


Makasar is an Austronesian language belonging to the South Sulawesi subgroup within the large Western-Malayo Polynesian family. It is spoken by about two million people in the province of South Sulawesi in Indonesia, and is the second largest language on the island of Sulawesi (behind Bugis, with about three million speakers). The phonology is notable for the large number of geminate and pre-glottalised consonant sequences, while the morphology is characterised by highly productive affixation and pervasive encliticisation of pronominal and aspectual elements. The language has a literary tradition including detailed local histories (Cummings Reference Cummings2002), and over the centuries has been represented orthographically in many ways: with two indigenous Indic or aksara-based scripts, a system based on Arabic script, and a variety of Romanised conventions. From at least the early 18th century Macassan sailors travelled regularly to northern Australia to collect and process trepang or sea cucumber (Macknight Reference Macknight1976), and many loanwords passed into Aboriginal languages of the northern part of Australia (Evans Reference Evans1992, Reference Evans, McConvell and Evans1997).
In the Makasar language, the language itself is referred to as basa Mangkasara’, the ethnic group who speak it are referred to as tau Mangkasara’, and the city which dominates the region as Mangkasara’.Footnote 1 In modern Indonesian they are bahasa Makassar, orang Makassar and Makassar, respectively. At various times in English the forms Makassarese, Macassarese, Macassan and Makasar (among others) have been found, and in the present paper we choose to use Makasar, which has become more common in linguistic research in recent years. For detail on the orthographic system, the reader is referred to Chapter 3 of Jukes (Reference Jukes2006).
Makasar is a relatively thriving regional language of Indonesia. In rural areas and poorer sections of Makassar city the language is used almost exclusively; and although in upwardly mobile sections of Makassar society it competes with Indonesian (the national language), command of the Makasar language is an important part of ethnic identity. Code-switching and code-mixing of Makasar and Indonesian is pervasive in the urban setting, but less so in rural ones. However, most speakers are not literate in Makasar. No-one can read the defunct Makasar or jangang-jangang script, while few are becoming fluent readers of the Bugis script; at the same time people are generally prevented from gaining literacy in Romanised Makasar by the lack of standardisation and a paucity of available texts.Footnote 2 In addition to being fluent speakers of standard Indonesian and/or its local variant Makassar Indonesian, Makasar speakers may also have some knowledge of the neighbouring language Bugis, of Arabic (the language of religion, as the vast majority of Makasar speakers are Muslims), of Dutch or Japanese (the languages of historical colonialism), and of English (for its global importance).
The speaker in this Illustration is Isnawati Osman, a 42-year-old female from Makassar, who at the time of recording was enrolled in doctoral studies in Human Resource Management at a university in Melbourne, Australia. The words were elicited with a modified Swadesh list augmented by examples drawn from the comprehensive Makasar–Dutch dictionary (Cense Reference Cense1979).
Figure 1 shows a map of Indonesia, with the town of Makassar at the south-western corner of the island of Sulawesi.
Figure 1 Map of Indonesia. The city of Makassar on the island of Sulawesi is circled.
Consonants

In the above table, the orthographic form is given in angled brackets where it does not correspond to the IPA symbol. It can be seen that there are four places of articulation in both the voiced and voiceless stop series, and also in the nasal series. There are also two liquids, two glides, and two glottal consonants. All consonants except the glottal stop may occur in onset position, but coda position is restricted to the glottal stop, the nasals (preceding a homorganic consonant), and voiceless stops as part of a geminate sequence.Footnote 3 All the nasals, /l/, /s/, /r/ and the glides /w/ and /j/ appear in lengthened forms which are also analysed as geminated; thus, these also may appear syllable-finally. Only two consonants are possible word-finally: the glottal stop /ʔ/ and the velar nasal /ŋ/.
Each pair of voiced and voiceless stops can be contrasted in onset position. The stop /t/ (but not /d/) is dental in the speech of many speakers, and the palatals /c/ and /ɟ/ are likely lamino-alveopalatal, given their strong affrication.
The following examples illustrate some minimal pairs:

Table 1 below gives values for stop burst duration, collapsed across all prosodic contexts. It can be seen that, in general, the voiceless stop bursts are about twice as long as the voiced stop bursts, according to place of articulation. Jukes (Reference Jukes2006) notes implosive variants of the voiced stops /b/ and /d/ in certain environments (notably word-initial and following a glottal stop); however in our present database of seven speakers (four male and three female, including the speaker in this Illustration), we tend to see voiced stops being voiceless unaspirated, particularly /b/ in initial position.
Table 1 Singleton stop burst duration (in milliseconds) in Makasar: Mean, Standard Deviation (SD) and number of tokens (N). The absence of a burst is coded as 0 ms in this statistical summary. Data are based on seven speakers (four male and three female). Total of 5801 tokens.

