



No CrossRef data available.
Article contents
Deep learning for morphological identification of extended radio galaxies using weak labels
Published online by Cambridge University Press: 07 September 2023
Abstract
The present work discusses the use of a weakly-supervised deep learning algorithm that reduces the cost of labelling pixel-level masks for complex radio galaxies with multiple components. The algorithm is trained on weak class-level labels of radio galaxies to get class activation maps (CAMs). The CAMs are further refined using an inter-pixel relations network (IRNet) to get instance segmentation masks over radio galaxies and the positions of their infrared hosts. We use data from the Australian Square Kilometre Array Pathfinder (ASKAP) telescope, specifically the Evolutionary Map of the Universe (EMU) Pilot Survey, which covered a sky area of 270 square degrees with an RMS sensitivity of 25–35 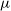 $\mu$Jy beam
$\mu$Jy beam $^{-1}$. We demonstrate that weakly-supervised deep learning algorithms can achieve high accuracy in predicting pixel-level information, including masks for the extended radio emission encapsulating all galaxy components and the positions of the infrared host galaxies. We evaluate the performance of our method using mean Average Precision (mAP) across multiple classes at a standard intersection over union (IoU) threshold of 0.5. We show that the model achieves a mAP
$^{-1}$. We demonstrate that weakly-supervised deep learning algorithms can achieve high accuracy in predicting pixel-level information, including masks for the extended radio emission encapsulating all galaxy components and the positions of the infrared host galaxies. We evaluate the performance of our method using mean Average Precision (mAP) across multiple classes at a standard intersection over union (IoU) threshold of 0.5. We show that the model achieves a mAP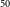 $_{50}$ of 67.5% and 76.8% for radio masks and infrared host positions, respectively. The network architecture can be found at the following link: https://github.com/Nikhel1/Gal-CAM
$_{50}$ of 67.5% and 76.8% for radio masks and infrared host positions, respectively. The network architecture can be found at the following link: https://github.com/Nikhel1/Gal-CAM
Keywords
- Type
- Research Article
- Information
- Copyright
- © The Author(s), 2023. Published by Cambridge University Press on behalf of the Astronomical Society of Australia
Footnotes
Permanent address: Depto. de Astronomía, DCNE, Universidad de Guanajuato, Guanajuato, CP, Mexico
References
Ahn, J., Cho, S., & Kwak, S. 2019, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2209Google Scholar
Bowles, M., Scaife, A. M. M., Porter, F., Tang, H., & Bastien, D. J. 2020, MNRAS, 501, 4579
CrossRefGoogle Scholar
Chen, Z., et al. 2022, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 969Google Scholar
Comrie, A., et al. 2021, CARTA: The Cube Analysis and Rendering Tool for Astronomy, Zenodo
Google Scholar
Hay, S., O’Sullivan, J., Kot, J., & Granet, C. 2006, in ESA Special Publication, Vol. 626, The European Conference on Antennas and Propagation: EuCAP 2006, ed. Lacoste, H., & Ouwehand, L., 663Google Scholar
Leahy, J. P. 1993, in Jets in Extragalactic Radio Sources, ed. Röser, H.-J., & Meisenheimer, K., Vol. 421, 1Google Scholar
Lin, T.-Y., et al. 2014, in Computer Vision – ECCV 2014, ed. Fleet, D., Pajdla, T., Schiele, B., & Tuytelaars, T. (Cham: Springer International Publishing), 740Google Scholar
Perley, R. A., Chandler, C. J., Butler, B. J., & Wrobel, J. M. 2011, ApJ, 739, L1
CrossRefGoogle Scholar
Whiting, M., Voronkov, M., Mitchell, D., & Team, Askap. 2017, in Astronomical Society of the Pacific Conference Series, Vol. 512, Astronomical Data Analysis Software and Systems XXV, ed. Lorente, N. P. F., Shortridge, K., & Wayth, R., 431
Google Scholar
Wu, Y., & He, K. 2018, in Proceedings of the European Conference on Computer Vision (ECCV), 3CrossRefGoogle Scholar
Zhou, B., Khosla, A., Lapedriza, A., Oliva, A., & Torralba, A. 2016, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2921Google Scholar