


Introduction
Depression rating scales have acquired an indispensable role in clinical trials [Reference Hughes, O’Hara and Rehm1], in which they are used to select eligible patients and to assess changes in symptoms and in symptom intensity during treatment [Reference Snaith2]. Depression treatment guidelines strongly recommend the use of measurement tools to monitor the course of treatment [3,4], while in some countries, health care providers even link the use of validated questionnaires to funding [Reference Kilbourne, Beck, Spaeth-Rublee, Ramanuj, O’Brien and Tomoyasu5,Reference Macdonald and Elphick6].
On the contrary, most clinicians do not use scales in everyday practice. In the United Kingdom, as much as 88.7% of psychiatrists never or occasionally use standardized measures in patients with depression or an anxiety disorder [Reference Gilbody and Sheldon7]. In the United States, 82% of psychiatrists never, rarely or only sometimes use scales to monitor outcome in depressed patients [Reference Zimmerman and McGlinchey8]. Some clinicians report doubts on the validity of available tools or fear that using scales is too time-consuming [Reference Zimmerman and McGlinchey8,Reference Hatfield and Ogles9]. Others worry about potential (mis)use in the current management-benchmarking-ranking culture [Reference Dowrick, Leydon, McBride, Howe, Burgess and Clarke10]. Developments as pay for quality could moreover guide clinicians to prioritize what can be measured, to consider unimportant what cannot be measured, and to direct organizational efforts toward what is easily quantified. Others consider themselves as insufficiently trained to apply scales correctly [Reference Zimmerman and McGlinchey8,Reference Hatfield and Ogles9]. Many caregivers do trust more on their own clinical judgment while blaming the reductionist nature of scales, insufficiently able to display the complex state of their patients [7–9,Reference Frank11]. Max Hamilton already warned that rating a patient risks to fit him “into a Procrustean bed” [Reference Hamilton12] meaning that, as Procrustes amputated the limbs of his guests to adjust them to his bed, clinicians can ignore vital patient information because it does not correspond with the content of a scale.
Since the Hamilton Depression Rating Scale [Reference Hamilton12] and the Montgomery–Åsberg Depression Rating Scale [Reference Montgomery and Asberg13], many other depression rating scales have been proposed: from observer-rating to self-rating scales, from disease-specific to non–disease-specific scales, from “subjective” questionnaires to “objective” lab assessments, from questionnaires to experience sampling. One overarching concern is that information delivered by scales is not always relevant to patients, families, and even to clinicians.
The present paper aims to summarize the trends in assessment tools for unipolar major depression in order to provide an orientating framework to the practicing clinician.
Methods
This paper is neither a compendium nor a systematic review of assessment scales for unipolar major depression. It is a selective review aiming to help the clinician/researcher in choosing a scale by providing an orientational framework wherein the existing scales can be positioned and categorized: observer-rating versus self-rating scales, disease-specific versus non–disease-specific scales, site rating versus centralized rating, “subjective” questionnaire rating versus “objective” (lab) assessment, and questionnaires versus experience sampling method (Table 1). This framework is illustrated by papers based on Pubmed searches and is followed by an overarching comment on the relevance of these scales from a depressed patient perspective.
Table 1. Categorization of assessment scales available for patients with unipolar depression.
