


Most large prospective cohorts use an FFQ to measure dietary intake. It is well known that an FFQ has substantial measurement error that can affect the results of such studies, leading to bias and the loss of power to detect diet–disease relationships(Reference Freudenheim and Marshall1, Reference Freedman, Schatzkin and Wax2). In order to evaluate the measurement error in an FFQ, and to correct observed diet–disease relationships for bias due to measurement error, many cohort studies include calibration sub-studies in which another, less biased, dietary instrument is administered as a reference instrument. The reference instrument is usually a short-term instrument such as a 24 h dietary recall (24HR) or food record.
Methods for evaluating an FFQ's ability to measure foods/nutrients that are consumed daily have been developed based on measurement error models that explicitly or implicitly assume that true usual intake and reported intake from the FFQ and reference instrument are all continuous variables(Reference Beaton, Milner and Corey3–Reference Freedman, Carroll and Wax5). These methods have sometimes been used to evaluate ‘episodically consumed’ foods, or foods that are not consumed nearly every day by almost everyone in the population(Reference Feskanich, Rimm and Giovannucci6–Reference Millen, Midthune and Thompson8). This can be problematic if the reference instrument covers only a short time period, since short-term instruments may have a substantial proportion of subjects reporting zero intake of an episodically consumed food, violating the assumption that the reported intake is continuous.
Recently, a measurement error model for episodically consumed foods has been developed and used in dietary surveillance to estimate population distributions of usual intakes of such foods(Reference Tooze, Midthune and Dodd9–Reference Marriott, Olsho and Hadden11) and to correct for measurement error in diet–health relationships when the 24HR is the main dietary instrument(Reference Kipnis, Midthune and Buckman12). The model allows for non-consumption on a given day by separating the probability to consume from the amount consumed on a consumption day using a two-part model(Reference Tooze, Midthune and Dodd9). The model has also been extended to a ‘three-part’ model to estimate the joint distribution of intakes of an episodically consumed food and energy(Reference Freedman, Guenther and Krebs-Smith10). In the present paper, we use these models to evaluate an FFQ's ability to measure intake of episodically consumed foods when the reference instrument measures short-term intake. After fitting a model that describes the relationship between the short-term reference and the FFQ, we use Monte Carlo methods to estimate the relationship between true and FFQ-reported intakes.
In 1995, the National Institutes of Health (NIH) and the AARP, formerly the American Association of Retired Persons, initiated a large prospective cohort study called the NIH–AARP Diet and Health Study, which was designed to study relationships between diet and cancer. The study uses an FFQ to measure diet and includes a calibration sub-study of about 2000 subjects who in addition to the FFQ were administered two 24HR. Thompson et al.(Reference Thompson, Kipnis and Midthune13) evaluated the ability of the NIH–AARP FFQ to measure nutrient intake. In the present paper we assess the FFQ's ability to measure intakes of twenty-nine food groups.
Methods
Study design
The design of the NIH–AARP Diet and Health Study is described in detail elsewhere(Reference Schatzkin, Subar and Thompson14). Briefly, a baseline questionnaire that included a 124-item FFQ was mailed to 3·5 million members of AARP in 1995–1996. A total of 617 119 men and women returned the questionnaire, and, after excluding some whose questionnaires were deemed to be of poor quality or who declined to participate, a cohort of 567 169 subjects was established. Age at baseline in the cohort ranged from 50 to 71 years.
Calibration sub-study participants were selected from the 46 970 subjects who had returned questionnaires as of January 1996. Subjects in the sub-study were asked to complete two non-consecutive unannounced 24HR administered over the telephone by trained interviewers. Of the 2795 individuals invited to participate in the sub-study, 2055 agreed and completed at least one 24HR (97 % completed both). The two 24HR were separated in time, with 50 % separated by at least 21 days and 75 % separated by at least 14 days. In our analysis, we include 1942 subjects (984 men, 958 women) after excluding 113 subjects who subsequently dropped out of the cohort study, had pre-baseline reports of cancer or death-only reports of cancer.
