


Friedrich Hegel thought conflict and war were the major engines of progress (Black, Reference Black1973). McKinsey & Company's notion of a war for talent (Chambers, Foulon, Handfield-Jones, Hankin, & Michael, Reference Chambers, Foulon, Handfield-Jones, Hankin and Michael1998) has created considerable interest in the development, validation, and application of innovative tools for quantifying human potential (Chamorro-Premuzic, Reference Chamorro-Premuzic2013). Like other forms of warfare, the talent war has spurred an explosion of digital tools for identifying new talent signals, that is, nontraditional indicators of work-related potential. As a result, not only are talent identification practices rapidly becoming more high tech but also they are evolving faster than industrial–organizational (I-O) psychology research (Roth, Bobko, Van Iddekinge, & Thatcher, Reference Roth, Bobko, Van Iddekinge and Thatcher2016). This leaves academics playing catch up and human resources (HR) practitioners with many unanswered questions: How valid are these methods; are new technologies just a fad; can new tools disrupt traditional assessment methods; what are the ethical constrains to adopting these new tools? This article attempts to address some of these questions by reviewing recent innovations in the assessment and talent identification space. We review these innovative tools by highlighting their link to equivalent old school methods. For example, gamified assessments are the digital equivalent of situational judgment tests, digital interviews represent computerized versions of traditional selection interviews, and professional social networks, such as LinkedIn, are the modern equivalent of a resumé and recommendation letters. Thus, our article draws parallels between the old and the new worlds of talent identification and provides an organizing framework for making sense of the emerging tools we are seeing in this space.
If It Ain't Broke, Don't Fix It: The Old World of Talent Is Alive and Well
Although definitions of talent vary, four basic heuristics distinguish between more and less talented employees. The first is the 80/20 rule (Craft & Leake, Reference Craft and Leake2002) based on Vilfredo Pareto's (1848–1923) observation that a small number of people will generally create a disproportionate amount of the output of any group. Specifically, around 20% of employees will account for around 80% of productivity, while the remaining 80% of employees will account for only 20% of productivity. Who, then, are the talented individuals? They are the vital few who are responsible for most of the output. The second heuristic concerns the principle of maximum performance (Barnes & Morgeson, Reference Barnes and Morgeson2007), which equates talent to the best an individual can do; that is, people are as talented as their best possible performance. The third heuristic equates talent to effortless performance, emphasizing its relation to innate ability or potential. Because performance is usually conceptualized as a combination of ability (talent) and motivation (effort; Heider, Reference Heider1958; Porter & Lawler, Reference Porter and Lawler1968), talent can be defined as performance minus effort. Thus, if two individuals are equally motivated, the more talented person will perform better. That means if ordinary people want to perform as well as the talented, then their best bet is to work harder. The final heuristic equates talent to personality in the right place. That is, when individuals’ skills, dispositions, knowledge, and abilities are matched to a task or job, they should perform to a higher level. This definition is the core of the so-called person–environment fit theory of I-O psychology (Edwards, Reference Edwards2008). Thus, a major goal of any talent acquisition venture is to maximize fit between the employees’ qualities and the role and organization in which they are placed.
With these heuristics in mind, it is possible to classify individuals as more or less talented. The vital few who have displayed higher levels of performance or achieved without trying hard or having much training and who seem to have found a niche that fits their dispositions and abilities will generally be considered more talented. Consider the case of Lionel Messi, the Barcelona soccer star. Although Messi's teammates are usually considered the best soccer players in the world, he is consistently the best player on the team, and in some seasons he is individually responsible for over 60% of the critical goals and assists on his team. This makes Messi not just part of the vital few but perhaps the vital one on the team. Furthermore, as hundreds of YouTube compilations show, Messi's maximum performance is matched by none, and it is also effortless—he has been dribbling and scoring in the same way since his early teens and, unlike Cristiano Ronaldo, is not known for training particularly hard. However, while Messi's qualities are certainly in the right place at Barcelona—where he plays with his lifelong friends and shares the values of the club and supporters—he has struggled to show a similar form when playing for the Argentine national team. Thus even for an extraordinary talent like Messi, fit matters.
