


1. Introduction
One way quota programs imposed on producers are enforced is a two-tier price system. Under this system, a quota-restricted output receives different prices depending on whether it is delivered inside or outside the quota. Usually prices for surplus output are unprofitably low. However, producers may still plan to overproduce their allotted quota if yields are uncertain (Fraser, 1986, Reference Fraser1995). Such excess production protects producers from two potential losses that are associated with yield uncertainty (Alston and Quilkey, Reference Alston and Quilkey1980). These losses are the loss of revenue from forgone sales when quota shortfalls occur and the loss of unused quota in future allocations of production rights. In the context of dairy production, Alston and Quilkey (Reference Alston and Quilkey1980) termed such excess production as “insurance milk.”
Fraser (1986, Reference Fraser1995) provided a more formal treatment of yield uncertainty when modeling the relationship between planned production and yield uncertainty. Babcock (Reference Babcock1990) extended the treatment to risk-averse producers. Building on Babcock's framework, Borges and Thurman (Reference Borges and Thurman1994) proposed an approach to compute the probability of planned production exceeding quota and the relative importance of price incentives for supply response in the two-tier price setup. Using data from peanut production in North Carolina, Borges and Thurman (Reference Borges and Thurman1994) found that planned production was likely to exceed the quota with a high probability, ranging from 0.87 to 0.97. Furthermore, the relative importance of price changes in the quota peanut market for supply response was at least 30 times higher compared with equivalent price changes in the surplus peanut market.
Similar empirical studies are lacking for the dairy sector. This deficiency is surprising given that the pioneering work of Alston and Quilkey (Reference Alston and Quilkey1980) was on dairy production, and milk supply management using marketing quotas has been pervasive (e.g., in Canada, the European Union until April 2015, Norway, Iceland, and California in the United States). Furthermore, though to a lesser extent, dairy production can be affected by yield uncertainty, arising from different sources. For example, in relatively small dairy enterprises, a significant portion of forage is produced on the farm. The implication is that weather-related risks that are usually associated with crop production can also be sources of yield uncertainty in dairy production. Weather-related sources of uncertainty are especially likely in areas where dairy production takes place under difficult agroecological conditions. In such cases, adverse weather can also have implications beyond forage production such as on animal health because dairy cows may have to be kept indoors for extended periods of time (Jóhannesson, Reference Jóhannesson2010). Other sources of milk yield uncertainty are random occurrences of dairy cow diseases such as mastitis, death of cows, incorrect detection of ovulation for artificial insemination, and optimization errors.
This article has four objectives. First, the Borges and Thurman (Reference Borges and Thurman1994) model is augmented to consider multiple inputs. The consideration of multiple inputs is important for two reasons. First, when any single input is chosen to compute yield in a multiple input setting, the underlying assumption is that the probability distribution of yield per this single input is unaffected by the application of the remaining inputs (Babcock, Reference Babcock1990). However, the probability distribution of yield per any single input in agriculture is likely to be affected by the application of other inputs. For example, Nelson and Preckel (Reference Nelson and Preckel1989) showed that the application of fertilizer in five Iowa counties had a significant effect on the first three moments of a corn yield distribution. Similarly, Babcock and Hennessy (Reference Babcock and Hennessy1996) found that the application of fertilizer up to 200 pounds an acre decreased the probability of low yields on experimental Iowa corn farms. Second, yield data constructed based on a single input portray the chosen input as more productive than it actually is as long as the marginal product of all other inputs is positive. To the contrary, farmers are likely to perceive the chosen input as less productive than portrayed by the yield data. An implication is that the observed level of the chosen input is larger than what farmers would have used if they had perceived it as productive as implied by the yield data. Because the observed input levels are used to infer planned production, the seemingly overapplication of the chosen input will exaggerate the likelihood of overproduction.Footnote 1
With the increasing availability of detailed farm management data, one way to address these problems is to compute yield levels in such a manner that the contribution of other inputs to total output is accounted for. This result is achieved by computing yield per aggregate input rather than any particular single input. Aggregation over multiple inputs is achieved using weights obtained from a parametric production frontier. In addition to facilitating the aggregation of inputs, estimating a parametric frontier has an additional benefit in the context of yield density estimation. This benefit relates to the fact that yield data come from farms that are not always fully technically efficient. Therefore, by providing farm- and time-specific technical efficiency scores, the estimation of a parametric frontier facilitates data pooling under fewer assumptions than are required when aggregate data are used.
Using the augmented approach, a second objective is to compute the probability of planned production exceeding quota on Icelandic dairy farms. Third, the relative marginal importance of price changes in the quota and surplus milk markets is computed. These estimates are the primary policy-relevant outputs of this exercise because they are useful for evaluating, for instance, the supply effects of price changes in the quota milk market, which are usually determined administratively. Finally, the implication of allowing for multiple inputs is evaluated by comparing the results from the augmented approach with the results from an approach that considers a single input only.