Study instruments
The FFQ used in the NIH–AARP study was an early version of the Diet History Questionnaire (DHQ) developed at the National Cancer Institute (NCI)(15). Frequency responses were asked for 124 food items; portion sizes for 116. An additional twenty-one questions asked about specific food choices and cooking practices. Databases from the US Department of Agriculture's (USDA) Continuing Survey of Food Intakes of Individuals (CSFII) (1989–91, 1994–96) were used to develop a nutrient composition database for the FFQ(Reference Subar, Midthune and Kulldorff16). The MyPyramid Equivalents Database (MPED) version 1·0, developed by USDA(Reference Friday and Bowman17), was used to obtain food group intakes in MPED servings consistent with 2005 Dietary Guidelines for Americans(18). The MPED disaggregates components of food mixtures into food groups (e.g. pepperoni pizza components are placed into grain, dairy, vegetable and meat food groups).
In the 24HR interviews, participants were asked to report all foods and beverages consumed on the day before the interview. Interviewers used a food probe list containing standardized probes specific to foods in over 100 food categories. Data were coded using the Food Intake Analysis System (FIAS) version 2·3, developed at the University of Texas; the same nutrient composition database is used for both FIAS and USDA's CSFII. Data checks were performed on reports with extremely high values for fat, total energy and total fruit and vegetable intakes, and corrections were made when extreme values were due to coding errors.
Statistical analysis
We evaluate the FFQ in terms of its ability to detect diet–disease relationships in observational studies. Two important parameters for characterizing this ability are the correlation of true and FFQ-reported intakes and the attenuation factor. The correlation of true and FFQ-reported intakes is a measure of the statistical power to detect diet–disease relationships, while the attenuation factor for FFQ-reported intake is a measure of the bias in estimated relationships. Both parameters are functions of the joint distribution of true and FFQ-reported intakes. Although one cannot observe true usual intake in free-living populations, one can estimate its distribution and its relationship to the FFQ-reported intake using statistical models and appropriate reference instruments.
Statistical model for episodically consumed foods
The model for episodically consumed foods is described in detail in Kipnis et al.(Reference Kipnis, Midthune and Buckman12), who use the model to correct for measurement error when 24HR is the main dietary instrument. In the present application, FFQ is the main instrument and 24HR is used as a reference instrument.
For individual i, i = 1,…,n, let
Tij be the true intake of an episodically consumed food on day j
pi = P(Tij > 0|i) be the true probability to consume on a given day
![]() be the true average amount consumed on a consumption day
be the true average amount consumed on a consumption day
![]() be the true usual intake of the episodically consumed food
be the true usual intake of the episodically consumed food
Rij be the 24HR-reported intake of the episodically consumed food on day j
Qi be the FFQ-reported intake of the episodically consumed food.
We assume that an individual's 24HR-reported intake Rij is an unbiased estimate of true usual intake Ti. In particular, we assume that the probability to report consumption is equal to the true probability to consume, pi, and that the average reported amount on a consumption day is equal to the true average amount consumed on a consumption day, Ai. Then the mean of Rij equals pi × Ai = Ti. We note that this is a strong assumption that may not be exactly true, although it is generally believed that a 24HR is less biased than an FFQ (see Discussion section for more on this).
We also assume that, after appropriate transformations, the relationship between the FFQ-reported intake and the probability to consume can be described by a logistic regression model and that the relationship between the FFQ-reported intake and the amount consumed on a consumption day can be described by a linear regression model. The resulting two-part model can be written as:
and
where β k 0 and β k 1 are the intercept and slope in the logistic or linear regression; U 1i and U 2i are person-specific random effects that have a bivariate normal distribution with mean zero, variances ![]() and
and ![]() , and correlation
, and correlation ![]() ; and
; and ![]() is within-person random error that is normally distributed with mean zero and variance
is within-person random error that is normally distributed with mean zero and variance ![]() ; and
; and ![]() is independent of (U 1i, U 2i). We include random effects U 1i and U 2i to allow for individual variations in probability and amount that are not explained by the FFQ. Variables
is independent of (U 1i, U 2i). We include random effects U 1i and U 2i to allow for individual variations in probability and amount that are not explained by the FFQ. Variables ![]() and
and ![]() are Box–Cox transformations of Qi and Rij to scales on which they are approximately normal(Reference Box and Cox19) (see Appendix 1 for details).
are Box–Cox transformations of Qi and Rij to scales on which they are approximately normal(Reference Box and Cox19) (see Appendix 1 for details).
