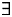1. Introduction
This article addresses the problem of the evolution from demonstrative to definite determiners using quantitative data from the diachrony of French. This development is one of the most robustly attested instances of grammaticalization and is part of what Greenberg (Reference Greenberg1978) labels the definiteness cycle. The cycle consists of a series of shifts in the meaning and syntactic distribution of a morpheme. Its different stages are listed in (1).Footnote 1
(1)
a. Stage I: demonstrative determiner
b. Stage II: definite determiner
c. Stage III: non-generic marker
d. Stage VI: noun class marker
The shift from Stage I to Stage II has been hypothesized for a number of European languages including, but not limited to, French (De Mulder and Carlier Reference De Mulder, Carlier, Bernd and Heiko2011), English (Van Gelderen Reference Van Gelderen2007, Crisma Reference Crisma, Sleeman and Perridon2011, Keenan Reference Keenan2011), Spanish (Roca Reference Roca2009), Hungarian (Egedi Reference Egedi and Kiss2014), Swedish (Skrzypek Reference Skrzypek2012).
While the semantic and pragmatic properties of the endpoints of the shift, viz. bona fide demonstrative determiners and bona fide definite determiners, are relatively well understood, the change itself is not. The biggest problem, acknowledged in all of the aforementioned works, is the seeming inconsistency of the patterning of the determiner forms in question. That is, during the transition period, such determiners seem to concomitantly manifest properties typical for demonstratives and those typical for definite determiners. As an illustration of the issue, consider the following dataset from Old French, for which the evolutionary start and end points are the Late Latin distal demonstrative ille, as in (2), and Modern French definite determiners le/la/les (l-forms), respectively. Between these two points, for several centuries we find a paradigm of l-forms exhibiting what seems to be a mixed distribution.Footnote 2
(2) Lucca castrum dirig-unt, atque funditus
Loches fort.acc.n.sg go.towards-PRS.3PL and at.the.bottom
subvert-unt, custod-es ill-ius castr-i
destroy-prs.3pl guardian-acc.pl that-gen.sg fort-gen.sg
cap-iunt
capture-prs.3pl
‘They go to the fort of Loches, they raze it to the ground and take prisoner the guardians of that fort.’
(Fredegarius, Continuations 25, cited from De Mulder and Carlier (Reference De Mulder, Carlier, Bernd and Heiko2011))
In (3a)–(3b) we observe noun phrases without a determiner in contexts where definite determiners are strictly required in Modern French, (4a)–(4b).
(3)
a. Por amor Deu e pur mun cher ami…
for love God and for my dear friend
‘For the love of God and for my dear friend…’ (10XX-ALEXIS-V,45.422)
b. Soleill n’ i luist
sun not there shines
‘The sun does not shine there.’ (1100-ROLAND-V,78.951)
(4)
a. Pour l’/*Ø/*un amour de Dieu…
for the/Ø/a love of God
‘For the love of God’ Modern french
b. Le/*Ø/*un soleil n’ y brille pas.
the/Ø/a sun not there shines neg
‘The sun does not shine there.’ Modern french
The absence of the l-forms in such contexts is not surprising and is even expected on the hypothesis that in (Early) Old French the l-forms had demonstrative semantics, which constrains their use to configurations where reference is made to an entity present in the extralinguistic context or mentioned in the (previous) linguistic context (5)–(6), as well as to configurations involving first-mention NPs with a relative clause (7).
(5) Le jur passerent Franceis a grant dulur.
l-form day passed French at great pain
‘That day the French passed (the mountains) with difficulty.’
(1100-ROLAND-V,66.778)
(6) Dunc li acatet filie d’ un noble Franc. Fud la pulcela nethe de
So him bought daughter of a noble Frank was l-form girl born of
halt parentét.
high lineage
‘So (he) bought for him a marriage to a daughter of a noble Frank. That girl was of noble birth.’
(10XX-ALEXIS-PENN-V,8.87)
(7) Anna nomnavent le judeu a cui Jhesus furet menez
Annas they.called l-form Jew to whom Jesus was brought
‘The Jew to whom Jesus was brought was called Annas.’
(1000-PASSION-BFM-P,106.120)
However, this hypothesis is readily falsified by the following example, where the use of the l-forms extends beyond the demonstrative contexts, as the ungrammaticality of the Modern French counterpart with a c-series demonstrative in (8) shows.
(8) la plus noble fud claméé Anna.
l-form most noble was named Anna
‘The most noble was named Anna.’ (1150-QUATRELIVRE-PENN-P,3.11)
(9) La/*cette plus noble fut appelée Anne.
the/*this most noble was named Anne
‘The/*this most noble was named Anne.’ Modern French
The ungrammaticality of the cette variant in (9) illustrates an important property of demonstratives which we call anti-uniqueness, namely, the requirement that the denotation of the noun phrase not be a singleton (e.g., Corblin (Reference Corblin1987) for French demonstratives, Wiltschko (Reference Wiltschko2012) for Austro-Bavarian strong determiners, Wolter (Reference Wolter2006), Simonenko (Reference Simonenko2014) for English demonstratives). The compatibility of the l-forms with uniquely denoting noun phrases makes it impossible to maintain the hypothesis that they had a demonstrative-like semantics across the board. In particular, it makes the proposals in Rickard (Reference Rickard1989) and Fournier (Reference Fournier2002) that the l-forms kept demonstrative semantics up until the end of the thirteenth century untenable. The l-forms also do not lend themselves to an analysis in terms of a consistent definite determiner semantics, since this would fail to account for the fact that they are missing in (3a)–(3b).
This issue is closely related to the problem of capturing the conditions on the use of bare nouns in Old French (Carlier and Goyens Reference Carlier and Goyens1998, Mathieu Reference Mathieu, Ghomeshi, Paul and Wiltschko2009, Carlier and De Mulder Reference Carlier, De Mulder, Cuykens, Davidse and Van de Lanotte2010, Déchaine et al. Reference Déchaine, Dufresne and Tremblay2018). Carlier and Goyens (Reference Carlier and Goyens1998) have shown that bare nouns are attested in a variety of uses, both with generic and existential interpretations, whether the NP has a definite or indefinite interpretation, with singular as well as plural count nouns, and with mass and abstract nouns. The diversity of contexts in which bare nouns are encountered seems to suggest that they correspond to a default option, whereas the use of a determiner is associated with more specific pragmatic conditions.
The mixed distribution problem, i.e., a distribution inconsistent with either a stable demonstrative or a stable definite interpretation, is not idiosyncratic to French. The same issue has been raised for a number of other European languages. Consider, for instance, the following example from Old Norse where the form hinn, originating as a distal demonstrative, is used with a uniquely denoting noun phrase.
(10) ok hinn siðasta vetr er hann var í Nóregi
and hinn last winter that he was in Norway
‘and the last winter that he was in Norway’
Old Norse Bjarni's Voyage 41.8, Gordon (1956), cited from Van Gelderen (Reference Van Gelderen2007:291), ex. 19a
At the same time, Old Norse allows bare nouns in contexts requiring a definite determiner in Modern North Germanic languages. Van Gelderen (Reference Van Gelderen2007:291) notes that “Gordon (1956) translates the demonstrative as both ‘the’ and ‘that’, indicating that the demonstrative may already be quite grammaticalized as a definiteness marker.” The notion of grammaticalization which would allow us to order the data on the temporal scale according to lower or higher degrees of this process is not explicitly discussed here, however. Exactly the same issue arises in Old Hungarian (Egedi Reference Egedi and Kiss2014:63). Finally, Crisma (Reference Crisma, Sleeman and Perridon2011:176) notes that in Old English “there is one morpheme – se – that sometimes corresponds to the demonstrative that, sometimes to the definite article the, while often it is impossible to decide between the two.”
