
114 results in 62Fxx
On the dynamic residual measure of inaccuracy based on extropy in order statistics
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences , First View
- Published online by Cambridge University Press:
- 11 January 2024, pp. 1-22
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Trajectory fitting estimation for reflected stochastic linear differential equations of a large signal
- Part of
-
- Journal:
- Journal of Applied Probability , First View
- Published online by Cambridge University Press:
- 31 October 2023, pp. 1-14
-
- Article
- Export citation
BAYESIAN SPATIOTEMPORAL MODELS FOR INFECTIOUS DISEASES IN RELATION TO HEALTH INEQUALITY
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 108 / Issue 3 / December 2023
- Published online by Cambridge University Press:
- 31 August 2023, pp. 516-517
- Print publication:
- December 2023
-
- Article
-
- You have access
- HTML
- Export citation
Extropy: Characterizations and dynamic versions
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 02 June 2023, pp. 1333-1351
- Print publication:
- December 2023
-
- Article
- Export citation
Self-normalized Cramér moderate deviations for a supercritical Galton–Watson process
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 4 / December 2023
- Published online by Cambridge University Press:
- 24 April 2023, pp. 1281-1292
- Print publication:
- December 2023
-
- Article
- Export citation
-
Let
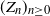 $(Z_n)_{n\geq0}$ be a supercritical Galton–Watson process. Consider the Lotka–Nagaev estimator for the offspring mean. In this paper we establish self-normalized Cramér-type moderate deviations and Berry–Esseen bounds for the Lotka–Nagaev estimator. The results are believed to be optimal or near-optimal.
$(Z_n)_{n\geq0}$ be a supercritical Galton–Watson process. Consider the Lotka–Nagaev estimator for the offspring mean. In this paper we establish self-normalized Cramér-type moderate deviations and Berry–Esseen bounds for the Lotka–Nagaev estimator. The results are believed to be optimal or near-optimal.
On Bayesian credibility mean for finite mixture distributions
- Part of
-
- Journal:
- Annals of Actuarial Science / Volume 18 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 29 March 2023, pp. 5-29
-
- Article
- Export citation
-
Consider the problem of determining the Bayesian credibility mean
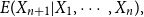 $E(X_{n+1}|X_1,\cdots, X_n),$ whenever the random claims
$E(X_{n+1}|X_1,\cdots, X_n),$ whenever the random claims 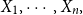 $X_1,\cdots, X_n,$ given parameter vector
$X_1,\cdots, X_n,$ given parameter vector 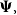 $\boldsymbol{\Psi},$ are sampled from the K-component mixture family of distributions, whose members are the union of different families of distributions. This article begins by deriving a recursive formula for such a Bayesian credibility mean. Moreover, under the assumption that using additional information
$\boldsymbol{\Psi},$ are sampled from the K-component mixture family of distributions, whose members are the union of different families of distributions. This article begins by deriving a recursive formula for such a Bayesian credibility mean. Moreover, under the assumption that using additional information 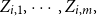 $Z_{i,1},\cdots,Z_{i,m},$ one may probabilistically determine a random claim
$Z_{i,1},\cdots,Z_{i,m},$ one may probabilistically determine a random claim 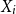 $X_i$ belongs to a given population (or a distribution), the above recursive formula simplifies to an exact Bayesian credibility mean whenever all components of the mixture distribution belong to the exponential families of distributions. For a situation where a 2-component mixture family of distributions is an appropriate choice for data modelling, using the logistic regression model, it shows that: how one may employ such additional information to derive the Bayesian credibility model, say Logistic Regression Credibility model, for a finite mixture of distributions. A comparison between the Logistic Regression Credibility (LRC) model and its competitor, the Regression Tree Credibility (RTC) model, has been given. More precisely, it shows that under the squared error loss function, it shows the LRC’s risk function dominates the RTC’s risk function at least in an interval which about
$X_i$ belongs to a given population (or a distribution), the above recursive formula simplifies to an exact Bayesian credibility mean whenever all components of the mixture distribution belong to the exponential families of distributions. For a situation where a 2-component mixture family of distributions is an appropriate choice for data modelling, using the logistic regression model, it shows that: how one may employ such additional information to derive the Bayesian credibility model, say Logistic Regression Credibility model, for a finite mixture of distributions. A comparison between the Logistic Regression Credibility (LRC) model and its competitor, the Regression Tree Credibility (RTC) model, has been given. More precisely, it shows that under the squared error loss function, it shows the LRC’s risk function dominates the RTC’s risk function at least in an interval which about 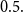 $0.5.$ Several examples have been given to illustrate the practical application of our findings.
$0.5.$ Several examples have been given to illustrate the practical application of our findings.