Equations (1) and (2) define a non-linear mixed-effects model that can be fit using the NLMIXED procedure in SAS to obtain maximum likelihood estimates of the model parameters β 10, β 11, β 20, β 21, ![]() ,
, ![]() ,
, ![]() and
and ![]() . For foods that are consumed every day, the model simplifies to:
. For foods that are consumed every day, the model simplifies to:
Under the model assumptions, true usual intake Ti can be written as a function of Qi, U 1i and U 2i (or U 3i), and one can estimate relationships between true and FFQ-reported intakes by generating a Monte Carlo distribution of Ti and Qi (see Appendix 2 for details).
Note that under the model for episodically consumed foods, intake on a given day (Tij and Rij) can be zero, but usual intake (Ti) is assumed to be greater than zero (although it can be arbitrarily small). There may be foods which some people never consume (e.g. alcohol). Kipnis et al.(Reference Kipnis, Midthune and Buckman12) describe an extension of the present model that allows Ti to be zero; with only two 24HR per person, however, it is difficult in practice to distinguish never consumers from infrequent consumers.
A SAS macro that calls the NLMIXED procedure to fit the model for episodically consumed foods (equations (1) and (2)) or foods consumed every day (equation (3)) is available online(20). Prior to fitting the model, we removed outliers of ![]() and positive
and positive ![]() for each food group, where outliers were defined to be values that fell below the 25th percentile of the distribution of the variable minus two interquartile ranges or above the 75th percentile plus two interquartile ranges. The average number of outliers removed for
for each food group, where outliers were defined to be values that fell below the 25th percentile of the distribution of the variable minus two interquartile ranges or above the 75th percentile plus two interquartile ranges. The average number of outliers removed for ![]() was 2 (men) and 4 (women), and the average number removed for
was 2 (men) and 4 (women), and the average number removed for ![]() was 4 (men) and 3 (women).
was 4 (men) and 3 (women).
Correlation with true intake and attenuation factor
The attenuation factor and correlation with true intake are measures of the bias and loss of power in diet–disease studies due to measurement error in the FFQ. We assume that measurement error is non-differential with respect to disease; that is, that reported intake Qi contributes no additional information about disease risk beyond that provided by true intake Ti. Suppose the true diet–disease relationship follows a logistic model:
where ri is the probability of disease given true usual intake Ti, α 0 and α 1 are the intercept and slope in the logistic regression, and ![]() is a Box–Cox transformation of Ti to a scale on which it is approximately normal. The logistic regression model does not require covariates to have any particular distribution. In practice, however, covariates with skewed distributions are often transformed to make extreme values less influential.
is a Box–Cox transformation of Ti to a scale on which it is approximately normal. The logistic regression model does not require covariates to have any particular distribution. In practice, however, covariates with skewed distributions are often transformed to make extreme values less influential.
We want to estimate the bias in the estimation of log odds ratio α 1 caused by using reported intake ![]() rather than
rather than ![]() in equation (4). Since
in equation (4). Since ![]() and
and ![]() are transformed using different Box–Cox transformations, the interpretation of α 1 depends on which variable is in the model. In order to make the interpretations comparable, we first standardize the transformed variables so that a unit change equals the change from the 10th to the 90th percentile of true intake Ti on that scale. We can then interpret α 1 as the log odds ratio comparing the 90th and 10th percentiles of true intake.
are transformed using different Box–Cox transformations, the interpretation of α 1 depends on which variable is in the model. In order to make the interpretations comparable, we first standardize the transformed variables so that a unit change equals the change from the 10th to the 90th percentile of true intake Ti on that scale. We can then interpret α 1 as the log odds ratio comparing the 90th and 10th percentiles of true intake.
To a close approximation, fitting equation (4) using ![]() rather than
rather than ![]() leads to estimating not the true risk parameter α 1 but the product
leads to estimating not the true risk parameter α 1 but the product ![]() , where γ 1 is the slope in the linear regression of
, where γ 1 is the slope in the linear regression of ![]() v.
v. ![]() (Reference Kipnis, Midthune and Freedman21). The value γ 1 is called the attenuation factor and is interpreted as the multiplicative bias in estimating log odds ratio α 1 due to measurement error in Qi.
