



INTRODUCTION
The legal system, which is designed to uphold the law and ensure the delivery of justice, is a process conducted through language. The activity of investigating and prosecuting criminal activity is interactional, at each stage of the process. Given this, the language of the legal system has, for many years (see Bhatia Reference Bhatia1987), attracted scholarly interest from linguists as well as from researchers working in other related areas such as psychology. In particular, much attention has been given to designing and evaluating models of interviewing and interview techniques (see e.g. Griffiths & Milne Reference Griffiths and Milne2018; Shepherd & Griffiths Reference Shepherd and Griffiths2021 for the input from psychology), including how interview questions are designed and issued (e.g. Heydon Reference Heydon2005; Grant, Taylor, Oxburgh, & Pankhurst Reference Grant, Taylor, Oxburgh;, Pankhurst, Oxburgh, Myklebust, Grant and Milne2015; Haworth Reference Haworth2017).
As a type of institutional discourse (Drew & Heritage Reference Drew, Heritage, Drew and Heritage1992), these routinized, formal interactions in legal settings often abide by the turn-taking rules of the context, tied to the hierarchy of the setting. For example, the talk within investigative interviews is heavily structured with parties rarely diverting from a consistent interactional pattern (see e.g. Heydon Reference Heydon2005). This talk plays out with visible asymmetry (e.g. the professional parties talk more, including interrupting) (Momeni Reference Momeni2011). However, as we show in this article, when police transcribers produce official written records of the spoken interaction, much of this interactional detail is not included, meaning it is lost to any future observers, and the significance of such factors over the account produced by the interviewee is obscured.
The institutional function of the interview record
In England and Wales, there is a legal requirement for investigative police interviews with suspects to be audio-recorded (Police and Criminal Evidence Act 1984, Code E) with only a few exceptions (e.g. some terrorism cases). Sometimes, interviews are also video recorded. In addition to the audio/video record, a written version is also produced either ‘in full’ (an attempt to capture the talk ‘verbatim’) or, more commonly, a shorter version with parts summarised is produced. Written versions are referred to in the legal system as a ‘Record of Taped/Videoed Interview’ or ROTI/ROVI.
The mandatory audio recording of investigative interviews was introduced in response to records of investigative interviews being at best inaccurate (Dixon & Travis Reference Dixon and Travis2007) and at worst fabricated (see e.g. Coulthard Reference Coulthard, Caldas-Coulthard and Coulthard1996, Reference Coulthard and Cotterill2002). Prior to the introduction of audio recording, the interviewer was expected to write down what happened post interview from notes and memory (see e.g. Coulthard Reference Coulthard, Caldas-Coulthard and Coulthard1996, Reference Coulthard and Cotterill2002), which inevitably resulted in a record which contained substantially less detail and accuracy than the original interaction.
While the audio/video record remains to be the most accurate representation of what was said, producing a written record of the audio/video recording renders the interaction easily accessible to future audiences within the legal process (Walker Reference Walker, Levi and Walker1990; Gibbons Reference Gibbons2003). We even see, from the audio recordings of suspect interviews, parties orienting to these potential future audiences in their original spoken interaction (e.g. “For the benefit of the tape”; Stokoe Reference Stokoe2009), who might be the investigating police officers, the Crown Prosecution Service (CPS), and members of the courtroom (Haworth Reference Haworth2013).
One of the central functions of the record in legal settings is for it to be tested and compared with accounts obtained at other points from the interviewee (given to a different audience, or in a different context, for example) and from others involved in the alleged crime. Our previous work (see Richardson, Haworth, & Deamer Reference Richardson, Haworth and Deamer2022) indicated that written texts are more ‘referenceable’, by which we mean easier for users to locate, mark, and reference part of the material from the whole than the audio/visual record, making them preferable to users over audio/visual materials.
Additionally, written records of the spoken suspect investigative interview are routinely presented in court in place of the audio or video recordings. The transcript is not only viewed and referred to as part of the prosecution evidence, but it is also used like a script, performed by members of the prosecution team, usually the prosecution lawyer and a police representative role-playing the interviewer(s) and the interviewee (see Haworth Reference Haworth2018). This reliance on the transcript rather than the audio/video recording is therefore deeply embedded in current legal practice. Although this is something we might seek to challenge and reform, this is an extremely ambitious target. Therefore, the focus of our current work is on ensuring the written record of the suspect interview is a more reliable representation of the original spoken interaction.
The process of entextualisation
Whether the record is an audio, video, or written text there are numerous, often unacknowledged, considerations when producing records of spoken interaction. To produce a transcription of a spoken interaction involves ‘entextualization’, ‘the process of rendering discourse extractable, of making a stretch of linguistic production into a unit—a text—that can be lifted out of its interactional setting’ (Bauman & Briggs Reference Bauman and Briggs1990:73). This is later decontextualized, and then recontextualised—a process that Bauman & Briggs (Reference Bauman and Briggs1990) argue is an act of control and indexes social power. In creating records, ‘producers’ make decisions of focus, whether that is the positioning of the video cameras in an interview suite or police transcribers choosing what to include or exclude in the written transcript.
Haworth (Reference Haworth2018) highlighted how interview evidence undergoes multiple significant transformations as it is captured and processed in the legal system. At each stage, the record is treated as an identical ‘copy’ of the original, without acknowledgement that the spoken data are substantially altered when converted into written format. Haworth (Reference Haworth2018) makes a comparison between the practices and procedures associated with the handling of physical evidence (e.g. DNA, blood spatter, and fingerprint evidence) and the way in which spoken evidence is handled. Blackwell (Reference Blackwell and Kniffka1996:253) stated that ‘the need for forensic linguists to develop an understanding of the transcription process is as pressing as ever’. Yet, there continues to be minimal recognition, certainly in legal contexts, of the non-equivalence of spoken and written text (Biber Reference Biber1988; Halliday Reference Halliday1989).
The work detailed in the current article forms one part of a wider project, ‘For the Record’, comprising three distinct but interrelated strands. First, psycholinguistic experiments were designed to test our hypothesis that different formats (spoken/written) and transcription choices have an effect on interpretation (Deamer, Richardson, Basu, & Haworth Reference Deamer, Richardson, Basu and Haworth2022; Tompkinson, Haworth, Deamer, & Richardson Reference Tompkinson, Haworth, Deamer and Richardson2023). Second, (reported here) we conducted a qualitative linguistic analysis of the two types of record, the audio/visual and the written. Third, focus groups with police transcribers and investigative interviewers were conducted to ensure that the findings are firmly grounded in the practical realities of the professional context. The project as a whole is designed as a holistic examination of the process of producing investigative interview records, focusing in particular on the question of evidential consistency.
The quantitative findings from the first psycholinguistic experiment (Deamer et al. Reference Deamer, Richardson, Basu and Haworth2022) suggested that participants (representing potential jury members) presented with a transcript of a police interview were significantly more likely to (i) perceive the interviewee as anxious and unrelaxed, (ii) interpret the interviewee's behaviour as being agitated, aggressive, defensive, and nervous, (iii) determine that the interviewee was un-calm and uncooperative, and (iv) deem the interviewee's version of events to be untrue, than those participants presented with the original audio recording. Moreover, from the qualitative analysis, participants identified (a) consistency, (b) phrase and lexical choice, (c) emotion (crying/upset), (d) hesitation and/or pauses to be significant factors influencing their perception and interpretation of the interviewee and their story (Deamer et al. Reference Deamer, Richardson, Basu and Haworth2022). This highlights the potentially serious consequences of a legal system which relies on written records of the interview which do not include such features, rather than playing the original audio.
Building on Haworth (Reference Haworth2018), and complementing the above findings, it is our intention in this article to highlight some of the ways in which producing these written records from the audio and video recordings, in fact, alters the content from what actually occurred in the original spoken interaction. Central to this is the process of transcription.
Transcription and existing notation systems
At the most basic level, transcription is the process of taking spoken language and producing from that, a written text. Transcripts can be produced by human transcribers or through automatic transcription software. All transcripts are reductionist, selective, and necessarily only capture details relevant to the institutional purpose they serve, some of which we have discussed elsewhere (Richardson et al. Reference Richardson, Haworth and Deamer2022; see also Fraser Reference Fraser2022). Transcripts are used across many settings for a wide range of purposes. Contrast, for example, a transcript that a journalist makes using specialist shorthand notation against a transcript made by a speech and language therapist to assist a client who has a swallowing disorder. Both transcripts serve to capture spoken language in written form, but the functions of these transcripts would be very different. The relationship between form and function is essential to ensuring that a transcript is fit for purpose. The function of a particular transcript will inform the specific aspects of speech that need to be captured in writing. Without full integration between both form and function, there will always be the potential for a transcript to be insufficient for its intended purpose. In the police interview context this can be especially difficult to achieve, due to the fact that these transcripts are used in various ways, as we have detailed elsewhere (Haworth Reference Haworth2013, Reference Haworth2018; Richardson et al. Reference Richardson, Haworth and Deamer2022).
Transcripts can be produced from ‘live’ interaction, although are more commonly produced from recorded speech, as in the case of ROTI/ROVI transcripts. As Fraser (Reference Fraser2003) highlights, transcription is also inherently linked to human speech perception. Transcription relies on a listener perceiving and understanding the words that are spoken, and then having the appropriate system or tools to encode words and meaning within the transcript. Fraser's work on this topic (e.g. Reference Fraser2003, Reference Fraser, Coulthard, May and Sousa-Silva2020, Reference Fraser2021, Reference Fraser2022) has elucidated some of the speech perception issues that can influence the quality of a transcript, including implicit listener-based biases, background noise, and/or poor-quality recordings, the continuous nature of speech, and the introduction of errors in hearing on the part of the transcriber.
