric and description data. Overall, we observe that combining the textual and non-textual features improves the learned model and provides performance benefits when compared against using only one of the feature types. We also provide a freely available application for house price prediction, which is solely based on a house text description and uses our final developed model with Word2Vec and Deep Learning to predict the house price.
$R^2$ of 0.7904 is achieved by the deep learning model using only description data on the testing data. This clearly indicates that using the house description text alone is a strong predictor for the house price. However, when observing the RMSE on the test data, the best model was gradient boosting using both numeric and description data. Overall, we observe that combining the textual and non-textual features improves the learned model and provides performance benefits when compared against using only one of the feature types. We also provide a freely available application for house price prediction, which is solely based on a house text description and uses our final developed model with Word2Vec and Deep Learning to predict the house price.
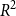
Linguistically aware evaluation of coreference resolution from the perspective of higher-level applications
-
- Published online by Cambridge University Press:
- 19 June 2023, pp. 1-30
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A resampling-based method to evaluate NLI models
-
- Published online by Cambridge University Press:
- 09 June 2023, pp. 1-28
-
- Article
-
- You have access
- Open access
- HTML
- Export citation