


1. Introduction
A natural language toolkit is a library or framework used to analyze human language in a statistical, rule-based or hybrid Natural Language Processing (NLP). These toolkits have been used in the development of a range of applications from various domains. For instance, life sciences and medicine (Cunningham et al. Reference Cunningham, Tablan, Roberts and Bontcheva2013), bio-informatics (Ferrucci and Lally Reference Ferrucci and Lally2004), computer science (Maynard et al. Reference Maynard, Greenwood, Roberts, Windsor and Bontcheva2015; Rush, Chopra, and Weston Reference Rush, Chopra and Weston2015), linguistics (Gries and John Reference Gries and John2014), Machine Learning (ML) (Bird et al. Reference Bird, Klein, Loper and Baldridge2008), and the analysis of social media (Dietzel and Maynard Reference Dietzel and Maynard2015).
The majority of existing NLP toolkits are for English with many other languages supported (Cunningham et al. Reference Cunningham, Maynard, Bontcheva and Tablan2002; Bird, Klein, and Loper Reference Bird, Klein and Loper2009; Manning et al. Reference Manning, Surdeanu, Bauer, Finkel, Bethard and McClosky2014; Kwartler Reference Kwartler2017). However, there is a lack of standard text processing tools and methods for South Asian languages, particularly Urdu, which has 300 million speakers around the world (Riaz 2009) for which a large amount of digital text is available through online repositories. Urdu is an Indo-AryanFootnote a (or Indic) language derived from Sanskrit/Hindustani language (Bögel et al. Reference Bögel, Butt, Hautli and Sulger2007), has been heavily influenced by Arabic, Persian (Bögel et al. Reference Bögel, Butt, Hautli and Sulger2007) and less by Turkic (ChagataiFootnote b) languages for literary and technical vocabulary (Sharjeel, Nawab, and Rayson Reference Sharjeel, Nawab and Rayson2017), and is written from right to left in Nastaliq style (Shafi Reference Shafi2020). Urdu is a morphologically rich language (Saeed et al. 2012), including many multiword expressions and letters which may change their shape based on context, which makes the tokenization task very complex and challenging. Moreover, it is a free word order language (Mukund, Srihari, and Peterson Reference Mukund, Srihari and Peterson2010; Riaz Reference Riaz2012; Daud, Khan, and Che Reference Daud, Khan and Che2016).
In the previous literature, a small amount of work has been carried out to propose systematic text processing NLP approaches for Urdu including word tokenization (Durrani and Hussain Reference Durrani and Hussain2010; Lehal Reference Lehal2010; Rashid and Latif Reference Rashid and Latif2012; Rehman and Anwar Reference Rehman and Anwar2012), sentence tokenization (Rehman and Anwar Reference Rehman and Anwar2012; Raj et al. Reference Raj, Rehman, Rauf, Siddique and Anwar2015), and POS tagging (Hardie Reference Hardie2004; Anwar et al. Reference Anwar, Wang, Li and Wang2007a; Reference Anwar, Wang, Li and Wangb; Sajjad and Schmid Reference Sajjad and Schmid2009; Muaz, Ali, and Hussain Reference Muaz, Ali and Hussain2009; Ahmed et al. Reference Ahmed, Urooj, Hussain, Mustafa, Parveen, Adeeba, Hautli and Butt2014) (see Section 2 for details). However, there are a number of limitations of these existing Urdu NLP studies: (i) most of them are not formed into NLP tools and the ones that are implemented are not publicly and freely available, (ii) training/testing data sets along with developed resources are not always freely and publicly available to improve, compare, and evaluate new and existing methods (Daud et al. Reference Daud, Khan and Che2016), (iii) they have been trained and tested on very small data sets (Anwar et al. Reference Anwar, Wang, Li and Wang2007a; Durrani and Hussain Reference Durrani and Hussain2010; Rehman and Anwar Reference Rehman and Anwar2012), (iv) the efficiency of dictionary-based word tokenization approach (Rashid and Latif Reference Rashid and Latif2012) is entirely dependent on a dictionary of complete Urdu words, which is not practically possible to produce for the Urdu language, (v) statistical n-gram based word tokenizers (Durrani and Hussain Reference Durrani and Hussain2010; Rehman et al. Reference Rehman, Anwar, Bajwa, Xuan and Chaoying2013) cannot handle unknown words or back off to a lesser contextual models, (vi) sentence tokenization methods require data sets to train machine learning algorithms and these are unavailable (Rehman and Anwar Reference Rehman and Anwar2012; Raj et al. Reference Raj, Rehman, Rauf, Siddique and Anwar2015), (vii) current rule-based POS tagging methods (Hardie Reference Hardie2004) are closely tailored to a particular data set, therefore, not portable across different domains, (viii) smoothing and other features to handle unknown words in statistical POS taggers have not been thoroughly explored, (ix) less contextual POS tagging techniques have been proposed, and (x) POS tagsets that have been used to train/test statistical POS taggers (Hardie Reference Hardie2004; Anwar et al. Reference Anwar, Wang, Li and Wang2007b; Sajjad and Schmid Reference Sajjad and Schmid2009) have several shortcomings (see Section 4.3.1).
To overcome the limitations of existing Urdu NLP studies, this study presents the UNLT (Urdu Natural Language Toolkit), initially with text processing methods and three NLP tools including a word tokenizer, sentence tokenizer, and POS tagger. Our proposed Urdu word tokenizer is based on a novel algorithm that makes use of rule-based morpheme matching, n-gram statistical model with backoff and smoothing characteristics, and dictionary look-up. It is trained on our proposed data set of 1361K tokens and evaluated on our proposed test data set containing 59K tokens. The UNLT sentence tokenizer is a combination of rule-based, regular expressions, and dictionary lookup techniques that are evaluated on our proposed test data set of 8K sentences. Furthermore, we have also proposed a ML-based sentence tokenizer. Finally, the UNLT POS tagger is mainly based on Hidden Markov and Maximum Entropy models, with multiple variations based on smoothing, suffix length, context window, word number, lexical, and morphological features. The set of UNLT POS taggers were trained on our proposed training data set of 180K tokens and evaluated on our proposed test data set of 20K tokens.
The UNLT and our training/testing data sets will be crucial in (i) fostering research in an under-resourced language, that is, Urdu, (ii) the development and evaluation of Urdu word tokenizers, sentence tokenizers, and POS taggers, (iii) facilitating comparative evaluations of existing and future methods for Urdu word tokenization, sentence tokenization, and POS tagging, (iv) the development of various NLP tools and applications in other areas such as information retrieval, corpus linguistics, plagiarism detection, semantic annotation, etc., and (v) providing a framework in which other Urdu NLP tools can be integrated.
The rest of the article is organised as follows: Section 2 describes related work, and Section 3 presents challenges for word tokenization, sentence tokenization, and POS tagging methods. Section 4 explains the proposed UNLT modules. Whereas Section 5 present the proposed data sets. Section 6 introduces evaluation measures, results, and their analysis. Section 7 presents a summary and future directions of our research.
2. Related work
2.1 Existing Urdu word tokenization approaches
In the existing literature, we find only a few studies that have addressed the problem of word tokenization for the Urdu language, these are (Durrani and Hussain Reference Durrani and Hussain2010; Lehal Reference Lehal2010; Rashid and Latif Reference Rashid and Latif2012; Rehman and Anwar Reference Rehman and Anwar2012). The study in Rashid and Latif (Reference Rashid and Latif2012) performs Urdu word tokenization in three phases. First, Urdu words are tokenized based on spaces, thus returning the cluster(s) of valid (single word) and invalid (merged word(s)Footnote c) Urdu words. Next, a dictionary is checked against valid/invalid words to assure the robustness of the word(s). If the word is present in the dictionary, then it will be considered as a valid Urdu word, returning all single words. However, if the word is not matched in the dictionary, then it is considered as a merged word, hence, needing further segmentation. In the second phase, the merged words are divided into all possible combinations, to check the validity of each produced combination through dictionary lookup. If it is present in the dictionary, it will be considered as a valid word. The first two phases solve the problem of space omission (see Section 4.1), and the third phase addresses the space insertion problem by combining two consecutive words and checking them in the dictionary. If the compound word is found in the dictionary, then it will be considered as a single word. This technique of word tokenization was tested on 11,995 words with a reported error rate of 2.8%. However, the efficiency of this algorithm is totally dependent on the dictionary (used to check whether a word is valid or not), and it is practically not possible to have a complete dictionary of Urdu words. Furthermore, if a valid word is not present in the dictionary, then this technique will mark it as invalid, which will be wrong.
Durrani and Hussain (Reference Durrani and Hussain2010) proposed a hybrid Urdu word tokenizer that works in three phases. In the first phase, words are segmented based on space, thus returning a set of an orthographic word(s).Footnote d Further, a rule-based maximum matching technique is used to generate all possible word segmentations of the orthographic words. In the second phase, the resulting words are ranked using minimum word heuristics, uni, and bi-grams based sequence probabilities. In the first two phases, the authors solved the space omission problem (see Section 4.1). In the third phase, the space insertion problem is solved to identify compound words by combining words using different algorithms. The proposed Urdu word tokenizer is trained on 70K words, whereas it is tested on a very small data set of 2367 words reporting an overall error rate of 4.2%. Although the authors have reported a very low error rate, this study has some serious limitations: (i) the evaluation is carried out on a very small data set, which makes the reported results less reliable in terms of how good the word tokenizer will perform on real-world data, (ii) using a statistical n-gram technique that may ultimately lead to data sparseness, and (iii) it does not tokenize Urdu text correctly even for short texts.
Another online CLE Urdu word tokenizer is available through a website,Footnote e which allows tokenization of up to 100 words. Its implementation details are not provided. It reports an accuracy of 97.9%. However, the link is not always available,Footnote f and its API is not freely available.Footnote g We applied the CLE online Urdu work tokenizer on three randomly selected input short texts, and they all were incorrectly tokenized with many mistakes.
The research cited in Lehal (Reference Lehal2010) takes an approach to Urdu word tokenization, based on the Hindi language. The authors tokenized Urdu words after transliterating them from Hindi, as the Hindi language uses spaces consistently as compared to its counterpart Urdu. They also addressed and resolved the space omission problem for Urdu in two phases. In the first phase, Urdu grammar rules have been applied to decide if the Urdu adjacent words have to be merged or not. If the grammatical rules analyzer provides a definite answer that two adjacent words can be joined or not, then no further processing is required. However, if the rule-based analyzer is not confident about two words either it can be joined or not, then the second phase is invoked. In the second phase, Urdu and Hindi uni-gram and bi-gram bilingual lexical resources are used to make the final decision, that is, either we need to join the two adjacent words or not. This technique of Urdu word tokenization used 2.6 million words as training data, whereas it was tested on 1.8 million tokens. The results show an error rate of 1.44%. The limitations of this study are (i) the problem of space insertion has not been addressed, (ii) this approach requires large bilingual corpus which is difficult to create particularly for under-resourced languages like Urdu and Hindi.
Rehman et al. (Reference Rehman, Anwar, Bajwa, Xuan and Chaoying2013) proposed an Urdu word tokenizer by using rule-based (maximum matching) with n-gram statistical approach. This approach to Urdu word tokenization uses several different algorithms to solve the problem of space omission and insertion. First, the forward maximum matching algorithm is used to return the list of individual tokens of Urdu text. Second, the Dynamic Maximum Matching (DMM) algorithm returns all the possible tokenized sequences of the Urdu text, segments are ranked and the best one is accepted. Third, DMM is combined with the bi-gram statistical language model. These three algorithms are used to solve the space omission problem, whereas for the space insertion problem, six different algorithms were used. The authors used 6400 tokens for training and 57,000 tokens for testing. This approach has produced up to 95.46%
 $F_1$
score. Furthermore, the algorithms are based on probabilities that may result in zero probability being assigned to some unknown words. The authors have not handled such cases with either back off or other smoothing estimators.
$F_1$
score. Furthermore, the algorithms are based on probabilities that may result in zero probability being assigned to some unknown words. The authors have not handled such cases with either back off or other smoothing estimators.
To overcome the limitations of the existing studies, our study proposes a novel Urdu word tokenization algorithm using a rule-based morpheme matching approach, with off-the-shelf statistical tri-gram language model with back-off and smoothing characteristics for the space omission problem, whereas the space insertion problem has been solved using dictionary lookup technique (see Section 4.1.2). To train and test our proposed word tokenizer, we developed benchmark training (contains 1.65 million tokens) and testing (contains 59K tokens) data sets. Our word tokenizer and training/testing data sets are freely and publicly available for download (see Section 7 for details).
2.2 Sentence tokenization approaches
The problem of Urdu sentence tokenization has not been thoroughly explored, and we found only two studies (Rehman and Anwar Reference Rehman and Anwar2012; Raj et al. Reference Raj, Rehman, Rauf, Siddique and Anwar2015) that address the issue. Rehman and Anwar (Reference Rehman and Anwar2012) used a hybrid approach that works in two stages. First, a uni-gram statistical model was trained on annotated data. The trained model was used to identify word boundaries on a test data set. In the second step, the authors used heuristic rules to identify sentence boundaries. This study achieved up to 99.48% precision, 86.35% recall, 92.45%
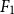 $F_1$
, and 14% error rate, when trained on 3928 sentences; however, the authors did not mention any testing data. Although this study reports an acceptable score, it has some limitations: (1) the error rate is high (14%), (2) the evaluation is carried out on a very small data set, which makes the reported results less reliable, and it is difficult to tell how well the sentence tokenizer will perform on real test data, and (3) the trained model along with training/testing data are not publicly available.
$F_1$
, and 14% error rate, when trained on 3928 sentences; however, the authors did not mention any testing data. Although this study reports an acceptable score, it has some limitations: (1) the error rate is high (14%), (2) the evaluation is carried out on a very small data set, which makes the reported results less reliable, and it is difficult to tell how well the sentence tokenizer will perform on real test data, and (3) the trained model along with training/testing data are not publicly available.
In another study, Raj et al. (Reference Raj, Rehman, Rauf, Siddique and Anwar2015) used an Artificial Neural Network along with POS tags for sentence tokenization in two stages. In the first phase, a POS tagged data set is used to calculate the word-tag probability (P) based on the general likelihood ranking. Furthermore, the POS tagged data set along with probabilities was converted to bipolar descriptor arrays,Footnote h to reduce the error as well as training time. In the next step, these arrays along with frequencies were then used to train feed forward Artificial Neural Network using back propagation algorithm and delta learning rules. The training and testing data used in this study are 2688 and 1600 sentences, respectively. The results show 90.15% precision, 97.29% recall, and 95.08%
 $F_1$
-measure with 0.1 threshold values. The limitations of this study are that the evaluation is carried out on a small set of test data, and the trained model, as well as the developed resources, is not publicly available.
$F_1$
-measure with 0.1 threshold values. The limitations of this study are that the evaluation is carried out on a small set of test data, and the trained model, as well as the developed resources, is not publicly available.
Again, similar to the Urdu word tokenization problem (see Section 2.1), the developed Urdu sentence tokenizers along with training/testing data sets are not publicly available. To fill this gap, our contribution here is an Urdu sentence tokenizer which is a combination of rule-based, regular expressions and dictionary lookup techniques, along with training (contain 12K sentences) and testing (containing 8K sentences) data sets, all of which are free and publicly available for research purposes. Moreover, we have also proposed a novel supervised ML-based sentence tokenizer by extracting various features.
2.3 Part-Of-Speech tagging approaches
Similar to Urdu word (see Section 2.1) and sentence tokenization (see Section 2.2), the problem of Urdu POS tagging has not been thoroughly explored. We found only six studies (Hardie Reference Hardie2004; Anwar et al. Reference Anwar, Wang, Li and Wang2007a; Reference Anwar, Wang, Li and Wangb; Sajjad and Schmid Reference Sajjad and Schmid2009; Muaz et al. Reference Muaz, Ali and Hussain2009; Ahmed et al. Reference Ahmed, Urooj, Hussain, Mustafa, Parveen, Adeeba, Hautli and Butt2014) that addressed the issue.
A pioneering piece of research on Urdu POS tagging is described in Hardie (Reference Hardie2004). This work focused on the development of a uni-rule POS tagger, which consists of 270 manual crafted rules. The author used a POS tagset with 350 tags (Hardie Reference Hardie2003). The training data consist of 49K tokens, whereas testing was carried out on two different data sets containing 42K and 7K tokens. The reported average accuracy for the 42K tokens is 91.66%, whereas for the 7K corpus, the average accuracy is 89.26% with a very high ambiguity level (3.09 tags per word). However, the POS tagset used in this study has several limitations (see Section 4.3) and, therefore, cannot be used for a grammatical tagging task, and having a large number of POS tags with a relatively small training data will affect the accuracy and manually deducing rules is a laborious and expensive task.