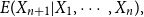
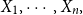
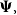
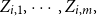
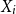
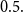
A new measure of inaccuracy for record statistics based on extropy
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 38 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 10 March 2023, pp. 207-225
-
- Article
-
- You have access
- HTML
- Export citation
Robustness of iterated function systems of Lipschitz maps
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 60 / Issue 3 / September 2023
- Published online by Cambridge University Press:
- 28 February 2023, pp. 921-944
- Print publication:
- September 2023
-
- Article
- Export citation
-
Let
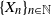 $\{X_n\}_{n\in{\mathbb{N}}}$ be an
$\{X_n\}_{n\in{\mathbb{N}}}$ be an 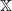 ${\mathbb{X}}$-valued iterated function system (IFS) of Lipschitz maps defined as
${\mathbb{X}}$-valued iterated function system (IFS) of Lipschitz maps defined as 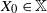 $X_0 \in {\mathbb{X}}$ and for
$X_0 \in {\mathbb{X}}$ and for 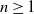 $n\geq 1$,
$n\geq 1$, 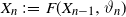 $X_n\;:\!=\;F(X_{n-1},\vartheta_n)$, where
$X_n\;:\!=\;F(X_{n-1},\vartheta_n)$, where 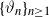 $\{\vartheta_n\}_{n \ge 1}$ are independent and identically distributed random variables with common probability distribution
$\{\vartheta_n\}_{n \ge 1}$ are independent and identically distributed random variables with common probability distribution 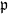 $\mathfrak{p}$,
$\mathfrak{p}$, 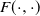 $F(\cdot,\cdot)$ is Lipschitz continuous in the first variable, and
$F(\cdot,\cdot)$ is Lipschitz continuous in the first variable, and 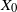 $X_0$ is independent of
$X_0$ is independent of 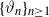 $\{\vartheta_n\}_{n \ge 1}$. Under parametric perturbation of both F and
$\{\vartheta_n\}_{n \ge 1}$. Under parametric perturbation of both F and 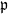 $\mathfrak{p}$, we are interested in the robustness of the V-geometrical ergodicity property of
$\mathfrak{p}$, we are interested in the robustness of the V-geometrical ergodicity property of 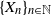 $\{X_n\}_{n\in{\mathbb{N}}}$, of its invariant probability measure, and finally of the probability distribution of
$\{X_n\}_{n\in{\mathbb{N}}}$, of its invariant probability measure, and finally of the probability distribution of 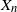 $X_n$. Specifically, we propose a pattern of assumptions for studying such robustness properties for an IFS. This pattern is implemented for the autoregressive processes with autoregressive conditional heteroscedastic errors, and for IFS under roundoff error or under thresholding/truncation. Moreover, we provide a general set of assumptions covering the classical Feller-type hypotheses for an IFS to be a V-geometrical ergodic process. An accurate bound for the rate of convergence is also provided.
$X_n$. Specifically, we propose a pattern of assumptions for studying such robustness properties for an IFS. This pattern is implemented for the autoregressive processes with autoregressive conditional heteroscedastic errors, and for IFS under roundoff error or under thresholding/truncation. Moreover, we provide a general set of assumptions covering the classical Feller-type hypotheses for an IFS to be a V-geometrical ergodic process. An accurate bound for the rate of convergence is also provided.
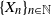
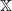
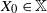
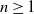
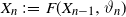
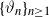
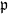
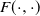
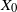
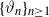
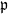
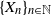
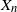
The rescaled Pólya urn: local reinforcement and chi-squared goodness-of-fit test
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 54 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 18 October 2022, pp. 849-879
- Print publication:
- September 2022
-
- Article
- Export citation
Maximum likelihood estimation for tensor normal models via castling transforms
- Part of
-
- Journal:
- Forum of Mathematics, Sigma / Volume 10 / 2022
- Published online by Cambridge University Press:
- 01 July 2022, e50
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Central limit theorem for bifurcating markov chains under L2-ergodic conditions
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 54 / Issue 4 / December 2022
- Published online by Cambridge University Press:
- 15 June 2022, pp. 999-1031
- Print publication:
- December 2022
-
- Article
- Export citation
-
Bifurcating Markov chains (BMCs) are Markov chains indexed by a full binary tree representing the evolution of a trait along a population where each individual has two children. We provide a central limit theorem for additive functionals of BMCs under
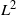 $L^2$
-ergodic conditions with three different regimes. This completes the pointwise approach developed in a previous work. As an application, we study the elementary case of a symmetric bifurcating autoregressive process, which justifies the nontrivial hypothesis considered on the kernel transition of the BMCs. We illustrate in this example the phase transition observed in the fluctuations.
$L^2$
-ergodic conditions with three different regimes. This completes the pointwise approach developed in a previous work. As an application, we study the elementary case of a symmetric bifurcating autoregressive process, which justifies the nontrivial hypothesis considered on the kernel transition of the BMCs. We illustrate in this example the phase transition observed in the fluctuations.