The next step in talent identification concerns two critical questions: what to assess and how (Ployhart, Reference Ployhart2006). The “what” question involves defining the key components of talent. This question is important because if you don't know what to measure, there is no point in measuring it well. In other words, you can do a great job measuring the wrong thing, but that will not get you very far. The “how” question concerns the methods that can be used to quantify individual differences in talent—in effect, these are the tools used by consultants, recruiters, and coaches to help organizations win the war for talent. We see test designers and publishers as arms merchants in the war for talent. We ourselves provide scientifically defensible “weapons” that help organizations win the talent war by better understanding and predicting work-related behaviors, particularly in leaders. There are, of course, many other key players in the war for talent: from CEOs, who represent the generals, to HR managers, who are the lieutenants, to coaches and consultants, who are the soldiers, hit men, or mercenaries, respectively. We all share a common goal, which is to help organizations attract, engage, and retain more talented individuals, who are the commodity being fought over.
To provide a more granular answer to the “what” question of talent identification, we can examine the qualities that talented individuals tend to display at work. As argued earlier in this journal, the generic attributes of talent can be described with the acronym RAW (R. T. Hogan, Chamorro-Premuzic, & Kaiser, Reference Hogan, Chamorro-Premuzic and Kaiser2013). First, talented people are more rewarding to deal with (R)—they are likable and pleasant. Interpersonal and intrapersonal competencies such as emotional intelligence (EQ), emotional stability, political skill, and extraversion capture this core element of talent, which enables individuals to get along at work (Van Rooy & Viswesvaran, Reference Van Rooy and Viswesvaran2004). In a world where the employees’ direct-line manager tends to determine career success, it is unsurprising that perceptions of talent will be largely driven by being pleasant and rewarding to deal with. Second, talented people are more able (A), meaning they learn faster and solve problems better. This is a function of experience, general intellectual ability (Schmidt & Hunter, Reference Schmidt and Hunter1998), and the domain-specific expertise that the Nobel laureate Herbert Simon described as a person's “network of possible wanderings” (Amabile, Reference Amabile1998). The more able employees are, the easier it is for them to make sense of work-related problems, translate information into knowledge, and quickly identify patterns in critical work tasks. Third, talented people are more willing to work hard (W), thereby displaying more initiative and drive. This theme, which concerns how employees get ahead, is reflected in meta-analytic studies highlighting the consistent positive effects of ambition, conscientiousness, and achievement motivation on job performance and career success (Almlund, Duckworth, Heckman, & Kautz, Reference Almlund, Duckworth, Heckman and Kautz2011). Although the labels vary, these universals of talent compose fairly stable individual differences that have been studied and validated extensively in I-O psychology, as well as social, educational, and differential psychology (Kuncel, Ones, & Sackett, Reference Kuncel, Ones and Sackett2010). A great deal of conceptual confusion about talent arises because organizations prefer their own labels, and they devote significant time devising “original” competency models—as the saying goes, “A camel is a horse designed by a committee.”
As for the “how” question, it is noteworthy that traditional methods for talent identification are alive and well. Indeed, 100 years of research in I-O psychology provide conclusive evidence for the validity of job interviews (Levashina, Hartwell, Morgeson, & Campion, Reference Levashina, Hartwell, Morgeson and Campion2014), assessment centers (Thornton & Gibbons, Reference Thornton and Gibbons2009), cognitive ability tests (Schmitt, Reference Schmitt2013), personality inventories (J. Hogan & Holland, Reference Hogan and Holland2003), biodata (Breaugh, Reference Breaugh2009), situational judgment tests (Christian, Edwards, & Bradley, Reference Christian, Edwards and Bradley2010), 360-degree feedback ratings (Borman, Reference Borman1997), resumés (Cole, Feild, & Stafford, Reference Cole, Feild and Stafford2005), letters of recommendations (Chamorro-Premuzic & Furnham, Reference Chamorro-Premuzic and Furnham2010), and supervisors’ ratings of performance (Viswesvaran, Schmidt, & Ones, Reference Viswesvaran, Schmidt and Ones2005). Unfortunately, HR practitioners are not always aware of this literature, or practitioners remain attached to their amateurish competency labels and meta-models, which explains why they often prefer to rely on their intuition to identify talent (Dries, Reference Dries2013) and also why the face and social validity of these methods are often unrelated to their psychometric validity (Chamorro-Premuzic, Reference Chamorro-Premuzic2013). Similarly, shiny new talent identification objects often bamboozle recruiters and talent acquisition professionals with no regard for predictive validity.