The first stochastic POS tagger for the Urdu language was developed in 2007 (Anwar et al. Reference Anwar, Wang, Li and Wang2007a). They have proposed a POS tagger based on a bi-gram Hidden Markov Model with back off to uni-gram model. TwoFootnote i different POS tagsets were used. The reported average accuracies for the 250 POS tagset and 90 POS tagset are 88.82% and 92.60%, respectively. Both were trained on a data set of 1,000 words; however, the authors have not provided any information about the test data set. As before, this study has several limitations; the POS tagset of 250 tags has several grammatical deficiencies (see Section 4.3), the information about the proposed tagset of 90 tags is not available, the system was trained and tested on a very small data set, which shows that it is not feasible for morphological rich and free word order language, that is, Urdu, and used less contextual bi/uni-gram statistical models.
Anwar et al. (Reference Anwar, Wang, Li and Wang2007b) have developed an Urdu POS tagger using bi-gram Hidden Markov Model. The authors proposed six bi-gram Hidden Markov-based POS taggers with different smoothing techniques to resolve data sparseness. The accuracy of these six models varies from 90% to 96%. For each model, they used a POS tagset of 90 tags. However, the authors have not mentioned the size of training/test data sets. This study has several limitations as, like the one in Anwar et al. (Reference Anwar, Wang, Li and Wang2007a), the authors have used a 350 POS tagset, which has several misclassifications (see Section 4.3), the training/testing data split is unknown to readers, and limited smoothing estimators have been used, it used bi-gram language model (i.e., less contextual), and suffix information has not been explored.
The authors in Sajjad and Schmid (Reference Sajjad and Schmid2009) trained Trigrams-and-Tag (TnT) (Brants Reference Brants2000), Tree Tagger (TT) (Schmid Reference Schmid1994b), Random Forest (RF) (Schmid and Laws Reference Schmid and Laws2008), and Support Vector Machine (SVM) (Giménez and Marquez Reference Giménez and Marquez2004) POS taggers, using a tagset containing 42 POS tags. All these stochastic Urdu POS taggers were trained on a 100K word data set, whereas for testing only 9K words were used. The reported accuracy for TnT, TT, RF, and SVM is 93.40%, 93.02%, 93.28%, and 94.15%, respectively. In terms of limitations, they used a POS tagset of 42 tags, which has several grammatical irregularities (see Section 4.3).
In another study (Muaz et al. Reference Muaz, Ali and Hussain2009), stochastic Urdu POS taggers are presented, that is, TnT and TT tagger. These taggers are trained and tested on two different data sets with the following statistics: (i) first data set consists of 101,428 tokens (4584 sentences) and 8670 tokens (404 sentences) for training and testing, respectively, and (ii) the second data set consists of 102,454 tokens (3509 sentences) and 21,181 tokens (755 sentences) for training and testing, respectively. The reported accuracy for the first data set is 93.01% for TnT tagger, whereas 93.37% for TT tagger. For the second data set, TnT tagger produced 88.13% accuracy and TT had 90.49% accuracy. Similar to other studies, it employed a POS tagset that has several grammatical problems (see Section 4.3), meaning that it is no longer practical for Urdu text.
The authors in Ahmed et al. (Reference Ahmed, Urooj, Hussain, Mustafa, Parveen, Adeeba, Hautli and Butt2014) have proposed an Urdu POS taggerFootnote j which is based on Decision Trees and smoothing technique of Class Equivalence, using a tagset of 35 POS tags. It is trained and tested on the CLE Urdu Digest corpus,Footnote k training and test data split are 80K and 20K tokens, respectively. However, this POS tagger is only available through an online interface, which allows tagging of 100 words. It is trained on a relatively small data set that is not freely available. The Decision Tree statistical models are less accurate for Urdu text as compared to HMM, etc. Sajjad and Schmid (Reference Sajjad and Schmid2009) (see Section 6.3).
In contrast, our study contributes a set of Urdu POS taggers along with large training (containing 180K POS tagged tokens) and testing (containing 20K POS tagged tokens) data sets. Our proposed POS taggers are based on two machine learning techniques, tri-gram Hidden Markov Model (HMM) and Maximum Entropy (MaEn) based models. Each of our proposed HMM and MaEn models is a combination of different backoff, smoothing estimators, suffix, and other types of binary valued features. To the best of our knowledge, these models along with smoothing, backoff, suffix, and binary valued features have not been explored previously for the Urdu language.
3. Challenges of Urdu NLP tools
3.1 Challenges for word tokenization
Is a challenging and complex task for the Urdu language due to three main problems (Durrani and Hussain Reference Durrani and Hussain2010): (i) the space omission problem—Urdu uses Nastalique writing style and cursive script, in which Urdu text does not often contain spaces between words, (ii) the space insertion problem—irregular use of spaces within two or more words, and (iii) ambiguity in defining Urdu words—in some cases, Urdu words lead to an ambiguity problem because there is no clear agreement to classify them as a single word or multiple words.
The first two problems stated above mostly arise due to the nature of Urdu characters, which are divided into (i) joiner (nonseparators) and (ii) nonjoiner (separators). Non-joiner charactersFootnote l only merge themselves with their preceding character(s). Therefore, there is no need to insert space or Zero Width Non Joiner (ZWNJ; an Urdu character which is used to keep the word separate from their following) if a word ends with such characters. These can form isolated shapes besides final shape, whereas joiner charactersFootnote m can form all shapes (isolated, initial, medial, and final) (Bhat et al. Reference Bhat and Sharma2012) with respect to their neighboring letter(s). For instance, the Urdu character ![]() (khay) is a joiner and has four shapes: (i) isolated
(khay) is a joiner and has four shapes: (i) isolated ![]() (khay), for example,
(khay), for example,  (KHOKH ‘peach’), that is, it can be seen that at the end of a word, if the character is a joiner and its preceding character is nonjoiner, it will form an isolated shape, (ii) final
(KHOKH ‘peach’), that is, it can be seen that at the end of a word, if the character is a joiner and its preceding character is nonjoiner, it will form an isolated shape, (ii) final ![]() (khay), for example,
(khay), for example,  (MKH ‘brain’), it can be observed that at the end of a word, if the character is a joiner, it acquires the final shape when leading a joiner, (iii) medial
(MKH ‘brain’), it can be observed that at the end of a word, if the character is a joiner, it acquires the final shape when leading a joiner, (iii) medial ![]() (khay), for example,
(khay), for example,  (BKHAR ‘fever’), in other words, it shows that in the middle of a word, if the character is a joiner, it will form the medial shape when the preceding character is a joiner, (iv) initial
(BKHAR ‘fever’), in other words, it shows that in the middle of a word, if the character is a joiner, it will form the medial shape when the preceding character is a joiner, (iv) initial ![]() (khey), for example,
(khey), for example, ![]() (KHOF ‘fear’), it shows that at the start of a word, if the character is a joiner, it acquires the initial shape when following a nonjoiner. Furthermore, the Urdu character
(KHOF ‘fear’), it shows that at the start of a word, if the character is a joiner, it acquires the initial shape when following a nonjoiner. Furthermore, the Urdu character ![]() (zaal) is a nonjoiner, thus has only two shapes: (i) isolated
(zaal) is a nonjoiner, thus has only two shapes: (i) isolated ![]() (zaal), for example,
(zaal), for example, ![]() (“Zakir”), it can be noticed that at the beginning of a word, if the character is a nonjoiner, it acquires isolated shape when following a joiner, (ii) final
(“Zakir”), it can be noticed that at the beginning of a word, if the character is a nonjoiner, it acquires isolated shape when following a joiner, (ii) final ![]() (zaal), for example,
(zaal), for example,  (LZYZ ‘delicious’), it can be examined that at the end of a word, if the character is nonjoiner, it acquires final shape when preceding a joiner character. The shapes that these characters (joiner or nonjoiners) acquire totally depend upon the context.
(LZYZ ‘delicious’), it can be examined that at the end of a word, if the character is nonjoiner, it acquires final shape when preceding a joiner character. The shapes that these characters (joiner or nonjoiners) acquire totally depend upon the context.
A reader can understand a text if a word which ends on a joiner character is separated by a space 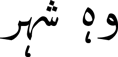 (OH SHHR, ‘that city’) or ZWNJ characterFootnote n
(OH SHHR, ‘that city’) or ZWNJ characterFootnote n  (NYY SAYYKL HE, ‘is new bicycle’). Likewise, the dropping of either of them (space or ZWNJ) will result in a visual incorrectFootnote o text,
(NYY SAYYKL HE, ‘is new bicycle’). Likewise, the dropping of either of them (space or ZWNJ) will result in a visual incorrectFootnote o text,  (OH SHHR, “that city”) and
(OH SHHR, “that city”) and  (NYY SAYYKL HE, “is new bicycle”), thus being perceived as a single word even though they are two and three different words, respectively. On the other hand, a word which ends on a nonjoiner character does not character does not merge itself with other words, for instance,
(NYY SAYYKL HE, “is new bicycle”), thus being perceived as a single word even though they are two and three different words, respectively. On the other hand, a word which ends on a nonjoiner character does not character does not merge itself with other words, for instance,  (KMPYOTR ANTRNYT, “computer internet”) and
(KMPYOTR ANTRNYT, “computer internet”) and ![]() (MDDKRO, “help him”), even if we remove space or ZWNJ character. Note that the (KMPYOTR ANTRNYT, “computer internet”) and
(MDDKRO, “help him”), even if we remove space or ZWNJ character. Note that the (KMPYOTR ANTRNYT, “computer internet”) and ![]() (MDDKRO, “do help”) are also incorrect text, each of them is a combination of two words. As,
(MDDKRO, “do help”) are also incorrect text, each of them is a combination of two words. As, ![]() (MDDKRO, “do help”) is
(MDDKRO, “do help”) is ![]() (MDD, “help”) and
(MDD, “help”) and ![]() (KRO, “do”), whereas
(KRO, “do”), whereas  (KMPYOTR ANTRNYT, “computer internet”) have
(KMPYOTR ANTRNYT, “computer internet”) have  (KMPYOTR, “computer”) and
(KMPYOTR, “computer”) and ![]() (ANTRNYT, “internet”) words. However, omitted space(s) between all ambiguous text results in a space omission problem, which can be overcome by inserting a space at the end of the first word so that two or three distinct words can be detected. For example,
(ANTRNYT, “internet”) words. However, omitted space(s) between all ambiguous text results in a space omission problem, which can be overcome by inserting a space at the end of the first word so that two or three distinct words can be detected. For example,  (NYY SAYYKL HE, “is new bicycle”) are three distinct words, written without spaces, in order to tokenize them properly we need to insert spaces at the end of
(NYY SAYYKL HE, “is new bicycle”) are three distinct words, written without spaces, in order to tokenize them properly we need to insert spaces at the end of ![]() (NYY, “new”), and
(NYY, “new”), and  (SAYYKL “bicycle”) so that three different tokens can be generated: (i)
(SAYYKL “bicycle”) so that three different tokens can be generated: (i) ![]() (NYY, “new”), (ii)
(NYY, “new”), (ii)  (SAYYKL, “bicycle”), and (iii)
(SAYYKL, “bicycle”), and (iii) ![]() (HY, “is”). As it can be noted from the above discussion, space omission problems are complex thus making the Urdu word tokenization task particularly challenging.
(HY, “is”). As it can be noted from the above discussion, space omission problems are complex thus making the Urdu word tokenization task particularly challenging.
In the space insertion problem, if the first word ends either on a joiner or nonjoiner, a space at the end of the first word (see Table 1, Correct column– incorrect multiple tokens with space (-), but correct shape) can be inserted for several reasons: (i) affixes can be separated from their root, (ii) to keep separate Urdu abbreviations when transliterated, (iii) increase readability for Urdu proper nouns and English/foreign words are transliterated, (iv) compound words and reduplication morphemes do not visually merge and form a correct shape, and (v) to avoid making words written incorrectly or from combining (see Table 1, incorrect column-single token but incorrect shape). For example,  (KHOSH AKHLAK, “polite”) is a compound word of type affixation; however, space was inserted between
(KHOSH AKHLAK, “polite”) is a compound word of type affixation; however, space was inserted between ![]() (KHOSH, “happy”), that is, a prefix (literally “happy”) and
(KHOSH, “happy”), that is, a prefix (literally “happy”) and ![]() (AKHLAK, “ethical”), that is, root to increase the readability and understandability. To identify
(AKHLAK, “ethical”), that is, root to increase the readability and understandability. To identify  (KHOSH AKHLAK, “polite”) as a single word/token the tokenizer will need to ignore the space between them. This also serves to emphasize the fact that the space insertion problem is also a very challenging and complex task in Urdu word tokenization.
(KHOSH AKHLAK, “polite”) as a single word/token the tokenizer will need to ignore the space between them. This also serves to emphasize the fact that the space insertion problem is also a very challenging and complex task in Urdu word tokenization.
Table 1. Example text for various types of space omission problems

As discussed earlier, in some cases, Urdu words are harder to disambiguate. There is no clear agreement on word boundaries in a few cases (sometimes they are considered as a single word even by a native speaker). For example the compound word, 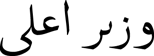 (OZYR AALY, “chief minister”),
(OZYR AALY, “chief minister”),  (BHN BHAYY, “sibling,” literally “brother sister”). The same is the case for reduplications,
(BHN BHAYY, “sibling,” literally “brother sister”). The same is the case for reduplications, ![]() (FR FR, “fluent”) and affixation,
(FR FR, “fluent”) and affixation, ![]() (BD AKLAK, “depravedly”). Certain function words (normally case markers, postpositions, and auxiliaries) can be written jointly, for example,
(BD AKLAK, “depravedly”). Certain function words (normally case markers, postpositions, and auxiliaries) can be written jointly, for example, ![]() (ASMYN, “herein”),
(ASMYN, “herein”),  (YHOKT, “this time”), or
(YHOKT, “this time”), or  (Ho GEE). Alternatively, the same function words can be written separately such as
(Ho GEE). Alternatively, the same function words can be written separately such as  (AS MYN, “herein”),
(AS MYN, “herein”), ![]() (YH OKT, “this time”), and (HO GEE) (i.e., two auxiliaries), respectively. These distinct forms of the same word(s) are visually correct and may be perceived as single or multiple words. These types of cases are ambiguous, that is, can be written with or without spaces and can be treated as a single unit or two different words. Consequently, this changes the perception of where the word boundary should sit. A possible solution to handle such words is to use a knowledge base. To conclude, the space insertion problem, space omission problem, and ambiguity in tokenizing multiwords make the Urdu word boundary detection a complex and challenging task. This may be a possible explanation for the fact that no standard efficient Urdu word tokenizer is publicly available. An efficient Urdu word tokenization system would be needed to deal with these issues and to properly tokenize Urdu text.
(YH OKT, “this time”), and (HO GEE) (i.e., two auxiliaries), respectively. These distinct forms of the same word(s) are visually correct and may be perceived as single or multiple words. These types of cases are ambiguous, that is, can be written with or without spaces and can be treated as a single unit or two different words. Consequently, this changes the perception of where the word boundary should sit. A possible solution to handle such words is to use a knowledge base. To conclude, the space insertion problem, space omission problem, and ambiguity in tokenizing multiwords make the Urdu word boundary detection a complex and challenging task. This may be a possible explanation for the fact that no standard efficient Urdu word tokenizer is publicly available. An efficient Urdu word tokenization system would be needed to deal with these issues and to properly tokenize Urdu text.
To conclude, the space insertion problem, space omission problem, and ambiguity in tokenizing multi-words make the Urdu word boundary detection a complex and challenging task. This may be a possible explanation for the fact that no standard efficient Urdu word tokenizer is publicly available. An efficient Urdu word tokenization system would be needed to deal with these issues and to properly tokenize Urdu text.
3.2 Challenges for sentence boundary detection
Sentence boundary detection is a nontrivial task for Urdu text because (i) it does not use any special distinguishing characters between upper and lower case, (ii) punctuation markers are not always used as sentence separators, (iii) sentences are written without any punctuation markers, and (iv) there is a lack of standard evaluation and supporting resources. For English and other languages, the difference in upper and lower case is helpful in identifying sentence boundaries. Furthermore, in English language, there is a convention that if a period is followed by a word starting with a capital letter, then it is more likely to be a sentence marker, whereas in Urdu, there are no upper and lower-case distinctions. Punctuation such as “![]() ”, “.”, “
”, “.”, “![]() ” and “
” and “![]() ’” are used as sentence terminators, and these can also be used inside the sentence.