2. Model
The theoretical model used in this article is a modified version of the model in Borges and Thurman (Reference Borges and Thurman1994). The modification relates to the lack of opportunities for Icelandic dairy farms to carry over their unused milk quota to a subsequent production period.Footnote 2 In the remainder of this section, the Borges and Thurman (Reference Borges and Thurman1994) model based on an aggregate input is presented first. A discussion on the construction of the aggregate input follows.
2.1. Probability of Surplus Production and Relative Marginal Importance of Price Changes
Let y be the milk yield per unit of an aggregate input x, and Y be the total milk that is produced by a dairy farm, which is constrained by a farm-level quota q. Then, q/x is the yield that is required per unit of an aggregate input to meet the quota exactly or the yield requirement. Yield is random, and f(y) is its probability density function. Consequently, Y = x · y, and the production problem of the farm reduces to a choice of aggregate input quantity. In this setting, the observed levels of the aggregate input provide information concerning the unobservable planned production given the yield density, which then allows evaluation of planned production relative to each farm's quota. For example, if the yield requirement is smaller than the expected yield at the chosen level of the aggregate input, then we can infer that the dairy farm must have planned to overproduce its quota.
Under risk neutrality, no price uncertainty, and no carryover of unused quota, the economic problem of the dairy farm can be presented as a maximization of expected profit, as given in Borges and Thurman (Reference Borges and Thurman1994):
 $$\begin{eqnarray}
E\left( \Pi \right) &=& \int_0^{q/x} {\left[ {p_q^{}xy} \right]f\left( y \right)} \,dy \nonumber\\
&& +\,\int_{q/x}^{\infty} {\left[ {p_q^{}q + {p_a}\left( {xy - q} \right)} \right]} \,f\left( y \right)dy - C\left( x \right),
\end{eqnarray}$$
$$\begin{eqnarray}
E\left( \Pi \right) &=& \int_0^{q/x} {\left[ {p_q^{}xy} \right]f\left( y \right)} \,dy \nonumber\\
&& +\,\int_{q/x}^{\infty} {\left[ {p_q^{}q + {p_a}\left( {xy - q} \right)} \right]} \,f\left( y \right)dy - C\left( x \right),
\end{eqnarray}$$
where pq is the milk price in the quota milk market, pa is the milk price in the surplus milk market, and C(x) is the cost of employing x. That is, the expected profit is the excess of a weighted sum of revenues over production cost. The probabilities that the milk yield will be within or above the quota are used as weights. As in Borges and Thurman (Reference Borges and Thurman1994), Φ = ∫∞ q/x f(y) dy is an estimate of the probability that planned production may exceed the farm's quota.
Following the same procedure as in Borges and Thurman (Reference Borges and Thurman1994), the relative marginal importance of price changes in the quota and surplus milk markets would be the following:Footnote 3
 $$\begin{equation}
\Theta _q = \frac{{{{\partial x}
/ {\partial p_q}}}}{{{{\partial x}
/ {\partial p_q}} + {{\partial x}
/ {\partial p_a}}}} = \frac{{\int_0^{q/x} {yf\left( y \right)dy} }}{{\int_0^{\infty} {yf\left( y \right)dy} }}, 0 \le \Theta _q \le 1,
\end{equation}$$
$$\begin{equation}
\Theta _q = \frac{{{{\partial x}
/ {\partial p_q}}}}{{{{\partial x}
/ {\partial p_q}} + {{\partial x}
/ {\partial p_a}}}} = \frac{{\int_0^{q/x} {yf\left( y \right)dy} }}{{\int_0^{\infty} {yf\left( y \right)dy} }}, 0 \le \Theta _q \le 1,
\end{equation}$$
 $$\begin{equation}
\Theta _a = 1 - \Theta _q.
\end{equation}$$
$$\begin{equation}
\Theta _a = 1 - \Theta _q.
\end{equation}$$
Θ
q
measures the relative marginal importance of a price change in the quota milk market relative to an equivalent and simultaneous price change in the quota and surplus milk markets. Therefore, Θ
q
implies the increasing importance of price changes in the quota milk market as it gets closer to unity and vice versa. Furthermore, as noted by Borges and Thurman (Reference Borges and Thurman1994),
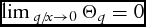 $\mathop {\lim \,}_{{q / {x \to 0}}} \Theta _q = 0$
and
$\mathop {\lim \,}_{{q / {x \to 0}}} \Theta _q = 0$
and
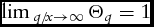 $\mathop {\lim \,}_{{q / {x \to \infty }}} \Theta _q = 1$
. This outcome is intuitive because for a given quota size, the relative marginal importance of a price change in the quota milk market decreases as q/x gets smaller, which indicates a producer that is planning to overproduce its quota. In contrast, when a producer seeks to avoid overproduction, q/x increases and the relative marginal importance of a price change in the quota milk market increases.
