
47 results
9 - Multivariate Data Exploration and Discrimination
-
- Book:
- A Practical Guide to Data Analysis Using R
- Published online:
- 11 May 2024
- Print publication:
- 30 May 2024, pp 400-468
-
- Chapter
- Export citation
The relative clause resisting unification
-
- Journal:
- Canadian Journal of Linguistics/Revue canadienne de linguistique , First View
- Published online by Cambridge University Press:
- 13 May 2024, pp. 1-11
-
- Article
- Export citation
Constrained read-once refutations in UTVPI constraint systems: A parallel perspective
-
- Journal:
- Mathematical Structures in Computer Science / Volume 34 / Issue 3 / March 2024
- Published online by Cambridge University Press:
- 11 September 2023, pp. 227-243
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
In this paper, we analyze two types of refutations for Unit Two Variable Per Inequality (UTVPI) constraints. A UTVPI constraint is a linear inequality of the form:
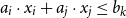 $a_{i}\cdot x_{i}+a_{j} \cdot x_{j} \le b_{k}$, where
$a_{i}\cdot x_{i}+a_{j} \cdot x_{j} \le b_{k}$, where 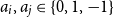 $a_{i},a_{j}\in \{0,1,-1\}$ and
$a_{i},a_{j}\in \{0,1,-1\}$ and 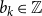 $b_{k} \in \mathbb{Z}$. A conjunction of such constraints is called a UTVPI constraint system (UCS) and can be represented in matrix form as:
$b_{k} \in \mathbb{Z}$. A conjunction of such constraints is called a UTVPI constraint system (UCS) and can be represented in matrix form as: 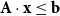 ${\bf A \cdot x \le b}$. UTVPI constraints are used in many domains including operations research and program verification. We focus on two variants of read-once refutation (ROR). An ROR is a refutation in which each constraint is used at most once. A literal-once refutation (LOR), a more restrictive form of ROR, is a refutation in which each literal (
${\bf A \cdot x \le b}$. UTVPI constraints are used in many domains including operations research and program verification. We focus on two variants of read-once refutation (ROR). An ROR is a refutation in which each constraint is used at most once. A literal-once refutation (LOR), a more restrictive form of ROR, is a refutation in which each literal (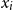 $x_i$ or
$x_i$ or 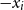 $-x_i$) is used at most once. First, we examine the constraint-required read-once refutation (CROR) problem and the constraint-required literal-once refutation (CLOR) problem. In both of these problems, we are given a set of constraints that must be used in the refutation. RORs and LORs are incomplete since not every system of linear constraints is guaranteed to have such a refutation. This is still true even when we restrict ourselves to UCSs. In this paper, we provide NC reductions between the CROR and CLOR problems in UCSs and the minimum weight perfect matching problem. The reductions used in this paper assume a CREW PRAM model of parallel computation. As a result, the reductions establish that, from the perspective of parallel algorithms, the CROR and CLOR problems in UCSs are equivalent to matching. In particular, if an NC algorithm exists for either of these problems, then there is an NC algorithm for matching.
$-x_i$) is used at most once. First, we examine the constraint-required read-once refutation (CROR) problem and the constraint-required literal-once refutation (CLOR) problem. In both of these problems, we are given a set of constraints that must be used in the refutation. RORs and LORs are incomplete since not every system of linear constraints is guaranteed to have such a refutation. This is still true even when we restrict ourselves to UCSs. In this paper, we provide NC reductions between the CROR and CLOR problems in UCSs and the minimum weight perfect matching problem. The reductions used in this paper assume a CREW PRAM model of parallel computation. As a result, the reductions establish that, from the perspective of parallel algorithms, the CROR and CLOR problems in UCSs are equivalent to matching. In particular, if an NC algorithm exists for either of these problems, then there is an NC algorithm for matching.