In addition to the mixed distribution problem, there is the problem of the temporally unstable distribution of the l-forms. Namely, over time the frequency of bare nouns goes down, while the frequency of NPs with determiners, in particular with the l-forms, goes up. We offer quantitative illustrations of these tendencies in the next section.
This article proposes a solution both to the mixed distribution problem and to the change in frequency issue by conceptualizing the distribution of the l-forms and the evolution of this distribution over time by means of the grammar competition model of Kroch (Reference Kroch1989). In particular, we will analyse quantitative data from a corpus of Old French under the assumption that the observed l-forms are a mix of determiners with the structure/semantics of anaphoric demonstratives (or strong definites in the sense of Schwarz (Reference Schwarz2009)) and of determiners with a definite semantics of the Fregean/Russellian type (or weak definites in the sense of Schwarz (Reference Schwarz2009)). Since the two types, by assumption, are associated to one and the same form, the only way to test this hypothesis is to check the quantitative predictions it makes concerning the use of the l-forms in various contexts. In particular, conceiving the change as a gradual increase in the probability of the grammar ascribing a weak definite structure/semantics to the l-forms predicts that over time they occur more frequently in contexts incompatible with anaphoric demonstratives.
Before laying out the grammar-competition model, we present in section 2 a morphosyntactic model which follows up on the results of Déchaine et al. (Reference Déchaine, Dufresne and Tremblay2018), who carried out the first, to our knowledge, properly variationist study of bare nouns in Old French. In section 3 we outline our assumptions concerning the grammar competition model as applied to the evolution of determiner semantics, and offer some speculations concerning the environments where the reanalysis could have taken place. The predictions of this model are spelled out in section 4. Section 5 is dedicated to discussing the results in view of the predictions. Section 6 concludes.
2. A Morpho-Syntactic Model
While Latin had no specific paradigm of nominal determiners, French developed a complete paradigm of determiners. This rise of determiners has often been linked to a progressive erosion of grammatical inflection: whereas the rich suffixal morphology in Latin expressed grammatical oppositions such as case, number and gender, these same oppositions gradually came to be marked by determiners as the suffixal morphology eroded.
For instance, it has often been argued that, in the context of the erosion of case suffixes, l-forms are increasingly present in order to preserve the distinction between subject and oblique case. This hypothesis is at first sight corroborated by the empirical fact that case marking lasts longer on determiners than on nouns or adjectives in Old French (Schøsler Reference Schøsler, Carlier and Guillot-Barbance2018). However, this system of case marking on determiners is already defective in Old French, since it only appears on determiners agreeing with masculine nouns, as feminine l-forms no longer exhibit this opposition. In the same vein, it has been suggested that the development of determiners allowed the preservation of the expression of number and gender.
2.1 Déchaine et al. (Reference Déchaine, Dufresne and Tremblay2018)
The study of Déchaine et al. (Reference Déchaine, Dufresne and Tremblay2018) investigates the role of determiners in preserving morphological oppositions by looking at bare noun distribution in Le voyage de saint Brendan (ca. 1120 AD) and in the Lais de Marie de France (ca. 1180). Analysing the distribution of the determiner in terms of morphosyntactic factors, they predict, for instance, that the presence of the l-form is favoured in subject position because it disambiguates singular and plural masculine nouns with -s, as Table 1 shows.
Table 1: Inflection of a masculine noun ‘father’ in Old French

In the same vein, they predict that l-forms will be less frequently omitted with masculine than with feminine nouns, as the latter convey unambiguous number marking, as Table 2 illustrates.
Table 2: Inflection of a feminine noun ‘door’ in Old French

They compare the results of a logistic regression analysis for the two texts treating the presence/absence of an overt determiner as a binary random variable, with predicativity, grammatical function (subject vs. object), semantic class (count, mass, abstract), definiteness, number, gender, and word order as predictor variables.
Déchaine et al. (Reference Déchaine, Dufresne and Tremblay2018) report that subjecthood, definiteness, singular number, and countability have a significant positive effect on the appearance of a determiner across the two texts, while gender is a significant factor in Le voyage de saint Brendan but not in the Lais de Marie de France. The fact that definiteness did not come out as a categorical predictor (that is, knowing whether a noun phrase has a definite or indefinite interpretation does not allow us to be certain about the (non)use of an l-form) is an example of the mixed distribution problem we described above: unlike in Modern French, an utterance that satisfies the conditions of use of a Fregean definite is not guaranteed to have an l-form in Old French.
Between Le voyage de saint Brendan and the Lais de Marie de France, Déchaine et al. (Reference Déchaine, Dufresne and Tremblay2018) observe a decrease of bare count nouns, but they do not offer an account of this observation. Conversely, they report an increase of bare mass and abstract nouns. Making the assumption that l-forms corresponded to two lexical entries, viz. a semantically vacuous entry (expletive) used with non-count nouns, and a true definite used with count nouns, Déchaine et al. (Reference Déchaine, Dufresne and Tremblay2018) argue that the masculine expletive entry dropped out of use by the time the Lais de Marie de France was composed, thus accounting for the increase in bare mass and abstract NPs in this text.
2.2 Follow-up study
Using 44 texts from the corpora of Martineau et al. (Reference Martineau2010) and Kroch and Santorini (Reference Kroch and Santorini2010), we follow up on the results of this study.
2.2.1 Methodology
In this study, we used two morphologically and syntactically annotated corpora of Old French: MCVF (Martineau et al. Reference Martineau2010) and the Penn Supplement to MCVF (Kroch and Santorini Reference Kroch and Santorini2010). The search software CorpusSearch (Randall Reference Randall2010) contains a feature that can code clauses for any number of parameters present either directly in the annotation scheme or in additional lists composed by the user.Footnote 3 For instance, these corpora are not annotated for the noun classes of interest to us (mass, abstract, individual, relational), therefore we manually annotated a sample of approximately 15500 noun forms and fed these classified lists into our search queries.Footnote 4 In Table 3 we give examples of the four noun classes.
Table 3: Noun classes

In order to follow up on the results of Déchaine et al. (Reference Déchaine, Dufresne and Tremblay2018), we used a logistic regression model similar to theirs, and discuss here the performance of this model.
We coded subject and direct object NPs containing common nouns in the corpus for the variables given in Table 4. These variables are used as predictors of the (non-)appearance of a determiner. We limited the sample to subject and direct object NPs, excluding NPs with quantifiers incompatible with other determiners, as well as NPs with conventional address nouns such as monseigneur (‘sir’), which, again, exclude determiners.Footnote 5 We coded an NP with a yes value for the variable DETERMINER if it contained one of the following: an l-form, a demonstrative of the c-paradigm (e.g., cist, cil), an indefinite determiner (e.g., un(s), une(s)), a partitive determiner (e.g., de, possibly followed by or contracted with li, le, la, les), or a prenominal possessive.Footnote 6 The rest of the NPs were coded with no for the variable DETERMINER. This yielded a total of 73873 data points.
