



Policy Significance Statement
This work provides a comprehensive analysis of the legal issues concerning generative deep learning, including the storage of protected works, for training neural networks, the potential plagiarism risks associated with both the models and the outputs, and the problem of ownership of generated artifacts. Moreover, this work provides researchers with a list of practical and actionable suggestions for ensuring compliance in their daily work. At the same time, it offers an in-depth analysis of several critical points in copyright laws to policymakers. These issues will be central to the debate around these themes in the coming years.
1. Introduction
In recent years, we have witnessed an exponential growth of interest in the field of generative deep learning (GDL; Brown et al., Reference Brown, Mann, Ryder, Subbiah, Kaplan, Dhariwal, Neelakantan, Shyam, Sastry, Askell, Agarwal, Herbert-Voss, Krueger, Henighan, Child, Ramesh, Ziegler, Wu, Winter, Hesse, Chen, Sigler, Litwin, Gray, Chess, Clark, Berner, McCandlish, Radford, Sutskever and Amodei2020; Devlin et al., Reference Devlin, Chang, Lee and Toutanova2019; Goodfellow et al., Reference Goodfellow, Pouget-Abadie, Mirza, Xu, Warde-Farley, Ozair, Courville and Bengio2014; Isola et al., Reference Isola, Zhu, Zhou and Efros2017; Karras et al., Reference Karras, Laine and Aila2019; Ramesh et al., Reference Ramesh, Pavlov, Goh, Gray, Voss, Radford, Chen and Sutskever2021; Van Den Oord et al., Reference Van Den Oord, Dieleman, Zen, Simonyan, Vinyals, Graves, Kalchbrenner, Senior and Kavukcuoglu2016a; Yu et al., Reference Yu, Zhang, Wang and Yu2017, among others).
GDL is a subfield of deep learning (Goodfellow et al., Reference Goodfellow, Bengio and Courville2016) with a focus on generation of new data. Following the definition provided by Foster (Reference Foster2019), a generative model describes how a dataset is generated (in terms of a probabilistic model); by sampling from this model, we are able to generate new data. Nowadays, machine-generated artworks have entered the market (Vernier et al., Reference Vernier, Caselles-Dupré and Fautrel2020), they are fully accessible online,Footnote 1 and they have the focus of major investments.Footnote 2
Privacy problems in generating faces or personal data are in the spotlight since few years (a technical survey for privacy in visual monitoring systems can be found in Padilla-López et al. (Reference Padilla-López, Chaaraoui and Flórez-Revuelta2015); the use of differential privacy (Dwork and Roth, Reference Dwork and Roth2014) has opened a new field of research (Liu et al., Reference Liu, Peng, Yu and Wu2019; Wu et al., Reference Wu, Zhao, Chen, Xu, Wang, Zhang, Sun and Zhou2019; Xu et al., Reference Xu, Ren, Zhang, Zhang, Qin and Ren2019; etc.), but also privacy in clinical data sharing is considered (see, e.g., Beaulieu-Jones et al., Reference Beaulieu-Jones, Wu, Williams, Lee, Bhavnani, Byrd and Greene2019). Ethical debates have, fortunately, found a place in the conversation (for an interesting summary of machine learning researches related to fairness, see Chouldechova and Roth (Reference Chouldechova and Roth2020)) because of biases and discrimination they may cause (as happened with AI Portrait Ars [O’Leary, Reference O’Leary2019], leading to some very remarkable attempts to overcome them, as in Xu et al. (Reference Xu, Yuan, Zhang and Wu2018) or Yu et al. (Reference Yu, Li, Zhou, Malik, Davis and Fritz2020)).
However, copyright issues—the focus of this article—also arise from the use of deep learning to generate artworks. GDL techniques are trained on a large amount of data, which may be protected by copyright (especially in case of artworks); moreover, they allow for the generation of new samples similar to the training data, which in turn could claim copyright protection (or could represent plagiarism of other works). In this context, it is possible to identify at least three problems: the use of protected works, which have to be stored in memory until the end of the training process (even if not for more time, in order to verify and reproduce the experiment); the use of protected works as training set, processed by deep learning techniques through the extraction of information and the creation of a model upon them; and the ownership of intellectual property (IP) rights (if a rightholder would exist) over the generated works. Although these arguments have already been extensively studied (e.g., Sobel (Reference Sobel2017) examines use as training set and Deltorn and Macrez (Reference Deltorn and Macrez2018) discuss authorship), this paper aims at analyzing all the problems jointly, creating a general overview useful for both the sides of the argument (developers and policymakers); aims at focusing only on GDL, which (as we will see) has its own peculiarities, and not on artificial intelligence (AI) in general (which contains too many different subfields that cannot be generalized as a whole); and is written by GDL researchers, which may help provide a new and practical perspective to the topic. For doing so, we first provide the reader with a brief review of what GDL means (Section 2). We then present an in-depth discussion of the existing legal frameworks in both the United States and the European Union in relation to storing protected works for using them as training set (Section 3) and, then, owning the copyright of machine-generated works (Section 4). In addition to legal analysis, we present a policy discussion that leads to practical suggestions for artists and developers working in this new field, as well as to considerations about the adequacy of current laws. Finally, even if the main case study will be about artworks, which are by a long margin the main (potentially copyrighted) outputs generated with deep learning, in the last section, we discuss the issues around GDL in relation to source code generation (Section 5).
2. Generative Deep Learning
As with other machine learning algorithms, GDL is based on the availability of a training set, which is a set containing examples of the entities that will be our starting point for the generation of new data. The machine learning model itself has to be probabilistic in order to generate new data (if it is deterministic, it will generate each time the same entity). A generative model is intrinsically different from a discriminative one, which represents the most popular (and classic) technique in machine learning. In discriminative modeling, for example, classification or logistic regression, we aim at distinguishing among classes after training on labeled data (it is, in a way, a synonymous of supervised learning). Instead, in generative modeling, we use the (unlabeled) dataset to learn to generate new data.
In general, Foster (Reference Foster2019) defines the generative modeling framework as follows: given a dataset of observations
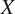 $ X $
, and assuming that
$ X $
, and assuming that
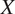 $ X $
has been generated according to an unknown distribution
$ X $
has been generated according to an unknown distribution
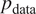 $ {p}_{\mathrm{data}} $
, a generative model
$ {p}_{\mathrm{data}} $
, a generative model
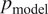 $ {p}_{\mathrm{model}} $
is used to mimic
$ {p}_{\mathrm{model}} $
is used to mimic
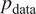 $ {p}_{\mathrm{data}} $
in such a way that we can sample from
$ {p}_{\mathrm{data}} $
in such a way that we can sample from
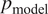 $ {p}_{\mathrm{model}} $
to generate observations that appear to have been drawn from
$ {p}_{\mathrm{model}} $
to generate observations that appear to have been drawn from
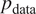 $ {p}_{\mathrm{data}} $
(and that are suitably different from the observations in
$ {p}_{\mathrm{data}} $
(and that are suitably different from the observations in
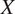 $ X $
).
