



1. Introduction
Personality refers to the relatively stable disposition of an individual that influences long-term behavioral style (Back, Schmukle, & Egloff, Reference Back, Schmukle and Egloff2009; Furr, Reference Furr2009; Hong, Paunonen, & Slade, Reference Hong, Paunonen and Slade2008; Jaccard, Reference Jaccard1974). It is especially conspicuous in social interactions, and in emotional expression. It is what we pick up on when we observe a person for an extended time, and what leads us to make predictions about general tendencies in behaviors and interactions in the future. Often, these predictions are inaccurate stereotypes, and they can be evoked even by very fleeting impressions, such as merely looking at photographs of people (Todorov, Reference Todorov2017). Yet there is also good reliability (Viswesvaran & Ones, Reference Viswesvaran and Ones2000) and consistency (Roberts & DelVecchio, Reference Roberts and DelVecchio2000) for many personality traits currently used in psychology, which can predict real-life outcomes (Roberts, Kuncel, Shiner, Caspi, & Goldberg, Reference Roberts, Kuncel, Shiner, Caspi and Goldberg2007).
While human personality traits are typically inferred from questionnaires, viewed as latent variables they could plausibly be derived also from other measures. In fact, there are good reasons to think that biological measures other than self-reported questionnaires can be used to estimate personality traits. Many of the personality traits similar to those used to describe human dispositions can be applied to animal behavior as well, and again they make some predictions about real-life outcomes (Gosling & John, Reference Gosling and John1999; Gosling & Vazire, Reference Gosling and Vazire2002). For instance, anxious temperament has been a major topic of study in monkeys, as a model of human mood disorders. Hyenas show neuroticism in their behavior, and also show sex differences in this trait as would be expected from human data (in humans, females tend to be more neurotic than males; in hyenas, the females are socially dominant and the males are more neurotic). Personality traits are also highly heritable. Anxious temperament in monkeys is heritable and its neurobiological basis is being intensively investigated (Oler et al., Reference Oler, Fox, Shelton, Rogers, Dyer, Davidson and … Kalin2010). Twin studies in humans typically report heritability estimates for each trait between 0.4 and 0.6 (Bouchard & McGue, Reference Bouchard and McGue2003; Jang, Livesley, & Vernon, Reference Jang, Livesley and Vernon1996; Verweij et al., Reference Verweij, Zietsch, Medland, Gordon, Benyamin, Nyholt and … Wray2010), even though no individual genes account for much variance (studies using common single-nucleotide polymorphisms report estimates between 0 and 0.2; see Power & Pluess, Reference Power and Pluess2015; Vinkhuyzen et al., Reference Vinkhuyzen, Pedersen, Yang, Lee, Magnusson, Iacono and … Wray2012).
Just as gene–environment interactions constitute the distal causes of our phenotype, the proximal cause of personality must come from brain–environment interactions, since these are the basis for all behavioral patterns. Some aspects of personality have been linked to specific neural systems—for instance, behavioral inhibition and anxious temperament have been linked to a system involving the medial temporal lobe and the prefrontal cortex (Birn et al., Reference Birn, Shackman, Oler, Williams, McFarlin, Rogers and … Kalin2014). Although there is now universal agreement that personality is generated through brain function in a given context, it is much less clear what type of brain measure might be the best predictor of personality. Neurotransmitters, cortical thickness or volume of certain regions, and functional measures have all been explored with respect to their correlation with personality traits (for reviews see Canli, Reference Canli2006; Yarkoni, Reference Yarkoni2015). We briefly summarize this literature next and refer the interested reader to review articles and primary literature for the details.
1.1 The search for neurobiological substrates of personality traits
Since personality traits are relatively stable over time (unlike state variables, such as emotions), one might expect that brain measures that are similarly stable over time are the most promising candidates for predicting such traits. The first types of measures to look at might thus be structural, connectional, and neurochemical; indeed a number of such studies have reported correlations with personality differences. Here, we briefly review studies using structural and functional magnetic resonance imaging (fMRI) of humans, but leave aside research on neurotransmission. Although a number of different personality traits have been investigated, we emphasize those most similar to the “Big Five,” since they are the topic of the present paper (see below).
1.1.1 Structural magnetic resonance imaging (MRI) studies
Many structural MRI studies of personality to date have used voxel-based morphometry (Blankstein, Chen, Mincic, McGrath, & Davis, Reference Blankstein, Chen, Mincic, McGrath and Davis2009; Coutinho, Sampaio, Ferreira, Soares, & Gonçalves, Reference Coutinho, Sampaio, Ferreira, Soares and Gonçalves2013; DeYoung et al., Reference DeYoung, Hirsh, Shane, Papademetris, Rajeevan and Gray2010; Hu et al., Reference Hutton, Draganski, Ashburner and Weiskopf2011; Kapogiannis, Sutin, Davatzikos, Costa, & Resnick, Reference Kapogiannis, Sutin, Davatzikos, Costa and Resnick2013; Liu et al., Reference Liu, Weber, Reuter, Markett, Chu and Montag2013; Lu et al., Reference Lu, Huo, Li, Chen, Liu, Wang and … Chen2014; Omura, Constable, & Canli, Reference Omura, Todd Constable and Canli2005; Taki et al., Reference Taki, Thyreau, Kinomura, Sato, Goto, Wu and … Fukuda2013). Results have been quite variable, sometimes even contradictory (e.g., the volume of the posterior cingulate cortex has been found to be both positively and negatively correlated with agreeableness; see DeYoung et al., Reference DeYoung, Hirsh, Shane, Papademetris, Rajeevan and Gray2010; Coutinho et al., Reference Coutinho, Sampaio, Ferreira, Soares and Gonçalves2013). Methodologically, this is in part due to the rather small sample sizes (typically less than 100; 116 in DeYoung et al., Reference DeYoung, Hirsh, Shane, Papademetris, Rajeevan and Gray2010; 52 in Coutinho et al., Reference Coutinho, Sampaio, Ferreira, Soares and Gonçalves2013) which undermine replicability (Button et al., Reference Button, Ioannidis, Mokrysz, Nosek, Flint, Robinson and Munafò2013); studies with larger sample sizes (Liu et al., Reference Liu, Weber, Reuter, Markett, Chu and Montag2013) typically fail to replicate previous results.
More recently, surface-based morphometry has emerged as a promising measure to study structural brain correlates of personality (Bjørnebekk et al., Reference Bjørnebekk, Fjell, Walhovd, Grydeland, Torgersen and Westlye2013; Holmes et al., Reference Holmes, Lee, Hollinshead, Bakst, Roffman, Smoller and Buckner2012; Rauch et al., Reference Rauch, Milad, Orr, Quinn, Fischl and Pitman2005; Riccelli, Toschi, Nigro, Terracciano, & Passamonti, Reference Riccelli, Toschi, Nigro, Terracciano and Passamonti2017; Wright et al., Reference Wright, Williams, Feczko, Barrett, Dickerson, Schwartz and Wedig2006). It has the advantage of disentangling several geometric aspects of brain structure which may contribute to differences detected in voxel-based morphometry, such as cortical thickness (Hutton, Draganski, Ashburner, & Weiskopf, Reference Hu, Erb, Ackermann, Martin, Grodd and Reiterer2009), cortical volume, and folding. Although many studies using surface-based morphometry are once again limited by small sample sizes, one recent study (Riccelli et al., Reference Riccelli, Toschi, Nigro, Terracciano and Passamonti2017) used 507 subjects to investigate personality, although it had other limitations (e.g., using a correlational, rather than a predictive framework; see Dubois & Adolphs, Reference Dubois and Adolphs2016; Woo, Chang, Lindquist, & Wager, Reference Woo, Chang, Lindquist and Wager2017; Yarkoni & Westfall, Reference Yarkoni and Westfall2017).
There is much room for improvement in structural MRI studies of personality traits. The limitation of small sample sizes can now be overcome, since all MRI studies regularly collect structural scans, and recent consortia and data sharing efforts have led to the accumulation of large publicly available data sets (Job et al., Reference Job, Dickie, Rodriguez, Robson, Danso, Pernet and … Wardlaw2017; Miller et al., Reference Miller, Alfaro-Almagro, Bangerter, Thomas, Yacoub, Xu and … Smith2016; Van Essen et al., Reference Van Essen, Smith, Barch, Behrens, Yacoub and Ugurbil2013). One could imagine a mechanism by which personality assessments, if not available already within these data sets, are collected later (Mar, Spreng, & Deyoung, Reference Mar, Spreng and Deyoung2013), yielding large samples for relating structural MRI to personality. Lack of out-of-sample generalizability, a limitation of almost all studies that we raised above, can be overcome using cross-validation techniques, or by setting aside a replication sample. In short: despite a considerable historical literature that has investigated the association between personality traits and structural MRI measures, there are as yet no very compelling findings because prior studies have been unable to surmount this list of limitations.
1.1.2 Diffusion MRI studies
Several studies have looked for a relationship between white-matter integrity as assessed by diffusion tensor imaging and personality factors (Cohen, Schoene-Bake, Elger, & Weber, Reference Cohen, Schoene-Bake, Elger and Weber2009; Kim & Whalen, Reference Kim and Whalen2009; Westlye, Bjørnebekk, Grydeland, Fjell, & Walhovd, Reference Westlye, Bjørnebekk, Grydeland, Fjell and Walhovd2011; Xu & Potenza, Reference Xu and Potenza2012). As with structural MRI studies, extant focal findings often fail to replicate with larger samples of subjects, which tend to find more widespread differences linked to personality traits (Bjørnebekk et al., Reference Bjørnebekk, Fjell, Walhovd, Grydeland, Torgersen and Westlye2013). The same concerns mentioned in the previous section, in particular the lack of a predictive framework (e.g., using cross-validation), plague this literature; similar recommendations can be made to increase the reproducibility of this line of research, in particular aggregating data (Miller et al., Reference Miller, Alfaro-Almagro, Bangerter, Thomas, Yacoub, Xu and … Smith2016; Van Essen et al., Reference Van Essen, Smith, Barch, Behrens, Yacoub and Ugurbil2013) and using out-of-sample prediction (Yarkoni & Westfall, Reference Yarkoni and Westfall2017).
1.1.3 fMRI studies
fMRI measures local changes in blood flow and blood oxygenation as a surrogate of the metabolic demands due to neuronal activity (Logothetis & Wandell, Reference Logothetis and Wandell2004). There are two main paradigms that have been used to relate fMRI data to personality traits: task-based fMRI and resting-state fMRI.
Task-based fMRI studies are based on the assumption that differences in personality may affect information-processing in specific tasks (Yarkoni, Reference Yarkoni2015). Personality variables are hypothesized to influence cognitive mechanisms, whose neural correlates can be studied with fMRI. For example, differences in neuroticism may materialize as differences in emotional reactivity, which can then be mapped onto the brain (Canli et al., Reference Canli, Zhao, Desmond, Kang, Gross and Gabrieli2001). There is a very large literature on task-fMRI substrates of personality, which is beyond the scope of this overview. In general, some of the same concerns we raised above also apply to task-fMRI studies, which typically have even smaller sample sizes (Yarkoni, Reference Yarkoni2009), greatly limiting power to detect individual differences (in personality or any other behavioral measures). Several additional concerns on the validity of fMRI-based individual differences research apply (Dubois & Adolphs, Reference Dubois and Adolphs2016) and a new challenge arises as well: whether the task used has construct validity for a personality trait.
The other paradigm, resting-state fMRI, offers a solution to the sample size problem, as resting-state data are often collected alongside other data, and can easily be aggregated in large online databases (Biswal et al., Reference Biswal, Mennes, Zuo, Gohel, Kelly, Smith and … Milham2010; Eickhoff, Nichols, Van Horn, & Turner, Reference Eickhoff, Nichols, Van Horn and Turner2016; Poldrack & Gorgolewski, Reference Poldrack and Gorgolewski2017; Van Horn & Gazzaniga, Reference Van Horn and Gazzaniga2013). It is the type of data we used in the present paper. Resting-state data does not explicitly engage cognitive processes that are thought to be related to personality traits. Instead, it is used to study correlated self-generated activity between brain areas while a subject is at rest. These correlations, which can be highly reliable given enough data (Finn et al., Reference Finn, Shen, Scheinost, Rosenberg, Huang, Chun and … Constable2015; Laumann et al., Reference Laumann, Gordon, Adeyemo, Snyder, Joo, Chen and … Petersen2015; Noble et al., Reference Noble, Spann, Tokoglu, Shen, Constable and Scheinost2017), are thought to reflect stable aspects of brain organization (Shen et al., Reference Shen, Finn, Scheinost, Rosenberg, Chun, Papademetris and Constable2017; Smith et al., Reference Smith, Vidaurre, Glasser, Winkler, McCarthy, Robinson and … Van Essen2013). There is a large ongoing effort to link individual variations in functional connectivity (FC) assessed with resting-state fMRI to individual traits and psychiatric diagnosis (for reviews see Dubois & Adolphs, Reference Dubois and Adolphs2016; Orrù, Pettersson-Yeo, Marquand, Sartori, & Mechelli, Reference Orrù, Pettersson-Yeo, Marquand, Sartori and Mechelli2012; Smith et al., Reference Smith, Vidaurre, Glasser, Winkler, McCarthy, Robinson and … Van Essen2013; Woo et al., Reference Woo, Chang, Lindquist and Wager2017).