$\mathop {\lim \,}_{{q / {x \to \infty }}} \Theta _q = 1$
. This outcome is intuitive because for a given quota size, the relative marginal importance of a price change in the quota milk market decreases as q/x gets smaller, which indicates a producer that is planning to overproduce its quota. In contrast, when a producer seeks to avoid overproduction, q/x increases and the relative marginal importance of a price change in the quota milk market increases.
2.2. Construction of Aggregate Input
In this section, the construction of weights required to compute an aggregate input is presented. Given that yield data imply a technical relation between an input and an output, an obvious candidate for generating aggregation weights is a production frontier. A production frontier represents the best available technique for transforming inputs into outputs. To obtain an econometric estimate of the production frontier, a mathematical relation between inputs and an output is specified in a translog form, which provides a second-order approximation to any unknown function (Christensen, Jorgenson, and Lau, Reference Christensen, Jorgenson and Lau1973):
 $$\begin{eqnarray}
\ln {Y_{it}} &=& {\alpha _0} + \sum_{j = 1}^n {{\alpha _j}} \ln {x_{jit}} + \rho t + \frac{1}{2}\sum_{j = 1}^n {\sum_{k = 1}^n {{\alpha _{jk}}\ln {x_{jit}}\ln {x_{kit}}} } \nonumber\\
&& +\, \sum_{j = 1}^n {{\alpha _{jt}}} t\ln {x_{jit}} + \frac{1}{2}{\rho _{tt}}{t^2} + {\varepsilon _{it}}.
\end{eqnarray}$$
$$\begin{eqnarray}
\ln {Y_{it}} &=& {\alpha _0} + \sum_{j = 1}^n {{\alpha _j}} \ln {x_{jit}} + \rho t + \frac{1}{2}\sum_{j = 1}^n {\sum_{k = 1}^n {{\alpha _{jk}}\ln {x_{jit}}\ln {x_{kit}}} } \nonumber\\
&& +\, \sum_{j = 1}^n {{\alpha _{jt}}} t\ln {x_{jit}} + \frac{1}{2}{\rho _{tt}}{t^2} + {\varepsilon _{it}}.
\end{eqnarray}$$
The xjit ’s are the j inputs used to produce milk, t is a time trend introduced to capture the effect of technical change, and ε it is a composite error term that contains a random noise component, vit , and a nonnegative time-varying technical inefficiency component, uit , or ε it = vit − uit . The farm- and time-specific technical efficiency scores (TEit ) for each farm are obtained by TEit = exp (− uit ). Following Battese and Coelli (Reference Battese and Coelli1992), the temporal pattern of technical inefficiency is specified as uit = exp { − η(t − T)} · ui , where η is a decay parameter and T is the terminal period in the data. When η > 0, technical efficiency increases over time, and it decreases when η < 0. Furthermore, the random noise term vit is symmetrical and assumed to be normally distributed—that is, vit ~ N(0, σ2 v ). In contrast, technical inefficiency is assumed to follow a truncated normal distribution; that is, ui ~ N +(μ, σ2 u ), which also nests the commonly used half-normal distribution or ui ~ N +(0, σ2 u ). Therefore, one can use nested hypothesis testing to choose the distributional assumption that fits the data best. In addition, the two error terms are assumed to be independently and identically distributed and orthogonal to one another as well as the independent variables of the model.
Given the parameters of the production frontier, the aggregate input is constructed as follows:
 $$\begin{equation}
{x_{it}} = \sum_{j = 1}^n {\left( {{{{\delta _{jit}}}
/ {{\delta _{it}}}}} \right)} \cdot {x_{jit}},
\end{equation}$$
$$\begin{equation}
{x_{it}} = \sum_{j = 1}^n {\left( {{{{\delta _{jit}}}
/ {{\delta _{it}}}}} \right)} \cdot {x_{jit}},
\end{equation}$$
where
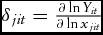 ${\delta _{jit}} = \frac{{\partial \ln {Y_{it}}}}{{\partial \ln {x_{jit}}}}$
and δ
it
= ∑
n
j = 1δ
jit
. When markets are competitive, inputs are paid their marginal product, and profits are maximum, the weights can be understood as follows (Kim, Reference Kim1992):
${\delta _{jit}} = \frac{{\partial \ln {Y_{it}}}}{{\partial \ln {x_{jit}}}}$
and δ
it
= ∑
n
j = 1δ
jit
. When markets are competitive, inputs are paid their marginal product, and profits are maximum, the weights can be understood as follows (Kim, Reference Kim1992):
 $$\begin{equation}
\frac{{{\delta _{jit}}}}{{{\delta _{it}}}} = \frac{{{{\partial \ln {Y_{it}}}
/ {\partial \ln {x_{jit}}}}}}{{\sum_{j = 1}^n {{{\partial \ln {Y_{it}}}
/ {\partial \ln {x_{jit}}}}} }} = \frac{{{w_{jt}}{x_{jit}}}}{{{C_{it}}}},
\end{equation}$$
$$\begin{equation}
\frac{{{\delta _{jit}}}}{{{\delta _{it}}}} = \frac{{{{\partial \ln {Y_{it}}}
/ {\partial \ln {x_{jit}}}}}}{{\sum_{j = 1}^n {{{\partial \ln {Y_{it}}}
/ {\partial \ln {x_{jit}}}}} }} = \frac{{{w_{jt}}{x_{jit}}}}{{{C_{it}}}},
\end{equation}$$
where w is the input price and C is the minimum cost of production. Therefore, the weights that are attached to each input can also be understood as the cost share of the input from total cost.