For example, employers and recruiters have used social media to evaluate job candidates for several years. Intuitive examinations of social media profiles are a popular, albeit clandestine, method for “discovering the applicant's true self.” Informal assessments of a candidate's online reputation, called “cybervetting” (Berkelaar, Reference Berkelaar2014), are often preferred to reviewing the more formal but overly polished resumé. Yet, most people spend a great deal of time curating their online personae, which are burnished by the same degree of impression management and social desirability as their resumés (Back et al., Reference Back, Stopfer, Vazire, Gaddis, Schmukle, Egloff and Gosling2010). Burnishing has even been taken as a right, seen in the ability of European Union citizens to limit access and hide links to images or posts that do not fit the reputation they want to portray online (Warman, Reference Warman2014). When social media users decide what images, achievements, musical preferences, and conversations to display online, the same self-presentational dynamics are at play as in any traditional social setting (Chamorro-Premuzic, Reference Chamorro-Premuzic2013. Consequently, people's online reputations are no more “real” than their analogue reputations; the same individual differences are manifested in virtual and physical environments, albeit in seemingly different ways. It is therefore naïve to expect online profiles to be more genuine than resumés, although they may offer a much wider set of behavioral samples. Indeed, recent studies suggest that when machine-learning algorithms are used to mine social media data, they tend to outperform human inferences of personality in accuracy because they can process a much bigger range of behavioral signals (Lambiotte & Kosinski, Reference Lambiotte and Kosinski2014, Youyou, Kosinski, & Stillwell, Reference Youyou, Kosinski and Stillwell2015). That said, social media is as deceptive as any other form of communication (B. Hogan, Reference Hogan2010); employers and recruiters are right to regard it as a rich source of information about candidates’ talent—if they can get past the noise and make accurate inferences.
For their part, candidates seem to expect that their digital lives will be examined for hiring purposes (El Ouirdi, Segers, El Ouirdi, & Pais, Reference El Ouirdi, Segers, El Ouirdi and Pais2015). Although studies suggest that candidates may find cybervetting unfair (Madera, Reference Madera2012), most candidates seem habituated to the idea that their social media activity will influence potential staffing or promotion decisions. Indeed, one study found that nearly 70% of respondents agreed that employers have the right to check their social networking profile when evaluating them (Vicknair, Elkersh, Yancey, & Budden, Reference Vicknair, Elkersh, Yancey and Budden2010). Job applicants may therefore face a “posting paradox” (Berkelaar & Buzzanell, Reference Berkelaar and Buzzanell2015), torn between sharing authentic personal information—and risking inappropriate self-disclosure—or creating a professional but deceptive online persona that appeals to potential employers. Yet humans always regulate their social behavior to conform to others’ expectations and social rules, even when the environment tolerates narcissistic indulgences in self-presentation, such as on Facebook. This is the fundamental skill that enables people to live in harmony and reflects individual differences in social competence (Kaiser, Hogan, & Craig, Reference Kaiser, Hogan and Craig2008).
The New Kids on the Blog: Talent in the Digital World
Most innovations in talent identification are the product of the digital revolution, enabled by the application of innovative tools designed to evaluate massive data sets. When the human need for connectedness met digital and mobile technologies, it generated a wealth of data about individuals’ preferences, values, and reputation. These traces of behavior, also known as the online footprint or digital breadcrumbs (Lambiotte & Kosinski, Reference Lambiotte and Kosinski2014), may be used to infer talent or job-related potential. For example, MIT researchers used phone metadata (e.g., call frequency, duration, location, etc.) to produce fairly accurate descriptions of users’ personalities (de Montjoye, Quiodbach, Robic, & Pentland, Reference de Montjoye, Quiodbach, Robic, Pentland, Greenberg, Kennedy and Bos2013). Similarly, Chorley, Whitaker, and Allen (Reference Chorley, Whitaker and Allen2015) successfully inferred some elements of the Big Five personality taxonomy by tracking user location behavior. Although data have turbo-charged analytics in fields as diverse as medicine, credit and risk, media, and marketing, HR generally lags behind. Despite all the talk about a big data revolution in HR and the rebranding of the field as “people analytics,” novel talent identification tools are still in their infancy, and user adoption is relatively low even in industrialized markets. One notable exception is the use of professional social networking sites, such as LinkedIn, for recruitment purposes. However, these sites are simply the modern equivalent of a resumé and phone directory, with the option of including personal endorsements (the modern version of a recommendation letter). Inferences based on these signals are mostly holistic and intuitive, and the focus is on hard skills rather than core talent qualities, for example, ambition, EQ, and intelligence (Zide, Elman, & Shahani-Denning, Reference Zide, Elman and Shahani-Denning2014). Nonetheless, demand for recruitment-related networking sites is growing at double or triple digit rates (Recruiting Daily, 2015), with hundreds of startups offering technologies to screen, interview, and profile candidates online (Davison, Maraist, Hamilton, & Bing, Reference Davison, Maraist, Hamilton and Bing2012).
