



INTRODUCTION
A central question in second language (L2) acquisition research concerns how learners represent and utilize morphosyntactic features. One generalization that emerges from this literature is that learners show variability in the comprehension and use of inflection (i.e., the morphological exponence of features), even at high‑proficiency levels (e.g., Franceschina, Reference Franceschina2005; Grüter et al., Reference Grüter, Lew-Williams and Fernald2012; Hopp, Reference Hopp2010; Keating, Reference Keating2009, Reference Keating, Van Patten and Jegerski2010; Lardiere, Reference Lardiere1998; McCarthy, Reference McCarthy2008, Reference McCarthy2012; Rossi et al., Reference Rossi, Kroll and Dussias2014; Tsimpli & Dimitrakopoulou, Reference Tsimpli and Dimitrakopoulou2007; see Slabakova, Reference Slabakova, Malovrh and Benati2018). Theoretical models have suggested distinct, non-mutually exclusive sources of variability. For example, some prominent theories attribute variability to L1‑L2 (dis)similarity with respect to either feature instantiation (e.g., Hawkins, Reference Hawkins2001; Hawkins & Chan, Reference Hawkins and Chan1997; Schwartz & Sprouse, Reference Schwartz and Sprouse1996; Tsimpli & Dimitrikopoulou, Reference Tsimpli and Dimitrakopoulou2007) or morphological realization (e.g., Jiang, Reference Jiang2004, Reference Jiang2007; Lardiere, Reference Lardiere2009; Tokowicz & MacWhinney, Reference Tokowicz and MacWhinney2005). Others identify processing pressure as the locus of variability, either in production (e.g., Pienemann, Reference Pienemann2015; Prévost & White, Reference Prévost and White2000; Rothman, Reference Rothman2007; White, Reference White2011) or in online comprehension (e.g., Grüter et al., Reference Grüter, Lew-Williams and Fernald2012; Hopp, Reference Hopp2010; McDonald, Reference McDonald2006). Additional work has shown that factors such as phonological realization (e.g., Cabrelli Amaro et al., Reference Cabrelli Amaro, Campos and Rothman2018; Carrasco‑Ortiz & Frenck‑Mestre, Reference Carrasco-Ortiz and Frenck-Mestre2014; Goad & White, Reference Goad and White2006, Reference Goad and White2019) or structural/linear distance (e.g., Gillon‑Dowens et al., Reference Gillon-Dowens, Vergara, Barber and Carreiras2010; Keating, Reference Keating, Van Patten and Jegerski2010) also account for inflectional variability.
The present study investigates the relationship between L2 inflectional variability and markedness, the observation that different feature values are asymmetrically represented. Morphological theory proposes that marked features are more complex, have more internal structure, or are less frequent than unmarked features. For person, the claim is that first and second person are marked, while third person is unmarked (e.g., Forchheimer, Reference Forchheimer1953; Harley & Ritter, Reference Harley and Ritter2002; Harris, Reference Harris and Campos1995; McGinnis, Reference McGinnis2005; Nevins, Reference Nevins2011).Footnote 1 An additional claim is that only marked features are specified. For example, first and second person are specified as participants in the speech act, the speaker and addressee, respectively. Third person, in contrast, is underspecified (i.e., it lacks featural information) because it is a nonparticipant in the speech act. Third person is considered to be the “default” person, a sort of “elsewhere” form. Our study examines whether/how this asymmetry impacts L1‑English L2‑Spanish learners’ processing of sentences like (1a–b), which differ with respect to person markedness. We build on previous observations that learners overuse “defaults,” that is, forms that are unmarked/underspecified (although not necessarily uninflected) and thus appear in a wider range of contexts (e.g., third‑person verbal inflection emerges with personless subjects, as in Correr relaja “Running relax‑3RD-SG”) (e.g., Hawkins, Reference Hawkins2001, Reference Hawkins2009; McCarthy, Reference McCarthy2008; Prévost & White, Reference Prévost and White2000).

Several L2 theoretical models claim that markedness modulates acquisition, although the specific proposals differ (e.g., Hawkins, Reference Hawkins2001, Reference Hawkins2009; Haznedar & Schwartz, Reference Haznedar, Schwartz, Hughes, Hughes and Greenhill1997; McCarthy, Reference McCarthy2008; Prévost & White, Reference Prévost and White2000). For example, the Missing Surface Inflection Hypothesis (MSIH) (e.g., Prévost & White, Reference Prévost and White2000) posits that learners overuse defaults (i.e., masculine, singular, third person) in contexts that require marked features (i.e., feminine, plural, first/second person), but rarely do the reverse. The source of this variability is assumed to be a computational deficit. More specifically, it is argued that learners can represent abstract features, but have difficulty with the retrieval of inflectional morphemes and their mapping onto lexical items under computational pressure (e.g., White, Reference White2011). For example, when establishing agreement with a first‑person subject, which is marked/specified for person (speaker), learners might incorrectly supply third-person verbal inflection (e.g., Yo *habla español “I-1ST‑SG speak-3RD‑SG Spanish”) because unmarked/underspecified forms (i.e., defaults) are easier to retrieve and function as a sort of all‑purpose form. However, if the subject corresponds to the third person, learners rarely inflect verbs for first person (Él *hablo español “He-3RD‑SG speak-1ST‑SG Spanish”) because they have difficulty retrieving marked/specified forms. In sum, learners tend to underspecify agreement targets such as verbs (or adjectives), but they rarely do the reverse.
Alternatively, McCarthy (Reference McCarthy2008) posits that the overuse of defaults is not due to lexical retrieval difficulty, but to the asymmetrical representation of features in the learner’s grammar. McCarthy’s account predicts qualitatively similar variability (i.e., overreliance on defaults) across tasks (i.e., comprehension, production). This contrasts with the MSIH, which predicts variability to emerge as a function of the task’s computational burden. McCarthy (Reference McCarthy2008) found that intermediate/advanced English‑speaking learners of Spanish incorrectly extended masculine forms to feminine contexts in both comprehension and production, but they seldom did the reverse. Furthermore, the learners overused singular in production. With respect to person, McCarthy (Reference McCarthy2012) found that L1‑English L2‑Spanish learners produced third-person verbs with first‑person subjects (83/111 errors), but rarely did the reverse (18/111 errors). Importantly, the intermediate group outperformed low‑intermediate learners with first‑person verbs (~88% vs. ~70%), but not with third‑person verbs (~92% vs. ~94%, respectively), suggesting that marked forms are acquired later. Although this aligns with McCarthy’s proposal, the lack of comprehension data showing the same asymmetry precludes conclusions.
Recent investigations have examined inflectional variability in real‑time comprehension (e.g., Grüter et al., Reference Grüter, Lew-Williams and Fernald2012; Hopp, Reference Hopp2010; López Prego, Reference López Prego2015; López Prego & Gabriele, Reference López Prego and Gabriele2014). For example, López Prego and Gabriele (Reference López Prego and Gabriele2014) examined number and gender agreement in Spanish with a design manipulating both markedness and task demands (untimed vs. speeded grammaticality judgment task [GJT]). Under time pressure, the intermediate and advanced learners were slower and less accurate detecting “plural noun + singular adjective” errors than the reverse configuration, suggesting some reliance on defaults (i.e., overusing singular). Crucially, the L1‑Spanish controls showed a similar asymmetry for both number and gender when tested under stress, suggesting that overreliance on defaults can emerge under computational pressure in intact grammars.
Another relevant finding from López Prego and Gabriele’s study is that the intermediate/advanced learners were faster and more accurate rejecting “feminine noun + masculine adjective” errors relative to “masculine noun + feminine adjective” errors, contra McCarthy’s predictions. The authors suggest that, when the first element in the dependency is marked/specified for gender (feminine), feature activation might ease agreement resolution by allowing the parser to better anticipate the gender of the upcoming adjective (e.g., Dussias et al., Reference Dussias, Valdés Kroff, Guzzardo Tamargo and Gerfen2013; Foucart et al., Reference Foucart, Martin, Moreno and Costa2014; Hopp, Reference Hopp2013).
López Prego and Gabriele’s proposal connecting markedness to facilitation originated in the psycholinguistics literature, where it has been argued that marked features remain longer in the focus of attention (e.g., Wagers & McElree, Reference Wagers and McElree2011; Wagers & Phillips, Reference Wagers and Phillips2014) and are, thus, more likely to impact agreement operations. For example, ungrammatical strings such as the key to the cabinets *are cause less disruption when the attractor noun (cabinets) is plural (e.g., Acuña Fariña et al., Reference Acuña Fariña, Meseguer and Carreiras2014; Dillon et al., Reference Dillon, Mischler, Sloggett and Phillips2013; Pearlmutter et al., Reference Pearlmutter, Garnsey and Bock1999; Wagers et al., Reference Wagers, Lau and Phillips2009). Likewise, Carminati (Reference Carminati2005) showed that coreference between a null pronoun and a structurally dispreferred antecedent is less disruptive when the disambiguating verb is inflected for first/second person (marked) relative to third person (unmarked). Crucially, Nevins et al. (Reference Nevins, Dillon, Malhotra and Phillips2007) posited that markedness might determine whether agreement is established predictively. Their proposal is that, upon encountering a marked feature, the parser can generate a stronger prediction regarding upcoming agreement elements.
To summarize, certain L2 theoretical models (McCarthy, Reference McCarthy2008, Reference McCarthy2012; Prévost & White, Reference Prévost and White2000) posit that learners have difficulty accessing marked/specified forms when establishing agreement. Consequently, they incorrectly overextend unmarked/underspecified forms (i.e., defaults) to contexts that require marked ones, due either to computational pressure (e.g., the MSIH) or to representational issues (e.g., McCarthy, Reference McCarthy2008). Alternatively, proposals from the psycholinguistics literature (e.g., Nevins et al., Reference Nevins, Dillon, Malhotra and Phillips2007; Wagers & Phillips, Reference Wagers and Phillips2014) capitalize on the predictive value of marked features. Under this proposal, when the first element in the dependency is marked, feature activation allows the parser to better resolve agreement further down the line.