Table 4: Variables coded for in our study

2.2.2 Model
The model represented in (11) includes all the predictor variables from Table 4 except noun class. The reason we first created a model excluding noun class as a predictor is that, as indicated above, we classified only a subset of the nouns occurring in the corpus. Introducing this variable would necessitate restricting our model to that subset and therefore significantly reducing the dataset to which we fit our model. We will return to the noun classes towards the end of this section. Predictor variables in this model do not include gender, which was found not to be a significant factor by Déchaine et al. (Reference Déchaine, Dufresne and Tremblay2018). We also exclude word order as a predictor, since this factor was not significant in either of the two texts. As for definiteness, although it is plausible that this factor would enhance the accuracy of the model, it will not be taken into account at this point since it is not a morphosyntactic but rather a pragmatico-semantic feature. It will be discussed in detail in section 3. We also included two additional morphosyntactic variables, namely the presence of a relative clause or of an adnominal PP modifying the noun in question.
(11) P(Determiner = yes|Date = d, Number = n, Function = f, Relative = r, Complement = c)
 $\displaystyle{\;={{e^{\alpha + \beta _1\ast Date + \beta _2\ast Number + \beta _3\ast Function + \beta _4\ast Relative + \beta _5\ast AdnominalPP}} \over {1 + e^{\alpha + \beta _1\ast Date + \beta _2\ast Number + \beta _3\ast Function + \beta _4\ast Relative + \beta _5\ast AdnominalPP}}}}$
$\displaystyle{\;={{e^{\alpha + \beta _1\ast Date + \beta _2\ast Number + \beta _3\ast Function + \beta _4\ast Relative + \beta _5\ast AdnominalPP}} \over {1 + e^{\alpha + \beta _1\ast Date + \beta _2\ast Number + \beta _3\ast Function + \beta _4\ast Relative + \beta _5\ast AdnominalPP}}}}$
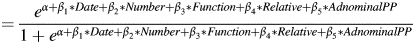
2.2.3 Results
Table 5 gives estimates of the parameters of this model.
Table 5: Parameter estimates of the morphosyntactic model with the following reference levels for categorical predictor variables: Number = pl, Function = obj, Relative = no, Adnominal PP = no

We observe that estimates of coefficients (in the second column of Table 5) associated with all predictor variables are significantly different from zero (p < 2 × 10−16). The size of a coefficient for a given predictor variable (e.g., FUNCTION) indicates how strongly the choice of an indicated value (e.g., subject) as opposed to the reference value (chosen arbitrarily, e.g., object) affects the dependent variable (i.e., the probability of determiner use). In accordance with the results of Déchaine et al. (Reference Déchaine, Dufresne and Tremblay2018), subjecthood turns out to be a highly significant factor. If we look at number, the coefficient estimates seem to indicate at first sight that plural, rather than singular, favours determiner use. However, when we limit our sample to nouns for which number is a relevant feature, viz. count nouns (sample size is 32389), it turns out that number is not a significant factor in determiner use (p = 0.182), which contrasts with the findings of Déchaine et al. (Reference Déchaine, Dufresne and Tremblay2018). We infer that the effect of number in Table 5 may be an epiphenomenon caused by annotation conventions: non-count nouns, which, as we will see later, disfavour determiner use, are coded as singular in the corpus. In contrast, the presence of a relative clause or an adnominal PP are factors which significantly favour the occurrence of a determiner. Additionally, the date of the composition of the manuscript is relevant insofar as determiners become significantly more likely to be used as time progresses. This positive effect of time is consistent with the conclusion of Déchaine et al. (Reference Déchaine, Dufresne and Tremblay2018) that their later text (Lais de Marie de France, ca. 1180) disfavours determiner omission as compared to their earlier text (Le voyage de saint Brendan, ca. 1120).
The accuracy of this model, defined as the proportion of the correctly classified cases with respect to all classified cases, is 0.742. As is customary, we consider our model's prediction to be correct if the predicted probability for the actual positive observation (the presence of a determiner in our case) is greater than 0.5. The confusion matrix for this model is given in Table 6. We see that the model is not particularly good at predicting bare nouns.
Table 6: Confusion matrix for the morphosyntactic model

To have a baseline for evaluating the performance of this model, we compared it to a null model (P(Determiner = yes) = 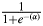 ${1 \over {1 + e^{-\lpar \alpha \rpar }}}$) that does not have any predictor variables and estimates only the intercept parameter α, which corresponds to a log-odds of “successes”, in our case, the presence of a determiner: α = ln
${1 \over {1 + e^{-\lpar \alpha \rpar }}}$) that does not have any predictor variables and estimates only the intercept parameter α, which corresponds to a log-odds of “successes”, in our case, the presence of a determiner: α = ln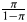 ${\pi \over {1-\pi }}$. In our case, α equals 1.057. Therefore, P(Determiner = yes) = 0.746, which is the probability of determiner appearance across the board, since the model does not distinguish between different contexts (it has no predictor variables). The accuracy of this model is 0.742, just as in the case of the morphosyntactic model. Given our conventions for evaluating accuracy, the null model predicts that an NP will always have a determiner, since the predicted probability is the same across the board and is greater than 0.5 (i.e., 0.746). Thus, the accuracy in this case simply matches the empirical proportion of NPs with determiners. In other words, predicting a determiner with a likelihood of 1 for a dataset with a proportion of NPs with determiners x (0.742 in our dataset) means that the accuracy of the prediction will be x (0.742). We thus see that our morphosyntactic model fares no better than a model which simply predicts that a determiner is used across the board.
${\pi \over {1-\pi }}$. In our case, α equals 1.057. Therefore, P(Determiner = yes) = 0.746, which is the probability of determiner appearance across the board, since the model does not distinguish between different contexts (it has no predictor variables). The accuracy of this model is 0.742, just as in the case of the morphosyntactic model. Given our conventions for evaluating accuracy, the null model predicts that an NP will always have a determiner, since the predicted probability is the same across the board and is greater than 0.5 (i.e., 0.746). Thus, the accuracy in this case simply matches the empirical proportion of NPs with determiners. In other words, predicting a determiner with a likelihood of 1 for a dataset with a proportion of NPs with determiners x (0.742 in our dataset) means that the accuracy of the prediction will be x (0.742). We thus see that our morphosyntactic model fares no better than a model which simply predicts that a determiner is used across the board.
As Table 6 shows, only 73 empirically attested bare nouns are predicted to be bare, whereas 18969 empirically observed bare nouns are predicted to appear with a determiner. That is, the model has a very low sensitivity (proportion of true positive predictions among true positive and false negative predictions) with respect to bare nouns (0.003).
In order to further evaluate the model, we consider the relation between accurate positive predictions and inaccurate positive predictions at different cut-off points, also known as receiver operating characteristics (ROC), as reflected by the area under the curve (AUC) measure. ROC (AUC) for the morphosyntactic model is 0.67, which is not a very good result given that no predictive ability at all corresponds to a ROC (AUC) of 0.5.Footnote 7
This exploration shows that, first, a model that takes into account a number of morphosyntactic factors does not have a very high predictive ability and, second, that the distribution of bare nouns clearly evolves over time (date being a significant factor for predicting the probability of determiner use.)
In order to evaluate the effect of noun type on bare noun/determiner distribution, we fitted a model in (12) that involves only one predictor variable, viz. Date, to our four nominal classes in Figure 1.Footnote 8 Figure 1 shows us, in particular, that although the frequencies of NPs with determiners vary greatly across noun classes and fluctuate over time, the overall trend is rising for all noun classes.
(12) P(Determiner = yes) =
${\displaystyle{e^{\alpha + \beta _1\ast Date}} \over {1 + \,e^{\alpha + \beta _1\ast Date}}}$
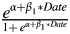

Figure 1: Regression models for determiners in subject and object position (total of 46089 NPs sorted by noun class); the dates are spread vertically to avoid overlapping of very close dates
In terms of its predictive ability, this model fares just as well as the model with the full set of morphosyntactic predictors in (11), having an accuracy of 0.74 and ROC of (AUC) 0.67.
Déchaine et al. (Reference Déchaine, Dufresne and Tremblay2018) report an increase in bare abstract and mass nouns in the Lais de Marie de France with respect to Le voyage de saint Brendan and hypothesize that a grammatical shift took place between the two texts yielding the disappearance of expletive l-forms, used with non-count nouns in Le voyage de saint Brendan. Our observations based on a larger corpus do not corroborate this conclusion. If we compare, in particular, Le voyage de saint Brendan (1120) and the Lais de Marie de France (1180), according to our data, the former has a lower frequency of determiners with mass NPs than the latter (0.44 vs. 0.59) but a higher frequency of determiners with abstract nouns (0.44 vs. 0.41).Footnote 9 Figure 1 also shows that, overall, the frequency of determiners increases for abstract and mass nouns, though not as quickly as for individual or relational nouns. This is indicated by a lower coefficient for abstract and mass nouns in Table 7.
Table 7: Parameter estimates of the model with noun types

Our follow-up study shows that the frequency of bare nouns with all noun types, including non-count nouns, fluctuates greatly and does not increase or decrease monotonically. Relatedly, it shows that none of the considered models where determiner use is taken to depend on morphosyntactic or chronological (date) factors fits the data well: in Figure 1 data points are widely dispersed around the lines representing the fitted values. It shows nevertheless that the general chronological trend is a decrease in bare nouns.
With respect to the problem of the distribution and evolution of determiners during the period from the 10th to the 14th century, it has been shown that a morphosyntactic model captures certain facts about the synchronic distribution of bare nouns, namely, that subject position, countability, and the presence of an adnominal modifier (relative clause or an adnominal PP) favour determiner use. But this type of model does not offer a satisfactory account of the overall diachronic trend of an increase in the use of determiners for all noun classes.
In the next section, we will argue that the rise of nominal determiners in the period considered is due essentially to pragmatico-semantic factors. On the basis of the observation that the increase of nominal determiners in the period considered (10th—14th c.) is mainly due to an increase in the frequency of l-forms, we will show how their mixed distribution, illustrated by the examples (5)–(9), and the progressive changes in their distribution, can be appropriately conceptualized as a probabilistic competition between an old grammatical meaning and a new grammatical meaning associated to these l-forms, in line with the grammar competition model of Kroch (Reference Kroch1989). We will develop a concrete proposal concerning the nature of the competing grammars and proceed to evaluate its predictions in the corpus material.
3. Towards a semantico-pragmatic model
As Figure 2 illustrates, Old French shows a gradual decline in the relative frequency of bare nouns, or, conversely, a gradual rise in the relative frequency of various determiners.Footnote 10
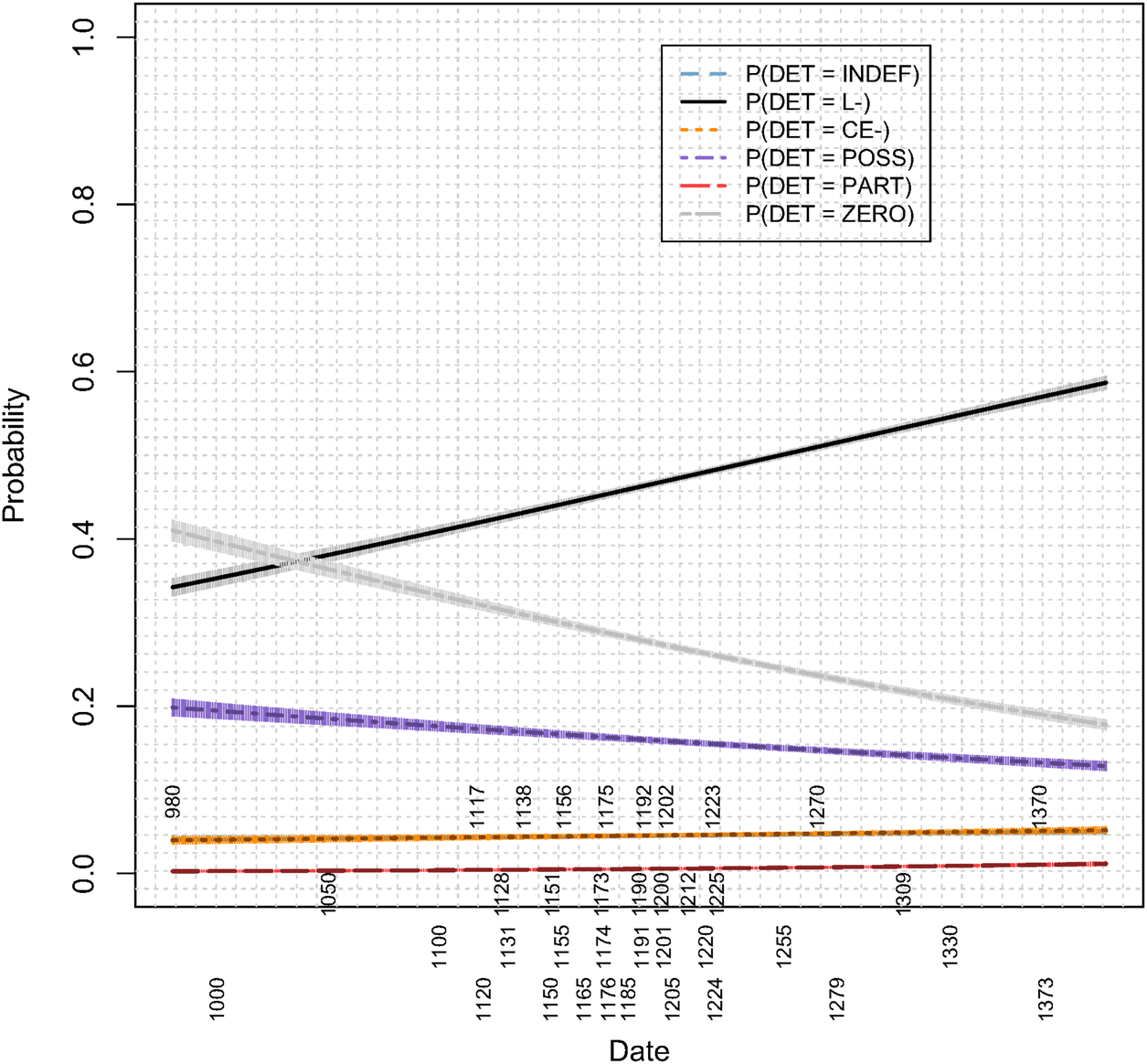
Figure 2: Regression models for different determiners in subject and object positions (lines corresponding to indefinite and demonstrative determiners completely overlap)
3.1 Theoretical framework: competing grammars
From the quantitative perspective, the frequency rise is not parallel for different determiners. In particular, although there are early occurrences of both the indefinite determiner and of the partitive determiner, there is a consensus that the frequency of indefinite and partitive determiners takes off a couple centuries later than the l-forms (Carlier (Reference Carlier and Arteaga2013) and references therein). This observation is confirmed by our statistical data: as we see in Table 8, the intercept for the logistic regression model fitted to un-forms is lower than for the l-forms, indicating a later change onset. Old French also shows a rise of indefinite and partitive determiners. Given the extremely low empirical proportions of these forms – the average rate of indefinites being 0.04 and of partitives 0.005 (as compared to 0.4 for le/la/les) – we will make the assumption that both are still in an early stage of development during the period considered here and that the major developments belong to a later time period. Therefore, we will disregard them here and focus on the definite determiners.Footnote 11
Table 8: Parameter estimates of the six models for different determiners in subject and object positions

As discussed in section 1, from the earliest attested sources, a subset of uses of the l-forms is similar to Modern French, whereas another subset is similar to the use of their etymon in Late Latin. We called this phenomenon a mixed distribution. We conclude from this that whatever semantics handles the distribution of Modern French definite determiners, it is not suitable for the l-forms in Old French: the distributional blueprints do not match up. As already mentioned, the blueprint of (anaphoric) demonstratives is not matched either, because the l-forms occur in contexts in which anaphoric demonstratives would not be used in Modern European languages.
One way of approaching this problem is to come up with another model of determiner semantics which would capture the empirically attested distribution. Within non-formal frameworks, such attempts have been undertaken. To quote Egedi (Reference Egedi and Kiss2014:63), “in the descriptive literature on O[ld]H[ungarian] there is a strong tendency to consider these early articles as ‘pre-articles’ or ‘pronoun-articles’ that belong to a special transitional word class with dual nature”. A major challenge for such an attempt would be modelling a clearly variationist dimension of the data: in a given Old French text, in contexts which require the l-forms in Modern French, determiner use is variable. This is illustrated in (13) and (14), where the first clause contains an l-form in abstract and individual NPs, respectively, whereas in the second clause an l-form is lacking.Footnote 12
(13) [Granz fu li dols], [fort marrimenz]
great was l-form pain strong suffering
‘Great was the pain, strong the suffering.’ (1000-PASSION-BFM-P,103.83)
(14) [Fame la mort nous pourchaça]. [Fame vie nous restora].
woman the death us acquired woman life us restored
‘A woman brought to us death. A woman restored us to life.’
(1190-BORON-PENN-R,27.430 & 1190-BORON-PENN-R,27.431)
Even if a formal model capturing mixed distributions could be designed for a given period, this would address the issue only in part, because the quantitative blueprint changes over time. Accounting for this would require the additional assumption that the frequency of contexts in which a given lexical entry can be uttered increases over time, which strikes us as very implausible.Footnote 13
Instead of proposing a new semantic entry, we pursue a hypothesis that the mixed distribution results from a contemporaneous use of two grammars, which ascribe two distinct semantics to the l-forms: demonstrative and definite.
We also assume that a change is a period of the co-existence in the speech community of two grammars and that the completion of the change amounts to the old grammar going completely out of use in the speech of adult speakers. This approach belongs to the tradition launched by Kroch (Reference Kroch1989) and is instantiated in a series of studies of language change based on quantitative data. Within this framework, competition is modeled as a change in probabilities associated with alternative grammatical analyses (see Pintzuk (Reference Pintzuk, Joseph and Janda2003) and Kauhanen and Walkden (Reference Kauhanen and Walkden2018) for in-depth discussions of the literature).Footnote 14
We propose that the change in question involves a competition between grammars which differ in whether givenness, formally identified with existential presupposition, is marked at the level of the (possibly extended) NP. Specifically, the “new” grammar is characterised by an obligatory marking of givenness at the NP-level by means of existential presupposition triggers. The old grammar, in contrast, does not have this requirement, and the givenness is marked by means of constituent order and/or prosodic means. We dub the competing grammars NP-givenness and T(ense)P(hrase)-givenness grammars, respectively.
Concerning the makeup of the competing grammars, we assume that the new grammar borrowed l-forms and possessive morphemes from the old grammar but ascribed different semantics to them. This is summarized in Table 9, and semantic details are discussed in section 3.2.
Table 9: Competing grammars

We furthermore hypothesize that the rise of the NP-givenness grammar is correlated with the decline of information structure-driven word order. It is commonly acknowledged that Old French underwent a major restructuring of its word order which can be roughly summarised as the replacement of a syntactically “flexible” word order by dominant SVO (Marchello-Nizia Reference Marchello-Nizia1995, Vance Reference Vance1997, Labelle and Hirschbühler Reference Labelle, Hirschbühler, Batllori, Hernanz, Picallo and Roca2005, Labelle Reference Labelle2007, Zaring Reference Zaring2011, Marchello-Nizia and Rouquier Reference Marchello-Nizia, Rouquier and Dufresne2012, Kroch and Santorini Reference Kroch and Santorini2014, Simonenko et al. Reference Simonenko, Crabbé and Prévost2018, to name just a few).
In the next section, we detail the semantic entries for the l-forms and possessives which distinguish the competing TP- and NP-givenness grammars.
3.2 One form, two grammatical meanings
We assume that the conditions of use of the l-forms in Modern French can be captured within a Fregean model of definite determiners.Footnote 15 Specifically, we assume that they denote functions from sets (denoted by the NP) to a unique (or maximal, Sharvy (Reference Sharvy1980)) individual from that set in a given situation (Elbourne Reference Elbourne2008). The semantics is given in (16). This corresponds closely to the entry Schwarz (Reference Schwarz2009) proposes as the semantics of the so-called weak definite determiners in Standard German.Footnote 16 We assume that such DPs involve a structure as in (15), where s is a silent situation pronoun.Footnote 17
(15) D-s NP
(16)
$\lsqb \kern-0.15em\lsqb D \rsqb \kern-0.15em\rsqb $ = λs$_\sigma $. λP〈e,σt〉 :$\exists $!x$\forall $y[Max(P)(y)(s) & x = y]. $\iota $x[Max(P)(x)(s)],where Max(P) = λxe. λs
$_\sigma $. P(x)(s) & $\neg \exists $y[P(y)(s) & x < y]
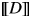
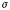
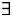

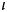
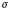
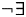
The utterances containing this entry will be judged true if the relevant semantic role is associated with the totality of individuals having the nominal property in a contextually given situation.Footnote 18 For instance, the utterance in (17) is predicted to be true iff the semantic role of experiencer (of the predicate being ready) is associated with all children in a given situation and false if it is not.
(17) Les enfants sont prêts.
the children are ready
‘The children are ready.’
This utterance is perceived as felicitous by native speakers only if the speaker and the listener are both aware of the existence of children in the situation in question. This fact is captured by the definedness conditions in (16): the expression 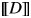 $\lsqb \kern-0.15em\lsqb D \rsqb \kern-0.15em\rsqb $ (
$\lsqb \kern-0.15em\lsqb D \rsqb \kern-0.15em\rsqb $ (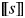 $\lsqb \kern-0.15em\lsqb s \rsqb \kern-0.15em\rsqb $)(
$\lsqb \kern-0.15em\lsqb s \rsqb \kern-0.15em\rsqb $)(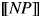 $\lsqb \kern-0.15em\lsqb {NP} \rsqb \kern-0.15em\rsqb $) is defined if and only if there exists a (maximal) individual with the nominal property in a given situation.Footnote 19
$\lsqb \kern-0.15em\lsqb {NP} \rsqb \kern-0.15em\rsqb $) is defined if and only if there exists a (maximal) individual with the nominal property in a given situation.Footnote 19
In Modern French, just as in all other languages we are aware of, the non-use of definite determiners of the Fregean type in argument positions in contexts which satisfy their conditions of use is perceived as infelicitous, as illustrated by the examples (4a)–(4b) above. Thus, there is no optionality in the use of a definite determiner in a given context: if it can be used, it must be used.Footnote 20 An explanation for this observation can presumably be derived from the Maximize Presupposition principle, according to which a presupposition trigger should be preferred to a non-presuppositional alternative if the relevant presupposition is satisfied in a given context (Heim Reference Heim, von Stechow and Wunderlich1991, Sauerland Reference Sauerland and Steube2008, Rouillard and Schwarz Reference Rouillard and Schwarz2017).
If the l-forms in Old French were to be analysed across the board as definite determiners of the Modern French kind (i.e., as in (16)), their non-use in suitable contexts would be problematic. The bare NP terra in (18) is another example of the non-use of an l-form in a context where it is strictly required in Modern French.
(18) Cum de Jesu l’ anma ’n anet, tan durament terra
when from Jesus l-form soul from.there went, then strongly land
crollet,
trembled
‘When the soul of Jesus left Him, the land trembled mightily.’
(1000-PASSION-BFM-P,114.235
We argue that such examples were possible in Old French because speakers during the relevant periods had access to the two grammars we described above: an NP-givenness grammar which ascribes to the l-forms the (Modern French) semantics in (16) and an alternative TP-givenness grammar where the l-forms had the meaning of their Latin etymon, an anaphoric demonstrative ille.
This proposal is less unorthodox than it may seem. Modern French maintains ambiguity of un-forms, which are still used both as a cardinal numeral meaning ‘one’ and as an indefinite determiner. Such an ambiguity is not exceptional.Footnote 21 Cross-linguistically, according to Dryer (Reference Dryer, Dryer and Haspelmath2013), there are more languages where a numeral ‘one’ and indefinite determiner are homophonous (112 languages in his sample) than those where they are not (102). According to Schwarz (Reference Schwarz2009) (and earlier references therein), Modern Standard German has homophonous “weak” and “strong” definite determiners, which have been treated in the literature as counterparts of English the and that, respectively.Footnote 22
There is a consensus about a direct etymological connection between the l-forms in Old French and the Late Latin anaphoric demonstrative ille (e.g., De Mulder and Carlier (Reference De Mulder and Carlier2006), a.o.). The latter was used in contexts featuring a deictic antecedent, a linguistic antecedent in the preceding discourse (including a propositional antecedent), and with noun phrases modified by relative clauses. The latter of these two contexts, featuring linguistic antecedents and relative clauses, constitute the distributional blueprint of anaphoric demonstratives in many languages, including Modern French ce, English that, and the strong definite determiners in German. We will assume that in the “initial” grammar l-forms had a meaning akin to that of demonstratives. Specifically, we will build on the semantics of English demonstratives put forth by Elbourne (Reference Elbourne2008).
The requirement that there be a linguistic antecedent is captured by Elbourne (Reference Elbourne2008) by assuming a silent pronominal element in the semantic decomposition of anaphoric demonstratives. A version of such a decomposition, adopted from Simonenko (Reference Simonenko2014), is given in (19), where i is the index of the salient pronoun in question, s is the situation pronoun, and R is a relational component introducing the pronominal argument.
(19) D-s [i [R NP]]
For D in (19) we assume the semantics in (16), while (20) is a semantic entry for R. This is a function which takes two properties, and returns a property of individuals that has these two properties. In case the second argument of R happens to be of type e, as in (19), it is turned into a property by an (intensional version of a) type-shifting operation ident (Partee Reference Partee1987) which maps an individual to a property of being identical to that individual.Footnote 23
(20)
$\lsqb \kern-0.15em\lsqb R \rsqb \kern-0.15em\rsqb $ = λP〈e,σt〉. λQ〈e,σt〉. λxe. λs$_\sigma $ : |{x: P(x)(s)}| >1. [P(x)(s) & Q(x)(s)]
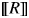
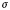
The structure in (19) is interpretable only if the context provides an individual to which an assignment function can map the index i. The truth conditions in (20), combined with those in (16) and the structure in (19), ensure that the relevant individual has the nominal property.
The entry in (20) also captures the anti-uniqueness of demonstratives, that is, their incompatibility with uniquely denoting noun phrases. This is illustrated in (9) for Modern French anaphoric demonstratives, by means of a definedness condition that requires that the set of individuals of which the first argument property holds be greater than a singleton.Footnote 24 We assume that anti-uniqueness is easily accommodated, meaning that it is satisfied by any context that does not entail that the relevant set of individuals is a singleton. Consequently, we will assume that the set of contexts in which anti-uniqueness holds is the complement of the set of contexts where uniqueness holds.
Anaphoric demonstratives are also used in the absence of an antecedent when a noun phrase contains a relative clause.Footnote 25 Adopting the analysis of Simonenko (To appear), we assume that R in these cases introduces an individual index within the relative clause, which gets bound by a relative operator. The function denoted by the higher copy of RP takes the denotation of the resulting relative clause (a property) as its argument (i.e., the second argument of 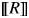 $\lsqb \kern-0.15em\lsqb R \rsqb \kern-0.15em\rsqb $, the first one being the property denoted by the NP).
$\lsqb \kern-0.15em\lsqb R \rsqb \kern-0.15em\rsqb $, the first one being the property denoted by the NP).
The structure without a (restrictive) relative clause is schematized in Figure 3 and the structure with a (restrictive) relative clause in Figure 4 (from Simonenko (To appear)).

Figure 3: Demonstrative determiner structure without an RRC
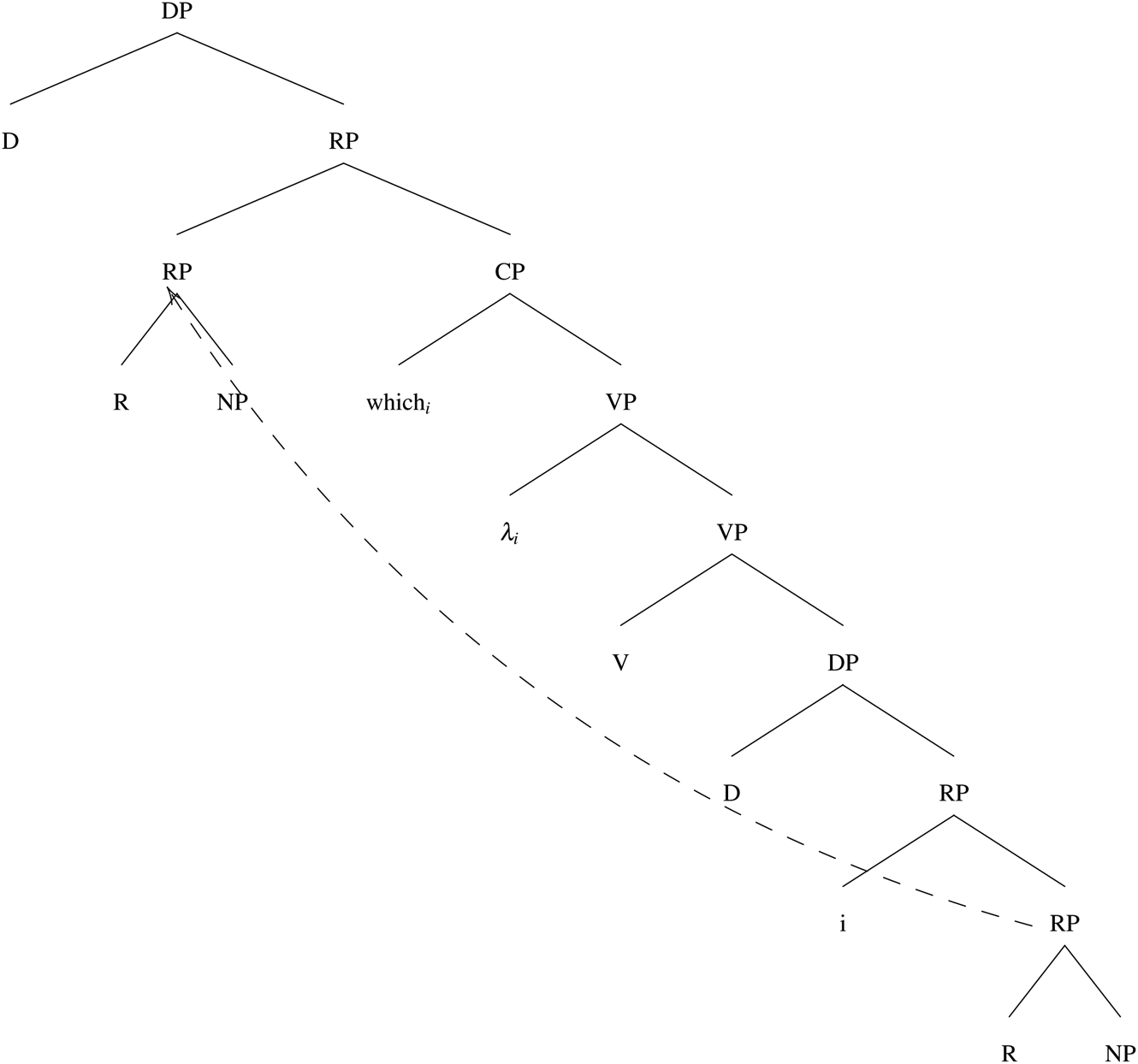
Figure 4: Demonstrative determiner structure with an RRC
Because of the reference resolution rules associated with the pronominal element in its structure, an anaphoric demonstrative is not expected to be used in contexts that simply entail the existence of an individual with a nominal property. Rather, an anaphoric demonstrative needs a referent-introducing antecedent expression. Thus, an l-form with demonstrative semantics is expected not to be used in cases such as (18). In other words, these cases are compatible with the hypothesis that in some cases l-forms in Old French had the semantics of anaphoric demonstratives.
Summarising, demonstrative and definite determiners impose different sets of conditions on contexts, as in Table 10, where RRC stands for a restrictive relative clause. As usual, all conditions are to be relativized to a relevant situation.
Table 10: Conditions of determiner use

The sets of contexts satisfying these conditions overlap. For instance, if a context entails the existence of a maximal individual with the property denoted by an NP with a restrictive relative clause, the conditions on the use of both demonstrative and definite entries are satisfied. The example in (21) illustrates this type of context in Modern French, where the attested cette can be replaced by la.
(21) L’ histoire de cette/la fille qui a réparé l’ aile cassée d’ un
the story of that/the girl who has repaired the wing broken of a
papillon nous a redonné foi en 2018.
butterfly us have give.back hope in 2018
‘The story of that/the girl who repaired the broken wing of a butterfly gave us hope in 2018.’Footnote 26
By hypothesis, during the period of change, l-forms of both types co-existed.
As specified in Table 9, the new NP-givenness grammar comes with a “new” semantics not only for the l-forms, but also for possessive morphemes. Following Simonenko and Carlier (under review), we assume that possessives undergo a shift from intersective modifiers to definite determiners.Footnote 27 Semantic entries for the former and for the latter, adopted from Simonenko and Carlier (under review), are given in (22) and (23), respectively, for the case of a first person singular possessor.Footnote 28
(22)
$\lsqb \kern-0.15em\lsqb {mon} \rsqb \kern-0.15em\rsqb ^{c\comma g}$ = λP〈e,σt〉. λxe. λs$_\sigma $. x belongs to Speaker in c & P(x)(s)(23)
$\lsqb \kern-0.15em\lsqb {mon} \rsqb \kern-0.15em\rsqb ^{c\comma g}$ = λs$_\sigma $. λP〈e,σt〉 :$\exists $!x[Max(λze. λs$_\sigma $. z belongs to Speaker in c & P(z) in s)(x)(s)].$\iota $x.Max(λye. λs$_\sigma $. y belongs to Speaker in c & P(y) in s)(x)(s)
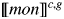
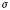
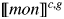
In our evaluations of the rise of the new grammar we count the l-forms and possessives together, assuming that the rate of their use in a given grammar is stable and that any significant increase is due to the spread of the new grammar.Footnote 29
3.3 Semantic shift
The Logical Forms we assumed for the l-determiners as the starting and end points of change are repeated in (24) and (25), from (19) and (15), respectively.
(24) D-s [i [R NP]]
(25) D-s NP
3.3.1 From source meaning to target meaning
Given that we assumed the same semantics for D, the one in (16), the difference between the two grammatical objects amounts to the presence vs. absence of a relational layer which introduces an additional restrictor on the denotation of NP, either in the form of an individual pronoun or a relative clause. Its effect on interpretation is very noticeable: it constrains the contexts of truthful and felicitous use of the l-forms to those which either provide a suitable referent introduced by a linguistic or extralinguistic antecedent, or a relative clause, while making sure that the property denoted by the nominal predicate holds of more than one individual in a given situation.
The structures in (24) and (25) are associated with different truth and felicity conditions. Hence, the following question arises: what made it possible for the speakers to assign the structure in (25) to the forms (l-forms) which were associated with the structure in (24)? In what follows we suggest that there are at least two contexts where both (24) and (25) make identical truth and felicity condition contributions and are thus indistinguishable as analytical possibilities for the l-forms. Those are contexts involving relative clauses and relational nouns. These contexts, we argue, fulfil the Constant entailments condition of Beck (Reference Beck2012: 88):
(26) “Variability in the meaning of an expression α between interpretations α′ and α′′ is promoted by the existence of contexts ϕ in which an occurrence of α under both interpretations α′ and α′′ leads to the same proposition ϕ′.”
3.3.2 Context of equivalence 1: NPs with relative clauses
Notice that with noun phrases containing relative clauses, the interpretation of DPs with demonstratives no longer depends on the availability of an antecedent. As observed by King (Reference King2001), when inserted within the scope of a quantifier, demonstrative DPs containing a relative clause receive a quantificational reading; their interpretation covaries with a quantifier bound variable. Observe the contrast between (27) and (28).Footnote 30
(27) Every father dreads that moment. [The same moment in time for all fathers]
(28) Every father dreads that/the moment when the postman comes. [The time when the postman comes is not necessarily the same for every father.]