Transcription practices differ in what details they capture and which they leave out, based on what the police transcriber considers important or relevant for the context, considering the purpose the record will serve and the intended user. As such, a good transcription system is able to capture those details that the institution is interested in and leave out those details that are deemed irrelevant. When it comes to transcription systems, their level of granularity varies significantly, from the broadest verbatim transcriptions to complex and detailed multimodal transcriptions that capture both the verbatim utterances, temporal, linguistic and paralinguistic resources, as well as embodied practices such as gaze direction, recognisable gestures, and limb/body movements (see Mondada Reference Mondada2018).
The simplest type of transcripts (orthographic transcripts) usually aims to represent only the words that are spoken, with minimal or no information about aspects of speech such as stress placement, intonation, emotion, or other extra-linguistic markers such as clicks and sniffs. Orthographic transcripts are most appropriate when the central function is capturing what was said and capturing information about how words were spoken or the potential meaning of aspects of spoken interaction are of limited or no importance. One area of the legal system in which orthographic transcripts are frequently deployed is in so-termed ‘forensic transcripts’ (Ariani, Sajedi, & Sajedi Reference Ariani, Sajedi; and Sajedi2014; Fraser Reference Fraser2018, Reference Fraser, Coulthard, May and Sousa-Silva2020, Reference Fraser2021). These are transcripts of often poor-quality recordings which are produced with a primary function of assisting juries, lawyers, and judges to understand indistinct speech. Given that the purpose of an orthographic transcript is to represent the words spoken, and that orthographic transcripts are most commonly produced for general audiences with no specific linguistic or specialist knowledge, they are designed to contain no specialist notation and have a high level of general comprehensibility. The trade-off for this is that they lack standardised methods of representing aspects of speech which cannot be captured by words alone. For example, even within more ‘formal’ transcription systems, O'Connell & Kowal (Reference O’Connell and Kowal1994) highlight variation in how aspects of speech such as emphasis, pitch, and loudness have all been marked using italics, capitalisation, and underlining.
Jefferson's transcription system (Reference Jefferson and Lerner2004) is one that is widely used in social sciences, as it allows the transcriber to ‘catch details’ of actual occurrences of interaction which a researcher's imagination could not produce as hypotheticalized-typical versions and assert as real (see Sacks Reference Sacks1992). This system aims to capture a number of details which are heard in talk but are not represented in an orthographic transcript. The system uses symbols common to any word processor to capture the timing and placement of talk, the onset of overlaps, pauses in turns, or gaps between turns. It also captures the sound qualities such as when a speaker stretches a sound or speeds up a word, emphasis, quietness/loudness, marked pitch changes, in and out breaths, laughter/crying, cut-off words or sounds, and other intonational features of the talk (Drew Reference Drew, Fitch and Sanders2005).
A further development of the Jeffersonian transcription system is Mondada's (Reference Mondada2018) system for transcribing embodied actions as they are coproduced with spoken utterances. Mondada (Reference Mondada2018) argues that transcribing cannot be separated from analysis and proposes transcription conventions which aim to implement the principles of multimodal analysis in a systematic, coherent, robust, and explicit way. The system enables the transcriber to focus in on an unlimited range of embodied conducts and anchor them in within the temporality of action as it unfolds.
Another example of a specialist transcription system is the International Phonetic Alphabet (IPA), designed to capture the sounds of the languages and give the user a one-to-one sound-to-symbol notation system to provide users with a method to finely capture how words are produced by speakers. The handbook of the IPA (International Phonetic Association 1999) identifies that the goal of the system is to ensure that sounds can be transcribed and represented consistently, and it provides an unambiguous set of symbols for the phonetic transcription of both segmental and suprasegmental aspects of speech. This has a clear advantage over the imposition of these kinds of features in an unstructured way in orthographic transcripts, but the disadvantage that it requires users, including readers, to have specific training in IPA transcription.
As we have shown, there are so many possible ways to transcribe interaction; choices are made based on the most appropriate system for the intended purpose. For our own analysis presented here, we use the Jefferson (Reference Jefferson and Lerner2004) transcription system, employed by conversation analysts, since—in line with the point made above—we feel this best suits our purpose here, in terms of the level of detail and the type of interactional feature we seek to analyse. We use CA since it is crucial to our analysis to consider the subtle nuances of the talk, as these can be consequential for the way recipients hear and respond to talk. In turn, this is consequential for the way talk is organized (Sidnell Reference Sidnell2010). A Jeffersonian transcript renders those interactional features analysable and referenceable; it also enables us to present clear and direct comparisons with the official transcripts.
Further, in CA, transcripts are not treated as ‘data’ as such; data are the original audio or video recordings and the transcripts a representation of it (Hutchby & Wooffitt Reference Hutchby and Wooffitt2008). This is because in CA transcripts are acknowledged to be selective in the details represented and thus are never treated as a replacement for the data (Hepburn & Bolden Reference Hepburn, Bolden, Sidnell and Stivers2012). We do not claim that a Jeffersonian transcript is more ‘neutral’ or ‘objective’ than others listed above; as Fraser (Reference Fraser2022) rightly points out, it is not. However, Jefferson transcription tries to capture as much of that interactional nuance as is available on the recording, for the purpose here of evidencing transformation of social actions, while also acknowledging that any transcriber (ourselves included) is unlikely to capture all relevant information when transcribing. This strongly aligns with our position that a transcript should never be taken as a straightforward replacement for the original, as we see routinely occurring in the legal process.
DATA AND METHODS
Data
We were granted access by a police service located in the England and Wales jurisdiction to digitally recorded investigative interviews and their corresponding transcripts. The dataset comprises twenty-five audio-recorded suspect interviews and four achieving best evidence (ABE) video-recorded interviews with victims or witnesses, and their accompanying transcripts. Witness interviews and their records play a different role in the criminal justice system, especially ABE video interviews which can be played in court as the witness's evidence in chief instead of them giving that evidence in person (s.27 Youth Justice and Criminal Evidence Act 1999). However, a transcript is still produced in the same way as with suspect interviews, so we included them in our analysis of police transcription practices. The digital recordings and transcripts were made as part of the routine work of the organization and not recorded for research purposes. The processing and use of the data is governed by a data sharing agreement between the police service and us as research partners. All personal information was redacted from the interviews on site at the police station, and the recordings anonymized. Where names, locations, and dates are shown in the data extracts presented here, they are pseudonyms. All data were stored on encrypted systems that are specialized for forensic and legally sensitive materials. The project received ethical approval from the university of the research team.
We acknowledge the limitation that this only includes data from one police force, and we are aware that each police force has its own practice in the production of interview records. We therefore make no claims of generalisability here; however, this approach enables us to gain deep insight into professional practice in this one location, as well as producing findings and outcomes which are maximally relevant to our partner force.
The method of analysis
For the purposes of this strand of the wider research program, we take an ethnomethodological approach (the study of how people produce social order through their social interactions (Garfinkel Reference Garfinkel1984) and draw on CA. CA is both a field of study and a research method for analyzing naturally occurring conversation, which has shown that, and how, conversation is systematic (not ‘messy’); that there is ‘order at all points’ (even in one single turn at talk), and that much of its core machinery is universal across languages (Stivers, Brown, & Levinson Reference Stivers, Enfield, Brown and Levinson2009).
Conversation analysis requires ‘the study of naturally occurring activities as they ordinarily unfold in social settings, and, consequently, on the necessity of recordings of actual situated activities for a detailed analysis of their relevant endogenous order’ (Mondada Reference Mondada, Sidnell and Stivers2012:33). In essence, to understand the full range of practices including not just the words uttered but pauses, silences, spontaneous talk, pace, non-lexical vocalisations, and so on, it is necessary to examine actual recordings; the next step is then to evaluate the ways in which the social interaction observable in the recording is encapsulated (or not) in the official record. In so doing, we recognise and acknowledge that the recording is itself merely a partial version of the original; however, our purpose here is specifically to examine the process of converting these institutionally produced recordings into the institutionally sanctioned official transcripts.
An inductive approach to analysis was employed, informed by the findings from the preliminary experiments and focus groups. Our analysis proceeds to make available, systematically, the activities that comprise the complete interactions; the way those activities are designed, and how different designs lead to different trajectories and outcomes for speakers. In addition to describing the production of the talk by speakers, conversation analysis identifies the social actions that are performed by the speakers as they interact in real-time and, by documenting those using the Jefferson transcription system, can evidence the substantial change in the social actions that occurs in the transformative process of presenting these in the official written records of the spoken interaction.
ANALYSIS
Our analysis comprises four sections. First, we introduce the written record and describe the organization of this document. We then move to three sections analyzing the content of the record, focusing specifically on how silence, temporal features of the speech, and emotion are represented in the transcriptions.
The layout
The standard template on which records of taped interviews (ROTIs) are produced is the Manual of Guidance form number 15 (known as the MG15). An example of an MG15 is provided below. The form is laid out conforming to European culture of literacy norms which ‘socializes its members to encode ideas not only from top to bottom, but from left to right of the writing surface’ (Ochs Reference Ochs, Ochs and Schieffelin1979:49).
At the top of the form (see Figure 1), information about the suspect or witness is populated from information stated by the parties during the preliminary phase of the audio record. This includes verbalised details about the time, duration, and place of the interview, who conducted the interview, and any other present parties. There are three columns on the form: from left to right there is first a space to record tape counter times; next, in the middle, a column to record ‘person speaking’; and on the right, a column titled ‘text’ where the transcriber records what was said in the spoken interview. The text column is segmented into rows.

