



1. Introduction
Consider a system with  $N \geq 1$ subordinates and
$N \geq 1$ subordinates and  $1 \leq M \leq N$ supervisors. Assume that there is an unlimited supply of work, that each customer requires two stages of service, and that customers are impatient and can leave without receiving the service at the second stage. The first service stage is completed by an assigned subordinate, whereas the second service stage (also referred to as the advanced service) is completed jointly by the assigned subordinate and a supervisor. The subordinate can only start work on a new customer when her previously assigned customer departs. Thus, the subordinate will serve the customer on her own (the first-stage service), wait for a supervisor together with the customer, and then serve the customer together with a supervisor (the second-stage service) if the customer does not leave before the second-stage service starts. In addition to their work with the subordinates, the supervisors have an unlimited supply of their own responsibilities to attend to. Therefore, supervisors may not immediately attend to waiting customers. Our problem is to determine how the supervisors should dynamically divide their time between their joint work with the subordinates and their own responsibilities. Rewards are incurred both when first- and second-stage service is completed for a customer and also when supervisors finish one of their own responsibilities. However, a cost is incurred when customers depart without completing the second-stage service. Our objective is to maximize the long-run average profit per unit time.
$1 \leq M \leq N$ supervisors. Assume that there is an unlimited supply of work, that each customer requires two stages of service, and that customers are impatient and can leave without receiving the service at the second stage. The first service stage is completed by an assigned subordinate, whereas the second service stage (also referred to as the advanced service) is completed jointly by the assigned subordinate and a supervisor. The subordinate can only start work on a new customer when her previously assigned customer departs. Thus, the subordinate will serve the customer on her own (the first-stage service), wait for a supervisor together with the customer, and then serve the customer together with a supervisor (the second-stage service) if the customer does not leave before the second-stage service starts. In addition to their work with the subordinates, the supervisors have an unlimited supply of their own responsibilities to attend to. Therefore, supervisors may not immediately attend to waiting customers. Our problem is to determine how the supervisors should dynamically divide their time between their joint work with the subordinates and their own responsibilities. Rewards are incurred both when first- and second-stage service is completed for a customer and also when supervisors finish one of their own responsibilities. However, a cost is incurred when customers depart without completing the second-stage service. Our objective is to maximize the long-run average profit per unit time.
Our research is motivated by situations where supervisors must sign off on the work of their subordinates. However, this type of queueing systems may arise in other real-life situations. For example, consider some government service where people need to fill out forms or take other actions by themselves as the first stage. The second stage involves being served by the officials. The limited place for people to finish the self-service can be regarded as the limited number of (subordinate) servers in the first stage. Since there are typically fewer officials than people needing service, and since the officials may have other responsibilities, customers may get impatient and leave while waiting for officials. The assumption on unlimited supply of work for both the first-stage service and the supervisors is consistent with real-life observations and common assumptions in the literature on modern service and manufacturing systems. Specifically, in healthcare facilities, for example, emergency rooms, it is widely acknowledged that overcrowding is prevalent at all times (see, e.g., [Reference Derlet and Richards12,Reference Derlet, Richards and Kravitz13,Reference Yarmohammadian, Rezaei, Haghshenas and Tavakoli28]), indicating the rationality of the assumption on the unlimited supply of patients in such healthcare facilities. Similarly, in make-to-stock manufacturing systems, it is common to assume ample availability of raw materials (see, e.g., [Reference Muth21,Reference Wein27,Reference Zhao and Melamed31]).
We assume that the amount of time that it takes a supervisor to switch from one activity to the other is negligible. Furthermore, we assume that the service times of each customer in the first stage are exponential random variables with rate  $\mu _1 \gt 0$. The patience time of a customer for the second-stage service is exponentially distributed with rate
$\mu _1 \gt 0$. The patience time of a customer for the second-stage service is exponentially distributed with rate  $\theta \gt 0$. The corresponding abandonment cost is
$\theta \gt 0$. The corresponding abandonment cost is  $c$. We first assume that abandonments can only occur when the customers are waiting for the second-stage service. Later, we extend the problem to the case where abandonments may also occur during the first- and/or second-stage service. The second-stage service time is exponentially distributed with rate
$c$. We first assume that abandonments can only occur when the customers are waiting for the second-stage service. Later, we extend the problem to the case where abandonments may also occur during the first- and/or second-stage service. The second-stage service time is exponentially distributed with rate  $\mu _2 \gt 0$. The amounts of time that the supervisors spend on their own responsibilities have an exponential distribution with rate
$\mu _2 \gt 0$. The amounts of time that the supervisors spend on their own responsibilities have an exponential distribution with rate  $\mu _s \gt 0$. We assume that supervisors can switch between tasks in a preemptive manner (rather than only upon completing a task). Finally, all random variables are independent. There is a reward of
$\mu _s \gt 0$. We assume that supervisors can switch between tasks in a preemptive manner (rather than only upon completing a task). Finally, all random variables are independent. There is a reward of  $r_1 \geq 0$ when a subordinate completes the first-stage service and a reward of
$r_1 \geq 0$ when a subordinate completes the first-stage service and a reward of  $r_2 \geq 0$ when a supervisor and a subordinate complete the second-stage service together. There is also a reward of
$r_2 \geq 0$ when a supervisor and a subordinate complete the second-stage service together. There is also a reward of  $r_s \geq 0$ when a supervisor finishes one of her own responsibilities. The abandonment cost
$r_s \geq 0$ when a supervisor finishes one of her own responsibilities. The abandonment cost  $c$ is not restricted to be positive; when
$c$ is not restricted to be positive; when  $c$ is negative, it can be regarded as the reward for a customer who left the system with the first-stage service only. Note that without loss of generality, we can always set
$c$ is negative, it can be regarded as the reward for a customer who left the system with the first-stage service only. Note that without loss of generality, we can always set  $r_1 = 0$ since the case where
$r_1 = 0$ since the case where  $r_1 \gt 0$ is equivalent to the case where
$r_1 \gt 0$ is equivalent to the case where  $r_1^\prime =0$,
$r_1^\prime =0$,  $c^\prime =c -r_1$, and
$c^\prime =c -r_1$, and  $r_2^\prime = r_1+r_2$. The remainder of this paper considers the case where
$r_2^\prime = r_1+r_2$. The remainder of this paper considers the case where  $r_1=0$.
$r_1=0$.
For this service system, we are interested in determining the dynamic assignment of the supervisors to their two tasks with the objective of maximizing the long-run average profit. Controlling flexible servers in tandem queueing systems has been studied in many papers. For example, Duenyas et al. [Reference Duenyas, Gupta and Olsen16] considered the optimal control of a tandem queueing system with setups where there is only one flexible server and Ahn et al. [Reference Ahn, Duenyas and Lewis1] studied the optimal control of two flexible servers in a two-stage tandem queueing system to minimize holding costs. Andradóttir and Ayhan [Reference Andradóttir and Ayhan2] characterized the optimal assignment of  $M$ flexible servers to two stations in a tandem queueing system with the objective to maximize the long-run average throughput, and Andradóttir et al. [Reference Andradóttir, Ayhan and Down4] considered the assignment of flexible servers in a tandem queueing network with
$M$ flexible servers to two stations in a tandem queueing system with the objective to maximize the long-run average throughput, and Andradóttir et al. [Reference Andradóttir, Ayhan and Down4] considered the assignment of flexible servers in a tandem queueing network with  $N$ stations and several dedicated servers. Berman and Sapna-Isotupa [Reference Berman and Sapna-Isotupa8] studied the optimal server allocation between the front and back rooms of a service facility when the work in the back room is generated by the service provided in the front room and the servers are cross-skilled. The above server assignment problems mainly focus on how to assign servers between different stations within the queueing system, while our work considers the server assignment problem between the queue and other responsibilities.
$N$ stations and several dedicated servers. Berman and Sapna-Isotupa [Reference Berman and Sapna-Isotupa8] studied the optimal server allocation between the front and back rooms of a service facility when the work in the back room is generated by the service provided in the front room and the servers are cross-skilled. The above server assignment problems mainly focus on how to assign servers between different stations within the queueing system, while our work considers the server assignment problem between the queue and other responsibilities.
Moreover, server assignment problems are also seen in call centers with call blending, as well as in other practical applications. Motivated by a Bell Canada call center, Deslauriers et al. [Reference Deslauriers, L'Ecuyer, Pichitlamken, Ingolfsson and Avramidis14] proposed five Markovian models with inbound and outbound calls where there are two types of servers, that is, inbound-only and blend servers, and compared these models with a benchmark model using simulation. When there are two types of jobs served by a common pool of servers and there is a waiting time constraint on one type of jobs, Bhulai and Koole [Reference Bhulai and Koole9] showed that a trunk reservation policy is optimal for the case where the service rates are the same for the two types of jobs. That is, the optimal server assignment policy is a threshold policy on the number of available servers. Furthermore, Bhulai et al. [Reference Bhulai, Farenhorst-Yuan, Heidergott and van der Laan10] extended the assignment problem in call centers to the case where there is no specific condition on the service rates, and proposed a stochastic approximation algorithm to find the optimal balanced policy. Pang and Perry [Reference Pang and Perry22] proposed a logarithmic safety-staffing rule, combined with a threshold policy, under which the server utilization can be close to 1. Wang et al. [Reference Wang, Baron and Scheller-Wolf24] analyzed an  $M/M/c$ queue with two priority classes by reducing the two-dimensional Markov chain to a one-dimensional Markov chain. Meanwhile, in the setting of assigning homecare employees to patients, Koeleman et al. [Reference Koeleman, Bhulai and van Meersbergen19] showed that a trunk reservation heuristic is close to optimal. Compared with the above work on server assignment, our work involves a tandem queueing system, where a customer and a subordinate will wait together for the second-stage service with a supervisor, and the customer may abandon while waiting.
$M/M/c$ queue with two priority classes by reducing the two-dimensional Markov chain to a one-dimensional Markov chain. Meanwhile, in the setting of assigning homecare employees to patients, Koeleman et al. [Reference Koeleman, Bhulai and van Meersbergen19] showed that a trunk reservation heuristic is close to optimal. Compared with the above work on server assignment, our work involves a tandem queueing system, where a customer and a subordinate will wait together for the second-stage service with a supervisor, and the customer may abandon while waiting.
Abandonment is a natural and ubiquitous phenomenon in queueing systems. We include customer abandonments in our model to reflect this common phenomenon. For example, Garnett et al. [Reference Garnett, Mandelbaum and Reiman17] pointed out that customer abandonment is a key factor for call center operations. Weerasinghe and Mandelbaum [Reference Weerasinghe and Mandelbaum26] studied the trade-off between abandonment and blocking in a one-stage, many-server queue where customers may abandon while waiting for service and will balk once the queue is full. Batt and Terwiesch [Reference Batt and Terwiesch7] conducted an empirical study on queue abandonments in a hospital emergency department and identified that the abandonment is correlated with the queue length and queue flows during the waiting exposure.
Abandonment is also considered in two-station tandem queues. For example, Khudyakov et al. [Reference Khudyakov, Feigin and Mandelbaum18] considered a two-stage queueing system in a call center with Interactive Voice Response (IVR). The customer is served by an IVR processor in the first stage and may leave the system with probability  $1-p$ before proceeding to the second stage. Operational performance measures are approximated in an asymptotic Quality and Efficiency Driven regime. Wang et al. [Reference Wang, Abouee-Mehrizi, Baron and Berman25] evaluated the performance of a tandem queueing network with abandonment using an exact numerical method. Zayas-Cabán et al. [Reference Zayas-Cabán, Xie, Green and Lewis29] investigated the server assignment problem between the two stations of a tandem service system with abandonment in both stations. Zayas-Caban et al. [Reference Zayas-Caban, Xie, Green and Lewis30] modeled the triage and treatment processes in an emergency department as a two-phase service system where patients may leave the system without treatment. They provided numerical examples to analyze the rewards and patient waiting times under the policy that treatment is prioritized unless there are
$1-p$ before proceeding to the second stage. Operational performance measures are approximated in an asymptotic Quality and Efficiency Driven regime. Wang et al. [Reference Wang, Abouee-Mehrizi, Baron and Berman25] evaluated the performance of a tandem queueing network with abandonment using an exact numerical method. Zayas-Cabán et al. [Reference Zayas-Cabán, Xie, Green and Lewis29] investigated the server assignment problem between the two stations of a tandem service system with abandonment in both stations. Zayas-Caban et al. [Reference Zayas-Caban, Xie, Green and Lewis30] modeled the triage and treatment processes in an emergency department as a two-phase service system where patients may leave the system without treatment. They provided numerical examples to analyze the rewards and patient waiting times under the policy that treatment is prioritized unless there are  $K$ or more patients in triage. However, none of the above works on tandem queueing systems with abandonment characterized the optimal policy explicitly, while we provide an optimal threshold policy with respect to the abandonment cost for a tandem queueing system. Additionally, Atar et al. [Reference Atar, Giat and Shimkin6] considered a multi-class queueing system with homogeneous servers and abandonment, and provided a server-scheduling policy that is asympotically optimal for minimizing the long-run average holding cost. Ansari et al. [Reference Ansari, Debo and Iravani5] studied a multi-class queueing system with a single server and abandonment, and characterized the conditions under which the asymptotically optimal policy of Atar et al. [Reference Atar, Giat and Shimkin6] is indeed optimal. Down et al. [Reference Down, Koole and Lewis15] identified the optimal server control in a two-class service system with abandonments, where they considered two models with different reward/cost structures. However, Atar et al. [Reference Atar, Giat and Shimkin6], Ansari et al. [Reference Ansari, Debo and Iravani5], and Down et al. [Reference Down, Koole and Lewis15] all considered single-stage queueing systems, whereas our model is a two-stage service system.
$K$ or more patients in triage. However, none of the above works on tandem queueing systems with abandonment characterized the optimal policy explicitly, while we provide an optimal threshold policy with respect to the abandonment cost for a tandem queueing system. Additionally, Atar et al. [Reference Atar, Giat and Shimkin6] considered a multi-class queueing system with homogeneous servers and abandonment, and provided a server-scheduling policy that is asympotically optimal for minimizing the long-run average holding cost. Ansari et al. [Reference Ansari, Debo and Iravani5] studied a multi-class queueing system with a single server and abandonment, and characterized the conditions under which the asymptotically optimal policy of Atar et al. [Reference Atar, Giat and Shimkin6] is indeed optimal. Down et al. [Reference Down, Koole and Lewis15] identified the optimal server control in a two-class service system with abandonments, where they considered two models with different reward/cost structures. However, Atar et al. [Reference Atar, Giat and Shimkin6], Ansari et al. [Reference Ansari, Debo and Iravani5], and Down et al. [Reference Down, Koole and Lewis15] all considered single-stage queueing systems, whereas our model is a two-stage service system.
Moreover, most of the related work focuses on allocating flexible servers over time to different stations while we focus on the assignment of the supervisors who have other responsibilities in addition to serving the queueing system. In our model, the supervisors work together with the subordinates in the second stage. Motivated by a healthcare application, Andradóttir and Ayhan [Reference Andradóttir and Ayhan3] considered a two-stage service system where the first stage is the examination of patients done by residents and the second stage is the consultation between residents and their (one) attending physician. By comparison, we consider multiple supervisors, customer abandonments, and a different cost structure (abandonment costs rather than holding costs). The comparison between dedicated versus pooled systems has also been investigated and quantified in many research papers. Cattani and Schmidt [Reference Cattani and Schmidt11] reviewed and summarized the related work regarding the effects of pooling. We study the performance of dedicated versus pooled systems in this setting (with collaboration between subordinates and supervisors and abandonments) and show that pooling supervisors (and their subordinates) improves performance.
The remainder of this paper is organized as follows. In Section 2, we provide a Markov decision process formulation of the problem and translate the continuous-time optimization problem into a discrete-time Markov decision process problem. In Section 3, we show that one of two policies is optimal and the optimal policy is defined by a threshold on the abandonment cost  $c$. We also determine the limit of this threshold as the abandonment rate becomes small or large. In Section 4, we prove that pooling supervisors (and their associated subordinates) improves the system performance, but the improvement per pooled supervisor is bounded. Section 5 concludes the paper.
$c$. We also determine the limit of this threshold as the abandonment rate becomes small or large. In Section 4, we prove that pooling supervisors (and their associated subordinates) improves the system performance, but the improvement per pooled supervisor is bounded. Section 5 concludes the paper.
2. Problem formulation
In this section, we consider the stochastic process  $\{\mathcal {X}_\pi (t): t \geq 0 \}$ where
$\{\mathcal {X}_\pi (t): t \geq 0 \}$ where  $\Pi$ is the set of possible supervisor assignment policies,
$\Pi$ is the set of possible supervisor assignment policies,  $\pi \in \Pi$, and
$\pi \in \Pi$, and  $\mathcal {X}_\pi (t)=x \in X = \{0,1, \ldots, N\}$ is the number of customers who have been served by a subordinate and are waiting for a supervisor at time
$\mathcal {X}_\pi (t)=x \in X = \{0,1, \ldots, N\}$ is the number of customers who have been served by a subordinate and are waiting for a supervisor at time  $t$ under policy
$t$ under policy  $\pi$. We assume that
$\pi$. We assume that  $\Pi$ consists of all Markovian stationary deterministic policies corresponding to the state space
$\Pi$ consists of all Markovian stationary deterministic policies corresponding to the state space  $X$ of the stochastic process
$X$ of the stochastic process  $\{ \mathcal {X}_\pi (t)\}$. The policy
$\{ \mathcal {X}_\pi (t)\}$. The policy  $\pi \in \Pi$ specifies if each supervisor is serving the customers or working on her own responsibilities as a function of the current state
$\pi \in \Pi$ specifies if each supervisor is serving the customers or working on her own responsibilities as a function of the current state  $x \in X$ (i.e., the number of customers who are waiting for the supervisor). We note that
$x \in X$ (i.e., the number of customers who are waiting for the supervisor). We note that  $\{ \mathcal {X}_\pi (t)\}$ is a birth-and-death process with finite state space
$\{ \mathcal {X}_\pi (t)\}$ is a birth-and-death process with finite state space  $X$ and there exists a finite scalar
$X$ and there exists a finite scalar  $q$ such that the transition rates
$q$ such that the transition rates  $\{q_\pi (x,x^\prime )\}$ of
$\{q_\pi (x,x^\prime )\}$ of  $\{ \mathcal {X}_{\pi } (t)\}$ satisfy
$\{ \mathcal {X}_{\pi } (t)\}$ satisfy  $\sum _{x^{\prime } \in X, x^{\prime } \neq x} q_\pi (x,x^\prime ) \leq q$ for all
$\sum _{x^{\prime } \in X, x^{\prime } \neq x} q_\pi (x,x^\prime ) \leq q$ for all  $x \in X$ and
$x \in X$ and  $\pi \in \Pi$. This indicates that
$\pi \in \Pi$. This indicates that  $\{ \mathcal {X}_\pi (t)\}$ is uniformizable for all
$\{ \mathcal {X}_\pi (t)\}$ is uniformizable for all  $\pi \in \Pi$. Let
$\pi \in \Pi$. Let  $\{Y_\pi (k)\}$ denote the corresponding discrete-time Markov chain, so that
$\{Y_\pi (k)\}$ denote the corresponding discrete-time Markov chain, so that  $\{Y_\pi (k)\}$ has the same state space
$\{Y_\pi (k)\}$ has the same state space  ${X}$ as
${X}$ as  $\{ \mathcal {X}_\pi (t)\}$ and transition probabilities
$\{ \mathcal {X}_\pi (t)\}$ and transition probabilities  $p_{\pi }(x,x^\prime )=q_\pi (x,x^\prime )/q$ if
$p_{\pi }(x,x^\prime )=q_\pi (x,x^\prime )/q$ if  $x^\prime \neq x$ and
$x^\prime \neq x$ and  $p_{\pi }(x,x)=1-\sum _{x^\prime \in {X}, x^\prime \neq x}q_\pi (x,x^\prime )/q$ for all
$p_{\pi }(x,x)=1-\sum _{x^\prime \in {X}, x^\prime \neq x}q_\pi (x,x^\prime )/q$ for all  $x \in {X}$. We then translate the continuous-time optimization problem to a discrete-time Markov decision problem (see, e.g., [Reference Lippman20]). That is to say, we can generate sample paths of
$x \in {X}$. We then translate the continuous-time optimization problem to a discrete-time Markov decision problem (see, e.g., [Reference Lippman20]). That is to say, we can generate sample paths of  $\{ \mathcal {X}_\pi (t)\}$, where
$\{ \mathcal {X}_\pi (t)\}$, where  $\pi \in \Pi$, by generating a Poisson process
$\pi \in \Pi$, by generating a Poisson process  $\{ K (t)\}$ with rate
$\{ K (t)\}$ with rate  $q = N\mu _1+N\theta +M\mu _2 \lt \infty$ and at the times of events of
$q = N\mu _1+N\theta +M\mu _2 \lt \infty$ and at the times of events of  $\{ K (t)\}$, the next state of
$\{ K (t)\}$, the next state of  $\{ \mathcal {X}_\pi (t)\}$ is generated using the transition probabilities of
$\{ \mathcal {X}_\pi (t)\}$ is generated using the transition probabilities of  $\{Y_\pi (k)\}$.