BACKGROUND OF THE PRESENT STUDY
In previous studies, we evaluated the previously mentioned proposals regarding how markedness impacts agreement resolution in both native (Alemán Bañón & Rothman, Reference Alemán Bañón and Rothman2016, Reference Alemán Bañón and Rothman2019) and nonnative speakers of Spanish (Alemán Bañón et al., Reference Alemán Bañón, Miller and Rothman2017). In those studies, we examined online agreement resolution using event‑related potentials (ERPs). In addition to providing high temporal resolution and being multidimensional, ERPs can unveil qualitative differences between different agreement dependencies. For example, Foucart and Frenck‑Mestre (Reference Foucart and Frenck-Mestre2012) found that the same L1‑English L2‑French learners elicited qualitatively different brain responses to gender errors (N400 vs. P600), depending on the syntactic configuration where they were realized. ERPs are, therefore, well suited for investigating both quantitative and qualitative differences between agreement dependencies that differ with respect to markedness.
In Alemán Bañón and Rothman (Reference Alemán Bañón and Rothman2019), we argued in favor of Nevins et al.’s proposal (Reference Nevins, Dillon, Malhotra and Phillips2007) that markedness allows the parser to resolve agreement top‑down, at least when the dependency is sufficiently constraining (e.g., Dillon et al., Reference Dillon, Mischler, Sloggett and Phillips2013). In that study, we examined subject‑verb person agreement with both first-person (marked/specified: speaker; see 2) and third‑person singular subjects (unmarked/underspecified: see 3) in a group of 28 native speakers of European Spanish. We then manipulated agreement by crossing first-person subjects with third‑person verbs (2b) and vice versa (3b). Both violation types yielded a P600 (500–1,000 ms), a component associated with various morphosyntactic operations (e.g., Osterhout & Holcomb, Reference Osterhout and Holcomb1992), consistent with previous studies on person agreement (e.g., Mancini et al., Reference Mancini, Molinaro, Rizzi and Carreiras2011, Reference Mancini, Massol, Duñabeitia, Carreiras and Molinaro2019; Nevins et al., Reference Nevins, Dillon, Malhotra and Phillips2007; Silva Pereyra & Carreiras, Reference Silva Pereyra and Carreiras2007; Zawiszewsky et al., Reference Zawiszewsky, Santesteban and Laka2016).Footnote 2


Violations with a first‑person subject (2b) yielded a larger P600 (700–900 ms) than violations with a third‑person subject (3b), which we interpreted as evidence that the parser can better resolve agreement when the first element in the dependency is marked (Nevins et al., Reference Nevins, Dillon, Malhotra and Phillips2007). Recall that the rationale behind this proposal is that, when the first element in the dependency is marked/specified for person, feature activation allows the parser to generate a stronger prediction regarding the upcoming verb. When this prediction is unmet, the result is a larger P600. This is in line with current proposals interpreting the P600 as an index of the reanalysis processes triggered by violations of top‑down expectations (e.g., Bornkessel-Schlesewsky & Schlesewsky, Reference Bornkessel-Schlesewsky and Schlesewsky2008; Kuperberg, Reference Kuperberg2007; Tanner et al., Reference Tanner, Grey and van Hell2017; van de Meerendonk et al., Reference van de Meerendonk, Kolk, Vissers and Chwilla2010).Footnote 3
In contrast, our investigation of noun‑adjective number and gender agreement with the same native speakers (Alemán Bañón & Rothman, Reference Alemán Bañón and Rothman2016) failed to provide similar evidence. In that study, we probed agreement with both feminine and masculine nouns (corresponding to the marked/specified and unmarked/underspecified genders, respectively), which could be used in the plural or in the singular (marked/specified vs. unmarked/underspecified number values, respectively) (see an example of a sentence with a feminine singular noun in (4)).
Our results revealed an earlier P600 for number and gender violations realized on marked adjectives (example from the gender conditions: coche que parecía *cara “car‑MASC that looked expensive‑FEM”) relative to the opposite error type (e.g., catedral que parecía *inmenso “cathedral‑FEM that looked huge‑MASC”). In addition, number violations realized on plural adjectives (e.g., coche que parecía *caros “car‑SG that looked expensive‑PL”) yielded a larger P600 than the reverse error type (e.g., coches que parecían *caro “car‑PL that looked expensive‑SG”). In sum, native speakers were sensitive to number/gender markedness (like the Spanish natives under stress in López Prego and Gabriele’s study, 2014 and in line with McCarthy’s predictions for L2ers), but we found no evidence that the marked status of the first element in the dependency (i.e., the noun) facilitated agreement. Possibly, the structure where we examined number/gender agreement was not sufficiently constraining to allow the parser to generate predictions regarding upcoming adjectives because continuations other than an adjective were possible (e.g., una calle que parecía zigzaguear “a street that seemed to zigzag”). The same is not true of the subject‑verb agreement manipulation in (2–3), where the subject made it certain that a verb would appear to satisfy the sentence‑building phrase structure rule (e.g., Chomsky, Reference Chomsky1957, Reference Chomsky1995).
In Alemán Bañón et al. (Reference Alemán Bañón, Miller and Rothman2017), we extended the examination of noun‑adjective number and gender agreement to 22 upper‑intermediate/advanced L1‑English L2‑Spanish learners, and found qualitatively similar results to the native controls. That is, the learners showed a P600 across both types of gender violations, with an earlier onset for gender violations realized on marked/specified (feminine) adjectives. In addition, they elicited a P600 across both number violation types, marginally larger for errors on marked/specified (plural) adjectives. Thus, similar to the native controls, the L2ers were sensitive to the marked status of the adjective, as opposed to the marked status of the noun (i.e., the first element in the dependency). Importantly, this sensitivity was qualitatively nativelike, which does not align with representational accounts of variability.
Herein, we investigate how the same learners resolve subject‑verb person dependencies that differ with respect to markedness (first person: marked/specified as speaker; third person: unmarked/underspecified). We will examine whether learners overuse defaults (i.e., third‑person verbal inflection), as predicted by L2 theories of morphological variability. We will further investigate whether this asymmetry is computational (e.g., Prévost & White, Reference Prévost and White2000) or representational (McCarthy, Reference McCarthy2008). We will do so by examining the learners’ brain responses to the violating verbs (i.e., the point when the dependency is established) and their accuracy with both dependencies in the untimed GJT at the end of each sentence.
We will also examine the extent to which proficiency explains this potential overreliance on default morphology. Recall that, in McCarthy’s study (Reference McCarthy2012), intermediate learners outperformed low‑intermediate learners with first‑person verbs, but not with third‑person verbs, suggesting that marked forms (i.e., first‑person inflection) emerge later in L2 production. We will examine whether a similar asymmetry characterizes L2 comprehension, as predicted by McCarthy. Importantly, proficiency is the most reliable predictor of whether L2ers elicit a P600 for morphosyntactic errors (Caffarra et al., Reference Caffarra, Molinaro, Davidson and Carreiras2015). We will also follow recent claims for the need to dissociate global proficiency from experiential factors, such as amount of L2 instruction and immersion in L2‑speaking countries (Bowden et al., Reference Bowden, Steinhauer, Sanz and Ullman2013; Caffarra et al., Reference Caffarra, Molinaro, Davidson and Carreiras2015; DeLuca et al., Reference DeLuca, Rothman and Pliatsikas2019). A few studies have investigated the relative contribution of these factors to L2 processing, but results remain inconclusive (e.g., Alemán Bañón et al., Reference Alemán Bañón, Fiorentino and Gabriele2018; Faretta‑Stutenberg & Morgan‑Short, Reference Faretta-Stutenberg and Morgan-Short2018).
Alternatively, we will examine whether, similar to the native controls in Alemán Bañón and Rothman (Reference Alemán Bañón and Rothman2019), the marked status of the first element in the dependency eases person agreement resolution in the L2. If so, learners should show increased sensitivity (i.e., a larger P600) to person violations with a first‑person subject (marked/specified). To our knowledge, only López Prego (Reference López Prego2015) has examined this question in L2 comprehension. López Prego used self‑paced reading to examine adjective‑noun gender agreement in Spanish with a design manipulating whether the adjective showed overt gender cues (e.g., nueva “new‑FEM”/verde “green” in 5a) and whether the trigger noun was feminine (5a) or masculine (5b), corresponding to the marked/specified and unmarked/underspecified genders.

Her results showed that both native speakers and advanced English‑speaking learners read the complementizer following the trigger noun (blusa que …) faster when the preceding adjective was feminine (marked/specified), relative to when it was morphologically invariant (nueva vs. verde in 5a), although the effect was marginal in the learners. In contrast, no such facilitation emerged in the comparison of masculine (unmarked/underspecified) versus invariant adjectives (nuevo vs. verde in 5b). López Prego argues that marked features ease agreement resolution at the noun (although in her study facilitation emerged after the noun).
The present study examines whether other markedness‑related properties, such as speech participant status, also facilitate L2 agreement resolution. To our knowledge, only Rossi et al. (Reference Rossi, Gugler, Friederici and Hahne2006) and Tanner et al. (Reference Tanner, McLaughlin, Herschensohn and Osterhout2013) have used ERPs to examine L2 person agreement resolution, and neither study manipulated markedness. Rossi et al.’s bidirectional study found that German‑Italian learners elicited a P600 for “third‑person subject + first/second‑person verb” errors (e.g., Il signore…beve/*bevo “the man drink‑3RD-SG/drink‑1ST-SG”), which was modulated by proficiency. Tanner et al. (Reference Tanner, McLaughlin, Herschensohn and Osterhout2013) found that third‑year L1‑English L2‑German learners elicited a P600 for “first‑person subject + third‑person verb” errors (e.g., Ich wohne/*wohnt in Berlin “I live‑1ST‑SG/live‑3RD‑SG…”), but first‑year students showed a biphasic N400‑P600 pattern, which they argue reflects individual differences with respect to morphosyntactic development. Thus, the question of how person markedness modulates L2 processing remains unexplored. Importantly, as Slabakova (Reference Slabakova, Malovrh and Benati2018) points out, studies examining potential reliance on defaults among intermediate/advanced learners are lacking. Our study fills these gaps.
THE PRESENT STUDY
The present study investigates how markedness modulates subject‑verb person agreement in Spanish, among upper‑intermediate/advanced English‑speaking learners. Our design manipulates both person markedness (first person: marked/specified as speaker; third person: unmarked/underspecified) and agreement. Our research questions “RQ” are:
RQ1. Does markedness impact subject‑verb person agreement resolution in the L2?
