Gene interactions are commonly found in genetic experiments but their overall importance for quantitative genetics is not well understood (Phillips, Reference Phillips2008; Flint & Mackay, Reference Flint and Mackay2009). In this paper, we introduce a new way of testing for epistatic interactions when one or more QTLs affecting a quantitative character have been identified. For a specific QTL, the marginal averages, defined to be the character averages in individuals with each of the QTL genotypes, depend on other loci affecting the character. After the marginal averages are estimated in the initial population, selection can be applied. Changes in the marginal averages in the selected population reflect interactions with other loci affecting the character. In particular, the differences in the marginal averages, which we call the marginal differences, increase or decrease if interactions tend to increase or decrease the character from the expectation under additivity. Such interactions are called directional epistatic interactions by Hansen & Wagner (Reference Hansen and Wagner2001). They can affect the evolutionary dynamics of a trait even when they do not result in a substantial epistatic component of genetic variance.
Directional epistatic interactions have been discussed extensively in the context of loci affecting fitness. If alleles that increase fitness have negative interactions (i.e. overall fitness is less than would be predicted by the individual effects), then negative linkage disequilibrium results. Under some conditions, this situation can favour the evolution of increased recombination and sexual reproduction (reviewed in Otto, Reference Otto2009). This theoretical prediction has motivated a substantial number of experiments searching for consistent patterns in the sign of epistasis. No clear trend has emerged (de Visser & Elena, Reference de Visser and Elena2007; Kouyos et al., Reference Kouyos, Silander and Bonhoeffer2007). Those results, however, largely rest on two experimental paradigms: constructing genotypes with known combinations of mutations, and following changes in time and differences between mutation accumulation lines. These and other approaches used to quantify epistasis, however, have a variety of limitations that we review in the Discussion. It would therefore be useful to have other experimental strategies that could be applied to other genes, organisms and traits.
Early work on the effects of epistasis on quantitative traits was led by Cockerham (Reference Cockerham1954) and Kempthorne (Reference Kempthorne1954), who first worked out the theory for estimating epistatic components of genetic variance from the resemblance between relatives. Since then, many specific models of epistasis have been developed and analysed, some based on the deviations from additivity expressed in algebraic terms (Lewontin & Kojima, Reference Lewontin and Kojima1960) and others based on explicit assumptions about interactions of gene products (Kacser & Burns, Reference Kacser and Burns1981). In most cases, explicit models of gene interactions do not result in much epistatic variance (Keightley, Reference Keightley1989). Hansen and Wagner (Reference Hansen and Wagner2001), Barton and Turelli (Reference Barton and Turelli2004) and others have explored the properties of general models of epistasis. Pavlicev et al. (Reference Pavlicev, Le Rouzic, Cheverud, Wagner and Hansen2010) implemented the Hansen and Wagner theory and found evidence for directional epistasis between QTLs affecting several characters in inbred mice. Le Rouzic et al. (Reference Le Rouzic, Skaug and Hansen2010) developed a statistical method for estimating epistatic effects by analysing data from selection experiments. Although they did not assume that QTL frequencies could be monitored in the same experiment, their method could be adapted to allow for that possibility.
In this paper, we propose a strategy to detect directional epistasis using selection experiments. Our method differs from that used by Pavlicev et al. (Reference Pavlicev, Le Rouzic, Cheverud, Wagner and Hansen2010) because it is designed to detect directional epistasis between a previously identified QTL and all other QTLs affecting the same character, including both those that have been identified and those that are still unknown. The method used by Pavlicev et al. (Reference Pavlicev, Le Rouzic, Cheverud, Wagner and Hansen2010) tests for directional epistasis between only those QTLs that have been identified. We begin by describing a null model of additive effects across loci (i.e. no epistasis). We next define three simple models of gene interactions that will allow us to illustrate our results. The first is a completely symmetric model of epistasis for which the theory is relatively simple. We then consider two other models for epistasis in which one locus, representing a known QTL, is distinguished from the others. We then turn to detecting epistasis. Using analysis and simulation of the models, we show that with directional epistasis the average differences between the genotypes at a QTL changes following selection. We propose a statistical test for detecting these changes and examine its power.
Model assumptions
We assume that a quantitative character, x, is determined by the genotype at L unlinked diallelic loci. At each locus, the allele that tends to increase x is denoted by +. The genotype of an individual is represented by a vector k={k 1, …kL }, where ki =0, 1 or 2, indicates the number of+alleles at that locus. In general,
where f(k) is the phenotype map that specifies the average phenotype associated with each genotype. In general, f depends on 3L parameters, one for each genotype.
Our reference by which to judge the effects of epistasis is the additive model. It assumes that the contributions of each locus add:
The first and simplest of our three models that include epistasis is the symmetric model. It assumes that all+alleles are equivalent in their effect on the character, which implies that f depends only on the total number of+alleles:
where ![]() . If hi
is a linear function of i, then the symmetric model is also additive. In later analysis, we will assume quadratic functional dependence on i:
. If hi
is a linear function of i, then the symmetric model is also additive. In later analysis, we will assume quadratic functional dependence on i: ![]() . A generalization of the symmetric model assumes that a random interaction term, e
k
is added with probability q to each genotype:
. A generalization of the symmetric model assumes that a random interaction term, e
k
is added with probability q to each genotype:
The parameter q allows us to vary the sparseness of the additional epistatic terms. We will assume that each e k is drawn independently from a distribution with mean 0 and standard deviation σI.