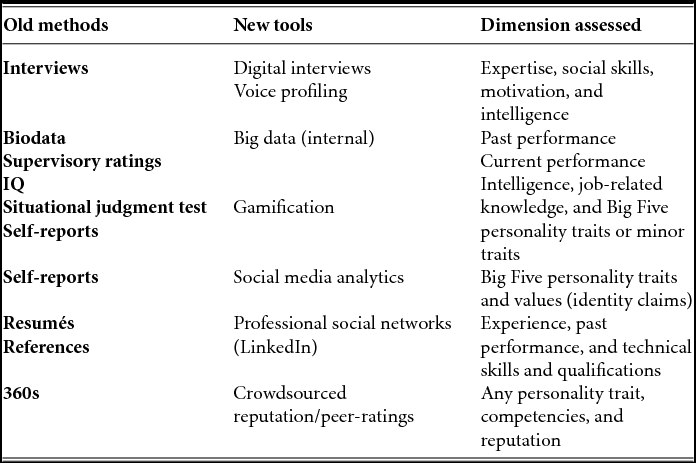
These new ventures are predominantly based on four methodologies that have the potential to disrupt and perhaps even advance the talent identification industry; they are (a) digital interviewing and voice profiling, (b) social media analytics and web scraping, (c) internal big data and talent analytics, and (d) gamification. As shown in Table 1, each of these methodologies corresponds to a well-established talent identification approach. We discuss the new methodologies below.
Table 1. A Comparison Between Old and New Talent Identification Methods
Digital Interviewing and Voice Profiling
Although preemployment job interviews are generally less valid than other assessment tools, they are ubiquitous (Roth & Huffcutt, Reference Roth and Huffcutt2013). Furthermore, job interviews are often the only method used to evaluate candidates, and when used in conjunction with other methods they are generally the final hurdle applicants need to pass. Technology can make interviews more efficient, standardized, and cost effective by enhancing both structure and validity (Levashina et al., Reference Levashina, Hartwell, Morgeson and Campion2014). Some companies have developed structured interviews that ask candidates to respond via webcam to prerecorded questions using video chat software similar to Skype (thus digital interviewing). This increases standardization and allows hiring panels and managers to watch the recordings at their convenience. Moreover, through the addition of innovations, such as text analytics (see below) and algorithmic reading of voice-generated emotions, a wider universe of talent signals can be sampled. In the case of voice mining, candidates’ speech patterns are compared with an “attractive” exemplar, derived from the voice patterns of high performing employees. Undesirable candidate voices are eliminated from the context, and those who fit move to the next round. More recent developments use similar video technology to administer scenario-based questions, image-based tests, and work-sample tests. Work samples are increasingly common, automated, and sophisticated. For example, Hirevue.com, a leading provider of digital interview technologies, employs coding challenges to screen software engineers for their software writing ability. Likewise, Uber uses similar tools to test and evaluate potential drivers exclusively via their smartphones (see www.uber.com).
Based on Ekman's research on emotions (Ekman, Reference Ekman1993), the security sector has developed microexpression detection and analysis technology to enhance the accuracy of interrogation techniques for identifying deception (Ryan, Cohn, & Lucey, Reference Ryan, Cohn and Lucey2009). The recent creation of large databases of microexpressions (Yan, Wang, Liu, Wu, & Fu, Reference Yan, Wang, Liu, Wu and Fu2014) is likely to facilitate the standardization and validation of these methods. Beyond using automated emotion reading, new research aims to correlate facial features and habitual expression with personality (Kosinski, Reference Kosinski2016). Although effect sizes tend to be small, this methodology can provide additional talent signals to produce more accurate and predictive profiles.