’” are used as sentence terminators, and these can also be used inside the sentence.
The Table 2 shows example sentence boundary markers (SBM) (such as sentences at index i, ii, iii, and iv, in all these sentences question, period, exclamation, and double quotes marker are used at the end of sentences to represent a sentence boundary) and nonsentence boundary markers (NSBM) for Urdu text. It can be observed from these examples that the NSBM are also frequent because they are being used between dates (such as sentence at index vii, in this sentence a period mark is used with in a sentence which is actually not a sentence boundary), abbreviations (index v, this sentence is composed of several period markers; however, first two are not indicating a sentence boundary marker), emphatic declaration (index vi, here exclamation marker is used with in a sentence, that is, not a sentence boundary mark), names and range (index viii, i.e., a first period and double quote marker is used within a sentence, but both are not a sentence ending marker), and sentences without any SBM (index ix). Consequently, these kinds of examples make the sentence tokenization of Urdu text a challenging task.
Table 2. Examples showing Sentence Boundary Markers (SBM) and Non-Sentence Boundary Markers (NSBM) for Urdu text

aQM: Question Mark, PM: Period Mark, EM: Exclamation Mark, DQ: Double Quotes
3.3 Challenges for POS tagging
POS tagging for the Urdu language is also challenging and difficult task due to four main problems (Mukund et al. Reference Mukund, Srihari and Peterson2010; Naz et al. Reference Naz, Anwar, Bajwa and Munir2012): (i) free word order (general word order is SOV), (ii) polysemous words, (iii) Urdu is highly inflected and morphologically rich, and (iv) the unavailability of gold-standard training/testing data set(s). We briefly discuss these issues here.
First, Urdu sentences have a relatively complex syntactic structure compared to English. Anwar et al. (Reference Anwar, Wang, Li and Wang2007b) have shown examples of the free word order and its semantic meaningfulness in the Urdu language. Second, as with other languages, Urdu also has many polysemous words, where a word changes it meaning according to its context. For example, the word ![]() (BASY) means “stale” if it is an adjective and “resident” when it is a noun. Third, Urdu is also a highly inflected and a morphologically rich language because gender, case, number, and forms of verbs are expressed by the morphology (Hardie Reference Hardie2003; Sajjad and Schmid Reference Sajjad and Schmid2009). Moreover, Urdu language represents case with a separate character after the head noun of the noun phrase (Sajjad and Schmid Reference Sajjad and Schmid2009). They are sometimes considered as postpositions in Urdu due to their place of occurrence and separate occurrence. If we consider them as case markers, then Urdu has accusative, dative, instrumental, genitive, locative, nominative, and ergative cases (Butt, Reference Butt1995: p. 10). Usually, a verb phrase contains a main verb, a light verb (which is used to describe the aspect), and a tense verb (describes the tense of the phrase) (Hardie Reference Hardie2003; Sajjad and Schmid Reference Sajjad and Schmid2009). Finally, there is a lack of benchmark training/testing data sets that can be used for the development and evaluation of Urdu POS taggers.
(BASY) means “stale” if it is an adjective and “resident” when it is a noun. Third, Urdu is also a highly inflected and a morphologically rich language because gender, case, number, and forms of verbs are expressed by the morphology (Hardie Reference Hardie2003; Sajjad and Schmid Reference Sajjad and Schmid2009). Moreover, Urdu language represents case with a separate character after the head noun of the noun phrase (Sajjad and Schmid Reference Sajjad and Schmid2009). They are sometimes considered as postpositions in Urdu due to their place of occurrence and separate occurrence. If we consider them as case markers, then Urdu has accusative, dative, instrumental, genitive, locative, nominative, and ergative cases (Butt, Reference Butt1995: p. 10). Usually, a verb phrase contains a main verb, a light verb (which is used to describe the aspect), and a tense verb (describes the tense of the phrase) (Hardie Reference Hardie2003; Sajjad and Schmid Reference Sajjad and Schmid2009). Finally, there is a lack of benchmark training/testing data sets that can be used for the development and evaluation of Urdu POS taggers.
4. Urdu natural language toolkit
This study aims to develop a natural language toolkit for the Urdu language. The UNLT consists of word tokenization, sentence tokenization, and POS tagging modules. The following sections discuss these modules in more detail.
4.1 Urdu word tokenizer
4.1.1 Generating supporting resources for Urdu word tokenizer
For our proposed Urdu word tokenizer, we have developed two dictionaries: (i) a complex words dictionary— to address space insertion problem and (ii) a morpheme dictionary—to address the problem of space omission.
Complex words dictionary: To address the space insertion problem, a large complex words dictionary was created using the UMC Urdu data set (Jawaid, Kamran, and Bojar Reference Jawaid, Kamran and Bojar2014), which contains data from various domains including Sports, Politics, Blogs, Education, Literature, Entertainment, Science, Technology, Commerce, Health, Law, Business, Showbiz, Fiction, and Weather. From each domain, at least 1000 sentences were randomly selected and preprocessed to remove noise (see Section 5.4). After noise removal, to speed up the dictionary creation process, a basic space-based tokenization approach was implemented in Java to split sentences into words. Space-based tokenization resulted in some incorrect word generation, for example, complex words such as the prefix ![]() (AN GNT “countless”) is incorrectly split into a morpheme,
(AN GNT “countless”) is incorrectly split into a morpheme, ![]() (AN, literally “this”) and a stem,
(AN, literally “this”) and a stem, ![]() (GNT, literally “count”), postfix
(GNT, literally “count”), postfix  (HMLH AAOR, “assailant”) is incorrectly split as
(HMLH AAOR, “assailant”) is incorrectly split as ![]() (HMLH, “attack”), that is, a root and
(HMLH, “attack”), that is, a root and  (AAOR, literally “hour”), that is, a morpheme
(AAOR, literally “hour”), that is, a morpheme
Compound words that can be categorized into three types with respect to their formation: (i) AB formation– two roots and stems join together, (ii) A-o-B formation– two stems or roots are linked to each other with the help of ![]() (wao) (a linking morpheme), and (iii) A-e-B formation– “e” is the linking morpheme which shows relation between A and B (for more detailed discussion see Rehman, Anwar, and Bajwa Reference Rehman, Anwar and Bajwa2011). In this research, all three types have been used without any classification, for example, A-o-B formation type of compound word
(wao) (a linking morpheme), and (iii) A-e-B formation– “e” is the linking morpheme which shows relation between A and B (for more detailed discussion see Rehman, Anwar, and Bajwa Reference Rehman, Anwar and Bajwa2011). In this research, all three types have been used without any classification, for example, A-o-B formation type of compound word ![]() (GHOR O FKR, “contemplation”) is incorrectly split as
(GHOR O FKR, “contemplation”) is incorrectly split as ![]() (GHOR, literally “ponder”) a root,
(GHOR, literally “ponder”) a root, ![]() (O) a linking morpheme, and a stem
(O) a linking morpheme, and a stem ![]() (FKR, literally “worry”). Reduplication that have two types: (i) full reduplicated word—two duplicate words are used to form a word and (ii) echo reduplication—the onset of the content word is replaced with another consonant (detailed information can be found in Bögel et al. Reference Bögel, Butt, Hautli and Sulger2007). Echo reduplication word,
(FKR, literally “worry”). Reduplication that have two types: (i) full reduplicated word—two duplicate words are used to form a word and (ii) echo reduplication—the onset of the content word is replaced with another consonant (detailed information can be found in Bögel et al. Reference Bögel, Butt, Hautli and Sulger2007). Echo reduplication word, ![]() (DN BDN, “day by day”) is incorrectly split as
(DN BDN, “day by day”) is incorrectly split as ![]() (DN, literally “day”), that is, content word and
(DN, literally “day”), that is, content word and ![]() (BDN, literally “body”), a consonant. One million space-based tokenized words list (henceforth UMC-Words) has been used to form a large complex words dictionary containing: (i) affixes, (ii) reduplications, (iii) proper nouns, (iv) English words, and (v) compound words.
(BDN, literally “body”), a consonant. One million space-based tokenized words list (henceforth UMC-Words) has been used to form a large complex words dictionary containing: (i) affixes, (ii) reduplications, (iii) proper nouns, (iv) English words, and (v) compound words.
To collect affixes (prefixes and postfixes) complex words from the UMC-Words list (Jawaid et al. Reference Jawaid, Kamran and Bojar2014), a two-step approach is used. In the first step, a list of prefixes and postfixes are manually generated. In the second step, an automatic routine is used to extract words containing affixes from the large UMC-Words list. Using prefixes and postfixes, the previous and next words are extracted, respectively, from the UMC-Words list.
Reduplications complex words are collected using two methods: (i) full extraction and (ii) partial extraction. The full extraction method is used to extract the full reduplicated words such as ![]() (JYSY JYSY, “as”). To extract such full reduplicated words, we compared each word in the UMC-Words list to the next word, if both are the same then concatenate both to form a full reduplicated compound word. The partial extraction method is used to collect the words of echo reduplication, that is, in which a consonant word is a single edit distance away from the first content word. The echo reduplication words can be further collected using two methods: (i) one insertion extraction and (ii) single substitution extraction.
(JYSY JYSY, “as”). To extract such full reduplicated words, we compared each word in the UMC-Words list to the next word, if both are the same then concatenate both to form a full reduplicated compound word. The partial extraction method is used to collect the words of echo reduplication, that is, in which a consonant word is a single edit distance away from the first content word. The echo reduplication words can be further collected using two methods: (i) one insertion extraction and (ii) single substitution extraction.
One insertion extraction method extracts the one insertion reduplicated words, in which the consonant word has one insertion in its content word, for example, ![]() (DN BDN, “day by day”). It can be noted that the consonant word
(DN BDN, “day by day”). It can be noted that the consonant word ![]() (BDN, literally meaning “body”) has one more character (three) as compared to the content word
(BDN, literally meaning “body”) has one more character (three) as compared to the content word ![]() (DN, literally “day”) (which have two characters). Furthermore, the last two characters of the consonant word are identical to the content word. To extract one insertion reduplicated words, we used the UMC-Words list. The extraction process works as follows: after excluding the first character, if the remaining characters of consonant word are identical as well as having the same character count to the content word, they are one insertion reduplicated word(s) we concatenated them to form a single word.
(DN, literally “day”) (which have two characters). Furthermore, the last two characters of the consonant word are identical to the content word. To extract one insertion reduplicated words, we used the UMC-Words list. The extraction process works as follows: after excluding the first character, if the remaining characters of consonant word are identical as well as having the same character count to the content word, they are one insertion reduplicated word(s) we concatenated them to form a single word.
The single substitution extraction method extracts the single substituted reduplicated word(s)—here the consonant word has single substitution in its content word, for example, ![]() (KHLT MLT, “intermixed”). It is worth noting that both words content
(KHLT MLT, “intermixed”). It is worth noting that both words content ![]() (KHLT, literally “bad”) and consonant
(KHLT, literally “bad”) and consonant ![]() (transliteration: MLT) has three characters and the final two characters are overlapping. To extract one substituted reduplicated word(s) we used automatic routine and applied the following process over the UMC-Words list as: if the length of the content word is matched with the length of the consonant word and the length of content word is greater than twoFootnote p characters, and if one character is dissimilar after comparing character by character, then it will form a single substitution reduplicated complex word.
(transliteration: MLT) has three characters and the final two characters are overlapping. To extract one substituted reduplicated word(s) we used automatic routine and applied the following process over the UMC-Words list as: if the length of the content word is matched with the length of the consonant word and the length of content word is greater than twoFootnote p characters, and if one character is dissimilar after comparing character by character, then it will form a single substitution reduplicated complex word.
To automatically extract abbreviations (91) and proper nouns (2K), regular expressions are used and further supplemented by manual checking to increase the size of the proper nouns (3K) and abbreviations lists (187). The remaining 65K proper noun list was generated in another NLP project and are used in this study for Urdu word tokenization. In addition to this, manual workFootnote q was also carried out to remove noisy affix entries. Moreover, compound words (of formation AB and A-e-B) and English words are added to increase the size of the complex words dictionary. However, to collect words of A-o-B formation automatically, a linking morpheme (![]() , O) has been used. While using a linking morpheme both previous and next words are extracted from the UMC-Words list to form a A-o-B compound words.
, O) has been used. While using a linking morpheme both previous and next words are extracted from the UMC-Words list to form a A-o-B compound words.
The complete statistics of the complex words dictionary are as follows: there are in total 80,278 complex words (7820 are affixes, 278 are abbreviations, 10,000 are MWEs, 1480 are English words, 60,000 are proper nouns, and 700 are reduplication words).
Morpheme segmentation process: To address the space omission problem (see Section 4.1.2), a large-scale morpheme dictionary is automatically compiled from the HC data set (Christensen Reference Christensen2014). Before we proceed further toward the approach used to generate the morphemes dictionary, it is worth describing the morpheme types. Urdu language morphemes can be categorized into (i) free and (ii) bound morphemes. Proposed word tokenizer has to rely on both categories. The bound or functional morphemes such as affixes include prefixes, for example, “ ” (GA, LA, KO), linking morphemes, for example,
” (GA, LA, KO), linking morphemes, for example, ![]() (A, O) or suffixes, for example,
(A, O) or suffixes, for example, ![]() (transliteration: SHDH, ZDH), can only expose their meanings if they are attached to other words, that is, they cannot stand alone. Whereas free or lexical morphemes can stand alone, for example,
(transliteration: SHDH, ZDH), can only expose their meanings if they are attached to other words, that is, they cannot stand alone. Whereas free or lexical morphemes can stand alone, for example,  (MKBOL, CHST, ALM, GHM, “grief, knowledge, clever, famous”).
(MKBOL, CHST, ALM, GHM, “grief, knowledge, clever, famous”).
There are two further categories of free morphemes: (i) true free morphemes and (ii) pseudo-free morphemes. True free morphemes can be either standalone (for e.g., ![]() (DL, “heart”)) or form part of other words (e.g.,
(DL, “heart”)) or form part of other words (e.g., ![]() (DRD DL, “angina pectoris”)). Pseudo-free morphemes can be a character, affix, or word.
(DRD DL, “angina pectoris”)). Pseudo-free morphemes can be a character, affix, or word.
The preceding discussion summarizes the various types of morphemes. However, from a computational linguistics view, free and bound morphemes play a vital role in Urdu word formations (Khan et al. Reference Khan, Anwar, Bajwa and Wang2012); hence, they will be used without any further classification in our proposed UNLT word tokenizer module.
In order to generate the morpheme dictionary, the 1000 most frequent words which have more than 20 occurrences in the HC data set are used (Christensen Reference Christensen2014); the selected words were split to form a morpheme dictionary. The whole chopping process is completed in two steps: (i) Crude-Morphemes (CM) chopping and (ii) Ultra-Crude-Morphemes (UCM) chopping.
In the first step, the first n character(s) of each word are kept while the rest are discarded. For example, in case of
 $n = 1$
, we kept only the first character and discarded all others, thus words such as
$n = 1$
, we kept only the first character and discarded all others, thus words such as ![]() (OAKFYT, “awareness”) will return
(OAKFYT, “awareness”) will return ![]() (wao). Such single character morphemes are helpful to formulate compound words, for instance
(wao). Such single character morphemes are helpful to formulate compound words, for instance  (KHSH O KHRM, “canty”). Furthermore, we keep chopping all the words repeatedly with the following values of
(KHSH O KHRM, “canty”). Furthermore, we keep chopping all the words repeatedly with the following values of
 $n = 2,3.4,5,6$
.Footnote r This process returns
$n = 2,3.4,5,6$
.Footnote r This process returns  (transliterations are: OA, OAK, OAKF, OAKFY, OAKFYT) morphemes for the word
(transliterations are: OA, OAK, OAKF, OAKFY, OAKFYT) morphemes for the word ![]() (OAKFYT, “awareness”). There may be a situation where we may lose several valuable morpheme(s), if the length of
(OAKFYT, “awareness”). There may be a situation where we may lose several valuable morpheme(s), if the length of
 $n > 6$
. Nevertheless, this is a rare case. Henceforth, we will call this method Crude-Morpheme chopping.