$\{Y_\pi (k)\}$.
Let  $a \in A=\{0,1,\ldots,M\}$ denote the assignment of supervisors, where
$a \in A=\{0,1,\ldots,M\}$ denote the assignment of supervisors, where  $a$ represents the number of supervisors who are working with the subordinates and
$a$ represents the number of supervisors who are working with the subordinates and  $A$ is the action space. Let
$A$ is the action space. Let  $A_{x}$ and
$A_{x}$ and  $a_x$ denote the set of allowable actions in state
$a_x$ denote the set of allowable actions in state  $x \in X$. Note that
$x \in X$. Note that  $A_0 = \{0\}$, representing that supervisors can only work on their own responsibilities when there are no customers waiting for the second-stage service, and
$A_0 = \{0\}$, representing that supervisors can only work on their own responsibilities when there are no customers waiting for the second-stage service, and  $A_N = \{1,\ldots,M\}$, representing that we have at least one supervisor serving the customers if the number of customers who are waiting for supervisors attains the maximum (since it would be unethical for supervisors not to serve customers when all the first-stage servers cannot serve any more customers). For
$A_N = \{1,\ldots,M\}$, representing that we have at least one supervisor serving the customers if the number of customers who are waiting for supervisors attains the maximum (since it would be unethical for supervisors not to serve customers when all the first-stage servers cannot serve any more customers). For  $1 \leq x \leq N-1$, we have
$1 \leq x \leq N-1$, we have  $A_{x} = \{0,1,\ldots,\min \{x,M\}\}$. Figure 1 illustrates the corresponding rate diagram when action
$A_{x} = \{0,1,\ldots,\min \{x,M\}\}$. Figure 1 illustrates the corresponding rate diagram when action  $a_x \in A_x$ is selected in state
$a_x \in A_x$ is selected in state  $x \in X$.
$x \in X$.

Figure 1. State-transition diagram for the two-stage service system.
For the discrete-time Markov decision process problem with uniformization constant  $q$, we have, for all
$q$, we have, for all  $a_{x}\in A_{x}$, the following one-step transition probabilities:
$a_{x}\in A_{x}$, the following one-step transition probabilities:
 \begin{equation} p(x^\prime\,|\,x,a_{x})=\left\{\begin{array}{ll} \dfrac{(N-x)\mu_1}{q} & \text{for}\ x \in \{0,\ldots,N-1\}, x^\prime=x+1,\\ \dfrac{(x-a_{x})\theta+a_{x} \mu_2}{q} & \text{for}\ x \in \{1,\ldots,N\}, x^\prime=x-1,\\ 1-\dfrac{(N-x)\mu_1+(x-a_{x})\theta+a_{x} \mu_2}{q} & \text{for}\ x \in \{0,\ldots,N\}, x^\prime=x,\\ 0 & \text{otherwise}. \end{array}\right. \end{equation}
\begin{equation} p(x^\prime\,|\,x,a_{x})=\left\{\begin{array}{ll} \dfrac{(N-x)\mu_1}{q} & \text{for}\ x \in \{0,\ldots,N-1\}, x^\prime=x+1,\\ \dfrac{(x-a_{x})\theta+a_{x} \mu_2}{q} & \text{for}\ x \in \{1,\ldots,N\}, x^\prime=x-1,\\ 1-\dfrac{(N-x)\mu_1+(x-a_{x})\theta+a_{x} \mu_2}{q} & \text{for}\ x \in \{0,\ldots,N\}, x^\prime=x,\\ 0 & \text{otherwise}. \end{array}\right. \end{equation}
Furthermore, for all  $x \in X$ and
$x \in X$ and  $a_{x} \in A_{x}$, we specify the immediate reward
$a_{x} \in A_{x}$, we specify the immediate reward  $r(x,a_{x})$ of choosing action
$r(x,a_{x})$ of choosing action  $a_{x}$ in state
$a_{x}$ in state  $x$:
$x$:
 $$r(x,a_{x}) = \frac{(M-a_{x}) r_s \mu_s+a_{x} r_2 \mu_2-(x-a_{x})c\theta}{q}.$$
$$r(x,a_{x}) = \frac{(M-a_{x}) r_s \mu_s+a_{x} r_2 \mu_2-(x-a_{x})c\theta}{q}.$$
Note that due to the abandonments, this Markov decision process problem is unichain. Since  $X$ is finite,
$X$ is finite,  $A_{x}$ is finite for each
$A_{x}$ is finite for each  $x \in X$, and
$x \in X$, and  $r(x,a_{x})$ is bounded, there exists a stationary long-run average optimal policy (see [Reference Puterman23], Theorem 8.4.5).
$r(x,a_{x})$ is bounded, there exists a stationary long-run average optimal policy (see [Reference Puterman23], Theorem 8.4.5).
For any policy  $\pi \in \Pi$, let
$\pi \in \Pi$, let  $g_{N,M}^\pi$ denote the gain (long-run average reward) of the continuous-time problem under policy
$g_{N,M}^\pi$ denote the gain (long-run average reward) of the continuous-time problem under policy  $\pi$ for a system with
$\pi$ for a system with  $N$ subordinates and
$N$ subordinates and  $M$ supervisors. Note that
$M$ supervisors. Note that  ${g_{N,M}^\pi }/{q}$ is the gain for the corresponding discrete-time problem. The objective is to identify the optimal policy
${g_{N,M}^\pi }/{q}$ is the gain for the corresponding discrete-time problem. The objective is to identify the optimal policy  $\pi ^* \in \Pi$ that attains the optimal gain
$\pi ^* \in \Pi$ that attains the optimal gain  $g_{N,M}^*$, that is, find
$g_{N,M}^*$, that is, find  $\pi ^*$ such that
$\pi ^*$ such that
 $$g_{N,M}^{\pi^*}=g_{N,M}^*=\max_{\pi \in \Pi}g_{N,M}^\pi.$$
$$g_{N,M}^{\pi^*}=g_{N,M}^*=\max_{\pi \in \Pi}g_{N,M}^\pi.$$
3. Optimal policy
In this section, we show that one of two policies is always optimal and characterize the conditions under which each policy is optimal. Note that a Markovian deterministic decision rule  $d: X\rightarrow A$ specifies which action
$d: X\rightarrow A$ specifies which action  $d(x)\in A_{x}$ to choose in each state
$d(x)\in A_{x}$ to choose in each state  $x\in X$. Thus, a stationary policy
$x\in X$. Thus, a stationary policy  $\pi$ can be defined using the corresponding decision rule
$\pi$ can be defined using the corresponding decision rule  $d$ which will be denoted as
$d$ which will be denoted as  $\pi =d^{\infty }$.
$\pi =d^{\infty }$.
Define  $\pi ^{\mathcal {S}}=(d_{\mathcal {S}})^{\infty }$, where
$\pi ^{\mathcal {S}}=(d_{\mathcal {S}})^{\infty }$, where
 $$d_{\mathcal{S}}(x)=\left\{\begin{array}{ll} 0 & \text{for}\ x=0,\ldots,N-1,\\ 1 & \text{for}\ x=N. \end{array}\right.$$
$$d_{\mathcal{S}}(x)=\left\{\begin{array}{ll} 0 & \text{for}\ x=0,\ldots,N-1,\\ 1 & \text{for}\ x=N. \end{array}\right.$$
Similarly, define  $\pi ^{\mathcal {C}}=(d_{\mathcal {C}})^{\infty }$ where
$\pi ^{\mathcal {C}}=(d_{\mathcal {C}})^{\infty }$ where  $d_{\mathcal {C}}(x)=\min \{x,M\}$ for all
$d_{\mathcal {C}}(x)=\min \{x,M\}$ for all  $x\in \{0,\ldots,N\}$. Thus,
$x\in \{0,\ldots,N\}$. Thus,  $\pi ^{\mathcal {S}}$ gives priority to the
$\pi ^{\mathcal {S}}$ gives priority to the  $\mathcal {S}$upervisors’ own responsibilities and
$\mathcal {S}$upervisors’ own responsibilities and  $\pi ^{\mathcal {C}}$ gives priority to the
$\pi ^{\mathcal {C}}$ gives priority to the  $\mathcal {C}$ustomers. The following theorem completely characterizes the optimal policy.
$\mathcal {C}$ustomers. The following theorem completely characterizes the optimal policy.
Theorem 1.
(i) If
 $c \leq c_0:={[(r_s \mu _s -r_2 \mu _2)(\theta +\mu _1)]}/{[(\mu _1+\mu _2)\theta ]}$, then $\pi ^{\mathcal {S}}$ is optimal;
$c \leq c_0:={[(r_s \mu _s -r_2 \mu _2)(\theta +\mu _1)]}/{[(\mu _1+\mu _2)\theta ]}$, then $\pi ^{\mathcal {S}}$ is optimal;(ii) If
$c \geq c_0$, then $\pi ^{\mathcal {C}}$ is optimal.




Remark 2. It immediately follows from the proof of Theorem 1 that even if the supervisors are not required to serve the customers when there are  $N$ customers waiting (i.e.,
$N$ customers waiting (i.e.,  $A_N = A = \{0, 1,\ldots,M\}$), a result similar to Theorem 1 remains true. That is to say, if
$A_N = A = \{0, 1,\ldots,M\}$), a result similar to Theorem 1 remains true. That is to say, if  $c \leq c_0$, it is optimal for all supervisors to always work on their own responsibilities (even in state
$c \leq c_0$, it is optimal for all supervisors to always work on their own responsibilities (even in state  $N$); if
$N$); if  $c \geq c_0$, it is optimal for supervisors to start serving customers as soon as there is a customer waiting.
$c \geq c_0$, it is optimal for supervisors to start serving customers as soon as there is a customer waiting.
Proof of Theorem 1 and Remark 2. It follows from  $1 \leq M \leq N$ that
$1 \leq M \leq N$ that  $N=1$ implies
$N=1$ implies  $M=1$, in which case
$M=1$, in which case  $X=\{0,1\}$,
$X=\{0,1\}$,  $A_0=\{0\}$, and
$A_0=\{0\}$, and  $A_1=\{1\}$. Thus, there is only one feasible policy when
$A_1=\{1\}$. Thus, there is only one feasible policy when  $N=1$ and
$N=1$ and  $\pi ^{\mathcal {S}} = \pi ^{\mathcal {C}}$ are both optimal. Therefore, we assume
$\pi ^{\mathcal {S}} = \pi ^{\mathcal {C}}$ are both optimal. Therefore, we assume  $N \geq 2$ in the rest of the proof.
$N \geq 2$ in the rest of the proof.
Without loss of generality, we assume that  $q =1$ and use the value iteration algorithm for unichain Markov decision process problems (see p. 364 of [Reference Puterman23]).
$q =1$ and use the value iteration algorithm for unichain Markov decision process problems (see p. 364 of [Reference Puterman23]).
To prove the optimality of  $\pi ^{\mathcal {S}}$ and
$\pi ^{\mathcal {S}}$ and  $\pi ^{\mathcal {C}}$ under different conditions, for all
$\pi ^{\mathcal {C}}$ under different conditions, for all  $x=0,\ldots,N$, we set
$x=0,\ldots,N$, we set
 $$v_0(x)=(N-x-1)\times \frac{r_s\mu_s-r_2\mu_2}{\mu_1+\mu_2}$$
$$v_0(x)=(N-x-1)\times \frac{r_s\mu_s-r_2\mu_2}{\mu_1+\mu_2}$$
and compute  $v_n(x)=\max _{a_{x} \in A_{x}}v_n^{a_{x}}(x)$ for
$v_n(x)=\max _{a_{x} \in A_{x}}v_n^{a_{x}}(x)$ for  $n\geq 1$, where for
$n\geq 1$, where for  $x\in X$ and
$x\in X$ and  $a_{x}\in A_{x}$,
$a_{x}\in A_{x}$,
 \begin{align} v_n^{a_{x}}(x)& = (M-a_{x})r_s \mu_s+ a_{x} r_2\mu_2 -(x-a_{x}) c \theta+(N-x)\mu_1 v_{n-1}(x+1)\nonumber\\ & \quad +[(x-a_{x})\theta+a_{x}\mu_2] v_{n-1}(x-1)\nonumber\\ & \quad +[1-(N-x)\mu_1-(x-a_{x})\theta-a_{x}\mu_2] v_{n-1}(x). \end{align}
\begin{align} v_n^{a_{x}}(x)& = (M-a_{x})r_s \mu_s+ a_{x} r_2\mu_2 -(x-a_{x}) c \theta+(N-x)\mu_1 v_{n-1}(x+1)\nonumber\\ & \quad +[(x-a_{x})\theta+a_{x}\mu_2] v_{n-1}(x-1)\nonumber\\ & \quad +[1-(N-x)\mu_1-(x-a_{x})\theta-a_{x}\mu_2] v_{n-1}(x). \end{align}
Note that since  $A_0=\{0\}$,
$A_0=\{0\}$,  $v_n(0)=v_n^0(0)$ follows. For
$v_n(0)=v_n^0(0)$ follows. For  $a_{x}^{1},a_{x}^{2}\in A_{x}$ and
$a_{x}^{1},a_{x}^{2}\in A_{x}$ and  $x\in \{1,\ldots,N\}$, define
$x\in \{1,\ldots,N\}$, define
 \begin{equation} \Delta_n^{a_{x}^{1},a_{x}^{2}}(x)=v_n^{a_{x}^{1}}(x)-v_n^{a_{x}^{2}}(x) =(a_{x}^{2}-a_{x}^{1})(r_s \mu_s -r_2 \mu_2-c \theta +(\theta -\mu_2)[v_{n-1}(x-1)-v_{n-1}(x)]). \end{equation}
\begin{equation} \Delta_n^{a_{x}^{1},a_{x}^{2}}(x)=v_n^{a_{x}^{1}}(x)-v_n^{a_{x}^{2}}(x) =(a_{x}^{2}-a_{x}^{1})(r_s \mu_s -r_2 \mu_2-c \theta +(\theta -\mu_2)[v_{n-1}(x-1)-v_{n-1}(x)]). \end{equation}
We first prove part (i). We will show that  $\Delta _n^{a_{x}^{1},a_{x}^{2}}(x)\geq 0$ for all
$\Delta _n^{a_{x}^{1},a_{x}^{2}}(x)\geq 0$ for all  $n\geq 1$,
$n\geq 1$,  $x\in \{1,\ldots,N\}$ and
$x\in \{1,\ldots,N\}$ and  $a_{x}^{1} \lt a_{x}^{2}\in A_{x}$, which implies that
$a_{x}^{1} \lt a_{x}^{2}\in A_{x}$, which implies that  $v_n(x)=v_n^0(x)$ for all
$v_n(x)=v_n^0(x)$ for all  $x\in \{1,\ldots,N-1\}$ and
$x\in \{1,\ldots,N-1\}$ and  $v_n(N)=v_n^1(N)$ (
$v_n(N)=v_n^1(N)$ ( $v_n(N)=v_n^0(N)$ in Remark 2). First assume
$v_n(N)=v_n^0(N)$ in Remark 2). First assume  $\theta = \mu _2$. We then have:
$\theta = \mu _2$. We then have:
 $$\Delta_n^{a_{x}^{1},a_{x}^{2}}(x)=(a_{x}^{2}-a_{x}^{1})(r_s \mu_s -r_2 \mu_2-c \theta) \geq 0$$
$$\Delta_n^{a_{x}^{1},a_{x}^{2}}(x)=(a_{x}^{2}-a_{x}^{1})(r_s \mu_s -r_2 \mu_2-c \theta) \geq 0$$
for all  $n\geq 1$ and
$n\geq 1$ and  $x\in \{1,\ldots,N\}$ as long as
$x\in \{1,\ldots,N\}$ as long as  $c \leq {(r_s \mu _s -r_2 \mu _2)}/{\theta }=c_0$.
$c \leq {(r_s \mu _s -r_2 \mu _2)}/{\theta }=c_0$.