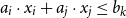
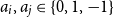
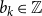
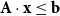
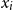
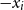
13 - School Matching and Learning under the Influence of Intergenerational Advice
- from Part V - Advice and Economic Mechanisms
-
- Book:
- Advice, Social Learning and the Evolution of Conventions
- Published online:
- 09 March 2023
- Print publication:
- 09 March 2023, pp 360-393
-
- Chapter
- Export citation
12 - Chatting and Matching
- from Part V - Advice and Economic Mechanisms
-
- Book:
- Advice, Social Learning and the Evolution of Conventions
- Published online:
- 09 March 2023
- Print publication:
- 09 March 2023, pp 321-359
-
- Chapter
- Export citation
Glucose promotes controlled processing: Matching, maximizing, and root beer
-
- Journal:
- Judgment and Decision Making / Volume 5 / Issue 6 / October 2010
- Published online by Cambridge University Press:
- 01 January 2023, pp. 450-457
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Effects of crop insurance on farm input use: Evidence from Kansas farm data
-
- Journal:
- Agricultural and Resource Economics Review / Volume 51 / Issue 2 / August 2022
- Published online by Cambridge University Press:
- 06 May 2022, pp. 361-379
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Raising and matching in Pharasiot Greek relative clauses: A diachronic reconstruction
-
- Journal:
- Journal of Linguistics / Volume 58 / Issue 3 / August 2022
- Published online by Cambridge University Press:
- 21 December 2021, pp. 495-533
- Print publication:
- August 2022
-
- Article
- Export citation
A stochastic matching model on hypergraphs
- Part of
-
- Journal:
- Advances in Applied Probability / Volume 53 / Issue 4 / December 2021
- Published online by Cambridge University Press:
- 22 November 2021, pp. 951-980
- Print publication:
- December 2021
-
- Article
- Export citation
3 - Pattern Matching
-
- Book:
- 125 Problems in Text Algorithms
- Published online:
- 10 June 2021
- Print publication:
- 01 July 2021, pp 53-110
-
- Chapter
- Export citation

125 Problems in Text Algorithms
- with Solutions
-
- Published online:
- 10 June 2021
- Print publication:
- 01 July 2021
Combining Outcome-Based and Preference-Based Matching: A Constrained Priority Mechanism
-
- Journal:
- Political Analysis / Volume 30 / Issue 1 / January 2022
- Published online by Cambridge University Press:
- 08 March 2021, pp. 89-112
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We introduce a constrained priority mechanism that combines outcome-based matching from machine learning with preference-based allocation schemes common in market design. Using real-world data, we illustrate how our mechanism could be applied to the assignment of refugee families to host country locations, and kindergarteners to schools. Our mechanism allows a planner to first specify a threshold
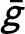 $\bar g$
for the minimum acceptable average outcome score that should be achieved by the assignment. In the refugee matching context, this score corresponds to the probability of employment, whereas in the student assignment context, it corresponds to standardized test scores. The mechanism is a priority mechanism that considers both outcomes and preferences by assigning agents (refugee families and students) based on their preferences, but subject to meeting the planner’s specified threshold. The mechanism is both strategy-proof and constrained efficient in that it always generates a matching that is not Pareto dominated by any other matching that respects the planner’s threshold.
$\bar g$
for the minimum acceptable average outcome score that should be achieved by the assignment. In the refugee matching context, this score corresponds to the probability of employment, whereas in the student assignment context, it corresponds to standardized test scores. The mechanism is a priority mechanism that considers both outcomes and preferences by assigning agents (refugee families and students) based on their preferences, but subject to meeting the planner’s specified threshold. The mechanism is both strategy-proof and constrained efficient in that it always generates a matching that is not Pareto dominated by any other matching that respects the planner’s threshold.
Do Overseas Returnees Excel in the Chinese Labour Market?
-
- Journal:
- The China Quarterly / Volume 247 / September 2021
- Published online by Cambridge University Press:
- 19 February 2021, pp. 875-897
- Print publication:
- September 2021
-
- Article
- Export citation
On the Use of Two-Way Fixed Effects Regression Models for Causal Inference with Panel Data
-
- Journal:
- Political Analysis / Volume 29 / Issue 3 / July 2021
- Published online by Cambridge University Press:
- 12 November 2020, pp. 405-415
-
- Article
- Export citation
6 - Regular Expressions
-
- Book:
- Python for Linguists
- Published online:
- 20 April 2020
- Print publication:
- 07 May 2020, pp 117-137
-
- Chapter
- Export citation
8 - Muddied waters: The challenge of confounding
-
- Book:
- Essential Epidemiology
- Published online:
- 31 August 2020
- Print publication:
- 29 November 2019, pp 185-209
-
- Chapter
- Export citation
Assessing the computational complexity of multilayer subgraph detection
-
- Journal:
- Network Science / Volume 7 / Issue 2 / June 2019
- Published online by Cambridge University Press:
- 05 August 2019, pp. 215-241
-
- Article
- Export citation
3 - Topological connectedness and independent sets in graphs
-
-
- Book:
- Surveys in Combinatorics 2019
- Published online:
- 17 June 2019
- Print publication:
- 27 June 2019, pp 89-114
-
- Chapter
- Export citation
Why Propensity Scores Should Not Be Used for Matching
-
- Journal:
- Political Analysis / Volume 27 / Issue 4 / October 2019
- Published online by Cambridge University Press:
- 07 May 2019, pp. 435-454
-
- Article
- Export citation
The structure of priority in the school choice problem
-
- Journal:
- Economics & Philosophy / Volume 35 / Issue 3 / November 2019
- Published online by Cambridge University Press:
- 24 January 2019, pp. 361-381
-
- Article
- Export citation