A number of recent studies have investigated FC markers from resting-state fMRI and their association with personality traits (Adelstein et al., Reference Adelstein, Shehzad, Mennes, Deyoung, Zuo, Kelly and … Milham2011; Aghajani et al., Reference Aghajani, Veer, van Tol, Aleman, van Buchem, Veltman and … van der Wee2014; Baeken et al., Reference Baeken, Marinazzo, Van Schuerbeek, Wu, De Mey, Luypaert and De Raedt2014; Beaty et al., Reference Beaty, Benedek, Wilkins, Jauk, Fink, Silvia and … Neubauer2014, Reference Beaty, Kaufman, Benedek, Jung, Kenett, Jauk and … Silvia2016; Gao et al., Reference Gao, Xu, Duan, Liao, Ding, Zhang and … Chen2013; Jiao et al., Reference Jiao, Zhang, Liang, Liang, Wang, Li and … Liu2017; Lei, Zhao, & Chen, Reference Lei, Zhao and Chen2013; Pang et al., Reference Pang, Cui, Wang, Chen, Wang, Han and … Chen2016; Ryan, Sheu, & Gianaros, Reference Ryan, Sheu and Gianaros2011; Takeuchi et al., Reference Takeuchi, Taki, Hashizume, Sassa, Nagase, Nouchi and Kawashima2012; Wu, Li, Yuan, & Tian, Reference Wu, Li, Yuan and Tian2016). Somewhat surprisingly, these resting-state fMRI studies typically also suffer from low sample sizes (typically less than 100 subjects, usually about 40), and the lack of a predictive framework to assess effect size out-of-sample. One of the best extant data sets, the Human Connectome Project (HCP) has only in the past year reached its full sample of over 1,000 subjects, now making large sample sizes readily available. To date, only the exploratory “MegaTrawl” (Smith et al., Reference Smith, Vidaurre, Beckmann, Glasser, Jenkinson, Miller and … Van Essen2016) has investigated personality in this database; we believe that ours is the first comprehensive study of personality on the full HCP data set, offering very substantial improvements over all prior work.
1.2 Measuring personality
Although there are a number of different schemes and theories for quantifying personality traits, by far the most common and well validated one, and also the only one available for the HCP data set, is the five-factor solution of personality (aka “The Big Five”). This was originally identified through systematic examination of the adjectives in English language that are used to describe human traits. Based on the hypothesis that all important aspects of human personality are reflected in language, Raymond Cattell (Reference Cattell1945) applied factor analysis to peer ratings of personality and identified 16 common personality factors. Over the next three decades, multiple attempts to replicate Cattell’s study using a variety of methods (e.g., self-description and description of others with adjective lists and behavioral descriptions) agreed that the taxonomy of personality could be robustly described through a five-factor solution (Borgatta, Reference Borgatta1964; Fiske, Reference Fiske1949; Norman, Reference Norman1963; Smith, Reference Smith1967; Tupes & Christal, Reference Tupes and Christal1961). Since the 1980s, the Big Five has emerged as the leading psychometric model in the field of personality psychology (Goldberg, Reference Goldberg1981; McCrae & John, Reference McCrae and Costa1992). The five factors are commonly termed “openness to experience,” “conscientiousness,” “extraversion,” “agreeableness,” and “neuroticism.”
While the Big Five personality dimensions are not based on an independent theory of personality, and in particular have no basis in neuroscience theories of personality, proponents of the Big Five maintain that they provide the best empirically based integration of the dominant theories of personality, encompassing the alternative theories of Cattell, Guilford, and Eysenck (Amelang & Borkenau, Reference Amelang and Borkenau1982). Self-report questionnaires, such as the Neuroticism/Extraversion/Openness Five-Factor Inventory (NEO-FFI) (McCrae & Costa, Reference McCrae and Costa2004), can be used to reliably assess an individual with respect to these five factors. Even though there remain critiques of the Big Five (Block, Reference Block1995; Uher, Reference Uher2015), its proponents argue that its five factors “are both necessary and reasonably sufficient for describing at a global level the major features of personality” (McCrae & Costa, Reference McCrae and Costa1986).
1.3 The present study
As we emphasized above, personality neuroscience based on MRI data confronts two major challenges. First, nearly all studies to date have been severely underpowered due to small sample sizes (Button et al., Reference Button, Ioannidis, Mokrysz, Nosek, Flint, Robinson and Munafò2013; Schönbrodt & Perugini, Reference Schönbrodt and Perugini2013; Yarkoni, Reference Yarkoni2009). Second, most studies have failed to use a predictive or replication framework (but see Deris, Montag, Reuter, Weber, & Markett, Reference Deris, Montag, Reuter, Weber and Markett2017), making their generalizability unclear—a well-recognized problem in neuroscience studies of individual differences (Dubois & Adolphs, Reference Dubois and Adolphs2016; Gabrieli, Ghosh, & Whitfield-Gabrieli, Reference Gabrieli, Ghosh and Whitfield-Gabrieli2015; Yarkoni & Westfall, Reference Yarkoni and Westfall2017). The present paper takes these two challenges seriously by applying a predictive framework, together with a built-in replication, to a large, homogeneous resting-state fMRI data set. We chose to focus on resting-state fMRI data to predict personality, because this is a predictor that could have better mechanistic interpretation than structural MRI measures (since ultimately it is brain function, not structure, that generates the behavior on the basis of which we can infer personality).
Our data set, the HCP resting-state fMRI data (HCP rs-fMRI) makes available over 1,000 well-assessed healthy adults. With respect to our study, it provided three types of relevant data: (1) substantial high-quality resting-state fMRI (two sessions per subject on separate days, each consisting of two 15 min 24 s runs, for ~1 hr total); (2) personality assessment for each subject (using the NEO-FFI 2); (3) additional basic cognitive assessment (including fluid intelligence and others), as well as demographic information, which can be assessed as potential confounds.
Our primary question was straightforward: given the challenges noted above, is it possible to find evidence that any personality trait can be reliably predicted from fMRI data, using the best available resting-state fMRI data set together with the best generally used current analysis methods? If the answer to this question is negative, this might suggest that studies to date that have claimed to find associations between resting-state fMRI and personality are false positives (but of course it would still leave open future positive findings, if more sensitive measures are available). If the answer is positive, it would provide an estimate of the effect size that can be expected in future studies; it would provide initial recommendations for data preprocessing, modeling, and statistical treatment; and it would provide a basis for hypothesis-driven investigations that could focus on particular traits and brain regions. As a secondary aim, we wanted to explore the sensitivity of the results to the details of the analysis used and gain some reassurance that any positive findings would be relatively robust with respect to the details of the analysis; we therefore used a few (well established) combinations of intersubject alignment, preprocessing, and learning models. This was not intended as a systematic, exhaustive foray into all choices that could be made; such an investigation would be extremely valuable, yet was outside the scope of this work.
2. Methods
2.1. Data set
We used data from a public repository, the 1,200 subjects release of the HCP (Van Essen et al., Reference Van Essen, Smith, Barch, Behrens, Yacoub and Ugurbil2013). The HCP provides MRI data and extensive behavioral assessment from almost 1,200 subjects. Acquisition parameters and “minimal” preprocessing of the resting-state fMRI data are described in the original publication (Glasser et al., Reference Glasser, Sotiropoulos, Wilson, Coalson, Fischl and Andersson2013). Briefly, each subject underwent two sessions of resting-state fMRI on separate days, each session with two separate 14min34s acquisitions generating 1,200 volumes (customized Siemens Skyra [Siemens Medical Solutions, NJ, USA] 3 Tesla MRI scanner, repetition time (TR)=720 ms, echo time (TE)=33 ms, flip angle=52°, voxel size=2 mm isotropic, 72 slices, matrix=104×90, field of view (FOV)=208×180 mm, multiband acceleration factor=8). The two runs acquired on the same day differed in the phase encoding direction, left-right and right-left (which leads to differential signal intensity especially in ventral temporal and frontal structures). The HCP data were downloaded in its minimally preprocessed form, that is, after motion correction, B 0 distortion correction, coregistration to T1-weighted images and normalization to Montreal Neurological Institute (MNI) space (the T1w image is registered to MNI space with a FLIRT 12 DOF affine and then a FNIRT nonlinear registration, producing the final nonlinear volume transformation from the subject’s native volume space to MNI space).
2.2. Personality assessment, and personality factors
The 60-item version of the Costa and McCrae NEO-FFI, which has shown excellent reliability and validity (McCrae & Costa, Reference McCrae and Costa2004), was administered to HCP subjects. This measure was collected as part of the Penn Computerized Cognitive Battery (Gur et al., Reference Gur, Ragland, Moberg, Turner, Bilker, Kohler and … Gur2001, Reference Gur, Richard, Hughett, Calkins, Macy, Bilker and … Gur2010). Note that the NEO-FFI was recently updated (NEO-FFI-3, 2010), but the test administered to the HCP subjects is the older version (NEO-FFI-2, 2004).
The NEO-FFI is a self-report questionnaire—the abbreviated version of the 240-item Neuroticism/Extraversion/Openness Personality Inventory Revised (Costa & McCrae, Reference Costa and McCrae1992). For each item, participants reported their level of agreement on a 5-point Likert scale, from strongly disagree to strongly agree.
The Openness, Conscientiousness, Extraversion, Agreeableness, and Neuroticism scores are derived by coding each item’s answer (strongly disagree=0; disagree=1; neither agree nor disagree=2; agree=3; strongly agree=4) and then reverse coding appropriate items and summing into subscales. As the item scores are available in the database, we recomputed the Big Five scores with the following item coding published in the NEO-FFI two manual, where * denotes reverse coding:
∙ Openness: (3*, 8*, 13, 18*, 23*, 28, 33*, 38*, 43, 48*, 53, 58)
∙ Conscientiousness: (5, 10, 15*, 20, 25, 30*, 35, 40, 45*, 50, 55*, 60)
∙ Extraversion: (2, 7, 12*, 17, 22, 27*, 32, 37, 42*, 47, 52, 57*)
∙ Agreeableness: (4, 9*, 14*, 19, 24*, 29*, 34, 39*, 44*, 49, 54*, 59*)
∙ Neuroticism: (1*, 6, 11, 16*, 21, 26, 31*, 36, 41, 46*, 51, 56)
We note that the Agreeableness factor score that we calculated was slightly discrepant with the score in the HCP database due to an error in the HCP database in not reverse-coding item 59 at that time (downloaded 06/07/2017). This issue was reported on the HCP listserv (Gray, Reference Gray2017).
To test the internal consistency of each of the Big Five personality traits in our sample, Cronbach’s α was calculated.
Each of the Big Five personality traits can be decomposed into further facets (Costa & McCrae, Reference Costa and McCrae1995), but we did not attempt to predict these facets from our data. Not only does each facet rely on fewer items and thus constitutes a noisier measure, which necessarily reduces predictability from neural data (Gignac & Bates, Reference Gignac and Bates2017); also, trying to predict many traits leads to a multiple comparison problem which then needs to be accounted for (for an extreme example, see the HCP “MegaTrawl” Smith et al., Reference Smith, Vidaurre, Beckmann, Glasser, Jenkinson, Miller and … Van Essen2016).
Despite their theoretical orthogonality, the Big Five are often found to be correlated with one another in typical subject samples. Some authors have suggested that these intercorrelations suggest a higher-order structure, and two superordinate factors have been described in the literature, often referred to as {α/socialization/stability} and {β/personal growth/plasticity} (Blackburn, Renwick, Donnelly, & Logan, Reference Blackburn, Renwick, Donnelly and Logan2004; DeYoung, Reference DeYoung2006; Digman, Reference Digman1997). The theoretical basis for the existence of these superordinate factors is highly debated (McCrae et al., Reference McCrae, Yamagata, Jang, Riemann, Ando, Ono and … Spinath2008), and it is not our intention to enter this debate. However, these superordinate factors are less noisy (have lower associated measurement error) than the Big Five, as they are derived from a larger number of test items; this may improve predictability (Gignac & Bates, Reference Gignac and Bates2017). Hence, we performed a principal component analysis (PCA) on the five-factor scores to extract two orthogonal superordinate components, and tested the predictability of these from the HCP rs-fMRI data, in addition to the original five factors.
While we used resting-state fMRI data from two separate sessions (typically collected on consecutive days), there was only a single set of behavioral data available; the NEO-FFI was typically administered on the same day as the second session of resting-state fMRI (Van Essen et al., Reference Van Essen, Smith, Barch, Behrens, Yacoub and Ugurbil2013).