$n > 6$
. Nevertheless, this is a rare case. Henceforth, we will call this method Crude-Morpheme chopping.
To generate entirely different morphemes from the same word, we further applied a modified version of CM chopping, that is, UCM. In which, we skipped the first character and then applied the CM chopping with length
 $n = 2,3,4$
. Thus, UCM chopping resulted with these morphemes,
$n = 2,3,4$
. Thus, UCM chopping resulted with these morphemes,  (transliterations are: AK, AKF, AKFY, AKFYT) for the word
(transliterations are: AK, AKF, AKFY, AKFYT) for the word ![]() (OAKFYT, “awareness”). Furthermore, we iterate the UCM chopping method by skipping the first two characters (as well as three, four etc.), until we meet the last two characters. Thus, the following morphemes are returned by UCM, in the third
(OAKFYT, “awareness”). Furthermore, we iterate the UCM chopping method by skipping the first two characters (as well as three, four etc.), until we meet the last two characters. Thus, the following morphemes are returned by UCM, in the third ![]() (transliterations are: KF, KFY, KFYT), in the fourth
(transliterations are: KF, KFY, KFYT), in the fourth ![]() (transliterations are FY, FYT), and in the last
(transliterations are FY, FYT), and in the last ![]() (transliteration, YT) iterations.
(transliteration, YT) iterations.
Repeating CM and UCM chopping on the entire list of words will return all possible morphemes. The two chopping methods used in this study will result in erroneous morphemes. However, we manually examined the morpheme dictionary and removed these. The number of morphemes generated by the CM and UCM chopping methods is 5089 and 7376, respectively.
It can be observed from the above discussion that two different large-scale dictionaries, that is, the complex words dictionary and the morphemes dictionary are generated with distinct approaches and with various statistics. These dictionaries will be used to solve the space omission and space insertion problems with the word tokenizer module of UNLT. To the best of our knowledge, no such large complex words (a study Hautli and Sulger 2009 just proposed a scheme to extract location and person name), and morpheme dictionaries have been previously compiled semi-automatically for Urdu, to perform Urdu word tokenization.
4.1.2 Proposed Urdu word tokenizer
To investigate an effective approach for UNLT Word Tokenization (henceforth UNLT-WT approach), our method (see Algorithm 1) is a combination of state-of-the-art approaches: rule-based maximum matching, dictionary lookup, statistical tri-gram Maximum Likelihood Estimation (MLE) with back-off to bi-gram MLE. Furthermore, smoothing is applied to avoid data sparseness. A step-by-step working example of the proposed algorithm can be seen at.Footnote s However, this section just presents the statistical approach used to solve space omission problem.
Algorithm 1 UNLT-WT approach

Maximum likelihood and smoothing estimation: In our proposed UNLT-WT approach (see Algorithm 1) at step 11.1, we used tri-gram MLE and smoothing estimations because there can be multiple tokenized sequences for which flag_bit=false and word_count are equal. For instance, there are two given texts, (i)  (transliteration: ASE BAHR JA KE PRHNE DO, “let him go abroad for higher studies”) and (ii)
(transliteration: ASE BAHR JA KE PRHNE DO, “let him go abroad for higher studies”) and (ii)  (transliteration: ASE BAHR JY KE PRHNE DO, literally meaning “let him yes abroad for higher studies”). Both have six tokens with flag_bit= false, but only the first text is semantically correct and meaningful. For such ambiguous cases, we calculate an N-gram language model with MLE for parameter and Laplace for smoothing estimation. The goal of these estimations is to find an optimized segmented sequence with the highest probability. This can be shown by a given mathematical expression, a general statistical model of our proposed UNLT-WT approach.
(transliteration: ASE BAHR JY KE PRHNE DO, literally meaning “let him yes abroad for higher studies”). Both have six tokens with flag_bit= false, but only the first text is semantically correct and meaningful. For such ambiguous cases, we calculate an N-gram language model with MLE for parameter and Laplace for smoothing estimation. The goal of these estimations is to find an optimized segmented sequence with the highest probability. This can be shown by a given mathematical expression, a general statistical model of our proposed UNLT-WT approach.
 \begin{equation} \hat{P} (m_{j}|m_{1-N+1}m_{n-N+2}...m_{j-1})= \underset{M\in \varsigma (I|D)}{\arg \max} P(M)\end{equation}
\begin{equation} \hat{P} (m_{j}|m_{1-N+1}m_{n-N+2}...m_{j-1})= \underset{M\in \varsigma (I|D)}{\arg \max} P(M)\end{equation}
Here,
 $\varsigma(I|D)$
denotes all possible tokenized words of the input string, that is,
$\varsigma(I|D)$
denotes all possible tokenized words of the input string, that is,
 $I=i_{1} i_{2} ... i_{l}$
with l characters, and M denotes string concatenation of all possible tokenized sequences, that is,
$I=i_{1} i_{2} ... i_{l}$
with l characters, and M denotes string concatenation of all possible tokenized sequences, that is,
 $M=m_{1}m_{2}...m_{n}$
, in terms of morphemes dictionary D. Theoretically, it is assumed that the n-gram model outperforms with a high value of N. However, practically the data sparseness restricts better performance with high order N. Therefore, in our UNLT-WT approach, we opted for tri-gram (
$M=m_{1}m_{2}...m_{n}$
, in terms of morphemes dictionary D. Theoretically, it is assumed that the n-gram model outperforms with a high value of N. However, practically the data sparseness restricts better performance with high order N. Therefore, in our UNLT-WT approach, we opted for tri-gram (
 $N=3$
) or bi-gram (
$N=3$
) or bi-gram (
 $N=2$
) MLE. These have proved to be successful in several tasks for resolving ambiguity (e.g., POS tagging Brants Reference Brants2000, automatic speech recognition Abdelhamid, Abdulla, and MacDonald Reference Abdelhamid, Abdulla and MacDonald2012 and word tokenization Fu, Kit, and Webster Reference Fu, Kit and Webster2008).
$N=2$
) MLE. These have proved to be successful in several tasks for resolving ambiguity (e.g., POS tagging Brants Reference Brants2000, automatic speech recognition Abdelhamid, Abdulla, and MacDonald Reference Abdelhamid, Abdulla and MacDonald2012 and word tokenization Fu, Kit, and Webster Reference Fu, Kit and Webster2008).
The task of resolving similar sequence ambiguities for the above two texts is accomplished by using tri-gram MLE (Jurafsky and Martin Reference Jurafsky and Martin2014) as
 \begin{equation} P\left ( t_j |t_{j-2},t_{j-1} \right )= \frac{C\left ( t_{j-2},t_{j-1},t \right )}{C\left ( t_{j-2},t_{j-1} \right )}\end{equation}
\begin{equation} P\left ( t_j |t_{j-2},t_{j-1} \right )= \frac{C\left ( t_{j-2},t_{j-1},t \right )}{C\left ( t_{j-2},t_{j-1} \right )}\end{equation}
where t represents the individual token, C is a count of three (
 $t_{j-2}t_{j-1}t$
) and two (
$t_{j-2}t_{j-1}t$
) and two (
 $t_{j-2}t_{j-1}$
) consecutive words in the data set, and P is the tri-gram contestant MLE value of each of the possible segmented sequences. The calculated probability for the first sequence is 3.2e-08 while for the second it is 0.
$t_{j-2}t_{j-1}$
) consecutive words in the data set, and P is the tri-gram contestant MLE value of each of the possible segmented sequences. The calculated probability for the first sequence is 3.2e-08 while for the second it is 0.
As tri-grams take account of more context, if this specific context is not found in the training data (see Section 5.1), we back-off to a narrower contextual bi-gram language model. Bi-gram cumulative probability values have been calculated as given by Jurafsky and Martin (Reference Jurafsky and Martin2014):
 \begin{equation} P\left ( t_j |t_{j-1} \right )= \frac{C\left ( t_{j-1}t \right )}{C\left ( t_{j-1} \right )}\end{equation}
\begin{equation} P\left ( t_j |t_{j-1} \right )= \frac{C\left ( t_{j-1}t \right )}{C\left ( t_{j-1} \right )}\end{equation}
where t represents the individual token, C is a count of two (
 $t_{j-1}t$
) and one (
$t_{j-1}t$
) and one (
 $t_{j-1}$
) consecutive word(s) in the data set, and P is the bi-gram contestant MLE value of each of the possible segmented sequences. The calculated probability for the first sequence is 2.7e-6 for the former sequence and 0 for the latter one.
$t_{j-1}$
) consecutive word(s) in the data set, and P is the bi-gram contestant MLE value of each of the possible segmented sequences. The calculated probability for the first sequence is 2.7e-6 for the former sequence and 0 for the latter one.
These zero probabilities are again an underestimation of the input string, ultimately a cause for the data sparseness. Even if a statistical language model is trained on a very large data set, it will remain sparse in some cases. However, there is always a possibility that the input text occurs in the test data set (Chen and Goodman Reference Chen and Goodman1999), thus assigning them to zero made this an unstable, frail, and specific estimator. Therefore, to overcome this, different smoothing techniques have been proposed in previous literature (Jurafsky and Martin Reference Jurafsky and Martin2014) with different characteristics (such as smoothing the probability, etc.). Hence, it is primarily aimed at making a robust and generalize language model by re-evaluating lower or zero probability upward and vice-versa for high probabilities.
For this study, we employed Laplace (add-one) smoothing (Jeffreys Reference Jeffreys1998), as one of the oldest, simplest, and baseline estimations. This estimation adds one to all frequency counts, that is, that all bi-gram probability counts have been seen one more time than actually exists in the training data as
 \begin{equation} P_{add:1}\left ( t_j |t_{j-1} \right )= \frac{1+C\left ( t_{j-1},t \right )}{V+C\left ( t_{j-1} \right )}\end{equation}
\begin{equation} P_{add:1}\left ( t_j |t_{j-1} \right )= \frac{1+C\left ( t_{j-1},t \right )}{V+C\left ( t_{j-1} \right )}\end{equation}
where v represents the unique words (types), added to the total number of words
 $C(t_{j-1}) $
in order to keep the probability normalized (Jurafsky and Martin Reference Jurafsky and Martin2014). We have used Laplace smoothing to estimate the parameters required for data sparseness in order to increase the bi-gram MLE value for
$C(t_{j-1}) $
in order to keep the probability normalized (Jurafsky and Martin Reference Jurafsky and Martin2014). We have used Laplace smoothing to estimate the parameters required for data sparseness in order to increase the bi-gram MLE value for  (transliteration: ASE BAHR JY KE PRHNE DO, “let him go abroad for higher studies”), from 0 to 1.9e-14, and decreased value for
(transliteration: ASE BAHR JY KE PRHNE DO, “let him go abroad for higher studies”), from 0 to 1.9e-14, and decreased value for  (transliteration: ASE BAHR JA KE PRHNE DO, literally meaning “let him yes abroad for higher studies”), from 2.7e-6 to 3.8e-7. As the latter tokenized sequence has the highest smoothing MLE. Therefore, it will be selected by UNLT-WT as the best tokenized sequence, which is correct.
(transliteration: ASE BAHR JA KE PRHNE DO, literally meaning “let him yes abroad for higher studies”), from 2.7e-6 to 3.8e-7. As the latter tokenized sequence has the highest smoothing MLE. Therefore, it will be selected by UNLT-WT as the best tokenized sequence, which is correct.
4.2 Urdu sentence tokenizer
4.2.1 Rule-based approach
For our proposed rule-based approach, to manually extract rules for the sentence tokenization task, initially, a subset of the UMC data set (Jawaid et al. Reference Jawaid, Kamran and Bojar2014) composed of 13K sentences is selected, which contains Urdu text from various domains or genres including News, Religion, Blogs, Literature, Science, and Education. After preprocessing (see Section 5.4), we retained 10K sentences, which were used to extract rules to develop our proposed Urdu sentence tokenizer. The rules were devised to include sentence termination markers (![]() ,
, ![]() ,
, ![]() and
and ![]() ), regular expressions, and supplementary dictionary lookupFootnote t (henceforth UNLT-ST-RB approach). These heuristics are applied as follows:
), regular expressions, and supplementary dictionary lookupFootnote t (henceforth UNLT-ST-RB approach). These heuristics are applied as follows:
-
1. If the current character is a period marker (
 ) AND the same mark appears after two or three characters, then consider it as an abbreviation and match it in the abbreviation list.
) AND the same mark appears after two or three characters, then consider it as an abbreviation and match it in the abbreviation list. -
2. If within the next 9 characters (from any previous SBM marker), an exclamation mark (
) is found, then this is not a sentence boundary marker. -
3. If the character before a double quote (
) is a period () or question () mark, then it is a sentence boundary marker. -
4. Apply regular expressions for detecting the date and hyphenated numeric values.
-
5. In addition to this all the above rules from 1 to 4, split sentences based on the question (
), period (), and exclamation () markers.
4.2.2 ML-based approach
In this approach, we are exploiting a support vector machines (SVM) classifier (Hearst et al. Reference Hearst, Dumais, Osuna, Platt and Scholkopf1998) to detect the sentence boundaries of the Urdu text—using the features described below another approach is formed, that is, UNLT-ST-ML. SVMs offer robust classification even with sparse vectors of large dimension (Akita et al. Reference Akita, Saikou, Nanjo and Kawahara2006), its good performance results on textual data and its suitability for binary classification (Kreuzthaler et al. 2015) task make this a suitable classifier for sentence boundary detection. Moreover, SVMs use a function (see Equation (5)) for classifying sentence boundary label pairs
 $(x_j, y_j), j= 1,...,m$
for all
$(x_j, y_j), j= 1,...,m$
for all
 $x_j \in \mathbb{R}^{n}$
to a target value
$x_j \in \mathbb{R}^{n}$
to a target value
 $y \in \{ 1,-1 \}$
. Where
$y \in \{ 1,-1 \}$
. Where
 $w \in \mathbb{R}^{n}$
a weight coefficient and
$w \in \mathbb{R}^{n}$
a weight coefficient and
 $b \in \mathbb{R}$
is a bias. We are using a polynomial kernel implemented in Weka.Footnote u
$b \in \mathbb{R}$
is a bias. We are using a polynomial kernel implemented in Weka.Footnote u
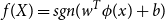 \begin{equation} f(X) = sgn (w^{T} \phi (x)+b)\end{equation}
\begin{equation} f(X) = sgn (w^{T} \phi (x)+b)\end{equation}
Features for ML approach:
-
• Probability (UMC data setFootnote v Jawaid et al. Reference Jawaid, Kamran and Bojar2014 is used) that a word with “
, and ” occurs at the end of a sentence -
• Probability (UMC data setFootnote w is used Jawaid et al. Reference Jawaid, Kamran and Bojar2014) that a word with “
, and ” occurs at the beginning of a sentence -
• Length of a word with “
, and ” -
• Length of a word after “
, and ” -
• Is a sentence contains an abbreviation
-
• Is a sentence contains a date/numeration
-
• Bi- and tri-grams words information (preceding “
, and ”) are used -
• If a word before “
, and ” markers contains any one of the tag (NN, NNP, JJ, SC, PDM, PRS, CD, OD, FR, Q, and CC. See Section 4.3.1 for POS tags) is not a sentence boundary
4.3 Urdu part of speech tagging
4.3.1 Existing Urdu POS tagset
The tagging accuracy of a POS tagger is not only dependent on the quality and amount of training data set but also on the POS tagset used for annotation. In the prior literature, we found three commonly used POS tagsets for the Urdu language:
-
(i) Hardie’s POS tagset (Hardie Reference Hardie2004),
-
(ii) Sajjad’s POS tagset (Sajjad Reference Sajjad2007), and
-
(iii) Centre for Language Engineering (CLE) Urdu POS tagset (Ahmed et al. Reference Ahmed, Urooj, Hussain, Mustafa, Parveen, Adeeba, Hautli and Butt2014).