Figure 1. Interview 4. Example of the MG15 (ROTI).
Our examination of the ROTIs revealed that although the form is standardised, there is variation in how the form is used by police transcribers to record the spoken interview. We note variation not only across the records, but within them. In the following sections, we describe the inconsistency present. Figures are taken from the official ROTIs and extracts are the research team's own representations of the talk using a Jeffersonian (Reference Jefferson and Lerner2004) transcription system. Relevant transcription conventions are provided throughout.
The column labelled ‘Tape counter times’
The first of the three columns on the MG15 is titled ‘tape counter times’ (see Figure 1), despite the ‘tape counter’ now being obsolete technology as, in this force at least, they are now all digitally recorded. In this column, times are recorded in minutes and seconds which allows the user of the transcript to locate the text (transcribed in the third column) within the audio or video file. We observe no common practice for when transcribers link a textbox to the audio recording by inputting a time; transcribers do not write a time in the column for each textbox. The most common practice is to not write the time in the box (see Figure 1). When transcribers do note a time, we observe three different practices: to approximate where the text is on the audio record (Figure 2), to indicate the beginning of a new sequence (Figure 3) and to indicate where there is a point of interest in the record (Figure 4).

Figure 2. Interview 12. Tape counter times: approximation.
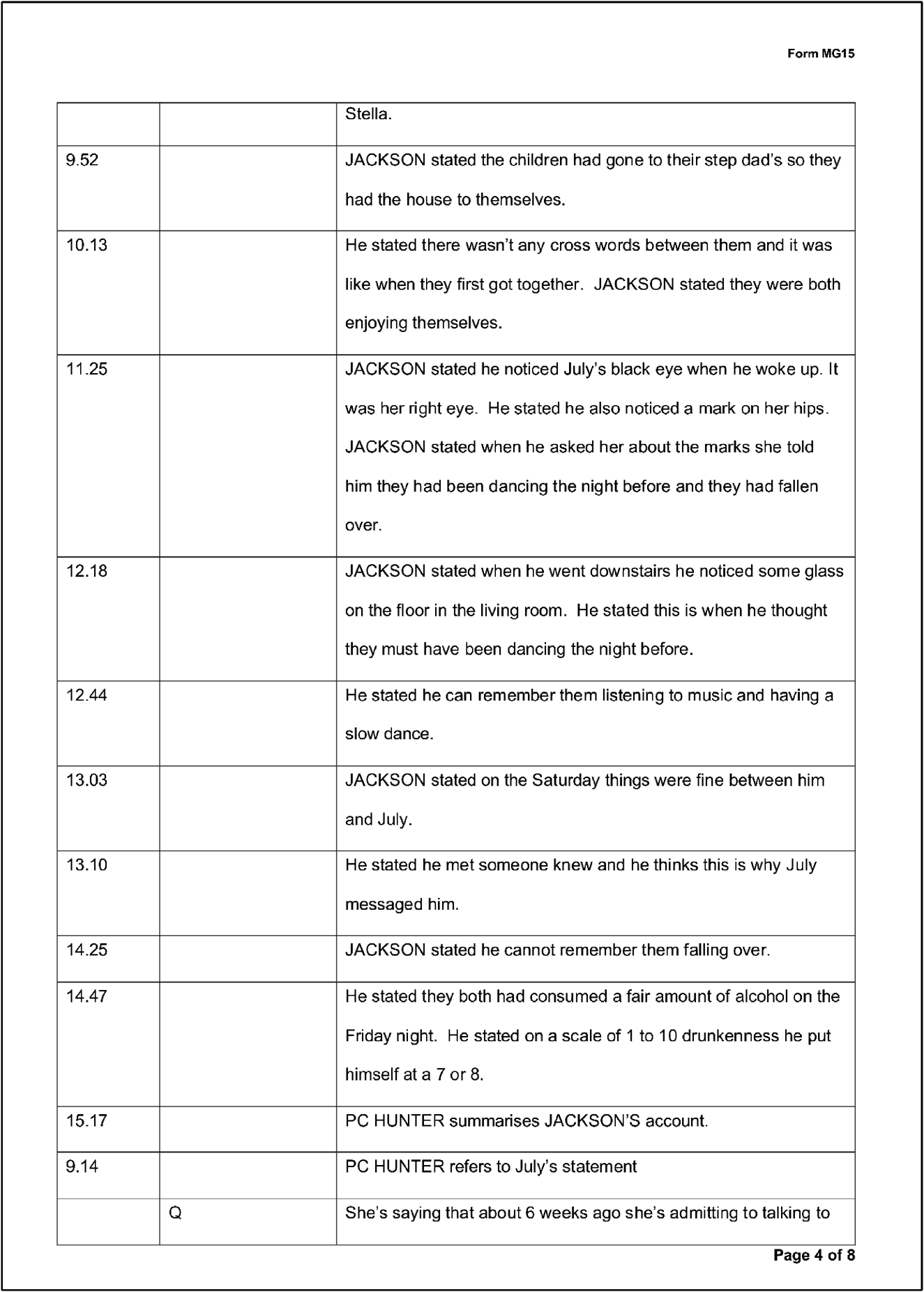
Figure 3. Interview 25. Tape counter times: Marking a new sequence.