STOCHASTIC MODELLING AND STATISTICAL ANALYSIS OF SPATIAL AND LONG-RANGE DEPENDENT DATA
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 106 / Issue 1 / August 2022
- Published online by Cambridge University Press:
- 10 June 2022, pp. 170-173
- Print publication:
- August 2022
-
- Article
-
- You have access
- HTML
- Export citation
Disorder detection with costly observations
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 59 / Issue 2 / June 2022
- Published online by Cambridge University Press:
- 25 April 2022, pp. 338-349
- Print publication:
- June 2022
-
- Article
- Export citation
ELECTRICAL IMPEDANCE TOMOGRAPHY USING NONCONFORMING MESH AND POSTERIOR APPROXIMATED REGRESSION
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 105 / Issue 3 / June 2022
- Published online by Cambridge University Press:
- 03 March 2022, pp. 520-522
- Print publication:
- June 2022
-
- Article
-
- You have access
- HTML
- Export citation
MODEL-BASED ADAPTIVE MONITORING: IMPROVING THE EFFECTIVENESS OF REEF MONITORING PROGRAMS
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 105 / Issue 3 / June 2022
- Published online by Cambridge University Press:
- 09 February 2022, pp. 511-513
- Print publication:
- June 2022
-
- Article
-
- You have access
- HTML
- Export citation
CONFIDENCE INTERVALS IN GENERAL REGRESSION MODELS THAT UTILISE UNCERTAIN PRIOR INFORMATION
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 105 / Issue 3 / June 2022
- Published online by Cambridge University Press:
- 08 February 2022, pp. 516-517
- Print publication:
- June 2022
-
- Article
-
- You have access
- HTML
- Export citation
MODES OF CONVERGENCE TO THE TRUTH: STEPS TOWARD A BETTER EPISTEMOLOGY OF INDUCTION
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 15 / Issue 2 / June 2022
- Published online by Cambridge University Press:
- 03 January 2022, pp. 277-310
- Print publication:
- June 2022
-
- Article
- Export citation
Gibbs partitions, Riemann–Liouville fractional operators, Mittag–Leffler functions, and fragmentations derived from stable subordinators
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 58 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 23 June 2021, pp. 314-334
- Print publication:
- June 2021
-
- Article
- Export citation
-
Pitman (2003), and subsequently Gnedin and Pitman (2006), showed that a large class of random partitions of the integers derived from a stable subordinator of index
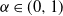 $\alpha\in(0,1)$ have infinite Gibbs (product) structure as a characterizing feature. The most notable case are random partitions derived from the two-parameter Poisson–Dirichlet distribution,
$\alpha\in(0,1)$ have infinite Gibbs (product) structure as a characterizing feature. The most notable case are random partitions derived from the two-parameter Poisson–Dirichlet distribution, 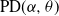 $\textrm{PD}(\alpha,\theta)$, whose corresponding
$\textrm{PD}(\alpha,\theta)$, whose corresponding  $\alpha$-diversity/local time have generalized Mittag–Leffler distributions, denoted by
$\alpha$-diversity/local time have generalized Mittag–Leffler distributions, denoted by 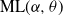 $\textrm{ML}(\alpha,\theta)$. Our aim in this work is to provide indications on the utility of the wider class of Gibbs partitions as it relates to a study of Riemann–Liouville fractional integrals and size-biased sampling, and in decompositions of special functions, and its potential use in the understanding of various constructions of more exotic processes. We provide characterizations of general laws associated with nested families of
$\textrm{ML}(\alpha,\theta)$. Our aim in this work is to provide indications on the utility of the wider class of Gibbs partitions as it relates to a study of Riemann–Liouville fractional integrals and size-biased sampling, and in decompositions of special functions, and its potential use in the understanding of various constructions of more exotic processes. We provide characterizations of general laws associated with nested families of 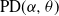 $\textrm{PD}(\alpha,\theta)$ mass partitions that are constructed from fragmentation operations described in Dong et al. (2014). These operations are known to be related in distribution to various constructions of discrete random trees/graphs in [n], and their scaling limits. A centerpiece of our work is results related to Mittag–Leffler functions, which play a key role in fractional calculus and are otherwise Laplace transforms of the
$\textrm{PD}(\alpha,\theta)$ mass partitions that are constructed from fragmentation operations described in Dong et al. (2014). These operations are known to be related in distribution to various constructions of discrete random trees/graphs in [n], and their scaling limits. A centerpiece of our work is results related to Mittag–Leffler functions, which play a key role in fractional calculus and are otherwise Laplace transforms of the 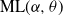 $\textrm{ML}(\alpha,\theta)$ variables. Notably, this leads to an interpretation within the context of
$\textrm{ML}(\alpha,\theta)$ variables. Notably, this leads to an interpretation within the context of 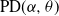 $\textrm{PD}(\alpha,\theta)$ laws conditioned on Poisson point process counts over intervals of scaled lengths of the
$\textrm{PD}(\alpha,\theta)$ laws conditioned on Poisson point process counts over intervals of scaled lengths of the  $\alpha$-diversity.
$\alpha$-diversity.
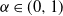
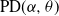

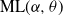
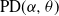
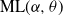
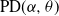

CONTROLLING THE FALSE DISCOVERY RATE THROUGH MULTIPLE COMPETITION
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 104 / Issue 1 / August 2021
- Published online by Cambridge University Press:
- 11 December 2020, pp. 169-170
- Print publication:
- August 2021
-
- Article
-
- You have access
- Export citation
INFLUENCE FUNCTIONS FOR DIMENSION REDUCTION METHODS
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 103 / Issue 3 / June 2021
- Published online by Cambridge University Press:
- 30 October 2020, pp. 517-519
- Print publication:
- June 2021
-
- Article
-
- You have access
- Export citation