(Reference Kipnis, Midthune and Freedman21). The value γ 1 is called the attenuation factor and is interpreted as the multiplicative bias in estimating log odds ratio α 1 due to measurement error in Qi.
The loss of statistical power due to using ![]() rather than
rather than ![]() in equation (4) is related to the correlation between
in equation (4) is related to the correlation between ![]() and
and ![]() , which we will call ρTQ. If a study would need a sample size of n to attain a desired power using
, which we will call ρTQ. If a study would need a sample size of n to attain a desired power using ![]() to measure intake, then the study would need a sample size of
to measure intake, then the study would need a sample size of ![]() to attain the same power using
to attain the same power using ![]() (Reference Kaaks, Riboli and van Staveren22). For both the correlation with true intake and the attenuation factor, one represents the ideal value. A correlation of one means no loss of power, while an attenuation factor of one means no bias in estimated risk. In a univariate diet–disease model, the attenuation factor is usually between zero and one, indicating that the estimated log odds ratio is biased towards zero, or attenuated.
(Reference Kaaks, Riboli and van Staveren22). For both the correlation with true intake and the attenuation factor, one represents the ideal value. A correlation of one means no loss of power, while an attenuation factor of one means no bias in estimated risk. In a univariate diet–disease model, the attenuation factor is usually between zero and one, indicating that the estimated log odds ratio is biased towards zero, or attenuated.
One can estimate γ 1 and ρTQ by generating a Monte Carlo distribution of ![]() and
and ![]() , based on the models described in the previous section. Under the model assumptions, the Monte Carlo distribution will be approximately the same as the distribution in the real population, so that estimates based on the Monte Carlo distribution will be approximately unbiased (see Appendix 2 for details).
, based on the models described in the previous section. Under the model assumptions, the Monte Carlo distribution will be approximately the same as the distribution in the real population, so that estimates based on the Monte Carlo distribution will be approximately unbiased (see Appendix 2 for details).
Energy-adjusted intake
Researchers are often interested in ‘energy-adjusted’ diet–disease relationships; that is, relationships between food intake and disease when total energy intake is held constant(Reference Willett, Howe and Kushi23). One popular energy-adjustment method is the ‘residual’ method, in which one first calculates the residual in the regression of food v. energy intake (after transforming both to approximate normality) and then relates residual intake to disease(Reference Willett, Howe and Kushi23). For simplicity, we refer to residual intake as ‘energy-adjusted’ intake.
To evaluate FFQ-reported energy-adjusted intake, we fit the three-part food and energy model described in Freedman et al.(Reference Freedman, Guenther and Krebs-Smith10) and generate Monte Carlo distributions of true and FFQ-reported food and energy intakes. We then calculate true and reported residual intakes from the Monte Carlo distributions and use them to estimate the correlation with truth and the attenuation factor for residual intake (see Appendix 3 for details).
Results
Table 1 shows the percentage of subjects in the calibration sub-study having zero intake on the 24HR or FFQ for thirty-two food groups. The food groups range from those that are rarely consumed to those that are consumed almost every day. For example, 98 % of men and women reported zero intake of organ meat on both 24HR, while 99 % reported non-zero intake of total grains on both 24HR.
Table 1 Percentage of subjects having zero intakes of MPED food groups on 24HR or FFQ; NIH–AARP Diet and Health Study

MPED, MyPyramid Equivalents Database; 24HR, 24 h dietary recall; NIH, National Institutes of Health.
*Percentages for the 24HR are based on the 953 men and 926 women who completed two 24HR.
Table 2 presents sample means for reported intakes of the thirty-two food groups. The means include both zero and non-zero amounts. In men, FFQ-reported intake tended be less than 24HR-reported intake, while in women it tended to be greater. For men, the FFQ mean was at least 20 % smaller than the 24HR mean for twelve food groups, and at least 20 % larger for six food groups. For women, the FFQ mean was at least 20 % smaller than the 24HR mean for five food groups, and at least 20 % larger for ten food groups.