Next assume  $\theta \neq \mu _2$. We use induction to prove that
$\theta \neq \mu _2$. We use induction to prove that  $\Delta _n^{a_{x}^{1},a_{x}^{2}}(s)\geq 0$ for all
$\Delta _n^{a_{x}^{1},a_{x}^{2}}(s)\geq 0$ for all  $n\geq 1$,
$n\geq 1$,  $x\in \{1,\ldots,N\}$, and
$x\in \{1,\ldots,N\}$, and  $a_{x}^{1} \lt a_{x}^{2}\in A_{x}$. For
$a_{x}^{1} \lt a_{x}^{2}\in A_{x}$. For  $n=1$ and
$n=1$ and  $x \in \{1,\ldots,N\}$, (3) yields
$x \in \{1,\ldots,N\}$, (3) yields
 \begin{equation} \Delta_1^{a_{x}^{1},a_{x}^{2}}(x) =(a_{x}^{2}-a_{x}^{1})\left[\frac{(r_s\mu_s-r_2\mu_2)(\theta+\mu_1)}{\mu_1+\mu_2}-c\theta\right] \geq 0, \end{equation}
\begin{equation} \Delta_1^{a_{x}^{1},a_{x}^{2}}(x) =(a_{x}^{2}-a_{x}^{1})\left[\frac{(r_s\mu_s-r_2\mu_2)(\theta+\mu_1)}{\mu_1+\mu_2}-c\theta\right] \geq 0, \end{equation}
where the inequality follows since  $c\leq c_0$. Now assume that
$c\leq c_0$. Now assume that  $\Delta _k^{a_{x}^{1},a_{x}^{2}}(x) \geq 0$ for
$\Delta _k^{a_{x}^{1},a_{x}^{2}}(x) \geq 0$ for  $k = 1, \ldots, n-1$,
$k = 1, \ldots, n-1$,  $x \in \{1,\ldots,N\}$ and
$x \in \{1,\ldots,N\}$ and  $a_{x}^{1} \lt a_{x}^{2}$ (i.e., for
$a_{x}^{1} \lt a_{x}^{2}$ (i.e., for  $k = 1, \ldots, n-1$,
$k = 1, \ldots, n-1$,  $v_k(x)=v_k^0(x)$ for all
$v_k(x)=v_k^0(x)$ for all  $x\in \{0,\ldots,N-1\}$ and
$x\in \{0,\ldots,N-1\}$ and  $v_k(N)=v_k^1(N)$ in Theorem 1;
$v_k(N)=v_k^1(N)$ in Theorem 1;  $v_k(N)=v_k^0(N)$ in Remark 2) as long as
$v_k(N)=v_k^0(N)$ in Remark 2) as long as  $c \leq c_0$. We will show that the same assertion holds for
$c \leq c_0$. We will show that the same assertion holds for  $k=n$. From the induction hypothesis, we have
$k=n$. From the induction hypothesis, we have
 $$v_{n-1}(x)=Mr_s \mu_s -xc\theta+(N-x)\mu_1 v_{n-2}(x+1)+x\theta v_{n-2}(x-1)+[1-(N-x)\mu_1-x\theta]v_{n-2}(x)$$
$$v_{n-1}(x)=Mr_s \mu_s -xc\theta+(N-x)\mu_1 v_{n-2}(x+1)+x\theta v_{n-2}(x-1)+[1-(N-x)\mu_1-x\theta]v_{n-2}(x)$$
for  $x \in \{0,\ldots, N-1\}$ (
$x \in \{0,\ldots, N-1\}$ ( $x \in \{0,\ldots, N\}$ in Remark 2), and
$x \in \{0,\ldots, N\}$ in Remark 2), and
 \begin{align*} v_{n-1}(N)& =(M-1)r_s \mu_s +r_2\mu_2-(N-1)c\theta+[(N-1)\theta +\mu_2]v_{n-2}(N-1)\\ & \quad +[1-(N-1)\theta-\mu_2]v_{n-2}(N). \end{align*}
\begin{align*} v_{n-1}(N)& =(M-1)r_s \mu_s +r_2\mu_2-(N-1)c\theta+[(N-1)\theta +\mu_2]v_{n-2}(N-1)\\ & \quad +[1-(N-1)\theta-\mu_2]v_{n-2}(N). \end{align*}
Furthermore, it follows from  $\Delta _{n-1}^{a_{x}^{1},a_{x}^{2}}(x)\geq 0$ and (3) that for
$\Delta _{n-1}^{a_{x}^{1},a_{x}^{2}}(x)\geq 0$ and (3) that for  $x =1,\ldots,N$,
$x =1,\ldots,N$,
 $$r_s \mu_s -r_2 \mu_2-c \theta +(\theta -\mu_2)[v_{n-2}(x-1)-v_{n-2}(x)]\geq 0,$$
$$r_s \mu_s -r_2 \mu_2-c \theta +(\theta -\mu_2)[v_{n-2}(x-1)-v_{n-2}(x)]\geq 0,$$
which implies that
 \begin{equation} (\theta -\mu_2)[v_{n-2}(x-1)-v_{n-2}(x)] \geq{-}r_s \mu_s +r_2 \mu_2+c \theta. \end{equation}
\begin{equation} (\theta -\mu_2)[v_{n-2}(x-1)-v_{n-2}(x)] \geq{-}r_s \mu_s +r_2 \mu_2+c \theta. \end{equation}
Note that for  $x \in \{1,\ldots,N-1\}$ (
$x \in \{1,\ldots,N-1\}$ ( $x \in \{1,\ldots, N\}$ in Remark 2),
$x \in \{1,\ldots, N\}$ in Remark 2),
 \begin{align} v_{n-1}(x-1)-v_{n-1}(x) & =c \theta +(N-x)\mu_1[v_{n-2}(x)-v_{n-2}(x+1)]\nonumber\\ & \quad +(x-1)\theta [v_{n-2}(x-2)-v_{n-2}(x-1)]\nonumber\\ & \quad +[1-(N-x+1)\mu_1-x\theta][v_{n-2}(x-1)-v_{n-2}(x)] \end{align}
\begin{align} v_{n-1}(x-1)-v_{n-1}(x) & =c \theta +(N-x)\mu_1[v_{n-2}(x)-v_{n-2}(x+1)]\nonumber\\ & \quad +(x-1)\theta [v_{n-2}(x-2)-v_{n-2}(x-1)]\nonumber\\ & \quad +[1-(N-x+1)\mu_1-x\theta][v_{n-2}(x-1)-v_{n-2}(x)] \end{align}
and
 \begin{align} v_{n-1}(N-1)-v_{n-1}(N) & =r_s \mu_s -r_2\mu_2+(N-1)\theta [v_{n-2}(N-2)-v_{n-2}(N-1)]\nonumber\\ & \quad +[1-(N-1)\theta-\mu_1-\mu_2][v_{n-2}(N-1)-v_{n-2}(N)]. \end{align}
\begin{align} v_{n-1}(N-1)-v_{n-1}(N) & =r_s \mu_s -r_2\mu_2+(N-1)\theta [v_{n-2}(N-2)-v_{n-2}(N-1)]\nonumber\\ & \quad +[1-(N-1)\theta-\mu_1-\mu_2][v_{n-2}(N-1)-v_{n-2}(N)]. \end{align}
Note that since  $q = N\mu _1+N\theta +M\mu _2$ and we assumed, without loss of generality, that
$q = N\mu _1+N\theta +M\mu _2$ and we assumed, without loss of generality, that  $q=1$, we have that
$q=1$, we have that  $1-(N-x+1)\mu _1-x\theta$ and
$1-(N-x+1)\mu _1-x\theta$ and  $1-(N-1)\theta -\mu _1-\mu _2$ are positive for
$1-(N-1)\theta -\mu _1-\mu _2$ are positive for  $x \in \{1,\ldots,N\}$.
$x \in \{1,\ldots,N\}$.
Observe that the multipliers  $(N-x)\mu _1$ and
$(N-x)\mu _1$ and  $(x-1)\theta$ of
$(x-1)\theta$ of  $v_{n-2}(x) -v_{n-2}(x+1)$ and
$v_{n-2}(x) -v_{n-2}(x+1)$ and  $v_{n-2}(x-2) -v_{n-2}(x-1)$ equal zero when
$v_{n-2}(x-2) -v_{n-2}(x-1)$ equal zero when  $x=N$ and
$x=N$ and  $x=1$, respectively. Equations (5), (6), and (7) yield
$x=1$, respectively. Equations (5), (6), and (7) yield
 \begin{align*} (\theta -\mu_2)[v_{n-1}(x-1)-v_{n-1}(x)] & \geq c\theta(\theta -\mu_2) + (1-\theta-\mu_1){({-}r_s \mu_s +r_2 \mu_2+c \theta)} \\ & ={(1-\mu_1-\mu_2)\theta c}+{(\theta+\mu_1-1)(r_s \mu_s -r_2 \mu_2)} \end{align*}
\begin{align*} (\theta -\mu_2)[v_{n-1}(x-1)-v_{n-1}(x)] & \geq c\theta(\theta -\mu_2) + (1-\theta-\mu_1){({-}r_s \mu_s +r_2 \mu_2+c \theta)} \\ & ={(1-\mu_1-\mu_2)\theta c}+{(\theta+\mu_1-1)(r_s \mu_s -r_2 \mu_2)} \end{align*}
for  $x \in \{1,\ldots,N-1\}$ (
$x \in \{1,\ldots,N-1\}$ ( $x \in \{1,\ldots, N\}$ in Remark 2), and
$x \in \{1,\ldots, N\}$ in Remark 2), and
 \begin{align*} (\theta -\mu_2)[v_{n-1}(N-1)-v_{n-1}(N)]& \geq (\theta -\mu_2)(r_s \mu_s -r_2\mu_2)+(1-\mu_1-\mu_2)({-r_s \mu_s +r_2 \mu_2+c \theta})\\ & ={(1-\mu_1-\mu_2)\theta c}+{(\theta+\mu_1-1)(r_s \mu_s -r_2 \mu_2)}. \end{align*}
\begin{align*} (\theta -\mu_2)[v_{n-1}(N-1)-v_{n-1}(N)]& \geq (\theta -\mu_2)(r_s \mu_s -r_2\mu_2)+(1-\mu_1-\mu_2)({-r_s \mu_s +r_2 \mu_2+c \theta})\\ & ={(1-\mu_1-\mu_2)\theta c}+{(\theta+\mu_1-1)(r_s \mu_s -r_2 \mu_2)}. \end{align*}
Now Eq. (3) yields that for all  $x=1,\ldots,N$ and
$x=1,\ldots,N$ and  $a_{x}^{1} \lt a_{x}^{2} \in A_{x}$,
$a_{x}^{1} \lt a_{x}^{2} \in A_{x}$,
 \begin{align} \Delta_n^{a_{x}^{1},a_{x}^{2}}(x) & \geq (a_{x}^{2}-a_{x}^{1})[r_s \mu_s -r_2 \mu_2-c \theta +(1-\mu_1-\mu_2)\theta c+(\theta+\mu_1-1)(r_s \mu_s -r_2 \mu_2)]\nonumber\\ & =(a_{x}^{2}-a_{x}^{1})[-(\mu_1+\mu_2)c\theta+(\theta+\mu_1)(r_s \mu_s -r_2 \mu_2)]\geq 0 \end{align}
\begin{align} \Delta_n^{a_{x}^{1},a_{x}^{2}}(x) & \geq (a_{x}^{2}-a_{x}^{1})[r_s \mu_s -r_2 \mu_2-c \theta +(1-\mu_1-\mu_2)\theta c+(\theta+\mu_1-1)(r_s \mu_s -r_2 \mu_2)]\nonumber\\ & =(a_{x}^{2}-a_{x}^{1})[-(\mu_1+\mu_2)c\theta+(\theta+\mu_1)(r_s \mu_s -r_2 \mu_2)]\geq 0 \end{align}
as long as  $c\leq c_0$.
$c\leq c_0$.
From (8), we have  $\Delta _n^{a_{x}^{1},a_{x}^{2}}(x) \geq 0$ for all
$\Delta _n^{a_{x}^{1},a_{x}^{2}}(x) \geq 0$ for all  $n \geq 1$,
$n \geq 1$,  $x \in \{1,\ldots,N\}$, and
$x \in \{1,\ldots,N\}$, and  $a_{x}^{1} \lt a_{x}^{2}$ when
$a_{x}^{1} \lt a_{x}^{2}$ when  $c \leq c_0$. Therefore,
$c \leq c_0$. Therefore,  $v_n(x)=v_n^0(x)$ for
$v_n(x)=v_n^0(x)$ for  $x=0,\ldots,N-1$ (
$x=0,\ldots,N-1$ ( $x=0,\ldots,N$ in Remark 2) and
$x=0,\ldots,N$ in Remark 2) and  $v_n(N)=v_n^1(N)$ for all
$v_n(N)=v_n^1(N)$ for all  $n\geq 1$ when
$n\geq 1$ when  $c \leq c_0$. Since we have a finite state space
$c \leq c_0$. Since we have a finite state space  $X$ and
$X$ and  ${A}_{x}$ is finite for all
${A}_{x}$ is finite for all  $x$,
$x$,  $r(x,a_{x})$ is bounded and the model is unichain, there exists a stationary long-run average optimal policy (see [Reference Puterman23], Theorem 8.4.5). Note that from (1) and
$r(x,a_{x})$ is bounded and the model is unichain, there exists a stationary long-run average optimal policy (see [Reference Puterman23], Theorem 8.4.5). Note that from (1) and  $q = N\mu _1+N\theta +M\mu _2=1$, regardless of the action
$q = N\mu _1+N\theta +M\mu _2=1$, regardless of the action  $a_{x}$ chosen in each state
$a_{x}$ chosen in each state  $x$, we have
$x$, we have  $p(x\,|\,x,a_{x}) =1-{[(N-x)\mu _1+(x-a_{x})\theta +a_{x} \mu _2]}/{q}$
$p(x\,|\,x,a_{x}) =1-{[(N-x)\mu _1+(x-a_{x})\theta +a_{x} \mu _2]}/{q}$  $= x\mu _1+(N-x+a_{x})\theta +(M-a_{x})\mu _2 \gt 0$ for
$= x\mu _1+(N-x+a_{x})\theta +(M-a_{x})\mu _2 \gt 0$ for  $\forall x \in X$ and
$\forall x \in X$ and  $a_{x} \in A_{x}$, which indicates that the transition matrix for any feasible stationary policy is aperiodic. Therefore, since the stationary policies are unichain and every optimal policy has an aperiodic transition matrix, it follows from Theorems 8.5.4 and 8.5.6 of Puterman [Reference Puterman23] that for any
$a_{x} \in A_{x}$, which indicates that the transition matrix for any feasible stationary policy is aperiodic. Therefore, since the stationary policies are unichain and every optimal policy has an aperiodic transition matrix, it follows from Theorems 8.5.4 and 8.5.6 of Puterman [Reference Puterman23] that for any  $\epsilon \gt 0$, value iteration will stop after a finite number of iterations with an
$\epsilon \gt 0$, value iteration will stop after a finite number of iterations with an  $\epsilon$-optimal policy. Furthermore, since
$\epsilon$-optimal policy. Furthermore, since  $\epsilon$ is arbitrary and the state and action spaces are finite, an
$\epsilon$ is arbitrary and the state and action spaces are finite, an  $\epsilon$-optimal policy (for
$\epsilon$-optimal policy (for  $\epsilon$ small enough) is indeed an optimal policy.
$\epsilon$ small enough) is indeed an optimal policy.
For part (ii), it follows from the proof of part (i) that  $\Delta _n^{a_{x}^{1},a_{x}^{2}}(x)\leq 0$ for all
$\Delta _n^{a_{x}^{1},a_{x}^{2}}(x)\leq 0$ for all  $n\geq 1$,
$n\geq 1$,  $x\in \{1,\ldots,N\}$, and
$x\in \{1,\ldots,N\}$, and  $a_{x}^{1} \lt a_{x}^{2}\in A_{x}$, when
$a_{x}^{1} \lt a_{x}^{2}\in A_{x}$, when  $c\geq c_0$ and
$c\geq c_0$ and  $\theta = \mu _2$. When
$\theta = \mu _2$. When  $\theta \neq \mu _2$, we again use induction to prove that
$\theta \neq \mu _2$, we again use induction to prove that  $\Delta _n^{a_{x}^{1},a_{x}^{2}}(x)\leq 0$ for all
$\Delta _n^{a_{x}^{1},a_{x}^{2}}(x)\leq 0$ for all  $n\geq 1$,
$n\geq 1$,  $x \in \{1,\ldots,N\}$, and
$x \in \{1,\ldots,N\}$, and  $a_{x}^{1} \lt a_{x}^{2}\in A_{x}$. From (4), we know that
$a_{x}^{1} \lt a_{x}^{2}\in A_{x}$. From (4), we know that  $\Delta _1^{a_{x}^{1},a_{x}^{2}}(x) \leq 0$ for
$\Delta _1^{a_{x}^{1},a_{x}^{2}}(x) \leq 0$ for  $x\in \{ 1,\ldots,N\}$ and
$x\in \{ 1,\ldots,N\}$ and  $a_{x}^{1} \lt a_{x}^{2} \in A_{x}$. Assume that
$a_{x}^{1} \lt a_{x}^{2} \in A_{x}$. Assume that  $\Delta _k^{a_{x}^{1},a_{x}^{2}}(x) \leq 0$ for
$\Delta _k^{a_{x}^{1},a_{x}^{2}}(x) \leq 0$ for  $k = 1, \ldots, n-1$,
$k = 1, \ldots, n-1$,  $x \in \{1,\ldots,N\}$, and
$x \in \{1,\ldots,N\}$, and  $a_{x}^{1} \lt a_{x}^{2}\in A_{x}$. Therefore, we have
$a_{x}^{1} \lt a_{x}^{2}\in A_{x}$. Therefore, we have  $v_{n-1}(x)=v_{n-1}^{\min \{x,M\}}(x)$ for
$v_{n-1}(x)=v_{n-1}^{\min \{x,M\}}(x)$ for  $x \in \{0,\ldots, N\}$.
$x \in \{0,\ldots, N\}$.
