
251 results
Chapter 25 - Modelling in DOHaD
- from Section 6 - Future Directions
-
-
- Book:
- The Handbook of DOHaD and Society
- Print publication:
- 27 June 2024, pp 279-289
-
- Chapter
-
- You have access
- Open access
- HTML
- Export citation
9 - Artificial Intelligence, Big Data, and Public Policy
-
- Book:
- Artificial Intelligence
- Published online:
- 23 May 2024
- Print publication:
- 30 May 2024, pp 256-268
-
- Chapter
- Export citation
2 - Artificial Intelligence and Economics
-
- Book:
- Artificial Intelligence
- Published online:
- 23 May 2024
- Print publication:
- 30 May 2024, pp 22-59
-
- Chapter
- Export citation
5 - Artificial Intelligence, Growth, and Inequality
-
- Book:
- Artificial Intelligence
- Published online:
- 23 May 2024
- Print publication:
- 30 May 2024, pp 107-172
-
- Chapter
- Export citation
Investigating the association of opioid prescription with the incidence of psychiatric disorders: nationwide cohort study in South Korea
-
- Journal:
- BJPsych Open / Volume 10 / Issue 3 / May 2024
- Published online by Cambridge University Press:
- 27 May 2024, e122
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
3 - Big Data Cannot Replace Entrepreneurs
- from Part I - The Nature of Knowledge and Entrepreneurship
-
- Book:
- Re-Understanding Entrepreneurship
- Published online:
- 02 May 2024
- Print publication:
- 02 May 2024, pp 41-57
-
- Chapter
- Export citation
6 - Data Flows as Digital Trade
- from Part III - Datafication and Data Flows
-
- Book:
- International Economic Law in the Era of Datafication
- Published online:
- 28 March 2024
- Print publication:
- 04 April 2024, pp 197-237
-
- Chapter
- Export citation
Instrumental Guanxi Culture and Inbound Urban Migration in China: A Prefecture-level Analysis Using Online Search Data
-
- Journal:
- The China Quarterly , First View
- Published online by Cambridge University Press:
- 22 March 2024, pp. 1-19
-
- Article
- Export citation
A comprehensive hierarchical comparison of structural connectomes in Major Depressive Disorder cases v. controls in two large population samples
-
- Journal:
- Psychological Medicine , First View
- Published online by Cambridge University Press:
- 18 March 2024, pp. 1-12
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The conditional Lyapunov exponents and synchronisation of rotating turbulent flows
-
- Journal:
- Journal of Fluid Mechanics / Volume 983 / 25 March 2024
- Published online by Cambridge University Press:
- 12 March 2024, A1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The synchronisation between rotating turbulent flows in periodic boxes is investigated numerically. The flows are coupled via a master–slave coupling, taking the Fourier modes with wavenumber below a given value
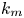 $k_m$ as the master modes. It is found that synchronisation happens when
$k_m$ as the master modes. It is found that synchronisation happens when 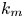 $k_m$ exceeds a threshold value
$k_m$ exceeds a threshold value 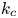 $k_c$, and
$k_c$, and 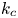 $k_c$ depends strongly on the forcing scheme. In rotating Kolmogorov flows,
$k_c$ depends strongly on the forcing scheme. In rotating Kolmogorov flows, 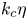 $k_c\eta$ does not change with rotation in the range of rotation rates considered,
$k_c\eta$ does not change with rotation in the range of rotation rates considered, 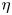 $\eta$ being the Kolmogorov length scale. Even though the energy spectrum has a steeper slope, the value of
$\eta$ being the Kolmogorov length scale. Even though the energy spectrum has a steeper slope, the value of 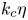 $k_c\eta$ is the same as that found in isotropic turbulence. In flows driven by a forcing term maintaining constant energy injection rate, synchronisation becomes easier when rotation is stronger. Here,
$k_c\eta$ is the same as that found in isotropic turbulence. In flows driven by a forcing term maintaining constant energy injection rate, synchronisation becomes easier when rotation is stronger. Here, 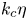 $k_c\eta$ decreases with rotation, and it is reduced significantly for strong rotations when the slope of the energy spectrum approaches