2.3. Fluid intelligence assessment
An estimate of fluid intelligence is available as the PMAT24_A_CR measure in the HCP data set. This proxy for fluid intelligence is based on a short version of Raven’s progressive matrices (24 items) (Bilker et al., Reference Bilker, Hansen, Brensinger, Richard, Gur and Gur2012); scores are integers indicating number of correct items. We used this fluid intelligence score for two purposes: (i) as a benchmark comparison in our predictive analyses, since others have previously reported that this measure of fluid intelligence could be predicted from resting-state fMRI in the HCP data set (Finn et al., Reference Finn, Shen, Scheinost, Rosenberg, Huang, Chun and … Constable2015; Noble et al., Reference Noble, Spann, Tokoglu, Shen, Constable and Scheinost2017); (ii) as a deconfounding variable (see “Assessment and removal of potential confounds” below). Note that we recently performed a factor analysis of the scores on all cognitive tasks in the HCP to derive a more reliable measure of intelligence; this g-factor could be predicted better than the 24-item score from resting-state data (Dubois, Galdi, Paul, & Adolphs, Reference Dubois, Galdi, Paul and Adolphs2018).
2.4. Subject selection
The total number of subjects in the 1,200-subject release of the HCP data set is N=1206. We applied the following criteria to include/exclude subjects from our analyses (listing in parentheses the HCP database field codes). (i) Complete neuropsychological data sets. Subjects must have completed all relevant neuropsychological testing (PMAT_Compl=True, NEO-FFI_Compl=True, Non-TB_Compl=True, VisProc_Compl=True, SCPT_Compl=True, IWRD_Compl=True, VSPLOT_Compl=True) and the Mini Mental Status Exam (MMSE_Compl=True). Any subjects with missing values in any of the tests or test items were discarded. This left us with N=1183 subjects. (ii) Cognitive compromise. We excluded subjects with a score of 26 or below on the Mini Mental Status Exam, which could indicate marked cognitive impairment in this highly educated sample of adults under age 40 (Crum, Anthony, Bassett, & Folstein, Reference Crum, Anthony, Bassett and Folstein1993). This left us with N=1181 subjects (638 females, 28.8±3.7 years old [y.o.], range 22–37 y.o). Furthermore, (iii) subjects must have completed all resting-state fMRI scans (3T_RS-fMRI_PctCompl=100), which leaves us with N=988 subjects. Finally, (iv) we further excluded subjects with a root mean squared (RMS) frame-to-frame head motion estimate (Movement_Relative_RMS.txt) exceeding 0.15 mm in any of the four resting-state runs (threshold similar to Finn et al., Reference Finn, Shen, Scheinost, Rosenberg, Huang, Chun and … Constable2015). This left us with the final sample of N=884 subjects (Table S1; 475 females, 28.6±3.7 y.o., range 22–36 y.o.) for predictive analyses based on resting-state data.
2.5. Assessment and removal of potential confounds
We computed the correlation of each of the personality factors with gender (Gender), age (Age_in_Yrs, restricted), handedness (Handedness, restricted), and fluid intelligence (PMAT24_A_CR). We also looked for differences in personality in our subject sample with other variables that are likely to affect FC matrices, such as brain size (we used FS_BrainSeg_Vol), motion (we computed the sum of framewise displacement in each run), and the multiband reconstruction algorithm which changed in the third quarter of HCP data collection (fMRI_3T_ReconVrs). Correlations are shown in Figure 2a. We then used multiple linear regression to regress these variables from each of the personality scores and remove their confounding effects.
Note that we do not control for differences in cortical thickness and other morphometric features, which have been reported to be correlated with personality factors (e.g. Riccelli et al., Reference Riccelli, Toschi, Nigro, Terracciano and Passamonti2017). These likely interact with FC measures and should eventually be accounted for in a full model, yet this was deemed outside the scope of the present study.
The five personality factors are intercorrelated to some degree (see Results, Figure 2a). We did not orthogonalize them—consequently predictability would be expected also to correlate slightly among personality factors.
It could be argued that controlling for variables such as gender and fluid intelligence risks producing a conservative, but perhaps overly pessimistic picture. Indeed, there are well-established gender differences in personality (Feingold, Reference Feingold1994; Schmitt, Realo, Voracek, & Allik, Reference Schmitt, Realo, Voracek and Allik2008), which might well be based on gender differences in FC (similar arguments can be made with respect to age [Allemand, Zimprich, & Hendriks, Reference Allemand, Zimprich and Hendriks2008; Soto, John, Gosling, & Potter, Reference Soto, John, Gosling and Potter2011] and fluid intelligence [Chamorro-Premuzic & Furnham, Reference Chamorro-Premuzic and Furnham2004; Rammstedt, Danner, & Martin, Reference Rammstedt, Danner and Martin2016]). Since the causal primacy of these variables with respect to personality is unknown, it is possible that regressing out sex and age could regress out substantial meaningful information about personality. We therefore also report supplemental results with a less conservative de-confounding procedure—only regressing out obvious confounds which are not plausibly related to personality, but which would plausibly influence FC data: image reconstruction algorithm, framewise displacement, and brain size measures.
2.6. Data preprocessing
Resting-state data must be preprocessed beyond “minimal preprocessing,” due to the presence of multiple noise components, such as subject motion and physiological fluctuations. Several approaches have been proposed to remove these noise components and clean the data, however, the community has not yet reached a consensus on the “best” denoising pipeline for resting-state fMRI data (Caballero-Gaudes & Reynolds, Reference Caballero-Gaudes and Reynolds2017; Ciric et al., Reference Ciric, Wolf, Power, Roalf, Baum, Ruparel and … Satterthwaite2017; Murphy & Fox, Reference Murphy and Fox2017; Siegel et al., Reference Siegel, Mitra, Laumann, Seitzman, Raichle, Corbetta and Snyder2017). Most of the steps taken to denoise resting-state data have limitations, and it is unlikely that there is a set of denoising steps that can completely remove noise without also discarding some of the signal of interest. Categories of denoising operations that have been proposed comprise tissue regression, motion regression, noise component regression, temporal filtering, and volume censoring. Each of these categories may be implemented in several ways. There exist several excellent reviews of the pros and cons of various denoising steps (Caballero-Gaudes & Reynolds, Reference Caballero-Gaudes and Reynolds2017; Liu, Reference Liu2016; Murphy, Birn, & Bandettini, Reference Murphy, Birn and Bandettini2013; Power et al., Reference Power, Mitra, Laumann, Snyder, Schlaggar and Petersen2014).
Here, instead of picking a single-denoising strategy combining steps used in the previous literature, we set out to explore three reasonable alternatives, which we refer to as A, B, and C (Figure 1c). To easily apply these preprocessing strategies in a single framework, using input data that is either volumetric or surface-based, we developed an in-house, Python (v2.7.14)-based pipeline, mostly based on open source libraries and frameworks for scientific computing including SciPy (v0.19.0), Numpy (v1.11.3), NiLearn (v0.2.6), NiBabel (v2.1.0), Scikit-learn (v0.18.1) (Abraham et al., Reference Abraham, Pedregosa, Eickenberg, Gervais, Mueller, Kossaifi and … Varoquaux2014; Gorgolewski et al., Reference Gorgolewski, Burns, Madison, Clark, Halchenko, Waskom and Ghosh2011; Gorgolewski et al., Reference Gorgolewski, Esteban, Ellis, Notter, Ziegler, Johnson and … Ghosh2017; Pedregosa et al., Reference Pedregosa, Varoquaux, Gramfort, Michel, Thirion, Grisel and … Duchesnay2011; Walt, Colbert, & Varoquaux, Reference Walt, Colbert and Varoquaux2011), implementing the most common denoising steps described in previous literature.
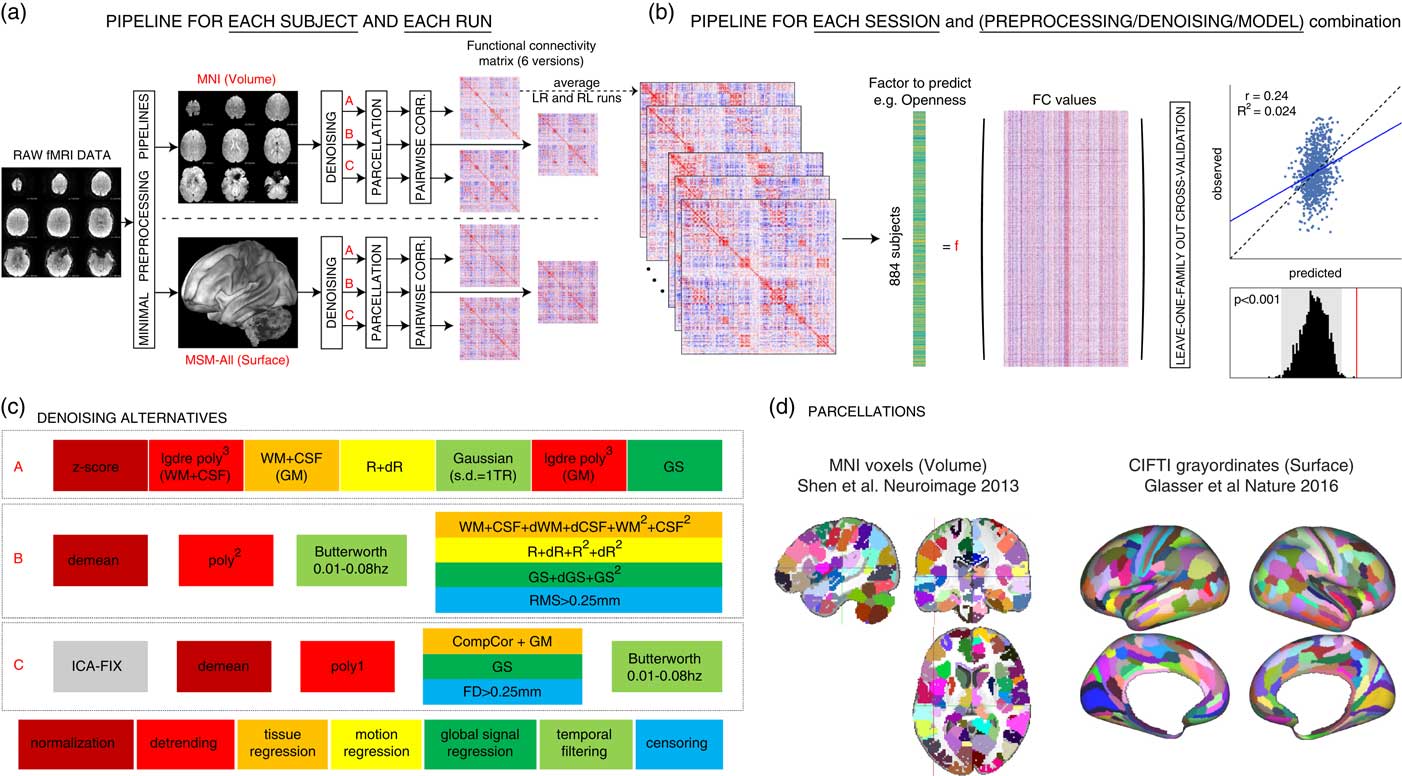
Figure 1 Overview of our approach. In total, we separately analyzed 36 different sets of results: two data sessions × two alignment/brain parcellation schemes × three preprocessing pipelines × three predictive models (univariate positive, univariate negative, and multivariate). (a) The data from each selected Human Connectome Project subject (N subjects=884) and each run (REST1_LR, REST1_RL, REST2_LR, REST2_RL) was downloaded after minimal preprocessing, both in MNI space, and in multimodal surface matching (MSM)-All space. The _LR and _RL runs within each session were averaged, producing two data sets that we call REST1 and REST2 henceforth. Data for REST1 and REST2, and for both spaces (MNI, MSM-All) were analyzed separately. We applied three alternate denoising pipelines to remove typical confounds found in resting-state functional magnetic resonance imaging (fMRI) data (see c). We then parcellated the data (see d) and built a functional connectivity matrix separately for each alternative. This yielded six functional connectivity (FC) matrices per run and per subject. In red: alternatives taken and presented in this paper. (b) For each of the six alternatives, an average FC matrix was computed for REST1 (from REST1_LR and REST1_RL), for REST2 (from REST2_LR and REST2_RL), and for all runs together, REST12. For a given session, we built a (N subjects×N edges) matrix, stacking the upper triangular part of all subjects’ FC matrices (the lower triangular part is discarded, because FC matrices are diagonally symmetric). Each column thus corresponds to a single entry in the upper triangle of the FC matrix (a pairwise correlation between two brain parcels, or edge) across all 884 subjects. There are a total of N parcels(N parcels−1)/2 edges (thus: 35,778 edges for the 268-node parcellation used in MNI space, 64,620 edges for the 360-node parcellation used in MSM-All space). This was the data from which we then predicted individual differences in each of the personality factors. We used two different linear models (see text), and a leave-one-family-out cross-validation scheme. The final result is a predicted score for each subject, against which we correlate the observed score for statistical assessment of the prediction. Permutations are used to assess statistical significance. (c) Detail of the three denoising alternatives. These are common denoising strategies for resting-state fMRI. The steps are color-coded to indicate the category of operation they correspond to (legend at the bottom) (see text for details). (d) The parcellations used for the MNI-space and MSM-All space, respectively. Parcels are randomly colored for visualization. Note that the parcellation used for MSM-All space does not include subcortical structures, while the parcellation used for MNI space does. WM=white matter; CSF=cerebrospinal fluid; GM=gray matter; dr=derivative of realignment parameters; GS=global signal; dWM=derivative of white matter signal; dCSF=derivative of CSF signal; dGS=derivative of global signal; CIFTI=Connectivity Informatics Technology Initiative; NEOFAC=revised NEO personality inventory factor.