McCarthy’s representational account (Reference McCarthy2008, Reference McCarthy2012) predicts reduced sensitivity to “first‑person subject + third‑person verb” errors relative to “third‑person subject + first-person verb” errors across all metrics (accuracy in an untimed GJT, brain responses). This is because the learner’s grammar allows the former error type due to representational issues. Alternatively, it is possible that such an asymmetry will only emerge in the ERP responses time‑locked to the presentation of the verb because the learners’ brain must detect the error exactly when the verb is encountered, whereas the end‑of‑the‑sentence GJT is less time constrained (e.g., Prévost & White, Reference Prévost and White2000).
RQ2. To what extent does L2 proficiency account for a potential overreliance on default morphology?
Proficiency should explain variability with “first‑person subject + third‑person verb” errors across metrics, but not with the opposite error type (McCarthy, Reference McCarthy2012). This is because the former error type involves overusing third‑person inflection (a default), a representational issue that learners are only predicted to overcome at higher levels of proficiency (based on McCarthy, Reference McCarthy2012). Alternatively, it is possible that proficiency and markedness will only interact in the ERP data (e.g., Prévost & White, Reference Prévost and White2000).
RQ3. Do L2 learners use person markedness information to ease agreement resolution?
If so, L2ers should elicit larger ERP responses to “first‑person subject + third‑person verb” errors (similar to the Spanish native speakers in Alemán Bañón and Rothman, Reference Alemán Bañón and Rothman2019) due to the fact that feature activation at the subject (i.e., the first element in the dependency) should facilitate agreement at the verb (e.g., López Prego, Reference López Prego2015; Nevins et al., Reference Nevins, Dillon, Malhotra and Phillips2007).
METHODS
PARTICIPANTS
Twenty‑two L1‑English L2‑Spanish learners (12 females; mean age: 25; SD: 7.5) with a mean age of L2 acquisition of 14 years (range: 8–23) provided their informed written consent to participate in the study. Their Spanish proficiency was monitored with a 50‑item test including the cloze section of the Diploma de Español como Lengua Extranjera and the vocabulary section from the MLA Cooperative Foreign Language Test (e.g., Alemán Bañón et al., Reference Alemán Bañón, Fiorentino and Gabriele2014; McCarthy, Reference McCarthy2008; White et al., Reference White, Valenzuela, Kozlowska Macgregor and Leung2004). Sixteen learners were of advanced proficiency (range: 43–50/50) and six of intermediate proficiency (33–38). Mean duration of Spanish instruction was 7.3 years (SD: 2.7 years; range: .5–12 years) and mean duration of immersion in Spanish‑speaking countries was 15 months (SD: 13 months; range: 0–48 months). Only four learners had lived in L2‑speaking countries for less than eight months. All learners grew up as monolingual speakers of English, with the exception of one heritage speaker of Japanese, a language that does not instantiate subject‑verb person agreement. Twenty of the learners reported knowledge of other foreign languages to varying degrees of proficiency.
A group of 28 native speakers of Spanish reported in Alemán Bañón and Rothman (Reference Alemán Bañón and Rothman2019) served as the control group. All 50 participants met the standard requirements for language‑related ERP studies: right‑handedness (Edinburgh Handedness Questionnaire; Oldfield, Reference Oldfield1971), normal or corrected‑to‑normal vision, and no history of neurological impairments. The testing took place in the United Kingdom and all participants received monetary compensation for their time.
MATERIALS
To examine the contribution of person markedness to agreement, we created 80 sentences with a first‑person singular subject (Table 1: condition 1), which is marked/specified for person (speaker), and 80 sentences with a third‑person singular lexical subject (condition 3), which is unmarked/underspecified for person (the default person). Agreement was manipulated by pairing up first‑person subjects with third‑person verbs (condition 2), and vice versa (condition 4).
Structure of the Sentences
All experimental sentences followed the structure in conditions 1–4. They started with the subject, followed by the adverb a menudo “often,” the verb, and a three‑word continuation that ensured that the verb (i.e., the critical word) was not sentence‑final. The adverb a menudo intervened between the subject and the verb to create linear distance between the agreeing elements. Previous ERP studies argued that comprehenders are more likely to exploit predictive strategies when they have sufficient time for prediction generation (e.g., Ito et al., Reference Ito, Martin and Nieuwland2017; Wlotko & Federmeier, Reference Wlotko and Federmeier2015). Thus, if the L2ers herein can successfully use the subject’s person markedness to ease agreement resolution at the verb, the present setup is suitable to investigate that possibility.
The Subjects of the Sentences
The conditions with a marked/specified subject involved the first‑person singular pronoun yo (conditions 1–2). For theoretical reasons, the conditions with an unmarked/underspecified subject involved third‑person singular lexical determiner phases (DPs) (conditions 3–4). There is disagreement in the literature regarding whether third‑person pronouns are underspecified for person (e.g., Harley & Ritter, Reference Harley and Ritter2002) or carry a nonparticipant person feature (e.g., Nevins, Reference Nevins, Dillon, Malhotra and Phillips2007). However, there is consensus that referential DPs like el maestro “the teacher” carry no person specification (e.g., Bianchi, Reference Bianchi2006; Den Dikken, Reference Den Dikken2011; Nevins, Reference Nevins2011). Because the present study is concerned with whether the parser can better establish person agreement when the subject carries person information, relative to when it does not, we opted for lexical DPs as unmarked/underspecified subjects. Because the Spanish verb also encodes number, all subjects were used in the singular (unmarked/underspecified for number). Two measures were taken to match the two markedness conditions as much as possible. First, we submitted the sentences with lexical DP subjects, truncated at the adverb a menudo, to a cloze probability rating (e.g., la artista a menudo…) to rule out the possibility that participants could predict the target verbs based on the lexical features of the subjects. This rating, which involved 33 Spanish native speakers who did not participate in the ERP study reported in Alemán Bañón and Rothman (Reference Alemán Bañón and Rothman2019), revealed that mean cloze probability was very low (mean cloze: .03; SD: .1), suggesting that the target verbs were, overall, not predictable. In addition, we added 80 fillers using other (nominative case) personal pronouns in coordinated structures with ellipsis (see Table 1). In 40 of those fillers, the pronouns were used in contrastive focus. The use of other person pronouns was expected to attenuate the salience of pronoun yo in the experiment. Likewise, the use of contrastive focus and ellipsis was expected to improve the naturalness of overt pronouns in the sentences, given that Spanish is a null‑subject language.
TABLE 1. Sample stimuli, including the conditions examining person agreement with first‑person and third‑person subjects (grammatical, ungrammatical), and the fillers

The Target Verbs
We used the same verbs in the conditions with first‑ and third‑person subjects. Thus, at the verb (i.e., the critical word) the two markedness conditions only differed with respect to the subject. Verbs inflected for first‑ and third‑person singular were controlled with respect to number of characters (mean length of third‑person verbs: 6.56; SD = 1.61; 95% CI [6.20, 6.92]; first‑person verbs: 6.57; SD = 1.65; 95% CI [6.21, 6.94]; t(79) = .445, p = .658; ηp2 = .003). However, third‑person verbs were significantly more frequent than first‑person ones (EsPal database; Duchon et al., Reference Duchon, Perea, Sebastián Gallés, Martí and Carreiras2013). Being underspecified for person, third‑person verbs emerge in more syntactic contexts than first‑person verbs, which results in the former being more frequent. Finally, the critical verbs were always located midsentence.
These 160 sentences were intermixed with 240 sentences from Alemán Bañón et al. (Reference Alemán Bañón, Miller and Rothman2017), a study that does not manipulate subject‑verb agreement. These materials were counterbalanced across 12 lists. Across lists, all sentences occurred in their grammatical and ungrammatical versions, but no participant saw the same sentence twice. Each participant saw two different lists, administered on separate days. Each list contained an equal number of items per condition. After combining the two lists, each participant saw 80 sentences with a first‑person subject (40 ungrammatical) and 80 sentences with a third‑person subject (40 ungrammatical). They also saw 20 items from each of the 12 conditions in Alemán Bañón et al. (Reference Alemán Bañón, Miller and Rothman2017) (80 grammatical, 80 number violations, 80 gender violations) and 80 grammatical fillers. The ratio of grammatical to ungrammatical sentences was 1/1. In total, participants saw 480 sentences across the two sessions. All materials associated with this study are published in Alemán Bañón and Rothman (Reference Alemán Bañón and Rothman2019). All materials from the study on number/gender agreement are published in Alemán Bañón and Rothman (Reference Alemán Bañón and Rothman2016).Footnote 4
PROCEDURE
The testing involved two EEG recordings, each including 240 sentences (with an equal number of items per condition, including the fillers). We used the software Paradigm (Perception Research Systems Inc.; Tagliaferri, Reference Tagliaferri2005) for sentence presentation. Participants were instructed to read the sentences silently, without blinking, and to decide whether each was grammatical or ungrammatical in Spanish (e.g., Rossi et al., Reference Rossi, Gugler, Friederici and Hahne2006; Tanner et al., Reference Tanner, McLaughlin, Herschensohn and Osterhout2013). They were asked to favor accuracy over speed. Each EEG recording included eight practice sentences. Four of them were ungrammatical, but none involved agreement violations or nouns/verbs from the experimental materials. Feedback was provided for the first three practice trials. The experiment began upon completion of the practice. Each recording was divided into six 40‑sentence blocks, separated by five short breaks. Each EEG recording lasted approximately 1 hour.
Trial Structure
First, a fixation cross was displayed in the center of the screen for 500 ms. Then, the presentation of the sentence began, one word at a time. Each word was displayed for 450 ms, followed by a 300 ms blank (e.g., Alemán Bañón et al., Reference Alemán Bañón, Fiorentino and Gabriele2012, Reference Alemán Bañón, Fiorentino and Gabriele2014; see Molinaro et al., Reference Molinaro, Barber and Carreiras2011). At the end of the sentence came a 1,000 ms pause. Participants then saw the words Bien “good” or Mal “bad” on the screen and decided if the sentence was grammatical or ungrammatical by pressing a button (middle and index fingers of the left hand, respectively). The prompts remained on the screen until the participant provided a response. Upon the button press, an intertrial interval was added ranging between 500–1,000 ms, pseudorandomly varied at 50 ms increments.