$ X $
).
GDL is based on the concept of representation learning. The algorithms are used to learn representations of the data that make it easier to extract patterns from them. Differently from classic machine learning techniques, representation learning works directly on unstructured data, not requiring to manually define the features of the input data (necessary to work with structured data). This adds an extra level of autonomy to the algorithm. Deep learning in itself is based on the composition of multiple nonlinear transformations (using multiple stacked layers of processing units) with the goal of yielding more abstract, and ultimately more useful, representations (Bengio et al., Reference Bengio, Courville and Vincent2013).
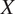 $ X $
is typically composed by unstructured data like images or texts.
$ X $
is typically composed by unstructured data like images or texts.
Several generative models based on deep learning have been proposed in last years (for a more exhaustive list, see Franceschelli and Musolesi (Reference Franceschelli and Musolesi2021b)). However, it is possible to identify a few families of techniques: Variational Auto-Encoders (VAE; first proposed by Kingma and Welling (Reference Kingma and Welling2014), but also used by Gregor et al. (Reference Gregor, Danihelka, Graves, Rezende and Wierstra2015)); autoregressive models (first proposed by Van Den Oord et al. (Reference Van Den Oord, Kalchbrenner and Kavukcuoglu2016b), but also used by Brown et al. (Reference Brown, Mann, Ryder, Subbiah, Kaplan, Dhariwal, Neelakantan, Shyam, Sastry, Askell, Agarwal, Herbert-Voss, Krueger, Henighan, Child, Ramesh, Ziegler, Wu, Winter, Hesse, Chen, Sigler, Litwin, Gray, Chess, Clark, Berner, McCandlish, Radford, Sutskever and Amodei2020); Devlin et al. (Reference Devlin, Chang, Lee and Toutanova2019); Huang et al. (Reference Huang, Vaswani, Uszkoreit, Simon, Hawthorne, Shazeer, Dai, Hoffman, Dinculescu and Eck2019); Parmar et al. (Reference Parmar, Vaswani, Uszkoreit, Kaiser, Shazeer, Ku and Tran2018); Payne (Reference Payne2019); Radford et al. (Reference Radford, Wu, Child, Luan, Amodei and Sutskever2019); Van Den Oord et al. (Reference Van Den Oord, Dieleman, Zen, Simonyan, Vinyals, Graves, Kalchbrenner, Senior and Kavukcuoglu2016a, Reference Van Den Oord, Kalchbrenner, Vinyals, Espeholt, Graves and Kavukcuoglu2016c)); sequence prediction models (very well explained by Karpathy (Reference Karpathy2015), and then used by Jaques et al. (Reference Jaques, Gu, Turner and Eck2016); Lau et al. (Reference Lau, Cohn, Baldwin, Brooke and Hammond2018); Potash et al. (Reference Potash, Romanov and Rumshisky2015); Sturm et al. (Reference Sturm, Santos, Ben-Tal and Korshunova2016); Yi et al. (Reference Yi, Sun, Li and Li2018); Zhang and Lapata (Reference Zhang and Lapata2014); Zugarini et al. (Reference Zugarini, Melacci and Maggini2019)); and Generative Adversarial Nets (GAN; first proposed by Goodfellow et al. (Reference Goodfellow, Pouget-Abadie, Mirza, Xu, Warde-Farley, Ozair, Courville and Bengio2014) and then used by Vernier et al. (Reference Vernier, Caselles-Dupré and Fautrel2020); modifications of the first proposal have been done by Brock et al. (Reference Brock, Donahue and Simonyan2019); Dong et al. (Reference Dong, Hsiao, Yang and Yang2018); Elgammal et al. (Reference Elgammal, Liu, Elhoseiny and Mazzone2017); Engel et al. (Reference Engel, Agrawal, Chen, Gulrajani, Donahue and Roberts2019); Isola et al. (Reference Isola, Zhu, Zhou and Efros2017); Karras et al. (Reference Karras, Aila, Laine and Lehtinen2018, Reference Karras, Laine and Aila2019); Yu et al. (Reference Yu, Zhang, Wang and Yu2017); Zhang et al. (Reference Zhang, Goodfellow, Metaxas and Odena2019)).
We refer the interested reader to the original papers for a detailed description of the technical aspects of GDL given the scope of this article. The first three techniques have in common the fact that the generator is trained directly on the dataset
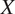 $ X $
of examples (with a very small but not important exception for VAE, since the real generator processes only an encoded version of the original work, and not its real version). On the other hand, the generator of a GAN never sees the real examples: it is trained with the so-called adversarial training. A GAN is composed by two networks: a discriminator and a generator (that is, the generative model). The generator never sees real data, while the discriminator is trained on them, with the goal of learning to distinguish between original data and generated ones; at the same time, the generator tries to generate data that fool the discriminator (so, the goal is to generate data that are recognized as real). The learning process proceeds with the two phases alternatively: when the discriminator becomes better in recognizing original data, the generator has to learn more things about their distribution to fool again the discriminator; and when the generator becomes better in generating seemingly real data, the discriminator has to become better in distinguishing them. At the end, the generator should have learned the model correctly, without training on it (Goodfellow et al., Reference Goodfellow, Pouget-Abadie, Mirza, Xu, Warde-Farley, Ozair, Courville and Bengio2014). In any case, data are always necessary as in any other machine learning algorithm. We will discuss the implications of this aspect later in this article.
$ X $
of examples (with a very small but not important exception for VAE, since the real generator processes only an encoded version of the original work, and not its real version). On the other hand, the generator of a GAN never sees the real examples: it is trained with the so-called adversarial training. A GAN is composed by two networks: a discriminator and a generator (that is, the generative model). The generator never sees real data, while the discriminator is trained on them, with the goal of learning to distinguish between original data and generated ones; at the same time, the generator tries to generate data that fool the discriminator (so, the goal is to generate data that are recognized as real). The learning process proceeds with the two phases alternatively: when the discriminator becomes better in recognizing original data, the generator has to learn more things about their distribution to fool again the discriminator; and when the generator becomes better in generating seemingly real data, the discriminator has to become better in distinguishing them. At the end, the generator should have learned the model correctly, without training on it (Goodfellow et al., Reference Goodfellow, Pouget-Abadie, Mirza, Xu, Warde-Farley, Ozair, Courville and Bengio2014). In any case, data are always necessary as in any other machine learning algorithm. We will discuss the implications of this aspect later in this article.