We next consider cases in which a focal locus, which we take to be locus 1 without loss of generality, is distinguished from the others. Locus 1 represents a QTL that has already been identified in a mapping study. In our second model for epistasis, which we call conditional additive, locus 1 interacts additively with all other loci considered together, but the other loci interact among themselves:
In our third and final model for epistasis, which we call conditional epistatic, locus 1 interacts with each other locus epistatically but the other loci do not interact with one another:
The conditional epistatic model allows for directional epistasis in an especially simple context.
Population properties
The mean and total genetic variance of x in the population are
and
where Pr(k) is the frequency of genotype k in the population.
We assume there is a base population in which the frequency of the + allele at locus j is pj and the loci are in Hardy–Weinberg and linkage equilibrium. Then we allow directional selection on x to be applied. Continued random mating will ensure Hardy–Weinberg genotype frequencies each generation, but selection will create linkage disequilibrium even between unlinked loci. We will assume that selection is applied for t 1 generations and then t 2 generations of random mating occur without selection in order to allow linkage equilibrium to be restored.
We calculated the components of genetic variance in the standard way (Falconer & Mackay, Reference Falconer and Mackay1996; Lynch & Walsh, Reference Lynch and Walsh1998). The total genetic variance is V G (eqn 8). We compute ![]() and
and ![]() , where
, where ![]() are the marginal averages for locus j. Then,
are the marginal averages for locus j. Then, ![]() ,
, ![]() and VI
=VG
−VA
−VD
.
and VI
=VG
−VA
−VD
.
Marginal averages and marginal differences
Our test for epistasis depends on changes in the differences between the average phenotypes produced by genotypes at the focal QTL. The marginal averages for that QTL (locus 1) are the expectations of x, given the genotype at locus 1:
where k=0, 1, 2 corresponds to the number of+alleles at the focal locus. At linkage equilibrium, the conditional probabilities do not depend on k.
We define the marginal differences for locus 1 to be ![]() and
and ![]() . These quantities are the key to the test we propose for detecting directional epistasis: as we will see in the following sections, changes in allele frequencies cause the marginal differences to change under some types of epistasis. If the marginal differences for a locus do change that will alter the additive genetic variance the locus contributes to the trait. To see this, write the additive genetic effect of locus 1 in terms of the marginal differences:
. These quantities are the key to the test we propose for detecting directional epistasis: as we will see in the following sections, changes in allele frequencies cause the marginal differences to change under some types of epistasis. If the marginal differences for a locus do change that will alter the additive genetic variance the locus contributes to the trait. To see this, write the additive genetic effect of locus 1 in terms of the marginal differences:
The marginal differences are therefore of interest for two reasons: they provide an opportunity to test for epistasis, and changes in their values alter the contribution of a locus to the additive genetic variance for a trait.
We now consider the properties of the marginal differences under the conditional additive and conditional epistatic model, where simple analytic results can be obtained, and under the symmetric model, where we rely on numerical analysis.
The conditional additive model
In the conditional additive model, the effect of locus 1 is added to the net effect of the other L–1 loci, which may interact among themselves. It is easy to see that the expectations of the marginal averages do not depend on the allele frequencies at the other loci at linkage equilibrium. From eqn (9),
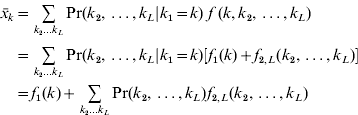
because, at linkage equilibrium, Pr(k 2, …, kL
|k 1=k) is independent of k. Therefore, ![]() and
and ![]() . The conclusion is that the marginal differences at locus 1 are independent of the allele frequencies at the other loci. In fact, all that is required for this result is that there should be linkage equilibrium between locus 1 and the others, even if there is linkage disequilibrium among the other loci.
. The conclusion is that the marginal differences at locus 1 are independent of the allele frequencies at the other loci. In fact, all that is required for this result is that there should be linkage equilibrium between locus 1 and the others, even if there is linkage disequilibrium among the other loci.
The conditional epistasis model
A different result holds under the conditional epistasis model. If locus 1 interacts with the other loci, the marginal differences may change. Substituting into eqn (9), we obtain
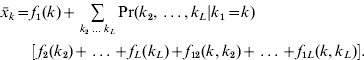
Subtracting and assuming linkage equilibrium yields
and
The third terms on the right-hand sides of these expressions represent the net effects of the epistatic interactions between locus 1 and the others. These expressions show that the marginal differences at locus 1 are functions of the allele frequencies at the other loci.
A special case of the conditional epistasis model is that in which fi (ki )=ki and f 1i(k 1,ki )=βik 1ki . Then
Thus, the changes in the marginal averages are proportional to the changes in allele frequency at the other loci, weighted by the βi.