EEG RECORDING AND ANALYSIS
We used Brain Vision Recorder (Brain Products, GmbH, Germany) to record the continuous EEG from 64 sintered Ag/AgCl electrodes attached to an elastic cap (Easycap, Brain Products, GmbH, Germany). The electrodes were placed following the 10% system (midline: FPz, Fz, FCz, Cz, CPz, Pz, POz, Oz; hemispheres: FP1/2, AF3/4, AF7/8, F1/2, F3/4, F5/6, F7/8, FC1/2, FC3/4, FC5/6, FT7/8, FT9/10, C1/2, C3/4, C5/6, T7/8, CP1/2, CP3/4, CP5/6, TP7/8, TP9/10, P1/2, P3/4, P5/6, P7/8, PO3/4, PO7/8, O1/2) and referenced online to FCz (with AFz as ground). We used electrodes FP1/2 (above the eyebrows) to monitor blinks, and electrode IO (on the outer canthus of the right eye) to monitor horizontal eye movements. All electrode impedances were kept below 10 kΩ. The recordings were amplified with an online bandpass filter of .016–250 Hz (with a 12dB/octave rolloff) by a BrainAmp MR Plus amplifier (Brain Products, GmbH, Germany), and digitized at a sampling rate of 1 kHz.
We used Brain Vision Analyzer 2.0 (Brain Products, GmbH, Germany) for offline data processing. First, we re-referenced the recordings to the average of near‑mastoid electrodes (TP7/8).Footnote 5 We then segmented the EEG into epochs from −300 ms to 1,200 ms relative to the verb. Upon visual inspection, we rejected trials with blinks, horizontal eye movements, excessive alpha waves, or excessive muscle movement. We then discarded trials with incorrect behavioral responses. Finally, the epochs were baseline‑corrected relative to the 300 ms prestimulus baseline, averaged per condition and per subject, and filtered with a phase‑shift free Infinite Impulse Response Butterworth filter, with a high cutoff of 30 Hz and a 12 dB/octave rolloff.
Rejection of trials with artifacts or incorrect behavioral responses resulted in approximately 16% of data loss. The mean number of good trials per condition ranged between 33–35/40 (Condition 1: 35; Condition 2: 33; Condition 3: 34; Condition 4: 33). A repeated‑measures ANOVA revealed that we had retained fewer trials associated with person violations than with grammatical sentences overall, F(1, 21) = 4.450, p = .047 (we discarded incorrectly judged trials, and learners were marginally less accurate rejecting person errors overall in the GJT). As Luck (Reference Luck2014, supplement, chapter 8, pp. 4–5) points out, different numbers of trials per condition is not problematic when analyzing mean amplitudes. Most importantly, this difference does not affect the examination of the Markedness by Agreement interaction because we retained a comparable number of trials for each error type.
We quantified ERPs using mean amplitudes between 250–450 ms and 450–900m, corresponding to the LAN/N400 and the P600, respectively (based on Alemán Bañón et al., Reference Alemán Bañón, Miller and Rothman2017). We used nine regions of interest (ROI) for statistical analysis, each calculated by averaging across the mean amplitudes of all electrodes in the region (Left Anterior: F1, F3, F5, FC1, FC3, FC5; Right Anterior: F2, F4, F6, FC2, FC4, FC6; Left Medial: C1, C3, C5, CP1, CP3, CP5 Right Medial: C2, C4, C6, CP2, CP4, CP6; Left Posterior: P1, P3, P5, P7, PO3, PO7; Right Posterior: P2, P4, P6, P8, PO4, PO8; Midline Anterior: Fz, FCz; Midline Medial: Cz, CPz; Midline Posterior: Pz, POz).
Statistical Analysis
To evaluate RQ1 and RQ3, mean amplitudes were submitted to a repeated‑measures ANOVA with Markedness (first‑person subject, third‑person subject), Agreement (grammatical, ungrammatical), Anterior‑Posterior (anterior, medial, posterior), and Hemisphere (left, right) as the within‑subjects factors. The hemisphere and midline regions were analyzed separately. For the analyses in the midline, the only topographical factor in the ANOVA was Anterior‑Posterior. Because the Markedness by Agreement interaction is critical for our discussion, whenever this interaction was qualified by a topographical factor, follow‑up analyses were conducted by examining the Markedness by Agreement interaction separately within the relevant ROIs. The Geisser and Greenhouse correction was applied for sphericity violations (we report corrected degrees of freedom; Field, Reference Field2005). To evaluate RQ2, we ran a series of multiple regressions with repeated measures (detailed in the following text). These analyses allowed us to examine how the linear relationship between proficiency measures (score in standardized Spanish proficiency test, amount of L2 instruction, immersion in L2‑speaking countries) and measures of sensitivity to agreement (P600 magnitude, D‑prime) varied for each level of the repeated factor (person error type) (Schneider et al., Reference Schneider, Avivi-Reich and Mindaugas2015).
A False Discovery Rate correction (Benjamini & Hochberg, Reference Benjamini and Hochberg1995) was applied to all follow‑up tests, to control for Type I error. For all follow‑up tests, we provide both the raw p value and the adjusted significance level (q*). We consider effects where p is below .05 as significant and effects where p is between .05 and .1 as marginal.
RESULTS
BEHAVIORAL
The percentage of accurate responses in the GJT is provided in Table 2 for all experimental conditions. For each person dependency type, the rightmost column of the table provides D‑Prime Scores (i.e., a single measure of sensitivity to each person dependency type that controls for response bias). The learners were very accurate across the board (above 90% across conditions), suggesting that they understood the task and were able to complete it. A repeated‑measures ANOVA with Markedness (first‑person subject, third-person subject) and Agreement (grammatical, ungrammatical) as the repeated factors revealed a marginal main effect of Agreement, F(1, 21) = 3.641, p = .07; ηp2 = .148, driven by the fact that learners were less accurate rejecting ungrammatical sentences overall (M = 92; SD = 11; 95% CI [87, 97]) than accepting grammatical ones (M = 96; SD = 5; 95% CI [93, 98]).
TABLE 2. Learners’ mean accuracy rates in the GJT (N = 22) for the conditions examining person agreement with first‑person (marked/specified) and third‑person (unmarked/underspecified) subjects

Note. Standard deviations are provided between parentheses. D‑prime scores are provided in the rightmost column.
ERP EFFECTS
Both types of person errors yielded more positive waveforms than their grammatical counterparts (Figures 1–2). This positivity starts ~450 ms upon presentation of the violating verb, does not go back to baseline by the end of the epoch (1,200 ms), and shows a central‑posterior distribution. Overall, this is consistent with the P600. The positivity appears less robust for “first‑person subject + third‑person verb” errors, as can be seen in Figure 3, which shows the magnitude of the effects. In the same time window where the P600 emerged (~450 ms until the end of the epoch), violations yielded more negative waveforms than their grammatical counterparts in Left Anterior. This negativity appears equally robust for both error types.
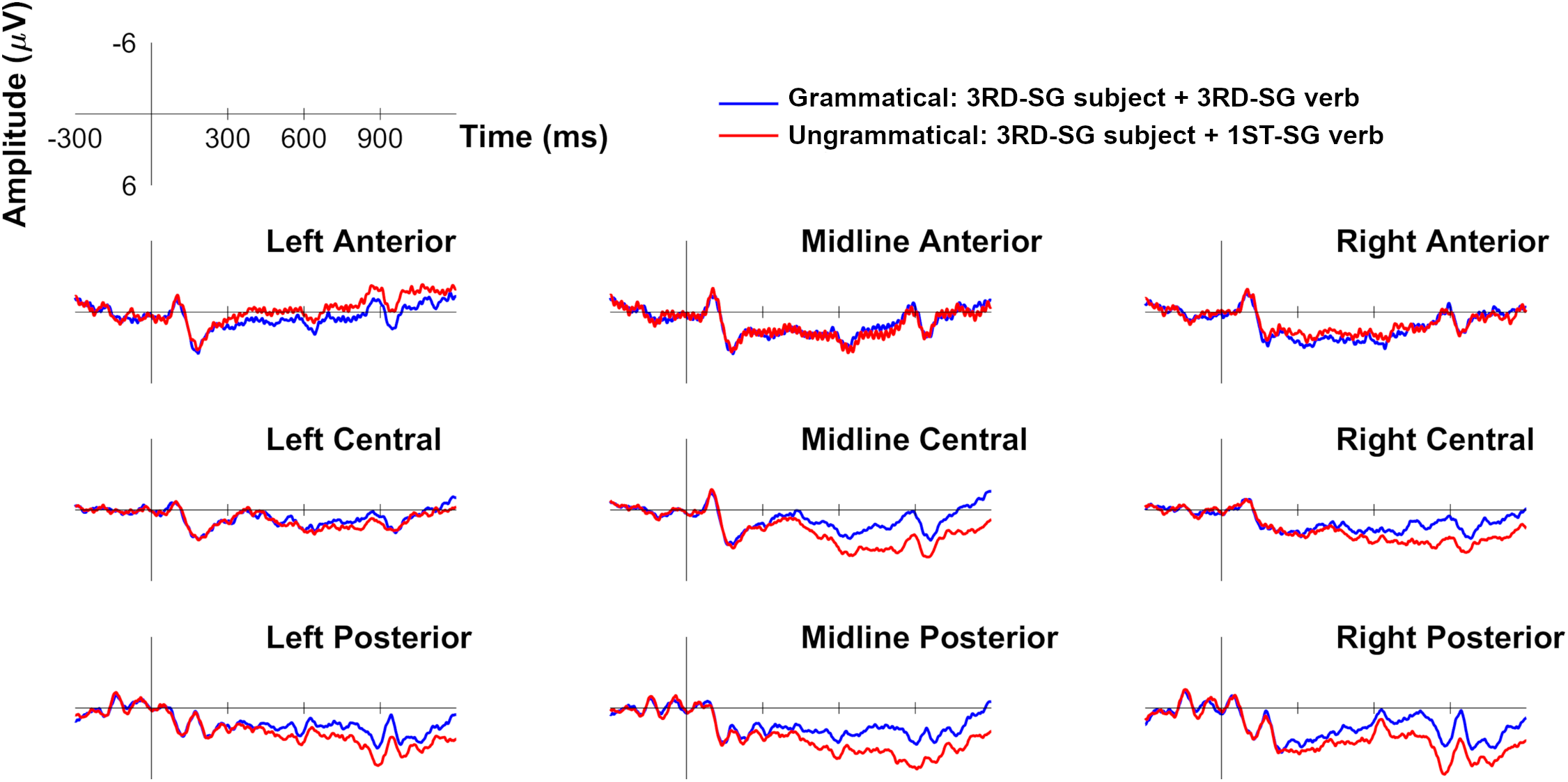
FIGURE 1. Grand average ERP waveforms for the conditions examining person agreement with third‑person (unmarked/underspecified) subjects: third‑person subject + third‑person verb (grammatical) and third‑person subject + first‑person verb (ungrammatical).