Social Media Analytics and Web Scraping
Humans are intrinsically social, and our need to connect is the driving force behind Facebook's dominance in social networking; it is estimated that nearly 25% of all the people in the world (and 50% of all Internet users) have active Facebook accounts. Unsurprisingly, Facebook has become a useful research tool—and ecosystem—to evaluate human behavior (Kosinski, Matz, & Gosling, Reference Kosinski, Matz and Gosling2015). Research finds that aspects of Facebook activity, such as users’ photos, messages, music lists, and “likes” (reported preferences for groups, people, brands, and other things), convey accurate information about individual differences in demographic, personality, attitudinal, and cognitive ability variables. Michal Kosinski and colleagues have shown that machine-learning algorithms can predict scores on well-established psychometric tests using Facebook “likes” as data input (Kosinski, Stillwell, & Graepel, Reference Kosinski, Stillwell and Graepel2013). This makes sense, because “likes” are the digital equivalent of identity claims: “Likes” tell others about our values, attitudes, interests, and preferences, all of which relate to personality and IQ. In some cases, associations between Facebook “likes” and psychometrically derived individual difference scores are intuitive. For example, people with higher IQ scores tend to “like” science, the Godfather movies, and Mozart. However, other associations are less intuitive and may not have been discovered without large-scale exploratory data mining. For example, one of the main markers—strongest signals—of high IQ scores was “liking” curly fries (a type of French fry, popular in the United States, characterized by a wrinkly, spring-like, shape). Somewhat ironically, media coverage of this finding led to an increase in “liking” curly fries, presumably without causing a global rise in IQ scores. However, unlike the static scoring keys used in traditional psychometric assessments, machine-learning algorithms can autocorrect in real time. Thus, when too many unintelligent individuals “like” curly fries, they cease to signal higher intelligence. This point is important for thinking about validity in the digital world: Some talent signals may not generalize from particular contexts or may change over time (like curly fries). Facebook is allegedly interested in using personality to understand user behavior and incorporates a wide range of personal signals, such as hometown, frequency of movement, friend count, and educational level to segment its audience for media and marketing purposes (Chapsky, Reference Chapsky2011). Perhaps the same information will soon be used for talent management purposes, especially in recruitment or prehiring decisions. Social media analytics has turned up several such counterintuitive associations, which big data enthusiasts and HR practitioners care little about because their main goal is to predict, rather than explain, behavior. I-O psychologists on the other hand—and psychologists in general—may fret about the atheoretical, black box, data-mining approach, which has created somewhat of a gap—and tension—between the science and the machine approach.
Some estimates suggest that 70% of adults are passive job seekers (i.e., not actively searching for new jobs, but open to new opportunities), and companies like TalentBin and Entelo identify potential job candidates outside the pool of existing job applicants (Bersin, Reference Bersin2013). Entelo claims that it can search (scrape) 200 million candidate profiles from 50 Internet sources and identify individuals likely to change jobs within the next 3 months (Entelo Outbound Recruiting Datasheet). If these claims are accurate, then it raises the possibility of placing workers in more relevant roles and lowering the proportion of disengaged employees, the economic value of which should not be underestimated.
Another unexpected talent signal concerns the language people use online. Psychologists from Freud and Rorschach onward have argued that people's language reveals core aspects of their personalities (Tausczik & Pennebaker, Reference Tausczik and Pennebaker2010). Linguistic analysis is a promising methodology for inferring talent from web activity, and it can be applied to free-form text (Schwartz et al., Reference Schwartz, Eichstaedt, Kern, Dziurzynski, Ramones, Agrawal and Ungar2013). This methodology has been around for 25 years, but modern scraping tools and publicly available text have made it applicable to large-scale profiling. Indeed, work with the Linguistic Inquiry and Word Count application (LIWC; Pennebaker, Reference Pennebaker1993) has shown that some LIWC categories correspond to the Big Five personality traits (Pennebaker, Reference Pennebaker2011). For example, for both men and women, higher word count and fewer large words predicted extraversion (Mehl, Gosling, & Pennebaker, Reference Mehl, Gosling and Pennebaker2006), which itself correlates with leader emergence (Grant, Gino, & Hofmann, Reference Grant, Gino and Hofmann2011). Other work (Schwartz et al., Reference Schwartz, Eichstaedt, Kern, Dziurzynski, Ramones, Agrawal and Ungar2013) shows that gender, religious identity, age, and personality can be identified from linguistic information.
Unlike other areas of assessment-related innovations, peer-reviewed studies provide evidence for the links between word usage and important individual differences. For example, the words that neurotics use in blogs include “awful,” “horrible,” and “depressing,” whereas extraverts talk about “bars,” “drinks,” and “Miami” (Schwartz et al., Reference Schwartz, Eichstaedt, Kern, Dziurzynski, Ramones, Agrawal and Ungar2013; Yarkoni, Reference Yarkoni2010). Less intelligent people mangle grammar and make more frequent spelling errors. There are free tools available to infer personality from open text (IBM's Watson does it for you here: http://bit.ly/1OjlkuR). These tools allow us to copy and paste anyone's writing into a web page and generate their personality profile. New applications analyze e-mail communications and provide users with tips on how to respond to senders, based on their inferred personality (http://bit.ly/1lkv5gB); others use speech-to-text tools and then parse the text through a personality engine (e.g., HireVue.com).