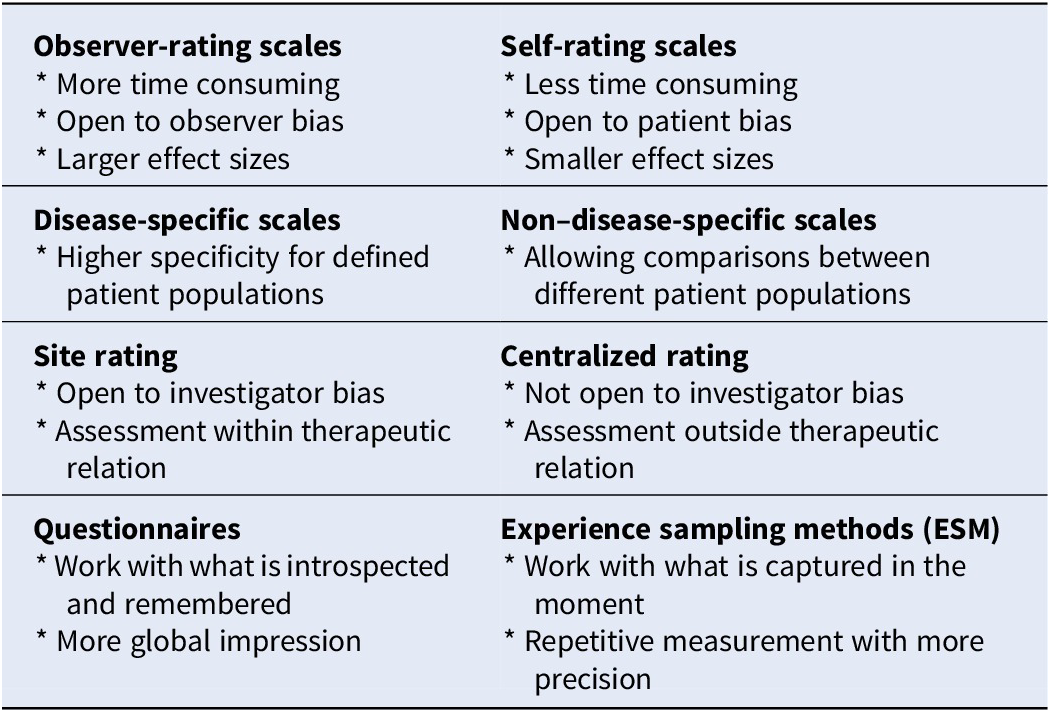
Observer-Rating versus Self-Rating Scales
A first positioning has to be made between observer-rating and self-rating scales. Observer-rating scales benefit from the experience of the rater, supposed to be free from patient bias [Reference Hamilton12,Reference Möller14], while self-rating scales are less time-consuming and supposed to be free from clinician bias [Reference Zimmerman and McGlinchey8,Reference Möller14].
The Hamilton Rating Scale for Depression (HAMD [Reference Hamilton12]) and the Montgomery–Asberg Depression Rating Scale (MADRS [Reference Montgomery and Asberg13]) are the first and second most commonly used clinician rating scales in depression treatment studies [Reference Zimmerman, Clark, Multach, Walsh, Rosenstein and Gazarian15]. Hamilton designed a tool to quantify results of clinical interviews in patients with established depression [Reference Hamilton16]. But since the HAMD has many anxiety and sleep items, the scale reflects the efficacy (and sedative side effects) of the tricyclics [Reference Tansey17,Reference Worboys18]. Sensitivity to change was at the origin of the development of the MADRS [Reference Montgomery and Asberg13]. For the construction of the scale, the authors selected the 10 items of the much larger Comprehensive Psychiatric Rating Scale that changed most during treatment with various antidepressants. One can hence conclude that both the HAMD and the MADRS are “antidepressant friendly” scales. And since the HAMD merges depressive and anxious symptoms as well as neurovegetative symptoms, it seems to put all depressions into one basket: a more anxious depression or a depression with neurovegetative symptoms will both be more severe depressions [Reference Demyttenaere and De Fruyt19]. Since the MADRS reflects the effects of a variety of antidepressants (with different mode of action), it seems to put all antidepressants in one basket and therefore cannot answer the question whether antidepressants with a different mode of action target different symptoms or different symptom clusters [Reference Demyttenaere and De Fruyt19]).
Similar comment can be made on self-rating questionnaires. The Beck Depression Inventory (BDI) is a widely used self-rating instrument [20–22] focusing on cognitive symptoms and is therefore “cognitive behavioral psychotherapy friendly” [Reference Hagen23].