FIGURE 2. Grand average ERP waveforms for the conditions examining person agreement with first‑person (marked/specified) subjects: first‑person subject + first‑person verb (grammatical) and first‑person subject + third‑person verb (ungrammatical).

FIGURE 3. Topographic plots for “third‑person subject + first‑person verb” violations and for “first‑person subject + third‑person verb” violations in the 450–900 ms time window.
Note. Plots were computed by subtracting the grammatical sentence from the violation condition. First and third person correspond to marked/specified and unmarked/underspecified values, respectively.
250–450 ms Time Window (LAN/N400)
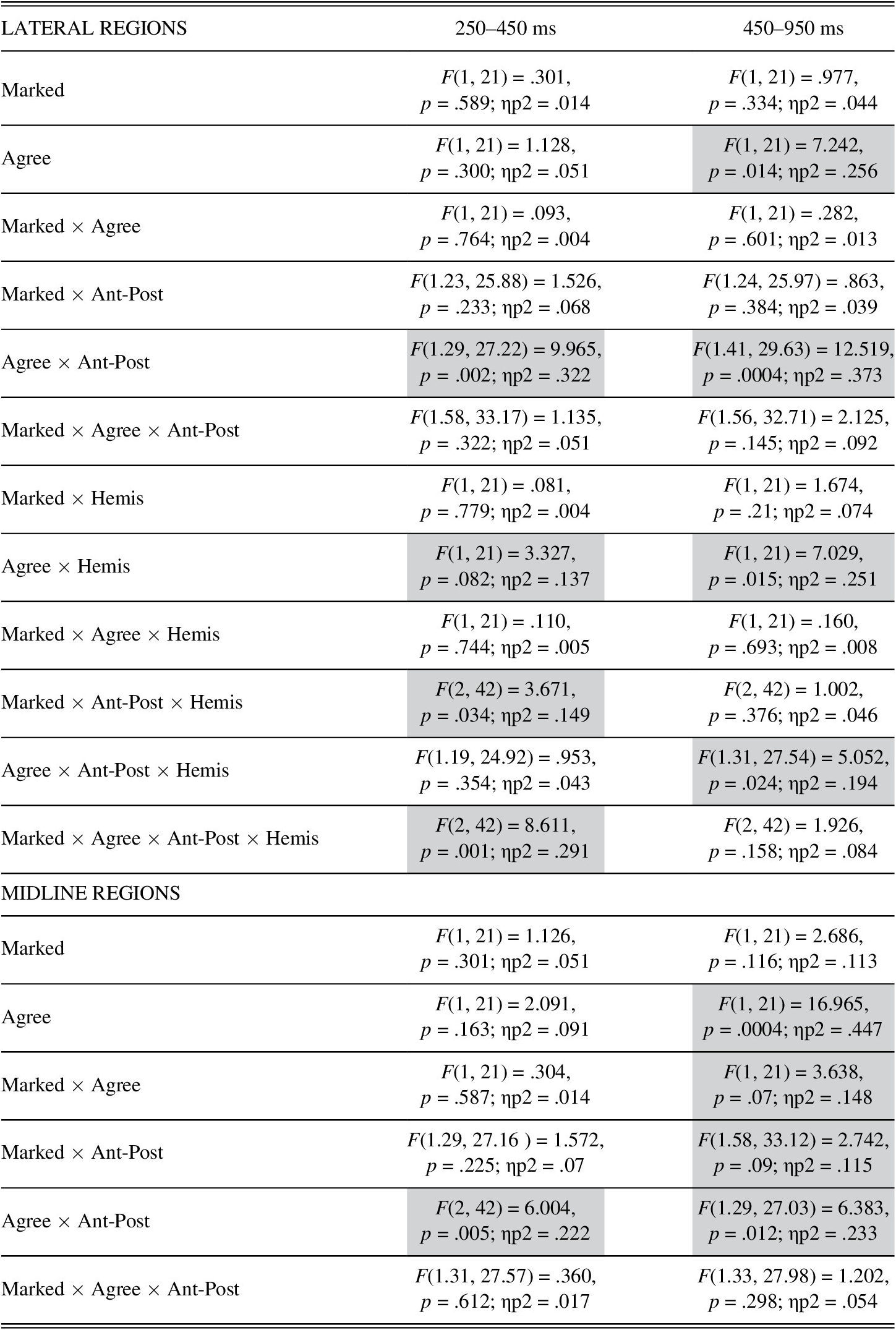
Table 3 (middle column) summarizes the results of the omnibus ANOVA in the 250–450 ms time window. In the hemispheres, the Markedness by Agreement by Anterior-Posterior by Hemisphere interaction was significant. As a follow‑up, we examined the Markedness by Agreement interaction within each ROI, but no significant interactions emerged in any ROI.
TABLE 3. Results of the omnibus ANOVA in the 250–450 ms and 450–900 ms time windows
Marked: Markedness; Agree: Agreement; Ant‑Post: Anterior‑Posterior; Hemis: Hemisphere
Note. Significant/marginal effects are shaded.
In the hemispheres, the omnibus ANOVA also revealed a significant Agreement by Anterior‑Posterior interaction (Table 3). Therefore, we examined the main effect of Agreement within each level of Anterior‑Posterior. The main effect of Agreement was only significant in Posterior, F(1, 21) = 10.748, p = .004, q* = .017; ηp2 = .339, driven by the fact that person violations overall yielded more positive waveforms (M = 1.85 μV; SD = 2.11; 95% CI [.92, 2.79]) than grammatical sentences (M = 1.41 μV; SD = 2.27; 95% CI [.40, 2.42]). The omnibus ANOVA also revealed a marginal Agreement by Hemisphere interaction, but follow‑up tests revealed no effects of Agreement in either hemisphere. Finally, follow‑up tests to the Markedness by Anterior‑Posterior by Hemisphere interaction revealed no effects of Markedness in any ROI.
In the midline, the omnibus ANOVA revealed a significant Agreement by Anterior‑Posterior interaction (Table 3). Follow‑up tests revealed a main effect of Agreement in Midline Posterior, F(1, 21) = 9.376, p = .006, q* = .017; ηp2 = .309, driven by the fact that person violations overall were more positive (M = 2.23 μV; SD = 2.50; 95% CI [1.13, 3.34]) than grammatical sentences (M = 1.67 μV; SD = 2.58; 95% CI [.53, 2.81]).
To summarize, the analyses conducted between 250–450 ms revealed no reliable LAN or N400 effects for either person violation type (see Figures 1–2). These analyses do reveal that, by 450 ms, the P600 has already emerged for person errors overall.
450–900 ms Time Window (P600)
Table 3 (right column) summarizes the results of the omnibus ANOVA between 450–900 ms. In the hemispheres, the Agreement by Hemisphere by Anterior‑Posterior interaction was significant. Follow‑up tests revealed that the main effect of Agreement was significant in Right Posterior, F(1, 21) = 13.590, p = .001, q* = .006, ηp2 = .393; Left Posterior, F(1, 21) = 12.988, p = .002, q* = .011, ηp2 = .382; Right Medial, F(1, 21) = 10.972, p = .003, q* = .017, ηp2 = .343; and Left Medial, F(1, 21) = 6.796, p = .016, q* = .027, ηp2 = .244. In all central‑posterior regions, person violations overall elicited more positive waveforms than grammatical sentences (Right Posterior, violation: M = 1.45 μV; SD = 1.66; 95% CI [.71, 2.18]; grammatical: M = .70 μV; SD = 1.63; 95% CI [–.02, 1.43]; Left Posterior, violation: M = 1.06 μV; SD = 2.10; 95% CI [.13, 1.99]; grammatical: M = .40 μV; SD = 1.82; 95% CI [–.40, 1.21]; Right Medial, violation: M = 2.45 μV; SD = 1.61; 95% CI [1.73, 3.17]; grammatical: M = 1.70 μV; SD = 1.57; 95% CI [1.01, 2.39]; Left Medial, violation: M = 1.70 μV; SD = 1.61; 95% CI [.99, 2.42]; grammatical: M = 1.34 μV; SD = 1.70; 95% CI [.58, 2.09]). In Left Anterior, the main effect of Agreement was also significant, F(1, 21) = 9.021, p = .007, q* = .022, ηp2 = .30, but here person violations overall were more negative (M = .21 μV; SD = 1.93; 95% CI [–.64, 1.07]) than grammatical sentences (M = .73 μV; SD = 1.62; 95% CI [.01, 1.45]), which partly explains the three‑way interaction.
In the midline, the omnibus ANOVA revealed a marginal Markedness by Agreement interaction (p = .07) (Table 3). Because this effect is critical to our discussion, we followed up on it by examining the main effect of Agreement within each level of Markedness. The interaction was driven by the fact that “third‑person subject + first‑person verb” errors yielded more positive waveforms (M = 2.84 μV; SD = 2.11; 95% CI [1.91, 3.78]) than grammatical sentences (M = 1.54 μV; SD = 1.86; 95% CI [.71, 2.36]), a difference that was significant, F(1, 21) = 13.691, p = .001, q* = .025, ηp2 = .395. For the reverse error type, violations were also more positive (M = 2.73 μV; SD = 1.79; 95% CI [1.94, 3.53]) than grammatical sentences (M = 2.51 μV; SD = 2.00; 95% CI [1.36, 3.14]), but this difference was only marginal, F(1, 21) = 3.687, p = .069, q* = .05, ηp2 = .149. This is visible in Figure 3.
In the midline, the omnibus ANOVA also revealed a significant main effect of Agreement, which was qualified by an interaction with Anterior‑Posterior (see Table 3). Follow‑up tests showed a main effect of Agreement in Midline Posterior, F(1, 21) = 19.939, p = .0002, q* = .017, ηp2 = .487 (violation: M = 3.24 μV; SD = 1.62; 95% CI [2.52, 3.95]; grammatical: M = 1.99 μV; SD = 1.97; 95% CI [1.11, 2.86]) and Midline Medial, F(1, 21) = 16.368, p = .001, q* = .033, ηp2 = .438 (violation: M = 3.08 μV; SD = 2.28; 95% CI [2.07, 4.09]; grammatical: M = 2.02 μV; SD = 2.47; 95% CI [.93, 3.12]).