Figure 4. Interview 4. Tape counter times: Point of interest.
The first way in which we note this practice being used is to approximate where in the audio file this text corresponds. The police transcriber periodically records rounded time intervals (e.g. entering 8:00 at the eight-minute mark, and then 11:00 at the eleven-minute mark as shown in Figure 2). However, we do not find these to be included at consistent intervals.
The second way in which we see the tape counter times column being used by police transcribers is to enter a time at the beginning of a new sequence (as shown in Figure 3), for example, when the interviewer asks a specific sequence-initiating question about a particular part of the incident. Where the audio is heavily summarised this might result in frequent time entries in the tape counter times column. Additionally, we see times in this column when the police transcriber moves from one mode of recording to another, so from a summarised sequence, to the transcriber typing out what the speakers have said word-for-word.
The final way we observed this column being used was to indicate when something about what is being said in the interview is considered to be ‘important’ enough to require a reference (as shown in Figure 4).
The column labelled ‘Person speaking’
Any transcript needs to reflect which of the turns are attributed to which speaker. In this form, there is a column titled ‘Person speaking’ to show who the talk is attributed to. In our analysis, we find multiple ways in which the different speakers are represented. The first is to use a ‘question-answer’ or a ‘question-response’ practice to mark the ‘speech act’ of the textbox. Here, ‘Q’ is used to represent ‘questions’ and either ‘R’ or ‘A’ is used to represent the ‘response’ or ‘answer’. This practice can be observed in Figure 4. The other ways in which transcribers assign ‘person speaking’ to the adjacent text box is to use the interviewer's collar number, as shown in Figure 5, or to use the speaker's last name. This practice is often, but not always, used when there is more than one interviewer putting questions to the interviewee.
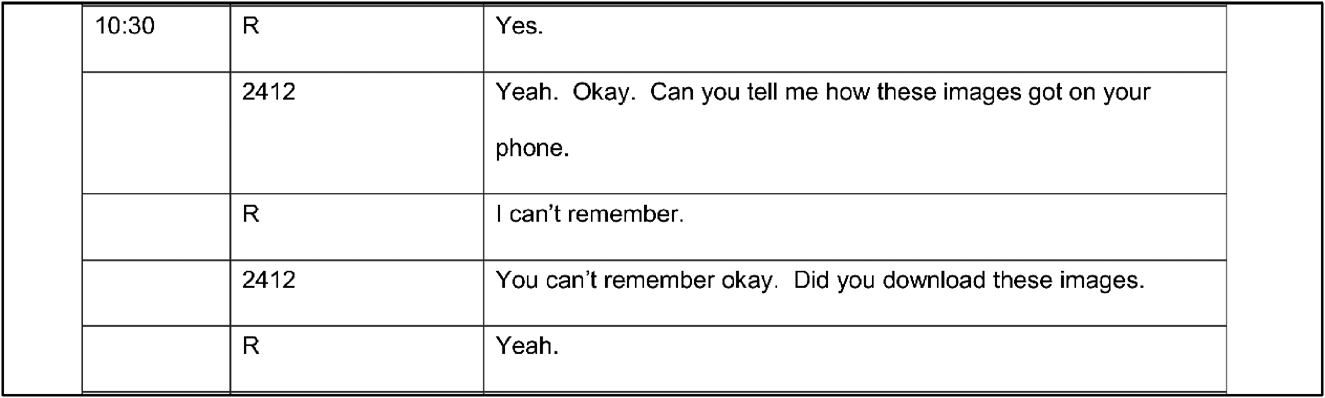
Figure 5. Interview 8. Use of collar number.
The column labelled ‘Text’
In the ‘Text’ column, police transcribers use rows to represent what was said in the audio or video recording. They can do this by either recording word for word what was said or by producing summaries of the talk. It is not within the scope of this article to comment on how police transcribers make choices about what to type word for word and what to summarise. Here, we seek to present the way in which the text column is used and consider any inconsistent practice.
In Figure 6 below, we see most of the text boxes contain summarized talk, but, between two blank rows, a few turns have been typed out word for word. Note that ‘…’ has been used to show a transition from summary to verbatim transcription.
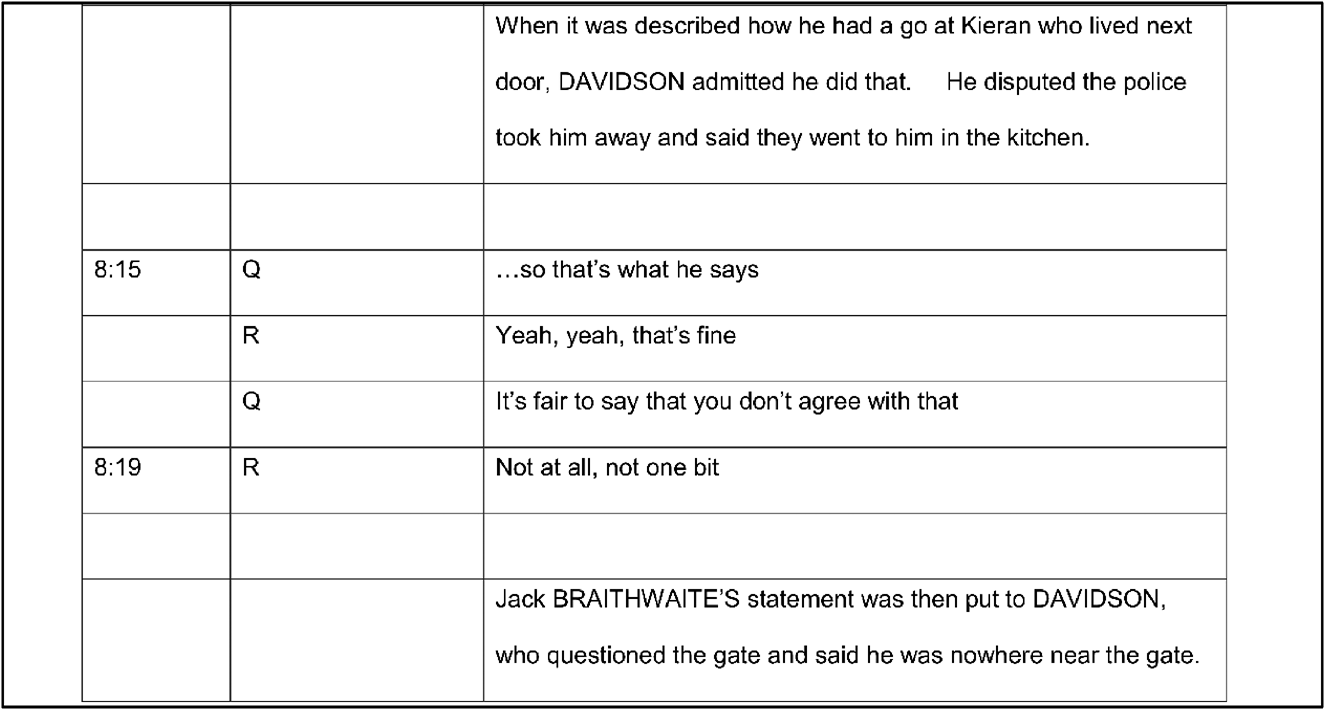
Figure 6. Interview 14.
We found that most often a new row is used for a new speaker, but this is not always the case. Sometimes, in conjunction with an entry in the tape counter times column, a new row with text is created to indicate a point of interest within the same speaker's turn (see Figure 7).
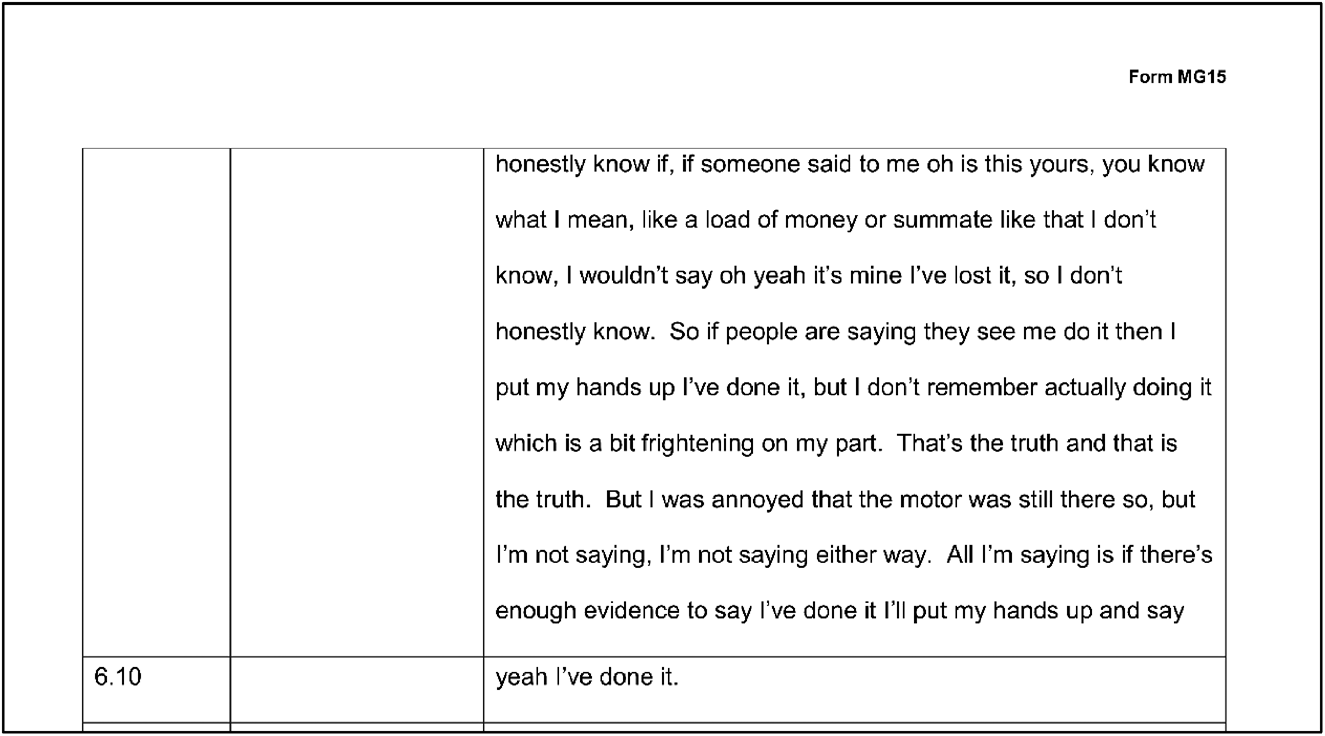
Figure 7. Interview 7.
As shown in this image, this practice can create artificial segregation of turns-at-talk. Positioning the “yeah I've done it” separately in its own text box, with a time in the ‘Tape counter times’ column, visually highlights these words. It also creates the risk that they are taken out of context and thereby misinterpreted, especially in terms of their evidential strength. The chosen layout has separated this part of the utterance from the very important conditional “if there's enough evidence to say I've done it I'll put my hands up and say…”. It is only the lack of a new attributed speaker in the ‘person speaking’ column which enables us to infer that the highlighted talk follows on directly from the text box above. The layout choices made here by the transcriber thus give the misleading impression that an interviewee has made an admission which he did not.
Transcription resources
For the most part, police transcribers enter the words spoken into the boxes, but we also see a range of ‘transcription resources’ being used to indicate other interactional features such as periods of silence and temporal features of the talk, like overlapping speech and turns that are ‘latched’ to the prior. Our analysis revealed varied practice within and across the transcripts of how these are used which we unpack in the forthcoming sections, informed by the experimental work (Deamer et al. Reference Deamer, Richardson, Basu and Haworth2022; Tompkinson et al. Reference Tompkinson, Haworth, Deamer and Richardson2023. We first consider the importance of silence in interaction and show the practices police transcribers have for representing silence. Second, we show how police transcribers attempt to capture temporal features of talk and provide commentary on what is gained and lost in doing so. Finally, in the last analytic section, we consider the representation of ‘emotion’ in the police interview.
Silence
In CA, silence is the absence of talk in relation to the sequential organization of turns (Hoey Reference Hoey2017). Table 1 below shows how, in CA, we use the Jeffersonian transcription system to represent silence and how we use it to demonstrate inconsistency in police transcriber practice.
Table 1. Jefferson notation relevant for silence (Hepburn & Bolden 2013).