Each of the four nasal consonants can be contrasted with the others:

The liquids /r/ and /l/ can be contrasted:
The fricatives /s/ and /h/, and affricated stops /c/ and /ɟ/ can be contrasted, too. Note, however, that /h/ is quite rare, and mostly occurs in borrowings from Arabic, Indonesian or Dutch:

The glides /w/ and /y/ can be contrasted between like vowels:
In some environments, glides can also be contrasted with sequences of vowels with no intervening glide:

The reader is referred to Jukes (Reference Jukes2006: 67–69) for discussion of the distribution of these glides, which are generally limited in occurrence.
In addition, there are contrasts between singleton and geminate for certain consonants, namely the voiceless stops, nasals, liquids, glides and the supra-laryngeal fricative /s/:

Footnote 4,Footnote 5,Footnote 6
Table 2 below gives mean and standard deviation duration values for the various singleton and geminate consonant pairs, averaged across 11,713 tokens from seven speakers. In general, the geminate consonants are between two-and-a-half and three times longer than their singleton counterparts, with the notable exception of the nasals and the fricative, which have inherently long singleton durations, and which are less than twice as long in their geminate form. It should also be noted that in our data, the velar nasal has similar duration values in both the singleton and the geminate forms.
Table 2 Singleton and geminate consonant duration (in milliseconds) in Makasar: Mean, Standard Deviation (SD) and number of tokens (N). Data are based on seven speakers (four male and three female). The final column shows the increase in duration for geminate consonants relative to their singleton counterparts.
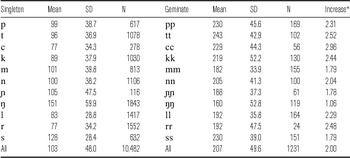
* Mean(geminate)/Mean(singleton)
The first element of the geminate is treated as the coda of the preceding syllable. Phonetic evidence for the moraic status of this first element is found in compensatory shortening of the vowel preceding the geminate. Table 3 gives mean and standard deviation of vowel duration preceding singleton vs. geminate stops – it can be seen that the vowel preceding a singleton stop tends around 150 milliseconds in our database, and the vowel preceding a geminate stop tends around 90 ms (i.e. more than 50% greater duration for the vowel preceding a singleton).
Table 3 Singleton and geminate stops in Makasar: Mean, Standard Deviation (SD) and number of tokens (N) for preceding vowel duration (in milliseconds). Data are based on seven speakers (four male and three female).

There are no examples of geminate voiced stops or glottals. Instead there are sequences of glottal stop and voiced stop:

The glottal stop can be contrasted with its absence in coda position, though this contrast can be extremely difficult to hear, especially in word-final position:

The reader is referred to Jukes (Reference Jukes2006: 70–72) for further discussion of the role of the glottal stop in morpho-phonological alternations.
Vowels

Makasar has five vowels /a e i o u/. In final position, the mid vowels /e o/ tend to be low-mid /ɛ ɔ/. However, for some speakers, these mid vowels are quite high in most environments, tending towards /i u/, hence our representation in the vowel plot above. Figure 2 shows an F1/F2 vowel plot for the five vowels of Makasar. It is based on 14,722 tokens from the same seven speakers (with no normalisation), and the ellipses represent two standard deviations around the mean. It can be seen that the means for /e o/ fall within the two standard deviations for /i u/, respectively.

Figure 2 F1~F2 plot of Makasar vowels based on 14,722 tokens from seven speakers (four male, three female, with no normalisation), and the ellipses represent two standard deviations around the mean.
Each of the five vowels can be contrasted with the others in both closed and open syllables:

Jukes (Reference Jukes2006: 76) notes that the vowel /a/ is about four times more frequent than any of the other four vowels in the system.Footnote 7 He attributes this asymmetry to the merger of two former phonemes /*a/ and /*ə/ from proto-South Sulawesi. A particularly notable result from our database, which we attribute to this historical merger, concerns the duration of the /a/ vowel in Makasar. Figure 3 shows plots of vowel duration and also of f0 (as measured at the temporal midpoint of the vowel) for each of the five vowels. It can be seen that, contra intrinsic phonetic effects, the /a/ vowel is noticeably shorter than any of the other vowels – it has a mean duration of 155 ms, whereas the other vowels tend around 170 ms. By contrast, the expected microprosodic effects apply, with /a/ having a lower f0 than the other vowels (147.5 Hz, compared to around 155 Hz for the other vowels). This is a very unusual phonetic pattern typologically, which we believe would benefit from further investigation.