Pipeline A reproduces as closely as possible the strategy described in (Finn et al., Reference Finn, Shen, Scheinost, Rosenberg, Huang, Chun and … Constable2015) and consists of seven consecutive steps: (1) the signal at each voxel is z-score normalized; (2) using tissue masks, temporal drifts from cerebrospinal fluid (CSF) and white matter (WM) are removed with third-degree Legendre polynomial regressors; (3) the mean signals of CSF and WM are computed and regressed from gray matter voxels; (4) translational and rotational realignment parameters and their temporal derivatives are used as explanatory variables in motion regression; (5) signals are low-pass filtered with a Gaussian kernel with a SD of 1 TR, that is, 720 ms in the HCP data set; (6) the temporal drift from gray matter signal is removed using a third-degree Legendre polynomial regressor; and (7) global signal regression is performed.
Pipeline B, described in Satterthwaite, Wolf, et al. (Reference Satterthwaite, Wolf, Ruparel, Erus, Elliott, Eickhoff and … Gur2013) and Ciric et al. (Reference Ciric, Wolf, Power, Roalf, Baum, Ruparel and … Satterthwaite2017), is composed of four steps in our implementation: (1) voxel-wise normalization is performed by subtracting the mean from each voxel’s time series; (2) linear and quadratic trends are removed with polynomial regressors; (3) temporal filtering is performed with a first order Butterworth filter with a passband between 0.01 and 0.08 Hz (after linearly interpolating volumes to be censored, cf. step 4); (4) tissue regression (CSF and WM signals with their derivatives and quadratic terms), motion regression (realignment parameters with their derivatives, quadratic terms, and square of derivatives), global signal regression (whole brain signal with derivative and quadratic term), and censoring of volumes with a RMS displacement that exceeded 0.25 mm are combined in a single regression model.
Pipeline C, inspired by Siegel et al. (Reference Siegel, Mitra, Laumann, Seitzman, Raichle, Corbetta and Snyder2017), is implemented as follows: (1) an automated independent component-based denoising was performed with ICA-FIX (Salimi-Khorshidi et al., Reference Salimi-Khorshidi, Douaud, Beckmann, Glasser, Griffanti and Smith2014). Instead of running ICA-FIX ourselves, we downloaded the FIX-denoised data which is available from the HCP database; (2) voxel signals were demeaned; and (3) detrended with a first degree polynomial; (4) CompCor, a PCA-based method proposed by Behzadi, Restom, Liau, and Liu (Reference Behzadi, Restom, Liau and Liu2007) was applied to derive five components from CSF and WM signals; these were regressed out of the data, together with gray matter and whole-brain mean signals; volumes with a framewise displacement greater than 0.25 mm or a variance of differentiated signal greater than 105% of the run median variance of differentiated signal were discarded as well; (5) temporal filtering was performed with a first-order Butterworth band-pass filter between 0.01 and 0.08 Hz, after linearly interpolating censored volumes.
2.7. Intersubject alignment, parcellation, and FC matrix generation
An important choice in processing fMRI data is how to align subjects in the first place. The most common approach is to warp individual brains to a common volumetric template, typically MNI152. However, cortex is a two-dimensional structure; hence, surface-based algorithms that rely on cortical folding to map individual brains to a template may be a better approach. Yet, another improvement in aligning subjects may come from using functional information alongside anatomical information—this is what the multimodal surface matching (MSM) framework achieves (Robinson et al., Reference Robinson, Jbabdi, Glasser, Andersson, Burgess, Harms and … Jenkinson2014). MSM-All aligned data, in which intersubject registration uses individual cortical folding, myelin maps, and resting-state fMRI correlation data, are available for download from the HCP database.
Our prediction analyses below are based on FC matrices. While voxel- (or vertex-) wise FC matrices can be derived, their dimensionality is too high compared with the number of examples in the context of a machine learning-based predictive approach. PCA or other dimensionality reduction techniques applied to the voxelwise data can be used, but this often comes at the cost of losing neuroanatomical specificity. Hence, we work with the most common type of data: parcellated data, in which data from many voxels (or vertices) is aggregated anatomically and the signal within a parcel is averaged over its constituent voxels. Choosing a parcellation scheme is the first step in a network analysis of the brain (Sporns, Reference Sporns2013), yet once again there is no consensus on the “best” parcellation. There are two main approaches to defining network nodes in the brain: nodes may be a set of overlapping, weighted masks, for example, obtained using independent component analysis of BOLD fMRI data (Smith et al., Reference Smith, Vidaurre, Glasser, Winkler, McCarthy, Robinson and … Van Essen2013); or a set of discrete, nonoverlapping binary masks, also known as a hard parcellation (Glasser, Coalson, et al., Reference Glasser, Coalson, Robinson, Hacker, Harwell, Yacoub and … Van Essen2016; Gordon et al., Reference Gordon, Laumann, Adeyemo, Huckins, Kelley and Petersen2016). We chose to work with a hard parcellation, which we find easier to interpret.
Here we present results based on a classical volumetric alignment, together with a volumetric parcellation of the brain into 268 nodes (Finn et al., Reference Finn, Shen, Scheinost, Rosenberg, Huang, Chun and … Constable2015; Shen, Tokoglu, Papademetris, & Constable, Reference Shen, Tokoglu, Papademetris and Constable2013); and, for comparison, results based on MSM-All data, together with a parcellation into 360 cortical areas that was specifically derived from this data (Glasser, Coalson, et al., Reference Glasser, Coalson, Robinson, Hacker, Harwell, Yacoub and … Van Essen2016) (Figure 1d).
Time series extraction simply consisted in averaging data from voxels (or grayordinates) within each parcel, and matrix generation in pairwise correlating parcel time series (Pearson correlation coefficient). FC matrices were averaged across runs (all averaging used Fisher-z transforms) acquired with left-right and right-left phase encoding in each session, that is, we derived two FC matrices per subject, one for REST1 (from REST1_LR and REST1_RL) and one for REST2 (from REST2_LR and REST2_RL); we also derived a FC matrix averaged across all runs (REST12).
2.8. Test-retest comparisons
We applied all three denoising pipelines to the data of all subjects. We then compared the FC matrices produced by each of these strategies, using several metrics. One metric that we used follows from the connectome fingerprinting work of Finn et al. (Reference Finn, Shen, Scheinost, Rosenberg, Huang, Chun and … Constable2015), and was recently labeled the identification success rate (ISR) (Noble et al., Reference Noble, Spann, Tokoglu, Shen, Constable and Scheinost2017). Identification of subject S is successful if, out of all subjects’ FC matrices derived from REST2, subject S’s is the most highly correlated with subject S’s FC matrix from REST1 (identification can also be performed from REST2 to REST1; results are very similar). The ISR gives an estimate of the reliability and specificity of the entire FC matrix at the individual subject level, and is influenced both by within-subject test-retest reliability as well as by discriminability among all subjects in the sample. Relatedly, it is desirable to have similarities (and differences) between all subjects be relatively stable across repeated testing sessions. Following an approach introduced in Geerligs, Rubinov, Cam-Can, and Henson (Reference Geerligs, Rubinov, Cam-Can and Henson2015), we computed the pairwise similarity between subjects separately for session 1 and session 2, constructing a N subjects×N subjects matrix for each session. We then compared these matrices using a simple Pearson correlation. Finally, we used a metric targeted at behavioral utility, and inspired by Geerligs, Rubinov, et al. (Reference Geerligs, Rubinov, Cam-Can and Henson2015): for each edge (the correlation value between a given pair of brain parcels) in the FC matrix, we computed its correlation with a stable trait across subjects, and built a matrix representing the relationship of each edge to this trait, separately for session 1 and session 2. We then compared these matrices using a simple Pearson correlation. The more edges reliably correlate with the stable trait, the higher the correlation between session 1 and session 2 matrices. It should be noted that trait stability is an untested assumption with this approach, because in fact only a single trait score was available in the HCP, collected at the time of session 2. We performed this analysis for the measure of fluid intelligence available in the HCP (PMAT24_A_CR) as well as all Big Five personality factors.
2.9. Prediction models
There is no obvious “best” model available to predict individual behavioral measures from FC data (Abraham et al., Reference Abraham, Milham, Di Martino, Craddock, Samaras, Thirion and Varoquaux2017). So far, most attempts have relied on linear machine learning approaches. This is partly related to the well-known “curse of dimensionality”: despite the relatively large sample size that is available to us (N=884 subjects), it is still about an order of magnitude smaller than the typical number of features included in the predictive model. In such situations, fitting relatively simple linear models is less prone to overfitting than fitting complex nonlinear models.
There are several choices of linear prediction models. Here, we present the results of two methods that have been used in the literature for similar purposes: (1) a simple, “univariate” regression model as used in Finn et al. (Reference Finn, Shen, Scheinost, Rosenberg, Huang, Chun and … Constable2015), and further advocated by Shen et al. (Reference Shen, Finn, Scheinost, Rosenberg, Chun, Papademetris and Constable2017), preceded by feature selection; and (2) a regularized linear regression approach, based on elastic-net penalization (Zou & Hastie, Reference Zou and Hastie2005). We describe each of these in more detail next.
Model (1) is the simplest model, and the one proposed by Finn et al. (Reference Finn, Shen, Scheinost, Rosenberg, Huang, Chun and … Constable2015), consisting in a univariate regressor where the dependent variable is the score to be predicted and the explanatory variable is a scalar value that summarizes the FC network strength (i.e., the sum of edge weights). A filtering approach is used to select features (edges in the FC correlation matrix) that are correlated with the behavioral score on the training set: edges that correlate with the behavioral score with a p-value <.01 are kept. Two distinct models are built using edges of the network that are positively and negatively correlated with the score, respectively. This method has the advantage of being extremely fast to compute, but some main limitations are that (i) it condenses all the information contained in the connectivity network into a single measure and does not account for any interactions between edges; and (ii) it arbitrarily builds two separate models (one for positively correlated edges, one for negatively correlated edges; they are referred to as the positive and the negative models [Finn et al., Reference Finn, Shen, Scheinost, Rosenberg, Huang, Chun and … Constable2015]) and does not offer a way to integrate them. We report results from both the positive and negative models for completeness.
To address the limitations of the univariate model(s), we also included a multivariate model. Model (2) kept the same filtering approach as for the univariate model (discard edges for which the p-value of the correlation with the behavioral score is >.01); this choice allows for a better comparison of the multivariate and univariate models, and for faster computation. Elastic Net is a regularized regression method that linearly combines L1- (lasso) and L2- (ridge) penalties to shrink some of the regressor coefficients toward 0, thus retaining just a subset of features. The lasso model performs continuous shrinkage and automatic variable selection simultaneously, but in the presence of a group of highly correlated features, it tends to arbitrarily select one feature from the group. With high-dimensional data and few examples, the ridge model has been shown to outperform lasso; yet it cannot produce a sparse model since all the predictors are retained. Combining the two approaches, elastic net is able to do variable selection and coefficient shrinkage while retaining groups of correlated variables. Here, however, based on preliminary experiments and on the fact that it is unlikely that just a few edges contribute to prediction, we fixed the L1 ratio (which weights the L1- and L2- regularizations) to 0.01, which amounts to almost pure ridge regression. We used threefold nested cross-validation (with balanced “classes,” based on a partitioning of the training data into quartiles) to choose the α parameter (among 50 possible values) that weighs the penalty term.
2.10. Cross-validation scheme
In the HCP data set, several subjects are genetically related (in our final subject sample, there were 410 unique families). To avoid biasing the results due to this family structure (e.g., perhaps having a sibling in the training set would facilitate prediction for a test subject), we implemented a leave-one-family-out cross-validation scheme for all predictive analyses.