Hardie’s POS tagset (Hardie Reference Hardie2004) was an early attempt to resolve the grammatical tag disambiguation problem for the Urdu language. This tagset follows the EAGLESFootnote x guidelines and consists of 350 morphosyntatic tags, which are divided into 13 main categories. Some grammarians (Platts Reference Platts1909) propose only three main categories, whereas (Schmidt Reference Schmidt1999) used 10 main categories for Urdu text. There were a number of shortcomings observed in Hardie’s POS tagset (Hardie Reference Hardie2004). For example, the possessive pronouns like ![]() (MYRA “my”),
(MYRA “my”),  (TMHARA “your”), and
(TMHARA “your”), and  (HMARA “our”) are assigned to the category of possessive adjective, which is incorrect. Many grammarians marked them as pronouns (Platts Reference Platts1909; Javed Reference Javed1985). Moreover, the Urdu language has no articles, but this tagset defined articles. Another issue with the tagset is the use of locative and temporal adverbs such as
(HMARA “our”) are assigned to the category of possessive adjective, which is incorrect. Many grammarians marked them as pronouns (Platts Reference Platts1909; Javed Reference Javed1985). Moreover, the Urdu language has no articles, but this tagset defined articles. Another issue with the tagset is the use of locative and temporal adverbs such as  (YHAN “here”),
(YHAN “here”),  (OHAN “there”), and
(OHAN “there”), and ![]() (AB “now”), which are treated as pronouns. The locative and temporal nouns such as treated as pronouns. The locative and temporal nouns such as
(AB “now”), which are treated as pronouns. The locative and temporal nouns such as treated as pronouns. The locative and temporal nouns such as ![]() (SBH “morning”),
(SBH “morning”),  (SHAM “evening”), and
(SHAM “evening”), and  (GHR “home”) appear in a very similar syntactic context. To conclude, these grammatical misclassifications as well as the large number of POS tags with relatively small training data will affect the accuracy of POS taggers developed for the Urdu language.
(GHR “home”) appear in a very similar syntactic context. To conclude, these grammatical misclassifications as well as the large number of POS tags with relatively small training data will affect the accuracy of POS taggers developed for the Urdu language.
Another POS tagset (henceforth Sajjad’s POS tagset) (Sajjad and Schmid Reference Sajjad and Schmid2009), consists of 42 POS tags with finer grained categories for pronouns and demonstratives. However, it is lacking in terms of Urdu verb, tense, and aspect.
A recently released CLE Urdu POS tagset (Ahmed et al. Reference Ahmed, Urooj, Hussain, Mustafa, Parveen, Adeeba, Hautli and Butt2014) contains 35 tags and addresses most of the issues reported above. It is based on the critical analysis of several previous iterations of Urdu POS tagsets. Furthermore, it is built on the guidelines of the Penn TreebankFootnote y and a POS tagset for common Indian languages.Footnote z In the CLE Urdu POS tagset, a verb category has multiple tags based on the morphology of the verbs. Furthermore, it has shown promising results on Urdu text see Section 2.3).
For this study, we selected the CLE Urdu POS tagset (Ahmed et al. Reference Ahmed, Urooj, Hussain, Mustafa, Parveen, Adeeba, Hautli and Butt2014) for the following reasons: (i) it provides correct grammatical classifications, (ii) it provides purely syntactic categories for major word classes, and (iii) provides reasonable performance on a small size test data set.
4.3.2 Proposed Urdu POS tagging approaches
For this study, we applied two stochastic approaches for Urdu POS tagging: (i) tri-gram Hidden Markov Model and (ii) Maximum Entropy-based model. The reason for selecting these two methods for Urdu POS tagging is many fold, (a) they have proven to be effective for POS tagging not just for English (Yi Reference Yi2015) but also for other languages which are closely related to Urdu such as Hindi (Dandapat Reference Dandapat2008; Joshi, Darbari, and Mathur Reference Joshi, Darbari and Mathur2013), (b) both are well established stochastic models for automatic POS tagging task (Wicaksono and Purwarianti Reference Wicaksono and Purwarianti2010), (c) these methods have been primarily investigated for when dealing with languages with limited resources (Azimizadeh, Arab, and Quchani Reference Azimizadeh, Arab and Quchani2008; Ekbal, Haque, and Bandyopadhyay Reference Ekbal, Haque and Bandyopadhyay2008), and (d) these models have not been previously compared for the Urdu language.
Hidden Markov Model (HMM) for POS tagging: In general, the Urdu POS tagging task can be formulated as: given a sequence of words
 $w_{1},...,w_{n}$
, find the sequence of POS tags
$w_{1},...,w_{n}$
, find the sequence of POS tags
 $t_{1},...,t_{n}$
from a POS tagsetFootnote aa using some statistical model. In this section, we have used HMM stochastic learning model described by Rabiner (Reference Rabiner1989), while Thede and Harper (Reference Thede and Harper1999) redefined it for the POS disambiguation task. This model was implemented in Garside and Smith (Reference Garside and Smith1997), Bird et al. (Reference Bird, Klein and Loper2009) for POS tagging. For our experiments, we used a third-order HMM learning model, also referred to as a tri-gram POS tagging. This model is composed of transitional (contextual) and lexical (emission) probabilities as:
$t_{1},...,t_{n}$
from a POS tagsetFootnote aa using some statistical model. In this section, we have used HMM stochastic learning model described by Rabiner (Reference Rabiner1989), while Thede and Harper (Reference Thede and Harper1999) redefined it for the POS disambiguation task. This model was implemented in Garside and Smith (Reference Garside and Smith1997), Bird et al. (Reference Bird, Klein and Loper2009) for POS tagging. For our experiments, we used a third-order HMM learning model, also referred to as a tri-gram POS tagging. This model is composed of transitional (contextual) and lexical (emission) probabilities as:
 \begin{equation} \hat{T}= \underset{t\in T}{\arg \max} P(t_{1},...,t_{n})|(w_{1},...,w_{n})\end{equation}
\begin{equation} \hat{T}= \underset{t\in T}{\arg \max} P(t_{1},...,t_{n})|(w_{1},...,w_{n})\end{equation}
Using Bayes’ theorem, the above equation can be rewritten as for
 $3{\rm rd}$
order model as
$3{\rm rd}$
order model as
 \begin{equation} P(t_{1},...,t_{n}|w_{1},...,w_{n})= \underset{t_{1},...,t_{n}} {\arg \max} \prod_{j=3}^{n} \underset{Transition Probability}{( \underbrace{{P(t_{j}|t_{j-1},t_{j-2}}})} * \prod_{i=1}^{n} \underset{Lexical Probability}{\underbrace{P(w_{i}|t_{i}}))}\end{equation}
\begin{equation} P(t_{1},...,t_{n}|w_{1},...,w_{n})= \underset{t_{1},...,t_{n}} {\arg \max} \prod_{j=3}^{n} \underset{Transition Probability}{( \underbrace{{P(t_{j}|t_{j-1},t_{j-2}}})} * \prod_{i=1}^{n} \underset{Lexical Probability}{\underbrace{P(w_{i}|t_{i}}))}\end{equation}
During the training process, the above tri-gram HMM language model computes two probability factors for the sequences: (i) emission probabilities, aimed at determining the probability of a particular tag conditioned on particular word and (ii) transitional probabilities, used to find the probability of a particular tag on the basis of given preceding tag(s). Given a sentence, the aim of the HMM language model is to search the tagging sequence and choose the most likely sequence that maximizes the dot product of lexical and transition probabilities. That can be computed by using a Viterbi algorithm (Viterbi Reference Viterbi1967).
Parameter estimation: We can estimate the HMM parameters by applying the simplest tri-gram MLE (see Section 4.1.2), used for computing relative frequencies. We have used a training data set (see Section 5.3) to find tag frequency counts (C) for two or three consecutive tag pairs (
 $t_{j-2},t_{j-1},t_{j}$
), (
$t_{j-2},t_{j-1},t_{j}$
), (
 $t_{j-2},t_{j-1}$
). Where
$t_{j-2},t_{j-1}$
). Where
 $t_{j}$
is the
$t_{j}$
is the
 $j_{th}$
tag of annotated data set used during training process. The following equation requires frequencies count of
$j_{th}$
tag of annotated data set used during training process. The following equation requires frequencies count of
 $w_{i}t_{i}$
, where
$w_{i}t_{i}$
, where
 $w_{i}$
is the word and
$w_{i}$
is the word and
 $t_{i}$
is the tag assigned to
$t_{i}$
is the tag assigned to
 $i_{th}$
word. The tri-gram language model (see Section 4.1.2) and the following equation is used with these parameter settings,
$i_{th}$
word. The tri-gram language model (see Section 4.1.2) and the following equation is used with these parameter settings,
 $1\leq (i,j) \leq n $
.
$1\leq (i,j) \leq n $
.
 \begin{equation} P(w_{i}|t_{i})= \frac{C(w_{i}t_{i})}{C(t_{i})}\end{equation}
\begin{equation} P(w_{i}|t_{i})= \frac{C(w_{i}t_{i})}{C(t_{i})}\end{equation}
Smoothing: We have used the MLE for parameter estimation (see Section 4.3.2), consequently, such models may come across a situation where unseen events do not occur or have quite low frequencies in the trained model. Therefore, the zero probability of such occurrences produces problems in the multiplication of probabilities, eventually, leading to a data sparseness.
To avoid data sparseness, we need some estimators that automatically assign a part of the probability mass to unknown words and tag sequences, thus yielding an improvement for unseen events and overall accuracy improvement for the POS tagger. For this, different smoothing techniques have been cited in the literature with an objective to decrease the probability of seen events and assigning appropriate nonzero probability mass to unseen events. In this study, five different smoothing techniques were adopted including (i) linear interpolation, (ii) Laplace, (iii) Lidstone’s, (iv) Good-Turing, and (v) Kneser–Ney estimations. Adopting them with an HMM model thus alleviates sparse data issues.
Linear interpolation: A well-practised smoothing technique consists of linearly combined estimation for different order n-grams as
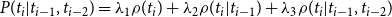 \begin{equation} P(t_{i}|t_{i-1},t_{i-2})= \lambda_{1}\rho(t_{i})+ \lambda_{2}\rho(t_{i}|t_{i-1})+ \lambda_{3}\rho(t_{i}|t_{i-1},t_{i-2})\end{equation}
\begin{equation} P(t_{i}|t_{i-1},t_{i-2})= \lambda_{1}\rho(t_{i})+ \lambda_{2}\rho(t_{i}|t_{i-1})+ \lambda_{3}\rho(t_{i}|t_{i-1},t_{i-2})\end{equation}
where P is a valid probability distribution,
 $\rho$
are maximum likelihood estimates of the probabilities, and
$\rho$
are maximum likelihood estimates of the probabilities, and
 $ \lambda_{1}+\lambda_{2}+\lambda_{3}=1$
to normalize the probability. Although there are different ways to estimate
$ \lambda_{1}+\lambda_{2}+\lambda_{3}=1$
to normalize the probability. Although there are different ways to estimate
 $ \lambda $
s, for our experiments, we adopted deleted linear interpolation, cited in Brants (Reference Brants2000).
$ \lambda $
s, for our experiments, we adopted deleted linear interpolation, cited in Brants (Reference Brants2000).
The deleted linear interpolation successively removes each tri-gram from the training data set. Moreover, this technique estimates the best value for the
 $ \lambda $
s from all other n-grams in the data set, making sure that the value of
$ \lambda $
s from all other n-grams in the data set, making sure that the value of
 $ \lambda $
does not depend upon the particular n-gram. Further, it computes the weights depending on the counts of each i-gram, involved in the interpolation. Thus, our first HMM-based proposed model is a combination of linear interpolation smoothing technique along with tri-gram HMM model (henceforth T-HMM-LI).
$ \lambda $
does not depend upon the particular n-gram. Further, it computes the weights depending on the counts of each i-gram, involved in the interpolation. Thus, our first HMM-based proposed model is a combination of linear interpolation smoothing technique along with tri-gram HMM model (henceforth T-HMM-LI).
Laplace and Lidstone’s estimation: Laplace estimation (one of the oldest and simplest smoothing techniques) updates the count by one of each bi-gram occurs compared to the actual frequency in training data (Jurafsky and Martin Reference Jurafsky and Martin2014) (see Section 4.1.2). Whereas Lidstone’s smoothing estimation (Manning and Schütze Reference Manning and Schütze1999) generalizes Laplace, by adding an arbitrary value to all (seen or unseen) the events. Although the values for
 $ \lambda $
can be calculated using different methods, for our experiments we used the same value cited in the research article (Manning and Schütze Reference Manning and Schütze1999), that is, a well-known expected likelihood estimation (ELE). Thus, Lidstone’s estimation (Manning and Schütze Reference Manning and Schütze1999) can be calculated as
$ \lambda $
can be calculated using different methods, for our experiments we used the same value cited in the research article (Manning and Schütze Reference Manning and Schütze1999), that is, a well-known expected likelihood estimation (ELE). Thus, Lidstone’s estimation (Manning and Schütze Reference Manning and Schütze1999) can be calculated as
 \begin{equation} P_{lidstone(x,\lambda)}= \frac{\lambda +C(X)}{V\lambda +N}\ \ \ \ \ \lambda = 0.5\end{equation}
\begin{equation} P_{lidstone(x,\lambda)}= \frac{\lambda +C(X)}{V\lambda +N}\ \ \ \ \ \lambda = 0.5\end{equation}
where V represents the unique words (vocabulary) against the total number of words N to keep probabilities normalized (Jurafsky and Martin Reference Jurafsky and Martin2014). The generalized formulation of Lidstones and Laplace estimation in an HMM-based Urdu tagger is as follows:
 \begin{equation} \pi_{i}= \frac{C(s_{i}(t=0))+\lambda }{C(tokens)+V_{tag}\lambda }\end{equation}
\begin{equation} \pi_{i}= \frac{C(s_{i}(t=0))+\lambda }{C(tokens)+V_{tag}\lambda }\end{equation}
 \begin{equation} a_{ij}= \frac{C(s_{i}\rightarrow s_{j} )+\lambda }{C(tokens)+V_{tag}\lambda }\end{equation}
\begin{equation} a_{ij}= \frac{C(s_{i}\rightarrow s_{j} )+\lambda }{C(tokens)+V_{tag}\lambda }\end{equation}
 \begin{equation} P{(s_j)}= \frac{C(s_{j} )+\lambda }{C(tokens)+V_{tag}\lambda }\end{equation}
\begin{equation} P{(s_j)}= \frac{C(s_{j} )+\lambda }{C(tokens)+V_{tag}\lambda }\end{equation}
 \begin{equation} P{(w_k)}= \frac{C(w_{k} )+\lambda }{C(tokens)+V_{w}\lambda }\end{equation}
\begin{equation} P{(w_k)}= \frac{C(w_{k} )+\lambda }{C(tokens)+V_{w}\lambda }\end{equation}
Here,
 $V_{tag}$
is the number of possible tags and
$V_{tag}$
is the number of possible tags and
 $V_w$
is the size of the approximated vocabulary. Our second POS tagging model is a combination of Laplace and tri-gram HMM model (henceforth T-HMM-LaE). The third POS tagger makes use of Lidstone’s estimation and supervised tri-gram HMM model parameters (we shall call this T-HMM-LiE).
$V_w$
is the size of the approximated vocabulary. Our second POS tagging model is a combination of Laplace and tri-gram HMM model (henceforth T-HMM-LaE). The third POS tagger makes use of Lidstone’s estimation and supervised tri-gram HMM model parameters (we shall call this T-HMM-LiE).
Good–Turing estimation: Uses the probability mass of n-grams (that occur
 $c+1$
times) which is seen once to re-estimate the count of n-grams (that are seen exactly c times) that were never seen. This can be described as
$c+1$
times) which is seen once to re-estimate the count of n-grams (that are seen exactly c times) that were never seen. This can be described as
 \begin{equation} c^{*} = (c+1) \frac{n_{c+1}}{n_{c}}\end{equation}
\begin{equation} c^{*} = (c+1) \frac{n_{c+1}}{n_{c}}\end{equation}
The fourth POS tagger makes use of Good–Turing estimation and supervised tri-gram HMM model parameters (hereafter, T-HMM-GT).
Kneser–Ney smoothing: This outperforms all other smoothing techniques. In this paper, we have used the modified version of this smoothing (Christer Reference Christer1996), which is an interpolated variation of Kneser–Ney smoothing with an augmented version of absolute discounting, thus the transition probabilities
 $p(t_j|t_{j-1})$
are calculated as
$p(t_j|t_{j-1})$
are calculated as
 \begin{equation} P(t_j|t_{j-1})= \frac{f(t_{j-1}t_j)-D(f(t_{j-1}t_j))}{\sum_{t_j} f(t_{j-1}t_j)}+\gamma (t_{j-1}).\frac{N_{1+}(\cdot ,t_i)}{N_{1+}(\cdot \cdot )}\end{equation}
\begin{equation} P(t_j|t_{j-1})= \frac{f(t_{j-1}t_j)-D(f(t_{j-1}t_j))}{\sum_{t_j} f(t_{j-1}t_j)}+\gamma (t_{j-1}).\frac{N_{1+}(\cdot ,t_i)}{N_{1+}(\cdot \cdot )}\end{equation}
Here D is estimated value and D(f) =
 $\{0$
if
$\{0$
if
 $f=0$
,
$f=0$
,
 $D_1$
if
$D_1$
if
 $f=1, D_2$
if
$f=1, D_2$
if
 $f=2,$
}. Another POS tagger is formed using supervised tri-gram HMM model and Kneser–Ney smoothing (henceforth T-HMM-KN).