Figure 3 Plots of mean plus 95% confidence intervals of vowel duration and f0 sampled at the temporal midpoint of the vowel. Plots based on 14,722 tokens from seven speakers (four male, three female, with no normalisation). Data are plotted according to vowel.
It is also notable that Makasar allows sequences of monophthong vowels. The syllabic status of each monophthong vowel is evidenced by stress patterns, and is also evidenced from songs and poetry requiring a fixed number of syllables per line. Table 4 gives some examples of such words.
Table 4 Examples of intra-morphemic vowel sequences in Makasar.

Some brief notes on prosody
The majority of Makasar roots are bi-syllabic, with stress on the penultimate syllable. A significant subset of roots is tri-syllabic with antepenultimate stress: these are roots which have been subject to a process labelled Echo-VC.Footnote 8 There is a small number of tri-syllabic roots with regular penultimate stress. Four-syllable ‘roots’ often appear to be compounds or other polymorphemic forms (e.g. the word balakebo’ ‘herring’ looks like a compound including kebo’ ‘white’, though the first element bala is not meaningful in this context). Monosyllabic roots are extremely rare, though there are several monosyllabic interjections and particles such as o and ri (respectively an interjection and a prepositional particle). Jukes (Reference Jukes2006: 89) states that he is aware of only four examples of monosyllabic lexemes which are not obviously loan words, including the words u’ ‘hair’ and pi’ ‘birdlime’ given in the following list:


Although the vast majority of roots have two or three syllables, much longer words are possible due to the fact that Makasar is agglutinative, and also to the fact that reduplication is highly productive. Jukes (Reference Jukes2006: 90) states that six- and seven-syllable words are common, but that any words longer than this almost always contain reduplication.
Jukes (Reference Jukes2006: 91) reports that stressed syllables are noticeably louder and have a higher pitch than unstressed syllables. He also notes that they have extra duration. Figure 4 below confirms these impressionistic observations with plots of vowel duration, f0 and RMS (Root Mean Square) energy according to different Stressed and Unstressed prosodic categories. An examination of vowel formant data for the three point vowels /i a u/ (Figure 5) according to these different prosodic categories suggested small differences in formant structure according to stress – it can be seen that both /i/ and /u/ are more central in Weak prosodic conditions (i.e. word-medial unstressed), and that /a/ varies by about 100 Hz in F1 according to prosodic context. However, there is no categorical impression of a shift in vowel quality from /a/ to /ə/, for example, according to prosodic context – even the weakest /a/ vowels (unstressed vowels and also word-final vowels) tend around 700 Hz for F1, whereas the high vowels /i/ and /u/ tend around 350–400 Hz for F1, and (in Figure 2 above) the mid vowels tend around 500 Hz.
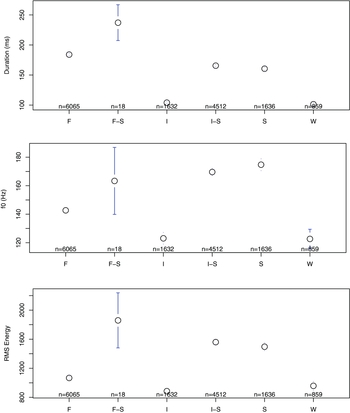
Figure 4 Plots of mean plus 95% confidence intervals of vowel duration, and f0 and RMS energy as sampled at the temporal midpoint of the vowel. Plots based on 14,722 tokens from seven speakers (four male, three female, with no normalisation). Data are plotted according to prosodic category: there are three Stressed categories (F-S = Final-Stressed; I-S = Initial-Stressed; and S = (medial) Stressed), and three Unstressed vowel categories (F = Final; I = Initial; and W = (medial) Weak).
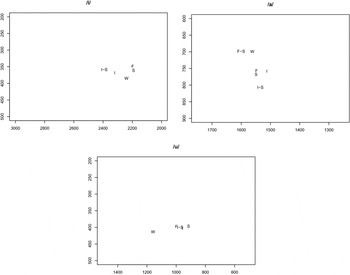
Figure 5 F1~F2 plot of Makasar vowels. The plotted points represent mean values according to prosodic category: three Stressed categories (F-S = Final-Stressed; I-S = Initial-Stressed; and S = (medial) Stressed), and three Unstressed vowel categories (F = Final; I = Initial; and W = (medial) Weak). Plots are based on 14,722 tokens from seven speakers (four male, three female, with no normalisation).
Importantly, Jukes also notes that secondary stress only occurs if the word is a reduplication – in this case, the first element takes the secondary stress, and the second element takes the primary stress, for instance, /amˌmekaŋˈmekaŋ/ ‘fishing (with a hook)’. Suffixes are counted for stress, but enclitics are not – and since stress is assigned from the right edge of the word, prefixes and proclitics are irrelevant for stress assignment.
For discussion of certain morpho-phonological processes, such as aphesis of initial /a/ (deletion of unstressed initial /a/ in rapid speech), ‘strengthening’ of the root-final glottal /ʔ/ to [k] when followed by a vowel-initial suffix or enclitic, and nasal ‘substitution’ (where a stem-initial consonant becomes the equivalent nasal when a prefix is added), the reader is referred to Jukes (Reference Jukes2006).
Transcribed passage ‘North Wind and the Sun’
Orthography
I Angin Wara’ siagang i Mata Allo
Na nia’mo se’re alloa na assigea’ anjo i Angin Wara’ siagang i Mata Allopassala’ angkanaya inai gassingangngang batang kalenna.
Na anjo ri wattua, allalomi se’re tau, ilalang ju’ba kebo’na, tau battu ri bori bellaya. Siturukkang kanamo i Angin Wara’ siagang i Mata Allo, angkana inai akkullei allappasangi ju’bana anjo tau ammaloa maka iami nirekeng gassingangngang batang kalenna.
Na appakarammulamo i Angin Wara’; natui’mi anginna sa’ge kancang. Minka sa’ge kancangi natui’ anjo anginna, sa’ge kancantongi na parapa’ ju’bana anjo lapung taua.
Na appakaramulatommi i Mata Allo, (napasiara’mi singara’) napasiara’mi singara’na siagang bambanna. So’na nakasia’namo anjo bambanga, anjo tau a’ju’baya na lappassammi ju’ba kebo’na.
Iami saba’ na nirekemmi i Mata Allo gassingangngang na i Angin Wara’.
Phonemic transcription
i aŋin waraʔ siaɡaŋ i mata allo
na niaʔmo seʔre alloa na assiɡeaʔ aɲɟo i aŋin waraʔ siaɡaŋ i mata allopassalaʔ aŋkanaja inai ɡassiŋaŋŋaŋ bataŋ kalenna
na aɲɟo ri wattua allalomi seʔre tau ilalaŋ ɟuʔba keboʔna tau battu ri bori bellaja
siturukkaŋ kanamo i aŋin waraʔ siaɡaŋ i mata allo aŋkana inai akkullei allappasaŋi ɟuʔbana aɲɟo tau ammaloa maka iami nirekeŋ ɡassiŋaŋŋaŋ bataŋ kalenna
na appakarammulamo i aŋin waraʔ natuiʔmi aŋinna saʔɡe kancaŋ
minka saʔɡe kancaŋi natuiʔ aɲɟo aŋinna saʔɡe kancantoŋi na parapaʔ juʔbana aɲɟo lapuŋ taua
na appakaramulatommi i mata allo (napasiaraʔmi siŋaraʔ) napasiaraʔmi siŋaraʔna siaɡaŋ bambanna
soʔna nakasiaʔnamo aɲɟo bambaŋa aɲɟo tau aʔɟuʔbaja na lappassammi ɟuʔba keboʔna
iami sabaʔ na nirekemmi i mata allo ɡassiŋaŋŋaŋ na i aŋin waraʔ
Acknowledgements
This work was supported by the Australian Research Council (a Discovery Project awarded to Anthony Jukes, and a Future Fellowship awarded to Marija Tabain). We are grateful to our speakers for their interest in language work – Isnawati Osman, Munahwarah Daeng Muna, Hasanuddin Salli Daeng Sikki, Daeng Sanga, Daeng Sarro, Daeng Tinggi and Daeng Tompo – and in particular to Isnawati for her translation of the ‘North Wind and the Sun’ passage. We are also thankful to Sally Bowman and the students of Marija Tabain's 2013 Honours class in Acoustic Phonetics, for their work in labelling the database, and to two anonymous reviewers for their positive feedback on this Illustration.