What is unknown is whether these types of talent signals are additive in terms of the predictive power. For example, do biodata and Facebook likes and voice profiling improve prediction of work-related outcomes? This is an area ripe for large-scale research.
Big Data and Workplace Analytics
In-house data are another source of information about talent. Because so much work is now digital—recorded or being logged and transmitted via the Internet of things—organizational performance data are both vast and fine-grained. Mining these data for critical signals of talent is consistent with the traditional I-O psychology view that past behavior is a good predictor of future behavior. For example, big data may be used to connect aggregate sales staff personality variables, LinkedIn use, engagement scores, and sales activity (including number of calls, frequency, length of time spent with customers, and net promoter scoring) to customer ordering data and future revenues. Once the data are recorded, models can be developed and tested backward in time to create predictions (as is the case when modeling share-market behavior).
Sandy Pentland and his MIT colleagues have used tracking badges to follow employees’ behaviors at work and record the frequency of talking, turn taking, and so on. This showed where people go for advice (or gossip) and how ideas and information spread within an organization. These data predicted team effectiveness (Woolley, Chabris, Pentland, Hashmi, & Malone, Reference Woolley, Chabris, Pentland, Hashmi and Malone2010) as well as identified the individuals who are a central node in the network (presumably because they are more useful to the organization or because they have more and stronger connections with colleagues).
One critical ingredient in talent identification is the criterion space: the empirical evidence of talent. In the I-O field, the well-known criterion problem (Austin & Villanova, Reference Austin and Villanova1992) remains problematic. Bartram noted that traditional validation research has been predictor centric (Bartram, Reference Bartram2005), and despite the development of competency frameworks (e.g., Lombardo & Eichinger, Reference Lombardo and Eichinger2002), criterion data remain noisy, dependent on supervisor ratings, and unsatisfactory. Although more data may not help conceptually, a finer understanding of performance is possible in principle, although this issue has not been addressed to date. Emergent tools and products suggest that this inevitably will happen.
For example, an important area in organizational big data is the case of peer evaluations or open source ratings. Glassdoor, a sort of Yelp of workplaces, is a good example. The site enables employees to rate their jobs and work experience, and the site has manager ratings for nearly 50,000 companies; anybody can retrieve the ratings. This enables employers to see how employees perceive the company culture and how individual managers have impacted workers and workplaces. With these data, organizations can effectively crowdsource their evaluations of leadership, looking at the link between employees’ ratings and company performance.
So long as organizations have robust criteria, their ability to identify novel signals will increase, even if those signals are unusual or counterintuitive. As an example of an unlikely talent signal, Evolv, an HR data analytics company, found that applicants who use Mozilla Firefox or Google Chrome as their web browsers are likely to stay in their jobs longer and perform better than those who use Internet Explorer or Safari (Pinsker, Reference Pinsker2015). Knowing which browser candidates used to submit their online applications may prove to be a weak but useful talent signal. Evolv hypothesizes that the correlations among browser usage, performance, and employment longevity reflect the initiative required to download a nonnative browser (Pinsker, Reference Pinsker2015).
Gamification
More Americans play games than do not, half of all gamers are under the age of 35 (Campbell, Reference Campbell2015), and parents mostly think video games are a positive influence on their children (Big Fish Blog, 2015; Lofgren, Reference Lofgren2016); therefore, it seems obvious to look for talent signals via this medium. For instance, HR Avatar conducts workplace simulations in the form of interactive cartoons aimed at customer service or security roles. Consider the personality assessments developed by Visual DNA, which present users with choices in the form of images and pictures, an intuitive and engaging experience with validity comparable with other questionnaire formats.