$f=2,$
}. Another POS tagger is formed using supervised tri-gram HMM model and Kneser–Ney smoothing (henceforth T-HMM-KN).
Maximum Entropy (MaEn) model for POS tagging: The other adopted stochastic learning model is MaEn, and we aimed to compare this to the above described tri-gram HMM-based models, to find the most optimal POS tagger for Urdu. The MaEn statistical assumption is a simplistic model, it assigns a probability distribution for every tag, given a word and its context as
 \begin{equation} P(t_{1},...,t_{n}|w_{1},...,w_{n})= \prod_{j=1}^{n} P(t_{j}|c_{j})\end{equation}
\begin{equation} P(t_{1},...,t_{n}|w_{1},...,w_{n})= \prod_{j=1}^{n} P(t_{j}|c_{j})\end{equation}
where t is the individual tag in the set T of all possible tags, that is,
 $t_{1},...,t_{n}$
for a given a sentence, c is defined as the context, usually defined as the sequence of words
$t_{1},...,t_{n}$
for a given a sentence, c is defined as the context, usually defined as the sequence of words
 $w_{1},...,w_{n}$
and the tag preceding the word. The maximum likelihood tag sequence is used for assigning probabilities to a string of input words.
$w_{1},...,w_{n}$
and the tag preceding the word. The maximum likelihood tag sequence is used for assigning probabilities to a string of input words.
The principle of estimating probabilities in MaEn model is to make as few assumptions as possible, other than the constraint imposed. Furthermore, these constraints are learned from the training data, which express some relation between features extracted and outcome. The probability distribution which satisfies the above property has the highest entropy; thus, it agrees with the maximum likelihood distribution and has a general form as cited in Ratnaparkhi (Reference Ratnaparkhi1996):
 \begin{equation} P(t|c)=\frac{1}{N}exp\sum_{j=1}^{k}\alpha_{j}f_{j}(c,t)\end{equation}
\begin{equation} P(t|c)=\frac{1}{N}exp\sum_{j=1}^{k}\alpha_{j}f_{j}(c,t)\end{equation}
where N is the total number of training samples (normalization constant), and
 $f_{j}$
is feature function on the event (c,t). Feature functions used by MaEn model are binary valued and defined to capture relevant aspects of language. The
$f_{j}$
is feature function on the event (c,t). Feature functions used by MaEn model are binary valued and defined to capture relevant aspects of language. The
 $\alpha_{j}$
is a model parameter with k features, which is determined through the Generalize Iterative Scaling (GIS) algorithm (Curran and Clark Reference Curran and Clark2003). However, these model values and features are primary ingredients of MaEn learning model.
$\alpha_{j}$
is a model parameter with k features, which is determined through the Generalize Iterative Scaling (GIS) algorithm (Curran and Clark Reference Curran and Clark2003). However, these model values and features are primary ingredients of MaEn learning model.
Features selection in MaEn model: As described previously, the MaEn is feature-based probabilistic model, to obtain high accuracy we used two binary valued features that might be helpful for predicting POS tag, these are determined empirically for Urdu POS tagging along with MaEn model as (i) context window and (ii) word number. The best context window with five words has been identified, which is composed of n-gram (
 $W_{i-2}$
,
$W_{i-2}$
,
 $W_{i-1}$
,
$W_{i-1}$
,
 $W_i$
,
$W_i$
,
 $W_{i+1}$
,
$W_{i+1}$
,
 $W_{i+2}$
) and n-POS (
$W_{i+2}$
) and n-POS (
 $t_{i-2}$
,
$t_{i-2}$
,
 $t_{i-1}$
, and
$t_{i-1}$
, and
 $t_i$
) information. If the current word is a number such as “
$t_i$
) information. If the current word is a number such as “![]() ”, another feature can be created:
”, another feature can be created:
 \begin{equation} f_{j}(c,t)=\begin{Bmatrix} \ 1 \ if \ WordReadIsNumber \ (w_{j})=true \ and \ t_{j}= CD\\else \ 0\end{Bmatrix}\end{equation}
\begin{equation} f_{j}(c,t)=\begin{Bmatrix} \ 1 \ if \ WordReadIsNumber \ (w_{j})=true \ and \ t_{j}= CD\\else \ 0\end{Bmatrix}\end{equation}
Using the above-mentioned features with MaEn, we formulated another Urdu POS tagging model (henceforth MEn). However, these suitable binary valued features are the same for other languages. We examine some other important feature sets for the Urdu language below.
Morphological information for HMM and MaEn models: To improve the tagging accuracy of the unknown words in the above models, we have developed an exclusive feature set after detailed analysis of the UNLT-POS training data set (see Section 5.3). This feature set is intended to have the capability to capture lexical and morphological characteristics (features) of the Urdu language. The captured morphological features are based on information retrieved from a stemmerFootnote bb and dictionary,Footnote cc assuming that information is complete.Footnote dd Thus, we boosted the lexical probability of assigning restricted lexical (POS) tag to a word. Consequently, the integrated models are expected to perform better with such artificial weight (reduced set of possibilities) for a given word. All the above models (T-HMM-LI, T-HMM-LaE, T-HMM-LiE, T-HMM-GT-MA, T-HMM-KN, and MEn) are incorporated with such restricted POS tags features, henceforth, T-HMM-LI-MA, T-HMM-LaE-MA, T-HMM-LIE-MA, T-HMM-GT-MA, T-HMM-KN-MA, and MEn-MA.
The above-mentioned MA information is helpful to restrict the possible choice of POS tags for a given word, on the other hand, suffix and prefix (of current word) information can also help us to further improve the POS models. For HMM-based POS models, suffix information has been used during the smoothing of emission probabilities. Whereas for the MEn model, the suffix and prefix information are used as another type of feature. It is extended using a prefix and suffix up to a length of four. It is also important to note, using prefix and suffixes of length
 $<=4$
for all words in MEn gives better results instead of using only rare words as described by Ratnaparkhi (Reference Ratnaparkhi1996). The primary reason for much improved results based on prefix and suffix is that a significant number of instances are not found for most of the word of the language vocabulary, with a small amount of annotated data. HMM based (T-HMM-LI, T-HMM-LaE, T-HMM-LiE, T-HMM-GT, and T-HMM-KN), and MEn models are incorporated with suffix information, we shall call them T-HMM-LI-Suf, T-HMM-LaE-Suf, T-HMM-LiE-Suf, T-HMM-GT-Suf, T-HMM-KN-Suf, and MEn-Suf POS taggers.
$<=4$
for all words in MEn gives better results instead of using only rare words as described by Ratnaparkhi (Reference Ratnaparkhi1996). The primary reason for much improved results based on prefix and suffix is that a significant number of instances are not found for most of the word of the language vocabulary, with a small amount of annotated data. HMM based (T-HMM-LI, T-HMM-LaE, T-HMM-LiE, T-HMM-GT, and T-HMM-KN), and MEn models are incorporated with suffix information, we shall call them T-HMM-LI-Suf, T-HMM-LaE-Suf, T-HMM-LiE-Suf, T-HMM-GT-Suf, T-HMM-KN-Suf, and MEn-Suf POS taggers.
The last six POS models represent combinations of various statistical, smoothing, and features as described above. The T-HMM-LI-Suf-MA is a combination of tri-gram HMM along with Linear interpolation, restricted POS tags feature, and suffix information. T-HMM-LaE-Suf-MA is based on the tri-gram HMM model with further incorporation of Laplace smoothing, suffix, and restricted POS tags. In T-HMM-LiE-Suf-MA, we have used tri-gram HMM along with Lidstone’s estimation, with suffix, and restricted POS tags. The T-HMM-GT-Suf-MA is a combination of tri-gram HMM along with Good-Turing, restricted POS tags, and suffix information. In T-HMM-KN-Suf-MA, tri-gram HMM, Kneser–Ney estimation, suffix, and restricted POS tags are used. MEn-Suf-MA POS tagging model is a collection of, MaEn, contextual window, suffix, and restricted POS tags.
4.4 Deep learning approaches for comparison
We have performed an empirical comparison of our proposed word/sentence tokenizers and POS tagger, with the recently proposed Trankit NLP Toolkit (Nguyen et al. Reference Nguyen, Lai, Veyseh and Nguyen2021). We have selected this deep learning toolkit for the evaluation process as this has reported good results as compared to other deep learning methods. This is a light-weight transformers-based (a deep neural network-based new SOTA architecture in NLP Vaswani et al. 2017) tool for multi/monolingual text processing, with trainable and pretrained pipelines for NLP tasks for 100 languages including Urdu. Trankit’s recent versionFootnote ee NLP tools are built upon the transformer XLM-RoBERTa (Conneau et al. Reference Conneau, Khandelwal, Goyal, Chaudhary, Wenzek, Guzman, Grave, Ott, Zettlemoyer and Stoyanov2020) (a cross-lingual transformers based masked language model, trained on more than 2 terabytes of preprocessed Common Crawl data for 100 languages), extends the state-of-the-art in word/sentence tokenization, dependency parsing, part-of-speech tagging, and tagging of morphological features. It also attained high performance in various other basic NLP tasks including word tokenization, multiword expansion, and lemmatization of the 90 treebanks.
Trankit’s word and sentence tokenizers are based on word parts rather than character-based to exploit the contextual information (Kudo Reference Kudo2018). It begins on a given input text t, by splitting it into substrings on the basis of space. Furthermore, a multilingual sentence splitter (Kudo and Richardson Reference Kudo and Richardson2018) further breaks each substring into word pieces, concatenated to obtain an overall sequence of word parts
 ${w}=[w_1,w_2,w_3,.....,w_n]$
for t. In the next step, a pretrained transformer takes w as input to produce corresponding representation vectors
${w}=[w_1,w_2,w_3,.....,w_n]$
for t. In the next step, a pretrained transformer takes w as input to produce corresponding representation vectors
 ${v}=[v_1,v_2,v_3,.....,v_n]$
for each word parts in the sequence w. Each vector from v will be fed to a feed forward neural network with a softmax at the end to predict whether the
${v}=[v_1,v_2,v_3,.....,v_n]$
for each word parts in the sequence w. Each vector from v will be fed to a feed forward neural network with a softmax at the end to predict whether the
 $w_i$
is the end of a single word, multiword, or a sentence. Finally, all of the predictions for all word parts w are accumulated to decide a single-word token, multiword token, and sentence boundaries for the given input text t. Word and sentence tokenization using this approach is denoted by Trankit-WT and Trankit-ST, respectively.
$w_i$
is the end of a single word, multiword, or a sentence. Finally, all of the predictions for all word parts w are accumulated to decide a single-word token, multiword token, and sentence boundaries for the given input text t. Word and sentence tokenization using this approach is denoted by Trankit-WT and Trankit-ST, respectively.
Trankit uses the detected words/tokens and sentences for POS tagging at sentence-level. For a given input sentence s, the transformers-generated representation of each of its words is computed by aggregating the representation of its word pieces. These distributed representational vectors are further fed to a softmax layer to predict the most probable POS tag for each word in the input sentence s. POS tagging using this approach is denoted by using Trankit-POST.
5. Proposed data set for UNLT
5.1 Data set for Urdu word tokenization
Testing data: Another key element of our research is to develop a large benchmark data set, for the evaluation of our proposed UNLT-WT approach (see Section 4.1.2). The process of developing a benchmark test data set is divided into three steps: (i) raw text collection, (ii) cleaning, and (iii) annotation.
In the first phase, raw data are collected from various online sources (BBC Urdu,Footnote ff Express news,Footnote gg Urdu Library,Footnote hh Urdu Point,Footnote ii Minhaj Library,Footnote jj Awaz-e-DostFootnote kk and WikipediaFootnote ll) by using a Web crawler.Footnote mm The collected raw data are free and publicly available for research purposes and belongs to following genres: Commerce, Entertainment, Health, Weather, Science and Technology, Sports, Politics and Religion. This collected text contains 61,152 tokens.
In the next phase of the test data set creation process, the collected raw text was preprocessed (see Section 5.4), which resulted in the removal of 2152 tokens. The remaining cleaned data are composed of 59,000 tokens (3583 sentences).
The quality of evaluation of an Urdu word tokenization approach depends on the annotation quality of the test data set because inconsistent and noisy annotations deteriorate the model’s performance. Thus, the annotations were performed by three different annotators (D, E, and F). All the annotators are native speakers of Urdu. The annotation process is further divided into three phases: (i) training, (ii) annotation, and (iii) inter-rater agreement calculation and conflict resolution.
In the training phase, two annotators (D and E) annotated a subset of 58 sentences. After that, the interannotator agreement was computed for these sentences, and conflicting tokens were discussed to further improve the annotation quality. In the annotation phase, the remaining test data set comprising of 3525 sentences was annotated by annotators D and E. After the annotation phase, the inter-rater reliability score was computed for the entire test data set of 59,000 tokens. We obtained the interannotator agreement of 86.3% as the annotators had agreement on 50,917 pairs. The Kappa coefficient was computed to be 78.09%, which is considered as good, considering the levels of difficulty for classifying the merge (space omission) and compound words (space insertion) into single or multiple tokens (see Section 3.1). Furthermore, the conflicting tokens were annotated, and decisions resolved by the third annotator F, which resulted in a gold standard UNLT-Word Tokenizer-Test (UNLT-WT-Test) data set.
Table 3 shows the type-token ratio of the UNLT-WT-Test data set that have a total of 59,000 tokens and 5849 types. The UNLT-WT-Test data set is stored in the standard “txt” format and is free and publicly available for research purposes (for license and URL see Section 7).
Table 3. Domain wise statistics of the UNLT-WT-Test data set
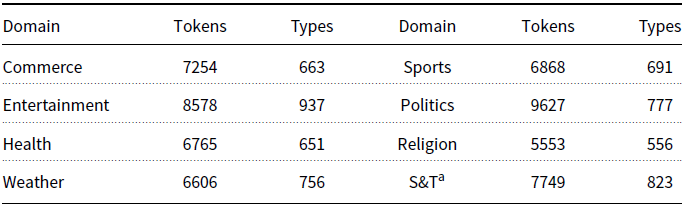
aScience and Technology
Training data: The training data set for our proposed Urdu word tokenizer was created by using a subset of the HC Corpus (Christensen Reference Christensen2014). To develop a gold standard training data set, two million tokens were randomly selected from the following domains: Politics, Culture, Crime & Law, Fashion, Religion, Business & Economy, Science & Technology, Sports, Weather, Education, Health, Entertainment.
After preprocessing (see Section 5.4) the collected raw data, the resulting data set contained 1.65 million tokens. The preprocessed text is used to create the gold standard training data set. In the first step, the text is tokenized on the basis of space. After that, a human annotator manually corrected the improperly tokenized words generated in the first step. The final benchmark training data set (hereafter called UNLT-WT-Train data set) is composed of 1.65 million tokens.
The UNLT-WT-Train data set was used to generate N-grams using the approach described in Jurafsky and Martin (Reference Jurafsky and Martin2014). Furthermore, we count the occurrences of each unique N-gram type, resulting in a total of 1,335,263 N-gram pairs with the following statistics: tri-grams: 636,765, bi-grams: 494,988, and uni-grams: 203,510.
5.2 Data set for Urdu sentence tokenization
For the evaluation of our proposed Urdu sentence tokenizer, we created a benchmark data set (hereafter called UNLT-ST data set) by following three steps: (i) raw Urdu text collection, (ii) preprocessing of raw data, and (iii) annotation. To construct the UNLT-ST data set, in the first step, we used a Web crawlerFootnote nn to extract raw Urdu text of 12.5K sentences from online sources (see Section 5.1) including BBC Urdu, Express news, Urdu Library, Urdu Point, Minhaj Library, Awaz-e-Dost, and Wikipedia. These sources allow their text (content) to be freely used for research purposes. To make the data set more realistic, we extracted the raw text of different domains and genres including Sports, Politics, Blogs, Education, Literature, Entertainment, Science, Religion, Fashion, Weather, Entertainment, Fiction, Health, Law, and Business. BBC Urdu is our largest source of text collection, which contains 3358 sentences, while the Urdu Point is the smallest one containing 1157 sentences. Statistics of sentences collected from other sources are Awaze-e-Dost: 1457, Express news: 1557, Minhaj library: 1657, Urdu library: 1357, and Wikipedia: 1957 sentences.