Note that from  $\Delta _{n-1}^{a_{x}^{1},a_{x}^{2}}(x)\leq 0$ and (3), for
$\Delta _{n-1}^{a_{x}^{1},a_{x}^{2}}(x)\leq 0$ and (3), for  $x =1,\ldots,N$, we have
$x =1,\ldots,N$, we have
 \begin{equation} (\theta -\mu_2)[v_{n-2}(x-1)-v_{n-2}(x)] \leq{-}r_s \mu_s +r_2 \mu_2+c \theta. \end{equation}
\begin{equation} (\theta -\mu_2)[v_{n-2}(x-1)-v_{n-2}(x)] \leq{-}r_s \mu_s +r_2 \mu_2+c \theta. \end{equation}
Furthermore, for  $x \in \{1,\ldots,N\}$, (2) yields
$x \in \{1,\ldots,N\}$, (2) yields
 \begin{align*} & v_{n-1}(x-1)-v_{n-1}(x)\\ & \quad = v_{n-1}^{\min\{x-1,M\}}(x-1)-v_{n-1}^{\min\{x,M\}}(x)\\ & \quad =(M-\min\{x-1,M\})r_s \mu_s +\min\{x-1,M\}r_2\mu_2 -(x-1-\min\{x-1,M\})c\theta\\ & \qquad +(N-x+1)\mu_1 v_{n-2}(x) +[(x-1-\min\{x-1,M\})\theta+\min\{x-1,M\}\mu_2] v_{n-2}(x-2)\\ & \qquad +[1-(N-x+1)\mu_1-(x-1-\min\{x-1,M\})\theta-\min\{x-1,M\}\mu_2]v_{n-2}(x-1)\\ & \qquad -(M-\min\{x,M\})r_s \mu_s -\min\{x,M\}r_2\mu_2 +(x-\min\{x,M\})c\theta\\ & \qquad -(N-x)\mu_1 v_{n-2}(x+1)-[(x-\min\{x,M\})\theta+\min\{x,M\}\mu_2] v_{n-2}(x-1)\\ & \qquad -[1-(N-x)\mu_1-(x-\min\{x,M\})\theta-\min\{x,M\}\mu_2]v_{n-2}(x)\\ & \quad =c\theta+(r_s\mu_s-r_2\mu_2-c\theta)\times {1}_{\{x\leq M\}}+(N-x)\mu_1[v_{n-2}(x)-v_{n-2}(x+1)]\\ & \qquad +[(x-1-\min\{x-1,M\})\theta+\min\{x-1,M\}\mu_2]\times[v_{n-2}(x-2)-v_{n-2}(x-1)]\\ & \qquad +[1-(N-x+1)\mu_1-(x-\min\{x,M\})\theta-\min\{x,M\}\mu_2]\times[v_{n-2}(x-1)-v_{n-2}(x)], \end{align*}
\begin{align*} & v_{n-1}(x-1)-v_{n-1}(x)\\ & \quad = v_{n-1}^{\min\{x-1,M\}}(x-1)-v_{n-1}^{\min\{x,M\}}(x)\\ & \quad =(M-\min\{x-1,M\})r_s \mu_s +\min\{x-1,M\}r_2\mu_2 -(x-1-\min\{x-1,M\})c\theta\\ & \qquad +(N-x+1)\mu_1 v_{n-2}(x) +[(x-1-\min\{x-1,M\})\theta+\min\{x-1,M\}\mu_2] v_{n-2}(x-2)\\ & \qquad +[1-(N-x+1)\mu_1-(x-1-\min\{x-1,M\})\theta-\min\{x-1,M\}\mu_2]v_{n-2}(x-1)\\ & \qquad -(M-\min\{x,M\})r_s \mu_s -\min\{x,M\}r_2\mu_2 +(x-\min\{x,M\})c\theta\\ & \qquad -(N-x)\mu_1 v_{n-2}(x+1)-[(x-\min\{x,M\})\theta+\min\{x,M\}\mu_2] v_{n-2}(x-1)\\ & \qquad -[1-(N-x)\mu_1-(x-\min\{x,M\})\theta-\min\{x,M\}\mu_2]v_{n-2}(x)\\ & \quad =c\theta+(r_s\mu_s-r_2\mu_2-c\theta)\times {1}_{\{x\leq M\}}+(N-x)\mu_1[v_{n-2}(x)-v_{n-2}(x+1)]\\ & \qquad +[(x-1-\min\{x-1,M\})\theta+\min\{x-1,M\}\mu_2]\times[v_{n-2}(x-2)-v_{n-2}(x-1)]\\ & \qquad +[1-(N-x+1)\mu_1-(x-\min\{x,M\})\theta-\min\{x,M\}\mu_2]\times[v_{n-2}(x-1)-v_{n-2}(x)], \end{align*}
where  ${1}_{\{x\leq M\}}$ is an indicator function defined as
${1}_{\{x\leq M\}}$ is an indicator function defined as
 $${1}_{\{x\leq M\}}= \left\{\begin{array}{ll} 1 & \text{when}\ x\leq M, \\ 0 & \text{when}\ x \gt M. \end{array}\right.$$
$${1}_{\{x\leq M\}}= \left\{\begin{array}{ll} 1 & \text{when}\ x\leq M, \\ 0 & \text{when}\ x \gt M. \end{array}\right.$$
Since  $q =N\mu _1+N\theta +M\mu _2$ and we assumed, without loss of generality, that
$q =N\mu _1+N\theta +M\mu _2$ and we assumed, without loss of generality, that  $q=1$, we have that
$q=1$, we have that  $1-(N-x+1)\mu _1-(x-\min \{x,M\})\theta -\min \{x,M\}\mu _2$ is positive for
$1-(N-x+1)\mu _1-(x-\min \{x,M\})\theta -\min \{x,M\}\mu _2$ is positive for  $x \in \{1,\ldots, N\}$. Therefore, for
$x \in \{1,\ldots, N\}$. Therefore, for  $x \in \{1,\dots,M\}$, (9) yields
$x \in \{1,\dots,M\}$, (9) yields
 \begin{align*} (\theta -\mu_2)[v_{n-1}(x-1)-v_{n-1}(x)] & \leq (\theta -\mu_2)(r_s \mu_s -r_2 \mu_2)+(N-x)\mu_1\times({-}r_s \mu_s +r_2 \mu_2+c \theta)\\ & \quad +(x-1)\mu_2\times({-}r_s \mu_s +r_2 \mu_2+c \theta)\\ & \quad +[1-(N-x+1)\mu_1-x\mu_2]\times({-}r_s \mu_s +r_2 \mu_2+c \theta)\\ & =(\theta -\mu_2)(r_s \mu_s -r_2 \mu_2)+(1-\mu_1-\mu_2)({-}r_s \mu_s +r_2 \mu_2+c \theta)\\ & =(1-\mu_1-\mu_2)c\theta - (1-\mu_1-\theta)(r_s \mu_s -r_2 \mu_2), \end{align*}
\begin{align*} (\theta -\mu_2)[v_{n-1}(x-1)-v_{n-1}(x)] & \leq (\theta -\mu_2)(r_s \mu_s -r_2 \mu_2)+(N-x)\mu_1\times({-}r_s \mu_s +r_2 \mu_2+c \theta)\\ & \quad +(x-1)\mu_2\times({-}r_s \mu_s +r_2 \mu_2+c \theta)\\ & \quad +[1-(N-x+1)\mu_1-x\mu_2]\times({-}r_s \mu_s +r_2 \mu_2+c \theta)\\ & =(\theta -\mu_2)(r_s \mu_s -r_2 \mu_2)+(1-\mu_1-\mu_2)({-}r_s \mu_s +r_2 \mu_2+c \theta)\\ & =(1-\mu_1-\mu_2)c\theta - (1-\mu_1-\theta)(r_s \mu_s -r_2 \mu_2), \end{align*}
and for  $x \in \{M+1,\dots,N\}$, we have
$x \in \{M+1,\dots,N\}$, we have
 \begin{align*} (\theta -\mu_2)[v_{n-1}(x-1)-v_{n-1}(x)] & \leq (\theta -\mu_2)c\theta+(N-x)\mu_1\times({-}r_s \mu_s +r_2 \mu_2+c \theta)\\ & \quad +[(x-1-M)\theta+M\mu_2]\times({-}r_s \mu_s +r_2 \mu_2+c \theta)\\ & \quad +[1-(N-x+1)\mu_1-(x-M)\theta-M\mu_2]\times({-}r_s \mu_s +r_2 \mu_2+c \theta)\\ & = (\theta -\mu_2)c\theta+(1-\mu_1-\theta)({-}r_s \mu_s +r_2 \mu_2+c \theta)\\ & =(1-\mu_1-\mu_2)c\theta - (1-\mu_1-\theta)(r_s \mu_s -r_2 \mu_2). \end{align*}
\begin{align*} (\theta -\mu_2)[v_{n-1}(x-1)-v_{n-1}(x)] & \leq (\theta -\mu_2)c\theta+(N-x)\mu_1\times({-}r_s \mu_s +r_2 \mu_2+c \theta)\\ & \quad +[(x-1-M)\theta+M\mu_2]\times({-}r_s \mu_s +r_2 \mu_2+c \theta)\\ & \quad +[1-(N-x+1)\mu_1-(x-M)\theta-M\mu_2]\times({-}r_s \mu_s +r_2 \mu_2+c \theta)\\ & = (\theta -\mu_2)c\theta+(1-\mu_1-\theta)({-}r_s \mu_s +r_2 \mu_2+c \theta)\\ & =(1-\mu_1-\mu_2)c\theta - (1-\mu_1-\theta)(r_s \mu_s -r_2 \mu_2). \end{align*}
Now for all  $x=1,\ldots,N$ and
$x=1,\ldots,N$ and  $a_{x}^{1} \lt a_{x}^{2} \in A_s$, Eq. (3) yields that
$a_{x}^{1} \lt a_{x}^{2} \in A_s$, Eq. (3) yields that
 \begin{align} \Delta_n^{a_{x}^{1},a_{x}^{2}}(x) & \leq (a_{x}^{2}-a_{x}^{1})[r_s \mu_s -r_2 \mu_2-c \theta +(1-\mu_1-\mu_2)c\theta -(1-\mu_1-\theta)(r_s \mu_s -r_2 \mu_2)]\nonumber\\ & =(a_{x}^{2}-a_{x}^{1})[-(\mu_1+\mu_2)c\theta+(\theta+\mu_1)(r_s \mu_s -r_2 \mu_2)]\leq 0 \end{align}
\begin{align} \Delta_n^{a_{x}^{1},a_{x}^{2}}(x) & \leq (a_{x}^{2}-a_{x}^{1})[r_s \mu_s -r_2 \mu_2-c \theta +(1-\mu_1-\mu_2)c\theta -(1-\mu_1-\theta)(r_s \mu_s -r_2 \mu_2)]\nonumber\\ & =(a_{x}^{2}-a_{x}^{1})[-(\mu_1+\mu_2)c\theta+(\theta+\mu_1)(r_s \mu_s -r_2 \mu_2)]\leq 0 \end{align}
as long as  $c\geq c_0$.
$c\geq c_0$.
Equation (10) shows that  $\Delta _n^{a_{x}^{1},a_{x}^{2}}(x) \leq 0$ for all
$\Delta _n^{a_{x}^{1},a_{x}^{2}}(x) \leq 0$ for all  $n \geq 1, x \in \{1,\ldots,N\}$, and
$n \geq 1, x \in \{1,\ldots,N\}$, and  $a_{x}^{1} \lt a_{x}^{2} \in A_{x}$ when
$a_{x}^{1} \lt a_{x}^{2} \in A_{x}$ when  $c \geq c_0$. Therefore, we have
$c \geq c_0$. Therefore, we have  $v_n(x)=v_n^{\min \{x,M\}}(x)$ for all
$v_n(x)=v_n^{\min \{x,M\}}(x)$ for all  $x \in \{0,\ldots,N\}$. The remaining proof of part (ii) regarding the
$x \in \{0,\ldots,N\}$. The remaining proof of part (ii) regarding the  $\epsilon$-optimality of the policy generated from value iteration is identical to the corresponding arguments in part (i).
$\epsilon$-optimality of the policy generated from value iteration is identical to the corresponding arguments in part (i).
The threshold  $c_0$ increases in
$c_0$ increases in  $r_s$,
$r_s$,  $\mu _s$ and decreases in
$\mu _s$ and decreases in  $r_2$,
$r_2$,  $\mu _2$. That is to say, the threshold on the abandonment cost where the supervisors switch from focusing on their own responsibilities to focusing on the customers increases with the rewards and processing rate of the supervisor on their own responsibilities, and decreases when the rewards or processing rate of the supervisors on the customers increase. This is because larger
$\mu _2$. That is to say, the threshold on the abandonment cost where the supervisors switch from focusing on their own responsibilities to focusing on the customers increases with the rewards and processing rate of the supervisor on their own responsibilities, and decreases when the rewards or processing rate of the supervisors on the customers increase. This is because larger  $r_s$,
$r_s$,  $\mu _s$ and smaller
$\mu _s$ and smaller  $r_2$,
$r_2$,  $\mu _2$ all imply relatively greater rewards when the supervisors are working on their own responsibilities. The fact that
$\mu _2$ all imply relatively greater rewards when the supervisors are working on their own responsibilities. The fact that  $c_0$ does not depend on
$c_0$ does not depend on  $M,N$ reflects the linearity of the rewards and lack of switching times and costs, as well as the fact that each supervisor's choices on whether to work with a subordinate or not has limited immediate impact on other supervisors and subordinates.
$M,N$ reflects the linearity of the rewards and lack of switching times and costs, as well as the fact that each supervisor's choices on whether to work with a subordinate or not has limited immediate impact on other supervisors and subordinates.
Moreover, when  $r_s\mu _s \gt r_2\mu _2$, i.e.,
$r_s\mu _s \gt r_2\mu _2$, i.e.,  $\pi ^{\mathcal {C}}$ is ineffective from the perspective of immediate revenue, then
$\pi ^{\mathcal {C}}$ is ineffective from the perspective of immediate revenue, then  $c_0$ decreases when
$c_0$ decreases when  $\theta$ increases. This means that when the supervisors earn greater rewards per unit time working on their own responsibilities, then as the abandonment rate
$\theta$ increases. This means that when the supervisors earn greater rewards per unit time working on their own responsibilities, then as the abandonment rate  $\theta$ increases, the supervisors switch from prioritizing their own responsibilities to prioritizing customers earlier (for lower abandonment costs). The condition
$\theta$ increases, the supervisors switch from prioritizing their own responsibilities to prioritizing customers earlier (for lower abandonment costs). The condition  $\mu _2 \gt \theta$ determines whether the rate of supervisors finishing the second-stage is larger than the abandonment rate. Therefore, if
$\mu _2 \gt \theta$ determines whether the rate of supervisors finishing the second-stage is larger than the abandonment rate. Therefore, if  $\mu _2 \gt \theta$, then
$\mu _2 \gt \theta$, then  $\pi ^{\mathcal {C}}$ is effective in reducing future abandonments. If
$\pi ^{\mathcal {C}}$ is effective in reducing future abandonments. If  $\mu _2 \lt \theta$, then
$\mu _2 \lt \theta$, then  $c_0$ decreases in
$c_0$ decreases in  $\mu _1$. In this case,
$\mu _1$. In this case,  $\pi ^{\mathcal {C}}$ is ineffective in both increasing immediate revenue and reducing future abandonments, and if
$\pi ^{\mathcal {C}}$ is ineffective in both increasing immediate revenue and reducing future abandonments, and if  $\pi ^{\mathcal {C}}$ is optimal for a particular
$\pi ^{\mathcal {C}}$ is optimal for a particular  $\mu _1$, then Policy
$\mu _1$, then Policy  $\pi ^{\mathcal {C}}$ will remain optimal for a larger
$\pi ^{\mathcal {C}}$ will remain optimal for a larger  $\mu _1$. However, if
$\mu _1$. However, if  $\mu _2 \gt \theta$, then
$\mu _2 \gt \theta$, then  $c_0$ increases in
$c_0$ increases in  $\mu _1$. In this case,
$\mu _1$. In this case,  $\pi ^{\mathcal {C}}$ is of mixed effectiveness in improving immediate revenue and reducing future abandonments, and if
$\pi ^{\mathcal {C}}$ is of mixed effectiveness in improving immediate revenue and reducing future abandonments, and if  $\pi ^{\mathcal {S}}$ is optimal for a particular
$\pi ^{\mathcal {S}}$ is optimal for a particular  $\mu _1$, then Policy
$\mu _1$, then Policy  $\pi ^{\mathcal {S}}$ will remain optimal for a larger
$\pi ^{\mathcal {S}}$ will remain optimal for a larger  $\mu _1$.
$\mu _1$.
When  $r_s\mu _s \lt r_2\mu _2$, i.e.,
$r_s\mu _s \lt r_2\mu _2$, i.e.,  $c_0$ is negative, then
$c_0$ is negative, then  $c_0$ increases in
$c_0$ increases in  $\theta$. When
$\theta$. When  $c_0$ is negative,
$c_0$ is negative,  $\pi ^{\mathcal {C}}$ is always optimal if there is a cost when a customer leaves the system without the second-stage service. However, when there is a reward for each customer leaving the system with the completion of the first-stage service only, an increase in the abandonment rate can lead supervisors to switch to serving the customers earlier (for lower abandonment rewards). If
$\pi ^{\mathcal {C}}$ is always optimal if there is a cost when a customer leaves the system without the second-stage service. However, when there is a reward for each customer leaving the system with the completion of the first-stage service only, an increase in the abandonment rate can lead supervisors to switch to serving the customers earlier (for lower abandonment rewards). If  $\mu _2 \gt \theta$, then
$\mu _2 \gt \theta$, then  $c_0$ decreases in
$c_0$ decreases in  $\mu _1$ and if
$\mu _1$ and if  $\mu _2 \lt \theta$, then
$\mu _2 \lt \theta$, then  $c_0$ increases in
$c_0$ increases in  $\mu _1$. This is because if
$\mu _1$. This is because if  $r_s\mu _s \lt r_2\mu _2$ and
$r_s\mu _s \lt r_2\mu _2$ and  $\mu _2 \gt \theta$, then Policy
$\mu _2 \gt \theta$, then Policy  $\pi ^{\mathcal {C}}$ is effective in both increasing immediate revenues and reducing future abandonments, which leads to the conclusion that when Policy
$\pi ^{\mathcal {C}}$ is effective in both increasing immediate revenues and reducing future abandonments, which leads to the conclusion that when Policy  $\pi ^{\mathcal {C}}$ is optimal for a specific
$\pi ^{\mathcal {C}}$ is optimal for a specific  $\mu _1$, it will remain optimal for larger
$\mu _1$, it will remain optimal for larger  $\mu _1$. Conversely, if
$\mu _1$. Conversely, if  $r_s\mu _s \lt r_2\mu _2$ and
$r_s\mu _s \lt r_2\mu _2$ and  $\mu _2 \lt \theta$, then Policy
$\mu _2 \lt \theta$, then Policy  $\pi ^{\mathcal {C}}$ is effective in increasing immediate revenues but ineffective in reducing future abandonments. In this case, if
$\pi ^{\mathcal {C}}$ is effective in increasing immediate revenues but ineffective in reducing future abandonments. In this case, if  $\pi ^{\mathcal {S}}$ is optimal for a particular
$\pi ^{\mathcal {S}}$ is optimal for a particular  $\mu _1$, then Policy
$\mu _1$, then Policy  $\pi ^{\mathcal {S}}$ will remain optimal for a larger
$\pi ^{\mathcal {S}}$ will remain optimal for a larger  $\mu _1$.
$\mu _1$.
Remark 3. If  $c=0$, the two extreme policies are still optimal. In particular, if
$c=0$, the two extreme policies are still optimal. In particular, if  $r_s \mu _s - r_2 \mu _2 \geq 0$, supervisors prioritize their own responsibilities; otherwise, they prioritize the customers. Thus, if there is no abandonment cost, the supervisors will focus on optimizing immediate revenue whenever they can.
$r_s \mu _s - r_2 \mu _2 \geq 0$, supervisors prioritize their own responsibilities; otherwise, they prioritize the customers. Thus, if there is no abandonment cost, the supervisors will focus on optimizing immediate revenue whenever they can.
Remark 4. If  $r_s \mu _s -r_2 \mu _2 = 0$, i.e.,
$r_s \mu _s -r_2 \mu _2 = 0$, i.e.,  $c_0 = 0$, the optimality of
$c_0 = 0$, the optimality of  $\pi ^{\mathcal {S}}$ (
$\pi ^{\mathcal {S}}$ ( $\pi ^{\mathcal {C}}$) depends on the whether
$\pi ^{\mathcal {C}}$) depends on the whether  $c$ is negative (positive) only. When
$c$ is negative (positive) only. When  $r_s \mu _s =r_2 \mu _2$, the rewards per unit time do not depend on the chosen action. Therefore, the optimal assignment of the supervisors only depends on whether there is a cost or a reward when a customer leaves the system without the second-stage service.
$r_s \mu _s =r_2 \mu _2$, the rewards per unit time do not depend on the chosen action. Therefore, the optimal assignment of the supervisors only depends on whether there is a cost or a reward when a customer leaves the system without the second-stage service.
The next corollary specifies the optimal policy when the abandonment rate  $\theta$ is small or large.
$\theta$ is small or large.
Corollary 5. When  $\theta \searrow 0$,
$\theta \searrow 0$,  $\pi ^{\mathcal {S}}$ is optimal if
$\pi ^{\mathcal {S}}$ is optimal if  $r_s \mu _s -r_2 \mu _2 \gt 0$ and
$r_s \mu _s -r_2 \mu _2 \gt 0$ and  $\pi ^{\mathcal {C}}$ is optimal if
$\pi ^{\mathcal {C}}$ is optimal if  $r_s \mu _s -r_2 \mu _2 \lt 0$. When
$r_s \mu _s -r_2 \mu _2 \lt 0$. When  $\theta \nearrow \infty$,
$\theta \nearrow \infty$,  $\pi ^{\mathcal {S}}$ is optimal if
$\pi ^{\mathcal {S}}$ is optimal if  $c \leq {(r_s \mu _s -r_2 \mu _2)}/{(\mu _1+\mu _2)}$ and
$c \leq {(r_s \mu _s -r_2 \mu _2)}/{(\mu _1+\mu _2)}$ and  $\pi ^{\mathcal {C}}$ is optimal if
$\pi ^{\mathcal {C}}$ is optimal if  $c \geq {(r_s \mu _s -r_2 \mu _2)}/{(\mu _1+\mu _2)}$.