Gamification is now mobile. One company, Knack, claims to evaluate several different talents (“knacks”) from playing puzzle-solving games on mobile phones. What is interesting is that Knack has completely taken on the gamified persona, awarding players badges that they can share with friends. Another company, Pymetrics, gamifies some of the assessment principles of neuroscience to infer the personality and intelligence of candidates. Whether and to what degree it is useful to share this information with others is yet to be seen. But this approach represents a shift in the relationship among test providers, test takers, and firms: from a business-to-business model to a business-to-consumer model and from a reactive test taker to a proactive test taker. We predict that the testing market will increasingly transition from the current push model—where firms require people to complete a set of assessments in order to quantify their talent—to a pull model where firms will search various talent badges to identify the people they seek to hire. In that sense, the talent industry may follow the footsteps of the mobile dating industry. Consider the case of Tinder, a popular and addictive mobile dating app. First, users agree to have some elements of their social media footprint profiled when they sign up for the service. Next, their peers are able to judge these profiles and report whether they are interested in them or not by swiping left or right (a gamified version of hot or not). This is consistent with research showing that personality traits can be accurately inferred through photographs and that these inferences drive dating and relationship choices (Zhang, Kong, Zhong, & Kou, Reference Zhang, Kong, Zhong and Kou2014). Finally, if the algorithm determines a match, both parties receive instant feedback on their preferences. This model could easily be applied to the talent identification and staffing process. In fact, it is easier to predict job performance and career success than relationship compatibility and success.
The Enablers of New Tools
The World Wide Web has made it possible for workers to leave digital footprints all over the Internet, perhaps most prominently on social networking sites. However, without devices to examine these footprints, these novel talent signals would be of no use. Technological advances in three key areas have made the new tools of HR professionals possible: data scraping, data storage, and data analytics.
Data scraping involves gathering data that are available on websites, smartphones, and computer networks and translating these data into behavioral insights. Gathering data on potential workers is a first step toward understanding what they are like, and some of the most powerful devices for gathering and manipulating data are open source and free to use (e.g., Python, Perl), making them quite flexible and readily available. Because many data scraping devices require working with and/or developing application program interfaces (i.e., programming skills), HR professionals are enlisting computer programmers to develop customized devices for their data scraping needs.
The availability of large amounts of useful data has increased demand for data storage. As a result, devices for data storage and centralization have emerged; they include cloud-based storage systems (e.g., iCloud, Dropbox) and advanced Hadoop clusters, which allow for massive data storage and enormous computer processing power to run virtually any application.
Finally, advances in data analytics have created interesting new HR tools. For example, software for text analysis and object recognition can rapidly transform purely qualitative information into quantitative data. Such data can then be submitted to a variety of new analytic techniques such as machine learning. In contrast with traditional data analytic techniques, machine-learning techniques rely on sophisticated algorithms to (a) detect hidden structures in the data (i.e., unsupervised learning) or (b) develop predictive models of known criteria (i.e., supervised learning). Once again, some of the most powerful tools for conducting these analyses are open source and free (e.g., R: R Core Team, Reference Core Team2015), making them available to anyone.
The Future Is Here, but Be Careful
As William Gibson pointed out, the future is already here; it's just not yet evenly distributed. In a hyperconnected world where everyday behaviors are recorded, unprecedented volumes of data are available to evaluate human potential. I-O psychologists need to recognize the impact our digital lives will have on research methods, findings, and practices. We believe that these vast data pools and improved analytic capabilities will fundamentally disrupt the talent identification process. There are several key points to be derived from our review. First, many more talent signals will become available. Second, even if these emerging signals are weak or noisy, they may still work additively and be useful. Third, new analytic tools and computing power will continue to emerge and allow us to improve and refine the prediction of behavior in a wide range of contexts, probably based on the additive nature of these signals. Alternatively, if they do not prove to be additive, we anticipate that subsets of these signals will allow more specific prediction of performance. That is to say, computing power and the vast number of data points will allow for much greater alignment between the criterion and the predictor, which is a fundamental tenet of validity (J. Hogan & Holland, Reference Hogan and Holland2003).
The datification of talent is upon us, and the prospect of new technologies is exciting. The digital revolution is just beginning to appear in practice, and research lags our understanding of these technologies. We therefore suggest four caveats regarding this revolution.
First, the new tools have not yet demonstrated validity comparable with old school methods, they tend to disregard theory, and they pay little attention to the constructs being assessed. This issue is important but possibly irrelevant, because big data enthusiasts, assessment purveyors, and HR practitioners are piling into this space in any event. Roth and colleagues (Roth et al., Reference Roth, Bobko, Van Iddekinge and Thatcher2016) point out that construct validity is lacking when using information from social media for employment purposes, which does not seem to worry big data enthusiasts who are simply interested in finding relationships between variables. In our view, predicting behavior is clearly a key priority in talent identification, but understanding behavior is equally important. Indeed, scientifically defensible assessment tools do not just provide accurate data, they also tell a story about the candidate that explains why we may expect them to behave in certain ways. Until we have peer-reviewed evidence regarding the incremental validity of the new methods over and above the old, they will remain bright, shiny objects in the brave new world of HR. Though, as we have pointed out, shiny objects interest HR practitioners regardless of their demonstrated validity and reliability.