Moreover, discrepancies can be found between how observer-rating and self-rating instruments detect change. Cuijpers et al. [Reference Cuijpers, Li, Hofmann and Andersson24] compared the effect sizes generated by self-report scales and clinician-rated scales and found that clinician-rated instruments consistently result in significantly higher effect sizes than self-report instruments from the same studies (Δg = 0.20; 95%, CI 0.10–0.30). On the contrary, Zimmerman found overall comparable effect sizes and percentage of responders (≥50% reduction in baseline scores) in routine clinical practice (away from a “sponsored” study context) [Reference Zimmerman, Walsh, Friedman, Boerescu and Attiullah25].
Interestingly, discrepancies are also found in observer-rated and self-rated versions of the same scale (MADRS vs. MADRS-S). In a randomized controlled trial comparing escitalopram and citalopram, responses were lower using the self-rating version than on the clinician-rating version (response rate on MADRS-S: 66.4 and 53.9% for escitalopram and citalopram, respectively [p = 0.043], vs. 76.1 and 61.5% on the MADRS [p = 0.009]) [Reference Fantino and Moore26].
Disease-Specific versus Non–Disease-Specific Scales
A second positioning has to be made between disease-specific scales that focus on disease-specific symptoms, and non–disease-specific scales that assess the “overall” impression of clinical status or “overall” impression of clinical change.
Within the so-called disease-specific scales (for major depression), some authors advocate the use of scales with an even higher specificity for specific subpopulations: more age specific (e.g., the Geriatric Depression Scale [Reference Mitchell, Bird, Rizzo and Meader27]), more psychiatric comorbidity specific (e.g., the Calgary Depression Scale for Schizophrenia [Reference Addington, Addington and Schissel28]), more somatic comorbidity specific (e.g., the Post-Stroke Depression Rating Scale [Reference Gainotti, Azzoni, Zazzano, Lannillotta, Marra and Gasparini29]), and more life phase specific (e.g., the Meno-D for perimenopausal depression [Reference Kulkarni, Gavrilidis, Hub-daib, Bleeker, Worsley and Gurvich30]).
The Clinical Global Impression (CGI) scale was originally developed to provide a brief, stand-alone assessment of the clinician’s view of the patient’s global functioning prior to and after initiating a study medication [Reference Guy31]. The CGI is concise and simple: it is a non–disease-specific tool that measures global illness severity (CGI-S) and global improvement (CGI-I). The CGI-S is rated with scores from 1 (normal) through to 7 (among the most severely ill patients). The CGI-I is also rated with scores from 1 (very much improved) through 7 (very much worse) [Reference Guy31]. In the past years, the need for instruments with similar user friendliness but with improved interrater reliability has led to a partial return to more disease-specific and transdiagnostic versions of the CGI [32–36].
There is ongoing controversy about what is a clinically meaningful change in score on a rating scale: response (a 50% reduction of the baseline score or “much improved” or “very much improved”) or remission (a score below a cut-off value or “very much improved”) [Reference Hawley, Gale and Sivakumaran37]. The question remains whether non–disease-specific scales differ in their ability to detect meaningful change in the condition of patients and to what degree they depend upon baseline severity of depression.
Investigators were asked to rank-order elements that determined their CGI scores: symptom severity and functional status were the two most important drivers, and strikingly less importance was given to self-report symptoms scores [Reference Forkmann, Scherer, Boecker, Pawelzik, Jostes and Gauggel38,Reference Leon, Shear, Klerman, Portera, Rosenbaum and Goldenberg39] indicating low attention to the patient perspective.