In the second step, the raw data were preprocessed (see Section 5.4), which resulted in the removal of 2500 sentences. The remainder of the 10,000 clean sentences are distributed as follows: Awaz-e-Dost: 1200, BBC Urdu: 2606, and Express News: 1297, Minhaj Library: 1303, Urdu Library: 1119, Urdu Point: 948, and Wikipedia: 1527 sentences.
In the third step, the preprocessed text containing 10,000 cleaned sentences was manually tokenized by three annotators (G, H, and I). All the annotators are native speakers of Urdu and have good knowledge about Urdu sentence tokenization task. Furthermore, the annotation process was split into three phases: (i) training, (ii) annotation, and (iii) inter-rater agreement and conflict resolution.
During the training phase, two annotators (G and H) annotated 1500 sentences. Subsequently, the interannotator agreement was computed for these sentences, and conflicting sentences were discussed to further improve the annotation quality. Further, during the annotation phase, the remaining 8500 sentences were manually annotated by annotators (G and H). In the third phase, the inter-rater agreement score was computed for all 10,000 sentences. We achieved an inter-rater agreement of 89.34%, as the annotators agreed upon 8934 sentences. Moreover, the Kappa coefficient was computed to be 81.83% (Cohen Reference Cohen1968). The conflicting 1066 sentences were annotated by the third annotator (I) for conflict resolution, and this judgement was considered as decisive, resulting in the gold standard UNLT-ST Training/Test data set.
The UNLT-ST Training/Test data set consists of 10,000 sentences. In our proposed test data set, 6469 period markers are SBM, while 536 are NSBM; 531 exclamation marks are SBM and 198 are NSBM; 421 question marks are SBM and 17 are NSBM; 197 double quotes, are SBM and 9 are NSBM; 382 SBM markers are #, @, $, *; the remaining 2000 sentence are without any SBM. As can be noted from these statistics, our proposed UNLT-ST Training/Test data set contains both SBM and NSBM for different characters as well as sentences without any SBM, which makes the data set much more realistic and challenging. The UNLT-ST Training/Test data set is saved in standard “txt” format (for licensing and URL see Section 7)
5.3 Data set for Urdu POS tagging
This section describes the creation of a large data set (hereafter called UNLT-POS data set) for the training and testing of the Urdu POS taggers. The data set creation process was accomplished in three steps: (i) raw text collection, (ii) cleaning process, and (iii) annotation process.
To construct a gold-standard Urdu POS tagging data set, in the first step, a Web crawler (see Section 5.1) was used to extract Urdu text of 239,834 words (14,137 sentences) from various online sources (see Section 5.1) including BBC Urdu, Express news, Urdu library, Urdu point, Minhaj library, Awaz-e-Dost, and Wikipedia. To make the data set more realistic, the raw data are from various domains: Sports (23,153), Politics (33,944), Blogs (10,976), Education (12,845), Literature (9045), Entertainment (13,946), Science and Technology (17,683), Fashion (10,463), Weather (9459), Business (17,328), Commerce (10,496), Showbiz (19,503), Fictions (8678), Health (12,783), Law (8185), and Religion (21,347).
The raw data were preprocessed (see Section 5.4), which resulted in 200,000 words. The domain and genre distribution of these words is Sports (20,128), Politics (26,145), Blogs (9428), Education (10,742), Literature (8756), Entertainment (10,560), Science and Technology (13,143), Fashion (9758), Weather (8996), Business (14,418), Commerce (9710), Showbiz (16,228), Fictions (8084), Health (11,584), Law (6952), and Religion (15,368).
The UNLT-POS data set was created using a manual approach. In the first step, a total of 2000 tokens were POS tagged using the CLE online POS taggerFootnote oo to train annotators. Manual inspection of the tagged data showed that a reasonable number of words are incorrectly tagged, particularly proper nouns, common nouns, verbs, auxiliaries, pronouns, adjectives, cardinal nominal modifiers, adverbs, conjunctions, participles, interjections, and foreign fragment. In the second training step, three annotators (A, B, and C) manually annotatedFootnote pp the automatically tagged data. Annotators A and B initially annotated 2000 tokens. An interannotator agreement was calculated for these tokens, and conflicting tagged tokens were discussed to further improve the annotation quality. After the training phase, the 200,000 words was manually annotated by annotators A and B, and the interannotator agreement was computed on the entire data set. An interannotator agreement of 85.7% was obtained. The Kappa coefficient was computed to be 77.41% (Cohen Reference Cohen1968). The conflicting tokens were annotated by the third annotator, resulting in a gold-standard UNLT-POS training/testing data set saved in “txt” format. As far as we are aware, our UNLT-POS training/testing data set is the largest manually POS tagged Urdu data set, free and publicly available for research purposes (for license and URL see Section 7).
Table 4. Statistics of three different training/testing data sets for evaluating the performance of Urdu POS taggers
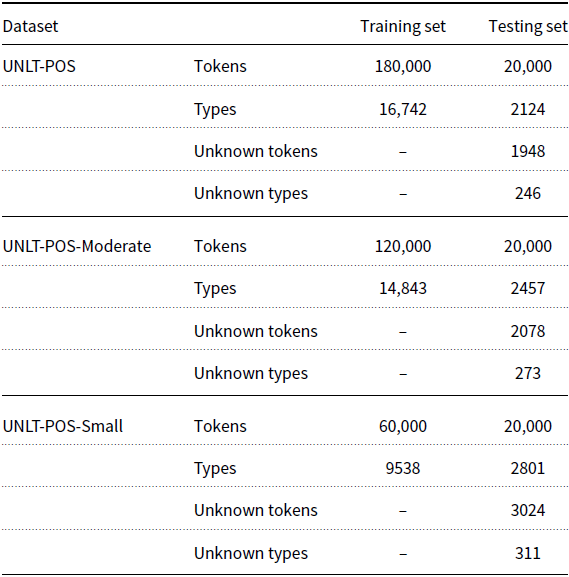
For experiments presented in this study, the UNLT-POST gold-standard data set is randomly divided into two different data sets: (i) consisting of 60K training and 20K of test data (henceforth UNLT-POS-Small training/testing data set, respectively) and (ii) consisting of 120K training and 20K for testing (henceforth UNLT-POS-Moderate training/testing data set, respectively).
The detailed statistics of different train/test data sets are shown in Table 4. The rows “Unknown Tokens” and “Unknown Types” of Table 4 represent the count of total tokens and types (unique tokens), respectively, not seen in the different UNLT-POS training/testing data sets. It has been observed that each test data set holds 9% to 11% words that are unknown with respect to the training data. These figures are a little higher as compared to the several European languages (Evangelos and George Reference Evangelos and George1995). However, Table 5 shows the detailed statistics of most frequent POS tags of the UNLT-POS testing data set.
Table 5. Statistics of most frequent POS tags of UNLT-POS testing data set

aNN, Common Noun; PSP, Postposition; VBF, Main Verb Finite; JJ, Adjective; AUXA, Aspectual Auxiliary; NNP, Proper Noun; RB, Common Adverb; AUXT, Tense Auxiliary.
bToken Count.
cUnknown tokens.
Table 6. Results obtained on UNLT-WT-Test data set using various techniques

5.4 Preprocessing
In this study, various data sets have been used, all these data sets (see Sections 5.1, 5.2, 5.3) are preprocessed as follows. Text in a data set is cleaned by removing multiple spaces, duplicated text, diacritics as they are optional (only used for altering pronunciation Mukund et al. Reference Mukund, Srihari and Peterson2010), and HTML tags. Moreover, noise from the data is removed by discarding ASCII and invalid UTF-8 characters, emoticons, asterisks, bullets, right and left arrows (Jawaid et al. Reference Jawaid, Kamran and Bojar2014). Further, only sentences with three or more words were kept.Footnote qq A language detection toolFootnote rr is used to discard foreign words and a text normalization tool.Footnote ss
6. Results and analysis of proposed UNLT tools
6.1 Results of Word tokenizer
Table 6 presents precision, recall,
 $F_1$
, and accuracy results when training on UNLT-WT-Train data set and testing on the UNLT-WT-Test (see Section 5.1) for Urdu word tokenization task by using various approaches. UNLT-WT-SP refers to results obtained using the space-based tokenization approach. UNLT-WT refers to results obtained using our proposed approach (see Section 4.1.2) for Urdu word tokenization. Duranni’s word tokenizer (see Section 2.1). Whereas CLE’s word tokenizer refers to an online tokenizer.Footnote tt The Trankit-WT is a deep learning model that implements a light-weight XLM-Roberta transformer (see Section 4.4).
$F_1$
, and accuracy results when training on UNLT-WT-Train data set and testing on the UNLT-WT-Test (see Section 5.1) for Urdu word tokenization task by using various approaches. UNLT-WT-SP refers to results obtained using the space-based tokenization approach. UNLT-WT refers to results obtained using our proposed approach (see Section 4.1.2) for Urdu word tokenization. Duranni’s word tokenizer (see Section 2.1). Whereas CLE’s word tokenizer refers to an online tokenizer.Footnote tt The Trankit-WT is a deep learning model that implements a light-weight XLM-Roberta transformer (see Section 4.4).
Overall, the best results are obtained by using our proposed UNLT-WT approach (precision = 0.91, recall = 0.87,
 $F_1$
= 0.89, and accuracy = 0.92). These results show that UNLT-WT is the most appropriate method for Urdu word tokenization on the UNLT-WT-Test data set. Furthermore, this also shows that combining maximum matching, dictionary lookup, and statistical N-gram MLE along with smoothing estimation are helpful in getting good performance on UNLT-WT-Test data set for Urdu word tokenization task. However, the highest
$F_1$
= 0.89, and accuracy = 0.92). These results show that UNLT-WT is the most appropriate method for Urdu word tokenization on the UNLT-WT-Test data set. Furthermore, this also shows that combining maximum matching, dictionary lookup, and statistical N-gram MLE along with smoothing estimation are helpful in getting good performance on UNLT-WT-Test data set for Urdu word tokenization task. However, the highest
 $F_1$
score of 0.89 for the word tokenization task indicates that Urdu word tokenization is a challenging task leaving room for further improvement.
$F_1$
score of 0.89 for the word tokenization task indicates that Urdu word tokenization is a challenging task leaving room for further improvement.
As expected, the overall results are lower for the baseline space-based tokenization UNLT-WT-SP (precision
 $= 0.55$
, recall
$= 0.55$
, recall
 $= 0.52$
,
$= 0.52$
,
 $F_1 = 0.54$
, and accuracy
$F_1 = 0.54$
, and accuracy
 $= 0.61$
) and approach, on UNLT-WT-Test data set. Durani’s word tokenizer reports an accuracy of
$= 0.61$
) and approach, on UNLT-WT-Test data set. Durani’s word tokenizer reports an accuracy of
 $0.49$
, precision of
$0.49$
, precision of
 $0.18$
, recall of
$0.18$
, recall of
 $0.20$
, and
$0.20$
, and
 $F_1 = 0.19$
. Furthermore, the CLE’s Urdu word tokenizer has shown precision
$F_1 = 0.19$
. Furthermore, the CLE’s Urdu word tokenizer has shown precision
 $= 0.58$
, recall
$= 0.58$
, recall
 $= 0.56$
,
$= 0.56$
,
 $F_1 = 0.57$
, and accuracy
$F_1 = 0.57$
, and accuracy
 $= 0.73$
. Whereas the Trankit-WT has produced the following results: precision
$= 0.73$
. Whereas the Trankit-WT has produced the following results: precision
 $= 0.73$
, recall
$= 0.73$
, recall
 $= 0.69$
,
$= 0.69$
,
 $F_1 = 0.71$
, and accuracy
$F_1 = 0.71$
, and accuracy
 $= 0.80$
. This highlights the fact that the UNLT-WT-SP, Durrani’s, CLE’s approaches are not appropriate for Urdu word tokenization tasks.
$= 0.80$
. This highlights the fact that the UNLT-WT-SP, Durrani’s, CLE’s approaches are not appropriate for Urdu word tokenization tasks.
The comparison of our proposed methods significantly outperformed the recently reported deep neural network-based word-piece based tokenization (Trankit-WT). There could be various possible reasons for this notable difference in the scores including simple space-based splitting of the raw input text as a preprocessing step in Trankit-WT seems to be a major contributor in producing low scores for word tokenization. This preprocess space-splitting could be efficient for many languages like English, Spanish, etc. but not suitable for the Urdu language. As has been described previously that spaces play a major role in word tokenization (see Section 3.1). We have further observed that Trankit-W is very poor in capturing multiwords.
While analyzing the errors of the proposed UNLT-WT approach, we observed that it does not explicitly handle unknown words for space omission, and this resulted in splitting an unknown Urdu morpheme into smaller morphemes. For instance, the word ![]() (KSYR ALLSAN, “multilingual”) erroneously split into
(KSYR ALLSAN, “multilingual”) erroneously split into  (KSY),
(KSY), ![]() , (RA)
, (RA) ![]() (LLS), and
(LLS), and ![]() (AN). Likewise, it might be less appropriate when a word is a combination of known and unknown morphemes, for instance,
(AN). Likewise, it might be less appropriate when a word is a combination of known and unknown morphemes, for instance,  (SHBAZ KO JANE DO, “let the Shahbaz go”). For space insertion, some compound words were not present in compound words dictionary, another major cause of incorrect word tokenization.
(SHBAZ KO JANE DO, “let the Shahbaz go”). For space insertion, some compound words were not present in compound words dictionary, another major cause of incorrect word tokenization.
6.2 Results of sentence tokenizer
Table 7 presents precision, recall,
 $F_1$
, and error rate resultsFootnote uu on the UNLT-ST Train/Test data setFootnote vv (see Section 5.2) for various Urdu sentence tokenization approachesFootnote ww (for other two, see Section 4.2.2). Trankit-ST is is a light-weight XLM-Roberta transformer for sentence tokenization (see Section 4.4).
$F_1$
, and error rate resultsFootnote uu on the UNLT-ST Train/Test data setFootnote vv (see Section 5.2) for various Urdu sentence tokenization approachesFootnote ww (for other two, see Section 4.2.2). Trankit-ST is is a light-weight XLM-Roberta transformer for sentence tokenization (see Section 4.4).
Table 7. Results obtained by using various sentence tokenization approaches on UNLT-ST-Train/Test data set

Overall, the best results are obtained using our proposed UNLT-ST-ML approach, precision = 0.90, recall = 0.92,
 $F_1$
= 0.91, and error rate = 0.09. The lowest results are obtained using a baseline UNLT-ST-PQEQM (precision = 0.89, recall = 0.19,
$F_1$
= 0.91, and error rate = 0.09. The lowest results are obtained using a baseline UNLT-ST-PQEQM (precision = 0.89, recall = 0.19,
 $F_1$
= 0.31, and error rate = 0.83). Whereas another proposed rule-based UNLT-ST-RB approach shows a precision of 0.81, recall of 0.74,
$F_1$
= 0.31, and error rate = 0.83). Whereas another proposed rule-based UNLT-ST-RB approach shows a precision of 0.81, recall of 0.74,
 $F_1$
of 0.77, and error rate of 0.29. This shows that combining various features in SVM is helpful in producing a good performance on the UNLT-ST Train/Test data set. Trankit-ST a deep learning- based approach has produced results as follows: precision = 0.86, recall = 0.83,
$F_1$
of 0.77, and error rate of 0.29. This shows that combining various features in SVM is helpful in producing a good performance on the UNLT-ST Train/Test data set. Trankit-ST a deep learning- based approach has produced results as follows: precision = 0.86, recall = 0.83,
 $F_1$
= 0.85, and error rate = 0.14. It is worth mentioning here that Trankit-S has produced more accurate results than two other sentence tokenization approaches, that is, UNLT-ST-RB/PQEQM. However, the highest
$F_1$
= 0.85, and error rate = 0.14. It is worth mentioning here that Trankit-S has produced more accurate results than two other sentence tokenization approaches, that is, UNLT-ST-RB/PQEQM. However, the highest
 $F_1$
score of 0.91 for sentence tokenization task indicates that Urdu sentence tokenization is a challenging task, and there is still room for further improvement.
