
64 results
Gabapentin as a novel adjunct for postoperative irritability after superior cavopulmonary connection operation in children
-
- Journal:
- Cardiology in the Young , First View
- Published online by Cambridge University Press:
- 03 May 2024, pp. 1-7
-
- Article
- Export citation
The Evolutionary Map of the Universe Pilot Survey – ADDENDUM
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 39 / 2022
- Published online by Cambridge University Press:
- 02 November 2022, e055
-
- Article
- Export citation
The Evolutionary Map of the Universe pilot survey
- Part of
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 38 / 2021
- Published online by Cambridge University Press:
- 07 September 2021, e046
-
- Article
-
- You have access
- HTML
- Export citation
-
We present the data and initial results from the first pilot survey of the Evolutionary Map of the Universe (EMU), observed at 944 MHz with the Australian Square Kilometre Array Pathfinder (ASKAP) telescope. The survey covers
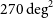 $270 \,\mathrm{deg}^2$
of an area covered by the Dark Energy Survey, reaching a depth of 25–30
$270 \,\mathrm{deg}^2$
of an area covered by the Dark Energy Survey, reaching a depth of 25–30
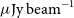 $\mu\mathrm{Jy\ beam}^{-1}$
rms at a spatial resolution of
$\mu\mathrm{Jy\ beam}^{-1}$
rms at a spatial resolution of
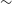 $\sim$
11–18 arcsec, resulting in a catalogue of
$\sim$
11–18 arcsec, resulting in a catalogue of
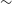 $\sim$
220 000 sources, of which
$\sim$
220 000 sources, of which
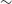 $\sim$
180 000 are single-component sources. Here we present the catalogue of single-component sources, together with (where available) optical and infrared cross-identifications, classifications, and redshifts. This survey explores a new region of parameter space compared to previous surveys. Specifically, the EMU Pilot Survey has a high density of sources, and also a high sensitivity to low surface brightness emission. These properties result in the detection of types of sources that were rarely seen in or absent from previous surveys. We present some of these new results here.
$\sim$
180 000 are single-component sources. Here we present the catalogue of single-component sources, together with (where available) optical and infrared cross-identifications, classifications, and redshifts. This survey explores a new region of parameter space compared to previous surveys. Specifically, the EMU Pilot Survey has a high density of sources, and also a high sensitivity to low surface brightness emission. These properties result in the detection of types of sources that were rarely seen in or absent from previous surveys. We present some of these new results here.
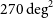
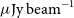
Use of Neuroimaging to Inform Optimal Neurocognitive Criteria for Detecting HIV-Associated Brain Abnormalities
-
- Journal:
- Journal of the International Neuropsychological Society / Volume 26 / Issue 2 / February 2020
- Published online by Cambridge University Press:
- 02 October 2019, pp. 147-162
-
- Article
- Export citation
Neurocognitive SuperAging in Older Adults Living With HIV: Demographic, Neuromedical and Everyday Functioning Correlates
-
- Journal:
- Journal of the International Neuropsychological Society / Volume 25 / Issue 5 / May 2019
- Published online by Cambridge University Press:
- 20 March 2019, pp. 507-519
-
- Article
- Export citation
Associations between childhood maltreatment and inflammatory markers
-
- Journal:
- BJPsych Open / Volume 5 / Issue 1 / January 2019
- Published online by Cambridge University Press:
- 04 January 2019, e3
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Differences in Neurocognitive Impairment Among HIV-Infected Latinos in the United States
-
- Journal:
- Journal of the International Neuropsychological Society / Volume 24 / Issue 2 / February 2018
- Published online by Cambridge University Press:
- 06 September 2017, pp. 163-175
-
- Article
-
- You have access
- HTML
- Export citation
Outdated Views of Qualitative Methods: Time to Move On
-
- Journal:
- Political Analysis / Volume 18 / Issue 4 / Autumn 2010
- Published online by Cambridge University Press:
- 04 January 2017, pp. 506-513
-
- Article
- Export citation
Toward a Pluralistic Vision of Methodology
-
- Journal:
- Political Analysis / Volume 14 / Issue 3 / Summer 2006
- Published online by Cambridge University Press:
- 04 January 2017, pp. 353-368
-
- Article
- Export citation
Assessing the Market for Poultry Litter in Georgia: Are Subsidies Needed to Protect Water Quality?
