
FirstView articles
Contents
Research Article
Structural priming facilitates L2 learning of the dative alternation in Mandarin
-
- Published online by Cambridge University Press:
- 18 September 2024, pp. 1-23
-
- Article
- Export citation
Methods Forum
Task-generated processes in second language speech production: Exploring the neural correlates of task complexity during silent pauses
-
- Published online by Cambridge University Press:
- 18 September 2024, pp. 1-27
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Research Article
Explicit information and practice type can affect the L2 acquisition of plural marking: Empirical insights from web-based contrastive instruction
-
- Published online by Cambridge University Press:
- 16 September 2024, pp. 1-32
-
- Article
- Export citation
Replication Study
First language effects on incidental vocabulary learning through bimodal input: A multisite, preregistered, and close replication of Malone (2018)
-
- Published online by Cambridge University Press:
- 27 June 2024, pp. 1-26
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Research Article
Bilingualism and flexibility in task switching: A close replication study
-
- Published online by Cambridge University Press:
- 23 May 2024, pp. 1-17
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Acceptance and engagement patterns of mobile-assisted language learning among non-conventional adult L2 learners: A survival analysis
-
- Published online by Cambridge University Press:
- 22 May 2024, pp. 1-27
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Coherence and Comprehensibility in Second Language Speakers’ Academic Speaking Performance
-
- Published online by Cambridge University Press:
- 20 May 2024, pp. 1-23
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The Interplay of Mindsets, Aptitude, Grit, and Language Achievement: What Role Does Gender Play?
-
- Published online by Cambridge University Press:
- 20 May 2024, pp. 1-24
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Replication Study
Statistical Insignificance is not wholesale transfer in L3 Acquisition: an approximate replication of Rothman (2011)
-
- Published online by Cambridge University Press:
- 13 May 2024, pp. 1-18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
This study was an approximate replication of Rothman (2011),examining the determiner phrase syntax of a large sample (n = 211) of L3 learners of Portuguese who spoke English and Spanish. Rothman (2011) investigated whether L3 Italian or Brazilian Portuguese speakers are differently impacted by another known Romance Language, if it was their L1 or L2. The original study concluded that groups did not perform differently on experimental tasks on the basis of a null effect, and that the typological similarity of Spanish, Portuguese, or Italian predicts transfer in the initial stages of L3 acquisition. The present replication recreated all materials, which were unavailable, and examined the same population and questions. However, rather than examining L3 Italian and L3 Brazilian Portuguese, the present work maintained a constant L3 Portuguese. Learners were divided into two groups in a mirror-image design (n = 96 L1 English-L2 Spanish, n = 115 L1 Spanish-L2 English), and data were collected online. Like the original study, there was no main effect of group in any of the two-way analyses of variance. However, results show that it should not be assumed that experimental groups behave equivalently based on a null effect: Of the four total post hoc tests of equivalence, only two were significant when the equivalence bounds were set at a small effect size (d =
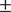 $ \pm $ .4). Ultimately, it is argued that determining the smallest effect size of interest and subsequent equivalence testing are necessary to answer key questions in the field of L3 acquisition.
$ \pm $ .4). Ultimately, it is argued that determining the smallest effect size of interest and subsequent equivalence testing are necessary to answer key questions in the field of L3 acquisition.
Research Article
How well are primary and secondary meanings of L2 words acquired?
-
- Published online by Cambridge University Press:
- 09 May 2024, pp. 1-23
-
- Article
- Export citation
Foreign Language Learning Boredom: Refining its Measurement and Determining its Role in Language Learning
-
- Published online by Cambridge University Press:
- 08 May 2024, pp. 1-28
-
- Article
- Export citation
L2 Language Development in Oral and Written Modalities
-
- Published online by Cambridge University Press:
- 08 May 2024, pp. 1-28
-
- Article
- Export citation
Research Report
Feeling signs: motor encoding enhances sign language learning in hearing adults
-
- Published online by Cambridge University Press:
- 29 April 2024, pp. 1-13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Research Article
The effects of distributed practice on second language fluency development
-
- Published online by Cambridge University Press:
- 22 April 2024, pp. 1-25
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Erratum
Clarifying the role of inhibitory control in L2 phonological processing: A preregistered, close replication of Darcy et al. (2016) – ERRATUM
-
- Published online by Cambridge University Press:
- 17 April 2024, p. 1
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Research Article
Effects of retrieval schedules on the acquisition of explicit, automatized-explicit, and implicit knowledge of L2 collocations
-
- Published online by Cambridge University Press:
- 17 April 2024, pp. 1-23
-
- Article
- Export citation
Replication Study
Development of verb argument constructions in L2 English learners: A close replication of research question 3 in Römer and Berger (2019)
-
- Published online by Cambridge University Press:
- 05 April 2024, pp. 1-19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Clarifying the role of inhibitory control in L2 phonological processing: A preregistered, close replication of Darcy et al. (2016)
-
- Published online by Cambridge University Press:
- 04 April 2024, pp. 1-21
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Robust evidence for the simple view of second language reading: Secondary meta-analysis of Jeon and Yamashita (2022)
-
- Published online by Cambridge University Press:
- 04 April 2024, pp. 1-18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The interpretation of verbal moods in Spanish: A close replication of Kanwit and Geeslin (2014)
-
- Published online by Cambridge University Press:
- 02 April 2024, pp. 1-18
-
- Article
-
- You have access
- Open access
- HTML
- Export citation