2.11. Statistical assessment of predictions
Several measures can be used to assess the quality of prediction. A typical approach is to plot observed versus predicted values (rather than predicted vs. observed; Piñeiro, Perelman, Guerschman, & Paruelo, Reference Piñeiro, Perelman, Guerschman and Paruelo2008). The Pearson correlation coefficient between observed scores and predicted scores is often reported as a measure of prediction (e.g., Finn et al., Reference Finn, Shen, Scheinost, Rosenberg, Huang, Chun and … Constable2015), given its clear graphical interpretation. However, in the context of cross-validation, it is incorrect to square this correlation coefficient to obtain the coefficient of determination R 2, which is often taken to reflect the proportion of variance explained by the model (Alexander, Tropsha, & Winkler, Reference Alexander, Tropsha and Winkler2015); instead, the coefficient of determination R 2 should be calculated as:
 $$R^{2} \,{\equals}\,1{\minus}{{\sum_{i{\rm }{\equals}{\rm }1}^n \left( {y_{i} {\rm }{\minus}{\rm }\widehat{{y_{i} {\rm }}}} \right)^{2} } \over {\sum_{i{\rm }{\equals}{\rm }1}^n \left( {y_{i} {\rm }{\minus}{\rm }\bar{y}} \right)^{2} }},$$
$$R^{2} \,{\equals}\,1{\minus}{{\sum_{i{\rm }{\equals}{\rm }1}^n \left( {y_{i} {\rm }{\minus}{\rm }\widehat{{y_{i} {\rm }}}} \right)^{2} } \over {\sum_{i{\rm }{\equals}{\rm }1}^n \left( {y_{i} {\rm }{\minus}{\rm }\bar{y}} \right)^{2} }},$$
where n is the number of observations (subjects), y the observed response variable, y̅ its mean, and ŷ the corresponding predicted value. Equation 1 therefore measures the size of the residuals from the model compared with the size of the residuals for a null model where all of the predictions are the same, that is, the mean value y̅. In a cross-validated prediction context, R 2 can actually take negative values (in cases when the denominator is larger than the numerator, i.e. when the sum of squared errors is larger than that of the null model)! Yet another, related statistic to evaluate prediction outcome is the root mean square deviation (RMSD), defined in Piñeiro et al. (Reference Piñeiro, Perelman, Guerschman and Paruelo2008) as:
 $${\rm RMSD} \,{\equals}\, \sqrt {{1 \over {n {\minus} 1}}\mathop \sum\limits_{i {\equals} 1}^n \left( {y_{i} {\minus} \widehat{{y_{i} }}} \right)^{2} } .$$
$${\rm RMSD} \,{\equals}\, \sqrt {{1 \over {n {\minus} 1}}\mathop \sum\limits_{i {\equals} 1}^n \left( {y_{i} {\minus} \widehat{{y_{i} }}} \right)^{2} } .$$
RMSD as defined in (2) represents the standard deviation of the residuals. To facilitate interpretation, it can be normalized by dividing it by the standard deviation of the observed values:
 $${\rm nRMSD}\,{\equals}\,{{\sqrt {{1 \over {n{\rm }{\minus}{\rm }1}}\sum_{i{\rm }{\equals}{\rm }1}^n \left( {y_{i} {\minus}\widehat{{y_{i} {\rm }}}} \right)^{2} } } \over {\sqrt {{1 \over {n{\rm }{\minus}{\rm }1}}\sum_{i{\rm }{\equals}{\rm }1}^n \left( {y_{i} {\minus}\bar{y}} \right)^{2} } }}\,{\equals}\,\sqrt {{{\sum_{i{\rm }{\equals}{\rm }1}^n \left( {y_{i} {\minus}\widehat{{y_{i} {\rm }}}} \right)^{2} } \over {\sum_{i{\rm }{\equals}{\rm }1}^n \left( {y_{i} {\minus}\bar{y}} \right)^{2} }}} \,{\equals}\,\sqrt {1{\rm }{\minus}{\rm }R^{2} } ,$$
$${\rm nRMSD}\,{\equals}\,{{\sqrt {{1 \over {n{\rm }{\minus}{\rm }1}}\sum_{i{\rm }{\equals}{\rm }1}^n \left( {y_{i} {\minus}\widehat{{y_{i} {\rm }}}} \right)^{2} } } \over {\sqrt {{1 \over {n{\rm }{\minus}{\rm }1}}\sum_{i{\rm }{\equals}{\rm }1}^n \left( {y_{i} {\minus}\bar{y}} \right)^{2} } }}\,{\equals}\,\sqrt {{{\sum_{i{\rm }{\equals}{\rm }1}^n \left( {y_{i} {\minus}\widehat{{y_{i} {\rm }}}} \right)^{2} } \over {\sum_{i{\rm }{\equals}{\rm }1}^n \left( {y_{i} {\minus}\bar{y}} \right)^{2} }}} \,{\equals}\,\sqrt {1{\rm }{\minus}{\rm }R^{2} } ,$$
nRMSD thus has a very direct link to R 2 (3); it is interpretable as the average deviation of each predicted value to the corresponding observed value, and is expressed as a fraction of the standard deviation of the observed values.
In a cross-validation scheme, the folds are not independent of each other. This means that statistical assessment of the cross-validated performance using parametric statistical tests is problematic (Combrisson & Jerbi, Reference Combrisson and Jerbi2015; Noirhomme et al., Reference Noirhomme, Lesenfants, Gomez, Soddu, Schrouff, Garraux and … Laureys2014). Proper statistical assessment should thus be done using permutation testing on the actual data. To establish the empirical distribution of chance, we ran our final predictive analyses using 1,000 random permutations of the scores (shuffling scores randomly between subjects, keeping everything else exactly the same, including the family structure).
3. Results
3.1. Characterization of behavioral measures
3.1.1. Internal consistency, distribution, and intercorrelations of personality traits
In our final subject sample (N=884), there was good internal consistency for each personality trait, as measured with Cronbach’s α. We found: Openness, α=0.76; Conscientiousness α=0.81; Extraversion, α=0.78; Agreeableness, α=0.76; and Neuroticism, α=0.85. These compare well with the values reported by McCrae & Costa (Reference McCrae and Costa2004).
Scores on all factors were nearly normally distributed by visual inspection, although the null hypothesis of a normal distribution was rejected for all but Agreeableness (using D’Agostino and Pearson’s, Reference D’Agostino and Pearson1973, normality test as implemented in SciPy) (Figure 2b).

Figure 2 Structure of personality factors in our subject sample (N=884). (a) The five personality factors were not orthogonal in our sample. Neuroticism was anticorrelated with Conscientiousness, Extraversion, and Agreeableness, and the latter three were positively correlated with each other. Openness correlated more weakly with other factors. There were highly significant correlations with other behavioral and demographic variables, which we accounted for in our subsequent analyses by regressing them out of the personality scores (see next section). (b) Distributions of the five personality scores in our sample. Each of the five personality scores was approximately normally distributed by visual inspection. (c) Two-dimensional principal component (PC) projection; the value for each personality factor in this projection is represented by the color of the dots. The weights for each personality factor are shown at the bottom.
Although in theory the Big Five personality traits should be orthogonal, their estimation from the particular item scoring of versions of the NEO in practice deviates considerably from orthogonality. This intercorrelation amongst the five factors has been reported for the Neuroticism/Extraversion/Openness Personality Inventory Revised (Block, Reference Block1995; Saucier, Reference Saucier2002), the NEO-FFI (Block, Reference Block1995; Egan, Deary, & Austin, Reference Egan, Deary and Austin2000), and alternate instruments (DeYoung, Reference DeYoung2006) (but, see McCrae et al., Reference McCrae, Yamagata, Jang, Riemann, Ando, Ono and … Spinath2008). Indeed, in our subject sample, we found that the five personality factors were correlated with one another (Figure 2a). For example, Neuroticism was anticorrelated with Conscientiousness (r=−0.41, p<10−37), Extraversion (r=−0.34, p<10−25), and Agreeableness (r=−0.28, p <10−16), while these latter three factors were positively correlated with one another (all r>0.21). Though the theoretical interpretation of these intercorrelations in terms of higher-order factors of personality remains a topic of debate (DeYoung, Reference DeYoung2006; Digman, Reference Digman1997; McCrae et al., Reference McCrae, Yamagata, Jang, Riemann, Ando, Ono and … Spinath2008), we derived two orthogonal higher-order personality dimensions using a PCA of the Big five-factor scores; we labeled the two derived dimensions α and β, following Digman (Reference Digman1997). The first component [α] accounted for 40.3% of the variance, and the second [β] for 21.6% (total variance explained by the two-dimensional principal component [PC] solution was thus 61.9%). Figure 2c shows how the Big Five project on this two-dimensional solution, and the PC loadings.
3.1.2. Confounding variables
There are known effects of gender (Ruigrok et al., Reference Ruigrok, Salimi-Khorshidi, Lai, Baron-Cohen, Lombardo, Tait and Suckling2014; Trabzuni et al., Reference Trabzuni, Ramasamy, Imran, Walker, Smith and Weale2013), age (Dosenbach et al., Reference Dosenbach, Nardos, Cohen, Fair, Power, Church and … Schlaggar2010; Geerligs, Renken, Saliasi, Maurits, & Lorist, Reference Geerligs, Renken, Saliasi, Maurits and Lorist2015), handedness (Pool, Rehme, Eickhoff, Fink, & Grefkes, Reference Pool, Rehme, Eickhoff, Fink and Grefkes2015), in-scanner motion (Power, Barnes, Snyder, Schlaggar, & Petersen, Reference Power, Barnes, Snyder, Schlaggar and Petersen2012; Satterthwaite, Elliott, et al., Reference Satterthwaite, Elliott, Gerraty, Ruparel, Loughead, Calkins and … Wolf2013; Tyszka, Kennedy, Paul, & Adolphs, Reference Tyszka, Kennedy, Paul and Adolphs2014), brain size (Hänggi, Fövenyi, Liem, Meyer, & Jäncke, Reference Hänggi, Fövenyi, Liem, Meyer and Jäncke2014), and fluid intelligence (Cole, Yarkoni, Repovs, Anticevic, & Braver, Reference Cole, Yarkoni, Repovs, Anticevic and Braver2012; Finn et al., Reference Finn, Shen, Scheinost, Rosenberg, Huang, Chun and … Constable2015; Noble et al., Reference Noble, Spann, Tokoglu, Shen, Constable and Scheinost2017) on the FC patterns measured in the resting-state with fMRI. It is thus necessary to control for these variables: indeed, if a personality factor is correlated with gender, one would be able to predict some of the variance in that personality factor solely from functional connections that are related to gender. The easiest way (though perhaps not the best way, see Westfall & Yarkoni, Reference Westfall and Yarkoni2016) to control for these confounds is by regressing the confounding variables on the score of interest in our sample of subjects.
We characterized the relationship between each of the personality factors and each of the confounding variables listed above in our subject sample (Figure 2a). All personality factors but Extraversion were correlated with gender: women scored higher on Conscientiousness, Agreeableness, and Neuroticism, while men scored higher on Openness. In previous literature, women have been reliably found to score higher on Neuroticism and Agreeableness, which we replicated here, while other gender differences are generally inconsistent at the level of the factors (Costa, Terracciano, & McCrae, Reference Costa, Terracciano and McCrae2001; Feingold, Reference Feingold1994; Weisberg, Deyoung, & Hirsh, Reference Weisberg, Deyoung and Hirsh2011). Agreeableness and Openness were significantly correlated with age in our sample, despite our limited age range (22–36 y.o.): younger subjects scored higher on Openness, while older subjects scored higher on Agreeableness. The finding for Openness does not match previous reports (Allemand, Zimprich, & Hendriks, Reference Allemand, Zimprich and Hendriks2008; Soto et al., Reference Soto, John, Gosling and Potter2011), but this may be confounded by other factors such as gender, as our analyses here do not use partial correlations. Motion, quantified as the sum of frame-to-frame displacement over the course of a run (and averaged separately for REST1 and REST2) was correlated with Openness: subjects scoring lower on Openness moved more during the resting-state. Note that motion in REST1 was highly correlated (r=.72, p<10−143) with motion in REST2, indicating that motion itself may be a stable trait, and correlated with other traits. Brain size, obtained from Freesurfer during the minimal preprocessing pipelines, was found to be significantly correlated with all personality factors but Extraversion. Fluid intelligence was positively correlated with Openness, and negatively correlated with Conscientiousness, Extraversion, and Neuroticism, consistently with other reports (Bartels et al., Reference Bartels, van Weegen, van Beijsterveldt, Carlier, Polderman, Hoekstra and Boomsma2012; Chamorro-Premuzic & Furnham, Reference Chamorro-Premuzic and Furnham2004). While the interpretation of these complex relationships would require further work outside the scope of this study, we felt that it was critical to remove shared variance between each personality score and the primary confounding variables before proceeding further. This ensures that our model is trained specifically to predict personality, rather than confounds that covary with personality, although it may also reduce power by removing shared variance (thus providing a conservative result).
Another possible confound, specific to the HCP data set, is a difference in the image reconstruction algorithm between subjects collected before and after April 2013. The reconstruction version leaves a notable signature on the data that can make a large difference in the final analyses produced (Elam, Reference Elam2015). We found a significant correlation with the Openness factor in our sample. This indicates that the sample of subjects who were scanned with the earlier reconstruction version happened to score slightly less high for the Openness factor than the sample of subjects who were scanned with the later reconstruction version (purely by sampling chance); this of course is meaningless, and a simple consequence of working with finite samples. Therefore, we also included the reconstruction factor as a confound variable.
Importantly, the multiple linear regression used for removing the variance shared with confounds was performed on training data only (in each cross-validation fold during the prediction analysis), and then the fitted weights were applied to both the training and test data. This is critical to avoid any leakage of information, however negligible, from the test data into the training data.