$F_1$
score of 0.91 for sentence tokenization task indicates that Urdu sentence tokenization is a challenging task, and there is still room for further improvement.
For the UNLT-ST-PQEQM approach, which uses different characters as sentence boundary indicators, the performance is high in term of precision of 0.89. The likely reason for this is the majority of sentences in Urdu text are terminated using these characters. However, other evaluation measures show very low results. This highlights the fact that these characters alone are not suitable for the Urdu sentence tokenization task. As far as the rule base (UNLT-ST-RB) approach is concerned, it shows good results as compared to the baseline approach. This shows that combining various heuristics, regular expressions, and dictionary lookup is helpful in producing a good performance on the UNLT-ST Test data set. However, this method also fails to detect sentence boundary where sentences are ended without any SBM. While manually analyzing the errors of the proposed UNLT-ST-RB approach, we came across some scenarios where our proposed approach failed to accurately tokenize sentences. It was found that NSBM including “
 $:$
”, “
$:$
”, “
 $||,$
” “$,” “
$||,$
” “$,” “
 $*$
”“@,” and “#” are the major reasons for incorrect tokenization of sentences. Moreover, the period used between different abbreviations also caused misclassification. Finally, all those sentences that end without any sentence boundary marker are also declassified.
$*$
”“@,” and “#” are the major reasons for incorrect tokenization of sentences. Moreover, the period used between different abbreviations also caused misclassification. Finally, all those sentences that end without any sentence boundary marker are also declassified.
6.3 Results of POS tagger
Table 8 presents accuracy results when trained and tested on the UNLT-POS-Small, UNLT-POS-Moderate, UNLT-POS test data sets (see Section 5.3) for the Urdu POS tagging tasks by using different models (see Sections 4.3.2 and 4.4).
Table 8. Results obtained using various POS tagging models based on several approaches on different POS test data sets
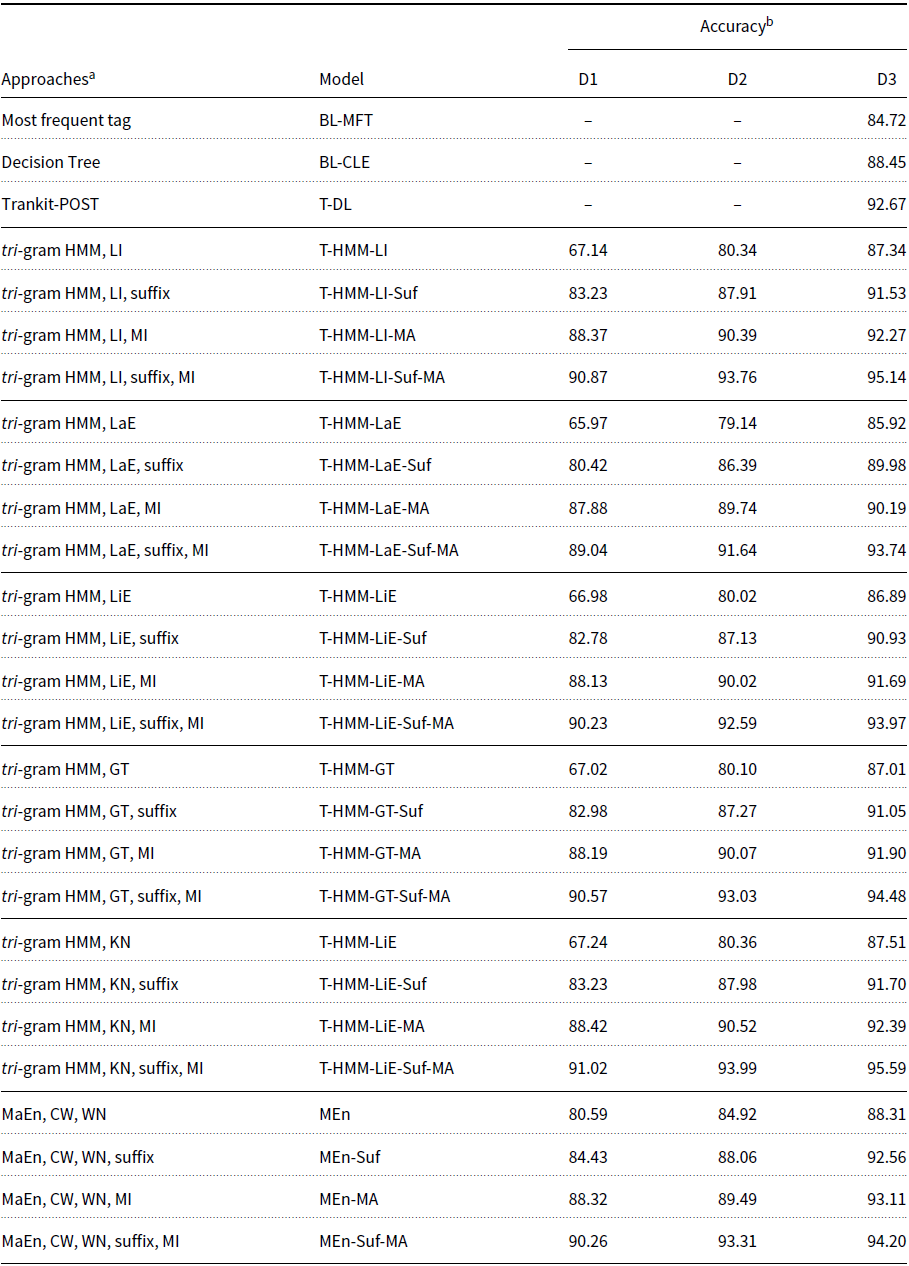
aLI: Linear Interpolation, MI: Morphological Information, LaE: Laplace Estimation, LiE: Lidstone’s Estimation, GT: Good-Turing, KN-Kneser-Ney MaEn: Maximum Entropy, CW: Context Window, WN: Word Number
bD1: UNLT-POS-Small training/testing data set, D2: UNLT-POS-Moderate training/testing data set, D3: UNLT-POS training/testing data set
Overall best results are obtained using our proposed T-HMM-GT-Suf-MA followed by T-HMM-GT-Suf-MA and MEn-Suf-MA POS tagging models, 95.59%, 95.14%, and 94.20%, respectively. This shows that combining various stochastic and smoothing techniques with language-dependent features is helpful in producing a very good performance on the UNLT-POS test data set. The highest accuracy score of 95.59% indicates that the Urdu POS tagging task is challenging, and there is still room for improvement. It can also be noted from these results that our proposed POS tagging approach (T-HMM-GT-Suf-MA) outperforms both baseline approaches BL-MFTFootnote xx (accuracy = 84.72%) and BL-CLEFootnote yy (Ahmed et al. Reference Ahmed, Urooj, Hussain, Mustafa, Parveen, Adeeba, Hautli and Butt2014) (which uses Decision Trees along with a smoothing technique of Class Equivalence) (accuracy = 88.45%) on UNLT-POS test data set. Furthermore, Trainkit-POST has produced an accuracy of 92.67%. This has good accuracy as compared to baseline and several other approaches. The reason for using the BL-CLE model as a baseline approach is that, currently, this is the only POS tagger available for Urdu which uses CLE Urdu POS tagset (see Section 4.3.1). Therefore, we can compare the results of CLE Urdu POS tagger with our proposed UNLT-POS tagger.
We can further observe that the tri-gram HMM-based models can produce good results if incorporated with linear interpolation, suffix, as well as Morphological Information (MI). Certainly, using MI along with linear interpolation gives better results as compared to suffix, but what is significant to note, using all the information together improved the accuracy of the models, T-HMM-LI-Suf-MA: 95.14%, T-HMM-LaE-Suf-MA: 93.74%, T-HMM-LiE-Suf-MA: 93.97%, T-HMM-GT-Suf-MA: 94.48%, T-HMM-KN-Suf-MA: 95.59%, and MEn-Suf-MA: 94.20%. Furthermore, it can be observed, T-HMM-LI, T-HMM-LaE, T-HMM-LiE, T-HMM-GT, and T-HMM-KN produce accuracies of 87.34%, 85.92%, 86.89%, 87.01%, and 87.51%, respectively, on the UNLT-POS data set. For the case of MEn, the reported accuracy is 88.31%. One important observation here is that by using smoothing and language-dependent features, the proposed Urdu POS tagging accuracies can be improved as compared to BL-MFT and BL-CLE models.
It can also be observed from the Table that T-HMM-GT performs better than the other four models T-HMM-LI, T-HMM-LaE, T-HMM-LiE, T-HMM-GT, and T-HMM-KN on UNLT-POS, UNLT-POS-Small, and UNLT-POS-Moderate test data sets. Moreover, the accuracy of T-HMM-LaE model is slightly poorer than the other HMM-based models (T-HMM-LI, T-HMM-LiE, T-HMM-GT, and T-HMM-KN), with UNLT-POS-Small data due to model overfitting. However, such discrepancies are alleviated with the increase of training data (UNLT-POS-Moderate and UNLT-POS training data sets).
It has been further observed that language-dependent features increased the accuracy of the models to a certain extent, even if trained on a UNLT-POS-Moderate training data set. However, with different features along with smoothing, the increase in the model accuracy is higher when training data are smaller. For instance, T-HMM-LI-MA and T-HMM-LI-Suf models improved around 16%, 7%, and 4% and 21%, 10%, and 5%, respectively, over the T-HMM-LI models, for UNLT-POS, UNLT-POS-Small, and UNLT-POS-Moderate test data sets.
From the above observations, it can be concluded that using MI and suffix increases in the model accuracy are higher for UNLT-POS-Small and UNLT-POS-Moderate training data sets. It is also important to note that the T-HMM-KN-MA models give an approximate improvement of around 5%, 7%, and 1% over the T-HMM-KN-Suf model for UNLT-POS-Small, UNLT-POS-Moderate, and UNLT-POS training data set, respectively. However, integrating all of them, an improvement has been observed in T-HMM-KN-Suf-MA models which are 8%, 6%, and 3% improved with respect to T-HMM-KN-Suf model in case of UNLT-POS-Small, UNLT-POS-Moderate, and UNLT-POS training data set. It can also be noticed that similar results have been observed for the other two (T-HMM-LaE, T-HMM-LiE, T-HMM-GT, and T-HMM-LI) HMM-based models. However, T-HMM-LiE performed better than the T-HMM-LaE model, but with the higher training data, the performance of these models is somewhat comparable.
MEn models outperform all others with smaller training data, but contrasting results have been observed with large training data. It is worth noting that MEn along with suffix and morphological information has positive effects with poor resources. Our results show the T-HMM-GT-Suf-MA and MEn-Suf-MA are more accurate than others, providing support for our further analysis based on such models.
Table 9 shows cases where the MEn-Suf-MA model performs better than T-HMM-KN-Suf-MA, by comparing the accuracies of open class tags for known and unknown words on the UNLT-POS testing data set. Our results show that the T-HMM-KN-Suf-MA model shows poor accuracy while predicting proper nouns (NNP) over the MEn-Suf-MA model. Mostly, the proper nouns (NNP) in T-HMM-KN-Suf-MA model are erroneously classified as an adjective (JJ). Furthermore, it is worth noting again that in Urdu, there is no discrimination between upper and lower-case characters, also using an adjective as a proper noun is frequent in Urdu, for example, ![]() (KBYR, “big”) and
(KBYR, “big”) and ![]() (SGHYR, “small”). Another reason for misclassification in tagging of the proper nouns is that many of them end with negation marker or pronoun, for example, the
(SGHYR, “small”). Another reason for misclassification in tagging of the proper nouns is that many of them end with negation marker or pronoun, for example, the  (“Nagyna”) end with the
(“Nagyna”) end with the ![]() (NH, “no”) or the NNP
(NH, “no”) or the NNP  (“Nazyh”) which end with the
(“Nazyh”) which end with the ![]() (YH, “this”), a pronoun. These errors need further investigation.
(YH, “this”), a pronoun. These errors need further investigation.
Table 9. Accuracies of open class tags on UNLT-POS testing data set using T-HMM-KN-Suf-MA and MEn-Suf-MA

Similarly, in the case of common adverb (RB), the accuracy of the MEn-Suf-MA model is approximately 2% and 6% higher for known and unknown words, respectively. However, the performance of MEn-Suf-MA for all other open class tags did not improve over the T-HMM-KN-Suf-MA. It is further observed that with the increase of unknown words, the accuracy of the MEn model has reduced.
The most prominent causes for Urdu POS tag misclassification are that there is no clear distinction between noun and proper noun, dropping of words is also frequent, if a noun in a noun phrase is dropped the adjective becomes a noun in that phrase, the highly inflected nature of Urdu, and ambiguity between noun and verb is due to verbal nouns.
7. Conclusion and future directions
In this paper, we have described a novel Urdu Natural Language Toolkit by integrating word and sentence tokenizers as well as a POS tagger. Words are tokenized by coupling a rule-based morpheme matching method with a tri-gram stochastic language model, backed-off to bi-gram Maximum Likelihood Estimation supplemented by smoothing technique for unseen words. We also developed large compound word and morpheme dictionaries, which were used in our proposed Urdu word tokenizer. A large benchmark training and testing data sets are also created. The training data set comprises 1,361,179 N-grams (1.65 million tokens), whereas test data set contains 59,000 manually tokenized words. Moreover, we have compared our results with state-of-the-art deep learning methods for comparison purposes. The results show that our proposed Urdu word tokenizer obtained precision of 0.96, recall of 0.92,
 $F_1$
of 0.94, and accuracy of 0.97. The sentence tokenization approach is formed by using rules extracted from a large raw Urdu corpus, regular expressions, and dictionary lookup. Our proposed Urdu sentence tokenizer obtained promising results on a large and new generated gold-standard test data set (precision = 91.08%, recall = 94.14%,
$F_1$
of 0.94, and accuracy of 0.97. The sentence tokenization approach is formed by using rules extracted from a large raw Urdu corpus, regular expressions, and dictionary lookup. Our proposed Urdu sentence tokenizer obtained promising results on a large and new generated gold-standard test data set (precision = 91.08%, recall = 94.14%,
 $F_1$
= 92.59%, and error rate = 6.85%). We have described 24 different stochastic models (and two baseline models) for the Urdu POS tagging task. Each of these models has a unique stochastic scheme supplemented with various language features and smoothing estimations. In addition, a large gold-standard training/testing data set was generated. Results show that the best performance is achieved by the T-HMM-KN-Suf-MA POS tagger which is a combination of tri-gram HMM, Kneser–Ney, suffix, and morphological information, achieving an accuracy of 95.59%. These resources have been made publicly available to the research community at https://github.com/UCREL/UNLT and https://doi.org/10.17635/lancaster/researchdata/494. under the terms of the Creative Commons Attribution 4.0 International LicenseFootnote zz and GNU General Public License v3.0.Footnote aaa
$F_1$
= 92.59%, and error rate = 6.85%). We have described 24 different stochastic models (and two baseline models) for the Urdu POS tagging task. Each of these models has a unique stochastic scheme supplemented with various language features and smoothing estimations. In addition, a large gold-standard training/testing data set was generated. Results show that the best performance is achieved by the T-HMM-KN-Suf-MA POS tagger which is a combination of tri-gram HMM, Kneser–Ney, suffix, and morphological information, achieving an accuracy of 95.59%. These resources have been made publicly available to the research community at https://github.com/UCREL/UNLT and https://doi.org/10.17635/lancaster/researchdata/494. under the terms of the Creative Commons Attribution 4.0 International LicenseFootnote zz and GNU General Public License v3.0.Footnote aaa
Our next primary target for follow-up research work will be to extend the toolkit by developing and integrating various NLP tools. As far as the word tokenization is concerned, we aim to adopt machine learning approaches (conditional random field, maximum entropy, etc.) to learn the morphological pattern of the valid morphemes (instead of morphemes lookup) and to handle out-of-vocabulary words in morpheme matching process of space omission problem. For the sentence tokenizer, we plan to develop a hybrid approach for Urdu sentence tokenization task, that is, rule-based along with artificial neural network. Finally, in the future, we aim to deal with unknown words and will adopt further statistical methods (CRF, deep learning, etc.) along with heuristic rules to increase the POS tagging accuracy for Urdu text.
Acknowledgements
This work has been supported by the COMSATS University Islamabad, Lahore Campus, Pakistan and Lancaster University, U.K. under the Split-Site Ph.D. programme.







 (KR KE, literally “by doing”).
(KR KE, literally “by doing”).










 Open access
Open access