Another very interesting GDL architecture is Google’s DeepDream (Mordvintsev et al., Reference Mordvintsev, Olah and Tyka2015). The designers of DeepDream trained a convolutional neural network for image classification, and then they used the network as a generative model working in reverse: the image is not obtained as an output, but through modifications of an image provided in input, where the modifications are done according to the patterns learned by the network. In particular, the input image is modified in such a way that the “excitement” of a selected layer is maximized; this entails the emergence of the patterns that the specific layer has learned to recognize, which might just be simple ornament-like patterns, but also more sophisticated features.
As it is apparent from the overview given above, GDL has very specific characteristics, which have direct implications for copyright. First of all, GDL techniques are trained on large training sets from which information is extracted. These training sets may contain data, which are protected by copyright, especially if they are artworks. In fact, differently from other learning techniques, they directly learn from the whole work as it is. It means researchers need to store potentially protected works in their expressive form, which is what is protected by copyright, and not by means of features or small chunks if not of their underlined ideas. Second, because of the nature of the generated outputs (especially against the nature of outputs generated by other kinds of AI (Colton, Reference Colton2008), which simply follow rules explicitly provided by the programmer). They only depend on the technique used and the knowledge acquired, without any kind of human intervention (except for the coding of the program and the choice of input data), making very difficult to determine who shall be considered as the owner of the copyright.
3. Storage of Protected Works and Use for Training
Our analysis starts considering if the storage, reproduction, and therefore the use for training of a protected work by a GDL algorithm violate the copyright, or if it is allowed by US and EU laws.
Sobel (Reference Sobel2020) identifies four different categories of uses of data performed by machine learning:
-
1. uses involving training data not protected by copyright, including works fallen into the public domain (not protected by economic rights anymore);
-
2. uses involving copyrighted subject matter released under a permissive license or licensed directly from rightholders;
-
3. market-encroaching uses (whose purpose threatens the market of those data); and
-
4. nonmarket-encroaching uses (whose purpose is unrelated to copyright’s monopoly entitlement).
In the first case, there is no problem in storing and using a work not protected by copyright for this goal. This also applies for works now in the public domain, which happens in the European Union 70 years after the author’s death (or the death of the last of the authors), and in the United States 95 years after publication date (if created and published before 1978; otherwise, 70 years after the author’s death). The same is also true if the work is protected, but it has been acquired digitally through a license agreement that does not expressly prevent a reproduction with this goal (the second case). Otherwise, for protected works on which we have a lawful access but not in digital form or not for a reproduction (third and fourth cases), the question remains open. To address it, the next two subsections consider it under the US law (3.1) and under the EU law (3.2).Footnote 3 Finally, the last subsection considers additional issues related on the outputs of generative models, and not on their inputs (3.3).
3.1. US law
The US Code establishes that the reproduction of a copyrighted work can be allowed if the use can be considered a fair use of the work (17 U.S.C. §107—Limitations of exclusive rights: Fair use). This provision sets the criteria used to determine if the use is fair, that is, the purpose of the use and its economic character, the nature of the work, the amount and substantiality of the portion used, and the impact of the use over its potential market. With these criteria, the law does not state unambiguously what is a fair use and what is not; it provides parameters on which Courts can base their decisions about the fairness of a use. This unpredictability has been criticized, not only because it requires a case-by-case analysis (Netanel, Reference Netanel2008)—and eventually to hire a lawyer (Lessig, Reference Lessig2004)—due to its nature of standard more than of rule (Carroll, Reference Carroll2007), but also because the four factors may fail to drive the analysis and may be instead used to support an independent and antecedent conclusion (Nimmer, Reference Nimmer2003). However, the fair use doctrine has also some remarkable strengths. It ensures that two competing public interests are balanced: to incentive the creation of new works, and to improve the public’s ability to use or access it (see Sony Corp. v. Universal City Studios, Inc., 464 U.S. 417). In its form, this doctrine helps exclude uses only where exclusivity promotes social welfare (Lunney, Reference Lunney2002). In addition, even if it seems unpredictable, fair use cases tend to be more coherent than expected and could be organized into clusters, which can help in Courts’ decisions (see Samuelson, Reference Samuelson2009).
Anyway, a deeper analysis of these four criteria in the special case of (generative) deep learning is now necessary. As regards the amount and substantiality criterion, although in GDL we aim at using the entire work (maybe divided into portions, if it is too long like a novel or a song), we have to consider that machine learning refers to the use of ideas, principles, facts, and correlations contained in data given in input; since copyright aims to protect original expressions and not ideas, procedures, or methods, data mining techniques do not use copyright works as works per se but to access the information stored in them, and so the use is not substantial—and neither they constitute a copyright infringement in theory (Kretschmer and Margoni, Reference Kretschmer and Margoni2018). Furthermore, Sag (Reference Sag2019) underlines that a nonexpressive use such as the one discussed above should be considered fair, since it is just about deriving from them meta-level information and not benefiting from their original expression; however, generative techniques could fall under the definition of expressive use, since they could use authors’ copyrighted expressions (Sobel, Reference Sobel2017), learning from their creative and expressive choices (Bonadio and McDonagh, Reference Bonadio and McDonagh2020). This would invalidate the insubstantiality theory. In addition, we need to consider that the single protected work is used alongside a large number of other protected works: it is rare that the result resembles one of them substantially, presenting its distinctive features. For this reason, the impact of its potential market is typically very small, because it becomes difficult to connect the generated work with the protected ones used during training (this is true in particular in the case of heterogeneous training sets; of course, if the training set is composed by few works from a single author, this consideration is not more valid). The economic character has to be seen considering that this exception is fair only for purposes like research, and so without a real economic character; however, the previously done distinction between market-encroaching uses and nonmarket-encroaching uses acquires significance in dividing between an (almost) sure fair use and a dubious case. Finally, when analyzing the purpose of the use (and its fairness), one needs to consider if it is transformative, the most common reason to assess fair use (Asay et al., Reference Asay, Sloan and Sobczak2020): if it adds something new, with a different character, which does not substitute for the original use of the work, the use is more likely to be considered fair.Footnote 4 In particular, the key question to determine a fair use is nowadays if the work is used for a different expressive purpose from that for which the work was created (Netanel, Reference Netanel2011). It is not straightforward to assess this for GDL, but this could eventually be the case of GDL techniques which aim to add a novelty degree in their production (as in Elgammal et al., Reference Elgammal, Liu, Elhoseiny and Mazzone2017). Finally, it is important to highlight that, if the use does not fall in the category of fair use, any sort of reproduction of copyrighted works is not permitted,Footnote 5 usually even if it is only on volatile RAM (as judged by many courts, as reported in U.S. Copyright Office, DMCA Section 104 Report 118; however, the Report suggests that in some cases the reproduction of copies on volatile RAM may be considered as a fair use).