The key conclusion that emerges from the conditional epistasis model is that the marginal differences for the focal QTL will change if there are allele frequency changes at other loci with which the focal locus has directional epistatic interactions. This motivates the experimental test proposed below, in which the allele frequencies change in response to artificial selection.
The symmetric model
The general model is not analytically or even numerically tractable for more than a few loci. This situation motivates the symmetric model, in which the frequency and effect of the + allele is assumed to be the same at all loci. These assumptions lead to a relatively simple theory that can be analysed numerically for larger numbers of loci.
Our analysis is based on that of Barton (Reference Barton1992) . We assume an infinitely large population and ignore the effects of genetic drift. The population is characterized by the frequencies of gametes carrying i+alleles. A generation consists of the random union of gametes, then selection based on the number of+alleles in zygotes, and finally free recombination to create the next generation of gametes. After one generation
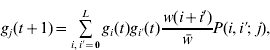
where gi
(t) is the frequency of gametes carrying i+alleles in generation t, w(i+i′) is the relative fitness of an individual with i+i′+alleles, ![]() is the average fitness in the population and P(i,i′;j) is the probability that an individual with gametes carrying i and i′+alleles will produce a gamete with j+alleles. Barton (Reference Barton1992) derived the expression for P by assuming all configurations of+alleles are equally probable in a gamete carrying i+alleles:
is the average fitness in the population and P(i,i′;j) is the probability that an individual with gametes carrying i and i′+alleles will produce a gamete with j+alleles. Barton (Reference Barton1992) derived the expression for P by assuming all configurations of+alleles are equally probable in a gamete carrying i+alleles:
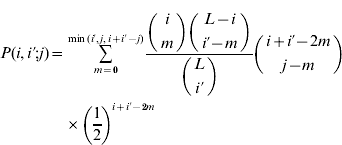
if i′⩽i and max(i+i′−L)⩽j⩽min(i+i′−L). By symmetry P(i,i′; j)=P(i′,i; j). Because the ratio of binomial coefficients in the sum is the same as the ratio in the hypergeometric probability distribution, this model is sometimes called the hypergeometric model. We compute the marginal differences and the variance components for the symmetric model as described in Appendix A. A Mathematica program that carries out these calculations is available on request.
There is no closed form solution for this model, but it is easy to iterate numerically for an arbitrary fitness function, w. Here we will assume truncation selection for larger x and let αx be the fraction of zygotes that survive to breed. Our interest is with the dependence on the marginal differences on the phenotype map, hi .
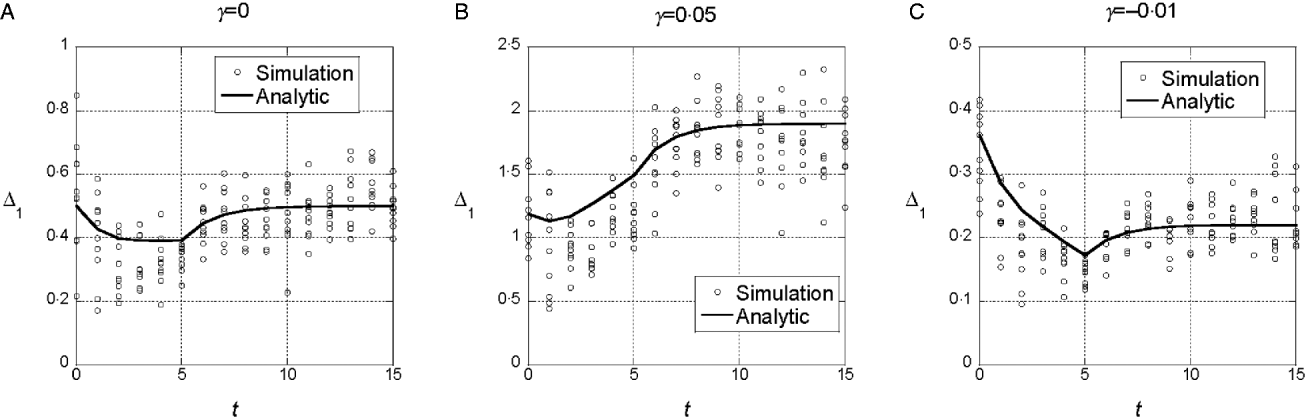
We assumed a quadratic phenotype map, ![]() , in order to contrast the results for the additive model (γ=0) with models that assume synergistic (γ>0) and antagonistic (γ<0) interactions of+alleles. Figure 1 shows typical results for experiments in which five generations of truncation selection with αx=0·5 are followed by 10 generations with no selection. In the additive model, the marginal differences initially decrease because of the accumulation of linkage disequilibrium, but then return to their original values after 10 generations of random mating. In contrast, if γ>0, the marginal differences are larger than their initial values after linkage equilibrium has been re-established (Fig. 1 b), and if γ<0, the marginal differences are smaller than their initial values (Fig. 1 c).