Table 2 Mean reported MPED food group intakes on 24HR and FFQ, with standard errors; NIH–AARP Diet and Health Study

MPED, MyPyramid Equivalents Database; 24HR, 24 h dietary recall; NIH, National Institutes of Health.
*Means for the 24HR are based on the 953 men and 926 women who completed two 24HR.
†FFQ mean at least 20 % smaller than 24HR mean.
‡FFQ mean at least 20 % larger than 24HR mean.
Table 3 presents estimated correlations of true and FFQ-reported intakes and attenuation factors for twenty-nine food groups. Three food groups (yoghurt, organ meat, soya) are not included because they are too rarely consumed to obtain stable estimates. Results are presented for both unadjusted and energy-adjusted (residual) intakes. For the five most commonly consumed food groups (non-whole grains, total grains, total vegetables, added sugars, discretionary fat (solid)), estimates were obtained using the method for foods consumed every day, described in the Methods section. For the rest of the food groups, estimates were obtained using the method for episodically consumed foods. After energy adjustment, most food groups had correlations with true intake greater than 0·5; the food groups with lowest correlations after energy adjustment were legumes (0·34 for women), potatoes (0·35 for women), discretionary fat (oil) (0·38 for women, 0·43 for men) and low omega fish (0·42 for men). Attenuation factors were generally greater than 0·4, although several food groups had lower values; the food groups with lowest attenuation factors after energy adjustment were discretionary fat (oil) (0·18 for women), potatoes (0·23 for women), legumes (0·28 for women) and other starchy vegetables (0·29 for women).
Table 3 Estimates of the correlation of true and FFQ-reported food intakes (ρQT) and the attenuation factor (λ) for FFQ-reported food intake, with standard errors; NIH–AARP Diet and Health Study

NIH, National Institutes of Health; MPED, MyPyramid Equivalents Database.
*For Other starchy vegetables in men, the measurement error model failed to converge.
Table 4 shows the number of incident cancers in the NIH–AARP cohort by gender and cancer type during the follow-up period, 1995 to 2003(Reference George, Mayne and Leitzmann24). Table 4 also shows for each cancer type the study's power to detect an odds ratio of 1·5 using FFQ-reported intake if ρTQ = 1 (no loss of power due to measurement error) and if ρTQ = 0·5. The odds ratio compares the 90th to 10th percentile of true intake in a univariate diet–disease model (see Appendix 4 for details). For common cancer types such as prostate, breast, lung and colorectal, the power to detect the association is at least 85 % when ρTQ = 0·5. For less common types such as myeloid leukaemia, thyroid and liver, the power is less than 30 %.
Table 4 Number of incident cancers in the NIH–AARP Diet and Health Study 1995–2003; power to detect an odds ratio of 1·5Footnote * using FFQ-reported intake if the correlation of true and FFQ-reported intakes ρTQ = 1 and if ρTQ = 0·5

* Odds ratio comparing the 90th to 10th percentile of true intake in a univariate diet–disease model.
Discussion
We have proposed a methodology to evaluate an FFQ's ability to measure intake of episodically consumed foods and used it to evaluate the FFQ in the NIH–AARP Diet and Health study. The methodology uses a two-part model designed for such foods(Reference Tooze, Midthune and Dodd9, Reference Kipnis, Midthune and Buckman12) and Monte Carlo methods to estimate the relationship between true and FFQ-reported intakes. In order to evaluate energy-adjusted intake of such foods, we use a three-part food and energy model(Reference Freedman, Guenther and Krebs-Smith10).
The model for episodically consumed foods is designed for studies in which the reference instrument covers only a short time period and the probability of zero intake is substantial. In the NIH–AARP study, the reference instrument is the repeat application of a single 24HR. Some other studies use as reference the average of many (up to 28) days of 24HR or food records(Reference Salvini, Hunter and Sampson25–Reference Shu, Yang and Jin27). In such studies, simpler measurement error models may be used. Such studies tend to be small (fewer than 200 subjects), however, and it is generally considered that study designs with more subjects and fewer days per subject are more efficient(Reference Rosner and Willett28, Reference Kaaks, Riboli and van Staveren29).