In 2016, Bobo et al. equated HAMD-17 response percentages with CGI-I scores in antidepressant trials and confirmed the consensus definition of response on standard scales (50% improvement): “much improved” ratings (CGI-I responders) corresponded with 50–57% improvement. Differentiating one step further, absolute changes in HAMD-17 and CGI-I scores have been compared in patients with higher or lower depression severity at baseline. Patients with higher depression severity needed a decrease of 13–14 points to be considered “much improved,” while the lower severity group only needed a nine-point decrease [Reference Bobo, Anglero, Jenkins, Hall-Flavin, Weinshilboum and Biernacka40,Reference Leucht, Fennema, Engel, Kaspers–Janssen, Lepping and Szegedi41]. This effect disappeared when the relative change on HAMD scores was considered. The more severe the depression severity, the larger should be the improvement before the clinician decides on a “much improved” status [Reference Leucht, Fennema, Engel, Kaspers–Janssen, Lepping and Szegedi41].
Site Rating versus Centralized Rating
At least in clinical research, a third positioning has to be made between site rating and centralized rating. The development of centralized rating tried to overcome the problem of many failed or negative pharmacological trials. One of the contributing factors of trial failure is measurement methodology: poor interrater reliability leading to smaller between-groups effect sizes, baseline score inflation, and rater expectancy effects leading to decreased signal detection [Reference Papakostas, Ostergaard and Iovieno42].
Centralized rating deploys highly skilled, site-independent raters, who asses patients through video- or teleconferencing [43–45], and they are blinded for inclusion criteria, study visit, and study site location. The comparison of these two assessment modalities (centralized vs. site rating) learned that 35% of the study subjects (included by the site raters) would not have entered the study (by the centralized raters). Moreover, site raters found significantly more placebo responders than central raters did (respectively, 28% vs. 14%, p < 0.001). Finally, this difference in placebo response between site raters and central raters disappeared when the analysis was conducted in the 65% of patients that would have been included by both site and central raters [Reference Kobak, Leuchter, DeBrota, Engelhardt, Williams and Cook44].
Targum and colleagues added the modality of self-rating to the comparison of site and central rating in three arms with placebo, 15 mg buspirone, or a combination of buspirone 15 mg and melatonine 3 mg. The difference in response rates between the combination treatment (buspirone and melatonine) and placebo was 15.9% when done by site raters and 7.1% when done by central raters. However, these differences between the two treatment arms increased (19.4% instead of 15.9% when done by site raters and 15.2% instead of 7.1% when done by centralized raters) when a “dual scoring” method was used: that is, excluding patients who at baseline had remarkably discordance (more than 1 standard deviation from baseline means) between site raters and central raters. The “dual scoring” method resulted in higher treatment response rates and lower placebo response rates (resp. 48.6% vs. 29.2% in site ratings, and resp. 48.57% vs. 33.33% in central ratings) suggesting that more advanced rating methodology could be useful in future clinical trials [Reference Targum, Wedel, Robinson, Daniel, Busner and Bleicher45].
Subjective Questionnaire Rating versus Objective (Lab) Assessment
A fourth positioning has to be made between more subjective questionnaire rating and more objective lab assessment. Some more biological-oriented psychiatrists blame the field for the lack of objective parameters while expressing their suspicion toward the subjectivity of rating scales and hope for biological measures (blood tests, imaging, genetics, etc.). More psychotherapeutically oriented psychiatrists on the contrary are convinced that the essence of psychotherapy is in working with subjectivity. A somewhat intermediate trend is to complement questionnaires with more objective lab testing.