A Jefferson (Reference Jefferson and Lerner2004) transcript records silences to the tenth of a second, above two tenths. This enables the reader of any Jefferson transcript to understand how long a silence was, and the positioning of the silence enables the reader to know if the transcriber heard this as a pause within a turn or a gap between (Sacks, Schegloff, & Jefferson Reference Sacks, Schegloff and Jefferson1974). This is a feature often analysed as interactionally salient in CA.
We find police transcribers do attempt to represent episodes of silence heard in the audio files on the written record. Figure 8 shows an example.
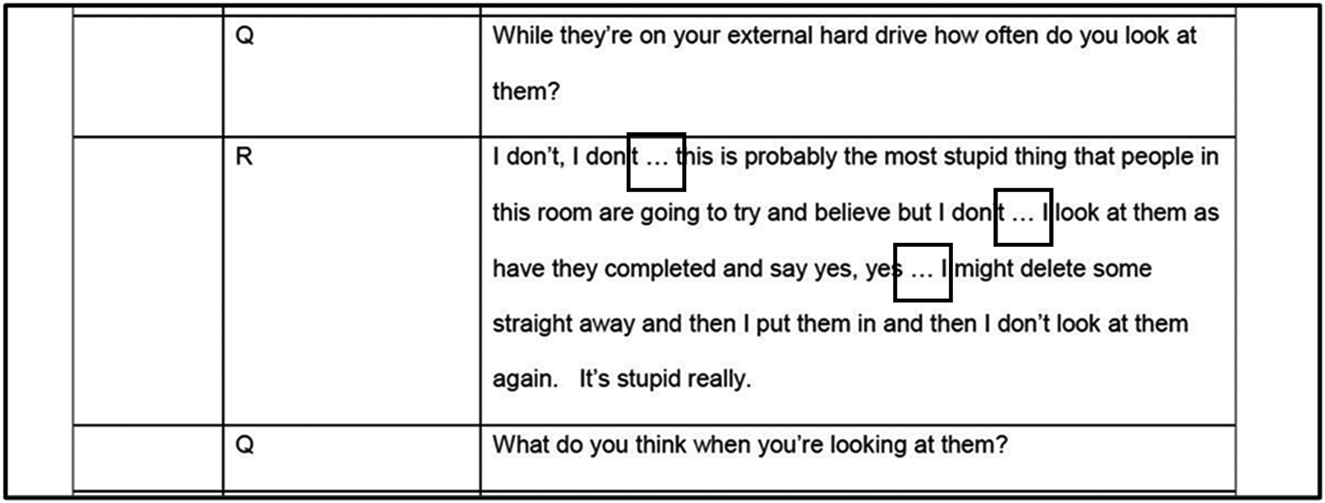
Figure 8. Silence: Interview 20.
In Figure 8 the square boxes indicate three places in which the police transcriber has represented something taking place between parts of the suspect's (‘R’) talk using a series of periods. However, it is not clear from this transcript alone whether ‘…’ is representing silence. To better understand this, we examined the audio and then used the notations from Table 1 to produce a Jefferson transcript of the same talk (see extract (1)).