In epidemiological studies, the most important characteristics in determining the utility of an FFQ are the correlation of true and FFQ-reported intakes and the attenuation factor. We estimated these characteristics for twenty-nine food groups in the NIH–AARP calibration sub-study. After energy adjustment, correlations of true and FFQ-reported intakes were estimated to be 0·5 or greater, and attenuation factors 0·4 or greater, for most of the food groups, including some that are of particular interest to nutritional epidemiologists, such as whole grains, total fruit, total vegetables, red meat and alcoholic beverages.
A limitation of our analysis (and of most FFQ validation studies) is our reliance on 24HR (or similar self-report instrument) as a reference instrument. We have assumed that the 24HR provides unbiased estimates of food group intake. Recent studies using biomarkers as references, however, have shown that the 24HR is biased for energy, protein and energy-adjusted protein intake, and that these biases sometimes, but not always, lead to overestimation of correlations with true intake and attenuation factors when the 24HR is used as a reference instrument(Reference Kipnis, Midthune and Freedman21, Reference Kipnis, Subar and Midthune30). While no such biomarkers are presently known for any food groups, it is not unreasonable to expect similar biases for at least some food groups. To the extent that this is so, our estimates of the correlations with true intake and attenuation factors could be biased and may overestimate the true parameters.
The two-part model used in the current analysis has been validated by computer simulations(Reference Tooze, Midthune and Dodd9). In addition, graphical methods have been developed to assess the model's goodness-of-fit to specific data(Reference Kipnis, Midthune and Buckman12). A comparison of Tables 1 and 3 indicates that the precision of the estimated correlations and attenuation factors is related to the frequency with which a food is consumed. The standard errors of the estimated correlations and attenuation factors for less frequently consumed food groups, such as legumes, fish and other starchy vegetables, tend to be larger than those for more frequently consumed food groups such as milk, whole grains and red meat, and, as we saw with other starchy vegetables in men, there is a possibility that the measurement error model will fail to converge if the food group is infrequently consumed. This is because there is less information about the amount consumed on consumption days when there are fewer consumption days in the data. In particular, if there are only a few subjects who have non-zero consumption on multiple days, then it is difficult to separate between- and within-person error (i.e. difficult to estimate the variances of U 2i and ε 2ij). To estimate infrequently consumed foods with more precision, it would be necessary to have a larger calibration sub-study.
A number of studies have validated FFQ for intakes of foods or food groups in American adults, including those described by Salvini et al.(Reference Salvini, Hunter and Sampson25), Flagg et al.(Reference Flagg, Coates and Calle7) and Millen et al.(Reference Millen, Midthune and Thompson8). Direct comparison with these studies is complicated by the fact that the food groups validated were generally not the same as in the present study and were not measured in MPED servings. Further, some studies, such as Salvini et al.(Reference Salvini, Hunter and Sampson25), used food records rather than 24HR as reference instrument. To the extent that comparisons can be made, results of the present study are generally similar to the earlier studies. For example, Salvini et al.(Reference Salvini, Hunter and Sampson25) reported energy-adjusted correlations for intake of fish, eggs (men) and tomatoes that were similar to those in Table 3, although the correlation for egg intake in women was somewhat higher in their study (0·77 compared to 0·55). Flagg et al.(Reference Flagg, Coates and Calle7) reported energy-adjusted correlations for total grains, total vegetables and red meat that were similar to those in the present study.
The study most comparable to ours is an analysis of the Eating at America's Table Study (EATS) reported by Millen et al .(Reference Millen, Midthune and Thompson8). In that analysis, the NCI's DHQ was validated for food groups derived from the USDA Pyramid Servings Database(Reference Cook and Friday31), a database that is similar to MPED but based on earlier dietary guidelines. The DHQ is a later version of the FFQ used in the NIH–AARP study. In general, energy-adjusted correlations in EATS and the present study are similar, although there are some differences. For example, energy-adjusted correlations for total vegetables were 0·63 (men) and 0·66 (women) in EATS, compared with 0·55 (men) and 0·52 (women) in the present study. Possible explanations for these differences include the facts that the EATS sample was comprised of subjects aged 20–70 years, while the NIH–AARP sample was older (50–71) years, and the EATS analysis did not use methods designed for episodically consumed foods.
