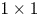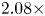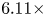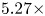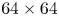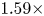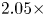Contents
Overview Paper
Subspace learning for facial expression recognition: an overview and a new perspective
-
- Published online by Cambridge University Press:
- 14 January 2021, e1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Original Paper
Laplacian networks: bounding indicator function smoothness for neural networks robustness
-
- Published online by Cambridge University Press:
- 05 February 2021, e2
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Toward community answer selection by jointly static and dynamic user expertise modeling
-
- Published online by Cambridge University Press:
- 01 March 2021, e3
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Industrial Technology Advances
Demystifying data and AI for manufacturing: case studies from a major computer maker
-
- Published online by Cambridge University Press:
- 08 March 2021, e4
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Original Paper
Automatic Deception Detection using Multiple Speech and Language Communicative Descriptors in Dialogs
-
- Published online by Cambridge University Press:
- 16 April 2021, e5
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Speech emotion recognition based on listener-dependent emotion perception models
-
- Published online by Cambridge University Press:
- 20 April 2021, e6
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Audio-to-score singing transcription based on a CRNN-HSMM hybrid model
-
- Published online by Cambridge University Press:
- 20 April 2021, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Selection from ChinaMM 2020
Analyzing public opinion on COVID-19 through different perspectives and stages
-
- Published online by Cambridge University Press:
- 17 March 2021, e8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Industrial Technology Advances
The future of biometrics technology: from face recognition to related applications
-
- Published online by Cambridge University Press:
- 28 May 2021, e9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Original Paper
A protection method of trained CNN model with a secret key from unauthorized access
-
- Published online by Cambridge University Press:
- 09 July 2021, e10
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Compression efficiency analysis of AV1, VVC, and HEVC for random access applications
-
- Published online by Cambridge University Press:
- 13 July 2021, e11
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
3D skeletal movement-enhanced emotion recognition networks
-
- Published online by Cambridge University Press:
- 05 August 2021, e12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Industrial Technology Advances
Immersive audio, capture, transport, and rendering: a review
-
- Published online by Cambridge University Press:
- 16 September 2021, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Original Paper
Robust deep convolutional neural network against image distortions
-
- Published online by Cambridge University Press:
- 11 October 2021, e14
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Two-stage pyramidal convolutional neural networks for image colorization
-
- Published online by Cambridge University Press:
- 08 October 2021, e15
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Social rhythms measured via social media use for predicting psychiatric symptoms
-
- Published online by Cambridge University Press:
- 28 October 2021, e16
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
TGHop: an explainable, efficient, and lightweight method for texture generation
-
- Published online by Cambridge University Press:
- 27 October 2021, e17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Cross-layer knowledge distillation with KL divergence and offline ensemble for compressing deep neural network
-
- Published online by Cambridge University Press:
- 17 November 2021, e18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Deep neural networks (DNN) have solved many tasks, including image classification, object detection, and semantic segmentation. However, when there are huge parameters and high level of computation associated with a DNN model, it becomes difficult to deploy on mobile devices. To address this difficulty, we propose an efficient compression method that can be split into three parts. First, we propose a cross-layer matrix to extract more features from the teacher's model. Second, we adopt Kullback Leibler (KL) Divergence in an offline environment to make the student model find a wider robust minimum. Finally, we propose the offline ensemble pre-trained teachers to teach a student model. To address dimension mismatch between teacher and student models, we adopt a $1\times 1$
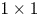 convolution and two-stage knowledge distillation to release this constraint. We conducted experiments with VGG and ResNet models, using the CIFAR-100 dataset. With VGG-11 as the teacher's model and VGG-6 as the student's model, experimental results showed that the Top-1 accuracy increased by 3.57% with a $2.08\times$
convolution and two-stage knowledge distillation to release this constraint. We conducted experiments with VGG and ResNet models, using the CIFAR-100 dataset. With VGG-11 as the teacher's model and VGG-6 as the student's model, experimental results showed that the Top-1 accuracy increased by 3.57% with a $2.08\times$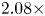 compression rate and 3.5x computation rate. With ResNet-32 as the teacher's model and ResNet-8 as the student's model, experimental results showed that Top-1 accuracy increased by 4.38% with a $6.11\times$
compression rate and 3.5x computation rate. With ResNet-32 as the teacher's model and ResNet-8 as the student's model, experimental results showed that Top-1 accuracy increased by 4.38% with a $6.11\times$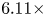 compression rate and $5.27\times$
compression rate and $5.27\times$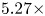 computation rate. In addition, we conducted experiments using the ImageNet$64\times 64$
computation rate. In addition, we conducted experiments using the ImageNet$64\times 64$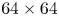 dataset. With MobileNet-16 as the teacher's model and MobileNet-9 as the student's model, experimental results showed that the Top-1 accuracy increased by 3.98% with a $1.59\times$
dataset. With MobileNet-16 as the teacher's model and MobileNet-9 as the student's model, experimental results showed that the Top-1 accuracy increased by 3.98% with a $1.59\times$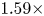 compression rate and $2.05\times$
compression rate and $2.05\times$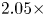 computation rate.
computation rate.