Authors of the HCP-MegaTrawl have used transformed variables (Age2) and interaction terms (Gender×Age, Gender×Age2) as further confounds (Smith et al., Reference Smith, Vidaurre, Beckmann, Glasser, Jenkinson, Miller and … Van Essen2016). After accounting for the confounds described above, we did not find sizeable correlations with these additional terms (all correlations <.008), and thus we did not use these additional terms in our confound regression.
3.2. Preprocessing affects test-retest reliability of FC matrices
As we were interested in relatively stable traits (which are unlikely to change much between sessions REST1 and REST2), one clear goal for the denoising steps applied to the minimally preprocessed data was to yield FC matrices that are as “similar” as possible across the two sessions. We computed several metrics (see Methods) to assess this similarity for each of our three denoising strategies (A, B, and C; cf. Figure 1c). Of course, no denoising strategy would achieve perfect test-retest reliability of FC matrices since, in addition to inevitable measurement error, the two resting-state sessions for each subject likely feature somewhat different levels of states such as arousal and emotion.
In general, differences in test-retest reliability across metrics were small when comparing the three denoising strategies. Considering the entire FC matrix, the ISR (Finn et al., Reference Finn, Shen, Scheinost, Rosenberg, Huang, Chun and … Constable2015; Noble et al., Reference Noble, Spann, Tokoglu, Shen, Constable and Scheinost2017) was high for all strategies, and highest for pipeline B (Figure 3a). The multivariate pairwise distances between subjects were also best reproduced across sessions by pipeline B (Figure 3b). In terms of behavioral utility, that is, reproducing the pattern of correlations of the different edges with a behavioral score, pipeline A outperformed the others (Figure 3c). All three strategies appear to be reasonable choices, and we would thus expect a similar predictive accuracy under each of them, if there is information about a given score in the FC matrix.

Figure 3 Test-retest comparisons between spaces and denoising strategies. (a) Identification success rate, and other statistics related to connectome fingerprinting (Finn et al., Reference Finn, Shen, Scheinost, Rosenberg, Huang, Chun and … Constable2015; Noble et al., Reference Noble, Spann, Tokoglu, Shen, Constable and Scheinost2017). All pipelines had a success rate superior to 87% for identifying the functional connectivity matrix of a subject in REST2 (out of N=884 choices) based on their functional connectivity matrix in REST1. Pipeline B slightly outperformed the others. (b) Test-retest of the pairwise similarities (based on Pearson correlation) between all subjects (Geerligs, Rubinov, et al., Reference Geerligs, Rubinov, Cam-Can and Henson2015). Overall, for the same session, the three pipelines gave similar pairwise similarities between subjects. About 25% of the variance in pairwise distances was reproduced in REST2, with pipeline B emerging as the winner (0.542=29%). (c) Test-retest reliability of behavioral utility, quantified as the pattern of correlations between each edge and a behavioral score of interest (Geerligs, Rubinov, et al., Reference Geerligs, Rubinov, Cam-Can and Henson2015). Shown are fluid intelligence, Openness to experience, and Neuroticism (all de-confounded, see main text). Pipeline A gave slightly better test-retest reliability for all behavioral scores. Multimodal surface matching (MSM)-All outperformed MNI alignment. Neuroticism showed lower test-retest reliability than fluid intelligence or Openness to experience.
We note here already that Neuroticism stands out as having lower test-retest reliability in terms of its relationship to edge values across subjects (Figure 3c). This may be a hint that the FC matrices do not carry information about Neuroticism.
3.3. Prediction of fluid intelligence (PMAT24_A_CR)
It has been reported that a measure of fluid intelligence, the raw score on a 24-item version of the Raven’s Progressive Matrices (PMAT24_A_CR), could be predicted from FC matrices in previous releases of the HCP data set (Finn et al., Reference Finn, Shen, Scheinost, Rosenberg, Huang, Chun and … Constable2015; Noble et al., Reference Noble, Spann, Tokoglu, Shen, Constable and Scheinost2017). We generally replicated this result qualitatively for the deconfounded fluid intelligence score (removing variance shared with gender, age, handedness, brain size, motion, and reconstruction version), using a leave-one-family-out cross-validation approach. We found positive correlations across all 36 of our result data sets: two sessions×three denoising pipelines (A, B, and C) × two parcellation schemes (in volumetric space and in MSM-All space) × three models (univariate positive, univariate negative, and multivariate learning models) (Figure 4a; Table 1). We note, however, that, using MNI space and denoising strategy A as in Finn et al. (Reference Finn, Shen, Scheinost, Rosenberg, Huang, Chun and … Constable2015), the prediction score was very low (REST1: r=0.04; REST2: r=0.03). One difference is that the previous study did not use deconfounding, hence some variance from confounds may have been used in the predictions; also the sample size was much smaller in Finn et al. (Reference Finn, Shen, Scheinost, Rosenberg, Huang, Chun and … Constable2015) (N=118; but N=606 in Noble et al., Reference Noble, Spann, Tokoglu, Shen, Constable and Scheinost2017), and family structure was not accounted for in the cross-validation. We generally found that prediction performance was better in MSM-All space (Figure 4a; Table 1).
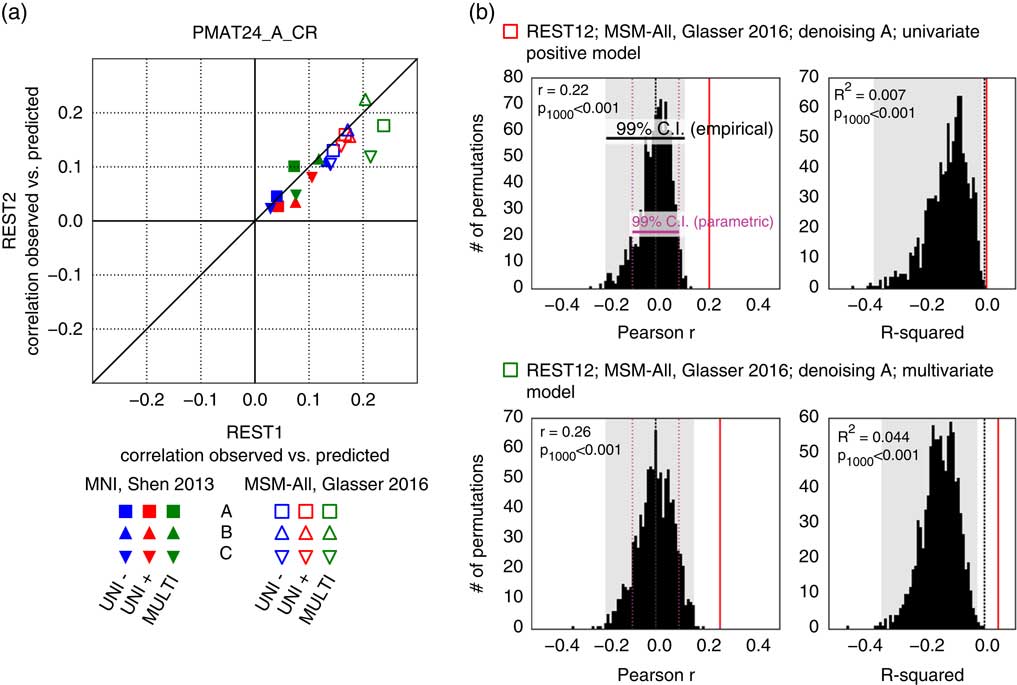
Figure 4 Prediction results for de-confounded fluid intelligence (PMAT24_A_CR). (a) All predictions were assessed using the correlation between the observed scores (the actual scores of the subjects) and the predicted scores. This correlation obtained using the REST2 data set was plotted against the correlation from the REST1 data set, to assess test-retest reliability of the prediction outcome. Results in multimodal surface matching (MSM)-All space outperformed results in MNI space. The multivariate model slightly outperformed the univariate models (positive and negative). Our results generally showed good test-retest reliability across sessions, although REST1 tended to produce slightly better predictions than REST2. Pearson correlation scores for the predictions are listed in Table 1. Supplementary Figure 1 shows prediction scores with minimal deconfounding. (b) We ran a final prediction using combined data from all resting-state runs (REST12), in MSM-All space with denoising strategy A (results are shown as vertical red lines). We randomly shuffled the PMAT24_A_CR scores 1,000 times while keeping everything else the same, for the univariate model (positive, top) and the multivariate model (bottom). The distribution of prediction scores (Pearson’s r, and R 2) under the null hypothesis is shown (black histograms). Note that the empirical 99% confidence interval (CI) (shaded gray area) is wider than the parametric CI (shown for reference, magenta dotted lines), and features a heavy tail on the left side for the univariate model. This demonstrates that parametric statistics are not appropriate in the context of cross-validation. Such permutation testing may be computationally prohibitive for more complex models, yet since the chance distribution is model-dependent, it must be performed for statistical assessment.
Table 1 Test-retest prediction results using deconfounded scores

Note. Listed are Pearson correlation coefficients between predicted and observed individual scores, for all behavioral scores and analytical alternatives (the two columns for each score correspond to the two resting-state sessions). See Supplementary Figure 1 for results with minimal deconfounding.
MSM=multimodal surface matching.
To generate a final prediction, we combined data from all four resting-state runs (REST12). We chose to use pipeline A and MSM-All space, which we had found to yield the best test-retest reliability in terms of behavioral utility (Figure 3c). We obtained r=.22 (R 2=.007, nRMSD=0.997) for the univariate positive model, r=.18 (R 2=−.023, nRMSD=1.012) for the univariate negative model, and r=.26 (R 2=.044, nRMSD=0.978) for the multivariate model. Interestingly, these performances on combined data outperformed performance on REST1 or REST2 alone, suggesting that decreasing noise in the neural data boosts prediction performance. For statistical assessment of predictions, we estimated the distribution of chance for the prediction score under both the univariate positive and the multivariate models, using 1,000 random permutations of the subjects’ fluid intelligence scores (Figure 4b). For reference we also show parametric statistical thresholds for the correlation coefficients; we found that parametric statistics underestimate the confidence interval for the null hypothesis, hence overestimate significance. Interestingly, the null distributions differed between the univariate and the multivariate models: while the distribution under the multivariate model was roughly symmetric about 0, the distribution under the univariate model was asymmetric with a long tail on the left. The empirical, one-tailed p-values for REST12 MSM-All space data denoised with strategy A and using the univariate positive model, and using the multivariate model, both achieved p<.001 (none of the 1,000 random permutations resulted in a higher prediction score).
3.4. Prediction of the Big Five
We established that our approach reproduces and improves on the previous finding that fluid intelligence can be predicted from resting-state FC (Finn et al., Reference Finn, Shen, Scheinost, Rosenberg, Huang, Chun and … Constable2015; Noble et al., Reference Noble, Spann, Tokoglu, Shen, Constable and Scheinost2017). We next turned to predicting each of the Big Five personality factors using the same approach (including deconfounding, which in this case removes variance shared with gender, age, handedness, brain size, motion, reconstruction version, and, importantly, fluid intelligence).
Test-retest results across analytical choices are shown in Figure 5a, and in Table 1. Predictability was lower than for fluid intelligence (PMAT24_A_CR) for all Big Five personality factors derived from the NEO-FFI. Openness to experience showed the highest predictability overall, and also the most reproducible across sessions; prediction of Extraversion was moderately reproducible; in contrast, the predictability of the other three personality factors (Agreeableness and Neuroticism, and Conscientiousness) was low and lacked reproducibility.

Figure 5 Prediction results for the Big Five personality factors. (a) Test-retest prediction results for each of the Big Five. Representation is the same as in Figure 4a. The only factor that showed consistency across parcellation schemes, denoising strategies, models, and sessions was Openness (NEOFAC_O), although Extraversion (NEOFAC_E) also showed substantial positive correlations (see also Table 1). (b) Prediction results for each of the (demeaned and deconfounded) Big Five, from REST12 functional connectivity matrices, using MSM-All intersubject alignment, denoising strategy A, and the multivariate prediction model. The blue line shows the best fit to the cloud of points (its slope should be close to 1 (dotted line) for good predictions, see Piñeiro et al., Reference Piñeiro, Perelman, Guerschman and Paruelo2008). The variance of predicted values is noticeably smaller than the variance of observed values.
It is worth noting that the NEO-FFI test was administered closer in time to REST2 than to REST1 on average; hence one might expect REST2 to yield slightly better results, if the NEO-FFI factor scores reflect a state component. We found that REST2 produced better predictability than REST1 for Extraversion (results fall mostly to the left of the diagonal line of reproducibility), while REST1 produced better results for Openness, hence the data does not reflect our expectation of state effects on predictability.
Although we conducted 18 different analyses for each session with the intent to present all of them in a fairly unbiased manner, it is notable that certain combinations produced the best predictions across different personality scores—some of the same combinations that yielded the best predictability for fluid intelligence (Figure 4). While the findings strongly encourage the exploration of additional processing alternatives (see Discussion), some of which may produce results yet superior to those here, we can provisionally recommend MSM-All alignment and the associated multimodal brain parcellation (Glasser, Coalson, et al., Reference Glasser, Coalson, Robinson, Hacker, Harwell, Yacoub and … Van Essen2016), together with a multivariate learning model such as elastic net regression.