Three additional issues may constrain the implementation of new assessment tools in talent identification processes. First, privacy and anonymity concerns may limit access to individual data, a point that has been raised repeatedly in earlier scholarly articles (Brown & Vaughn, Reference Brown and Vaughn2011; Davison et al., Reference Davison, Maraist, Hamilton and Bing2012; Roth et al., Reference Roth, Bobko, Van Iddekinge and Thatcher2016). On the other hand, scholarly concern has not stopped recruiters, HR, or managers from using individuals’ digital profiles, nor has it slowed the development of tools designed specifically to do this. Individuals may provide consent for their data to be used without understanding the implications of doing so or may simply be unaware. Governments and privacy advocates may step in to regulate access or control usage, but it would be better if consumers fully understood what can be known about them and how that information might be used. Note, however, that in other fields of application, such as programmatic marketing, predictive analytics appear to operate without many ethical concerns, even though they offer relatively less to consumers; for example, the promise of a relevant ad is arguably less enticing (and likely) than the promise of a relevant job.
Second, in order to match or surpass the accuracy attained by established tools, the cost of building new tools may be prohibitive. For example, developing a valid and comprehensive gamified assessment of personality costs much more than developing a traditional self-report or situational judgment test. Thus there is a trade-off developers make between price, accuracy, and user experience (e.g., when you increase the user experience, you increase price but decrease accuracy; when you increase accuracy, you increase price; and if you want to maintain the same level of accuracy while improving the user experience, you increase price substantially).
Third, new tools are extremely likely to identify an individual's ethnicity, gender, or sexual orientation as well as talent signals. Certainly in the United States, and throughout much of the industrialized world, Equal Employment Opportunity Commission guidelines concerning adverse impact must be considered; even a fundamentally solid assessment tool should come under additional scrutiny if it is seen to contribute to adverse impact. This issue strengthens the case for more evidence-based reviews of any emerging tools, in particular those that scrape publicly available records of individuals (e.g., Facebook or other social media algorithms). Clearly, emerging tools enable employers to know more about potential candidates than they probably should, and ethical concerns—as well as the law—may represent the ultimate barrier to the application of new technologies.
In short, people are living their lives online. By doing so they make their behavior public, and that behavior leaves more or less perpetual traces—often inadvertently. The ability to penetrate the noise of all this information and identify robust talent signals is improving, but merging today's fragmented services with scientifically proven methods will be necessary to create the most accurate and in-depth profiles yet.
Last Thoughts
In the context of overall enthusiasm for these adventures in digital mining as applied to talent identification, we have two last thoughts. First, although it is clear that most of the innovations discussed in this article have yet to demonstrate compelling levels of validity, such as those that characterize academic I-O research, from a practical standpoint that may not be too relevant. As most I-O psychologists will know, there is a substantial gap between what science prescribes and what HR practitioners do, especially around assessment practices. In particular, the accuracy of talent identification tools is not the only factor considered by real-world HR practitioners when they make decisions about talent identification methods. Even when it is, most real-world HR practitioners are not competent enough to evaluate accuracy. This enables vendors to make bogus claims, such as “the accuracy of our tool is 95%.” In a world driven by accuracy, the Myers-Briggs would not be the most popular assessment tool. It seems to us that organizations and HR practitioners are more interested in price and user experience than accuracy.
Second, the history of science is much more one of adventitious and serendipitous findings than many people realize. Raw empiricism has often produced marvelously useful outcomes. So we are not at all worried about the fact that this explosion of talent identification procedures is uninformed by any concerns with well-established personality theory and what we know about the nature of human nature. As discussed, there are two fundamental questions underlying the assessment process: (a) what to assess and (b) how to assess it? Virtually all of the innovative thinking in the digital revolution in talent identification concerns the second question. Having scraped and collated the various online cues, the next question concerns how to interpret the data. As Wittgenstein (an Austrian proto-psychologist) once observed, “In psychology there are empirical methods and conceptual confusions.” The most thoughtful of the data scrapers have provided evidence that their data can be used to predict aspects of the five-factor model, an idea at least 65 years old. Going forward, it would be nice to see as much effort put into reconceptualizing personality as is being put into assessment methods. In the end, true advancements will come if we can balance out data and theory, for only theory can translate information into knowledge. As Immanuel Kant famously noted, “Theory without data is groundless, but data without theory is just uninterpretable.”