To summarize, person violations overall yielded a P600 with a central‑posterior distribution. Importantly, the P600 was reduced for “first‑person subject + third‑person verb” violations (in the midline), although the interaction remained marginal. In this time window, a negativity emerged across person violations relative to grammatical sentences in Left Anterior. The P600 was already apparent in the preceding time window (250–450 ms).
REGRESSION ANALYSIS
P600 Magnitude
We used multiple regression with repeated measures to examine whether overreliance on defaults (reduced sensitivity to “first‑person subject + third‑person verb” errors) was accounted for by variables related to the learners’ proficiency in and experience with their L2. The dependent variable was P600 magnitude, corresponding to the mean amplitude between 450–900 ms in the ungrammatical minus the grammatical condition in a ROI including all regions where the P600 emerged (Left Medial, Right Medial, Left Posterior, Right Posterior, Midline Medial, and Midline Posterior). P600 magnitude was calculated separately for each person violation type. The two error types correspond to the two levels of the within‑subjects predictor, Error_Type. The between‑subjects predictors were Global_Proficiency (score in a standardized Spanish proficiency test), Instruction (years of instruction in L2 Spanish), and Months_Abroad (months spent in a Spanish‑speaking country). Table 4 shows all zero‑order correlations between the variables of interest.
TABLE 4. Zero‑order correlations between the learners’ (N = 22) overall proficiency in and experience with the L2 (Global_Proficiency, Instruction, Months_Abroad) and measures of sensitivity to person agreement (D‑prime_Score, P600_Magnitude)

Global_Proficiency: Score in standardized Spanish proficiency test;
Instruction: Years of instruction in L2 Spanish;
Months_Abroad: Months spent in Spanish‑speaking countries.
Note. Significant correlations are shaded.
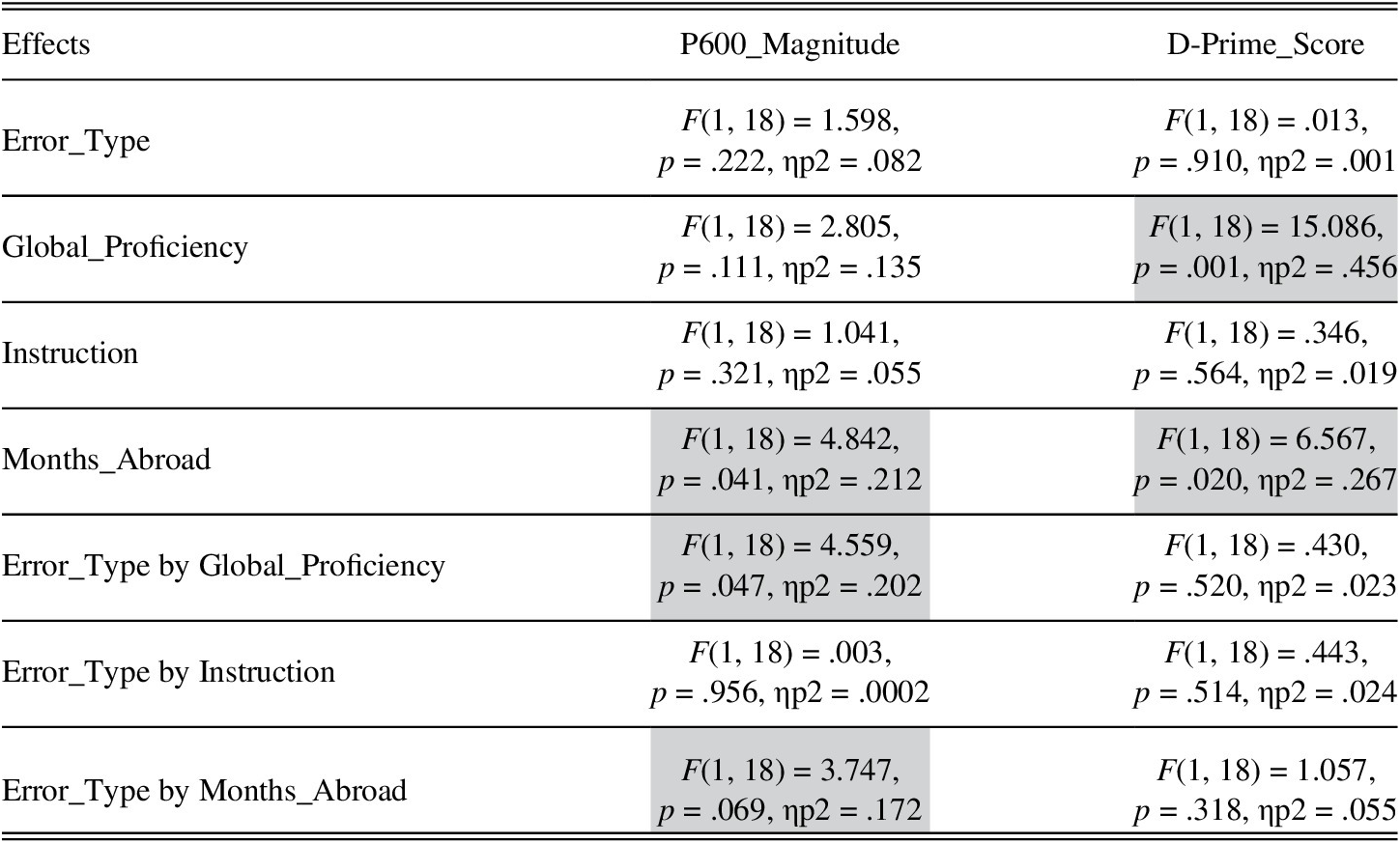
The assumptions of multiple regression (evaluated using the residuals) were met. Table 5 summarizes the results of the regression. The significant Global_Proficiency by Error_Type interaction was driven by the fact that Global_Proficiency significantly predicted P600 magnitude for “first‑person subject + third‑person verb” violations, t(18) = 2.84, p = .011, q* = .017, ηp2 = .309, an instance of overreliance on defaults, but not for the reverse error (Figure 4, Plots A–B). Examination of the unstandardized regression coefficient suggests that a one standard deviation increase in Global_Proficiency (i.e., a 5‑point score increase in the proficiency test) results in an estimated .57 μV increase in P600 magnitude (95% CI [.15, .98]) for “first‑person subject + third‑person verb” errors. Notice also that a few learners have negative values, consistent with the possibility that their sensitivity to the errors was qualitatively different. Thus, the positive value of the regression coefficient suggests development toward increasingly nativelike processing for “first‑person subject + third‑person verb” errors, both qualitatively and quantitatively.
TABLE 5. Results of the multiple regression analysis examining the relationship between the learners’ proficiency in and experience with the L2 (Global_Proficiency, Instruction, Months_Abroad) and measures of sensitivity to person agreement (P600_Magnitude, D‑Prime_Score)
Global_Proficiency: Score in standardized Spanish proficiency test;
Instruction: Years of instruction in L2 Spanish;
Months_Abroad: Months spent in Spanish‑speaking countries;
Error_Type: Person violation type.
Note. Significant/marginal effects are shaded.
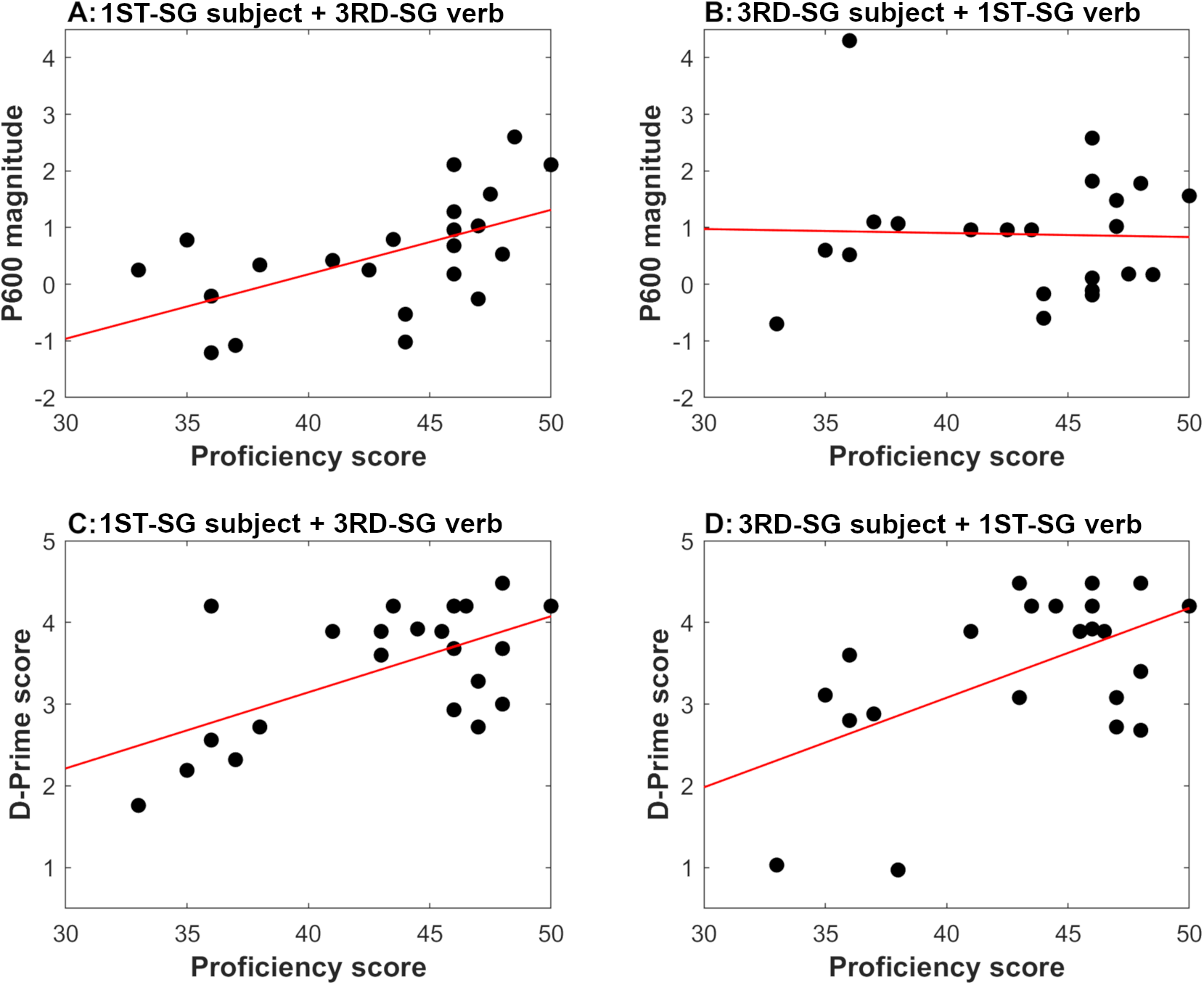
FIGURE 4. Scatterplots showing the relation between the learners’ global proficiency (score in a standardized Spanish proficiency test) and their sensitivity to person agreement both in terms of P600 magnitude (Plots A and B) and in terms of behavioral accuracy (Plots C and D).