As shown in Table 4, when the correlation of true and FFQ-reported intakes is at least 0·5, the NIH–AARP study will have at least 85 % power to detect moderate diet–disease associations (odds ratios 1·5 or greater) for common cancer types such as prostate, breast, lung and colorectal. For less common types such as thyroid or liver, however, the power to detect such associations will be much lower. Similarly, when the attenuation factor is at least 0·4, moderate diet–disease associations may be substantially underestimated, but not to the point where they disappear altogether. For example, if the true odds ratio is 1·5 (α 1 = log(1·5) in equation (4)) and the attenuation factor is 0·4, then the estimated odds ratio will have mean equal to about 1·50·4 = 1·18. Moreover, when the attenuation factor is small, say less than 0·2, attempting to ‘deattenuate’ estimates will give unreliable results and is not advised. When the attenuation factor is at least 0·4, however, it is possible to deattenuate an estimated log odds ratio by dividing it by the attenuation factor, giving an approximately unbiased estimate(Reference Rosner, Spiegelman and Willett4). In summary, the levels of correlation and attenuation factor that we have estimated indicate that the NIH–AARP FFQ is suitable for estimating and testing many, but not all, diet–disease relationships in the NIH–AARP cohort.
Acknowledgements
R.J.C.'s research was supported by a grant from the National Cancer Institute (CA57030). None of the authors have any conflict of interest. A.S. directed the study. A.S., A.F.S., F.E.T., L.S.F. and R.J.C. participated in the design of the study. D.M., L.S.F., R.J.C. and V.K. developed the statistical methodology and designed and reviewed the analysis. D.M. and M.A.S. carried out the analysis. D.M. had primary responsibility for writing the manuscript, but all authors contributed to its writing and revision.
Appendix 1
Box–Cox transformations
The Box–Cox transformation is defined as
for some transformation parameter λ. We use Box–Cox transformations to transform Qi and positive Rij to approximate normality, defining ![]() and
and ![]() , and choosing λQ and λR so as to maximize the Shapiro–Wilk test statistic for normality for Qi and positive Rij. We also define
, and choosing λQ and λR so as to maximize the Shapiro–Wilk test statistic for normality for Qi and positive Rij. We also define ![]() , choosing λT so as to minimize the Kolmogorov test statistic for normality for Ti in the Monte Carlo distribution (see Appendix 2).
, choosing λT so as to minimize the Kolmogorov test statistic for normality for Ti in the Monte Carlo distribution (see Appendix 2).
Appendix 2
Monte Carlo distribution of true and FFQ-reported intakes
Under the assumptions that Rij is an unbiased estimate of Ti, and that the model defined by equations (1) and (2) is correct, one can write Ti as a function of Qi and random effects (U 1i, U 2i) as:
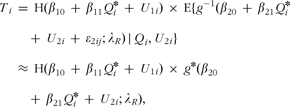
where H(x) is the logistic function and ![]() is a Taylor-series approximation of the expectation
is a Taylor-series approximation of the expectation ![]() ,
,
One can estimate relationships between true and FFQ-reported intakes by generating a Monte Carlo distribution of (Ti, Qi). For each individual i, generate random effects (U 1i, U 2i) having a joint normal distribution with variances ![]() ,
,![]() and correlation
and correlation ![]() , and calculate Ti as in equation (6). Repeat this process m = 100 times for each individual, so that the resulting Monte Carlo distribution has n × m pseudo-individuals. Under the assumptions listed above, the Monte Carlo distribution will be approximately the same as the real distribution of (Ti, Qi), and one can use it to estimate the attenuation factor γ 1 and correlation with true intake ρTQ, described in the main text. We estimate ρTQ as the sample correlation of Box–Cox transformed variables
, and calculate Ti as in equation (6). Repeat this process m = 100 times for each individual, so that the resulting Monte Carlo distribution has n × m pseudo-individuals. Under the assumptions listed above, the Monte Carlo distribution will be approximately the same as the real distribution of (Ti, Qi), and one can use it to estimate the attenuation factor γ 1 and correlation with true intake ρTQ, described in the main text. We estimate ρTQ as the sample correlation of Box–Cox transformed variables ![]() and
and ![]() in the Monte Carlo distribution. Similarly, we estimate γ 1 as the slope in the regression of
in the Monte Carlo distribution. Similarly, we estimate γ 1 as the slope in the regression of ![]() v.
v. ![]() , after standardizing both variables so that a unit change on the transformed scale is equal to the change from the 10th to 90th percentile of true intake on that scale. Standard errors are estimated using a bootstrap method.