3. Empirical Strategy
Under the methodology specified, a milk yield density function has to be estimated. However, two problems arise for this estimation. First, ideally, farm-level yield densities should be estimated (Ker and Coble, Reference Ker and Coble2003). However, a common problem is that yield observations per farm are usually too few to support reliable estimation (Goodwin and Ker, Reference Goodwin, Ker, Just and Pope2002). Therefore, data pooling under certain assumptions, such as equal yield variance, or using yield data from some aggregate levels, such as counties, is commonly considered to ensure sufficient observations for yield density estimations (Borges and Thurman, Reference Borges and Thurman1994; Ker and Coble, Reference Ker and Coble2003). The number of observations per farm is also too few in the data used here, and thus data pooling in some form is unavoidable. We start by assuming that the yield density is identical for all farms in a given year, although it may vary across years, for example, because of technical change. However, technical efficiency can vary across farms in a given year as well as over time.Footnote
4
This can be addressed using farm- and time-specific technical efficiency scores that are obtained from equation (3). In particular, the observed output levels are corrected for technical inefficiency as
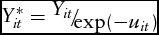 $Y_{it}^* = {\raise0.7ex\hbox{${{Y_{it}}}$} \!/ \!\lower0.7ex\hbox{${\exp ( { - {u_{it}}} )}$}}$
, where Y*
it
is the output level that will be observed if the farms are technically efficient or TE = exp (− uit
) = 1. Given the emphasis to learn about planned production, generating the yield data based on Y* rather than Y is logical because no rational farm will choose input levels aiming to be technically inefficient.
$Y_{it}^* = {\raise0.7ex\hbox{${{Y_{it}}}$} \!/ \!\lower0.7ex\hbox{${\exp ( { - {u_{it}}} )}$}}$
, where Y*
it
is the output level that will be observed if the farms are technically efficient or TE = exp (− uit
) = 1. Given the emphasis to learn about planned production, generating the yield data based on Y* rather than Y is logical because no rational farm will choose input levels aiming to be technically inefficient.
Under the assumption that technical change affects the expected yield only, while leaving higher moments unaffected, a simple approach is used to handle the effect of technical change. This approach involves three steps: First, the annual average yields are computed and subtracted from the yield data of the respective years. Second, the lowest annual average yield is added back to the demeaned yield data. Finally, the pooled data are used to estimate the yield density function of the year with the lowest annual average yield. Yield density functions of the other years are then recovered by scaling the yield density function of the year with the lowest annual average yield by the difference in average yields between the year under consideration and the least productive year. This approach is the same as the one used by Borges and Thurman (Reference Borges and Thurman1994) to control for assumed differences in technical efficiency between counties.
A second problem concerning estimating yield densities parametrically relates to the choice of functional form. The literature employs several functional forms to model crop yield densities (Goodwin and Ker, Reference Goodwin, Ker, Just and Pope2002; Ramirez, McDonald, and Carpio, Reference Ramirez, McDonald and Carpio2010). However, the estimation of yield densities for dairy production is not as common as it is for crop production. One alternative for minimizing a specification error is to use a flexible functional form, such as the Johnson distribution system (Johnson, Reference Johnson1949; Johnson, Kotz, and Balakrishnan, Reference Johnson, Kotz and Balakrishnan1994). The Johnson distribution system is a system of four distributions that can accommodate any finite and feasible combination of the first four moments. Consequently, it can approximate a wide range of distributions, including those that are commonly used for modeling crop yield data. Another alternative is to use nonparametric estimation (e.g., see Ker and Coble, Reference Ker and Coble2003; Ker and Goodwin, Reference Ker and Goodwin2000).
The distributions that form the Johnson family are identified by a set of normalizing transformations that were proposed by Johnson (Reference Johnson1949). In particular, given a continuous random variable with an unknown density function, Johnson (Reference Johnson1949) proposed a set of normalizing transformations with the general form:
 $$\begin{equation}
Z = \gamma + \delta \cdot g\left( u \right),
\end{equation}$$
$$\begin{equation}
Z = \gamma + \delta \cdot g\left( u \right),
\end{equation}$$
to obtain a unit normal distributed variable Z. The parameters γ and δ > 0 are shape parameters, whereas
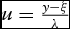 $u = \frac{{y - \xi }}{\lambda }$
, where ξ and λ > 0 are location and scale parameters, respectively. The parameter g(u) is a transformation function that assumes different forms to define the distributions in the Johnson family. These forms are the following (Johnson, Reference Johnson1949; Johnson, Kotz, and Balakrishnan, Reference Johnson, Kotz and Balakrishnan1994):
$u = \frac{{y - \xi }}{\lambda }$
, where ξ and λ > 0 are location and scale parameters, respectively. The parameter g(u) is a transformation function that assumes different forms to define the distributions in the Johnson family. These forms are the following (Johnson, Reference Johnson1949; Johnson, Kotz, and Balakrishnan, Reference Johnson, Kotz and Balakrishnan1994):
 $$\begin{equation}
g\left( u \right) = \left\{ {\begin{array}{l@{\qquad}l} {\ln \left( u \right),}&{{\rm{for\; the\; }}{S_L}\left( {{\rm{the\; log - normal}}} \right)\;{\rm{ family, }}\,}\\ {{\rm{ln}}\left[ {u + \sqrt {{u^2} + 1} } \right],}&{{\rm{for\; the\; }}{S_U}\left( {{\rm{unbounded}}} \right)\;{\rm{ family, }}\,}\\ {{\rm{ln}}\left[ {\frac{u}{{\left( {1 - u} \right)}}} \right],}&{{\rm{ for\; the\; }}{S_B}\left( {{\rm{bounded}}} \right)\;{\rm{family,\; and }}\,}\\ {u,}&{{\rm{for\; the\; }}{S_N}\left( {{\rm{normal}}} \right)\;{\rm{family}}{\rm{. }}} \end{array}} \right.
\end{equation}$$
$$\begin{equation}
g\left( u \right) = \left\{ {\begin{array}{l@{\qquad}l} {\ln \left( u \right),}&{{\rm{for\; the\; }}{S_L}\left( {{\rm{the\; log - normal}}} \right)\;{\rm{ family, }}\,}\\ {{\rm{ln}}\left[ {u + \sqrt {{u^2} + 1} } \right],}&{{\rm{for\; the\; }}{S_U}\left( {{\rm{unbounded}}} \right)\;{\rm{ family, }}\,}\\ {{\rm{ln}}\left[ {\frac{u}{{\left( {1 - u} \right)}}} \right],}&{{\rm{ for\; the\; }}{S_B}\left( {{\rm{bounded}}} \right)\;{\rm{family,\; and }}\,}\\ {u,}&{{\rm{for\; the\; }}{S_N}\left( {{\rm{normal}}} \right)\;{\rm{family}}{\rm{. }}} \end{array}} \right.
\end{equation}$$
As suggested by Hill, Hill, and Holder (Reference Hill, Hill and Holder1976), the estimated skewness and kurtosis coefficients of the data determine the particular distribution that fits the data best. However, such moment-matching estimators are criticized, for example, because of the sensitivity of the third and fourth moment estimates to outliers (Slifker and Shapiro, Reference Slifker and Shapiro1980). However, other estimators also exist, such as the quantile-based estimator that is suggested by Wheeler (Reference Wheeler1980) where the best distribution is selected based on five quantiles rather than the first four moments.
Given the previously discussed strategy, the milk yield density function is estimated twice: first based on the yield per aggregate input data and second based on the yield per cow data. The implication of allowing for multiple inputs is then evaluated by comparing the results from the two empirical yield density functions.
4. Data
The empirical analysis is based on production data from 324 Icelandic dairy farms that cover the period from 1998 to 2006.Footnote 5 Icelandic dairy farms are small family-owned enterprises with an average herd size of 31 cows in 2006. Iceland is among the countries identified with high support for agricultural producers (Organization for Economic Cooperation and Development, 2007). Consequently, the excess production problem that has followed farm support programs elsewhere also occurred in Iceland in the 1970s, and the need for production control measures had become more apparent by the end of the decade (Agnarsson, Reference Agnarsson2007).
Nontradable farm-level marketing quotas were then introduced in 1980. However, after the third milk agreement (1992–1997) between the Farmers Association of Iceland and the Ministry of Agriculture, the dairy quota has been freely tradable (Bjarnadottir and Kristofersson, Reference Bjarnadottir and Kristofersson2008). This change has resulted in the restructuring of the dairy sector toward fewer but larger dairy farms (Bjarnadottir and Kristofersson, Reference Bjarnadottir and Kristofersson2008). The quota entitles dairy producers to direct payments from the government and higher prices for all milk that is delivered inside the quota according to its composition and hygienic quality. Surplus milk can be sold in a surplus milk market at usually much lower prices that are determined by market forces. Additionally, the quota system requires that dairy farms fill their quota every 2 years or risk losing it. However, it is also possible to obtain permission not to use the quota for a certain time period (Agnarsson, Reference Agnarsson2007). See Atsbeha, Kristofersson, and Rickertsen (Reference Atsbeha, Kristofersson and Rickertsen2012) for more details of the Icelandic dairy sector.