One example of the differentiation between subjective and objective rating has been investigated in the assessment of cognitive symptoms in depression. One assessment method is the Perceived Deficits Questionnaire (PDQ), a brief screening instrument designed to measure perceived cognitive impairment (originally in patients with multiple sclerosis. This questionnaire comprises four subscales: attention/concentration, prospective memory, planning/organization, and retrospective memory [Reference Sullivan, Edgley and Dehoux46]. Another assessment method is more objective testing like the Digit Symbol Substitution Test supposed to assess executive functioning, psychomotor speed, attention, and memory [Reference Jaeger47], or like the Rey Auditory Verbal Learning Test supposed to assess acquisition and delayed recall [Reference Vakil and Blachstein48]. We use the wording “supposed to assess” since basic motivation or giving up at failure always interfere with these so-called objective cognitive tests. A marked correlation was found between subjectively perceived cognitive deficits on the PDQ and both depression and self-efficacy scores but no relationship with objective cognitive performance [Reference Strober, Binder, Nikelshpur, Chiaravalloti and DeLuca49]. A similar effect was seen in remitted unipolar and bipolar patients, where subjective cognitive dysfunction was correlated with depression severity but was not differentiating between unipolar and bipolar patients; this contradicts objective cognitive assessments generally showing a greater dysfunction in bipolar disorder [Reference Miskowiak, Vinberg, Christensen and Kessing50]. These findings suggest that subjective ratings of cognitive functioning are more strongly influenced by mood symptoms than objective ratings of cognitive functioning. Attempts have been made to disentangle the cognitive and the other depressive symptoms in a vortioxetine trial where path analysis showed that part of the subjective/objective cognitive improvement was independent from the improvement in depressive symptom severity [Reference McIntyre, Lophaven and Olsen51]. This suggests that for both subjective and objective measures of cognitive functioning, cognitive improvement can be disentangled from the improvement in the other depressive symptoms like lack of motivation or lack of energy.
Another example of the differentiation between subjective and objective rating has been investigated in the assessment of anhedonia. Anhedonia is a core symptom of depression, maybe even the most specific depressive symptom, but receives remarkably poor attention in standard observer scales as HAMD-17 or MADRS. In both scales, only one item is (partially) dedicated to anhedonia. To address this deficiency, scales that focus on the assessment of hedonic tone in depression such as the Snaith–Hamilton Pleasure scale (SHAPS [Reference Snaith, Hamilton, Morley, Humayan, Hargreaves and Trigwell52]), the Temporal Experience of Pleasure Scale (TEPS [Reference Gard, Gard, Kring and John53]), and Leuven Affect and Pleasure Scale (LAPS [Reference Demyttenaere, Mortier, Kiekens and Bruffaerts54]) have been developed. These self-report scales try to cover the multidimensional concept of anhedonia. The SHAPS assesses both sensory and social anhedonia but offers no differentiation between anticipatory and consummatory elements. The TEPS does address these aspects but solely for sensory anhedonia while the LAPS covers all dimensions.
Some researchers in the cognitive field moved away from assessing anhedonia with subjective questionnaires to develop more objective, laboratory-based anhedonia measures [55–58]. They operationalize hedonic capacity as responsiveness to reinforcing stimuli, assessed by a signal detection task. Pizzagalli, for instance, uses a signal detection task generating a differential monetary reward after correct identification of one of two possible stimuli. Normally, subjects develop a preference (bias) to the stimulus that is associated with more frequent awards. Absence of a response bias was found in participants with elevated depressive symptoms [Reference Pizzagalli, Jahn and O’Shea58] and in patients with major depressive disorder [Reference Pizzagalli, Iosifescu, Hallett, Ratner and Fava57]. Only moderate differences were found on the BDI melancholic subscore of the BDI anhedonia subscore for subjects showing a positive or negative response bias showing that the “objective” test results only partially overlap with the “subjective” test results.
Questionnaires versus Experience Sampling Method
A fifth positioning has to be made between questionnaires assessing mood states during a certain time interval and experience sampling assessing and aggregating mood states based upon multiple time points per day. Standard depression rating scales have the problem of a time frame: how could depressed patients who tend to (over) generalize be able to correctly report how they felt during the past week or during the past 2 weeks? This resulted in the development of the experience sampling method (ESM), aiming to assemble information of subjective experience of patients via collection of self-reports on activities, emotions, or other elements of daily life at various points throughout the day. ESM is considered as a more sophisticated version of the diary approach, subjects being invited to repeatedly answer short questionnaires, preferably timed randomly with restricted intervals to avoid behavioral adaptation to fixed intervals [Reference van Berkel, Ferreira and Kostakos59,Reference Verhagen, Hasmi, Drukker, van Os and Delespaul60]. It has been suggested that ESM “allows us to capture the film rather than a snapshot of daily life reality of patients” [Reference Myin-Germeys, Oorschot, Collip, Lataster, Delespaul and van Os61].