$c \geq {(r_s \mu _s -r_2 \mu _2)}/{(\mu _1+\mu _2)}$.
Proof. Theorem 1 introduces optimal policies with a threshold  $c_0$ on
$c_0$ on  $c$. We have
$c$. We have
 $$c_0=\frac{(r_s \mu_s -r_2 \mu_2)(\theta+\mu_1)}{(\mu_1+\mu_2)\theta}\nonumber=\frac{r_s \mu_s -r_2 \mu_2}{\mu_1+\mu_2}+\frac{(r_s \mu_s -r_2 \mu_2)\mu_1}{(\mu_1+\mu_2)\theta},$$
$$c_0=\frac{(r_s \mu_s -r_2 \mu_2)(\theta+\mu_1)}{(\mu_1+\mu_2)\theta}\nonumber=\frac{r_s \mu_s -r_2 \mu_2}{\mu_1+\mu_2}+\frac{(r_s \mu_s -r_2 \mu_2)\mu_1}{(\mu_1+\mu_2)\theta},$$
which leads to:
 $$\lim_{\theta \rightarrow 0} c_0 = \left\{\begin{array}{ll} +\infty & \text{when}\ r_s \mu_s -r_2 \mu_2 \gt 0, \\ 0 & \text{when}\ r_s \mu_s -r_2 \mu_2 =0,\\ -\infty & \text{when}\ r_s \mu_s -r_2 \mu_2 \lt 0, \end{array}\right.\quad \lim_{\theta \rightarrow \infty} c_0 =\frac{r_s \mu_s -r_2 \mu_2}{\mu_1+\mu_2}.$$
$$\lim_{\theta \rightarrow 0} c_0 = \left\{\begin{array}{ll} +\infty & \text{when}\ r_s \mu_s -r_2 \mu_2 \gt 0, \\ 0 & \text{when}\ r_s \mu_s -r_2 \mu_2 =0,\\ -\infty & \text{when}\ r_s \mu_s -r_2 \mu_2 \lt 0, \end{array}\right.\quad \lim_{\theta \rightarrow \infty} c_0 =\frac{r_s \mu_s -r_2 \mu_2}{\mu_1+\mu_2}.$$
Corollary 5 indicates that when the abandonment rate approaches 0, the optimal policy (whether a supervisor prioritizes her own responsibilities or serving customers) will maximize the immediate reward associated with the action. On the other hand, when the abandonment rate approaches infinity, the optimal policy still depends on how the abandonment cost  $c$ compares with a threshold. To better understand the value of the threshold, consider the case where
$c$ compares with a threshold. To better understand the value of the threshold, consider the case where  $N \gt M =1$ as an example. When
$N \gt M =1$ as an example. When  $\pi ^{\mathcal {S}}$ is adopted, in the limit all customers will abandon and the long-run average reward of the system approaches
$\pi ^{\mathcal {S}}$ is adopted, in the limit all customers will abandon and the long-run average reward of the system approaches  $r_s\mu _s-Nc\mu _1$. When
$r_s\mu _s-Nc\mu _1$. When  $\pi ^{\mathcal {C}}$ is adopted, in the limit the system behaves as a birth-death process with states 0, 1, birth rate
$\pi ^{\mathcal {C}}$ is adopted, in the limit the system behaves as a birth-death process with states 0, 1, birth rate  $N\mu _1$, death rate
$N\mu _1$, death rate  $\mu _2$, and the long-run average reward approaches
$\mu _2$, and the long-run average reward approaches  ${(\mu _2r_s\mu _s+N\mu _1[r_2\mu _2-(N-1)c\mu _1])}/{(\mu _2+N\mu _1)}$. The comparison of the long-run average rewards of the two systems leads to a threshold of
${(\mu _2r_s\mu _s+N\mu _1[r_2\mu _2-(N-1)c\mu _1])}/{(\mu _2+N\mu _1)}$. The comparison of the long-run average rewards of the two systems leads to a threshold of  ${(r_s \mu _s -r_2 \mu _2)}/{(\mu _1+\mu _2)}$ for the parameter
${(r_s \mu _s -r_2 \mu _2)}/{(\mu _1+\mu _2)}$ for the parameter  $c$.
$c$.
The next proposition shows the closed-form expressions of the gains for policies  $\pi ^{\mathcal {S}}$ and
$\pi ^{\mathcal {S}}$ and  $\pi ^{\mathcal {C}}$.
$\pi ^{\mathcal {C}}$.
Proposition 6. For  $1 \leq M \leq N$, the gains of
$1 \leq M \leq N$, the gains of  $\pi ^{\mathcal {S}}$ and
$\pi ^{\mathcal {S}}$ and  $\pi ^{\mathcal {C}}$ are
$\pi ^{\mathcal {C}}$ are
 \begin{equation} g_{N,M}^{\pi^{\mathcal{S}}} = \frac{\begin{array}{c} \sum_{j=0}^{N-1}{N \choose j}\theta^{N-j}\mu_1^j[\mu_2+(N-1)\theta](Mr_s \mu_s-jc\theta)\\ +N\theta\mu_1^N[(M-1)r_s \mu_s+r_2 \mu_2-(N-1)c\theta] \end{array}}{(\theta+\mu_1)^N [{\mu_2+(N-1)\theta}]+\mu_1^N ({\theta -\mu_2})}\end{equation}
\begin{equation} g_{N,M}^{\pi^{\mathcal{S}}} = \frac{\begin{array}{c} \sum_{j=0}^{N-1}{N \choose j}\theta^{N-j}\mu_1^j[\mu_2+(N-1)\theta](Mr_s \mu_s-jc\theta)\\ +N\theta\mu_1^N[(M-1)r_s \mu_s+r_2 \mu_2-(N-1)c\theta] \end{array}}{(\theta+\mu_1)^N [{\mu_2+(N-1)\theta}]+\mu_1^N ({\theta -\mu_2})}\end{equation}
and
 \begin{align} g_{N,M}^{\pi^{\mathcal{C}}} & = \frac{1}{\sum_{k=0}^M {N \choose k}(\frac{\mu_1}{\mu_2})^k+\sum_{k=M+1}^{N} \frac{\prod_{i=1}^k[(N+1-i)\mu_1]}{M!\mu_2^M(\Pi_{l=M+1}^k[M\mu_2+(l-M)\theta])}}\nonumber\\ & \quad \times \left\{ \sum_{k=0}^M {N \choose k}\left(\frac{\mu_1}{\mu_2}\right)^k[(M-k)r_s\mu_s+kr_2\mu_2]\right.\nonumber\\ & \quad \left.+\sum_{k=M+1}^{N} \frac{\prod_{i=1}^k[(N+1-i)\mu_1]}{M!\mu_2^M\Pi_{l=M+1}^k[M\mu_2+(l-M)\theta]} [Mr_2\mu_2-(k-M)c\theta]\right\}, \end{align}
\begin{align} g_{N,M}^{\pi^{\mathcal{C}}} & = \frac{1}{\sum_{k=0}^M {N \choose k}(\frac{\mu_1}{\mu_2})^k+\sum_{k=M+1}^{N} \frac{\prod_{i=1}^k[(N+1-i)\mu_1]}{M!\mu_2^M(\Pi_{l=M+1}^k[M\mu_2+(l-M)\theta])}}\nonumber\\ & \quad \times \left\{ \sum_{k=0}^M {N \choose k}\left(\frac{\mu_1}{\mu_2}\right)^k[(M-k)r_s\mu_s+kr_2\mu_2]\right.\nonumber\\ & \quad \left.+\sum_{k=M+1}^{N} \frac{\prod_{i=1}^k[(N+1-i)\mu_1]}{M!\mu_2^M\Pi_{l=M+1}^k[M\mu_2+(l-M)\theta]} [Mr_2\mu_2-(k-M)c\theta]\right\}, \end{align}
respectively (with the convention that the summation over an empty set is 0).
Proof. The long-run average rewards  $g_{N,M}^{\pi ^{\mathcal {C}}}$ and
$g_{N,M}^{\pi ^{\mathcal {C}}}$ and  $g_{N,M}^{\pi ^{\mathcal {S}}}$ can be computed using the birth-death structure of the underlying Markov chains under
$g_{N,M}^{\pi ^{\mathcal {S}}}$ can be computed using the birth-death structure of the underlying Markov chains under  $\pi ^{\mathcal {C}}$ and
$\pi ^{\mathcal {C}}$ and  $\pi ^{\mathcal {S}}$, respectively. Specifically, the closed-form expression of the gain (long-run average reward) for any specific policy can be uniquely determined by
$\pi ^{\mathcal {S}}$, respectively. Specifically, the closed-form expression of the gain (long-run average reward) for any specific policy can be uniquely determined by
 \begin{equation} g_{N,M}^\pi = \sum_{x=0}^N \eta_x^\pi r(x,d_{\pi}({x}))q, \end{equation}
\begin{equation} g_{N,M}^\pi = \sum_{x=0}^N \eta_x^\pi r(x,d_{\pi}({x}))q, \end{equation}
where  $\eta _x^\pi$ is the limiting probability of
$\eta _x^\pi$ is the limiting probability of  $\{\mathcal {X}_\pi (t)\}$ being in state
$\{\mathcal {X}_\pi (t)\}$ being in state  $x$ under policy
$x$ under policy  $\pi$.
$\pi$.
Let  $\pmb {\eta }^\pi$ denote the limiting probability vector under policy
$\pmb {\eta }^\pi$ denote the limiting probability vector under policy  $\pi$. The limiting probabilities can be obtained by solving the set of equations
$\pi$. The limiting probabilities can be obtained by solving the set of equations  $\eta _x^\pi [\sum _{k \neq x} q_\pi (x,k)] =\sum _{k \neq x} \eta _k^\pi q_\pi (k,x)$ for all
$\eta _x^\pi [\sum _{k \neq x} q_\pi (x,k)] =\sum _{k \neq x} \eta _k^\pi q_\pi (k,x)$ for all  $x \in X$, along with the equation
$x \in X$, along with the equation  $\sum _{k=0}^N \eta _k^\pi =1$.
$\sum _{k=0}^N \eta _k^\pi =1$.
Therefore, for policy  $\pi ^{\mathcal {S}}$, we have
$\pi ^{\mathcal {S}}$, we have
 \begin{equation} \eta^{\pi^{\mathcal{S}}}_x = \left\{\begin{array}{ll} \dfrac{{N \choose x}\theta^{N-x}\mu_1^x[\mu_2+(N-1)\theta]}{\sum_{j=0}^{N-1}{N \choose j}\theta^{N-j}\mu_1^j[\mu_2+(N-1)\theta]+N\theta\mu_1^N} & \text{for}\ x=0,\ldots,N-1, \\ \dfrac{N\theta\mu_1^N}{\sum_{j=0}^{N-1}{N \choose j}\theta^{N-j}\mu_1^j[\mu_2+(N-1)\theta]+N\theta\mu_1^N} & \text{for}\ x=N, \end{array}\right.\end{equation}
\begin{equation} \eta^{\pi^{\mathcal{S}}}_x = \left\{\begin{array}{ll} \dfrac{{N \choose x}\theta^{N-x}\mu_1^x[\mu_2+(N-1)\theta]}{\sum_{j=0}^{N-1}{N \choose j}\theta^{N-j}\mu_1^j[\mu_2+(N-1)\theta]+N\theta\mu_1^N} & \text{for}\ x=0,\ldots,N-1, \\ \dfrac{N\theta\mu_1^N}{\sum_{j=0}^{N-1}{N \choose j}\theta^{N-j}\mu_1^j[\mu_2+(N-1)\theta]+N\theta\mu_1^N} & \text{for}\ x=N, \end{array}\right.\end{equation}
and for policy  $\pi ^{\mathcal {C}}$, we have
$\pi ^{\mathcal {C}}$, we have
 \begin{equation} \eta^{\pi^{\mathcal{C}}}_x = \left\{\begin{array}{ll} \dfrac{{N \choose x}(\dfrac{\mu_1}{\mu_2})^x}{\sum_{k=0}^M {N \choose k}(\dfrac{\mu_1}{\mu_2})^k+\sum_{k=M+1}^{N} \dfrac{\prod_{i=1}^k[(N+1-i)\mu_1]}{M!\mu_2^M(\Pi_{l=M+1}^k[M\mu_2+(l-M)\theta])}} & \text{for}\ x=0,\ldots,M, \\ \dfrac{\dfrac{\prod_{i=1}^x[(N+1-i)\mu_1]}{M!\mu_2^M(\Pi_{l=M+1}^x[M\mu_2+(l-M)\theta])}}{\sum_{k=0}^M {N \choose k}(\dfrac{\mu_1}{\mu_2})^k+\sum_{k=M+1}^{N} \dfrac{\prod_{i=1}^k[(N+1-i)\mu_1]}{M!\mu_2^M(\Pi_{l=M+1}^k[M\mu_2+(l-M)\theta])}} & \text{for}\ x=M+1,\ldots,N. \end{array}\right.\end{equation}
\begin{equation} \eta^{\pi^{\mathcal{C}}}_x = \left\{\begin{array}{ll} \dfrac{{N \choose x}(\dfrac{\mu_1}{\mu_2})^x}{\sum_{k=0}^M {N \choose k}(\dfrac{\mu_1}{\mu_2})^k+\sum_{k=M+1}^{N} \dfrac{\prod_{i=1}^k[(N+1-i)\mu_1]}{M!\mu_2^M(\Pi_{l=M+1}^k[M\mu_2+(l-M)\theta])}} & \text{for}\ x=0,\ldots,M, \\ \dfrac{\dfrac{\prod_{i=1}^x[(N+1-i)\mu_1]}{M!\mu_2^M(\Pi_{l=M+1}^x[M\mu_2+(l-M)\theta])}}{\sum_{k=0}^M {N \choose k}(\dfrac{\mu_1}{\mu_2})^k+\sum_{k=M+1}^{N} \dfrac{\prod_{i=1}^k[(N+1-i)\mu_1]}{M!\mu_2^M(\Pi_{l=M+1}^k[M\mu_2+(l-M)\theta])}} & \text{for}\ x=M+1,\ldots,N. \end{array}\right.\end{equation}
By plugging Eqs. (14) ((15)) and the corresponding rewards  $r(x,d_{\pi ^{\mathcal {S}}}({x}))$ (
$r(x,d_{\pi ^{\mathcal {S}}}({x}))$ ( $r(x,d_{\pi ^{\mathcal {C}}}({x}))$) into (13), we can obtain the gains of
$r(x,d_{\pi ^{\mathcal {C}}}({x}))$) into (13), we can obtain the gains of  $\pi ^{\mathcal {S}}$ (
$\pi ^{\mathcal {S}}$ ( $\pi ^{\mathcal {C}}$).
$\pi ^{\mathcal {C}}$).
Until now, we have assumed that customers will not abandon while they are receiving (first- or second-stage) service. This is motivated by service applications where it is unlikely that customers will abandon when in service. However, there are situations where abandonments may occur during the service (e.g., in healthcare applications).
The next corollary extends Theorem 1 to the case where abandonments can also occur during the first- and second-stage service. In particular, the corollary show that the structure of the optimal threshold policy remains the same when abandonments can also occur during service. Let  $\theta _1$ (
$\theta _1$ ( $\theta _2$) denote the abandonment rate during the first-stage (second-stage) service and
$\theta _2$) denote the abandonment rate during the first-stage (second-stage) service and  $c_1$ (
$c_1$ ( $c_2$) denote the corresponding abandonment cost. Note that
$c_2$) denote the corresponding abandonment cost. Note that  $\theta _1$,
$\theta _1$,  $\theta _2$ or
$\theta _2$ or  $c_1$,
$c_1$,  $c_2$ do not necessarily equal
$c_2$ do not necessarily equal  $\theta$ or
$\theta$ or  $c$. Then, one of
$c$. Then, one of  $\pi ^{\mathcal {C}}$ and
$\pi ^{\mathcal {C}}$ and  $\pi ^{\mathcal {S}}$ is always optimal, but the threshold on the value of
$\pi ^{\mathcal {S}}$ is always optimal, but the threshold on the value of  $c$ is different.
$c$ is different.
Corollary 7. When abandonments can also occur during the first- and second-stage service,
(i) if
$c \leq c_0^\prime := \frac {c_1\theta _1(\mu _2+\theta _2-\theta )+(r_s \mu _s -r_2 \mu _2+c_2\theta _2)(\theta +\mu _1)}{(\mu _1+\mu _2+\theta _2)\theta }$, then $\pi ^{\mathcal {S}}$ is optimal;(ii) if
$c \geq c_0^{\prime }$, then $\pi ^{\mathcal {C}}$ is optimal.