, in order to contrast the results for the additive model (γ=0) with models that assume synergistic (γ>0) and antagonistic (γ<0) interactions of+alleles. Figure 1 shows typical results for experiments in which five generations of truncation selection with αx=0·5 are followed by 10 generations with no selection. In the additive model, the marginal differences initially decrease because of the accumulation of linkage disequilibrium, but then return to their original values after 10 generations of random mating. In contrast, if γ>0, the marginal differences are larger than their initial values after linkage equilibrium has been re-established (Fig. 1 b), and if γ<0, the marginal differences are smaller than their initial values (Fig. 1 c).
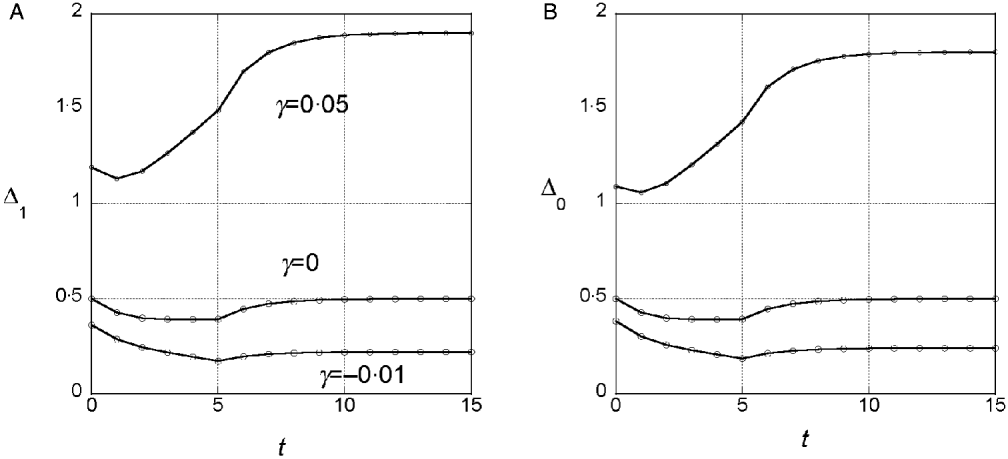
Fig. 1. Time dependence of the marginal differences, Δ1 and Δ0, after five generations of truncation selection with αx=1/2. The phenotype map in each case is ![]() . In all cases, β=0·5. Generation 0 is the initial population assumed to be in Hardy–Weinberg and linkage equilibrium with p=0·3 at all 10 loci. Selection was applied in generations 0–4 followed by 10 generations of random mating without selection.
. In all cases, β=0·5. Generation 0 is the initial population assumed to be in Hardy–Weinberg and linkage equilibrium with p=0·3 at all 10 loci. Selection was applied in generations 0–4 followed by 10 generations of random mating without selection.
This trend in the results does not require much synergistic or antagonistic interaction and these interactions do not create much interaction variance once linkage equilibrium is re-established. The final values of V I/V G are 0·002 for γ=0·05 and 0·015 for γ=−0·01.
We conclude from these numerical results that the marginal differences are sensitive to relatively weak gene interactions and that they are sensitive to gene interactions that do not create significant interaction components of the genetic variance.
Statistical test for changes in marginal differences
The symmetric model shows that the marginal differences depend on directional epistatic interactions between a QTL and other loci. To detect a significant change in the marginal differences, either in real or simulated data, a statistical test is needed. We developed a likelihood ratio test that is described in Appendix B. The test compares the genotype-specific distributions of the character in the initial and final populations. The data are in six vectors, {xki
} for the starting population and {yki
} for the final population, where k=0, 1, 2 is the number of copies of the+allele at the QTL. We assume that the elements of each vector are drawn from a normal distribution with means μkx or μky and variances Vkx
or Vky
. Our test is of whether ![]() and
and ![]() under the assumption that the variances can take any values. Our test assumes that twice ratio of likelihoods computed under the assumption of no constraints on the means and under the assumption of these two constraints has a χ2 distribution with two degrees of freedom. The P-value reported is the tail probability of this distribution.
under the assumption that the variances can take any values. Our test assumes that twice ratio of likelihoods computed under the assumption of no constraints on the means and under the assumption of these two constraints has a χ2 distribution with two degrees of freedom. The P-value reported is the tail probability of this distribution.
Like any statistical test, the power of this test increases with sample size. The power can be increased by accumulating data from several generations before and after selection is performed. In this way, larger total sample sizes can be obtained without having to increase the total size of the populations studied.
Simulations
The numerical analysis of the symmetric model assumes that selection is performed in infinitely large populations and that allele frequencies at all loci are the same in each generation. We wrote a simulation program for finite populations to test whether the trends seen in those analyses can be detected in selection experiments and to analyse other models for epistasis.
The simulation program assumes that a population of 2N gametes is formed into N zygotes. A phenotype x is assigned to each zygote according the specified phenotype map. Then the Ns =αxN individuals with the largest x are chosen to breed. Meiosis was modelled by randomly choosing individuals with replacement 2N times from the breeding pool and generating a random gamete from each, assuming no linkage. Because the gametes are paired randomly into zygotes, this method is equivalent to allowing self-fertilization.