Because of the repeated measures over time in the continuously changing context of daily life, ESM is supposed to have multiple benefits such as a higher ecological validity and a higher sensitivity to (subtle) change(s). It is seen as a method less dependent of participants memory, less vulnerable to assessment error, suitable to assess dynamic processes (e.g., how long does it last to be able to experience positive mood after a negative mood inducing event), and able to provide a view on variability in mental states. It also allows some “contextual” analysis by giving the possibility of linking emotions and affect to situational aspects (e.g., being at home or being at work while experiencing emotions). When used in clinical practice, ESM could increase the engagement of patients in the treatment process although the latter still has to be confirmed [Reference Verhagen, Hasmi, Drukker, van Os and Delespaul60]. It is certainly more precise, but the question can again be raised whether more precise is more “meaningful” to patients and to physicians. One can easily assume that ESM will be more easily integrated in cognitive behavior approaches than in family therapy or psychodynamic therapy.
But some doubts and some possible disadvantages of ESM have also been described [Reference van Berkel, Ferreira and Kostakos59]. One practical concern is the participant burden: being invited multiple times per day to fill out (even brief) assessments on your mobile can be intrusive and disruptive (e.g., on inopportune moments or in inopportune settings) and hence become a burden; several studies indeed showed rather high drop-out rates. A more fundamental comment is that measuring “in the moment” does not enable to capture the patient’s reflection on the measured phenomenon, while the latter is the basis for psychotherapeutical work [Reference van Berkel, Ferreira and Kostakos59,Reference Verhagen, Hasmi, Drukker, van Os and Delespaul60,Reference Engelbert and Carruthers62]. Moreover, the aggregation and time courses of the patient’s self-assessments can be poorly correlated with the memories of introspected experiences which again is the basis for psychotherapeutical work. The issue of “reactivity-induction” by bringing a certain content under the subject’s attention and possibly moving it from a preconscious/unconscious to a conscious level is less clear-cut and subject of an interesting debate. Another issue is that the so-called “contextual” assessment is extremely limited and therefore not very meaningful (assessed while “being at work” does not differentiate between probably important contextual aspects of that moment on the workplace).
Until today, ESM research in depression has mainly focused on the role and interaction of positive and negative affect and on the effect of (physical) activity to affect [Reference Armey, Schatten, Haradhvala and Miller63]. It is commonplace to state that patients with major depressive disorder suffer from reduced positive and increased negative affect [Reference Watson, Clark, Weber, Assenheimer, Strauss and McCormick64]. A refinement illustrated by ESM research found that stress generates stronger negative affect in MDD patients compared with controls, while the stress reactive decrease in positive affect was comparable in depressed patients and controls [Reference Myin-Germeys, Peeters, Havermans, Nicholson, DeVries and Delespaul65]. ESM has been used to document time courses of positive and negative affect in depressed patients, in remitted patients, and in controls but also to look at patterns predicting response. However, some of these studies get so methodologically refined that it becomes difficult to draw clinical relevant conclusions: one example is a study where it was shown that in recurrent-episode future responders, the daily maximum positive affect increase resulted in significantly lower levels of subsequent negative affect over the next few hours compared to future nonresponders or compared to first-episode responders [Reference Wichers, Peeters, Rutten, Jacobs, Derom and Theiry66].
Whether ESM will be a real assessment breakthrough and a real therapeutic breakthrough or whether it is mainly an academic sophistication and mainly a computer science–driven approach still has to be elucidated.
Is What is Commonly Assessed What Matters to Patients?
An overarching question is to whose reification each assessment tool contributes: to their author(s), to a specific theoretical framework, to a specific therapeutic effect, to the Diagnostic and Statistical Manual (DSM), or to the patient’s expectations?