The proof of Corollary 7 follows similar techniques as the proof of Theorem 1 by setting
 $$v_0(x)=(N-x-1)\times \frac{r_s\mu_s-r_2\mu_2+c_2\theta_2-c_1\theta_1}{\mu_1+\mu_2+\theta_2}.$$
$$v_0(x)=(N-x-1)\times \frac{r_s\mu_s-r_2\mu_2+c_2\theta_2-c_1\theta_1}{\mu_1+\mu_2+\theta_2}.$$
Alternatively, the new threshold can be obtained in an intuitive way as follows. Note that when abandonments can also occur during the first- and second-stage service, the birth rates in Figure 1 remain the same, while the death rate in state  $x \in \{1,\ldots,N\}$ is now
$x \in \{1,\ldots,N\}$ is now  $(x-a_x)\theta + a_x(\mu _2+\theta _2)$ due to the abandonments that may take place during the second-stage service. Similarly, the immediate reward of the second-stage service is now
$(x-a_x)\theta + a_x(\mu _2+\theta _2)$ due to the abandonments that may take place during the second-stage service. Similarly, the immediate reward of the second-stage service is now  $r_2 \times {\mu _2}/{(\mu _2+\theta _2)}-c_2\times {\theta _2}/{(\mu _2+\theta _2)}$. Moreover, for state
$r_2 \times {\mu _2}/{(\mu _2+\theta _2)}-c_2\times {\theta _2}/{(\mu _2+\theta _2)}$. Moreover, for state  $x \in \{1,\ldots,N\}$, the costs from the first-stage abandonments are
$x \in \{1,\ldots,N\}$, the costs from the first-stage abandonments are  $(N-x)c_1\theta _1$ per unit time. That is to say, the immediate reward
$(N-x)c_1\theta _1$ per unit time. That is to say, the immediate reward  $r(x,a_x)$ of choosing action
$r(x,a_x)$ of choosing action  $a_x$ in state
$a_x$ in state  $x$ now is
$x$ now is
 \begin{align*} r(x,a_x) & = \frac{(M-a_x) r_s \mu_s+a_x (r_2 \times \frac{\mu_2}{\mu_2+\theta_2}-c_2\times \frac{\theta_2}{\mu_2+\theta_2})(\mu_2+\theta_2) -(x-a_x)c\theta - (N-x)c_1\theta_1}{q} \\ & =\frac{(M-a_x) r_s \mu_s+a_x (\frac{r_2\mu_2}{\mu_2+\theta_2} + \frac{c_1\theta_1}{\mu_2+\theta_2}-\frac{c_2\theta_2}{\mu_2+\theta_2} )(\mu_2+\theta_2)-(x-a_x)(c-\frac{c_1\theta_1}{\theta})\theta - Nc_1\theta_1}{q}. \end{align*}
\begin{align*} r(x,a_x) & = \frac{(M-a_x) r_s \mu_s+a_x (r_2 \times \frac{\mu_2}{\mu_2+\theta_2}-c_2\times \frac{\theta_2}{\mu_2+\theta_2})(\mu_2+\theta_2) -(x-a_x)c\theta - (N-x)c_1\theta_1}{q} \\ & =\frac{(M-a_x) r_s \mu_s+a_x (\frac{r_2\mu_2}{\mu_2+\theta_2} + \frac{c_1\theta_1}{\mu_2+\theta_2}-\frac{c_2\theta_2}{\mu_2+\theta_2} )(\mu_2+\theta_2)-(x-a_x)(c-\frac{c_1\theta_1}{\theta})\theta - Nc_1\theta_1}{q}. \end{align*}
By ignoring the  ${Nc_1\theta _1}/{q}$ term as it is constant in
${Nc_1\theta _1}/{q}$ term as it is constant in  $x$, replacing the
$x$, replacing the  $r_2$ term in
$r_2$ term in  $c_0$ by
$c_0$ by  ${r_2\mu _2}/{(\mu _2+\theta _2)} + {c_1\theta _1}/{(\mu _2+\theta _2)}-{c_2\theta _2}/{(\mu _2+\theta _2)}$, replacing the
${r_2\mu _2}/{(\mu _2+\theta _2)} + {c_1\theta _1}/{(\mu _2+\theta _2)}-{c_2\theta _2}/{(\mu _2+\theta _2)}$, replacing the  $c$ term by
$c$ term by  $c-{c_1\theta _1}/{\theta }$, replacing the
$c-{c_1\theta _1}/{\theta }$, replacing the  $\mu _2$ term by
$\mu _2$ term by  $\mu _2+\theta _2$, and replacing the
$\mu _2+\theta _2$, and replacing the  $(\mu _1+\mu _2)$ term by
$(\mu _1+\mu _2)$ term by  $(\mu _1+\mu _2+\theta _2)$ in (8) and (10), the structure of the optimal policy remains unchanged, and the new threshold
$(\mu _1+\mu _2+\theta _2)$ in (8) and (10), the structure of the optimal policy remains unchanged, and the new threshold  $c_0^{\prime }$ should satisfy
$c_0^{\prime }$ should satisfy
 $$c_0^\prime = \frac{c_1\theta_1(\mu_2+\theta_2-\theta)+(r_s \mu_s -r_2 \mu_2+c_2\theta_2)(\theta+\mu_1)}{(\mu_1+\mu_2+\theta_2)\theta},$$
$$c_0^\prime = \frac{c_1\theta_1(\mu_2+\theta_2-\theta)+(r_s \mu_s -r_2 \mu_2+c_2\theta_2)(\theta+\mu_1)}{(\mu_1+\mu_2+\theta_2)\theta},$$
as in Corollary 7. We note that  $c_0^\prime$ increases in
$c_0^\prime$ increases in  $c_2$. This is because when the second-stage abandonment cost increases, the actual reward of a supervisor serving a customer (
$c_2$. This is because when the second-stage abandonment cost increases, the actual reward of a supervisor serving a customer ( $r_2 \times {\mu _2}/{(\mu _2+\theta _2)}-c_2\times {\theta _2}/{(\mu _2+\theta _2)}$) decreases. Therefore, the supervisors will only switch to serve the customers for larger abandonment costs while they are waiting for the second-stage service.
$r_2 \times {\mu _2}/{(\mu _2+\theta _2)}-c_2\times {\theta _2}/{(\mu _2+\theta _2)}$) decreases. Therefore, the supervisors will only switch to serve the customers for larger abandonment costs while they are waiting for the second-stage service.
Moreover,  $c_0^\prime$ is constant in
$c_0^\prime$ is constant in  $c_1$ or
$c_1$ or  $\theta _1$ when
$\theta _1$ when  $\mu _2+\theta _2 = \theta$;
$\mu _2+\theta _2 = \theta$;  $c_0^\prime$ increases in
$c_0^\prime$ increases in  $c_1$ or
$c_1$ or  $\theta _1$ when
$\theta _1$ when  $\mu _2+\theta _2 \gt \theta$; and
$\mu _2+\theta _2 \gt \theta$; and  $c_0^\prime$ decreases in
$c_0^\prime$ decreases in  $c_1$ or
$c_1$ or  $\theta _1$ when
$\theta _1$ when  $\mu _2+\theta _2 \lt \theta$. This is because when
$\mu _2+\theta _2 \lt \theta$. This is because when  $\mu _2+\theta _2 =\theta$, the death rate in state
$\mu _2+\theta _2 =\theta$, the death rate in state  $x \in \{1,\ldots,N\}$ is
$x \in \{1,\ldots,N\}$ is  $a_x(\mu _2+\theta _2)+(x-a_x)\theta =x\theta$. Thus, the death rate in state
$a_x(\mu _2+\theta _2)+(x-a_x)\theta =x\theta$. Thus, the death rate in state  $x$ is the same regardless of the chosen action
$x$ is the same regardless of the chosen action  $a_x$, which leads to the threshold
$a_x$, which leads to the threshold  $c_0^\prime$ remaining the same. However, when
$c_0^\prime$ remaining the same. However, when  $\mu _2+\theta _2 \gt \theta$, larger
$\mu _2+\theta _2 \gt \theta$, larger  $a_x$ results in higher death rates. Since the
$a_x$ results in higher death rates. Since the  $c_1$,
$c_1$,  $\theta _1$ terms in the immediate reward
$\theta _1$ terms in the immediate reward  $r(x,a_x)$ equal
$r(x,a_x)$ equal  $-(N-x)c_1\theta _1$, the effects of
$-(N-x)c_1\theta _1$, the effects of  $c_1$,
$c_1$,  $\theta _1$ are less for smaller
$\theta _1$ are less for smaller  $x$, leading to an increment in the threshold
$x$, leading to an increment in the threshold  $c_0^\prime$. On the contrary, when
$c_0^\prime$. On the contrary, when  $\mu _2+\theta _2 \lt \theta$, larger
$\mu _2+\theta _2 \lt \theta$, larger  $a_x$ results in lower death rates, and hence, the supervisors will switch to serve the customers for smaller abandonment costs
$a_x$ results in lower death rates, and hence, the supervisors will switch to serve the customers for smaller abandonment costs  $c$ while they are waiting for the second-stage service.
$c$ while they are waiting for the second-stage service.
Meanwhile, we note that  $c_0^\prime$ increases in
$c_0^\prime$ increases in  $\theta _2$ when
$\theta _2$ when  $c_1\theta _1+c_2(\mu _1+\mu _2) \gt r_s\mu _s-r_2\mu _2$; decreases in
$c_1\theta _1+c_2(\mu _1+\mu _2) \gt r_s\mu _s-r_2\mu _2$; decreases in  $\theta _2$ when
$\theta _2$ when  $c_1\theta _1+c_2(\mu _1+\mu _2) \lt r_s\mu _s-r_2\mu _2$; and is constant in
$c_1\theta _1+c_2(\mu _1+\mu _2) \lt r_s\mu _s-r_2\mu _2$; and is constant in  $\theta _2$ when
$\theta _2$ when  $c_1\theta _1+c_2(\mu _1+\mu _2) = r_s\mu _s-r_2\mu _2$. Thus, when the abandonment costs
$c_1\theta _1+c_2(\mu _1+\mu _2) = r_s\mu _s-r_2\mu _2$. Thus, when the abandonment costs  $c_1, c_2$ and rate
$c_1, c_2$ and rate  $\theta _1$ during service are large (small) relative to the benefit
$\theta _1$ during service are large (small) relative to the benefit  $r_s\mu _s-r_2\mu _2$ of supervisors focusing on their own responsibilities, the supervisors will switch later (earlier) from their own responsibilities to serving the customers as the abandonment rate
$r_s\mu _s-r_2\mu _2$ of supervisors focusing on their own responsibilities, the supervisors will switch later (earlier) from their own responsibilities to serving the customers as the abandonment rate  $\theta _2$ increases.
$\theta _2$ increases.
Remark 8. When abandonments can also occur during the first- and second-stage service, if  $c_1=c_2=c$ and
$c_1=c_2=c$ and  $\theta _1=\theta _2=\theta$, we have:
$\theta _1=\theta _2=\theta$, we have:
(i) if
$r_2 \mu _2 \leq r_s \mu _s$, then $\pi ^{\mathcal {S}}$ is optimal;(ii) if
$r_2 \mu _2 \geq r_s \mu _s$, then $\pi ^{\mathcal {C}}$ is optimal.




Note that when  $c_1=c_2=c$ and
$c_1=c_2=c$ and  $\theta _1=\theta _2=\theta$, the immediate reward
$\theta _1=\theta _2=\theta$, the immediate reward  $r(x,a_x)$ of choosing action
$r(x,a_x)$ of choosing action  $a_x$ in state
$a_x$ in state  $x$ is
$x$ is
 \begin{align} r(x,a_x) & = \frac{(M-a_x) r_s \mu_s+a_x (r_2 \times \frac{\mu_2}{\mu_2+\theta}-c\times \frac{\theta}{\mu_2+\theta})(\mu_2+\theta) -(x-a_x)c\theta - (N-x)c\theta}{q} \nonumber\\ & =\frac{M r_s \mu_s+a_x{(r_2\mu_2-r_s \mu_s)}- Nc\theta}{q}. \end{align}
\begin{align} r(x,a_x) & = \frac{(M-a_x) r_s \mu_s+a_x (r_2 \times \frac{\mu_2}{\mu_2+\theta}-c\times \frac{\theta}{\mu_2+\theta})(\mu_2+\theta) -(x-a_x)c\theta - (N-x)c\theta}{q} \nonumber\\ & =\frac{M r_s \mu_s+a_x{(r_2\mu_2-r_s \mu_s)}- Nc\theta}{q}. \end{align}
Since  ${M r_s \mu _s}/{q}$ and
${M r_s \mu _s}/{q}$ and  ${Nc\theta }/{q}$ in (16) are constant in
${Nc\theta }/{q}$ in (16) are constant in  $x$, the optimal policy depends solely on the comparison of
$x$, the optimal policy depends solely on the comparison of  $r_2\mu _2$ and
$r_2\mu _2$ and  $r_s\mu _s$ in this case.
$r_s\mu _s$ in this case.
Remark 9. When abandonments can also occur during the first-stage (but not during the second-stage service), if  $c_1=c$ and
$c_1=c$ and  $\theta _1=\theta$, we have
$\theta _1=\theta$, we have
(i) if
$c \leq {(r_s \mu _s - r_2 \mu _2)}/{\theta }$, then $\pi ^{\mathcal {S}}$ is optimal;(ii) if
$c \geq {(r_s \mu _s - r_2 \mu _2)}/{\theta }$, then $\pi ^{\mathcal {C}}$ is optimal.




Note that in this case,  $\pi ^{\mathcal {S}}$ is optimal when
$\pi ^{\mathcal {S}}$ is optimal when  $r_s \mu _s \geq r_2 \mu _2 +c\theta$ and
$r_s \mu _s \geq r_2 \mu _2 +c\theta$ and  $\pi ^{\mathcal {C}}$ is optimal otherwise. This is because the immediate reward
$\pi ^{\mathcal {C}}$ is optimal otherwise. This is because the immediate reward  $r(x,a_x)$ of choosing action
$r(x,a_x)$ of choosing action  $a_x$ in state
$a_x$ in state  $x$ now is
$x$ now is
 \begin{align*} r(x,a_x) & = \frac{(M-a_x) r_s \mu_s+a_x (r_2 \mu_2+c\theta) - Nc\theta}{q} \\ & = \frac{Mr_s \mu_s+a_x{(r_2\mu_2+{c\theta}-r_s\mu_s)}- Nc\theta}{q}, \end{align*}
\begin{align*} r(x,a_x) & = \frac{(M-a_x) r_s \mu_s+a_x (r_2 \mu_2+c\theta) - Nc\theta}{q} \\ & = \frac{Mr_s \mu_s+a_x{(r_2\mu_2+{c\theta}-r_s\mu_s)}- Nc\theta}{q}, \end{align*}
which does not depend on  $x$. Therefore, the optimal policy depends on the comparison of
$x$. Therefore, the optimal policy depends on the comparison of  $r_2\mu _2+{c\theta }$ and
$r_2\mu _2+{c\theta }$ and  $r_s\mu _s$ in this case.
$r_s\mu _s$ in this case.
Remark 10. When abandonments can also occur during the second-stage (but not during the first-stage service), if  $c_2=c$ and
$c_2=c$ and  $\theta _2=\theta$, we have
$\theta _2=\theta$, we have
(i) if
$c \leq {[(r_s \mu _s - r_2 \mu _2)(\theta +\mu _1)]}/{\theta \mu _2}$, then $\pi ^{\mathcal {S}}$ is optimal;(ii) if
$c \geq {[(r_s \mu _s - r_2 \mu _2)(\theta +\mu _1)]}/{\theta \mu _2}$, then $\pi ^{\mathcal {C}}$ is optimal.




Note that in this case, the immediate reward  $r(x,a_x)$ of choosing action
$r(x,a_x)$ of choosing action  $a_x$ in state
$a_x$ in state  $x$ is
$x$ is
 \begin{align*} r(x,a_x) & = \frac{(M-a_x) r_s \mu_s+a_x (\frac{r_2 \mu_2}{\mu_2+\theta}-\frac{c\theta}{\mu_2+\theta})(\mu_2+\theta)-(x-a_x)c\theta }{q}\\ & = \frac{M r_s \mu_s+a_x ({r_2 \mu_2}-r_s \mu_s)-xc\theta }{q}, \end{align*}
\begin{align*} r(x,a_x) & = \frac{(M-a_x) r_s \mu_s+a_x (\frac{r_2 \mu_2}{\mu_2+\theta}-\frac{c\theta}{\mu_2+\theta})(\mu_2+\theta)-(x-a_x)c\theta }{q}\\ & = \frac{M r_s \mu_s+a_x ({r_2 \mu_2}-r_s \mu_s)-xc\theta }{q}, \end{align*}
which depends on the state  $x$. However, when
$x$. However, when  $r_s\mu _s-r_2\mu _2 \gt 0$, the threshold in Remark 10 satisfies
$r_s\mu _s-r_2\mu _2 \gt 0$, the threshold in Remark 10 satisfies  ${[(r_s \mu _s - r_2 \mu _2)(\theta +\mu _1)]}/{\theta \mu _2} \gt c_0={[(r_s \mu _s -r_2 \mu _2)(\theta +\mu _1)]}/{(\mu _1+\mu _2)\theta } \gt 0$. This implies that when the supervisors earn greater rewards per unit time working on their own responsibilities, if abandonments can also occur during the second-stage service and
${[(r_s \mu _s - r_2 \mu _2)(\theta +\mu _1)]}/{\theta \mu _2} \gt c_0={[(r_s \mu _s -r_2 \mu _2)(\theta +\mu _1)]}/{(\mu _1+\mu _2)\theta } \gt 0$. This implies that when the supervisors earn greater rewards per unit time working on their own responsibilities, if abandonments can also occur during the second-stage service and  $c_2=c \gt 0$, the expected rewards for supervisors serving the customers decrease. Therefore, the supervisors will switch to serve the customers for larger abandonment costs. However, when
$c_2=c \gt 0$, the expected rewards for supervisors serving the customers decrease. Therefore, the supervisors will switch to serve the customers for larger abandonment costs. However, when  $r_s\mu _s-r_2\mu _2 \lt 0$, we have
$r_s\mu _s-r_2\mu _2 \lt 0$, we have  ${[(r_s \mu _s - r_2 \mu _2)(\theta +\mu _1)]}/{\theta \mu _2} \lt c_0 \lt 0$. That is to say, when the supervisors earn greater rewards per unit time serving the customers, if abandonments can also occur during the second-stage service and there is a reward for customers leaving the system without second-stage service (i.e.,
${[(r_s \mu _s - r_2 \mu _2)(\theta +\mu _1)]}/{\theta \mu _2} \lt c_0 \lt 0$. That is to say, when the supervisors earn greater rewards per unit time serving the customers, if abandonments can also occur during the second-stage service and there is a reward for customers leaving the system without second-stage service (i.e.,  $-c$ as
$-c$ as  $c \lt 0$), there are added benefits for supervisors to serve the customers and hence they will switch to serving the customers earlier.
$c \lt 0$), there are added benefits for supervisors to serve the customers and hence they will switch to serving the customers earlier.
4. Benefits of pooling the subordinates of several supervisors
In this section, we investigate the effects of pooling supervisors (and their subordinates) on the system performance. When there are multiple supervisors, each of whom has her own subordinates, a natural question arises: should each supervisor work with her subordinates only, or should all supervisors work with all the subordinates? Consider our example of government services in Section 1. One possibility is that the waiting people form several queues and each official is responsible for one queue in addition to her other responsibilities. Alternatively, all officials can be jointly responsible for serving all the waiting people (in addition to their own responsibilities).
In particular, we consider two cases. In case 1, there are  $KM$ subordinates and
$KM$ subordinates and  $M$ supervisors (a pooled system with
$M$ supervisors (a pooled system with  $K$ subordinates per supervisor); in case 2, there are
$K$ subordinates per supervisor); in case 2, there are  $M$ systems each with
$M$ systems each with  $K \geq 1$ subordinates and one supervisor (
$K \geq 1$ subordinates and one supervisor ( $M$ dedicated systems). Note that since
$M$ dedicated systems). Note that since  $c_0$ does not depend on the number of subordinates or supervisors, the optimality condition is the same for both cases. We then have Proposition 12. Before we elaborate on Proposition 12, we first prove Lemma 11.
$c_0$ does not depend on the number of subordinates or supervisors, the optimality condition is the same for both cases. We then have Proposition 12. Before we elaborate on Proposition 12, we first prove Lemma 11.
Lemma 11. For  $1 \leq k \leq KM$,
$1 \leq k \leq KM$,  ${KM \choose k}k \geq \sum _{j=1}^{\min \{K,k\}} {KM \choose k-j}{K \choose j}j!(M-k+j)$.
${KM \choose k}k \geq \sum _{j=1}^{\min \{K,k\}} {KM \choose k-j}{K \choose j}j!(M-k+j)$.