Note. P600 effect size was calculated by subtracting the grammatical from the ungrammatical condition. Effects were averaged across all regions where P600 effects emerged for both types of person errors. Behavioral accuracy was operationalized as D-prime Score for each type of person dependency in the GJT. Each dot represents a data point from a single learner. The dashed line represents the best-fit regression line. Minimal jitter has been added to make learners with identical or near identical values visible. Marked subject = first-person; Unmarked subject = third-person.
The main effect of Months_Abroad was also significant, driven by the fact that P600 magnitude overall tended to be larger for learners with longer immersion time. The estimated increase in P600 magnitude for every one standard deviation increase in Months_Abroad (i.e., a 13-month increase in immersion time) was .37 μV (95% CI [.02, .73]). However, this effect was qualified by a marginal interaction with Error_Type (Table 5). As Plots A and B of Figure 5 reveal, this interaction was driven by the fact that Months_Abroad predicted P600 magnitude for “third‑person subject + first‑person verb” errors, t(18) = 2.782, p = .012, q* = .017, ηp2 = .301 (estimated increase in P600 magnitude for every one standard deviation increase in Months_Abroad = .68 μV; 95% CI [.17, 1.19]), but not for the other error.

FIGURE 5. Scatterplots showing the relation between the learners’ immersion time (number of months spent in Spanish-speaking countries) and their sensitivity to person agreement both in terms of P600 magnitude (Plots A and B) and in terms of behavioral accuracy (Plots C and D).
Note. P600 effect size was calculated by subtracting the grammatical from the ungrammatical condition. Effects were averaged across all regions where P600 effects emerged for both types of person errors. Behavioral accuracy was operationalized as D‑prime Score for each type of person dependency in the GJT. Each dot represents a data point from a single learner. The dashed line represents the best‑fit regression line. Minimal jitter has been added to make learners with identical or near identical values visible. Marked subject = first‑person; Unmarked subject = third-person.
D‑Prime Scores
A similar approach was undertaken to examine the relationship between the learners’ behavioral sensitivity to person agreement and their proficiency in and experience with L2 Spanish. The dependent variable was D‑Prime Score. All other aspects of the analysis were held constant. Zero‑order correlations and a summary of the effects are provided in Tables 4 and 5, respectively. The assumptions of multiple regression were met. The main effect of Global_Proficiency was significant, with more proficient L2ers showing higher D‑Prime scores overall (Figure 4, Plots C–D). The estimated increase in D‑Prime_Score for every one standard deviation increase in Global_Proficiency (i.e., a 5‑point score increase in the proficiency test) was .52 (95% CI [.24, .80]). The main effect of Months_Abroad was also significant. Learners with longer immersion time showed lower D‑Prime scores (i.e., lower accuracy) (Figure 5, Plots C–D). The estimated decrease in D‑Prime_Score for every one standard deviation increase in Months_Abroad (i.e., a 13‑month increase in immersion time) was −.38 (95% CI [−.68, −.07]). We come back to this surprising finding in the “Discussion” section.
DISCUSSION
The present study investigated the role of markedness in the processing of subject‑verb person agreement in Spanish by upper‑intermediate/advanced English‑speaking learners. Recall that our main aim was to adjudicate between different proposals regarding how markedness impacts L2 agreement resolution. L2 theoretical models posit that learners overuse default morphology (e.g., third‑person verbal inflection) in contexts that require marked/specified forms (e.g., first‑person subjects) due either to computational pressure (Prévost & White, Reference Prévost and White2000) or to the asymmetrical representation of features in the learner’s grammar (e.g., McCarthy, Reference McCarthy2008, Reference McCarthy2012). Alternative proposals from the psycholinguistics literature suggest that marked features remain longer in the focus of attention and, thus, facilitate agreement operations, for example, by recruiting top‑down mechanisms to resolve agreement (Nevins et al., Reference Nevins, Dillon, Malhotra and Phillips2007; Wagers & McElree, Reference Wagers and McElree2011; see López Prego, Reference López Prego2015). Under the latter proposal, feature activation upon encountering a marked/specified feature (e.g., a first‑person subject) allows the parser to better resolve agreement.
To that end, we probed subject‑verb person agreement with both first‑person (marked/specified as speaker) and third‑person (unmarked/underspecified) subjects (e.g., Bianchi, Reference Bianchi2006; Den Dikken, Reference Den Dikken2011; Harley & Ritter, Reference Harley and Ritter2002; Harris, Reference Harris and Campos1995; Jakobson, Reference Jakobson and Jakobson1971; McGinnis, Reference McGinnis2005; Nevins, Reference Nevins2011). By crossing each subject type with verbs inflected for the opposite person, we created two error types for which the previously mentioned proposals make different predictions. The learners’ brain responses revealed reduced sensitivity (i.e., a reduced P600) to “first‑person subject + third‑person verb” errors, relative to the opposite error type, although this effect remained marginal in the ANOVA. Recall however that, in the regression analyses, Proficiency interacted with Error_Type (i.e., P600 magnitude as a function of error type). This analysis showed that the reduced sensitivity to “first‑person subject + third‑person verb” errors characterized the less proficient learners in the sample. These data suggest that, in the course of online processing, learners tolerated unmarked/underspecified forms (third‑person inflection) in contexts that required marked/specified ones (first‑person subject), mainly at intermediate levels of proficiency. Importantly, the fact that no asymmetry emerged in the end‑of‑the‑sentence GJT, for which learners took as much time as they needed, indicates that such overreliance on defaults most likely results from computational burden (e.g., Alemán Bañón et al., Reference Alemán Bañón, Miller and Rothman2017; Hopp, Reference Hopp2010; López Prego & Gabriele, Reference López Prego and Gabriele2014; McDonald, Reference McDonald2006; Prévost & White, Reference Prévost and White2000). That is, while the learners’ brain might not have detected “first‑person subject + third‑person verb” errors exactly at the time when the violating verb was presented, it is possible that the learners detected the agreement error by the time they provided the grammaticality judgment. The learners also elicited a Late Anterior Negativity (similar to the native speakers) across both error types. This component has been argued to reflect the costs associated with keeping the violations in working memory for the GJT (e.g., Alemán Bañón et al., Reference Alemán Bañón, Fiorentino and Gabriele2012; Gillon‑Dowens et al., Reference Gillon-Dowens, Vergara, Barber and Carreiras2010; Sabourin & Stowe, Reference Sabourin and Stowe2004). This might explain why this component was unimpacted by markedness because the learners were equally accurate detecting both error types.
Recall that the same learners were sensitive to markedness asymmetries in the processing of noun‑adjective number and gender agreement (Alemán Bañón et al., Reference Alemán Bañón, Miller and Rothman2017). In that study, number violations on plural adjectives (marked for number) yielded a marginally larger P600 than number errors on singular adjectives. In addition, the P600 emerged earlier for gender errors realized on feminine (marked for gender) relative to masculine adjectives. Crucially, similar effects emerged in the L1‑Spanish controls (Alemán Bañón & Rothman, Reference Alemán Bañón and Rothman2016), suggesting that the learners’ processing profile was qualitatively nativelike, at least for noun‑adjective number/gender. The overall picture that emerges from these studies is that learners are sensitive to markedness asymmetries at the point when the agreement dependency is resolved (the adjective for noun‑adjective agreement; the verb for subject‑verb agreement), and that such sensitivity can also characterize native speaker processing (e.g., Alemán Bañón & Rothman, Reference Alemán Bañón and Rothman2016; López Prego & Gabriele, Reference López Prego and Gabriele2014).Footnote 6
We also asked whether learners eventually abandon their reliance on default morphology with development. Our regression analysis suggests so. As Figure 4 shows, more proficient learners showed larger P600 effects for “first‑person subject + third‑person verb” violations (Plot A), but not for “third‑person subject + first‑person verb” errors (Plot B). One possibility is that, at the upper‑intermediate level of proficiency (i.e., the lower bound of the proficiency range examined herein), the learners’ grammar still allows first‑person subjects with third‑person inflection, which still functions as a sort of all‑purpose form. However, the learners’ grammar already rules out “third‑person subject + first‑person verb” configurations. This aligns with McCarthy’s analysis (2012) of corpus production data, which showed that less proficient learners supplied third‑person verbs with first‑person subjects, but rarely did the reverse. Plots A–B from Figure 4 reveal that P600 effects were larger for “third‑person subject + first‑person verb” errors overall (Plot B). Twelve learners show a P600 of approximately 1 μV or larger for this error type, and these learners are scattered across the proficiency spectrum examined. In contrast, fewer learners (seven) show P600 effects of approximately similar size for “first‑person subject + third‑person verb” violations (Plot A), and all of them scored in the upper range of the advanced level. In addition, although we see negative effects for both error types, negativities tend to be larger for “first‑person subject + third‑person verb” errors, and the largest negativities for this error type are associated with learners near the lower end of the proficiency range examined. It is thus possible that lower proficiency learners rely on qualitatively different processing mechanisms for harder dependencies (e.g., Carrasco‑Ortiz et al., Reference Carrasco-Ortiz, Velázquez Herrera, Jackson-Maldonado, Avecilla Ramírez, Silva Pereyra and Wicha2017; Osterhout et al., Reference Osterhout, McLaughlin, Pitkänen, Frenck-Mestre and Molinaro2006; Tanner et al., Reference Tanner, Inoue and Osterhout2014) although the small number of negative responders in our sample precludes strong conclusions. That global proficiency interacted with error type in the ERP data is consistent with the claim we made in Alemán Bañón et al. (Reference Alemán Bañón, Miller and Rothman2017) that markedness impacts L2 processing without constraining it. Overreliance on default forms (i.e., reduced sensitivity to “first‑person subject + third‑person verb” errors) might characterize the intermediate levels of proficiency, but is progressively abandoned at higher ones.