Max Hamilton, who developed observer-rating scales, stated in 1977: “I have some antipathy to self-rating scales….self-rating scales provide an excellent excuse for the investigator to avoid interviewing his patient…” which could be considered a conflict of interest. On the contrary, Mark Zimmerman who developed several self-rating scales stated: “clinician-rated scales are time consuming, require training to ensure the ratings are reliable and valid, and may be prone to clinician bias. Self-report questionnaires are inexpensive in terms of professional time needed for incorporation into the clinical encounter, they do not require special training for administration, and they correlate highly with clinician ratings. Moreover, self-report scales are free of clinician bias and are therefore free from the potential risk of clinician overestimation of patient improvement (which might occur when there is incentive to document treatment success)”[Reference Zimmerman, Walsh, Friedman, Boerescu and Attiullah25].
The 21 items of the BDI-I [Reference Beck, Ward, Mendelson, Mock and Erbaugh21] were originally biased toward cognitive behavior theory and therapy and comprise many cognitive items, but the BDI-II changed the time frame (during the last 2 weeks instead of during the last week in BDI-I) [Reference Beck, Steer and Brown20] and changed some items in order to reflect more closely DSM-IV symptomatic diagnostic criteria for major depressive disorder. One step further in the reification of DSM was the development of the nine-item Patient Health Questionnaire mirroring the nine DSM criteria [Reference Kroenke, Spitzer and Williams67]. The HAMD items closely reflect the effects (efficacy as well as sedative side effects) of tricyclics, while the MADRS closely reflects the improvements obtained with a variety of antidepressants.
Important discrepancies do exist between the content of most depression scales and what matters to patients [Reference Fava, Tomba and Tossani68]. Patients rather want to know what are the chances they can get back to work, whether they will be able to fully resume their role as a partner or parent, and whether they will be able again to engage in pleasant activities [Reference Gilbody, Wahlbeck and Adams69,Reference Zimmerman, Martinez, Young, Chelminski and Dalrymple70]. When patients and caregivers were asked what they consider important in being cured from depression, caregivers emphasize the reduction of depressive symptoms, while patients take a greater interest in restoration of a meaningful life and in return of positive affect [Reference Demyttenaere, Donneau, Albert, Ansseau, Constant and van Heeringen71]. However, the concept of positive affect (and associated concepts: hedonic tone, pleasure, motivation, and reward) is at the risk of simplification: it has been suggested that a better disentangling of these concepts is helpful in understanding their neurobiological underpinnings [Reference Moccia, Mazza, Di Nicola and Janiri72].
Several attempts were made to develop scales based on patient’s expectations. The Remission from Depression Questionnaire [Reference Zimmerman, Galione, Attiullah, Friedman, Toba and Boerescu73] also assesses positive mental health, functioning, life satisfaction, and general sense of well-being and the LAPS [Reference Demyttenaere, Mortier, Kiekens and Bruffaerts54] assessing positive and negative affect, hedonic tone, (cognitive) functioning, meaningfulness of life, and happiness.
Conclusions
Assessment of severity of depressive symptomatology and of changes in severity during treatment is still suboptimal. It is remarkable that many clinicians do not routinely use scales in their daily practices: they should use at least one quantitative measure to assess clinical changes during treatment while accepting the reductionistic nature of it. Which scale should be used is maybe of only secondary importance compared to using at least one, despite being aware of the limitations. The present paper aims to give a framework facilitating the clinician’s or researcher’s orientation among scales commonly used in depression research: the choice is between observer-rating and self-rating scales, between disease-specific and non–disease-specific scales, between site rating and centralized rating, between subjective and objective (lab) rating, and between questionnaires versus experience sampling methods. The use of depression rating scales is highly recommended in clinical practice, as long as one realizes and accepts that “a rating scale is only a particular device for recording information about a patient…for clinical purposes, the best way of describing a patient is by a free and full psychiatric case history”[Reference Hamilton12].
Conflicts of interest
The authors declare no conflicts of interest.


 Open access
Open access
Comments
No Comments have been published for this article.