As seen, even if without a clear and unambiguous answer, the fair use doctrine certainly offers a support for machine learning researchers (maybe even too much, in comparison with what is allowed to humans [Grimmelmann, Reference Grimmelmann2016a]). For instance, in the field of text and data mining (TDM), as pointed out by Sag (Reference Sag2019) and confirmed by two famous cases (see Authors Guild, Inc. v. Google, Inc. and Authors Guild, Inc. v. HathiTrust), the transformative nature of the involved process makes it possible to claim fair use. However, it is not straightforward to extend it to GDL, since the use tends to be more expressive than nonexpressive (which makes it more difficult to be considered as fair [Sobel, Reference Sobel2017]). We can only wait until more clarifications (and Courts’ decisions) arrive to unravel it.
3.2. EU law
In the European Union, instead, there are two articles from Directive 2001/29/EC that can or cannot permit the reproduction of protected works. In particular, Article 2 states there shall be for authors the exclusive right to authorize or prohibit direct or indirect, temporary or permanent reproduction of their work by any means and in any form, in whole or in part; while Article 5(1) provides an exception to this (exclusive) reproduction right (an exception represents a situation in which a right is not reserved—as it usually is). In fact, it states there shall be an exception from the reproduction right in Article 2 for temporary acts of reproduction which are transient or incidental and an integral and essential part of a technological process, and whose sole purpose is to enable a lawful use of a work which has no independent economic significance (therefore excluding market-encroaching uses). This exception is quite similar to the one provided by the US Code, since it requires no independent economic significance (the third case by Sobel (Reference Sobel2020) is probably excluded; reproductions have an independent economic significance if their use generates an additional economic advantage (Triaille et al., Reference Triaille, d’Argenteuil and de Francquen2014), and it seems indeed the case: a neural network, deprived by some of the training data, would probably perform worse) and that the use is lawful (a use is lawful if it is authorized by the rightholder or not restricted by law; we will analyze soon if the use done by GDL is lawful or not), but it adds another constraint: the reproduction must be transient or incidental. Following Riedo (Reference Riedo2019), this exception could theoretically be applied to TDM activities (as long as TDM is a lawful use), since during the process data are stored in RAM and then erased when turned off, and so the reproduction is transient. For Schonberger (Reference Schonberger2018), Article 5(1) arguably covers copying the works for the training process, deleting them at the end of the process. Despite this, it is very likely that the miners, especially if they are researchers, have to retain the data corpus for verification, aggregation with new datasets and further analysis (Chiou, Reference Chiou2019), deleting it only once their work is completed and published; and therefore storing them until the end of the research is very unlikely to be considered under the exception for temporary reproduction.
To sum up, it is difficult to say that TDM activities are allowed under this exception—or at least there is a degree of uncertainty (Geiger et al., Reference Geiger, Frosio and Bulayenko2018b; Rosati, Reference Rosati2018). In addition, Article 5(1) requires the use to have no independent economic significance, therefore excluding for-profit research and private companies. This surely would put the European Union’s competitive position as both a research and an industrial area in danger (Geiger et al., Reference Geiger, Bulayenko, Hassler, Izyumenko, Schonherr and Seuba2015), and this is one of the main reasons behind the adoption, in 2019, of a Directive “on copyright and related rights in the Digital Single Market.”
This fundamental Directive tries to answer to all the questions examined above by the means of two Articles.
Directive’s Article 3 states there shall be an exception to allow reproductions and extractions of lawfully accessible protected works for performing TDM, if it is made by research organizations and cultural heritage institutions (for the purposes of scientific research and as long as the copies are stored with an appropriate level of security). Notably, the Article states the copies may be retained for the time required for the purposes of scientific research, including for the verification of research results. However, we have to remember that the Article only asks for an exception to the reproduction right (i.e., the exclusive right to make direct or indirect, temporary or permanent reproduction of the work by any means and in any form) and the extraction right (i.e., the exclusive right to permanently or temporarily transfer all or a substantial part of the contents of a database to another medium by any means or in any form). The Article is not about the making available right. On the contrary, it is common in scientific research to make source materials available in order to allow others to verify and repeat experiments. Since this is about the making available right and not the reproduction right (Geiger et al., Reference Geiger, Frosio and Bulayenko2018a), Directive’s Article 3 does not allow to publish protected works used during training. In principle, this appears to be correct: the researcher has lawful access to the works, whereas others may not. Making them (or derived versions of them) available means providing others access even if any terms or conditions have not been agreed. However, in practice, this means the verification of research results is not promoted, since it can only be performed by the researchers themselves (Geiger et al., Reference Geiger, Frosio and Bulayenko2018b, among others, highlighted this in vain before Directive’s adoption). In this direction, a good compromise appears to be Article 60d of the German Law on Copyright and Related Rights, which allows the making available of the (normalized and structured) dataset to a “specifically limited circle of persons for their joint scientific research, as well as to individual third persons” for quality assurance (Geiger et al., Reference Geiger, Frosio and Bulayenko2018b). Without a statement like this, in case of a research based on not publicly available data, the only (lawful) way to allow the verification of results will be to provide all the necessary information about the data usedFootnote 6 and all the preprocessing steps carried out on them or, even better, the related source code.
In addition, Article 4 states there shall be an exception or limitation to allow reproductions and extractions of lawfully accessible protected works also by other people or institutions, only for the time necessary for the purposes of TDM. Crucially, this exception or limitation is applied only if it has not been expressly reserved by their rightholders in an appropriate manner.
To summarize, the Directive includes the use of a (lawfully accessible) protected work for training among the lawful uses: it allows for research organizations to use it for TDM. In addition, also other entities can do the same, provided that its rightholder has not expressly reserved this right.