$k_c\eta$ decreases with rotation, and it is reduced significantly for strong rotations when the slope of the energy spectrum approaches 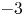 $-3$. It is shown that the conditional Lyapunov exponent for a given
$-3$. It is shown that the conditional Lyapunov exponent for a given 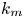 $k_m$ is reduced by rotation in the flows driven by the second type of forcing, but it increases mildly with rotation for the Kolmogorov flows. The local conditional Lyapunov exponents fluctuate more strongly as rotation is increased, although synchronisation occurs as long as the average conditional Lyapunov exponents are negative. We also look for the relationship between
$k_m$ is reduced by rotation in the flows driven by the second type of forcing, but it increases mildly with rotation for the Kolmogorov flows. The local conditional Lyapunov exponents fluctuate more strongly as rotation is increased, although synchronisation occurs as long as the average conditional Lyapunov exponents are negative. We also look for the relationship between 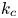 $k_c$ and the energy spectra of the Lyapunov vectors. We find that the spectra always seem to peak at approximately
$k_c$ and the energy spectra of the Lyapunov vectors. We find that the spectra always seem to peak at approximately 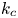 $k_c$, and synchronisation fails when the energy spectra of the conditional Lyapunov vectors have a local maximum in the slaved modes.
$k_c$, and synchronisation fails when the energy spectra of the conditional Lyapunov vectors have a local maximum in the slaved modes.
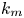
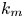
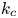
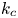
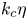
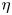
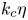
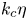
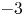
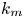
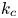
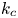
Analysis of spatial–temporal validation patterns in Fortaleza’s public transport systems: a data mining approach
-
- Journal:
- Data & Policy / Volume 5 / 2023
- Published online by Cambridge University Press:
- 14 December 2023, e40
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Select or adjust? How information from early treatment stages boosts the prediction of non-response in internet-based depression treatment
-
- Journal:
- Psychological Medicine / Volume 54 / Issue 8 / June 2024
- Published online by Cambridge University Press:
- 13 December 2023, pp. 1641-1650
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Chapter 4 - Big Data
-
-
- Book:
- Digital Mental Health
- Published online:
- 23 November 2023
- Print publication:
- 07 December 2023, pp 50-59
-
- Chapter
- Export citation

Large-Scale Data Analytics with Python and Spark
- A Hands-on Guide to Implementing Machine Learning Solutions
-
- Published online:
- 15 December 2023
- Print publication:
- 23 November 2023
-
- Textbook
- Export citation
Chapter 8 - Technology-Enabled Measurement in Singapore
- from Part III - Regional Focus
-
-
- Book:
- Technology and Measurement around the Globe
- Published online:
- 08 November 2023
- Print publication:
- 09 November 2023, pp 239-270
-
- Chapter
- Export citation
16 - Conclusion
- from Part III - Making Structural Predictions
-
- Book:
- Network Analysis
- Published online:
- 21 September 2023
- Print publication:
- 05 October 2023, pp 390-420
-
- Chapter
- Export citation
5 - No-Boundary Thinking for Transcriptomics and Proteomics Big Data
-
-
- Book:
- Integrative Bioinformatics for Biomedical Big Data
- Published online:
- 14 September 2023
- Print publication:
- 28 September 2023, pp 67-86
-
- Chapter
- Export citation
Predicting risk factors for pediatric mortality in clinical trial research: A retrospective, cross-sectional study using a Healthcare Cost and Utilization Project database
-
- Journal:
- Journal of Clinical and Translational Science / Volume 7 / Issue 1 / 2023
- Published online by Cambridge University Press:
- 22 September 2023, e211
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
12 - Concluding Comments: Evidence-Based Macroeconomics and Economic Theory
-
- Book:
- Structuralist and Behavioral Macroeconomics
- Published online:
- 10 November 2023
- Print publication:
- 21 September 2023, pp 336-341
-
- Chapter
- Export citation