Finally, results for REST12 (all resting-state runs combined), using MSM-All alignment and denoising strategy A, and the multivariate learning model, are shown in Figure 5b together with statistical assessment using 1,000 permutations. Only Openness to experience could be predicted above chance, albeit with a very small effect size (r=.24, R 2=.024).
3.5. Predicting higher-order dimensions of personality (α and β)
In previous sections, we qualitatively observed that decreasing noise in individual FC matrices by averaging data over all available resting state runs (REST12, 1 hr of data) leads to improvements in prediction performance compared to session-wise predictions (REST1 and REST2, 30 min of data each). We can also decrease noise in the behavioral data, by deriving composite scores that pool over a larger number of test items than the Big Five-factor scores (each factor relies solely on 12 items in the NEO-FFI). The PCA presented in Figure 2c is a way to achieve such pooling. We therefore next attempted to predict these two PC scores, which we refer to as α and β, from REST12 FC matrices, using denoising A and MSM-all intersubject alignment.
α was not predicted above chance, which was somewhat expected because it loads most highly on Neuroticism, which we could not predict well in the previous section.
β was predicted above chance (p 1000<.002), which we also expected because it loads most highly on Openness to experience (which had r=.24, R 2=.024; Figure 5b). Since β effectively combines variance from Openness with that from other factors (Conscientiousness, Extraversion, and Agreeableness; see Figure 2c) this leads to a slight improvement in predictability, and a doubling of the explained variance (β: r=.27, R 2=.050). This result strongly suggests that improving the reliability of scores on the behavioral side helps boost predictability (Gignac & Bates, Reference Gignac and Bates2017), just as improving the reliability of FC matrices by combining REST1 and REST2 improved predictability (Figure 6).
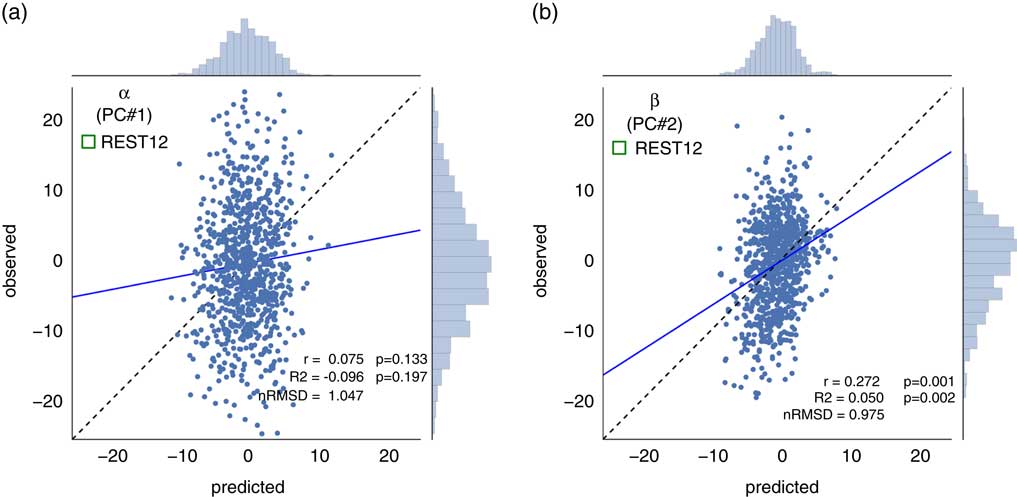
Figure 6 Prediction results for superordinate factors/principal components α and β, using REST12 data (1 hr of resting-state functional magnetic resonance imaging per subject). These results use MSM-All intersubject alignment, denoising strategy A, and the multivariate prediction model. As in Figure 5b, the range of predicted scores is much narrower than the range of observed scores. (a) The first principal component (PC), α, is not predicted better than chance. α loads mostly on Neuroticism (see Figure 2c), which was itself not predicted well (cf. Figure 5). (b) We can predict about 5% of the variance in the score on the second PC, β. This is better than chance, as established by permutation statistics (p 1000<.002). β loads mostly on Openness to experience (see Figure 2c), which showed good predictability in the previous section. RMSD=root mean square deviation.
4. Discussion
4.1. Summary of results
Connectome-based predictive modeling (Dubois & Adolphs, Reference Dubois and Adolphs2016; Shen et al., Reference Shen, Finn, Scheinost, Rosenberg, Chun, Papademetris and Constable2017) has been an active field of research in the past years: it consists in using FC as measured from resting-state fMRI data to predict individual differences in demographics, behavior, psychological profile, or psychiatric diagnosis. Here, we applied this approach and attempted to predict the Big Five personality factors (McCrae & Costa, Reference McCrae and John1987) from resting-state data in a large public data set, the HCP (N=884 after exclusion criteria). We can summarize our findings as follows.
1. We found that personality traits were not only intercorrelated with one another, but were also correlated with fluid intelligence, age, sex, handedness, and other measures. We therefore regressed these possible confounds out, producing a residualized set of personality trait measures (that were, however, still intercorrelated amongst themselves).
2. Comparing different processing pipelines and data from different fMRI sessions showed generally good stability of FC across time, a prerequisite for attempting to predict a personality trait that is also stable across time.
3. We qualitatively replicated and extended a previously published finding, the prediction of a measure of fluid intelligence (Finn et al., Reference Finn, Shen, Scheinost, Rosenberg, Huang, Chun and … Constable2015; Noble et al., Reference Noble, Spann, Tokoglu, Shen, Constable and Scheinost2017) from FC patterns, providing reassurance that our approach is able to predict individual differences when possible.
4. We then carried out a total of 36 different analyses for each of the five personality factors. The 36 different analyses resulted from separately analyzing data from two sessions (establishing test-retest reliability), each with three different preprocessing pipelines (exploring sensitivity to how the fMRI data are processed), two different alignment and hard parcellation schemes (providing initial results whether multimodal surface-based alignment improves on classical volumetric alignment), and three different predictive models (univariate positive, univariate negative, and multivariate). Across all of these alternatives, we generally found that the MSM-All multimodal alignment together with the parcellation scheme of Glasser, Coalson, et al. (Reference Glasser, Smith, Marcus, Andersson, Auerbach, Behrens and … Van Essen2016) was associated with the greatest predictability; and likewise for the multivariate model (elastic net).
5. Among the personality measures, Openness to experience showed the most reliable prediction between the two fMRI sessions, followed by Extraversion; for all other factors, predictions were often highly unstable, showing large variation depending on small changes in preprocessing, or across sessions.
6. Combining data from both fMRI sessions improved predictions. Likewise, combining behavioral data through PCA improved predictions. At both the neural and behavioral ends, improving the quality of our measurements could improve predictions.
7. We best predicted the β superordinate factor, with r=.27 and R 2=.05. This is highly significant as per permutation testing (though, in interpreting the statistical significance of any single finding, we note that one would have to correct for all the multiple analysis pipelines that we tested; future replications or extensions of this work would benefit from a preregistered single approach to reduce the degrees of freedom in the analysis).
Though some of our findings achieve statistical significance in the large sample of subjects provided by the HCP, resting-state FC still only explains at most 5% of the variance in any personality score. We are thus still far from understanding the neurobiological substrates of personality (Yarkoni, Reference Yarkoni2015) (and, for that matter, of fluid intelligence which we predicted at a similar, slightly lower level; but, see Dubois et al., Reference Dubois, Galdi, Paul and Adolphs2018). Indeed, based on this finding, it seems unlikely that findings from predictive approaches using whole-brain resting-state fMRI will inform hypotheses about specific neural systems that provide a causal mechanistic explanation of how personality is expressed in behavior.
Taken together, our approach provides important general guidelines for personality neuroscience studies using resting-state fMRI data: (i) operations that are sometimes taken for granted, such as resting-state fMRI denoising (Abraham et al., Reference Abraham, Milham, Di Martino, Craddock, Samaras, Thirion and Varoquaux2017), make a difference to the outcome of connectome-based predictions and their test-retest reliability; (ii) new intersubject alignment procedures, such as MSM (Robinson et al., Reference Robinson, Jbabdi, Glasser, Andersson, Burgess, Harms and … Jenkinson2014), improve performance and test-retest reliability; (iii) a simple multivariate linear model may be a good alternative to the separate univariate models proposed by Finn et al. (Reference Finn, Shen, Scheinost, Rosenberg, Huang, Chun and … Constable2015), yielding improved performance.
Our approach also draws attention to the tremendous analytical flexibility that is available in principle (Carp, Reference Carp2012), and to the all-too-common practice of keeping such explorations “behind the scenes” and only reporting the “best” strategy, leading to an inflation of positive findings reported in the literature (Neuroskeptic, 2012; Simonsohn, Nelson, & Simmons, Reference Simonsohn, Nelson and Simmons2014). At a certain level, if all analyses conducted make sense (i.e., would pass a careful expert reviewer’s scrutiny), they should all give a similar answer to the final question (conceptually equivalent to interrater reliability; see Dubois & Adolphs, Reference Dubois and Adolphs2016). The “vibration of effects” due to analytical flexibility (Ioannidis Reference Ioannidis2008; Varoquaux Reference Varoquaux2017) should be reported rather than exploited.
4.1.1. Effect of subject alignment
The recently proposed MSM framework uses a combination of anatomical and functional features to best align subject cortices. It improves functional intersubject alignment over the classical approach of warping brains volumetrically (Dubois & Adolphs, Reference Dubois and Adolphs2016). For the scores that can be predicted from FC, alignment in the MSM-All space outperformed alignment in the MNI space. However, more work needs to be done to further establish the superiority of the MSM-All approach. Indeed, the parcellations used in this study differed between the MNI and MSM-All space: the parcellation in MSM-All space had more nodes (360 vs. 268) and no subcortical structures were included. Moreover, it is unclear how the use of resting-state data during the alignment process in the MSM-All framework interacts with resting-state-based predictions, since the same data used for predictions has already been used to align subjects. Finally, it has recently been shown that the precise anatomy of each person’s brain, even after the best alignment, introduces variability that interacts with FC (Bijsterbosch et al., Reference Bijsterbosch, Woolrich, Glasser, Robinson, Beckmann, Van Essen and … Smith2018). The complete description of brain variability at both structural and functional levels will need to be incorporated into future studies of individual differences.
4.1.2. Effect of preprocessing
We applied three separate, reasonable denoising strategies, inspired from published work (Ciric et al., Reference Ciric, Wolf, Power, Roalf, Baum, Ruparel and … Satterthwaite2017; Finn et al., Reference Finn, Shen, Scheinost, Rosenberg, Huang, Chun and … Constable2015; Satterthwaite, Elliott, et al., Reference Satterthwaite, Elliott, Gerraty, Ruparel, Loughead, Calkins and … Wolf2013; Siegel et al., Reference Siegel, Mitra, Laumann, Seitzman, Raichle, Corbetta and Snyder2017) and our current understanding of resting-state fMRI confounds (Caballero-Gaudes & Reynolds, Reference Caballero-Gaudes and Reynolds2017; Murphy, Birn, & Bandettini, Reference Murphy, Birn and Bandettini2013). The differences between the three denoising strategies in terms of the resulting test-retest reliability, based on several metrics, were not very large—yet, there were differences. Pipeline A appeared to yield the best reliability in terms of behavioral utility, while Pipeline B was best at conserving differences across subjects. Pipeline C performed worst on these metrics in our hands, despite its use of the automated artifact removal tool ICA-FIX (Salimi-Khorshidi et al., Reference Salimi-Khorshidi, Douaud, Beckmann, Glasser, Griffanti and Smith2014); it is possible that performing CompCor and censoring are in fact detrimental after ICA-FIX (see also Muschelli et al., Reference Muschelli, Nebel, Caffo, Barber, Pekar and Mostofsky2014). Finally, in terms of the final predictive score, all three strategies demonstrated acceptable test-retest reliability for scores that were successfully predicted.
The particular choices of pipelines that we made were intended to provide an initial survey of some commonly used schemes, but substantial future work will be needed to explore the space of possibilities more comprehensively. For instance, global signal regression—which was a part of all three chosen strategies—remains a somewhat controversial denoising step, and could be omitted if computing partial correlations, or replaced with a novel temporal independent component analysis decomposition approach (Glasser et al., Reference Glasser, Coalson, Bijsterbosch, Harrison, Harms, Anticevic and … Smith2017). The bandpass filtering used in all our denoising approaches to reduce high frequency noise could also be replaced with alternatives such as PCA decomposition combined with “Wishart rolloff” (Glasser, Smith, et al., Reference Glasser, Smith, Marcus, Andersson, Auerbach, Behrens and … Van Essen2016). All of these choices impact the amount and quality of information in principle available, and how that information can be used to build a predictive model.