Article 3 is undoubtedly able to foster innovation and scientific research. Even if it only adds an exception for the reproduction right and not for the making available right, making it difficult to reproduce and validate research experiments, in our opinion, it is a good compromise between protection and innovation. In addition, Article 4 represents a positive contribution, at least from a theoretical perspective. It is able to encourage innovation also in private environments, avoiding the risk of losing considerable investments (see Hilty and Richter (Reference Hilty and Richter2017) for a discussion of compelling motivations for opening TDM to private entities). In our opinion, leaving the possibility of reserving this exception to rightholders is essential from an ethical perspective (we will talk about it in Section 5). However, many questions arise when trying to operationalize this Article. As highlighted by Rosati (Reference Rosati2019), private developers who want to use protected works to train generative models have to follow these three steps: obtain a lawful access to the data; check if rightholders have not reserved the right to make reproductions for TDM purposes; and retain any copies made only for as long as is necessary for TDM purposes. The first and third steps appear to be reasonable; instead, in our opinion, the second step presents some issues. How could an EU-based developer know if this right has been reserved for a certain protected work? In Recital 18, the Directive suggests reserving those rights through machine-readable means (e.g., metadata and terms or conditions of a website or a service) in case of publicly available content, and contractual agreements or unilateral declarations for other contents. Even if the list of means that is provided might appear as exhaustive, the issue does not appear to be addressed in a satisfactory manner. As we have seen in Section 2, a generative model is typically trained on a very large dataset. In other words, this might translate into the practical solutions of (a) having online databases that allow to filter (by means of metadata) the available works depending on this reservation or (b) directly publishing datasets only composed by reservation-free works, making sure at the same time they can be integrated with the reserved ones for research purposes. But are these providers forced to do so? Or will this checking activity fall on developers (in a way, dissuading them by training generative models [Chiou, Reference Chiou2019])? Finally, we have also mentioned Google’s DeepDream, which only requires one image in input. The same can apply to poems or other texts, which can be fed in input to emerging techniques such as VQ-GAN + CLIP (Esser et al., Reference Esser, Rombach and Ommer2021; Radford et al., Reference Radford, Kim, Hallacy, Ramesh, Goh, Agarwal, Sastry, Askell, Mishkin, Clark, Krueger and Sutskever2021) to obtain alien dreams (see Snell, Reference Snell2021). Here, only one protected work may be used, not extracted by a database provider, but independently acquired. Will the transaction report if this right has been reserved or not? How would it be possible to discover if a work (with an access acquired before 2019) can be used or not? We believe that there is an urgent need of addressing these questions before the TDM exception could be applied in all of its strength.
3.3. Additional issues
We should also remember from Section 2 that GDL involves the creation of a probabilistic model describing data of interest, from which we obtain new works through sampling. This peculiarity leads to other critical questions. In fact, the model creation and storage, which contains the extracted probabilistic features, may infringe the copyright of works used for training. Its storage cannot be considered as transient or incidental; therefore, it is allowed only if it does not constitute a (partial) reproduction of protected works, since, in that case, there is no copyright relevant activity (Margoni, Reference Margoni2018).
Deep learning models are usually stored as sets of numerical weights; usually, they do not fall in the category of those that are considered as a partial reproduction of a work. However, if the model is built to mimic in output the input (with some nonsubstantial changes) and it is trained over a protected work, the model would represent that work, at least partially. Moreover, even if the model is not intentionally built to mimic a protected work, it could still end up doing so to an infringing degree: it might reconstruct idiosyncrasies of input data instead of reflecting underlying trends about them (Sobel, Reference Sobel2017). If just trained with the goal of learning how to reproduce works, an overfitted generative model may actually be considered as a direct reproduction of the works.
These issues are not only related to the model itself, but also to the output it can generate. Protected input data are commonly used to train models to generate similar output. Then that output may infringe copyright in the preexisting work or works to which it is similar to (Sobel, Reference Sobel2017). In this context, the importance of adversarial training from GANs and searching for diverging from existing works as done by Elgammal et al. (Reference Elgammal, Liu, Elhoseiny and Mazzone2017) may tip the balance toward legality. With respect to other classic techniques, the generative part of a GAN never uses protected data; therefore, it is harder to obtain an output representing an expression of protected data. In addition, new techniques with a novelty objective, which tries to increase the distance between outputs and training data, will tend to be more transformative. This may be crucial, since prior appropriation art cases suggest that, if the result is sufficiently transformative, the use may be protected by fair use or may not represent an infringement of the copyright law (Ligon, Reference Ligon2019). However, accidental reproduction of protected works in part might happen, requiring the explicit rightholders’ authorization, and not only their not reservation (Sturm et al., Reference Sturm, Iglesias, Ben-Tal, Miron and Gomez2019). For this reason, in addition to use (new) transformative methods, we suggest to conduct experiments about accidental plagiarism that may be caused by the developed system, as done, for instance, by Hadjeres et al. (Reference Hadjeres, Pachet and Nielsen2017).
These considerations about the transformative nature of the result seem fundamental to establish a potential copyright infringement in case of using a protected work as the input image to algorithms like Google’s DeepDream. If the result of the modifications of the input is an image that substantially resembles it, it is likely to be considered a reproduction in part, and so this might lead to a copyright infringement. However, as reported by Guadamuz (Reference Guadamuz2017), this process typically results in producing new images that do not resemble the original ones. This opens the possibility of considering them sufficiently transformative not to be considered as a reproduction in part. In addition, the fact that they are not the result of creative decisions by the programmers leads to the question that we will try to address in the next section.
4. Copyright of Generated Works
The remaining question is who, if anyone, would be the owner of the IP rights associated with an artwork produced by a generative model. To answer this question, this section is divided in two parts: a subsection with the current legal analysis (Section 4.1) and a subsection with possible future addresses and some policy suggestions (Section 4.2).
4.1. Legal analysis
At first, it is important to make some distinctions. If the generative model is used just as a tool (or the human has an active role in the creative process), the human will be considered as the author; this means that if the human is in charge of the intellectual creation (e.g., by setting all the parameters required to characterize the product, as it is possible with StyleGAN [Karras et al., Reference Karras, Laine and Aila2019]) or the product can be considered as a co-creation, then the authorship is assigned to that person. In addition, even if the machine has generated the work independently from the human but the latter has selected and evaluated the outputs, rejecting some works and choosing only the best ones following his/her aesthetic tastes, the human can arguably be considered as the author of the work (Glasser, Reference Glasser2001). As far as works that are fully attributable to a machine are concerned, actually no one would obtain the copyright of machine-generated artworks (Santos and Machado, Reference Santos and Machado2020). In fact, a fundamental requirement for the application of all the actual laws is that of originality. Even if it is not straightforward to find a precise and applicable definition of originality, in the European Union, it has been commonly considered as satisfied when the work is the reflection of author’s personality (Deltorn, Reference Deltorn2017), whereas in the United States, it could be interpreted as a minimum requiring evidence of a human (intellectual) creativity (Gervais, Reference Gervais2002). It is questionable to say that computer-generated artworks are the result of the personality of someone—or something—leaving the works unprotected.Footnote 7 As a confirmation of this, the Compendium of U.S. Copyright Office Practices establishes that it will not register works produced by a machine or mere mechanical process that operates randomly or automatically without any creative input or intervention from a human author (see Article 313.2), citing, as example, a list of mechanical activities that are the exact opposite with respect to those performed by GDL, and the ones that might be reasonably considered as creative (Palace, Reference Palace2019). In addition, Spain, Germany, and Australia have formulated a similar criterion, establishing that only works created by humans can be protected by copyright.