Of the total sample, there are 63.1% instances of overproduction. However, surplus production by the average Icelandic farm is small, and it amounts to 3.8% of the average quota size. To get an idea of how systematic surplus production is, as opposed to optimization error, one can use the Norwegian case. Until 1997, Norway used a two-tier price system and subsequently replaced it with a levy system. Under the levy system, farmers pay penalties for surplus production. However, to allow for optimization errors, a farm can deliver milk up to 102% of its allocated quota before penalties apply. If the same allowance is used for Icelandic dairy farms, one can easily see that surplus production by choice may not be significantly high for the average Icelandic dairy farm. However, as shown in Table 1, there is significant variation across farms and over time. For the 83.4% of farms that exceeded their quota in some year, the average surplus production was 11.4% of the corresponding quota size during 1998–2006.
Table 1. Descriptive Statistics, 1998–2006

Note: 1 USD = ISK 111.2 on November 3, 2016 (http://www.sedlabanki.is).
The translog production function for milk was specified with six inputs and a trend variable. The inputs are concentrates, capital, veterinary services, land, number of cows, and labor. Concentrates, capital, and veterinary services are measured in monetary units that are deflated to 1998 prices using the consumer price index for agricultural products. Land is measured in hectares, and the number of cows is measured in cow-years, which is a weighted aggregate of the number of cows on a farm. The number of days in a year a cow has been active in milk production, or days in milk, is used for weighting. Labor use is measured as labor months per year. The descriptive statistics of these inputs are provided in Table 1.
The use of all inputs except for labor has increased over time. The largest increase is in capital and concentrates, which have increased by 15.6% and 6.5% per year, respectively. The number of cows increased by 1.7%, and quota size increased by 5.6% per year. These changes in input use are indicative of the significant structural adjustment that has occurred in the Icelandic dairy sector since 1992.
5. Results
All the variables were normalized through a division by their respective geometric means before estimation. The normalization allows the interpretation of first-order parameters as output elasticities at the geometric mean. The model is initially estimated by assuming an inefficiency term that is distributed as a truncated normal variable. However, the estimated value of the truncation point (i.e., μ) was not significantly different from zero at any conventional level of significance. Therefore, the model is reestimated under the assumption of a half-normally distributed technical inefficiency term. The resulting parameter estimates are provided in Table 2. All output elasticities are positive and significantly different from zero at the 5% level of significance. This result implies that the estimated production frontier is monotonic with respect to inputs at the geometric mean. However, monotonicity at the geometric mean does not guarantee that the output elasticities are positive at every data point. As shown by Berndt and Christensen (Reference Berndt and Christensen1973), the translog functional form does not satisfy monotonicity and curvature properties globally, nor can it be constrained to do so without losing its second-order flexibility (Sauer, Frohberg, and Hockman, Reference Sauer, Frohberg and Hockman2006). Accordingly, for all data points where monotonicity is violated, the output elasticities are replaced with zeros prior to the construction of the aggregation weights.Footnote 6
Table 2. Parameters of the Milk Production Function in Iceland, 1998–2006Footnote a

a Notes: Asterisks (***, **, and *) indicate significance at the 1%, 5%, and 10% levels, respectively. P values in parentheses.
b
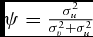 $\psi = \frac{{\sigma _u^2}}{{\sigma _v^2 + \sigma _u^2}}$
.
$\psi = \frac{{\sigma _u^2}}{{\sigma _v^2 + \sigma _u^2}}$
.
The parameter of the trend variable is positive and significantly different from zero at the 1% level. This result implies that there has been technical progress on Icelandic dairy farms. This outcome is expected because milk yield per cow increased by 32% between 1990 and 2007 (The Farmers Association of Iceland, 2009). Several changes in the Icelandic dairy sector can explain this increase (see Atsbeha, Kristofersson, and Rickertsen, Reference Atsbeha, Kristofersson and Rickertsen2012).
The average technical efficiency score for Icelandic dairy farms is 85.3%. This score suggests that the average farm can reduce its inputs by 14.7% to produce its output.Footnote 7 Furthermore, the decay parameter for technical inefficiency is negative, which suggests that technical efficiency declined during the study period. Atsbeha, Kristofersson, and Rickertsen (Reference Atsbeha, Kristofersson and Rickertsen2012) also found the same result for Icelandic dairy farms, and they provided some explanations for the decline relating to the managerial challenges of transition to large-scale production and the learning curve that is associated with the optimal employment of new technologies. Also see Alvarez and Arias (Reference Alvarez and Arias2003) for a similar finding about the link between managerial ability and size efficiency.