Proof. Observe that
 $${KM \choose k }k = {KM \choose k-1}[KM-(k-1)],$$
$${KM \choose k }k = {KM \choose k-1}[KM-(k-1)],$$
and
 \begin{align*} {K \choose j}j! (M-k+j)& \leq K(K-1)^{j-1}(M-k+j)\\ & =[KM-(k-j) -(k-j)(K-1)](K-1)^{j-1} \end{align*}
\begin{align*} {K \choose j}j! (M-k+j)& \leq K(K-1)^{j-1}(M-k+j)\\ & =[KM-(k-j) -(k-j)(K-1)](K-1)^{j-1} \end{align*}
for  $1 \leq k \leq KM$ and
$1 \leq k \leq KM$ and 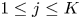 $1 \leq j \leq K$. When
$1 \leq j \leq K$. When  $1 \leq k \leq KM$, we have
$1 \leq k \leq KM$, we have
 \begin{align*} & {KM \choose k}k-\sum_{j=1}^{\min\{K,k\}} {KM \choose k-j}{K \choose j}j!(M-k+j)\\ & \quad \geq {KM \choose k-1}[KM-(k-1)]-\sum_{j=1}^{\min\{K,k\}} {KM \choose k-j}[KM-(k-j)-(k-j)(K-1)](K-1)^{j-1}\nonumber\\ & \quad = {KM \choose k-1}(k-1)(K-1)-\sum_{j=2}^{\min\{K,k\}} {KM \choose k-j}[KM-(k-j)-(k-j)(K-1)](K-1)^{j-1}\nonumber\\ & \quad = {KM \choose k-2}[KM-(k-2)](K-1)-\sum_{j=2}^{\min\{K,k\}} {KM \choose k-j}[KM-(k-j)-(k-j)(K-1)](K-1)^{j-1}\\ & \quad \geq{KM \choose k-2}(k-2)(K-1)^2-\sum_{j=3}^{\min\{K,k\}} {KM \choose k-j}[KM-(k-j)-(k-j)(K-1)](K-1)^{j-1}\\ & \qquad \vdots \\ & \quad \geq {KM \choose k-\min\{K,k\}}(k-\min\{K,k\})(K-1)^{\min\{K,k\}} \geq 0. \end{align*}
\begin{align*} & {KM \choose k}k-\sum_{j=1}^{\min\{K,k\}} {KM \choose k-j}{K \choose j}j!(M-k+j)\\ & \quad \geq {KM \choose k-1}[KM-(k-1)]-\sum_{j=1}^{\min\{K,k\}} {KM \choose k-j}[KM-(k-j)-(k-j)(K-1)](K-1)^{j-1}\nonumber\\ & \quad = {KM \choose k-1}(k-1)(K-1)-\sum_{j=2}^{\min\{K,k\}} {KM \choose k-j}[KM-(k-j)-(k-j)(K-1)](K-1)^{j-1}\nonumber\\ & \quad = {KM \choose k-2}[KM-(k-2)](K-1)-\sum_{j=2}^{\min\{K,k\}} {KM \choose k-j}[KM-(k-j)-(k-j)(K-1)](K-1)^{j-1}\\ & \quad \geq{KM \choose k-2}(k-2)(K-1)^2-\sum_{j=3}^{\min\{K,k\}} {KM \choose k-j}[KM-(k-j)-(k-j)(K-1)](K-1)^{j-1}\\ & \qquad \vdots \\ & \quad \geq {KM \choose k-\min\{K,k\}}(k-\min\{K,k\})(K-1)^{\min\{K,k\}} \geq 0. \end{align*}
Proposition 12.
(i) If
$c \leq c_0$ (i.e., $\pi ^{\mathcal {S}}$ is optimal), then $g^{\pi ^{\mathcal {S}}}_{KM,M}\geq Mg^{\pi ^{\mathcal {S}}}_{K,1}$ for $M, K \geq 1$ and
for$$\lim_{M \rightarrow \infty} \frac{g^{\pi^{\mathcal{S}}}_{KM,M}- Mg^{\pi^{\mathcal{S}}}_{K,1}}{M} = \frac{K\theta\mu_1^K[(\mu_1+\theta)(r_s\mu_s-r_2\mu_2)- c\theta(\mu_1+\mu_2)]}{(\mu_1+\theta)\{[\mu_2+(K-1)\theta](\theta+\mu_1)^K+\mu_1^K(\theta-\mu_2)\}}$$
$K \geq 1$;(ii) If
$c \geq c_0$ (i.e., $\pi ^{\mathcal {C}}$ is optimal), then $g^{\pi ^{\mathcal {C}}}_{KM,M}\geq Mg^{\pi ^{\mathcal {C}}}_{K,1}$ for $M, K \geq 1$ and
for$$0 \leq \frac{g^{\pi^{\mathcal{C}}}_{KM,M}- Mg^{\pi^{\mathcal{C}}}_{K,1}}{M} \leq \frac{c\theta(\mu_1+\mu_2)-(\mu_1+\theta)(r_s\mu_s-r_2\mu_2)}{(\mu_1+\theta)[1+T(K)]}$$
$K \geq 1$, where $T(K) = \sum _{k=1}^{K} {\prod _{i=1}^k[(K+1-i)\mu _1]}/{\Pi _{l=1}^k[\mu _2+(l-1)\theta ]}$.













Proof. (i) Using the closed-form expression of the gain for policy  $\pi ^{\mathcal {S}}$ in (11), with some algebra, we have
$\pi ^{\mathcal {S}}$ in (11), with some algebra, we have
 \begin{align} g_{KM,M}^{\pi^{\mathcal{S}}} - Mg_{K,1}^{\pi^{\mathcal{S}}} &=\frac{1}{\begin{matrix}(\mu_1+\theta)\{[(K-1)\theta+\mu_2](\theta+\mu_1)^K+\mu_1^K(\theta-\mu_2)\} \\ \{[(KM-1)\theta+\mu_2](\theta+\mu_1)^{KM}+\mu_1^{KM}(\theta-\mu_2)\}\end{matrix}}\nonumber\\ & \qquad \times KM\theta[(\mu_1+\theta)(r_s\mu_s-r_2\mu_2) - c\theta(\mu_1+\mu_2)]\nonumber\\ & \qquad \times\{\mu_1^K(\mu_1+\theta)^{KM}[(KM-1)\theta+\mu_2]-\mu_1^{KM}(\mu_1+\theta)^{K}[(K-1)\theta+\mu_2]\}. \end{align}
\begin{align} g_{KM,M}^{\pi^{\mathcal{S}}} - Mg_{K,1}^{\pi^{\mathcal{S}}} &=\frac{1}{\begin{matrix}(\mu_1+\theta)\{[(K-1)\theta+\mu_2](\theta+\mu_1)^K+\mu_1^K(\theta-\mu_2)\} \\ \{[(KM-1)\theta+\mu_2](\theta+\mu_1)^{KM}+\mu_1^{KM}(\theta-\mu_2)\}\end{matrix}}\nonumber\\ & \qquad \times KM\theta[(\mu_1+\theta)(r_s\mu_s-r_2\mu_2) - c\theta(\mu_1+\mu_2)]\nonumber\\ & \qquad \times\{\mu_1^K(\mu_1+\theta)^{KM}[(KM-1)\theta+\mu_2]-\mu_1^{KM}(\mu_1+\theta)^{K}[(K-1)\theta+\mu_2]\}. \end{align}
We now proceed to show that each term here is non-negative. Since  $c\leq c_0$,
$c\leq c_0$,  $(\mu _1+\theta )(r_s\mu _s-r_2\mu _2) - c\theta (\mu _1+\mu _2)\geq 0$. Furthermore,
$(\mu _1+\theta )(r_s\mu _s-r_2\mu _2) - c\theta (\mu _1+\mu _2)\geq 0$. Furthermore,
 $$\mu_1^K(\mu_1+\theta)^{KM}[(KM-1)\theta+\mu_2]-\mu_1^{KM}(\mu_1+\theta)^{K}[(K-1)\theta+\mu_2] \geq \mu_1^{KM}(\mu_1+\theta)^{K}K(M-1)\theta \geq 0.$$
$$\mu_1^K(\mu_1+\theta)^{KM}[(KM-1)\theta+\mu_2]-\mu_1^{KM}(\mu_1+\theta)^{K}[(K-1)\theta+\mu_2] \geq \mu_1^{KM}(\mu_1+\theta)^{K}K(M-1)\theta \geq 0.$$
Similarly,
 $$[(K-1)\theta+\mu_2](\theta+\mu_1)^K+\mu_1^K(\theta-\mu_2)\geq K\theta\mu_1^K \gt 0$$
$$[(K-1)\theta+\mu_2](\theta+\mu_1)^K+\mu_1^K(\theta-\mu_2)\geq K\theta\mu_1^K \gt 0$$
and
 $$[(KM-1)\theta+\mu_2](\theta+\mu_1)^{KM}+\mu_1^{KM}(\theta-\mu_2)\geq KM\theta\mu_1^{KM} \gt 0.$$
$$[(KM-1)\theta+\mu_2](\theta+\mu_1)^{KM}+\mu_1^{KM}(\theta-\mu_2)\geq KM\theta\mu_1^{KM} \gt 0.$$
Thus,  $g_{KM,M}^{\pi ^{\mathcal {S}}} - Mg_{K,1}^{\pi ^{\mathcal {S}}}\geq 0$ with the equality holding when
$g_{KM,M}^{\pi ^{\mathcal {S}}} - Mg_{K,1}^{\pi ^{\mathcal {S}}}\geq 0$ with the equality holding when  $c=c_0$ or
$c=c_0$ or  $M=1$. We now proceed to obtain the limit of
$M=1$. We now proceed to obtain the limit of  ${(g_{KM,M}^{\pi ^{\mathcal {S}}} - Mg_{K,1}^{\pi ^{\mathcal {S}}})}/{M}$ when
${(g_{KM,M}^{\pi ^{\mathcal {S}}} - Mg_{K,1}^{\pi ^{\mathcal {S}}})}/{M}$ when  $M$ goes to infinity. Based on (17), we have:
$M$ goes to infinity. Based on (17), we have:
 \begin{align*} & \lim_{M \rightarrow \infty} \frac{g^{\pi^{\mathcal{S}}}_{KM,M}- Mg^{\pi^{\mathcal{S}}}_{K,1}}{M}\\ & \quad = \frac{K\theta\mu_1^K[(\mu_1+\theta)(r_s\mu_s-r_2\mu_2)- c\theta(\mu_1+\mu_2)]}{(\mu_1+\theta)\{[(K-1)\theta+\mu_2](\theta+\mu_1)^K+\mu_1^K(\theta-\mu_2)\}}\\ & \qquad \times \lim_{M \rightarrow \infty}\frac{(\mu_1+\theta)^{KM}[(KM-1)\theta+\mu_2]-\mu_1^{K(M-1)}(\mu_1+\theta)^{K}[(K-1)\theta+\mu_2]}{[(KM-1)\theta+\mu_2](\theta+\mu_1)^{KM}+\mu_1^{KM}(\theta-\mu_2)}. \end{align*}
\begin{align*} & \lim_{M \rightarrow \infty} \frac{g^{\pi^{\mathcal{S}}}_{KM,M}- Mg^{\pi^{\mathcal{S}}}_{K,1}}{M}\\ & \quad = \frac{K\theta\mu_1^K[(\mu_1+\theta)(r_s\mu_s-r_2\mu_2)- c\theta(\mu_1+\mu_2)]}{(\mu_1+\theta)\{[(K-1)\theta+\mu_2](\theta+\mu_1)^K+\mu_1^K(\theta-\mu_2)\}}\\ & \qquad \times \lim_{M \rightarrow \infty}\frac{(\mu_1+\theta)^{KM}[(KM-1)\theta+\mu_2]-\mu_1^{K(M-1)}(\mu_1+\theta)^{K}[(K-1)\theta+\mu_2]}{[(KM-1)\theta+\mu_2](\theta+\mu_1)^{KM}+\mu_1^{KM}(\theta-\mu_2)}. \end{align*}
The result now follows from the fact that
 \begin{align*} \lim_{M \rightarrow \infty} \frac{(\mu_1+\theta)^{KM}[(KM-1)\theta+\mu_2]-\mu_1^{K(M-1)}(\mu_1+\theta)^{K}[(K-1)\theta+\mu_2]}{[(KM-1)\theta+\mu_2](\theta+\mu_1)^{KM}+\mu_1^{KM}(\theta-\mu_2)}=1. \end{align*}
\begin{align*} \lim_{M \rightarrow \infty} \frac{(\mu_1+\theta)^{KM}[(KM-1)\theta+\mu_2]-\mu_1^{K(M-1)}(\mu_1+\theta)^{K}[(K-1)\theta+\mu_2]}{[(KM-1)\theta+\mu_2](\theta+\mu_1)^{KM}+\mu_1^{KM}(\theta-\mu_2)}=1. \end{align*}
(ii) Using the closed-form expression of the gain for policy  $\pi ^{\mathcal {C}}$ in (12), with some algebra, we have
$\pi ^{\mathcal {C}}$ in (12), with some algebra, we have
 \begin{align} g_{KM,M}^{\pi^{\mathcal{C}}} - Mg_{K,1}^{\pi^{\mathcal{C}}}& =\frac{[c\theta(\mu_1+\mu_2)-(\mu_1+\theta)(r_s\mu_s-r_2\mu_2)]}{(\mu_1+\theta)[1+T(K)]}\nonumber\\ & \quad \times \frac{\Gamma}{\sum_{k=0}^M {KM \choose k}(\frac{\mu_1}{\mu_2})^k+\sum_{k=M+1}^{KM} \frac{\prod_{i=1}^k[(KM+1-i)\mu_1]}{M!\mu_2^M\Pi_{l=M+1}^k[M\mu_2+(l-M)\theta]}}, \end{align}
\begin{align} g_{KM,M}^{\pi^{\mathcal{C}}} - Mg_{K,1}^{\pi^{\mathcal{C}}}& =\frac{[c\theta(\mu_1+\mu_2)-(\mu_1+\theta)(r_s\mu_s-r_2\mu_2)]}{(\mu_1+\theta)[1+T(K)]}\nonumber\\ & \quad \times \frac{\Gamma}{\sum_{k=0}^M {KM \choose k}(\frac{\mu_1}{\mu_2})^k+\sum_{k=M+1}^{KM} \frac{\prod_{i=1}^k[(KM+1-i)\mu_1]}{M!\mu_2^M\Pi_{l=M+1}^k[M\mu_2+(l-M)\theta]}}, \end{align}
where
 \begin{align*} \Gamma & =M\sum_{k=M+1}^{KM} \frac{\prod_{i=1}^k[(KM+1-i)\mu_1]}{M!\mu_2^M\Pi_{l=M+1}^k[M\mu_2+(l-M)\theta]}+\sum_{k=1}^M {KM \choose k}\left(\frac{\mu_1}{\mu_2}\right)^kk\\ & \quad -\left(\sum_{k=1}^{M} {KM \choose {M-k}}\left(\frac{\mu_1}{\mu_2}\right)^{M-k}k \right)\times T(K). \end{align*}
\begin{align*} \Gamma & =M\sum_{k=M+1}^{KM} \frac{\prod_{i=1}^k[(KM+1-i)\mu_1]}{M!\mu_2^M\Pi_{l=M+1}^k[M\mu_2+(l-M)\theta]}+\sum_{k=1}^M {KM \choose k}\left(\frac{\mu_1}{\mu_2}\right)^kk\\ & \quad -\left(\sum_{k=1}^{M} {KM \choose {M-k}}\left(\frac{\mu_1}{\mu_2}\right)^{M-k}k \right)\times T(K). \end{align*}
We now show that the expression (18) is non-negative. Note that the term  $c\theta (\mu _1+\mu _2)-(r_s\mu _s-r_2\mu _2)(\mu _1+\theta )\geq 0$ since
$c\theta (\mu _1+\mu _2)-(r_s\mu _s-r_2\mu _2)(\mu _1+\theta )\geq 0$ since  $c \geq c_0$. We will show that
$c \geq c_0$. We will show that  $\Gamma \geq 0$. Define
$\Gamma \geq 0$. Define
 $$\alpha_k=\sum_{j=\max\{0,k-K\}}^{k-1}\frac{ {KM \choose j}{K \choose k-j}(k-j)!(M-j)}{\mu_2^j \Pi_{l=1}^{{k-j}}[\mu_2+(l-1)\theta]}$$
$$\alpha_k=\sum_{j=\max\{0,k-K\}}^{k-1}\frac{ {KM \choose j}{K \choose k-j}(k-j)!(M-j)}{\mu_2^j \Pi_{l=1}^{{k-j}}[\mu_2+(l-1)\theta]}$$
for  $1 \leq k \leq M$, and
$1 \leq k \leq M$, and
 $$\beta_{k}=\sum_{j=\max\{0,k-K\}}^{M-1} \frac{{KM \choose j}{K \choose k-j}(k-j)!(M-j)}{\mu_2^j \Pi_{l=1}^{{k-j}}[\mu_2+(l-1)\theta]}$$
$$\beta_{k}=\sum_{j=\max\{0,k-K\}}^{M-1} \frac{{KM \choose j}{K \choose k-j}(k-j)!(M-j)}{\mu_2^j \Pi_{l=1}^{{k-j}}[\mu_2+(l-1)\theta]}$$
for  $M+1 \leq k \leq M+K-1$. Note that by expanding
$M+1 \leq k \leq M+K-1$. Note that by expanding  $(\sum _{k=1}^{M} {KM \choose {M-k}}(\frac {\mu _1}{\mu _2})^{M-k}k )\times T(K)$ and ordering the terms by ascending exponent of
$(\sum _{k=1}^{M} {KM \choose {M-k}}(\frac {\mu _1}{\mu _2})^{M-k}k )\times T(K)$ and ordering the terms by ascending exponent of  $\mu _1$, we have
$\mu _1$, we have
 \begin{align*} \left(\sum_{k=1}^{M} {KM \choose {M-k}}\left(\frac{\mu_1}{\mu_2}\right)^{M-k}k \right)\times T(K) & =\left(\sum_{j=0}^{M-1} {KM \choose j}\left(\frac{\mu_1}{\mu_2}\right)^j(M-j) \right)\\ & \quad \times \left(\sum_{k=1}^{K} \frac{\prod_{i=1}^k[(K+1-i)\mu_1]}{\Pi_{l=1}^k[\mu_2+(l-1)\theta]}\right)\\ & =\sum_{k=1}^{M+K-1}\mu_1^k \sum_{j=\max\{0,k-K\}}^{\min\{k-1,M-1\}}\frac{ {KM \choose j}{K \choose k-j}(k-j)!(M-j)}{\mu_2^j \Pi_{l=1}^{{k-j}}[\mu_2+(l-1)\theta]}\\ & =\sum_{k=1}^{M}\mu_1^k \alpha_k + \sum_{k=M+1}^{M+K-1}\mu_1^k\beta_k. \end{align*}
\begin{align*} \left(\sum_{k=1}^{M} {KM \choose {M-k}}\left(\frac{\mu_1}{\mu_2}\right)^{M-k}k \right)\times T(K) & =\left(\sum_{j=0}^{M-1} {KM \choose j}\left(\frac{\mu_1}{\mu_2}\right)^j(M-j) \right)\\ & \quad \times \left(\sum_{k=1}^{K} \frac{\prod_{i=1}^k[(K+1-i)\mu_1]}{\Pi_{l=1}^k[\mu_2+(l-1)\theta]}\right)\\ & =\sum_{k=1}^{M+K-1}\mu_1^k \sum_{j=\max\{0,k-K\}}^{\min\{k-1,M-1\}}\frac{ {KM \choose j}{K \choose k-j}(k-j)!(M-j)}{\mu_2^j \Pi_{l=1}^{{k-j}}[\mu_2+(l-1)\theta]}\\ & =\sum_{k=1}^{M}\mu_1^k \alpha_k + \sum_{k=M+1}^{M+K-1}\mu_1^k\beta_k. \end{align*}
By grouping the terms in  $\Gamma$ based on the exponent of
$\Gamma$ based on the exponent of  $\mu _1$, we obtain
$\mu _1$, we obtain  $\Gamma =\Gamma _1+\Gamma _2+\Gamma _3$, where
$\Gamma =\Gamma _1+\Gamma _2+\Gamma _3$, where
 \begin{align*} \Gamma_1& =\sum_{k=1}^M\mu_1^k\left[{KM \choose k}\frac{k}{\mu_2^k}-\alpha_k\right],\\ \Gamma_2& =\sum_{k=M+1}^{M+K-1}\mu_1^k\left[\frac{M\prod_{i=1}^k(KM+1-i)}{M!\mu_2^M \Pi_{l=M+1}^k[M\mu_2+(l-M)\theta]}-\beta_{k}\right],\\ \Gamma_3& =\sum_{k=M+K}^{KM}\mu_1^k\frac{M\prod_{i=1}^k(KM+1-i)}{M!\mu_2^M \Pi_{l=M+1}^k[M\mu_2+(l-M)\theta]} \end{align*}
\begin{align*} \Gamma_1& =\sum_{k=1}^M\mu_1^k\left[{KM \choose k}\frac{k}{\mu_2^k}-\alpha_k\right],\\ \Gamma_2& =\sum_{k=M+1}^{M+K-1}\mu_1^k\left[\frac{M\prod_{i=1}^k(KM+1-i)}{M!\mu_2^M \Pi_{l=M+1}^k[M\mu_2+(l-M)\theta]}-\beta_{k}\right],\\ \Gamma_3& =\sum_{k=M+K}^{KM}\mu_1^k\frac{M\prod_{i=1}^k(KM+1-i)}{M!\mu_2^M \Pi_{l=M+1}^k[M\mu_2+(l-M)\theta]} \end{align*}
(recall that the summation over an empty set equals zero).