On the contrary, the most famous example of a law article for machine-generated artworks is Section 9(3) of the British Copyright, Designs and Patents Act. This section states that in case of a literary, dramatic, musical, or artistic work, which is computer-generated, the author shall be taken to be the person by whom the arrangements necessary for the creation of the work are undertaken (the same criterion is also considered by Ireland, New Zealand, Hong Kong, South Africa, and India). This section has been the subject of an intense debate (see Bond and Blair, Reference Bond and Blair2019). The general consensus is that is difficult, even if not impossible, to find a person who provides necessary arrangements for contemporary machine-generated artworks, i.e., the ones created by GDL (Smith, Reference Smith2017). The current lack of protection and the nongeneral applicability of British criterion are two of the reasons why the European Parliament and Commission have recently been highlighting the need of a specific law for IP rights in case of machine-generated works.
In particular, in 2020, the European Parliament adopted a Resolution “on IP rights for the development of AI technologies”, which follows a 2017 Resolution with recommendations to the Commission on Civil Law Rules on Robotics, the first step in trying to regulate this chaotic field. In 2017, the European Parliament asked a solution to protect and, at the same time, foster innovation to the Commission, in order to overcome the problem of nonallocating rights explained above, supporting a horizontal and technologically neutral approach to IP. This approach appears to have an influence on the content of the most recent Resolution. Here, the Parliament highlights the importance of creating a regulation to protect IPRs in the field of AI, in order to protect innovation, guarantee the legal certainty, and build the trust needed to encourage investments in these technologies (Points 3 and 6). Then, it suggests not to impart legal personality to AI—so, no rights can be assigned to it (Point 13). On the contrary, it recommends, if copyright is considered as the correct protection for AI-generated works, to assign the ownership of rights to the person who prepares and publishes a work lawfully, provided that the technology designer has not expressly reserved the right to use the work in that way (from the Explanatory Statement of Report A9-0176/2020, on which the Resolution is based; Point 15 specifies that ownership of rights should only be assigned to natural or legal persons that created the work lawfully, but in our opinion, the term “created” in the context of AI-generated works is misleading and unclear, and the explanation reported above is more useful). In addition, it clarifies that this position is legally correct and harmonized with the existing law; the only requirement is to consider the condition of originality as satisfied not only if the process is creative, but even when the result is creative. This derives from the assumption that AI-generated creation and traditional creation still have the aim of expanding cultural heritage in common, even if the creation takes place by means of a different act. For this reason, if and when this Resolution is embraced by the European Commission too, the owner of the rights will be the person that has prepared and published the work lawfully.
4.2. Policy suggestions
Even if the current laws do not contemplate machine-generated works for copyright protection, the matter of right attribution has been hugely discussed, not only in terms of law, but also in terms of ethical implications.
The position of not assigning copyright in machine-generated works may appear to be convenient at first; indeed, it does not ask to change anything. It might also help preserve the centrality of human authorship in copyright law (see Mezei, Reference Mezei2020) and stress the importance of what an author should be versus what an author should do (see Craig and Kerr, Reference Craig and Kerr2019). Another, more practical reason is that a work should receive copyright protection only if an author exists; but to be considered so, the work must include a meaning or a message he/she wishes to convey, and this cannot happen if no one is able to predict the output of the program (Boyden, Reference Boyden2016), as in deep learning models (Ginsburg, Reference Ginsburg2018). Finally, placing computer-generated works in the public domain can help preserve the centrality of humans in creative fields, since protection would be guaranteed only to work with an intellectual human contribution (Palace, Reference Palace2019).
At the same time, there are also strong reasons not to leave them unprotected. First of all, though consistent with the traditional concept of an author as a person, denying protection is inconsistent with the historically flexible interpretation and application of copyright laws as technology has developed. AI products should be evaluated following this flexible interpretation too (Butler, Reference Butler1982). However, the best motivation for the allocation of ownership interests to someone is that the person should be incentivized not for the ideation and creation of the work in itself, but for its public promotion and for making it possible for the computer to create the work (by writing it, training it, or instructing it; see Miller, Reference Miller1993). If the law considers a machine-generated work as incapable of being owned because of the lack of a human author, there is limited incentive for creating them and making them public. On the contrary, this might lead to potentially malicious behavior, for example, the person that used the algorithm to generate the work might be tempted to lie about the way it was created or change it in order to be considered its author (Samuelson, Reference Samuelson1986). Finally, the idea that this would mean to incentivize the proliferation of arts and articles of poor quality, penalizing the role of human artists and journalists (Gervais, Reference Gervais2020), does not convince us at all. If, as stated, the protection of computer-generated works would translate into a larger number of mediocre works, then for humans it will be easier to produce works of quality higher that those that have been generated by machines and clearly stand out. In addition, even if the current copyright laws were thought to regulate scarcity of products created by humans (Hurt and Schuchman, Reference Hurt and Schuchman1966) and not abundance (of machine-generated products), leaving all of them in the public domain could cause more damage to human authors. The possibility of using them for free may persuade clients to do so, even if human artworks are qualitatively better.Footnote 8
As we have seen in the previous subsection, the European Parliament seems to agree with this line of thought, proposing to allocate rights to who has prepared and published the work lawfully. The same conclusion (of the European Parliament) can be reached in different ways. Following Franceschelli (Reference Franceschelli2019), there can be three main individuals involved in the process: the programmer, the person who provides necessary arrangements, and the user. Notice that even if we will consider them separately, in many cases, they are the same person. The programmer is just the person who has written the code for the machine; the person who provides necessary arrangements can be, for example, the individual who provides instructions for the desired output, or necessary information about the work the machine has to generate; and the user is the person that, legitimately (because, e.g., the individual is the owner of the machine or has acquired it with a license), ultimately runs the machine and asks it to generate an artwork. In our opinion (but also of the European Parliament and of Bohlen (Reference Bohlen2017); Samuelson (Reference Samuelson1986); Yanisky-Ravid (Reference Yanisky-Ravid2017), among others), the rights should be allocated to the user, that can be considered an alter ego of the “person who prepares and publishes a work lawfully” (even if the person who provides the necessary arrangements can also be seen under the definition of who prepares the work). Although, in a way, it seems counterintuitive, there are different ways to reach this conclusion.