In each generation, we recorded the marginal differences and the genetic, additive, dominance and epistatic components of the genetic variance. After t 1+t 2 generations, we tested for significant changes in the marginal differences at locus 1 to obtain a P-value of the test that there was no change in the marginal differences.
Simulation results for the symmetric model
Figure 2 shows the simulation results for the marginal differences in the symmetric model for the same parameter values used in Fig. 1. The numerical results from Fig. 1 are included for comparison. In Fig. 2, the marginal differences for all 10 loci are plotted for each generation. In the symmetric model, all loci are equivalent, and hence variation among loci represents the variation among replicates for a single locus. The simulation results are consistent on average with the results for an infinitely large population and they illustrate that there is substantial stochastic variation even with N=1000. It is worth noting that the stochastic variation seen is not the result of the instability of allele frequencies caused by selection. Although the equality of allele frequencies in a symmetric model may be unstable to some kinds of selection (Barton & Shpak, Reference Barton and Shpak2000), that is not the case with the selection model we used. In these and other simulation results for the symmetric model, allele frequencies at different loci do not vary more than would be expected under genetic drift alone acting for the same number of generations. Instead, the variation in the marginal differences results from stochastic variation in linkage disequilibrium among the loci.
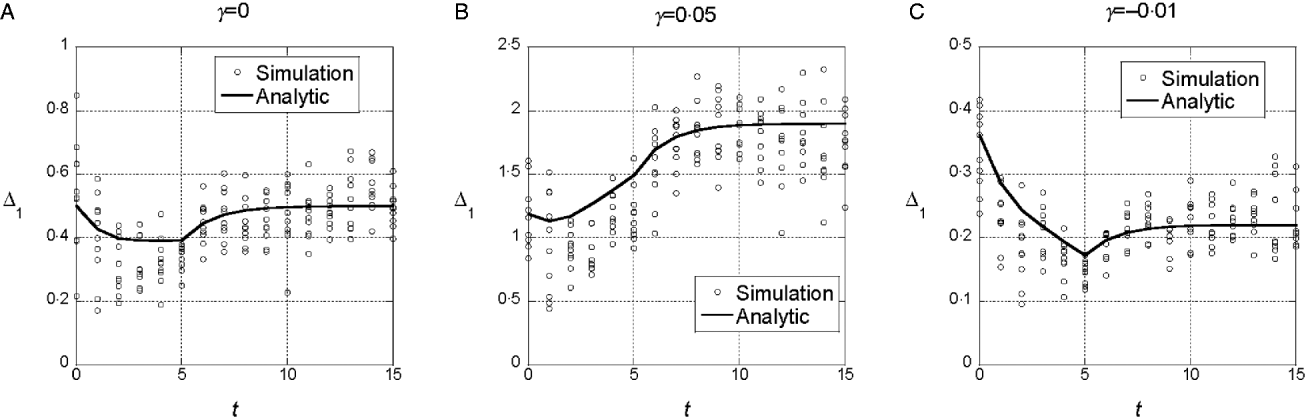
To determine whether significant changes in the marginal differences can be detected with the test described above, we ran 100 replicates each with the same parameter values used in the three cases shown in Fig. 2 but with ![]() chosen so that the heritability in each case is roughly 1/2:
chosen so that the heritability in each case is roughly 1/2: ![]() =1.1 for γ=0, 3·0 for γ=0·5 and 0·9 for γ=−0·1. For 3A (linear model), 5% had a significant change in the marginal differences at the 5% level. For 3B (synergistic), 31% were significant at the 5% level and for 3C (antagonistic) 14% were significant.
=1.1 for γ=0, 3·0 for γ=0·5 and 0·9 for γ=−0·1. For 3A (linear model), 5% had a significant change in the marginal differences at the 5% level. For 3B (synergistic), 31% were significant at the 5% level and for 3C (antagonistic) 14% were significant.
These simulation results confirm that the average behaviour predicted by the analytic theory is seen in populations of finite size and that there is some power to detect significant changes in the marginal differences. The symmetric model we analysed is not a realistic model for interactions affecting quantitative character, however, because all interactions are in the same direction. As a consequence, V G is predicted to change systematically in a way not seen in selection experiments. With γ=0·05, V G almost doubles and if γ=−0·01, it decreases by almost a half.
Simulation results for other models
The results from the symmetric model indicate that deviations from the additive model of the same sign (either synergistic or antagonistic) tend to have consistent effects on the marginal differences. To determine whether those results are sensitive to additional random epistatic effects, we simulated the model with the randomly generated interaction term, eqn (4). Figure 3(a) shows that if γ=0, selection on x does not tend to change the marginal differences, even though the additional interaction terms create a substantial interaction component of the variance. After linkage equilibrium is re-established, V I/V G≈0·25. With both synergistic (γ>0) and antagonistic (γ<0), the trends in the marginal differences persist (Fig. 3 b and c). In sets of 100 replicate simulations for each set of parameter values, we tested whether the marginal differences changed significantly at the 5% level. In 100 replicates, we found 10% significant changes in the marginal differences for the parameters in 3A (with ![]() ), 56% for 3B (with
), 56% for 3B (with ![]() ) and 5% for 3C (with
) and 5% for 3C (with ![]() )
)
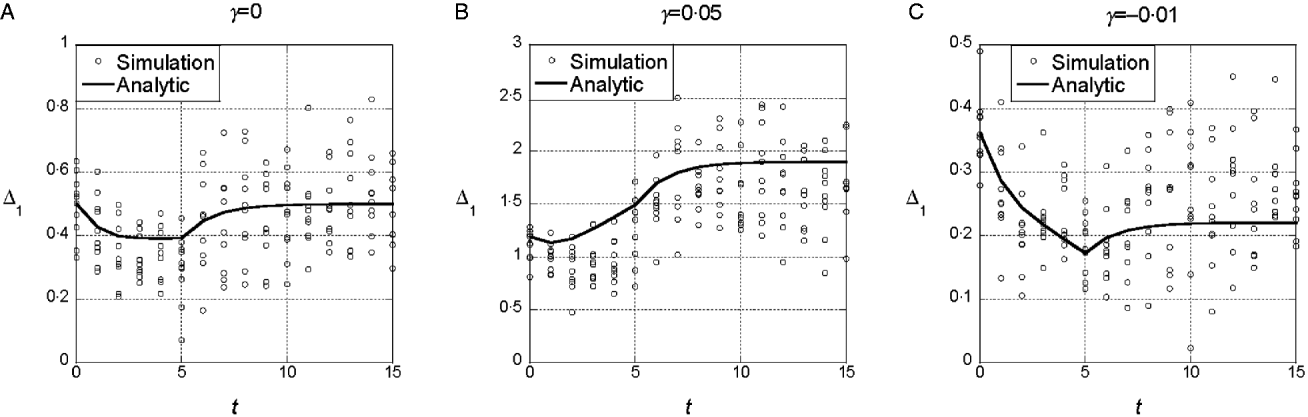
Fig. 3. Time dependence of Δ1 and Δ0 in the model with random epistatic terms added to the quadratic dependence on i (cf. eqn (4)). The parameter values are the same as in Figs 1 and 2. The additional epistatic term for each genotype was drawn with probability q=0.5 from a normal distribution with mean 0 and standard deviation σI =1. The predictions of the analytic theory from Fig. 1 are plotted with solid lines for comparison.
We determined the power of the likelihood ratio test for the conditional epistasis model with f 1i(k 1, ki
)=βi1ki
. Table 1 shows some results for L=10, pi
=0·2 initially, and the same β used for i=2, …, 10. With the parameter values used, the average pi
was approximately 0·8 in the final population. Therefore, from eqn (15) the expected change in the marginal differences is ![]() or approximately 10·6β. We can see there is some power to detect significant changes in marginal differences, particularly if N=1000.
or approximately 10·6β. We can see there is some power to detect significant changes in marginal differences, particularly if N=1000.
Table 1. Power to detect significant changes in the marginal differences (Δ1 and Δ0) for the conditional epistasis model. In all cases, 100 replicate simulations were run, αx=0·5, L=10, f1(k1)=k1, the frequency of the+allele was initially 0·2 at every locus, and the same value of βi was assumed for loci i=2, …, 10. If the+allele became fixed after selection, the test could not be performed. The numbers shown are the fractions of replicates for which the likelihood ratio test was performed and P⩽0·05. The numbers in parentheses are the numbers of tests performed
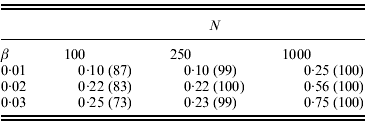
As mentioned above, the power of our test can be increased if information is accumulated over several generations before and after selection. To illustrate, we ran additional simulations for the middle cell in Table 1 (N=250 and β=0·02). With data taken in one generation before and after selection was performed, 22% of the replicates had a significant change in the marginal differences at the 5% level. With data accumulated over three generations before and after, 47% of the replicates were significant and over five generations before and after 62% were significant.
Discussion and conclusions
Four research strategies are currently used to study epistasis among genes affecting quantitative traits, each with its strengths and weaknesses. The total genetic variance can be decomposed to determine the contribution from epistasis (Cockerham, Reference Cockerham1954; Kempthorne, Reference Kempthorne1954). Limitations of this approach are that it does not give information about the form of epistasis, or how epistasis will affect evolutionary dynamics. A second approach is to construct known genotypes to study interactions between loci (Flint & Mackay, Reference Flint and Mackay2009). This strategy has the virtues that it can directly identify loci that interact, and allows the interactions to be quantified in detail and studied experimentally. It is limited to organisms in which appropriate mutations have been characterized and by the number of mutant combinations that can be constructed and analysed. A third strategy is to analyse replicated mutation accumulation lines (Elena & Lenski, Reference Elena and Lenski1997). The dynamics of trait values (such as fitness) within lines and differences between lines can be used to estimate parameters of epistasis. The strength of this method is that it can in principle detect the effects of epistasis at loci throughout the genome, and these loci do not need to be identified a priori. A major limitation is that it quantifies only the epistatic effects of spontaneous mutations, which may not be typical of genes segregating in natural populations. A fourth method used to study epistasis is QTL mapping (Manichaikul et al., Reference Manichaikul, Moon, Sen, Yandell and Broman2010). This approach identifies the QTLs involved, but is constrained by statistical power to detecting only strong epistatic interactions.