From listening to the original audio, and producing the above transcript, we can observe many episodes of silence in the talk. Silences which were represented in the official record are shown in bold font, and those which were not represented, but which our analysis revealed, are highlighted in grey. Of those which the police transcribers did represent, two are slightly misplaced in the official record when we compare Figure 8 and lines 4 and 9 of extract (1). We might ask why are some and not others represented?
Silences are categorized by Sacks and colleagues (1974) in three ways. The first of these are ‘pauses’, a silence within a speaker's turn construction unit (TCU). These are recorded at the point of silence. The next are ‘gaps’, which are silences between TCUs, at a transition-relevance point (TRP) and, in CA transcripts, are recorded on a new line before the next, or first, speaker continues. The last category of silence as categorized by Sacks and colleagues (1974) are ‘lapses’: at a TRP where the first speaker has not nominated a new speaker, they do not continue themselves and unlike a gap no new speaker takes the turn for such a duration that there is a ‘lapse’ in the flow of conversation.
Therefore, the Jefferson transcription enables us to distinguish between pauses, gaps, and lapses (visible through how they are represented in the Jefferson transcript), and therefore we can better understand the function the speakers are performing by pausing. The comparison of the two transcriptions enables us to see that not all ‘pauses’ (multiple between lines 7 and 12), ‘gaps’ (lines 2, 4, 6), or ‘lapses’ (line 14) present in the talk (audible on the audio record) are reproduced in the written record. We are not able to understand from this analysis why some might be included over others, or what the impact of including or excluding them might have on future audiences. What we can say is, without a standardized method for representing silence, and with limited transcription resources, it is not surprising to see inconsistency in representing episodes of silence.
We show in the next example where the police transcriber has chosen not to represent episodes of silence, as shown in Figure 9.

Figure 9. Interview 10.
If we then consider a Jefferson transcription of this same stretch of talk, we see there were some extended periods of silence.

In the Jefferson transcript, we have recorded a pause within the interviewee's turn construction unit (TCU) at line 2 and in the interviewer's turn at line 9. At the end of the victim's turn at line 3, there is a transition-relevance point (TRP), although the comma indicates that the speaker's turn does not end with falling intonation. Therefore, this gap is recorded on a separate line, as another speaker (here, the interviewer) could have said something in this space but chooses not to. This is also true of the gap at line 7. Compare this with Figure 9, where the speech appears continuous.
When we, as analysts, listen to and transcribe this stretch of talk we see there are multiple pauses and gaps of significant length which are not represented by the police transcriber. We might question, why? In this case, this interview has been video recorded. In the video record, we see (as the transcribers would) that during the seven second gap (line 4), and the shorter gap at line 7 the interviewee is leaning forwards and gazing toward images that are laid on the table. We cannot know from this study why the police transcriber did not choose to use ‘…’ as in Figure 8/extract (1). However, in those previous examples we see there is some repair, some laughter, and some trouble producing the account. Here, the lengthy pauses directly relate to the interviewee moving her body into a position to view the images that she has been asked to describe.
Silence represented by ‘…’ in some places/transcripts and not in others highlights how police transcribers are making judgements about when to represent pauses and gaps and when not to. We might assume that silence is recorded when it is considered to be interactionally important, or interesting, in the transcribers’ opinion.
However, with minimal transcription resources available, we identify a practice of using ‘…’ to do more than show pauses but also to represent a number of temporal features of the talk, which we unpack in the next section.
Other temporal and sequential features
CA, and the Jefferson transcription system, has revealed how precisely we as speakers co-ordinate our talk when interacting with others (Sacks et al. Reference Sacks, Schegloff and Jefferson1974). Some of the conventions to represent temporal features of the talk are represented in Table 2 below.
Table 2. The Jefferson notation relevant for temporal features.

In this section, we consider how police transcribers attempt to represent temporal features of the talk using their limited transcription resources to represent the audible features. We first consider overlap, then cut-off talk, and finally latched talk.
Overlap
In our dataset we found that, as well as representing silence, police transcribers used a series of periods (‘…’) to represent overlapping speech when they transcribe sections of the interview verbatim. Figure 10 shows multiple uses of ‘…’ in this extract of Interview 17.

Figure 10. Interview 17.
To explore what these might be representing, we produced a Jefferson transcription of this same talk below.

If we compare the two extracts, in the Jefferson transcript we see the exact placement of the overlap (denoted by [ ]), which differs substantially from the officially produced transcript. Each of the text boxes shown in Figure 10 features the ‘…’ convention. As this has also been used to represent silence, when we ‘view’ Figure 10, we could imagine a stretch of talk with periods of silence between the turns, as opposed to the direct overlap audible in the recording that we have identified.
CA has demonstrated that as speakers we project possible completions of TCUs and co-ordinate our turn-taking to minimise overlap, ensuring our talk begins at a transition relevance place (TRP) (Sacks et al. Reference Sacks, Schegloff and Jefferson1974). Therefore, when we do enter another's turn it is often to perform a social action. In this case, we see on line 4 the interviewer completes their turn, with questioning intonation, but then continues on line 5. However, the interviewee has begun to produce their own turn in overlap. Here, we see the interviewer quickly ‘drop-out’ of that overlap to minimize occasions of speaking over each other (Hepburn & Bolden Reference Hepburn, Bolden, Sidnell and Stivers2012).
In Figure 11, and the corresponding transcript we have produced ourselves in extract (4), we show another kind of social action being performed with overlap. Please be advised of sensitive content in this example.

Figure 11. Interview 8.

At line 5, the interviewee (SUS) projects the completion of the interviewer's turn and the early onset “no” (line 5) is produced (Jefferson Reference Jefferson, Atkinson and Heritage1984). The position of this performs a social action, to assert that the suspect does not remember seeing these images as early as possible (Vatanen Reference Vatanen2018). From our experimental work, conducted as part of this wider project, we found participants made judgements about interviewees based on the temporal production of their talk. These judgements included how ‘credible’ and ‘sincere’ the interviewee was and how plausible their account sounded. When asked to justify their ratings, participants made comments in free text boxes about how quickly the interviewee ‘latched’ their answers to the officer's questions, or how they hesitated in their production (Deamer et al. Reference Deamer, Richardson, Basu and Haworth2022). These temporal features were commented on regardless of whether the participant was a reader of, or listener to, the extract. Their inclusion or omission from an official interview transcript is therefore potentially of consequence, especially if we consider how a jury might interpret the interaction.
Cut off talk
Across the corpus, we observed the police transcriber practice of also using ‘…’ to indicate a cut off, trailing off or in some way unfinished turn. An example of this is in Figure 12 below, indicated by the timestamp 8:57. Here we see the interviewer talk transcribed as “…. (inaudible) he's saying you were….”. Then, in extract (5) we show a Jefferson transcription of the same talk.

Figure 12. Interview 14.

We have shown that elsewhere (Figure 6), ‘…’ at the beginning of an entry with an empty box prior was used to indicate that the transcriber is moving from summarising to verbatim mode of transcription. We see this same practice being used here, but by producing the Jefferson transcript, we reveal this is being done to represent a different phenomenon. Listening to the audio we find the ‘…’ at the end of the interviewer's (‘Q’) turn marked with the time stamp 8:57, and at the beginning of the interviewee's response (‘R’), is being used in an attempt to represent that the interviewer cut off their own turn, and before they could proceed the interviewee began their turn. Interestingly, as shown in our own transcript, almost the same interactional phenomenon occurs in the immediately following turns (lines 6 and 7), but here the transcriber chooses not to use ‘…’, or any other transcription convention, to capture this.
What we have shown in this section is that the police transcribers’ practice of using ‘…’ has many functions in the official transcript and is used inconsistently. This makes it challenging, if not impossible, for the reader to correctly interpret the meaning intended by the transcriber. It is through such mechanisms that meaning is thus lost or distorted through the transcription process. This is clearly of concern in a context where ‘the reader’ includes those tasked with determining the outcome of criminal proceedings against participants on the basis of such evidential documents.
Emotion
We do not find emotion represented in the official transcripts in our dataset. However, in our previous experiments, we did find participants comment on audible ‘emotion’ when making judgements about interviewees. In this section, we choose to focus on laughter and crying in interaction, first by examining how it functions in interaction by representing it using Jefferson transcription conventions. CA considers the display of emotion as an interactional accomplishment (Hepburn Reference Hepburn2004). Therefore, episodes of laughter or crying are analysable as part of the social action being performed, and decisions as to whether or not they are included in a transcript are of consequence.
Laughter
First, there is a difference between what Goffman (Reference Goffman1961) referred to as ‘flooding out’ laughter, which is uncontainable and disruptive to the talk, and laughter as placed (Jefferson Reference Jefferson1985). There has been some limited discussion of the form and function of laughter in the police investigative interview (Stokoe & Edwards Reference Stokoe and Edwards2008; Stokoe Reference Stokoe2009; Carter Reference Carter2013). In Table 3, we show the Jefferson transcription conventions for laughter, which we use to highlight the placement of laughter in extract 6 below.
Table 3. Jefferson transcription notation for laughter (Jefferson Reference Jefferson, Atkinson and Heritage1984, Reference Jefferson and Lerner2004).

To demonstrate how a speaker might use smiling/laughter as an interactional resource, we have produced a section of an interview where the interviewer asks a suspect of a car theft how they have come to be in possession of the keys to the car.

In the interviewee's answer at lines 3–4, they produce the latter part of their turn with a ‘smiley voice’, indicating the question is being treated by the suspect as humorous. Talk enclosed with ‘£’ represents an audible quality which can be heard as ‘smiley voice’ even when the facial expressions are not available to the interacting parties, such as when on the telephone (Jefferson Reference Jefferson, Atkinson and Heritage1984; Lavin & Maynard Reference Lavin and Maynard2001). The design of this turn at line 4 is to attend to the implication that the person who gave the keys to the interviewee is either the owner, or the thief, of the car. At line 9, where the interviewer asks the suspect if they are “willing to name that person?”, which would likely clarify the latter two positions, the suspect produces laughter particles (“hn .hgef.”, line 10) before “come on” and continuing in smiley voice to say “£That was a [stupid question£]”. The interviewer enters the suspect's turn at line 12 with “I've got to ask”, accounting for the question as procedural. Stokoe (Reference Stokoe2009) found in police interviews laughter can mitigate the lack of affiliation associated with not responding adequately to a question. In this extract, by answering, the suspect would presumably incriminate another party. We can understand the interviewee's laughter to attend to this issue. We now examine how this same talk was recorded in the official written transcript.
In Figure 13 above, the initial question (lines 1–2 of extract (6)) and response (lines 4 and 7 of extract (6)) have been typed out by the police transcribers ‘verbatim’, in that the words spoken are (essentially) preserved. Without the accompanying audio, readers would not have access to the ‘smiley voice’ audible in the delivery of R's response. We emphasize that we do not necessarily expect police audio transcribers to record this level of detail, we instead aim to draw attention to the fact that this omission leaves it to the reader to interpret how the answer was delivered. We have shown in our above analysis of this short extract the interactional work being done by interviewer and interviewee here, which is lost in the official version.

Figure 13. Interview 21.
In the next text box, we see the transcriber move from verbatim to producing a summary of the next stretch of talk. From listening to the audio, we know that the interviewer asked a follow-up question, “Are you willing to name that person?” (line 9) to which the interviewee had responded with laughter and talk in smiley voice. However, here the police transcriber has interpreted this as “ROY stresses he is not willing to name this person”. This is the police transcriber's interpretation of the talk between lines 10–12 in extract (6). It could be that their interpretation of the speech is that it is stressed in some way, or that terms such as ‘said’ and ‘stressed’ are used by transcribers interchangeably. It is not possible to know from the current analysis alone. However, here we demonstrate the subjective interpretation of what is audible in the recording and suggest that this is possibly a somewhat misleading one.
Crying
Similar to laughter, in CA crying is seen as interactionally organised, and transcribing the crying helps analysts understand the form and function (see Table 4). One way to represent the crying is to do as Manzo, Heath, & Blonder (Reference Manzo, Heath and Blonder1998) did in their study of stroke patients, which is to label that crying has taken place. Whalen & Zimmerman (Reference Whalen and Zimmerman1998) attempted to move beyond this and represent the features of callers’ distress when telephoning 911. Since then, Hepburn (Reference Hepburn2004) and later Hepburn & Potter (Reference Hepburn, Potter, Peräkylä and Sorjonen2012) have built on this and the work of Jefferson (Reference Jefferson1985) on laughter, subscribing to the need for transcription to do more than simply to note that crying had occurred. This is the approach we take here to represent the organisation of crying for our purposes. Hepburn (Reference Hepburn2004) and Hepburn & Potter (Reference Hepburn, Potter, Peräkylä and Sorjonen2012) outline the interactional features of crying and present the use of relevant transcription notations. Again, we are not advocating for police transcribers to use these methods; we employ them here for our own analytic purposes of highlighting exactly where crying is present in the audio.
Table 4. Jefferson transcription notation relevant for crying (Hepburn Reference Hepburn2004; Jefferson Reference Jefferson and Lerner2004; Hepburn & Potter Reference Hepburn, Potter, Peräkylä and Sorjonen2012).

In our experimental work, participants made judgements about interviewees based on crying when it was audible, and when it was represented in the written record (Deamer et al. Reference Deamer, Richardson, Basu and Haworth2022), indicating its potential significance in legal proceedings. Although we identified episodes of crying across our audio and video corpus, we did not find this to be recorded in the official police transcripts. Extract (7) is an example of an audibly distressed interviewee. We have used the transcription notation to show where crying is present within the talk.