Yanisky-Ravid (Reference Yanisky-Ravid2017) and Bohlen (Reference Bohlen2017) suggest an analogy with the ownership of economic rights in case of software produced by an employee, the so-called work-made-for-hire doctrine: as the employer is entitled to exercise all economic rights in an employee’s computer program (if the creation is part of the scope of his/her employment or it is commissioned by the employer), the user is the person who actually causes the creation of the work. Therefore, it is possible to say that the user has employed the computer for his/her creative endeavors. In this way, rights can be allocated preventing works from falling into the public domain regardless of the extent of human creative contribution. In addition, Hristov (Reference Hristov2017) and Gurkaynak et al. (Reference Gurkaynak, Yilmaz, Doygun and Ince2017) suggest to use the analogy with work-made-for-hire doctrine to allocate rights, but with a potentially different conclusion. In fact, they suggest that the equivalent of the employer has to be the programmer or the owner of the generative program, because they are those who really need to be incentivized, rejecting the chance of assigning rights to the end user. However, their definition of end users is quite different from that considered here: here, we consider as users the persons who have lawful access to the generative program, and can lawfully use it to generate works. We assume that they are the owners of the program (who, following Wu (Reference Wu1997), should be the copyright owners), possibly because (a) they are also its developers; (b) they have acquired it from the developers; or (c) following the same doctrine, the developers are their employees. In any case, they are the lawful owners of its economic rights. Alternatively, we assume that they have acquired it via license. In this way, there is no need of an extra economic incentive for the developers (they have already been paid or have chosen to release the product freely) or for the owners (they have already been paid for the license or have chosen to release the product freely). On the contrary, the users have paid for using the generative program, or they can use it freely because of a particular license. In general, we believe that, even if the generative program has been published and it is accessible by millions of end users, Terms of Service written by the publisher should regulate these kinds of problems. We suggest future publishers combine their generators with Terms of Service in order to clearly identify the owner of the generated products (and the associated terms).
Vice versa, Samuelson (Reference Samuelson1986) (but also see Denicola, Reference Denicola2016) states that even if users may not be the ultimate market-makers for machine-generated works, they are in the same position as traditional authors since they take the initial steps that will bring a work into the marketplace (and into its exterior form). Since society has an interest in making these works available to the public, the most effective solution is to give incentives to users to make them available and accessible to others.
Finally, we can reach the same conclusion also working by elimination. The programmer is responsible of the machine creative abilities and, for other kinds of AI (e.g., rule-based systems), it might seem to be enough to establish the originality requirement—and therefore the ownership—in the programmer (Farr, Reference Farr1989). However, as regards GDL, he/she just creates the potentiality for the creation of the output, but not its actuality (Samuelson, Reference Samuelson1986). It would be like trying to assign copyright to the teaching artist of a painter, instead of to the painter himself/herself, or, using the analogy proposed by Ralston (Reference Ralston2004), to claiming a knife manufacturer is more responsible for a murder than the person who wielded the knife. The person who provides necessary arrangements can be difficult to identify, and sometimes the generative model may not have such a person associated to it, due to the complexity of deciding which are necessary arrangements and which are just useful arrangements (Franceschelli, Reference Franceschelli2019). A simple example to understand why it is so difficult to use this definition to assign ownership is now presented. Consider the already mentioned Botnik and its creative keyboard.Footnote 9 When we open it, it starts with John Keats as the source, and it starts suggesting words according to John Keats’ texts on which a neural model was previously trained. Then, we can start selecting each time the word in the first position between suggestions, composing a new (and hopefully creative) text. Notice that we could choose the word among different options, and this selection would mean that we would be recognized as the authors (using Botnik just as a tool), be we did not. Now, which shall be considered the necessary arrangements? The only two things we have done as users were to open the website and compulsively click to the first suggested word. Is it enough to consider our actions as necessary arrangements? Of course not. So, necessary arrangements shall be the ones performed by who has loaded John Keats’ poems and trained the network; or maybe the ones performed by who has decided that the preset source was John Keats one. But no poems would arise from the creative keyboard without our incredibly simple operations, and it does not seem reasonable to leave, a priori, the ownership of these kinds of machine-generated works to someone who was not involved in the materialization of the work—that is, what the law shall protect. No solution seems reasonable, in these cases, in order to assign the rights to who has provided necessary arrangements; of course, there can be other cases in which it might seem the right choice, but it would be better to have a rule with the most general applicability, even if Grimmelmann (Reference Grimmelmann2016b) suggests a case-by-case analysis to deal with the heterogeneity of computer-generated works. For this reason, we discard the person who provides necessary arrangements. On the contrary, allocating rights to the user seems not to have any particular flaws; of course, he/she may not have provided any creative contribution, but, as explained above, this does not seem a valid argumentation. For all of these reasons, we think the user should be considered as the owner of (economic) rights.
Finally, an additional consideration about copyright allocation must be done. One of the most explored creative fields by AI researchers is (video)game design. With respect to GDL, it typically concerns the use of generated images (Tilson and Gelowitz, Reference Tilson and Gelowitz2019), characters (Jin et al., Reference Jin, Zhang, Li, Tian and Zhu2017), or soundtracksFootnote 10 inside games; in these cases, all the conclusions drawn until now are still valid, and no additional considerations are required. However, a growing application is the so-called procedural content generation, where the game scenarios are dynamically generated during game (Liu et al., Reference Liu, Snodgrass, Khalifa, Risi, Yannakakis and Togelius2021). Although this task is technically very similar to image generation (with an additional complexity provided by the need of dynamic adaptation and of complexity growth), an additional consideration about copyright allocation is needed. In fact, in procedural content generation, it is not immediate to identify the user (as we have intended him/her). Of course, there is the player, who is a game user; but the copyright allocation as stated above is about generative model user. In this case, the algorithm which generates the game content is not directly used by a person; it is directly used by the game code, and therefore indirectly by the game programmer, who has employed the GDL techniques not to generate content statically, but dynamically. By considering the programmer of the game code as the user of the generative model, the conclusion drawn during this section remains generally applicable in our opinion (and also according to previous literature, e.g., Bridy, Reference Bridy2012).