Next, an aggregate input is constructed based on farm- and time-specific weights, as in equation (4). The average aggregate input level is 481 units with a standard deviation of 222.4. The average yield per unit of the aggregate input is 386.3 liters with a standard deviation of 151.5. The average yield requirement per unit of aggregate input is 321.1 liters with a standard deviation of 130.1 liters. Concerning the yield per cow data, the average number of cows is 31.8 with a standard deviation of 12.6. The average yield per cow is 5,328 liters with a standard deviation of 1,073.2 liters. The average yield requirement per cow is 4,455.6 liters with a standard deviation of 1,162.1 liters. These figures imply a coefficient of variation of 39.2% and 20.1% for the yield data that are computed per aggregate input and per cow, respectively. The moderate variation in yield per cow is as expected, given that Icelandic dairy production is largely based on the Icelandic dairy cattle, a breed with relatively smaller population and hence limited genetic diversity with respect to milk yield. In contrast, a larger variation is observed in the yield per aggregate input, which implies that most of the variation in milk production arises from differences in the application of other inputs than cows and management practices.
To estimate the yield density functions, the SuppDists package (Wheeler, 2009) written for R is used. For both yield data sets, the Johnson SU is selected as the best-fit functional form. The parameters of the empirical yield density functions are γ = –0.88, δ = 1.47, ξ = 212.64, and λ = 137.9 for the yield per aggregate input data and γ = –0.04, δ = 1.27, ξ = 4619.12, and λ = 735.57 for the yield per cow data. Computed from these empirical yield density functions, Table 3 shows the probabilities that planned production each year may exceed the quota and the relative marginal importance of a price change in the quota milk market each year. As computed from the yield per aggregate input density function, the probability that the average Icelandic dairy farm will overproduce its quota is 0.65. This figure has shown a downward trend especially in the second half of the study period, with a peak at 0.69 in 2002 and its lowest point of 0.61 in 2005. Furthermore, the likelihood that overproduction is a mere consequence of an optimization error is low. This can be seen from the probabilities of overproducing the quota by different percentages. As shown in Table 3, the likelihood of overproducing the quota by 1% to 3% is consistently lower in all years than overproducing the quota by 3% or more.
Table 3. Overproduction Probabilities and Relative Marginal Importance of Price Changes in the Quota Milk Market of Iceland, 1998–2006

Next, the relative marginal importance of price changes in the quota milk market is computed as shown in equation (2a). The results that are reported in Table 3 show that the relative marginal importance of a price change in the quota milk market to milk supply response is 0.26 on average. This result implies that the supply response to a price change in the quota milk market is on average less than one-third of the response to an equivalent and simultaneous price change in both markets. Alternatively, a price change in the surplus milk market is approximately three times more effective in motivating milk supply response by Icelandic dairy farms than an equivalent price change in the quota milk market. As noted by a referee, the expected nature of yield shocks (i.e., whether shocks are presumed systemic or idiosyncratic) may be important for the strength of supply responses in the surplus milk market. For example, when yield shocks are presumed to be idiosyncratic, the expected consequent effect on total supply could be small. This effect, in turn, lowers expectations concerning prices in the surplus milk market and dampens the supply response to price changes in the surplus milk market. The reverse is true when yield shocks are expected to be systemic because of the significant negative effects of systemic yield shocks on total milk supply.
Finally, the previous computations were made based on the empirical yield density function that is estimated from the yield per cow data. As shown in Table 3, the average probability that an Icelandic dairy farm will exceed its quota is 0.81. As a result, the computed relative marginal importance of price changes in the quota milk market is lower by approximately 10 percentage points than the comparable estimate reported previously. The difference in these estimates is also tested for statistical significance using Wilcoxon's signed-rank test for paired data. The null hypothesis for the test is that the median of the difference between the estimates from the two approaches is zero. For the overproduction probabilities (Φ), the test statistic is z = –14.97 (p > | z | = 0.0001), and for the relative marginal supply response measures (Θ q ), the test statistic is z = 10.72 (p > | z | = 0.0001). In both cases, the difference in results between the two approaches is statistically significant at the 1% level.
As expected, these results show that the use of a single input to obtain yield data in a multiple input setting risks the possibility of inflated overproduction probabilities and therefore downplays the relative marginal importance of price changes in the quota output market. This result is likely the consequence of a yield density function estimated from yield data that portray a single input as more productive than farmers believe. In this case, the observed input choices by farmers will suggest the overapplication of the input and, therefore, lead to higher likelihoods of excess production.