, after standardizing both variables so that a unit change on the transformed scale is equal to the change from the 10th to 90th percentile of true intake on that scale. Standard errors are estimated using a bootstrap method.
The Monte Carlo method for energy-adjusted foods is similar to the method for unadjusted foods, except that we use the parameter estimates from the three-part food and energy model (see Appendix 3) to generate random effects (U 1i, U 2i , U 3i) and create a Monte Carlo distribution of ![]() . We then calculate
. We then calculate ![]() as the residual in the regression of
as the residual in the regression of ![]() v.
v. ![]() , and
, and ![]() as the residual in the regression of on
as the residual in the regression of on ![]() v.
v. ![]() . Finally, we estimate ρTQ as the sample correlation of
. Finally, we estimate ρTQ as the sample correlation of ![]() and
and ![]() , and γ 1 as the slope in the regression of
, and γ 1 as the slope in the regression of ![]() v.
v. ![]() .
.
Appendix 3
Three-part food and energy model
For individual i, ![]() , let
, let
![]() be the true usual intake of an episodically consumed food
be the true usual intake of an episodically consumed food
![]() be the true usual intake of energy
be the true usual intake of energy
![]() be the 24HR-reported intake of the episodically consumed food on day j
be the 24HR-reported intake of the episodically consumed food on day j
![]() be the 24HR-reported intake of energy on day j
be the 24HR-reported intake of energy on day j
![]() be the FFQ-reported intake of the episodically consumed food
be the FFQ-reported intake of the episodically consumed food
![]() be the FFQ-reported intake of energy.
be the FFQ-reported intake of energy.
Under the food and energy model, we assume that the 24HR is unbiased for true intake:
and
and that, after appropriate transformations, the relationship between 24HR and FFQ can be described by the following three-part non-linear mixed-effects model:
and
where pi is the probability that ![]() ,
, ![]() is the inverse of the logistic distribution function, random effects (U 1i , U 2i, U 3i) have a joint normal distribution with mean zero, within-person random errors (ε 2ij, ε 3ij) have a joint normal distribution with mean zero, and within-person errors (ε 2ij, ε 3ij) are independent of random effects (U 1i , U 2i, U 3i). Variables
is the inverse of the logistic distribution function, random effects (U 1i , U 2i, U 3i) have a joint normal distribution with mean zero, within-person random errors (ε 2ij, ε 3ij) have a joint normal distribution with mean zero, and within-person errors (ε 2ij, ε 3ij) are independent of random effects (U 1i , U 2i, U 3i). Variables ![]() ,
, ![]() ,
, ![]() and
and ![]() are Box–Cox transformations of
are Box–Cox transformations of ![]() ,
, ![]() ,
, ![]() and
and ![]() to scales on which they are approximately normal (see Appendix 1).
to scales on which they are approximately normal (see Appendix 1).
Appendix 4
Estimating power in a univariate diet–disease model
Suppose we are fitting diet–disease model, equation (4), using Qi to measure intake and there are D cases of disease in the cohort. Kaaks et al.(Reference Kaaks, Riboli and van Staveren22) show that the power to detect α 1 at significance level γ is approximately:
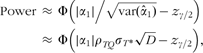
where ![]() is the standard deviation of
is the standard deviation of ![]() , Φ(z) is the standard normal distribution and
, Φ(z) is the standard normal distribution and ![]() . The power to test the hypothesis that the odds ratio comparing the 90th to 10th percentile of true intake is equal to 1·5, i.e. that
. The power to test the hypothesis that the odds ratio comparing the 90th to 10th percentile of true intake is equal to 1·5, i.e. that ![]() , is then:
, is then:




