



Introduction
Most studies on language contact in Iran have focused on the effects of Persian on the country’s minority languages.Footnote 1 There are also many cases where large regional languages such as Azeri, Kurdish, Balochi, Lori and Bakhtiari exert an influence on smaller regional languages, and a few studies have appeared on this topic.Footnote 2 In all of these studies, contact-induced change is demonstrated by structural convergence within a linguistic area.
However, the mechanisms of contact-induced change are rarely addressed in studies of Iran’s languages. Usually, contact-induced structural change is framed as contact between “languages” (as if languages have a life of their own apart from speakers) or—a little more accurately—“language communities.” In reality, specific contact-induced structural changes in language do not take place at one moment in time across an entire community, but within individual speakers and, more specifically, in the linguistic practices of bilingual individuals, as shaped by their individual language acquisition patterns and multilingual repertoires, where structures of each language they speak are competing with, influencing, reorganizing the structures of the other languages.Footnote 3
In this paper, we examine the patterning of language contact in the city of Juneqan, Chahar Mahal va Bakhtiari Province (henceforth C&B), where the position of two minority languages—Bakhtiari and Qashqai Turkic—appears to be evenly balanced. Our analysis is based on a comparison of L1 and L2 speech of individuals from both language communities. The paper opens with an overview of the research context, within the framework of the Atlas of the Languages of Iran (ALI) research programme.Footnote 4 We set the stage with a description of the language situation in Juneqan, with reference to the national, regional and local context. We then establish the methodology for this study through presentation of research questions, the datasets we collected to address these questions, and language acquisition profiles of the speakers consulted in this study. The core of the paper consists of an analysis of the structural effects of contact-induced change in the lexicon, phonology and morphosyntax of these speakers. Based on the data, which show equivalent influence of each language on the first- and second-language speech of members of the other language community, we argue that the regional dominance of Bakhtiari is evenly counterbalanced by the presence of a majority of mother-tongue Turkic speakers in this city.
Current Linguistic Research in Chahar Mahal va Bakhtiari (C&B) Province
This study was conducted in the context of research carried out for Chahar Mahal and Bakhtiari Province (C&B) for the Atlas of the Languages of Iran (ALI) research programme.Footnote 5 This is the area of Iran where work in the Atlas is most advanced. Field research began in 2014 with a survey of language distribution in each of the province’s cities, towns and villages—over 800 settlements in all.Footnote 6 This initial research clarified the geographic distribution of three main language communities: Bakhtiari, CharmahaliFootnote 7 and Turkic.Footnote 8 Results of this study, carried out according to the methodology described elsewhere,Footnote 9 are shown in Figure 1.
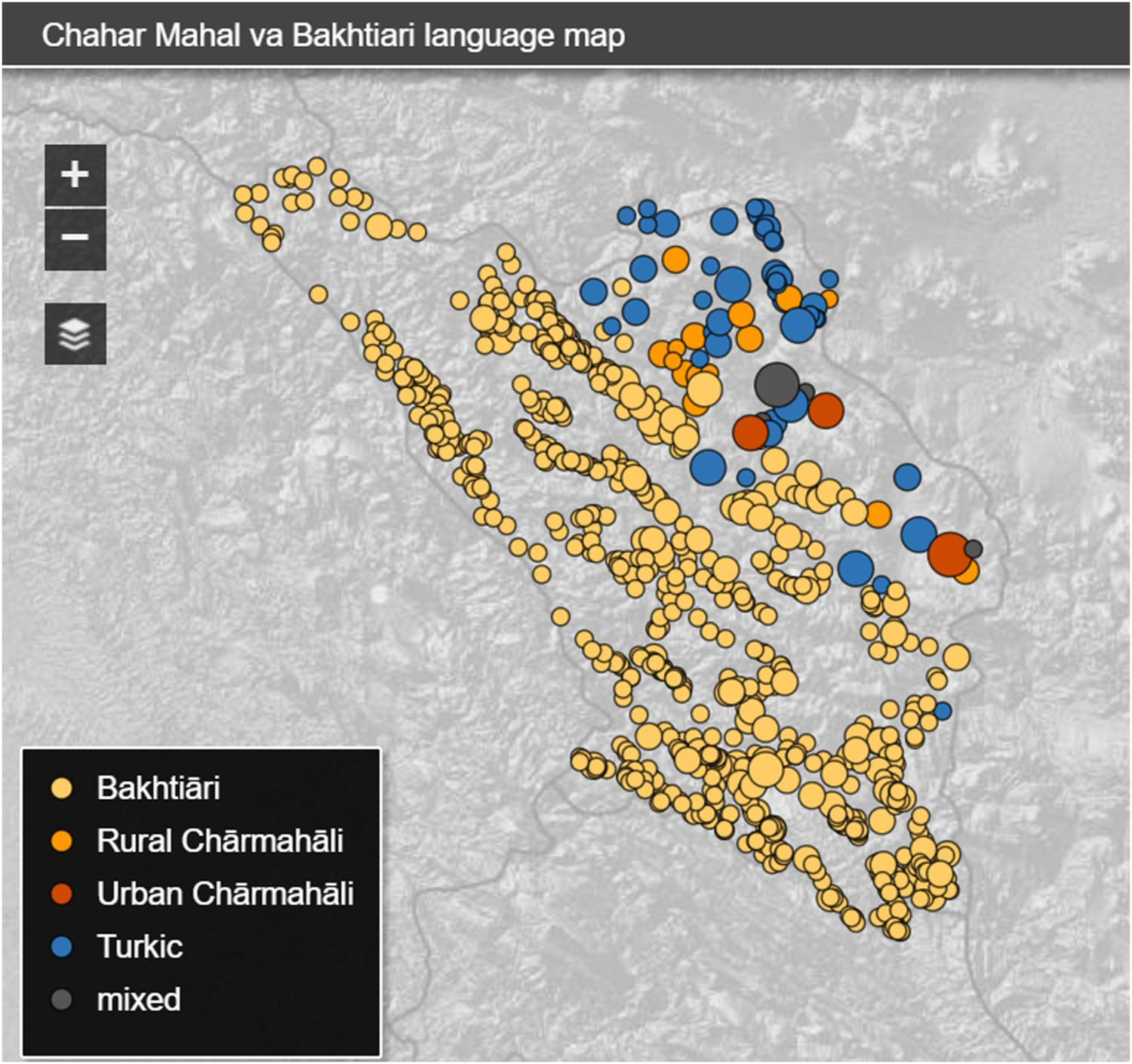
Figure 1. Language distribution in C&B Province.
Note: In each populated place, only the mother tongue of the majority of inhabitants is shown. In the case that no single language is spoken as a mother tongue by a majority of inhabitants, the settlement is shown as “mixed”.
Source: http://iranatlas.net/module/language-distribution.chahar_mahal_va_bakhtiari
After completing the language distribution map for the entire province, including notes on communities and districts with high levels of linguistic diversity, we were able to choose research sites for linguistic data collection from across the nine shahrestān (provincial sub-districts). Sites were selected to highlight situations of three types: (i) homogeneous rural dialects in communities with a single dominant language, where linguistic structures are often both conservative and distinctive; (ii) multilingual communities, in order to explore patterns of direct language contact and change; and (iii) district centres, which we projected would show the greatest impact of Persian on speaker proportions and linguistic structures. Research sites for C&B are shown in Figure 2.

Figure 2. Research site selection for C&B.
Source: http://iranatlas.net/module/language-distribution.chahar_mahal_va_bakhtiari_static
Over a two-year period, the research team used the ALI questionnaire (https://carleton.ca/iran/questionnaires) to collect linguistic data in 24 locations. In six of the 24 locations, it was carried out separately with people from two language communities, bringing the total of research interviews to 30. Analysis of the data is underway and general results, including findings on language variation, contact and typology, are presented elsewhere.Footnote 10 A sample linguistic data map from this phase of research is shown in Figure 3.
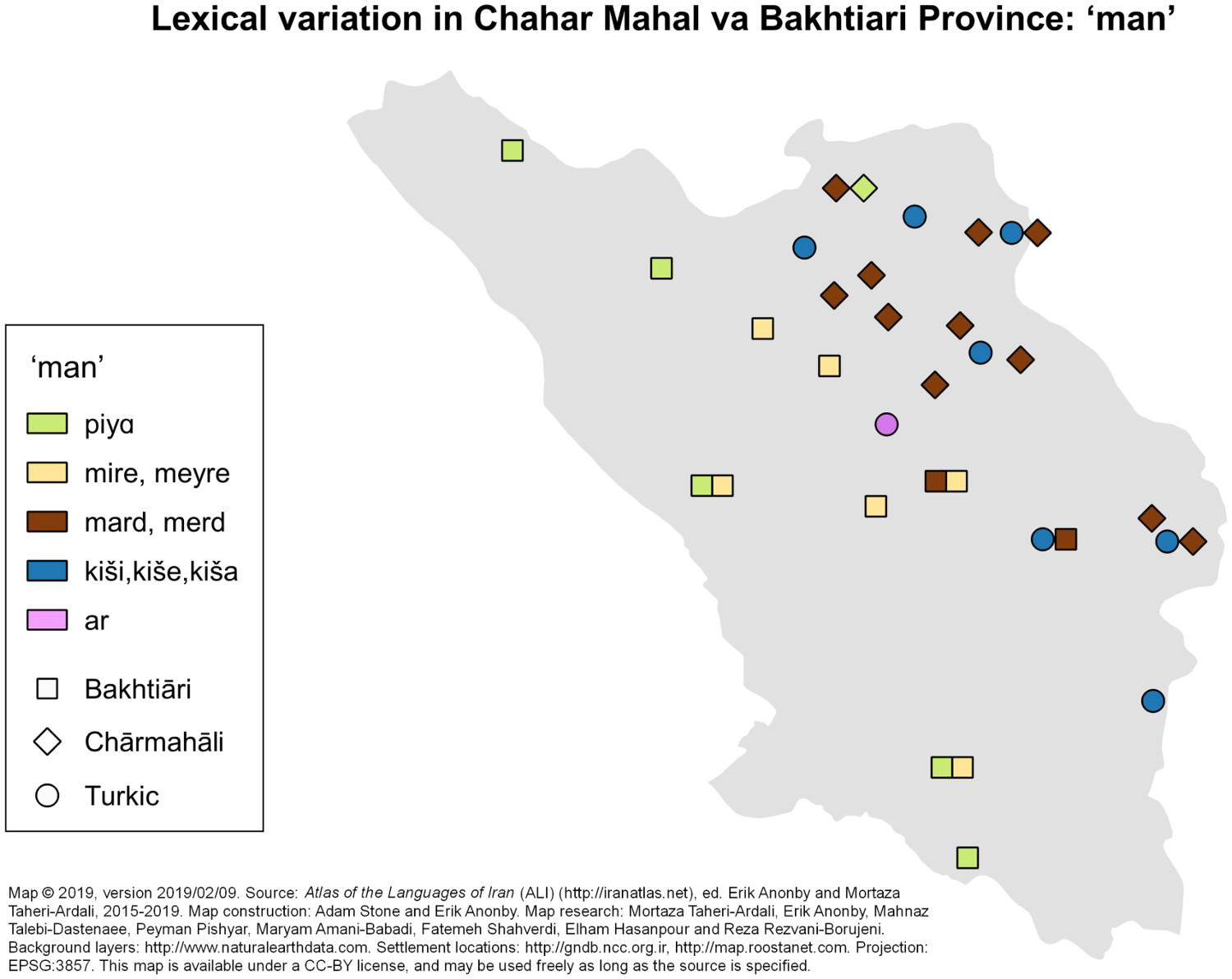
Figure 3. Lexical variation in C&B Province: “man”.
Source: http://iranatlas.net/module/linguistic-data.cb-lexicon-man
Typically, data collection for the Atlas focuses on linguistic structures used by fluent mother tongue (L1) speakers. However, many aspects of linguistic diversity are not addressed when research is limited to a single questionnaire carried out in a given location. The questionnaire contains items related to the multilingual profile of each community, but as a preliminary investigative tool carried out with a single speaker, or group of speakers, it cannot provide a satisfactory overview of patterns of multilingual language acquisition, use and change within a community. Further research is needed. This is the case for Juneqan, located in central C&B Province (see Figure 3).
When carrying out the ALI questionnaire with L1 speakers of Turkic and Bakhtiari in Juneqan, Taheri-Ardali observed a (to him) surprising pattern of “balanced Turkic-Bakhtiari bilingualism” in the town, which he had not seen elsewhere in his native province of C&B: most of the town’s residents are equally proficient in both Turkic and Bakhtiari, regardless of which they speak as a first language.
Although bilingualism is not a primary focus of the Atlas research, or an area of expertise among team members, we recognize that it is an important element in understanding Iran as a linguistic area. Since contact-induced language change first takes place at the level of individual speakers, it is appropriate to look at patterns of bilingual acquisition and correspondences in the linguistic structures used by individuals. For this reason, this study sets out to examine the multilingual profile and associated linguistic structures of individuals from both language communities.
Regional and Local Context: Community Multilingualism in Juneqan
Juneqan is located at the centre of C&B, at the edge of the mountainous Bakhtiari language area and in close proximity to the Charmahali- and Turkic-speaking communities in the foothills of the north-east corner of the province (Figure 4; see also Juneqan on the research site map, Figure 2).

Figure 4. Geographic context of Juneqan.
Source: photo from www.monom.ir, © Bahram Bahmani 2014. Used with permission.
Three languages are spoken in Juneqan: Turkic, Bakhtiari and Persian. Each is dominant in some ways and recessive in others, presenting a picture of balanced multilingualism in the town. We use the term “balanced multilingualism” here as an extension of the term “balanced bilingualism,” including three and more languages. In the bilingualism literature, “balanced bilingualism” is defined as an equivalent level of proficiency of two languages, implying equivalent functionality of the languages.Footnote 11 On a sociolinguistic level, we understand this functionality as patterning in different domains of language use in the speech community. We have not, however, fully accounted for the psycholinguistic aspect of age of onset of language acquisition: consultants for this study do not necessarily display the same kind of bilingual language acquisition with regard to age of onset of acquisition and mode of acquisition (see Research Topic and Methodology below).
In Juneqan, speakers of Turkic refer to their language simply as “Torki” (Turkic/Turkish), but when questioned further they confirm a connection with Qashqai Turkic of Fars Province. In Juneqan, Bakhtiari is also referred to as “Lori-ye Bakhtiyāri” (Bakhtiari Lori); this label, which is not commonly used for Bakhtiari elsewhere in C&B, may reflect a view of the language situation influenced by the Turkic speakers’ origin in Fars Province, where Southern Lori (a close relative of Bakhtiari) is spoken alongside Qashqai Turkic.
As for most places in Iran, Persian is the almost exclusive language of media and formal education. Regionally, Bakhtiari is the dominant spoken language, with approximately 60 percent of the province’s population claiming it as a mother tongue.Footnote 12 In addition to its numerical importance, it influences the other language communities—CharmahaliFootnote 13 and Turkic—because of large-scale employment-driven migration of Bakhtiari speakers to cities (especially the capital, Shahr-e Kord), as well as some migration of other groups to Bakhtiari-speaking communities. Bakhtiari speakers often pass through other language communities, whether on the way to Esfahan Province in the east, or as local tourists.
Respondents to the ALI questionnaire reported that the ethnic make-up of Juneqan itself is about 85 percent Turkic and 15 percent Bakhtiari; Turkic is therefore the dominant first language (L1) in the town. Turkic and Bakhtiari are used as home languages, and Turkic is the primary language used in shared local contexts. Both exist in a diglossic relationship with Persian, the “high” varietyFootnote 14 of literature, education, administration and media. Both ethnic communities are being affected by language shift toward Persian, since practice of teaching children Persian as L1 in the home is emerging among both communities—perhaps intensified by the social mix in the town. This recent change in acquisitional patterns opens up horizons for the growing field of studies at the intersection of multilingualism and language shift, although it is not itself the focus of this paper.
Research Topic and Methodology
This paper explores the patterning of language structures in Turkic and Bakhtiari used by multilingual speakers in Juneqan. We focus on the repertoire of two individuals, one with Turkic as L1, and the other with Bakhtiari as L1. Since both speakers are also proficient in the high-variety Persian, we also pay attention to the impact of Persian on the language structures used.
Research questions
The central research issue in this study is the mechanism of contact-induced language change in Turkic and Bakhtiari of Juneqan: Is there a contact explanation for the linguistic structures used in each of these languages? However, it needs to be kept in mind that we cannot directly identify contact-induced change in progress (even at the individual level); we need to refer to indirect evidence, identifying divergent or innovative patterns in linguistic structures used, and correlating these with general language acquisition patterns.
At the descriptive level, we examine the following questions:
(i) Is there evidence for Bakhtiari influence on Turkic?
(ii) Is there evidence for Turkic influence on Bakhtiari?
(iii) Are there Persian influences on both languages?
With regard to (i) and (ii), we hypothesize that:
(i) L1 Bakhtiari interferes with L2 Turkic (i.e. L1 interference), whereby L1 Turkic may already display potentially contact-induced changes from the diachronic dimension of contact between the languages;
(ii) L1 Turkic interferes with L2 Bakhtiari (i.e. L1 interference), whereby L1 Bakhtiari may already display earlier features of convergence.
The relevant overarching questions here are therefore: What are the language acquisition profiles for bilingual speakers of each language? When structures differ systematically between L1 and L2 speakers of the same language, what are recurrent patterns?
To identify possible cases of influence, we draw on the comparative variationist framework outlined in Poplack and Levey.Footnote 15 We will compare the linguistic structures used locally by people in Juneqan with those used by people elsewhere in the larger regional (Turkic or Bakhtiari) language communities outside the present contact setting.
Finally, as a summative question related to the direction of contact-induced change: What are possible explanations for these patterns? How do the patterns of difference identified here correlate to extralinguistic observations on the relative dominance of each of the languages?Footnote 16
To address these questions, we examined questionnaire data for lexicon, phonology and morphosyntax for Turkic and Bakhtiari of Juneqan, along with additional datasets of Turkic in C&B, Bakhtiari in C&B, and Persian for comparison.
Datasets
The research questions raised here necessitated the collection of 7 datasetsFootnote 17 based on the Atlas of the Languages of Iran (ALI) linguistic data questionnaire (https://carleton.ca/iran/questionnaires):

The Turkic and Bakhtiari reference varieties are essential in detecting local effects of the language contact situation in Juneqan. These datasets are treated elsewhere more fully,Footnote 18 but we refer to them in this study in cases where linguistic structures used in Juneqan differ from those found elsewhere in the province. Persian is important both as a high variety which influences the other languages, and because it was used as the language of the questionnaire.Footnote 19 For purposes of comparison, we also make occasional reference to Standard Turkish of Turkey.
The L1 and L2 datasets, for their part, are essential as a starting point in understanding the effects of language contact. In themselves, however, they do not directly show the mechanisms of language change at work in individual speaker’s bilingual repertoires. Controlled intergenerational data with a large sample of speakers from each generation would make our investigation more fine-grained and would allow for hypothesis of apparent language change, and a longitudinal study could track and confirm these patterns. In order to begin work toward a deeper understanding of the processes at work, we intend this study as an initial investigation into whether a contact explanation is likely for language variation and change in Juneqan Turkic and Bakhtiari.
To achieve this, we have opted for a tightly controlled study setting with two speakers with reciprocal multilingual profiles. Collecting both datasets (L1 and L2) from two speakers has some clear limitations: linguistic patterns and language changes we observe in either speaker’s repertoire might be of an idiolectal nature; and consulting the same two speakers for four datasets is not conducive to identification of generalized societal variables influencing language change such as mode of L2 acquisition, migration, and use and proficiency of additional languages. On the other hand, our tightly controlled approach allows us to assess the likelihood of contact as a source for language change in these two speakers. We intend the present study, which is based on systematic changes found in the datasets of the two speakers, as a catalyst for more thorough research on contact-induced changes in this language situation, and between regional languages of Iran more generally.
Speaker profiles
For the data from Juneqan, we focus on the linguistic repertoires of two bilingual speakers, one from each community. We controlled for the following variables:
gender
age
education
age of onset of L2 acquisition
mode of L2 acquisition
number of languages acquired
language proficiencies
migration patterns.
Since mobility is high in the community and has obvious repercussions for language acquisition and use patterns, it was difficult to identify two speakers with equivalent, reciprocal profiles. The following two speakers came closest to what we were looking for.
Individual 1 (L1 Turkic, L2 Bakhtiari)
Behruz is a 32-year-old male born in Juneqan. He grew up there, with the exception of two years (11–13 years old) in a nearby town. He was away in Ahvaz, Tehran and Karaj for university education (19–25 years old), and lives in Juneqan now.
The L1 of Behruz is Turkic, and he makes ongoing use of it at home and in the community. He is multilingual in Bakhtiari and Persian, but Turkic is his dominant language. Behruz reports that for his L2 Bakhtiari, he gained exposure from the age of 8 through non-immediate relatives and other Bakhtiari-speaking community members in Juneqan, and subsequently began to speak Bakhtiari in the community. At university, he underwent a period of intense use of Bakhtiari with friends. His acquisition of Persian was started earlier, from about the age of 4, but was less intense: it took place through passive exposure to media and occasional contact with members of his extended family. We therefore designate both Bakhtiari and Persian as L2s acquired before puberty, albeit in different contexts.
Behruz has an acquisition profile for Bakhtiari which is sequential (L1 then L2) and, with regard to the critical age hypothesis,Footnote 20 occurred late but still prior to puberty. It was not as (i) early (age of onset of acquisition); (ii) intense (mode of acquisition); (iii) complete (language proficiency reached); or (iv) geographically uniform as we might have wished to find, for methodological simplicity. Yet in all these ways, in line with other possible individuals that we considered for this study and our inquiries about the language situation generally, Behruz seems representative of L2 speakers of Bakhtiari in Juneqan.
Individual 2 (L1 Bakhtiari, L2 Turkic)
Ali Akbar is a 37-year-old male, also born in Juneqan. He grew up there and lived there until the end of high school. He was away for university education in Esfahan (1 year at the age of 18) and work in Kuwait (2 years, from 18 to 20 years old), and lives in Juneqan now.
Ali Akbar’s L1 is Bakhtiari, and he makes ongoing use of it at home and in the community. He is multilingual in Turkic and Persian, but Bakhtiari is his dominant language. Ali Akbar reports that for his L2 Turkic, he gained exposure in childhood through playmates, and reached fluency in the language by age 6. His acquisition of Persian occurred simultaneously in complementary high contexts, but was weaker than his Turkic acquisition and primarily passive (through the media) until he began to attend school at the age of 7. While working in Kuwait, he learned Arabic as an additional language.
As for Behruz, the acquisition profile of Ali Akbar is sequential, and his L2 acquisition (in this case, Turkic) was complete prior to the age range considered critical for language acquisition, i.e. between age 7 and puberty.Footnote 21 Similarly, in line with other possible individuals that we considered for this study and our inquiries about the language situation generally, Ali Akbar seems representative of L2 speakers of Turkic in Juneqan with regard to age of onset of acquisition, mode of acquisition and proficiency reached.
Lexicon
Contact-induced change is often simplest to spot in the lexicon. That said, the mechanisms of change can be hard to isolate. Salient general patterns in the data here include: (1) the influence of Iranic, and perhaps Bakhtiari in particular, on Turkic lexicon; (2) little evidence for contact-induced changes from Turkic on Bakhtiari, whether for L1 or L2 Bakhtiari; and (3) varying introduction of L1 vocabulary, Persian lexicon, or stereotyped terminology into a given L2 in place of the attested corresponding forms used by L1 speakers of that language.
Iranic influence on Juneqan Turkic lexicon
There is a high level of Iranic lexical borrowing into Turkic across Iran, and this is certainly true in Juneqan: 36 of the 130 items in the L1 Turkic questionnaire are borrowed from Iranic.
However, it is often unclear which Iranic variety has loaned its structures to Turkic here. Since Persian is a common source of loanwords into languages across Iran, this is often assumed. But because Bakhtiari is relative close to Persian, both being situated in the Southwestern branch of Iranic, it is not always possible to identify the direct source of a given item. When a lexical item is essentially identical across Turkic and Bakhtiari of Juneqan as well as Persian, as in the data shown in Table 1, we cannot determine whether it has been borrowed form Persian, or Bakhtiari, or even ultimately from Persian but via Bakhtiari (which has itself been influenced by Persian).
Table 1. Juneqan Turkic vocabulary borrowed from Iranic
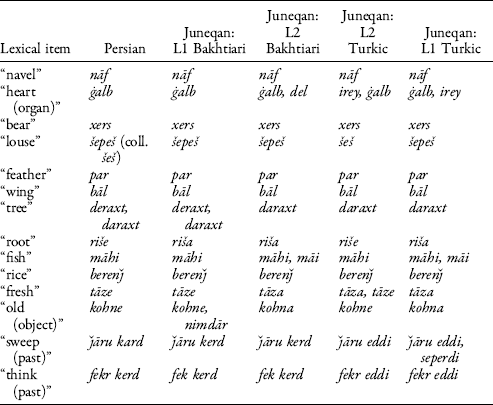
As Table 1 shows, borrowed Iranic words are occasionally used alongside an existing term (in this list: “heart,” “sweep”), but in most cases they have replaced the existing Turkic term.
Juneqan Turkic lexical borrowings attributable to Bakhtiari?
There are some cases where it appears to be clearer which Iranic language—Persian or Bakhtiari—Juneqan Turkic has borrowed from. In these instances, the examples in the data seem to point to a Bakhtiari origin in particular (Table 2). Bakhtiari provenance of a given term can be suggested either by the particular lexical item used, as in the first pair of words in the table, or by similarities in the segmental content of a cognate term, as in the remaining items.
Table 2. Juneqan Turkic vocabulary which may be borrowed from Bakhtiari
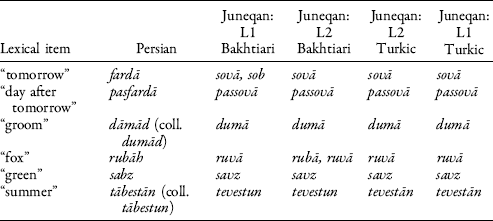
Still, questions remain. Are the shared similarities in the last four items proof of lexical borrowing into Turkic from Bakhtiari, or could they simply be showing regional diffusion of phonological structures in existing borrowings? The segment ān in the Turkic form teʋestān “summer” suggests that this item was borrowed in the past from some Iranic variety (neither Bakhtiari nor present-day spoken Persian) which has not been affected by the ān > un sound change characteristic of Bakhtiari and spoken Persian. At the same time, this word appears to have absorbed the typical Bakhtiari b > ʋ sound change—as is possible for five of the six items in Table 3.Footnote 22 Regarding loss of d in dāmād in all four Juneqan lists, there is indeed a shared regional phonological change that has taken place; see below. In sum, it is clear that Juneqan Turkic has carried out significant borrowing from Iranic, but the exact source variety is not entirely certain.
Table 3. Juneqan Turkic borrowings into Bakhtiari

Borrowing of Turkic vocabulary into Juneqan Bakhtiari
Given the numerical dominance of L1 Turkic speakers in Juneqan (see above), there is surprisingly little Turkic-origin vocabulary in the Bakhtiari lexicon. There are only two possible cases of borrowing, but both are interesting, and in both instances there is a difference between the L1 and L2 forms (Table 3).
For “sparrow,” the L1 Bakhtiari individual uses a Turkic form ġuš in his mother tongue. The L1 Turkic individual, on the other hand, uses a Persian-like form gonjišk when providing the Bakhtiari equivalent in the data. (The usual Bakhtiari form in this region, which is bengešt, does not show up in Juneqan.)
Concerning “red,” although it does not show up in this chart, which focuses on Juneqan, it is the case that all other Bakhtiari varieties in the province where we collected data use a cognate of sorx (most often sohr), whereas Turkic varieties across the province consistently use ġermez.Footnote 23 So here, when an L1 Bakhtiari speaker in a Turkic-dominated town uses the Iranic form ġermez Footnote 24 in his own language, rather than being a direct borrowing from Persian (as might be assumed without further consideration of the context) this form might actually result from borrowing via Turkic.
Asymmetries between L1 and L2 Bakhtiari lexicon
At the same time as the preceding two cases (“sparrow,” “red”) show borrowing of Turkic into Bakhtiari, they show asymmetry between forms used by L1 and L2 Bakhtiari speakers in Juneqan. A discussion of bilingualism at the level of individual speakers is necessary to account for such situations.
The fact that there are any differences at all in the vocabulary used by L1 and L2 speakers is in itself interesting. These differences are of several types, but none of them is dominant.
A first example of interference, as might be anticipated, is the case of speakers who introduce L1 forms into their L2, using terms that are not used in the L1 dataset. This lines up with the hypotheses of Lucas and van Coetsem, who have studied the effects of a more dominant language on a less dominant language in the linguistic practices of bilinguals.Footnote 25 In the data here, the L2 Turkic speaker introduces two L1 Bakhtiari forms into his Turkic usage (Table 4).
Table 4. Introduction of L1 vocabulary into L2

In the data, it is in fact more frequent that L2 speakers produce Persian equivalents in place of the words used by L1 speakers. This is shown for L2 speakers of both languages in Table 5.
Table 5. Introduction of Persian vocabulary into L2

There are a couple of possible explanations for this pattern, and they likely reinforce one another. First, similar to the role of the L1 in the data shown above (Table 4), Persian may simply be a dominant additional language and therefore naturally interfere with the linguistic production of L2. Secondly, however, it is possible that L2 speakers make recourse to Persian, as a common “high” language, because their acquisition of the L2 is incomplete and switching to an additional shared code can bridge the resulting gaps in communication.
Interestingly, the data show that even when speakers use a local form (i.e. a Turkic or Bakhtiari form which is obviously not from Persian) in their L1, and this form is shared by L1 speakers of the other language, they will still use a Persian term when they are speaking the L2. In other words, there is no lack of the existing term in their lexicon (although they might not be fully aware that it is also used by L1 speakers of the other community), and no need for recourse to Persian to bridge a communication gap. This is the case for “sparrow” in Table 4, and for “liver,” “ant” and “blue” in Table 5. Are speakers going out of their way to avoid forms they associate with their own L1, as a way of dealing with L1 interference? Or is the introduction of Persian vocabulary simply preferred, perhaps for reasons of prestige, in communication situations that bring together people from the two L1 language communities?
Finally, there are three cases where the L2 speaker uses an “expected” or “typical” Bakhtiari or Turkic form, even when the L1 speaker uses another, borrowed word in the data. (In these cases, we can confirm what “typical” forms are in other parts of the province through the linguistic data collected in the ALI research program.) It is as if the L1 Bakhtiari individual speaks an L2 Turkic which is “more Turkic” than the L1 Turkic data, or the L1 Turkic individual speaks an L2 Bakhtiari which is “more Bakhtiari” than the L1 Bakhtiari data. The three cases of this pattern are shown in Table 6.
Table 6. Introduction of Persian vocabulary into L2

Are these cases of overaccommodation or hypercorrection—in line with the data in Table 5, where speakers might be (consciously or unconsciously) trying to avoid letting L1 interfere with their L2 production, thus resulting in an artificial production? Or, conversely, might it be due to the fact that people do not notice borrowings when speaking in L1, whereas in L2 they are more conscious of the language forms they use?
Or, in this multilingual town, is there simply a high level of instability for lexical choices in both L1 and L2? That is, does this just happen to be the configuration we find for the lexical choices in the data in Table 6 and in the previous tables, as collected from these two particular speakers? Without analyzing lexical data from a larger sample of participants, it is difficult to draw broad conclusions about mechanisms for the differences between L1 and L2 vocabulary in Turkic and Bakhtiari of Juneqan.
Phonology
In contrast to what is found in the lexical data, where Iranic influences Turkic but there is little influence in the other direction, there appear to be contact-induced changes in phonology which have taken place in both directions. While we treat this topic separately in another study,Footnote 26 we will discuss the clearest examples of convergence here.
Iranic influence on Turkic phonology
One example of contact influence of Iranic on Juneqan Turkic is the absence of front-rounded vowels in the language, as in Bakhtiari (and elsewhere in Southwestern Iranic, including Persian). Historical front-rounded vowels are variously replaced by non-rounded or non-front counterparts.
This is evident in the data shown in Table 7, where we compare L1 and L2 Juneqan Turkic items with representative items from other regional Turkic varieties.Footnote 27
Table 7. Juneqan Turkic items showing loss of rounding on front vowels

Since the loss of front-rounded vowels is found with some other Turkic varieties in Iran,Footnote 28 especially among Qashqai varieties in the southwest part of the country,Footnote 29 it is not possible to determine whether this change has taken place in Juneqan in particular, or whether it has been inherited as part of a general historical pattern resulting from prior contact influence associated with Turkic varieties in the region.
Turkic influence on Bakhtiari phonology
In both Bakhtiari and Turkic of Juneqan, the word-final support vowel tends to be a, which is typical of regional Turkic,Footnote 30 rather than e, which is in turn characteristic of Bakhtiari generally, as well as most modern Persian varieties.Footnote 31 The use of word-final a is therefore likely an instance of Turkic influence on both L1 and L2 Bakhtiari of Juneqan (Table 8).
Table 8. Juneqan Bakhtiari items showing a as a word-final support vowel

Similarly, in both languages of Juneqan, the affricates č and ǰ are articulated forward from palato-alveolar position, in either alveolar [t͡s, d͡z] or alveo-palatal [t͡ɕ, d͡ʑ] place of articulation. Affricate fronting (whether phonemic or allophonic) is absent in most other Bakhtiari varieties, but it is a common feature of many Turkic varieties in Iran,Footnote 32 and it also occurs in Iranic varieties in contact with Turkic.Footnote 33 This pattern of fronted affricates is evident for the Bakhtiari items shown in Table 9.
Table 9. Juneqan Bakhtiari items showing a front articulation of č and ǰ

At one point, the L1 Turkic speaker made a comment (perhaps in response to our imperfect imitation of the sound) that a certain word was “not pronounced with a Persian ǰe, but with the d͡ze we use in Juneqan.” This indicates that speakers are conscious of this distinctive structure.
A shared local innovation
In almost all Bakhtiari varieties, there is an across-the-board pattern of softening of the stop d [d] to an approximant articulation [ð̞] in most post-vocalic positions.Footnote 34 However, in Bakhtiari of Juneqan, and in the Turkic here as well—in contrast to the other varieties of Bakhtiari and Turkic that we investigated in C&B—historical d is often deleted in this position.
This shows up sporadically in several Iranic-origin items that are shared between the three lists as seen in Table 10.
Table 10. Local loss of post-vocalic d in Bakhtiari and Turkic of Juneqan

This also takes place in L1 and L2 Bakhtiari and Turkic items that are not shared, for example:
Juneqan Bakhtiari:

Juneqan Turkic:
The direction of influence is unclear; perhaps it points in both directions. One account for the path of structural change could be as follows: (1) when speaking L2 Bakhtiari, L1 Turkic individuals fully dropped what was already a phonetically weak d [ð̞] in Bakhtiari; then, (2) L1 Bakhtiari individuals introduced this sound change back into their mother tongue.
Significance and limitations of phonological convergence
Because phonology is a relatively closed system, and many units are often already the same across languages, there is higher likelihood of convergence than for lexicon or morphosyntax (cf. below). The data show a generalized, bilateral convergence between the two languages in Juneqan, with contact-induced phonological changes taking place in both directions, and additionally some marked local changes shared by both languages.
In keeping with the idea of phonology as a limited system, the possibility of phonological mastery is high among fluent speakers, and this appears to be the case for the individuals considered in this study. In contrast to the lexical differences observed between L1 and L2 speakers of Bakhtiari and Turkic, we have not observed any systematic phonological differences (i.e. “accent”) between L1 and L2 speakers within each of the two languages. This means that the phonological data collected for this study—while still providing insight into the general patterning of language contact in the town—do not directly contribute to an understanding of contact-induced phonological changes at the level of individual bilingual speakers.
Morphosyntax
The present section sets out to summarize possible effects of language contact in the morphosyntax of Juneqan Turkic and Bakhtiari bilingual speakers with a focus on language change in Turkic. Some Juneqan Turkic structures pattern differently compared to other C&B Turkic varieties, and these can probably be attributed to contact with Bakhtiari. Both datasets considered for Juneqan Turkic—L1 and L2—form a good basis for the description of that variety since in general there appears to be a high level of similarity between them, suggesting high bilingual proficiency of the speakers. However, some differences between the two datasets are observable, hinting at patterns of instability as potential candidates for contact-induced change, which will be summarized in the following. It is to be noted, however, that these “instabilities” may simply be characteristic of Juneqan Turkic under Iranian influence (i.e. motivated by broader contact situations) and therefore not specifically due to patterns of bilingual acquisition in the speech of the individuals studied here—although they might pattern more strongly in L2 data.
In our attempt to account for the divergent patterns that we identify as candidates for language contact, eight candidate features will be presented and grouped as follows: First, we will present three general characteristics of Juneqan Turkic under Iranian influence, which do not necessarily pattern in the L2 data. Second, we will present three features showing less variability in the L2 Turkic dataset, i.e. constructions for which the L1 speaker exhibits more variability. Third, we will discuss two structures which are simplified in the L2 data.
Characteristics of Juneqan Turkic under Iranian influence
Three features of the noun phrase (NP) and sentence-level morphosyntax show general instability in the Juneqan Turkic data, suggesting an ongoing process of language change, itself likely contact-induced: (i) indefiniteness marking; (ii) definite plural marking with a postposed definiteness marker ǰāġāz; and (iii) a possessive construction with vār + possessive suffix.
(i) Instability in the marking of indefinite NPs in L1 Juneqan Turkic
Inherited Turkic marking of definiteness in noun phrases (NPs) is realized using the accusative case, a type of differential object marking (DOM).Footnote 35 In the Juneqan Turkic data, however, there seems to be variation in whether (past tense) indefinite phrases must be accusative marked (1). The accusative marker occurs in indefinite contexts in L1 data alongside the inherited zero-marking, but not in L2 data.

We analyze this feature as induced through contact with the patterning of the Bakhtiari indefinite marker -i (2a/c).Footnote 36 Conversely, in Bakhtiari L1 data the -i marking of indefinite NPs is omitted in the present tense (2b), a fact which may be due to contact with Turkic. In these cases, instability in both language’s structures, as shown by the parallel existence of two variants in L1 speech, can be reasonably attributed to language contact. The fact that this variability only occurs in L1 speech and not in the L2 data raises the question of who actually brings about language change, or what motivates the consistency in L2 data (for a possible explanation, see below).Footnote 37

(ii) Instability in L2 Juneqan Turkic definite plurals: postposed definiteness marker ǰāġāz
Juneqan Turkic displays an interesting feature which is found in only some Turkic varieties of C&B, namely, a postposed definiteness marker ǰāġāz.Footnote 38 We assume a reanalysis of the Turkic diminutive suffix -(I)cAğIz as the etymological source for ǰāġāz. The form is used optionally in emphatic and explicit definiteness contexts, and has been elicited from speakers in translations of stimuli containing the colloquial Persian definite suffix -e. This feature has so far only been described with singular nouns,Footnote 39 but in the data collected across C&B it also occurs with plural nouns in two locations: Juneqan and Margh Malek.Footnote 40 The Juneqan Turkic L2 data reveal interesting variation in definite plurals with ǰāġāz which does not occur in the L1 Turkic dataset for plural: The L2 Turkic speaker provides in plurals alongside the inherited Turkic definiteness marking with the accusative in -i (3a/d) a rare plural form of ǰāġāz (3b/c) which shows instability in the placement of the plural marker. The plural marker is attached either to the oblique definiteness marker ǰāġāz (3b) or to the noun (3c).




The variability of the plural marking of the ǰāġāz form may mirror a general instability in the feature. It might be even attributable to a contact explanation based on the Bakhtiari model of noun + plural + definiteness marker (4); or a combination of internal language change supported by the influence of Iranic. This is, however, at this point rather speculative since we so far lack a comprehensive description of this feature in Turkic varieties of Iran.
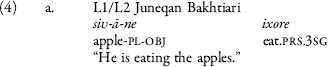

The appearance of variation in the plural marking of the ǰāġāz form in L2 speech and not in L1 data could be a result of hypercorrection by the L2 speaker in order to highlight the “Turkic-ness” of his speech. Additional support for hypercorrection by L2 speakers is found in the L2 Turkic speaker’s clear and consistent use of nasalized forms for second-person possessive endings—a typical feature in the wider Turkic family—whereas this feature is less salient in the speech of the L1 Turkic speaker. It may account for a generalized lack of variability in L2 data as compared to L1 speech, and perhaps even explain the appearance of conservative forms in the L2, where the L1 dataset shows contact influences like the indefiniteness marking of object NPs. Similar examples of possible hypercorrection by L2 speakers are also found in the analysis of lexicon. Another aspect of this hypercorrection might be the use of more emphatic constructions in L2 data: the use of the ǰāġāz definite plural expresses a more emphatic definite meaning than is present in the Persian translation prompt (dār-e sib-ā-ro mi-xor-e “he is eating the apples”; sib-ā-ro xord “he ate the apples”). A further example of the L2 speaker’s choice of an emphatic form is that he provides a demonstrative bu together with the third-person pronoun u when asked for an equivalent to the Persian personal pronoun.
(iii) Possessive construction (existential noun ʋār + possessive)
Turkic varieties in Iran exhibit a possessive construction formed using an existential noun ʋār “existent” with a possessive suffix.Footnote 42 This form is also present in Juneqan Turkic L1 and L2 data (5a). It has a possible parallel in the Bakhtiari L1 construction in (5b). For both L1 and L2 Bakhtiari, the structure in (5c) lacks the indefinite marker -i. This structure is also attested in a Bakhtiari variety outside the Turkic contact zone (Bakhtiari of Shalamzar), all C&B varieties of Charmahali and similarly also in some varieties of Persian.Footnote 43 This makes a direct contact explanation from Turkic less likely, although the feature does mirror the Turkic structure in (5a). In any case, the coexistence of two competing structures in Bakhtiari points at an instability in the feature and possible ongoing language change.

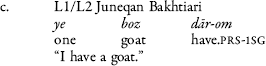
Reduced variability in L2 Juneqan Turkic
As a general pattern, the L2 Turkic dataset exhibits less variability than the L1 data. The following examples will be discussed here: (iv) nominal genitives; (v) object pronouns; and (vi) second person plural imperatives.
(iv) Variability in L1 nominal genitives
In Turkic of Iran, absence of genitive marking especially on proper nouns is a widespread feature,Footnote 44 although this genitive marking is obligatory in Turkey-Turkish (6b).Footnote 45 The omission of the genitive is also true of the L1 and L2 Juneqan Turkic datasets (6a). In this case, we analyze it as a case of pattern borrowingFootnote 46 from Bakhtiari where only the possessee is marked (6c): the third-person possessive marker on the possessee mirrors the Bakhtiari ezāfe (an associative construction suffix, widespread in Iranic, marked on the possessee) whereby the genitive marking applied in Turkey-Turkish is omitted.

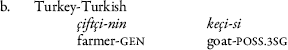
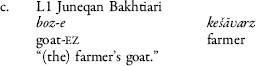
As with bare noun genitives, there is a tendency in proper noun genitive NPs to omit the genitive marking on the proper noun possessor. Our data show that genitive marking on the proper noun is variable in the L1 dataset (7a; note the nasalized pronunciation of the genitive, which corresponds to the -In suffix in Standard Turkish) and is absent in the L2 data (7b). We analyze the tendency to omit genitive marking on the proper noun as induced by contact with Iranic. As is the case with bare noun genitives, proper noun genitives in Bakhtiari only mark the possessee (with ezāfe) (7c).
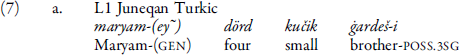

(v) Additional oblique pronominal stem bela-
Alongside inherited Turkic object pronouns, Turkic varieties of C&B exhibit an oblique pronominal stem based on bela + possessive suffix.Footnote 47 Both strategies are reflected in the L1 Turkic dataset (8a/b), although the bela- form is preferred there. In the L2 data, however, only the (more marked) bela-forms are provided (8a). This is in line with our assessment that the L2 speaker prefers “typical” features as a way of highlighting the differences between the two languages in his repertoire.

(vi) Second-person plural imperatives
Two alternative imperative forms for plural are presented in the L1 dataset, namely ge-ez and giy-eỹ (“go (pl)!”), whereas a shorter form of the second L1 strategy is presented by the L2 speaker, geỹ (“go (pl)!”).
Periphrastic/simplified structures in L2 speech
In some cases, the L2 speaker offers less complex forms which do not coincide with the L1 data. These features include (vii) a lack of grammatical superlatives in the L2 Turkic data; and (viii) the lack of a possessive construction in this same data.
(vii) Lack of superlatives in L2 Juneqan Turkic
Superlative constructions appear to be rare in Juneqan Turkic as well as in Bakhtiari. As evident in the data, they are mostly circumscribed by a periphrastic construction, although the L1 speaker reports the use of a reduplicated form of the Turkic comparative suffix -rāg, -yerarāg,Footnote 48 by some elderly speakers. Similar reduplicated forms of the Iranic comparative suffix -tar, i.e. -tartar, appear as superlatives in the speech of elderly Bakhtiari people. This is part of a general tendency towards language change in Juneqan.
The L1 Turkic dataset exhibits a periphrastic superlative construction of the kind “of all X the Y-er” (9a). The L2 speaker, in contrast, seems not to have a dedicated strategy to express superlatives (9b). The same strategy applied by the L1 Turkish speaker occurs in L2 Bakhtiari (10a), which might be a case of L1 interference. The L1 Bakhtiari speaker uses an analytic form with the Persian superlative suffix -tarin (10b).


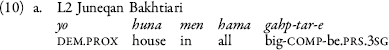

(viii) Lack of ʋār + possessive progressives in L2 Juneqan Turkic
The L1 dataset presents a progressive form which uses the existential copula ʋār + possessive suffix together with the fully inflected verb (see Table 11), which resembles the “have” construction outlined above, and which occurs in some Turkic varieties in Iran.Footnote 49 The L1 speaker presents this form as optional and otherwise offers only the present tense. In L2 data, only the default present tense form is offered, gey-ir-am “I go/am going.”
Table 11. Present and past continuous paradigm for the verb “to go” in L1 Juneqan Turkic

Notes:
a These two optional extended forms were not offered for the verb “to go,” which is the first verb in the questionnaire, but they were used for all other verbs.
b Regarding the L1 data, the L1 Turkic speaker observes that younger speakers insert a y glide between the two vowels for the sake of phonological simplicity.
Conclusion and Reflections
The present study has set out to investigate the effects of community multilingualism in Juneqan on Turkic and Bakhtiari. Although not symmetrical, with Turkish being the dominant language in the town and Bakhtiari dominating regionally (both further framed by Persian dominance at the national level), the four datasets support the view of a balanced bilingualism in Turkic and Bakhtiari in the community.
The purpose of this study was to look at mechanisms and patterning of contact-induced change as reflected in the language forms used by two bilingual individuals, one from each community—an approach which has not been applied so far in research on language contact between regional languages of Iran.
In the following discussion, the main findings from the lexicon, phonology and morphosyntax sections will be briefly summarized before the overall conclusion is presented.
Lexicon
We identified three salient patterns in the lexical data: (1) a general influence of Iranic, and Bakhtiari in particular, on the Turkic lexicon, although the exact source and mechanism of change was often difficult to isolate; (2) little evidence for contact-induced change from Turkic on Bakhtiari—in the two occurring cases, the Turkic word is introduced by the L1 speaker rather than the L2 speaker, a conservatism which was also identified in the L2 speakers’ morphosyntax; (3) some differences between datasets that were likely induced by the impact of bilingualism on the L2 data. We identified the following two patterns: (a) occurrences of L1 interference in L2 data, especially the introduction of Bakhtiari lexical items into L2 Turkic, and the use of Persian lexicon in the L2 of both languages. We have hypothesized that this second phenomenon is due to the fact that both Persian and the respective other regional language are competing L2s, and that Persian is shared as the prestige variety by both speakers; (b) the L2 speaker’s use of typical Turkic/Bakhtiari forms which are absent in the L1 data; a strategy of “hypercorrection” which may be applied to maintain a distinction between the two languages. In sum, the lexicon of Juneqan bilinguals shows a certain level of instability.
Phonology
In the domain of phonology, we detected contact-induced changes in both directions, pointing at phonological convergence between Turkic and Bakhtiari specific to Juneqan: (1) influence from Iranic on Turkic, such as the absence of front-rounded vowels; (2) influence from Turkic on Bakhtiari, such as the occurrence of a word-final support vowel in a instead of e, and fronting of the affricates č and ǰ; (3) and a shared innovation: deletion of d in most post-vocalic positions.
L1/L2 differences in phonology are not significant since both speakers appear to master the pronunciation of their L2 fully. The main differences were cases in which speakers maintain Persian pronunciation in borrowed Persian words—and these were ambivalent.
Morphosyntax
Here, we focused on morphosyntactic data from the L1 and L2 Juneqan Turkic datasets. As pointed out for phonology, the Turkic L1 and L2 morphosyntax data show in general a high level of congruence, affirming a high level of proficiency for both speakers. However, as a rule, the L2 data exhibit less variation than the L1 data. This may point to a bilingualism-related explanation for morphosyntactic differences between the speakers. We did not observe any corresponding patterns in the L1 and L2 Bakhtiari morphosyntactic data, however.
In order to account for differences between the L1 and L2 Turkic datasets, we considered any variation as a potentially unstable pattern and as such a candidate for language change. However, given the fact that some of the features discussed here are described only cursorily, we recognize that existing variants may simply express variation in Iran Turkic varieties which are at most candidates of language-internal change. This may be the case for definite plurals with ǰāġāz.
Other features show traces of contact influence which are likely to have happened at an earlier stage, since they are mostly present in L1 speech. These include indefiniteness marking of NPs and possessive constructions with ʋār + possessive. Variation in L1 proper noun genitives, a contact-related feature which is not present in the L2 data, might mirror an ongoing language change.
Finally, some features might be presently induced by bilingualism at the level of individuals, namely those where the L2 speaker shows a lack of a whole category; this is the case for the lack of the ʋār + possessive progressive in L2 data. The lack of superlatives, although apparent in the L2 data, may also point at an ongoing language change which is not necessarily contact-induced, although it is reminiscent of restrictions in the usage of superlatives in Bakhtiari generally.
We observe, especially in light of the limited data, and the early stages of our investigation, that the origin of variation is often difficult to isolate definitively, and that in many cases multiple factors may have played a role.
In addition to structural explanations of contact-induced change among bilinguals, we hypothesized that the L2 Turkic speaker may prefer “hypercorrect” marked variants—that is, features which he perceives as typically Turkic—in order to maintain or highlight the distinctiveness between the languages. Evidence in support of this hypothesis is the use of conservative forms like lack of indefinite marking displayed in L1 data and definite plurals with ǰāġāz, as well as the general lack of variability in L2 data such as in preference of the pronominal stem bela- in the L2 data.
Overall conclusion
In order to investigate our research question—Is there a contact explanation for the linguistic structures in L2 Turkic and Bakhtiari?—we have combined the bilingualism approach to contact-induced language change outlined by Lucas,Footnote 50 among others, and the comparative variationist framework,Footnote 51 comparing four datasets from two L1 and L2 Turkic and Bakhtiari bilinguals in Juneqan, with additional datasets from Turkic and Bakhtiari elsewhere in C&B, as well as with Persian.
Wherever structural differences between L1 and L2 datasets of the same language occurred, we identified recurrent patterns in order to answer the following questions:
(i) Is there evidence for influence of Bakhtiari on Turkic?
(ii) Is there evidence for influence of Turkic on Bakhtiari?
(iii) Are there Persian influences on both regional languages?
With regard to (i) and (ii), we have hypothesized that L1 interference occurs in L2 data, and that these patterns may also indicate earlier contact-induced changes.
In order to provide an answer to our research question with regard to how changes can be explained, we have tried to identify directions of change, and to correlate bilingualism effects and extralinguistic factors with these changes.
Based on the evidence provided in this paper, we answer our research question positively: there is evidence for a contact explanation in the language structures found in the Juneqan Turkic and Bakhtiari datasets. A substantial number of linguistic structures in Juneqan Turkic and Bakhtiari pattern differently from other C&B varieties, and we argue that this is most reasonably attributed to contact, though further research is required to establish this conclusion. More generally, several features point to a certain instability in Juneqan bilingual data, something which reflects a tendency of language change.
With regard to the direction of contact-induced change, we have found mutual influences in the various domains. Our findings can be summarized as follows:
(i) Influence of Bakhtiari on Turkic is well documented in the lexicon; in phonology, it shows up, for example, in the absence of front-rounded vowels in Turkic; and in morphosyntax, for example, in definite plurals with ǰāġāz, indefiniteness marking, possessive constructions with vār + possessive, and proper noun genitives. In line with our hypothesis, L1 interference occurs in the lexicon but is almost absent in phonology and morphosyntax. Prior contact-induced changes are visible in both L1 and L2 data in the domains mentioned above.
(ii) Influence of Turkic on Bakhtiari is much less prominent; while it is recurrently attested in phonology, influences in the lexicon are few and occur mostly in L1 data. Some influence is also discernable in the morphosyntax, e.g. in L1 Bakhtiari indefiniteness marking, although Bakhtiari morphosyntax has not been the main point of investigation here. Interestingly, most changes occur in L1 speech and can therefore not be explained by L1 interference.
(iii) Influence of Persian on both regional languages is clearest in the lexicon although, especially in the case of Turkic, it is not always easy to determine which Iranic language has exerted the influence.
With regard to the effects of bilingualism, earlier contact-induced changes, language-internal change and extralinguistic factors, Table 12 summarizes recurrent patterns that we encounter in the data, together with possible explanations.
Table 12. Recurrent patterns and possible explanations of language change in Juneqan Bakhtiari/Turkic bilinguals

Note:
a Cf. Lucas, “Contact-Induced Grammatical Change,” and others.
In sum, there appears to be ambivalence in (a) the differences in L1 versus L2 structures in the same language, and also (b) in the comparisons of the tendencies shown by each speaker across the two languages: there are some recurrent patterns but there is no single overarching pattern that clearly indicates a direction of contact-induced change. This ambivalence underlines a kind of flexibility (or perhaps even instability) inherent in the actual language situation (as shown by ambivalence in the forms used), but also in the usages and mental representations of the speakers themselves, within this language situation.
Even though we have observed only a modest and ambivalent repertoire of patterns, this snapshot of two bilingual individuals brings us closer to understanding mechanisms of contact-induced language change in one community where two minority languages exist in a kind of equilibrium—though disrupted now by Persian as an emerging L1 in the community.
Finally, a critical note is in order. At the present stage of research and in the light of the complexity of the topic, we highlighted the provisional nature of our findings, and stress that they are, at this point, observations based on limited evidence. First, we have only investigated bilingual data without a monolingual baseline for comparison from the same community (although data from other speech communities in C&B were considered). Further, testing of more than two respondents is necessary to rule out ideolectal effects and to see if the patterns we observe for these two individuals (especially L1 versus L2 differences in the same language) are representative of other speakers with equivalent language profiles; or whether the variability we found is characteristic of the language community as a whole. Subsequent studies with a higher number of respondents (reaching the threshold for significance in a quantitative study) would allow for a more fine-grained identification of the relevant variables in contact-induced language change. This process could then be extended and related to a survey of language competency and use across communities and generations, to see how language structures relate to language use patterns. For example, the C&B communities of Sulegan and Boldaji have equivalent proportions of Turkic and Bakhtiari speakers; comparison of bilingual data from these locations may help us clarify observations made in this study. Finally, the research methodology should be extended to collection of naturalistic data, such as oral narratives, in order to rule out translation bias.
Having said this, the present study is the first of its kind in the field of Iranian linguistics. It provides an analysis of mutual contact-induced change in two regional languages of Iran—one Iranic and one Turkic—and explores the role of balanced individual and community bilingualism in the structures that result. These findings, while preliminary, provide a path for further research and testing on language variation and change in Juneqan Turkic and Bakhtiari.
We would like to express our sincere appreciation to the two consultants, Behruz and Ali Akbar, who shared their language with us and worked with us patiently, over many hours and on many occasions, to enable us to complete this study. We also wish to thank Mr. Bahram Bahmani for generously allowing us to use his photo of Juneqan in its geographic context (Figure 4).
ORCID
Erik Anonby https://orcid.org/0000-0002-8719-4922
Laurentia Schreiber https://orcid.org/0000-0002-1260-6128
Appendix. Abbreviations


















 Open access
Open access