4.1.3. Effect of predictive algorithm
Our exploration of a multivariate model was motivated by the seemingly arbitrary decision to weight all edges equally in the univariate models (positive and negative) proposed by Finn et al. (Reference Finn, Shen, Scheinost, Rosenberg, Huang, Chun and … Constable2015). However, we also recognize the need for simple models, given the paucity of data compared with the number of features (curse of dimensionality). We thus explored a regularized regression model that would combine information from negative and positive edges optimally, after performing the same feature-filtering step as in the univariate models. The multivariate model performed best on the scores that were predicted most reliably, yet it also seemed to have lower test-retest reliability. More work remains to be done on this front to find the best simple model that optimally combines information from all edges and can be trained in a situation with limited data.
4.1.4. Statistical significance
It is inappropriate to assess statistical significance using parametric statistics in the case of a cross-validation analysis (Figure 4b). However, for complex analyses, it is often the preferred option, due to the prohibitive computational resources needed to run permutation tests. Here we showed the empirical distribution of chance prediction scores for both the univariate (positive)- and multivariate-model predictions of fluid intelligence (PMAT24_A_CR) using denoising pipeline A in MSM-All space (Figure 4b). As expected, the permutation distribution is wider than the parametric estimate; it also differs significantly between the univariate and the multivariate models. This finding stresses that one needs to calculate permutation statistics for the specific analysis that one runs. The calculation of permutation statistics should be feasible given the rapid increase and ready availability of computing clusters with multiple processors. We show permutation statistics for all our key findings, but we did not correct for the multiple comparisons (five personality factors, multiple processing pipelines). Future studies should ideally provide analyses that are preregistered to reduce the degrees of freedom available and aid interpretation of statistical reliability.
4.1.5. Will our findings reproduce?
It is common practice in machine learning competitions to set aside a portion of your data and not look at it at all until a final analysis has been decided, and only then to run that single final analysis on the held-out data to establish out-of-sample replication. We decided not to split our data set in that way due to its already limited sample size, and instead used a careful cross-validation framework, assessed test-retest reliability across data from different sessions, and refrained from adaptively changing parameters upon examining the final results. The current paper should now serve as the basis of a preregistered replication, to be performed on an independent data set (a good candidate would be the Nathan Kline Institute-enhanced data set (Nooner et al., Reference Nooner, Colcombe, Tobe, Mennes, Benedict, Moreno and … Milham2012), which also contains assessment of the Big Five).
4.2. On the relationship between brain and personality
The best neural predictor of personality may be distinct, wholly or in part, from the actual neural mechanisms by which personality expresses itself on any given occasion. Personality may stem from a disjunctive and heterogeneous set of biological constraints that in turn influence brain function in complex ways (Yarkoni, Reference Yarkoni2015); neural predictors may simply be conceived of as “markers” of personality: any correlated measures that a machine learning algorithm could use as information, on the basis of which it could be trained in a supervised fashion to discriminate among personality traits. Our goal in this study was to find such predictions, not a causal explanation (see Yarkoni & Westfall, Reference Yarkoni and Westfall2017). It may well someday be possible to predict personality differences from fMRI data with much greater accuracy than what we found here. However, we think it likely that, in general, such an approach will still fall short of uncovering the neural mechanisms behind personality, in the sense of explaining the proximal causal processes whereby personality is expressed in behavior on specific occasions.
4.3. Subjective and objective measures of personality
As noted already in the introduction, it is worth keeping in mind the history of the Big Five: They derive from factor analyses of words, of the vocabularies that we use to describe people. As such, they fundamentally reflect our folk psychology, and our social inferences (“theory of mind”) about other people. This factor structure was then used to design a self-report instrument, in which participants are asked about themselves (the NEO or variations thereof). Unlike some other self-report indices (such as the Minnesota Multiphasic Personality Inventory), the NEO-FFI does not assess test-taking approach (e.g., consistency across items or tendency toward a particular response set), and thus, offers no insight regarding validity of any individual’s responses. This is a notable limitation, as there is substantial evidence that NEO-FFI scores may be intentionally manipulated by the subject’s response set (Furnham, Reference Furnham1997; Topping & O’Gorman, Reference Topping and O’Gorman1997). Even in the absence of intentional “faking,” NEO outcomes are likely to be influenced by an individual’s insight, impression management, and reference group effects. However, these limitations may be addressed by applying the same analysis to multiple personality measures with varying degrees of face-validity and objectivity, as well as measures that include indices of response bias. This might include ratings provided by a familiar informant, implicit-association tests (e.g. Schnabel, Asendorpf, & Greenwald, Reference Schnabel, Asendorpf and Greenwald2008), and spontaneous behavior (e.g. Mehl, Gosling, & Pennebaker, Reference Mehl, Gosling and Pennebaker2006). Future development of behavioral measures of personality that provide better convergent validity and discriminative specificity will be an important component of personality neuroscience.
4.4. Limitations and future directions
There are several limitations of the present study that could be improved upon or extended in future work. In addition to the obvious issue of simply needing more, and/or better quality, data, there is the important issue of obtaining a better estimate of variability within a single subject. This is especially pertinent for personality traits, which are supposed to be relatively stable within an individual. Thus, collecting multiple fMRI data sets, perhaps over weeks or even years, could help to find those features in the data with the best cross-temporal stability. Indeed several such dense data sets across multiple sessions in a few subjects have already been collected, and may help guide the intelligent selection of features with the greatest temporal stability (Gordon et al., Reference Gordon, Laumann, Gilmore, Newbold, Greene, Berg and … Dosenbach2017; Noble et al., Reference Noble, Spann, Tokoglu, Shen, Constable and Scheinost2017; Poldrack et al., Reference Poldrack, Laumann, Koyejo, Gregory, Hover, Chen and … Mumford2015). Against expectations, initial analyses seem to indicate that the most reliable edges in FC from such studies are not necessarily the most predictive edges (for fluid intelligence; see Noble et al., Reference Noble, Spann, Tokoglu, Shen, Constable and Scheinost2017), yet more work needs to be done to further test this hypothesis. It is also possible that shorter timescale fluctuations in resting-state fMRI provide additional information (if these are stable over longer times), and it might thus be fruitful to explore dynamic FC, as some work has done (Calhoun, Miller, Pearlson, & Adalı, Reference Calhoun, Miller, Pearlson and Adalı2014; Jia, Hu, & Deshpande, Reference Jia, Hu and Deshpande2014; Vidaurre, Smith, & Woolrich, Reference Vidaurre, Smith and Woolrich2017).
No less important would be improvements on the behavioral end, as we alluded to in the previous section. Developing additional tests of personality to provide convergent validity to the personality dimension constructs would help provide a more accurate estimate of these latent variables. Just as with the fMRI data, collecting personality scores across time should help to prioritize those items that have the greatest temporal stability and reduce measurement error.
Another limitation is signal-to-noise. It may be worth exploring fMRI data obtained while watching a movie that drives relevant brain function, rather than during rest, in order to maximize the signal variance in the fMRI signal. Similarly, it could be beneficial to include participants with a greater range of personality scores, perhaps even including those with a personality disorder. A greater range of signal both on the fMRI end and on the behavioral end would help provide greater power to detect associations.
One particularly relevant aspect of our approach is that the models we used, like most in the literature, were linear. Nonlinear models may be more appropriate, yet the difficulty in using such models is that they would require a much larger number of training samples relative to the number of features in the data set. This could be accomplished both by accruing ever larger databases of resting-state fMRI data, and by further reducing the dimensionality of the data, for instance, through PCA or coarser parcellations. Alternatively, one could form a hypothesis about the shape of the function that might best predict personality scores and explicitly include this in a model.
A final important but complex issue concerns the correlation between most behavioral measures. In our analyses, we regressed out fluid intelligence, age, and sex, among other variables. However, there are many more that are likely to be correlated with personality at some level. If one regressed out all possible measures, one would likely end up removing what one is interested in, since eventually the residual of personality would shrink to a very small range. An alternative approach is to use the raw personality scores (without any removal of confounds at all), and then selectively regress out fluid intelligence, memory task performance, mood, etc., and make comparisons between the results obtained (we provide such minimally deconfounded results in Supplementary Figure 2). This could yield insights into which other variables are driving the predictability of a personality trait. It could also suggest specific new variables to investigate in their own right. Finally, multiple regression may not be the best approach to addressing these confounds, due to noise in the measurements. Specifying confounds within a structural equation model may be a better approach (Westfall & Yarkoni, Reference Westfall and Yarkoni2016).
4.5. Recommendations for personality neuroscience
There are well-known challenges to the reliability and reproducibility of findings in personality neuroscience, which we have already mentioned. The field shares these with any other attempt to link neuroscience data with individual differences (Dubois & Adolphs, Reference Dubois and Adolphs2016). We conclude with some specific recommendations for the field going forward, focusing on the use of resting-state fMRI data.
(i) Given the effect sizes that we report here (which are by no means a robust estimate, yet do provide a basis on which to build), we think it would be fair to recommend a minimum sample size of 500 or so subjects (Schönbrodt & Perugini, Reference Schönbrodt and Perugini2013) for connectome-based predictions. If other metrics are used, a careful estimate of effect size that adjusts for bias in the literature should be undertaken for the specific brain measure of interest (cf. Anderson, Kelley, & Maxwell, Reference Anderson, Kelley and Maxwell2017).
(ii) A predictive framework is essential (Dubois & Adolphs, Reference Dubois and Adolphs2016; Yarkoni & Westfall, Reference Yarkoni and Westfall2017), as it ensures out-of-sample reliability. Personality neuroscience studies should use proper cross-validation (in the case of the HCP, taking family structure into account), with permutation statistics. Even better, studies should include a replication sample which is held out and not examined at all until the final model has been decided from the discovery sample (advanced methods may help implement this in a more practical manner; e.g. Dwork et al., Reference Dwork, Feldman, Hardt, Pitassi, Reingold and Roth2015).
(iii) Data sharing: If new data are collected by individual labs, it would be very important to make these available, in order to eventually accrue the largest possible sample size in a database. It has been suggested that contact information about the participants would also be valuable, so that additional measures (or retest reliability) could be collected (Mar, Spreng, & Deyoung, Reference Mar, Spreng and Deyoung2013). Some of these data could be collected over the internet.
(iv) Complete transparency and documentation of all analyses, including sharing of all analysis scripts, so that the methods of published studies can be reproduced. Several papers give more detailed recommendations for using and reporting fMRI data (see Dubois & Adolphs, Reference Dubois and Adolphs2016; Nichols et al., Reference Nichols, Das, Eickhoff, Evans, Glatard, Hanke and … Thomas Yeo2016; Poldrack et al., Reference Poldrack, Fletcher, Henson, Worsley, Brett and Nichols2008). Our paper makes specific recommendation about detailed parcellation, processing, and modeling pipelines; however, this is a continuously evolving field and these recommendations will likely change with future work. For personality in particular, detailed assessment for all participants, and justified exclusionary and inclusionary criteria should be provided. As suggested above, authors should consider preregistering their study, on the Open Science Framework or a similar platform.
(v) Ensure reliable and uniform behavioral estimates of personality. This is perhaps one of the largest unsolved challenges. Compared with the huge ongoing effort and continuous development of the processing and analysis of fMRI data, the measures for personality are mostly stagnant and face many problems of validity. For the time being, a simple recommendation would be to use a consistent instrument and stick with the Big Five, so as not to mix apples and oranges by using very different instruments. That said, it will be important to explore other personality measures and structures. As we noted above, there is in principle a large range of more subjective, or more objective, measures of personality. It would be a boon to the field if these were more systematically collected, explored, and possibly combined to obtain the best estimate of the latent variable of personality they are thought to measure.
(vi) Last but not least, we should consider methods in addition to fMRI and species in addition to humans. To the extent that a human personality dimension appears to have a valid correlate in an animal model, it might be possible to collect large data sets, and to complement fMRI with optical imaging or other modalities. Studies in animals may also yield the most powerful tools to examine specific neural circuits, a level of causal mechanism that, as we argued above, may largely elude analyses using resting-state fMRI.
Financial Support
This work was supported by NIMH grant 2P50MH094258 (R.A.), the Carver Mead Seed Fund (R.A.), and a NARSAD Young Investigator Grant from the Brain and Behavior Research Foundation (J.D.).
Conflicts of Interest
The authors have nothing to disclose.
Authors’ contributions
J.D. and P.G. developed the overall general analysis framework and conducted some of the initial analyses for the paper. J.D. conducted all final analyses and produced all figures. Y.H. helped with literature search and analysis of behavioral data. L.P. helped with literature search, analysis of behavioral data, and interpretation of the results. J.D. and R.A. wrote the initial manuscript and all authors contributed to the final manuscript. All authors contributed to planning and discussion on this project.
Supplementary Material
To view supplementary material for this article, please visit https://doi.org/10.1017/pen.2018.8. The Young Adult HCP dataset is publicly available at https://www.humanconnectome.org/study/hcp-young-adult. Analysis scripts are available in the following public repository: https://github.com/adolphslab/HCP_MRI-behavior.









 Open access
Open access