Our transcription of this section of talk makes visible, sniffs, wobbly and creaky voice and sobs throughout. Between lines 3 and 4 the interviewee is having trouble producing their turns, which by line 5 and 6 has escalated into crying and an abandoned turn at talk. At line 12 and the beginning of line 15, the interviewee is audibly sobbing (“~~°Uh: [huh- huh::°~~”), with a wobbly voice (~) and quietly (̊ ̊). But when we look at what was recorded in the official transcript in Figure 14, it is not represented that the interviewee was crying.
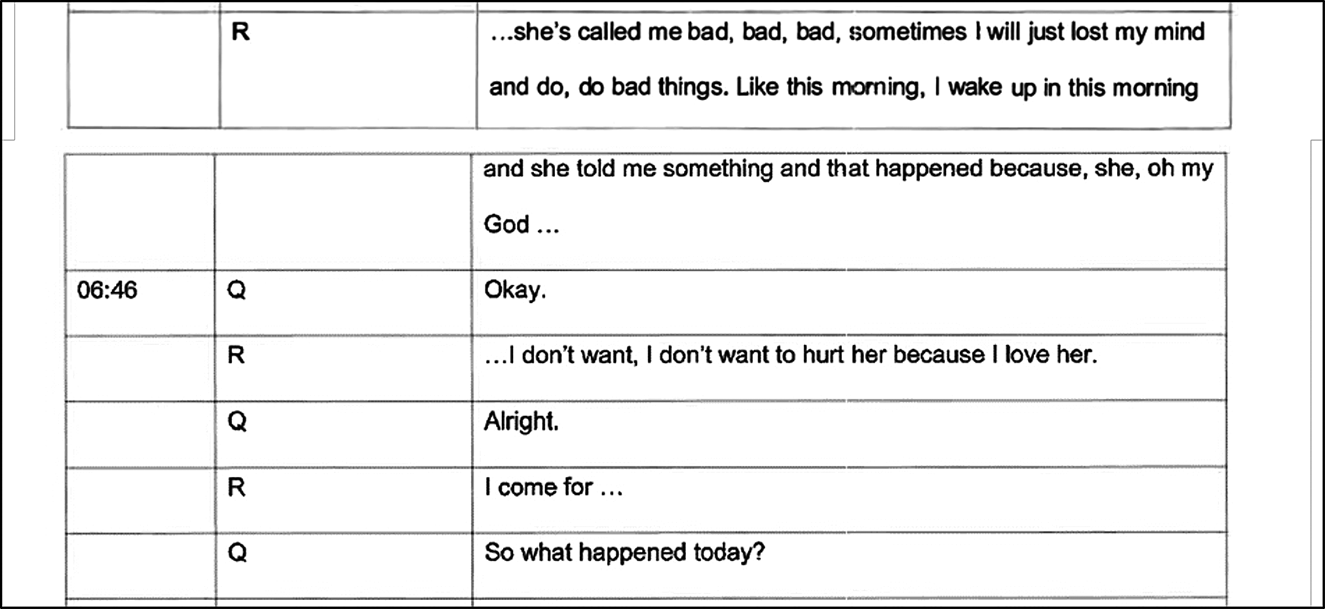
Figure 14. Interview 17.
Our focus here is again on the use of the three periods. The police transcriber has attempted to represent something after the interviewee says, “oh my God…” with these three periods, and again we see the same practice used here before the talk, “…I don't want”. However, there is a time stamped “Okay” delivered in between by the interviewer (‘Q’). Based on what we have seen elsewhere, ‘…’ could represent that the interviewer's turn was delivered in overlap, or there was silence. Therefore, it is not clear from this record that the interviewee was too distressed to complete his sentence, or that there was sobbing during his talk which we have shown in extract (7).
Understanding the interactional implications of distress and upset is particularly useful for studies of institutional settings. A party being so upset that they are unable to respond to turns can be highly consequential when 911 call-takers are gathering information, as Whalen & Zimmerman (Reference Whalen and Zimmerman1998) have shown. Understanding the responses to crying such as the use of tag questions by child protection officers can facilitate tellings of child abuse in calls to a child protection helpline (Hepburn & Potter Reference Hepburn, Potter, Freed and Ehrlich2010), and understanding how police interviewers deal with distressed, intellectually impaired child and adult victims of sexual offences (Antaki, Richardson, Stokoe, & Willott Reference Antaki, Richardson, Stokoe and Willott2015) is conducive to more effective information gathering and better experiences for all. Our finding that crying and distress are not represented in our corpus of official police transcripts is therefore of potential concern, in that it removes this interactionally significant feature from the record relied upon by many future audiences in the legal system and beyond. This strengthens our position that it is far preferable for audiences to hear the recording, especially at the point when any extracts are being presented as evidence in court.
DISCUSSION
Through our analysis, we have shown inconsistencies, omissions, and distortions in official police interview transcripts. While the features that we identify here might not be consequential for justice in every case, the very possibility that they could influence judicial outcomes is surely sufficient cause for concern. Our intention in highlighting these issues here is to make them empirically available for producers and users, and to lay foundations for further academic and practitioner work, especially with regard to moving towards more standardisation of practice.
It is important to remember that police transcripts are not produced for linguistic analysis (Blackwell Reference Blackwell and Kniffka1996); and to acknowledge that the purpose of the investigative interview record is a complicated matter (see Haworth Reference Haworth, Coulthard, May and Sousa-Silva2020). In a previous article (Richardson et al. Reference Richardson, Haworth and Deamer2022) we asked five questions of transcripts in legal settings: (i) Is the record produced an accurate representation of the spoken interaction?; (ii) Who has ownership of the record?; (iii) Who has agency, that is, whose ‘voice’ is represented in the recorded account?; (iv) How usable is the record?; and (v) How resource efficient it is to produce? In the current article we have explored the first of these points in more detail.
We have used CA and the Jefferson (Reference Jefferson and Lerner2004) transcription system to reveal police transcribers’ current practice. We previously outlined (Deamer et al. Reference Deamer, Richardson, Basu and Haworth2022) how the focus tends to be more on reproducing content, to ensure all or most of what was said is transcribed, and less on how it is said, borne out in our analysis.
We have shown how police transcribers do attempt to represent certain features, such as silence, overlap, and cut-off turns, but they do so inconsistently, making use of available transcription conventions repeatedly, most notably, the series of periods (…).
In the absence of standardised guidance and training, police transcribers are left to use their personal judgement on when to include how, in addition to what, was said. The difficulty here is for readers of the transcripts to know how to interpret the notations that are included. It is not possible to interpret the difference between indications of silence, overlap, moving from summarising to verbatim transcription, or crying if they are all denoted by ‘…’. Meaning therefore cannot be reliably communicated in this way from transcript creator to user.
Ultimately, the best way to solve the issues we highlight in this article would be for audiences to listen to the audio recording, rather than relying so heavily on a transcript. However, at least for now we have to accept the practical reality that transcripts do, and will continue to, have a role in legal proceedings. Therefore, we might consider recommending consistently including what scholars have found to be lacking in legal transcriptions: features such as disfluency in speech, overlapping talk, pauses, stress, and/or intonation (Bucholtz Reference Bucholtz2007; Fraser Reference Fraser2014; Komter Reference Komter2019). However, we are reluctant to do so without knowledge of how this would benefit the users of the transcripts. Certainly, it is not as straightforward as recommending transcription conventions. As Deamer et al. (Reference Deamer, Richardson, Basu and Haworth2022) has shown, adding a feature into a transcript, such as timed pauses, may in fact make this more salient to the user than its occurrence in the original recording, potentially distorting the interpretation as opposed to preserving it as closer to the original version. We are conducting experimental work to investigate this further, some of which is reported in Tompkinson et al. (Reference Tompkinson, Haworth, Deamer and Richardson2023).
The balance to be struck in collaboration with our police partners sits in the understanding that records do not need to be a ‘perfect’ representation of the interaction that took place. That is not reasonable nor is it required. Records need only to be adequate for the purpose(s) they serve (see Fraser Reference Fraser2022; Richardson et al. Reference Richardson, Haworth and Deamer2022), and it must also be feasible to keep pace with the demands and constraints of the justice process. Yet, at the heart of this is the fact that these records are ultimately used to secure the conviction of those charged with criminal offences, and as such, a focus should be on ensuring that if they are to remain a central feature of the legal system, end users are made more aware of their limitations, and of the fact that any transcript is only one of innumerable possible interpretations of the interaction it purports to represent. As Fraser (Reference Fraser2022:3) emphasises, they are viewing a transcript and not the transcript.
CONCLUSION
In this article, we use conversation analysis and Jefferson transcription conventions to empirically demonstrate and make available to practitioners and academics alike the transformation that can occur in the process of producing written records of police investigative interviews. This novel contribution systematically highlights the issues present in consistency of transcripts, which are produced and used as evidence every day in the England and Wales criminal justice system, despite the availability of the audio/video recording.
We intend this work, as part of a wider program of research and in collaboration with our police partners, to contribute to guidance and training to improve consistency in the production of transcripts, and we also endeavour to increase awareness within the legal system of the benefits of using audio/video recordings in preference to their traditional reliance on transcripts to be something which they cannot be.


























 Open access
Open access