Figure 4 (Plots C–D) shows that higher proficiency learners also tended to show higher D‑Prime scores for both person violation types, providing additional evidence for development (but not markedness) (e.g., Alemán Bañón et al., Reference Alemán Bañón, Fiorentino and Gabriele2018). The reader might wonder why global proficiency interacted with markedness in the ERP data, but not in the D‑Prime data. The two metrics probably tap into different types of sensitivity. While P600 magnitude is a measure of brain sensitivity to person dependencies exactly at the time when they are established, D‑Prime scores provide a measure of sensitivity to the same dependencies once the learner has read the whole sentence. That D‑Prime scores and P600 magnitude did not significantly correlate for either type of person dependency is consistent with this possibility (see Table 4). It is thus conceivable that proficiency modulated both types of sensitivity differently. Given what is required of a judgment task (i.e., detecting the ungrammaticality, maintaining decisions about grammaticality in working memory until the end of the sentence, wrapping up sentence meaning), a lower level of proficiency might have impacted accuracy with both types of person dependencies.
Therefore, the response to RQ1 and RQ2 (Does markedness impact subject‑verb person agreement resolution in the L2? To what extent does L2 proficiency account for a potential overreliance on default morphology?) is that L2 processing is not constrained by markedness, but is sensitive to it, particularly among less advanced learners. Because markedness did not impact the learners’ accuracy while judging the sentences at a later point and with no time pressure, sensitivity to markedness is more likely to be computational.
We now turn to the question of why these learners, who were qualitatively nativelike with noun‑adjective number and gender agreement, showed a qualitatively different processing profile from native speakers for subject‑verb person agreement.Footnote 7 One possibility is that, although the learners could successfully resolve person agreement at the verb, the markedness of the subject (i.e., the first element in the dependency) did not facilitate agreement. The question of whether L2 learners can use linguistic cues to facilitate integration of the bottom‑up input has played a central role in recent L2 processing research (see Kaan, Reference Kaan2014 for a review). While some studies have argued that L2 learners, even advanced ones, fail to use lexical, morphosyntactic, syntactic, or discourse cues predictively (e.g., Grüter et al., Reference Grüter, Lew-Williams and Fernald2012, Reference Grüter, Rohde and Schafer2017; Kaan et al., Reference Kaan, Kirkham and Wijnen2016; Martin et al., Reference Martin, Thierry, Kuipers, Boutonnet, Foucart and Costa2013), others have claimed that predictive processing is similar in the L1 and L2 (e.g., Kaan, Reference Kaan2014), but is modulated by proficiency (e.g., Dussias et al., Reference Dussias, Valdés Kroff, Guzzardo Tamargo and Gerfen2013), the strength of lexical representations (e.g., Hopp, Reference Hopp2013), L1‑L2 similarity (e.g., Foucart et al., Reference Foucart, Martin, Moreno and Costa2014; Hopp & Lemmerth, Reference Hopp and Lemmerth2018), and individual differences in cognitive factors (e.g., Hopp, Reference Hopp2013). It is still unclear, however, which cues learners can use predictively and which linguistic representations they can activate because most of the evidence supporting prediction in the L2 comes from studies manipulating overt gender cues (Dussias et al., Reference Dussias, Valdés Kroff, Guzzardo Tamargo and Gerfen2013; Foucart et al., Reference Foucart, Martin, Moreno and Costa2014; Hopp, Reference Hopp2013; López Prego, Reference López Prego2015). Thus, it is possible that, unlike gender cues, speech participant status was insufficient to facilitate agreement at the verb. So, the answer to RQ3 (Do L2 learners use person markedness information to ease agreement resolution?) is preliminarily “no,” based on the evidence provided herein.
It could be argued that the larger P600 for “third‑person subject + first‑person verb” errors does not reflect sensitivity to markedness, but rather facilitation from L1 English, which instantiates agreement with third‑person singular subjects (e.g., Jiang, Reference Jiang2004, Reference Jiang2007; Lardiere, Reference Lardiere2009; Tokowicz & MacWhinney, Reference Tokowicz and MacWhinney2005). First, we point out that using plural subjects would not have worked because third‑person plural DPs in Spanish agree with first‑ and second‑person plural verbs, a process called unagreement (e.g., Las viudas lloramos/lloráis “[we/you‑2ND‑PL] the widows cry‑1ST-PL/cry-2ND-PL”) (e.g., Höhn, Reference Höhn2016; Hurtado, Reference Hurtado, King and Maley1985), and previous work by Mancini et al. (Reference Mancini, Molinaro, Rizzi and Carreiras2011, Reference Mancini, Massol, Duñabeitia, Carreiras and Molinaro2019) has shown that native speakers treat these sentences differently from outright person violations (i.e., they do not elicit a P600). Most importantly, while previous ERP studies manipulating L1‑L2 similarity have consistently shown an advantage for L2 features instantiated in the L1 (e.g., Alemán Bañón et al., Reference Alemán Bañón, Fiorentino and Gabriele2014; Bond et al., Reference Bond, Gabriele, Fiorentino, Alemán Bañón, Tanner and Herschensohn2011; Gabriele et al., Reference Gabriele, Alemán Bañón, Hoffman, Covey, Rossomondo and Fiorentinoin press; Gillon‑Dowens et al., Reference Gillon-Dowens, Vergara, Barber and Carreiras2010, Reference Gillon-Dowens, Guo, Guo, Barber and Carreiras2011) they have consistently found no advantage for shared morphological instantiations of common features (e.g., Alemán Bañón et al., Reference Alemán Bañón, Fiorentino and Gabriele2014; Bond et al., Reference Bond, Gabriele, Fiorentino, Alemán Bañón, Tanner and Herschensohn2011; Gabriele et al., Reference Gabriele, Alemán Bañón, Hoffman, Covey, Rossomondo and Fiorentinoin press). For example, Bond et al. (Reference Bond, Gabriele, Fiorentino, Alemán Bañón, Tanner and Herschensohn2011) and Gabriele et al. (Reference Gabriele, Alemán Bañón, Hoffman, Covey, Rossomondo and Fiorentinoin press) examined L1‑English L2‑Spanish learners’ brain responses to subject‑verb number agreement with third‑person singular subjects (instantiated in English) and noun‑adjective number agreement (unique to Spanish), and found no facilitation for the former. Other studies have even found a disadvantage for contexts where the L1 overtly marks agreement. For example, Alemán Bañón et al. (Reference Alemán Bañón, Fiorentino and Gabriele2014) examined demonstrative‑noun and noun‑adjective number agreement in Spanish (e.g., este apartamento/*apartamentos “this apartment/apartments”; órgano muy complejo/*complejos “organ‑SG very complex‑SG/complex‑PL”) among advanced English‑speaking learners. Crucially, English instantiates number on demonstratives, but not on adjectives. Their results showed a larger P600 for number violations on adjectives, an effect that can be explained by markedness (i.e., este was unmarked, but complejos was marked) or differences in syntactic category, but crucially not by transfer (e.g., Tokowicz & MacWhinney, Reference Tokowicz and MacWhinney2005). Thus, it is unlikely that the effects herein reflect L1 facilitation, especially because the same learners showed enhanced sensitivity to gender errors realized on marked adjectives (Alemán Bañón et al., Reference Alemán Bañón, Miller and Rothman2017), an effect that cannot come from the L1.
Before concluding, we address the role of immersion in L2 morphosyntactic development, which showed inconsistency across measures. While Plot B of Figure 5 suggests that longer immersion results in greater brain sensitivity to “third‑person subject + first-person verb” errors, Plots C–D reveal lower D‑Prime scores (i.e., less sensitivity) to both error types for learners with similar immersion time. We can think of no reason why immersion in an L2‑speaking environment would result in poorer ability to resolve any type of morphosyntactic dependency. Importantly, immersion represents an indirect measure of proficiency. Learners with longer immersion time are assumed to have benefited from richer input, alongside increased opportunities for output. In turn, this is expected to promote morphosyntactic development. However, this might simply not be the case. In fact, previous studies on morphosyntactic development do not consistently report advantages for learners in study‑abroad programs relative to “at home” learners (Faretta‑Stutenberg & Morgan‑Short, Reference Faretta-Stutenberg and Morgan-Short2018, p. 5). In our study, the two learners with the longest immersion time (48 and 36 months, respectively) had mainly lived in English‑speaking communities and they both scored in the intermediate range in the standardized test (38 and 36, respectively). Both of them showed D‑Prime scores roughly one or two standard deviations below the mean. Likewise, one of the learners with the highest D‑Prime scores (approximately one standard deviation above the mean) had never resided in Spanish‑speaking countries. However, this learner had lived immersed in a Spanish‑speaking community for two years in the United States and benefited from native speaker input. It is, therefore, possible that, being an indirect measure of proficiency, immersion time is a noisier predictor of grammatical development. Another possibility is that there was not sufficient variability in the sample for reliable relations to emerge because half of the learners had an immersion time of ~10 months.
CONCLUSION
The present study found that a group of 22 L1‑English L2‑Spanish learners showed brain sensitivity (i.e., a P600) across two types of subject‑verb person dependencies that differed with respect to markedness. The learners were marginally less sensitive to violations where the subject corresponded to a marked/specified person (first person: speaker) and the verb was unmarked/underspecified for person (third person), suggesting some overreliance on default morphology (i.e., third‑person inflection). Markedness did not impact the learners’ ability to detect the same violations in an end‑of‑the‑sentence GJT, for which no time constraints were imposed, suggesting that overreliance on defaults is computational. Regression analyses showed that L2ers gradually abandon this overreliance on defaults with increased proficiency. Finally, unlike what we found in the Spanish controls (Alemán Bañón & Rothman, Reference Alemán Bañón and Rothman2019), the speech participant status of the subject (i.e., speaker vs. the default person) did not ease agreement resolution among learners.











 Open access
Open access