6. Conclusions
Under marketing quota programs, dairy farms may plan to overproduce their quota if yield is uncertain. Such tendencies of excess production in quota-regulated systems because of yield uncertainty are usually explored for crop production. However, marketing quotas are also pervasive in the dairy sectors of the developed world. Furthermore, although to a lesser extent, livestock production is also subjected to yield uncertainty that arises from weather-related risks in feed production, diseases, death of animals, and reproductive performance. In addition, when quota programs are enforced through two-tier price systems, the relative importance of prices in the quota and surplus output markets as supply management tools is not obvious beforehand.
In this article, the likelihoods of excess production and the relative importance of price changes in a two-market setup were investigated for Icelandic dairy farms. Because of the country's geographic location, agriculture in Iceland takes place under difficult agroecological conditions that complicate husbandry practices and tend to exacerbate yield uncertainty. The effects of yield uncertainty and the relative importance of prices in a two-market setup were studied using a method proposed by Borges and Thurman (Reference Borges and Thurman1994). This method selects a single input and assumes the yield density is unaffected by the application of other inputs. Given the multiple input nature of agriculture and the implications of the simplifying assumption on the likelihoods of overproduction, the method was modified to consider multiple inputs. The modification was implemented by aggregating the inputs based on weights obtained from a parametric production frontier.
The results showed that the average probability of planned production exceeding quota was 0.65, which indicates that the average Icelandic dairy farm is likely to choose input levels planning to overproduce its quota. The likelihood of optimization error as the reason for overproduction was also low. An implication of these observations was that farmers attach more importance to the risk of quota shortfalls than to the risk of potentially low prices in the surplus milk market. This behavior was as expected given that surplus milk prices are increasingly becoming closely comparable with prices in the quota milk market. From a policy point of view, it is useful to note that the relative marginal importance of a price change in the surplus milk market was nearly three times as high as an equivalent price change in the quota milk market.
The likelihood of overproduction was also computed with an approach that considers a single input only (i.e., cows) under the assumption that the yield per cow density function is unaffected by the application of other inputs. The results showed that the probability of exceeding the quota increases by approximately 16 percentage points, and the relative marginal importance of price changes in the quota milk market decreases by approximately 10 percentage points. These differences were also statistically significant at the 1% level of significance. A plausible explanation for the difference was that the yield data per single input portray the specific input as more productive than it is perceived to be by farmers. The observed levels of the input will then appear as an overapplication, which in turn leads to an exaggeration of overproduction probabilities.
Appendix A
This appendix shows the implication of using a single input to compute yield in a multiple input setting on the estimation of overproduction probabilities. Assume a multiple input production and let yb
be the yield of an input x
1 computed without taking the contribution of all other inputs to total output into account, and let ya
be the yield of x
1 computed after taking the contribution of all other inputs to total output into account. Then, to the extent the marginal product of all other inputs is positive, yb
> ya
; that is, any single input used to compute yield is going to appear more productive than it actually is when multiple inputs are involved to generate total output. Note, however, that farmers are likely to acknowledge the contribution of all inputs as they make their input choices, and the observed quantities of input x
1 are more likely to be made expecting ya
per unit of x
1 rather than yb
. Therefore, at any planned level of output and keeping all other input choices constant, x
1|yb
< x
1|ya
. If this is the case, then the yield requirement to meet the quota exactly is bigger when farmers expectyb
than ya
or
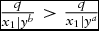 $\frac{q}{{{x_1}|{y^b}}} > \frac{q}{{{x_1}|{y^a}}}$
. Then, for any given yield distribution, Φ
a
= ∫∞
q/x|ya
f(y)dy > Φ
b
= ∫
q/x|yb
∞
f(y)dy; that is, the overproduction probability is larger when the yield density is evaluated under input choice made by farmers expecting ya
(as in Borges and Thurman [Reference Borges and Thurman1994] because they used observed acreage data to evaluate the empirical yield density) than farmers expecting yb
. An implication is that the relative importance of price changes in the quota market for supply response will decline because
$\frac{q}{{{x_1}|{y^b}}} > \frac{q}{{{x_1}|{y^a}}}$
. Then, for any given yield distribution, Φ
a
= ∫∞
q/x|ya
f(y)dy > Φ
b
= ∫
q/x|yb
∞
f(y)dy; that is, the overproduction probability is larger when the yield density is evaluated under input choice made by farmers expecting ya
(as in Borges and Thurman [Reference Borges and Thurman1994] because they used observed acreage data to evaluate the empirical yield density) than farmers expecting yb
. An implication is that the relative importance of price changes in the quota market for supply response will decline because
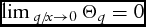 $\mathop {\lim \,}_{{q
/ {x \to 0}}} \Theta _q = 0$
. This effect is shown graphically in Figure A1.
$\mathop {\lim \,}_{{q
/ {x \to 0}}} \Theta _q = 0$
. This effect is shown graphically in Figure A1.

Figure A1. Probabilities of Excess Production under Two Ways of Computing Yield





 Open access
Open access