5. Code Generation
Finally, a quite different GDL use case is about code generation. In particular, GitHub (and OpenAI) CopilotFootnote 11 has caused a great debate about copyright implications (Guadamuz, Reference Guadamuz2021). Copilot is an AI system able to autocomplete lines of code, but also to generate entire blocks and functions just providing comments or signatures. It is based on an autoregressive model (very close to GPT-3 [Brown et al., Reference Brown, Mann, Ryder, Subbiah, Kaplan, Dhariwal, Neelakantan, Shyam, Sastry, Askell, Agarwal, Herbert-Voss, Krueger, Henighan, Child, Ramesh, Ziegler, Wu, Winter, Hesse, Chen, Sigler, Litwin, Gray, Chess, Clark, Berner, McCandlish, Radford, Sutskever and Amodei2020]) trained on English texts and source codes from publicly available sources as GitHub’s public repositories, but not exclusively.
From a legal perspective, GitHub Copilot introduces some additional complexities that are of particular interest for our analysis of copyright in generative learning. With respect to the acquisition and the storage of works used during training, we note that the fact a work is publicly available does not mean it is in the public domain, or it is released under a permissive license—see Points 1 and 2 in Section 3. For instance, the contents of GitHub’s public repositories, which are not associated a license, are intended to be under copyright’s law—see Points 3 and 4 in Section 3. The GitHub’s Terms of Service states that GitHub can process content shared in public repositories as needed to provide the Service, which includes all the applications, software, and products provided by GitHub—and therefore also includes Copilot. However, content from external sources is also used. In order to lawfully exploit these sources, their use must fall under the definition of “fair use” (or, in the European Union, must be considered a “lawful use”), as highlighted above. GitHub itself claims that training machine learning models on publicly available data is considered fair use across the machine learning community; however, it is not straightforward to confirm so. The fair use is determined based on the four criteria examined in Section 3.1. In this case, the use is not for research purpose, and it seems more expressive than non-expressive. In addition, its economic character is not negligible (Copilot is free to use, but companies may use it). The public availability of the works helps satisfy the second criterion for fair use. Then, the work is entirely used during training, but the substantiality of the use is questionable, as discussed before. Finally, the effect upon the potential market depends on the model itself. If it cannot substantially reproduce an existing source code or, if it can, it is able to identify it and refer the user to the original source, also this fourth condition is satisfied and the use could presumably be seen as a fair use.
We also note that publicly available contents have been released under licenses like GNU GPL, with the goal of protecting freedom.Footnote 12 These licenses are chosen in order to avoid any commercial use of the free software, asking to release the derivative work with the same license, in order to foster freedom (and innovation). This is in clear contradiction with the application of the fair use doctrine in case of training a model which could be used for economic purposes. In this way, the question becomes more about ethics than about law: should fair use doctrine be applicable to deep learning independently from the economic character of the application (as it is: fair use is an on/off switch (Ginsburg, Reference Ginsburg2014) and once established the use is fair, nothing prevents the user to do so) or should developers have the opportunity of reserving the right to this kind of utilization? The European Union appears to be aligned to the second option. As discussed in Section 3.2, Directive’s Article 4 considers this use as lawful, unless the rightholder has not expressly reserved this exception. It is not completely clear how to practically reserve it; in our opinion, an interesting possibility will be to augment current licenses and to deal with this right as with the others: as a license specifies if a commercial use is allowed or not, it can also specify if a training use (not only for research purposes) is allowed or not. Of course, this sort of solution could work in the United States only if they will decide that this use can be reserved, and that the fair use doctrine is not always applicable.
Another important consideration is related to potential copyright infringement. As observed in Section 3.3, training on protected works could cause a reproduction in parts of the model or, more probably, in the generated output. It has been shown that Copilot quotes existing content very rarely, and it mostly quotes very common code, for which it is almost impossible to detect a substantial reproduction (Ziegler, Reference Ziegler2021). However, since in principle it may happen, it is praiseworthy that GitHub and OpenAI are building a tracker to detect the rare instances of code that is repeated from the training set. We hope it will help users identify the source and author of the code, so that they can directly use it and check the corresponding license, which might require that certain conditions are satisfied.
Finally, the issue related to the ownership of generated code does not introduce any additional complexity. Currently, Copilot works only as a tool, asking the user to test, review, and complete the code; therefore, the user is lawfully considered as the author—and as the owner. If, in the future, it will not require active supervision anymore and the program will be considered as the author, then it will just become another example of how the work-made-for-hire doctrine perfectly fits GDL. The user, who also provides necessary arrangements (in the form of comments and signatures), is employing Copilot to perform a task within the scope of its employment; therefore, even with a higher degree of autonomy, the user should be considered as the owner of related rights.
6. Conclusion
In this article, we have explored the most important problems concerning copyright in relation to GDL, trying to understand how the current laws can or cannot permit some common practices. In particular, in Section 3, we have analyzed if and when, under US and EU law, it is possible to store protected works with the goal of training a generative model; the conclusion is that fair use doctrine and 2019 EU’s Directive seem to allow this, but with some reservations about the general applicability (for the United States) and a few practical obstacles (for the European Union). Then, in Section 4, after having explained that at the moment a GDL output is not protected by copyright, we have also explored future directions in terms of design of legislative frameworks and how these works shall be protected in near future.
In conclusion, from a practical point of view, as far as researchers are concerned, we suggest (a) to pay attention at the information that is stored (and for how long) during the whole process (and, in case of private use, to carefully check terms or other conditions which could prevent the TDM exception); (b) to try to diverge from the dataset used during training, in order to avoid the risk of a reproduction in part, but also in order to strengthen a transformative use claim; (c) to clarify their position through Terms of Service if other users would be able to use their generative model; and (d) of course, to keep update about the evolution of the legislative frameworks at national and international levels.
Acknowledgment
A preprint version of the article is available in arXiv (Franceschelli and Musolesi, Reference Franceschelli and Musolesi2021a).
Funding Statement
This work received no specific grant from any funding agency, commercial, or not-for-profit sectors.
Competing Interests
The authors declare no competing interests exist.
Author Contributions
G.F. and M.M. designed the study, wrote the first draft, and approved the final version of the manuscript.
Data Availability Statement
No data, code, or other materials have been used.
Ethical Standards
The research meets all ethical guidelines, including adherence to the legal requirements of the study country.

 Open access
Open access
Comments
No Comments have been published for this article.