Note that  $\Gamma _3$ is positive if
$\Gamma _3$ is positive if  $M,K \geq 2$ and
$M,K \geq 2$ and  $\Gamma _3$ is zero if
$\Gamma _3$ is zero if  $M =1$ or
$M =1$ or  $K=1$. Moreover, when
$K=1$. Moreover, when  $M=1$,
$M=1$,  $\Gamma _1 = 0$ and
$\Gamma _1 = 0$ and  $\Gamma _2 = \sum _{k=M+1}^{M+N-1} \mu _1^k \times 0 = 0$. Thus,
$\Gamma _2 = \sum _{k=M+1}^{M+N-1} \mu _1^k \times 0 = 0$. Thus,  $\Gamma =0$ when
$\Gamma =0$ when  $M=1$ and it suffices to show that
$M=1$ and it suffices to show that  $\Gamma _1$ and
$\Gamma _1$ and  $\Gamma _2$ are non-negative, which we will prove by showing that each term of the respective summation is non-negative. For
$\Gamma _2$ are non-negative, which we will prove by showing that each term of the respective summation is non-negative. For  $\Gamma _1$, when
$\Gamma _1$, when  $1 \leq k \leq M$, we have
$1 \leq k \leq M$, we have
 \begin{align} {KM \choose k}\frac{k}{\mu_2^k}-{\alpha_k} & \geq \frac{1}{\mu_2^k}\left[ {KM \choose k}k-\sum_{j=\max\{0,k-K\}}^{k-1} {KM \choose j}{K \choose k-j}(k-j)!(M-j)\right]\nonumber\\ & =\frac{1}{\mu_2^k}\left[{KM \choose k}k-\sum_{j=1}^{\min\{K,k\}} {KM \choose k-j}{K \choose j}j!(M-k+j)\right] \geq 0, \end{align}
\begin{align} {KM \choose k}\frac{k}{\mu_2^k}-{\alpha_k} & \geq \frac{1}{\mu_2^k}\left[ {KM \choose k}k-\sum_{j=\max\{0,k-K\}}^{k-1} {KM \choose j}{K \choose k-j}(k-j)!(M-j)\right]\nonumber\\ & =\frac{1}{\mu_2^k}\left[{KM \choose k}k-\sum_{j=1}^{\min\{K,k\}} {KM \choose k-j}{K \choose j}j!(M-k+j)\right] \geq 0, \end{align}
where the last inequality follows from Lemma 11. Similarly, note that
 $$\beta_{k} \leq \sum_{j=\max\{0,k-K\}}^{M-1}\frac{ {KM \choose j}{K \choose k-j}(k-j)!(M-j)}{\mu_2^{M} \Pi_{l=1}^{{k-M}}(\mu_2+l\theta)},\quad \text{for}\ M+1 \leq k \leq M+K-1.$$
$$\beta_{k} \leq \sum_{j=\max\{0,k-K\}}^{M-1}\frac{ {KM \choose j}{K \choose k-j}(k-j)!(M-j)}{\mu_2^{M} \Pi_{l=1}^{{k-M}}(\mu_2+l\theta)},\quad \text{for}\ M+1 \leq k \leq M+K-1.$$
Therefore, for  $M+1 \leq k \leq M+K-1$,
$M+1 \leq k \leq M+K-1$,
 \begin{align} & \frac{M\prod_{i=1}^{k}(KM+1-i)}{M!\mu_2^M \Pi_{l=M+1}^{k}[M\mu_2+(l-M)\theta]}-\beta_{k}\nonumber\\ & \quad\geq \frac{M{KM \choose k}k!}{M!\mu_2^M M^{k-M} \prod_{l=1}^{k-M} (\mu_2+l\theta)}-\frac{\sum_{j=\max\{0,k-K\}}^{M-1}{KM \choose j}{K \choose k-j}(k-j)!(M-j)}{\mu_2^M \prod_{l=1}^{k-M} (\mu_2+l\theta)}\nonumber\\ & \quad=\frac{1}{\mu_2^M\prod_{l=1}^{k-M} (\mu_2+l\theta)}\left[\frac{{KM \choose k}k!}{(M-1)!M^{k-M}}-\sum_{j=\max\{0,k-K\}}^{M-1}{KM \choose j}{K \choose k-j}(k-j)!(M-j)\right]\nonumber\\ & \quad\geq\frac{1}{\mu_2^M \prod_{l=1}^{k-M} (\mu_2+l\theta)} \left[{KM \choose k}k-\sum_{j=\max\{0,k-K\}}^{M-1}{KM \choose j}{K \choose k-j}(k-j)!(M-j)\right]\nonumber\\ & \quad=\frac{1}{\mu_2^M \prod_{l=1}^{k-M} (\mu_2+l\theta)} \left[{KM \choose k}k-\sum_{j=k-M+1}^{\min\{K,k\}}{KM \choose k-j}{K \choose j}j!(M-k+j)\right]\nonumber\\ & \quad\geq\frac{1}{\mu_2^M \prod_{l=1}^{k-M} (\mu_2+l\theta)} \left[{KM \choose k}k-\sum_{j=1}^{\min\{K,k\}}{KM \choose k-j}{K \choose j}j!(M-k+j)\right] \geq 0, \end{align}
\begin{align} & \frac{M\prod_{i=1}^{k}(KM+1-i)}{M!\mu_2^M \Pi_{l=M+1}^{k}[M\mu_2+(l-M)\theta]}-\beta_{k}\nonumber\\ & \quad\geq \frac{M{KM \choose k}k!}{M!\mu_2^M M^{k-M} \prod_{l=1}^{k-M} (\mu_2+l\theta)}-\frac{\sum_{j=\max\{0,k-K\}}^{M-1}{KM \choose j}{K \choose k-j}(k-j)!(M-j)}{\mu_2^M \prod_{l=1}^{k-M} (\mu_2+l\theta)}\nonumber\\ & \quad=\frac{1}{\mu_2^M\prod_{l=1}^{k-M} (\mu_2+l\theta)}\left[\frac{{KM \choose k}k!}{(M-1)!M^{k-M}}-\sum_{j=\max\{0,k-K\}}^{M-1}{KM \choose j}{K \choose k-j}(k-j)!(M-j)\right]\nonumber\\ & \quad\geq\frac{1}{\mu_2^M \prod_{l=1}^{k-M} (\mu_2+l\theta)} \left[{KM \choose k}k-\sum_{j=\max\{0,k-K\}}^{M-1}{KM \choose j}{K \choose k-j}(k-j)!(M-j)\right]\nonumber\\ & \quad=\frac{1}{\mu_2^M \prod_{l=1}^{k-M} (\mu_2+l\theta)} \left[{KM \choose k}k-\sum_{j=k-M+1}^{\min\{K,k\}}{KM \choose k-j}{K \choose j}j!(M-k+j)\right]\nonumber\\ & \quad\geq\frac{1}{\mu_2^M \prod_{l=1}^{k-M} (\mu_2+l\theta)} \left[{KM \choose k}k-\sum_{j=1}^{\min\{K,k\}}{KM \choose k-j}{K \choose j}j!(M-k+j)\right] \geq 0, \end{align}
where the last inequality follows from Lemma 11. It follows from (19) and (20) that  $\Gamma _1$ and
$\Gamma _1$ and  $\Gamma _2$ are non-negative, which implies that
$\Gamma _2$ are non-negative, which implies that  $\Gamma$ is positive when
$\Gamma$ is positive when  $M \geq 2$ and
$M \geq 2$ and  $K \geq 2$. When
$K \geq 2$. When  $M \geq 2$ and
$M \geq 2$ and  $K=1$, since
$K=1$, since  $\Gamma _2 = \Gamma _3 = 0$, we have
$\Gamma _2 = \Gamma _3 = 0$, we have
 $$\Gamma =\Gamma_1=\sum_{k=1}^M\mu_1^k\left[{M \choose k}\frac{k}{\mu_2^k}-\alpha_k\right]= \sum_{k=1}^M(\frac{\mu_1}{\mu_2})^k\left[{M \choose k}{k}-{ {M \choose k-1}(M-k+1)}\right] = 0.$$
$$\Gamma =\Gamma_1=\sum_{k=1}^M\mu_1^k\left[{M \choose k}\frac{k}{\mu_2^k}-\alpha_k\right]= \sum_{k=1}^M(\frac{\mu_1}{\mu_2})^k\left[{M \choose k}{k}-{ {M \choose k-1}(M-k+1)}\right] = 0.$$
Therefore, we have  $g_{KM,M}^{\pi ^{\mathcal {C}}} - Mg_{K,1}^{\pi ^{\mathcal {C}}} \geq 0$ with equality holding only when
$g_{KM,M}^{\pi ^{\mathcal {C}}} - Mg_{K,1}^{\pi ^{\mathcal {C}}} \geq 0$ with equality holding only when  $c=c_0$ or
$c=c_0$ or  $M=1$ or
$M=1$ or  $K=1$ (
$K=1$ ( $\Gamma =0$ in the last two cases).
$\Gamma =0$ in the last two cases).
We now proceed to obtain the lower and upper bounds of  ${(g_{KM,M}^{\pi ^{\mathcal {C}}} - Mg_{K,1}^{\pi ^{\mathcal {C}}})}/{M}$ when
${(g_{KM,M}^{\pi ^{\mathcal {C}}} - Mg_{K,1}^{\pi ^{\mathcal {C}}})}/{M}$ when  $M$ goes to infinity. Note that
$M$ goes to infinity. Note that
 \begin{align*} & {\frac{\Gamma}{\sum_{k=0}^M {KM \choose k}\left(\frac{\mu_1}{\mu_2}\right)^k+\sum_{k=M+1}^{KM} \frac{\prod_{i=1}^k[(KM+1-i)\mu_1]}{M!\mu_2^M\Pi_{l=M+1}^k[M\mu_2+(l-M)\theta]}}}\times \frac{1}{M}\nonumber\\ & \quad= \frac{\begin{array}{c} M\sum_{k=M+1}^{KM} \dfrac{\prod_{i=1}^k[(KM+1-i)\mu_1]}{M!\mu_2^M\Pi_{l=M+1}^k[M\mu_2+(l-M)\theta]}+\sum_{k=1}^M {KM \choose k}\left(\dfrac{\mu_1}{\mu_2}\right)^k k-T(K) \\ \times \left[\sum_{k=0}^{M-1} {KM \choose k}\left(\dfrac{\mu_1}{\mu_2}\right)^k(M-k)\right]\end{array}}{M\sum_{k=0}^M {KM \choose k}\left(\frac{\mu_1}{\mu_2}\right)^k+M\sum_{k=M+1}^{KM} \frac{\prod_{i=1}^k[(KM+1-i)\mu_1]}{M!\mu_2^M\Pi_{l=M+1}^k[M\mu_2+(l-M)\theta]}}\nonumber\\ & \quad=1-\frac{[1+T(K)]\sum_{k=0}^M {KM \choose k}\left(\frac{\mu_1}{\mu_2}\right)^k\times (M-k)}{M\sum_{k=0}^M {KM \choose k}\left(\frac{\mu_1}{\mu_2}\right)^k+M\sum_{k=M+1}^{KM} \frac{\prod_{i=1}^k[(KM+1-i)\mu_1]}{M!\mu_2^M\Pi_{l=M+1}^k[M\mu_2+(l-M)\theta]}} \lt 1. \nonumber \end{align*}
\begin{align*} & {\frac{\Gamma}{\sum_{k=0}^M {KM \choose k}\left(\frac{\mu_1}{\mu_2}\right)^k+\sum_{k=M+1}^{KM} \frac{\prod_{i=1}^k[(KM+1-i)\mu_1]}{M!\mu_2^M\Pi_{l=M+1}^k[M\mu_2+(l-M)\theta]}}}\times \frac{1}{M}\nonumber\\ & \quad= \frac{\begin{array}{c} M\sum_{k=M+1}^{KM} \dfrac{\prod_{i=1}^k[(KM+1-i)\mu_1]}{M!\mu_2^M\Pi_{l=M+1}^k[M\mu_2+(l-M)\theta]}+\sum_{k=1}^M {KM \choose k}\left(\dfrac{\mu_1}{\mu_2}\right)^k k-T(K) \\ \times \left[\sum_{k=0}^{M-1} {KM \choose k}\left(\dfrac{\mu_1}{\mu_2}\right)^k(M-k)\right]\end{array}}{M\sum_{k=0}^M {KM \choose k}\left(\frac{\mu_1}{\mu_2}\right)^k+M\sum_{k=M+1}^{KM} \frac{\prod_{i=1}^k[(KM+1-i)\mu_1]}{M!\mu_2^M\Pi_{l=M+1}^k[M\mu_2+(l-M)\theta]}}\nonumber\\ & \quad=1-\frac{[1+T(K)]\sum_{k=0}^M {KM \choose k}\left(\frac{\mu_1}{\mu_2}\right)^k\times (M-k)}{M\sum_{k=0}^M {KM \choose k}\left(\frac{\mu_1}{\mu_2}\right)^k+M\sum_{k=M+1}^{KM} \frac{\prod_{i=1}^k[(KM+1-i)\mu_1]}{M!\mu_2^M\Pi_{l=M+1}^k[M\mu_2+(l-M)\theta]}} \lt 1. \nonumber \end{align*}
Since  ${g_{KM,M}^{\pi ^{\mathcal {C}}} - Mg_{K,1}^{\pi ^{\mathcal {C}}}} \geq 0$ , it now follows from (18) that for all
${g_{KM,M}^{\pi ^{\mathcal {C}}} - Mg_{K,1}^{\pi ^{\mathcal {C}}}} \geq 0$ , it now follows from (18) that for all  $M \geq 1$,
$M \geq 1$,
 $$0\leq \frac{g_{KM,M}^{\pi^{\mathcal{C}}} - Mg_{K,1}^{\pi^{\mathcal{C}}}}{M} \leq \frac{c\theta(\mu_1+\mu_2)-(\mu_1+\theta)(r_s\mu_s-r_2\mu_2)}{(\mu_1+\theta)[1+T(K)]}.$$
$$0\leq \frac{g_{KM,M}^{\pi^{\mathcal{C}}} - Mg_{K,1}^{\pi^{\mathcal{C}}}}{M} \leq \frac{c\theta(\mu_1+\mu_2)-(\mu_1+\theta)(r_s\mu_s-r_2\mu_2)}{(\mu_1+\theta)[1+T(K)]}.$$
Remark 13. It follows directly from the proof of Proposition 12 that pooling supervisors and their associated subordinates is a strict improvement over the unpooled system, as long as  $M \gt 1$ and either
$M \gt 1$ and either  $c \lt c_0$ or
$c \lt c_0$ or  $c \gt c_0$ and
$c \gt c_0$ and  $K \gt 1$; otherwise, the pooled and unpooled systems have identical performance. While it may at first seem surprising that pooling is not beneficial when
$K \gt 1$; otherwise, the pooled and unpooled systems have identical performance. While it may at first seem surprising that pooling is not beneficial when  $c \gt c_0$ and
$c \gt c_0$ and  $K=1$, observe that the Markov chain models of the pooled and unpooled systems are identical under
$K=1$, observe that the Markov chain models of the pooled and unpooled systems are identical under  $\pi ^{\mathcal {C}}$ when
$\pi ^{\mathcal {C}}$ when  $K=1$.
$K=1$.
Proposition 12 shows that pooling supervisors and their subordinates improves the performance of the system in terms of the long-run average reward. However, the improvement per pooled supervisor is bounded. We utilize numerical examples to illustrate the comparison of dedicated and pooled systems and to quantify the incremental benefit per pooled supervisor of pooling systems as more supervisors are pooled. In our numerical examples, we have:  $\mu _1 = 4$,
$\mu _1 = 4$,  $r_1 = 5$,
$r_1 = 5$,  $\mu _2 = 6$,
$\mu _2 = 6$,  $r_2 = 8$,
$r_2 = 8$,  $\mu _s = 11$,
$\mu _s = 11$,  $r_s= 6$,
$r_s= 6$,  $\theta = 2$. Consider the dedicated and pooled systems where there are
$\theta = 2$. Consider the dedicated and pooled systems where there are  $M$ supervisors, each of whom has
$M$ supervisors, each of whom has  $K=4$ subordinates. Note that the threshold
$K=4$ subordinates. Note that the threshold  $c_0$ is
$c_0$ is  $\frac {27}{5} = 5.4$. Figure 2 shows the value of pooling
$\frac {27}{5} = 5.4$. Figure 2 shows the value of pooling  $M$ supervisors as a function of
$M$ supervisors as a function of  $M$ when
$M$ when  $c =2$ (where
$c =2$ (where  $\pi ^{\mathcal {S}}$ is optimal) and when
$\pi ^{\mathcal {S}}$ is optimal) and when  $c =10$ (where
$c =10$ (where  $\pi ^{\mathcal {C}}$ is optimal). The incremental value of pooling more than 5 (10) supervisors is small when
$\pi ^{\mathcal {C}}$ is optimal). The incremental value of pooling more than 5 (10) supervisors is small when  $c =2$ (
$c =2$ ( $c =10$).
$c =10$).

Figure 2. The incremental value of pooling  $M$ supervisors as a function of
$M$ supervisors as a function of  $M$.
$M$.
5. Conclusion
In this paper, we characterize the optimal policy for a two-stage service system with customer abandonments. There are subordinates who perform the first-stage service on their own and supervisors who work together with the subordinates to complete the second-stage service and also have other responsibilities beyond serving the customers in the system. We show that there are only two optimal policies, namely the supervisors start working on the second-stage service either when the subordinates can no longer serve new customers in the first stage or as soon as there is a customer waiting for the second-stage service. The optimality of the two policies depends on how the abandonment cost compares with a threshold that is a function of the other model parameters. We also investigate the effects of pooling supervisors (and their associated subordinates) and show that pooling improves the system performance. In a future research, we are interested in characterizing the optimal policies when there is not unlimited work, and instead the customers and/or other responsibilities of the supervisors arrive according to Poisson processes.
Acknowledgments
This work was supported in part by the National Science Foundation under the grant CMMI-1536990. The authors thank Dr. E. Lerzan Örmeci and two anonymous referees for their valuable suggestions for improving this paper.
Conflict of interest
The authors have not disclosed any competing interests.







 Open access
Open access