This paper proposes a new strategy for studying epistasis that complements these other methods. Its strengths are that it can detect contributions to epistasis from naturally segregating variation at loci throughout the genome. Its limitations are that it requires a large replicated selection experiment and is sensitive to only certain types of epistasis. The principle of our method depends on the fact that the marginal effects of a known QTL depend on the epistatic interactions of that locus with other loci affecting the same character. Changes in allele frequencies at those loci change the genetic environment for the QTL (Phillips, Reference Phillips2008). This generalization implies that changes in the marginal effects of a known QTL can provide evidence of interactions that tend to be in one direction, either synergistic or antagonistic. Furthermore, interactions that affect the marginal differences do not necessarily lead to a substantial interaction component of the genetic variance and therefore might not be detected by studies that focus on variance components.
Our method is not able to detect all types of epistatic interactions, only those that result in a net directional component. As shown in Fig. 3(a), interactions can be present and can generate a substantial interaction component of the variance and yet will not result in a net change in the marginal differences because their effects tend to cancel.
Our numerical and simulation results show that synergistic and antagonistic interactions result in predictable changes in the marginal differences, on average. At first sight, it may seem unlikely that epistatic interactions would show a bias towards synergistic or antagonistic interactions. It is, however, well established that dominance interactions often display directionality. Deleterious mutations are typically partly recessive (Eyre-Walker & Keightley, Reference Eyre-Walker and Keightley2007), and consistent dominance patterns have been seen for other kinds of traits, a phenomenon called ‘directional dominance’ (Falconer & Mackay, Reference Falconer and Mackay1996, p. 250). If dominance (i.e. interactions between alleles at a single locus) can show consistent patterns, it is plausible that epistasis (which is interactions between alleles at different loci) will also. Metabolic control theory gives support to that view (Keightley, Reference Keightley1989).
In our analysis, we have assumed that QTLs are unlinked. In that case a few generations of random mating with no selection will restore linkage equilibrium. Our conclusions are still true if there is very close linkage between the focal QTL and others. In the time scale of the experiment, very closely linked QTLs would behave as a single QTL because recombination between them would be unlikely. Complications arise if there is weaker linkage between the focal QTL and one or more unseen QTLs. Even if they are in linkage equilibrium in the initial population, directional selection would create LD between them that would not decay in a few generations of random mating. The remaining LD could create a false signal of directional epistasis that would decline if more generations of random mating were allowed. If a signal of significant directional epistasis were found in an experiment, it would be necessary to test for the presence of a linked QTL by doing controlled crosses.
Our method tests for directional epistasis between a specific QTL and others. If there were directional epistasis between all QTLs in the same direction, as in our symmetric model, then the directionality of the interactions would also be indicated by the response of the character mean to selection (an outcome that can also result from dominance). The mean would increase more than linearly in response to selection. In that case, the directionality could be removed by changing the scale of measurement so that the selection response is linear. The situation is different if the focal QTL interacts with others but they do not interact among themselves, as in our conditional epistasis model. Even when there are significant changes in the marginal differences, we found that the average response to selection is not distinguishable from linear. In a model in which there are positive directional interactions with one QTL and negative interactions with another, the effect of the directional interactions would cancel on average while directionality for each QTL could in principle be detected with our method.
It may be difficult to detect epistatic interactions by the approach explored in this paper because of the large stochastic fluctuations in the marginal differences. These stochastic fluctuations reflect the fact that the marginal differences are the difference in the averages of two distributions that are quite similar unless the QTL accounts for a substantial fraction of the genetic variance. Nevertheless, changes in marginal differences after selection reflect kinds of epistatic interactions that cannot be detected by other means.
Although relatively large sample sizes are required to detect significant directional epistasis between a known QTL and other QTLs that affect the same character, that is a problem for classical tests of epistatic interactions as well. Large sample sizes are needed to estimate additive by additive and other components of genetic variance from breeding experiments (Hill et al., Reference Hill, Goddard and Visscher2008). Estimates for the genetic variance resulting from epistasis, however, cannot predict evolutionary consequences, for example how the selection response will change as allele frequencies evolve.
Our method will not be effective in detecting directional epistasis caused by interactions with low frequency alleles. Changes in the marginal differences result from changes in the frequency of unseen QTLs because of directional selection, and low frequency alleles will respond very slowly to directional selection. However, low frequency alleles would be expected to contribute little to directional epistasis (cf. eqn 15), just as they contribute little to the interaction variance (Hill et al., Reference Hill, Goddard and Visscher2008). Epistatic interactions with more common QTLs may not contribute much to the interaction component of the genetic variance, even if they can be detected from changes in the marginal differences.
Our results also suggest a way to detect loci strongly affected by epistatic interactions. The idea is to perform a genome-wide association study (GWAS) for a quantitative character in an initial population and again after several generations of directional selection on the character. An experiment of this type was carried out by Burke et al. (Reference Burke, Dunham, Shahrestani, Thornton, Rose and Long2010) . They selected for accelerated development in Drosophila melanogaster and tested for significant differences in single nucleotide polymorphism (SNP) frequencies between selected and unselected (control) populations in order to identify SNPs associated with development time. In such an experiment, SNPs for which the marginal differences change substantially would likely be closely linked to loci that are affected by epistatic interactions. Although the statistical problems arising in the analysis of such data are formidable and complications would arise because linkage disequilibrium between the SNPs surveyed and causative genes could change, data from independent replicates would give increasing power to detecting interacting loci if they are present. Decreasing costs of genotyping on a genome wide scale will make such experiments increasingly feasible.
Acknowledgements
We thank J. Felsenstein and Y. S. Song for helpful discussions of this topic and comments on a draft of this paper. M. S. was supported in part by NIH Grant R01-GM40282 and M. K. was supported in part by NSF Grant DEB-0819901.
Appendix A. Formulae for symmetric model
We show here the formulae for calculating the marginal averages and components of genetic variance for the symmetric model with equal allele frequencies. From the distribution of the number of+alleles in gametes, gi . the distribution in zygotes is the convolution of gi with itself:
Therefore,
and
The distribution of i in gametes, given that one of the loci has k=0 or 1+alleles, is
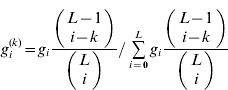
(i=0, …, L), where the binomial coefficients are assumed to be 0 if either of the arguments is negative. The marginal averages are then
and
The marginal differences, Δ1 and Δ0, are obtained by subtraction. For each locus, ![]() and
and ![]() . Substituting these into the expressions given in the text, V A, V D and V I are obtained.
. Substituting these into the expressions given in the text, V A, V D and V I are obtained.
Appendix B. Likelihood ratio test for a change in the marginal differences
In the initial population, there are mk individuals with k+alleles at locus 1 and nk in the final population. In the initial population, the phenotypes of individuals with each of the three genotypes are vectors with elements xki (k=0, 1, 2 and i=1, …, mk ) and in the final population they are yki (k=0, 1, 2 and i=1, …, nk ). We assume the x's and y's are normally distributed with arbitrary means and variances.
In the unconstrained model, the parameters of the normal distributions for xki are μkx and Vkx and for yki the parameters are μky and Vky .
The likelihood expressed as a function of these means and variances is
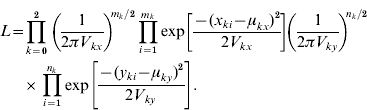
For the unconstrained model, the maximum likelihood estimates of the means and variances are the same as for three independent normal distributions:
with similar expressions for μky, and
(k=0, 1, 2) with similar expressions for the Vky .
The marginal differences at the beginning of the experiment are ![]() and
and ![]() and at the end of the experiment they are
and at the end of the experiment they are ![]() and
and ![]() . We want to test the hypothesis that
. We want to test the hypothesis that ![]() and
and ![]() . To do so, we find the maximum likelihood estimates for a model in which the variances can take any value but the means are constrained to satisfy
. To do so, we find the maximum likelihood estimates for a model in which the variances can take any value but the means are constrained to satisfy ![]() and
and ![]() .
.
For the constrained model, the six equations for the variances, given the means, are the same as for the unconstrained model. We parameterize the constrained model by setting ![]() ,
, ![]() ,
, ![]() and
and ![]() . We find that the maximum likelihood estimates of μ1x, μ1y, Δ1 and Δ0 have to satisfy the following four equations:
. We find that the maximum likelihood estimates of μ1x, μ1y, Δ1 and Δ0 have to satisfy the following four equations:
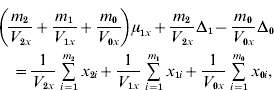
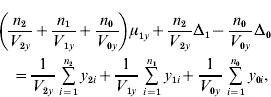
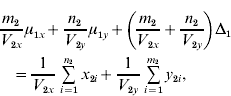
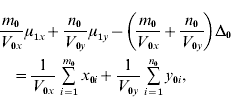
where the carats have been omitted for notational convenience.
In the constrained model, the estimates of the variances depend on the means and the estimates of the μs and Δs depend on the variances. To solve all 10 equations, we used an EM algorithm that starts with the means and variances from the unconstrained model, estimates the means by solving the above four equations, re-estimates the variances from the new means, and continues until the maximum change in any of the estimates in one cycle is less than a specified small value (10−8). This procedure converged in a few iterations in all cases ran. We then computed the logarithm of the ratio of likelihoods under the unconstrained and constrained models and computed a P-value from a χ2 distribution with two degrees of freedom. We found in a simulation test of a null model that this test rejected the null hypothesis at the 5% level roughly 5% of the time.