-
- Journal:
- Journal of Agricultural and Applied Economics / Volume 43 / Issue 4 / November 2011
- Published online by Cambridge University Press:
- 26 January 2015, pp. 553-568
-
- Article
- Export citation
Assimilate: A Critical History of Industrial Music. By S. Alexander Reed. New York: Oxford University Press, 2013. 368 pp. ISBN 978-0-199-83260-6
-
- Journal:
- Popular Music / Volume 34 / Issue 1 / January 2015
- Published online by Cambridge University Press:
- 19 December 2014, pp. 172-174
- Print publication:
- January 2015
-
- Article
- Export citation
Musical Rhythm in the Age of Digital Reproduction. By Anne Danielsen. Farnham: Ashgate, 2010. 265 pp. ISBN 978-1409403401
-
- Journal:
- Popular Music / Volume 31 / Issue 3 / October 2012
- Published online by Cambridge University Press:
- 12 October 2012, pp. 491-492
- Print publication:
- October 2012
-
- Article
- Export citation
A Prospective Twin Registry in Southwestern China (TRiSC): Exploring the Effects of Genetic and Environmental Factors on Cognitive and Behavioral Development and Mental Health Wellbeing in Children and Adolescents
-
- Journal:
- Twin Research and Human Genetics / Volume 12 / Issue 3 / 01 June 2009
- Published online by Cambridge University Press:
- 21 February 2012, pp. 312-319
-
- Article
-
- You have access
- Export citation
Understanding Process Tracing
-
- Journal:
- PS: Political Science & Politics / Volume 44 / Issue 4 / October 2011
- Published online by Cambridge University Press:
- 18 October 2011, pp. 823-830
- Print publication:
- October 2011
-
- Article
-
- You have access
- HTML
- Export citation
Dissecting the many genetic faces of schizophrenia
-
- Journal:
- Epidemiologia e Psichiatria Sociale / Volume 18 / Issue 2 / June 2009
- Published online by Cambridge University Press:
- 11 April 2011, pp. 91-95
-
- Article
-
- You have access
- Export citation
Eating disorders and obesity: two sides of the same coin?
-
- Journal:
- Epidemiologia e Psichiatria Sociale / Volume 18 / Issue 2 / June 2009
- Published online by Cambridge University Press:
- 11 April 2011, pp. 96-100
-
- Article
-
- You have access
- Export citation
Adaptation to tropical climate and research strategies to alleviate heat stress in livestock production
-
- Journal:
- Advances in Animal Biosciences / Volume 1 / Issue 2 / November 2010
- Published online by Cambridge University Press:
- 01 November 2010, pp. 378-379
- Print publication:
- November 2010
-
- Article
-
- You have access
- Export citation
Index
-
- Book:
- Statistical Models and Causal Inference
- Published online:
- 05 June 2012
- Print publication:
- 23 November 2009, pp 393-399
-
- Chapter
- Export citation
11 - Survival Analysis: An Epidemiological Hazard?
-
- Book:
- Statistical Models and Causal Inference
- Published online:
- 05 June 2012
- Print publication:
- 23 November 2009, pp 169-192
-
- Chapter
- Export citation
7 - Black Ravens, White Shoes, and Case Selection: Inference with Categorical Variables
-
- Book:
- Statistical Models and Causal Inference
- Published online:
- 05 June 2012
- Print publication:
- 23 November 2009, pp 105-114
-
- Chapter
- Export citation