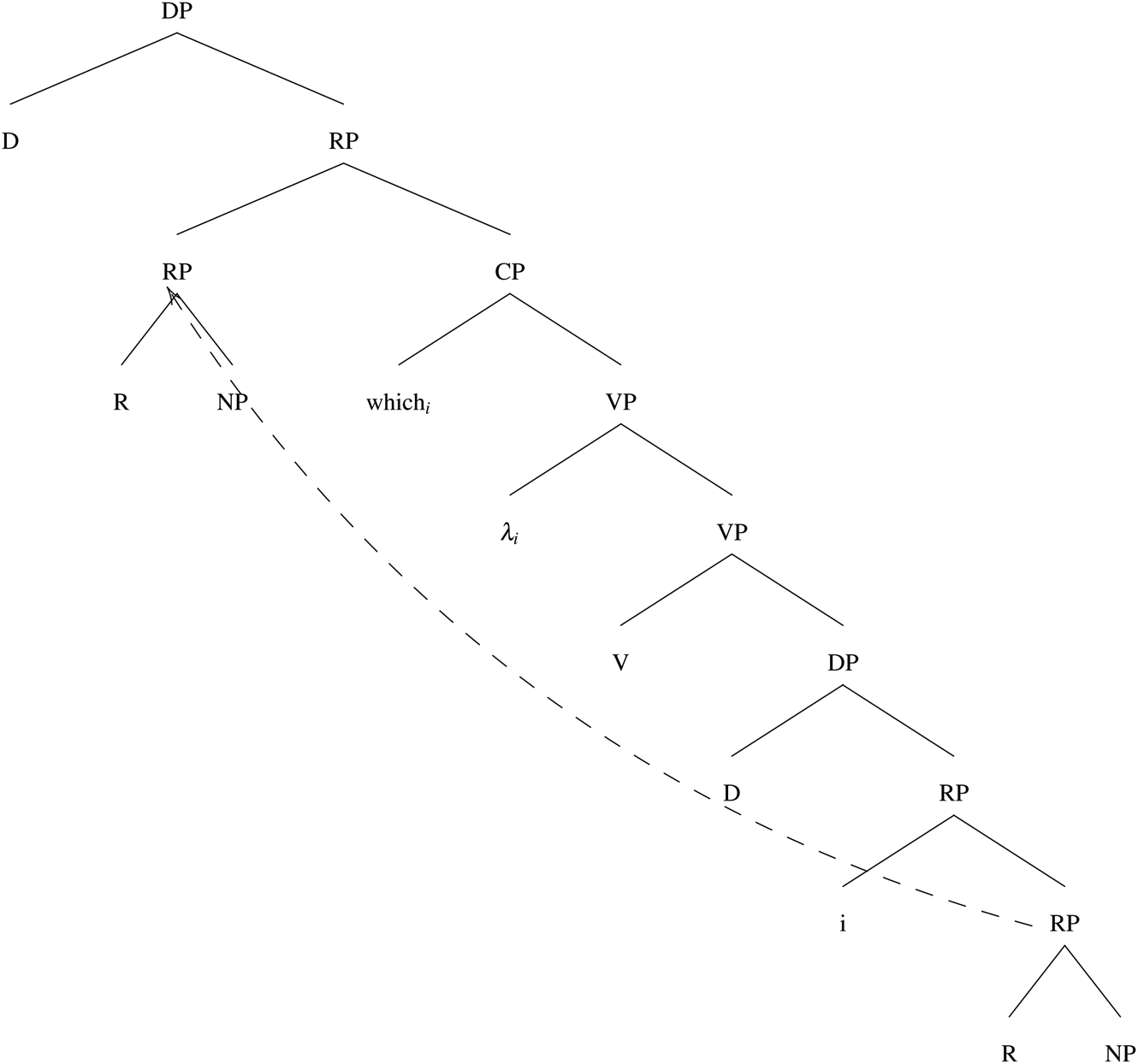
We assumed above, following Simonenko (to appear), that a relative clause can involve a demonstrative DP with a bound individual index (introduced by a relational head R), which accounts for the absence of a directly referential reading for demonstrative DPs in the presence of relative clauses. We also assume that in the case of other DP types, a relative clause can involve a covert variable insertion operation (Fox 2002). A demonstrative and a (simple) definite DP with an RRC are illustrated in Figures 4 and 5, respectively.
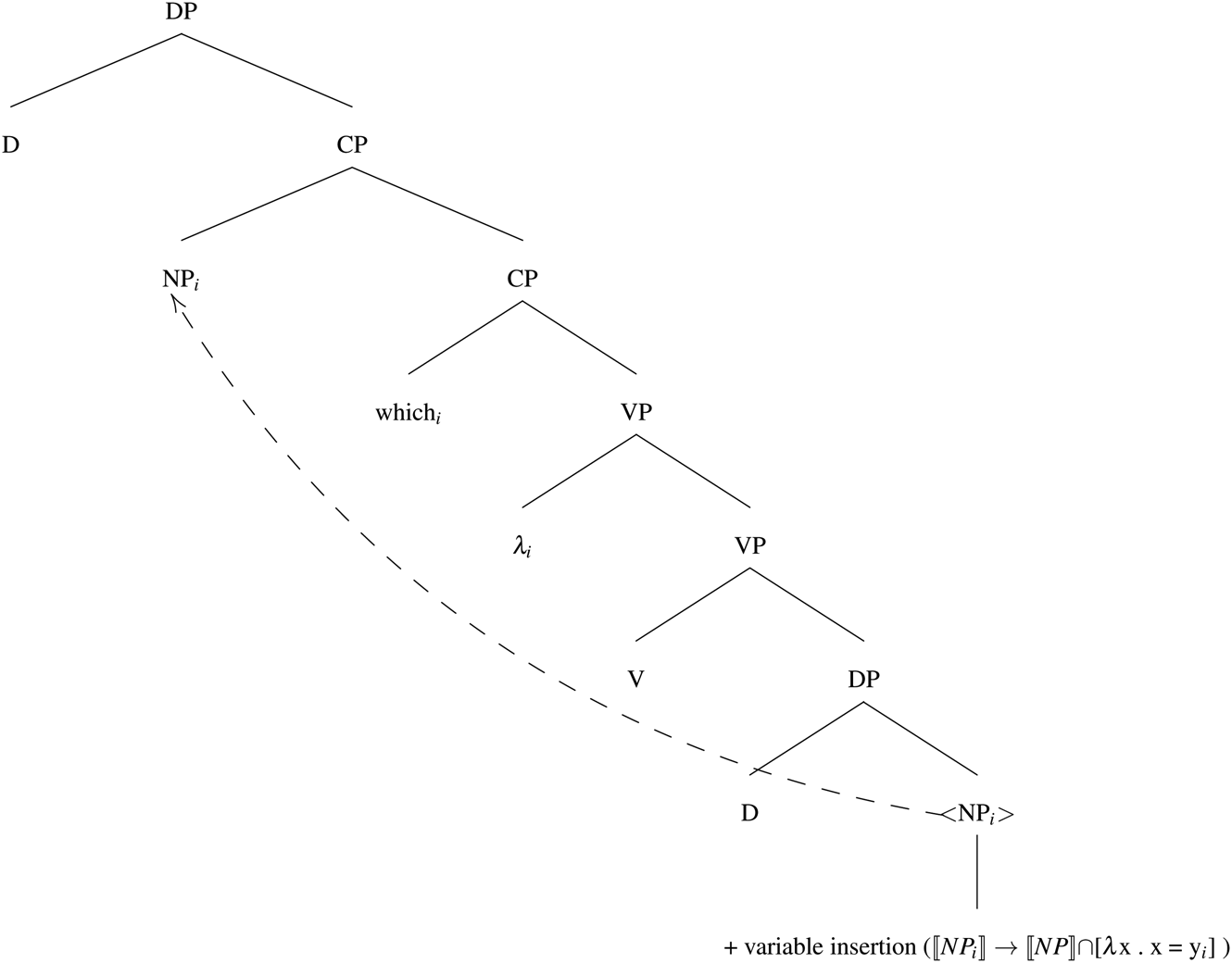
Figure 5: Definite determiner structure with an RRC
In addition to making an antecedent expression unnecessary for demonstratives, restrictive relative clauses also come with an anti-uniqueness condition similar to what we assumed for the semantics of R in (20). Namely, a felicitous use of a relative clause normally requires that the extension of the head noun in the relevant situation be greater than a singleton. Compare #That/#The current President of the United States that John met at the party and That/The restaurant that got three stars yesterday, where the former features an NP denoting uniquely (the current President of the United States) and the latter an NP denoting non-uniquely (a restaurant).
Importantly for us, there is no difference between the felicity- or truth-conditions associated with structures in Figure 4 and Figure 5. We therefore suggest that in Old French, noun phrases with l-forms and relative clauses were contexts of a potential structural and semantic shift, namely, from the Logical Form in (24) to the one in (25).
The contexts of the Late Latin etymon of the l-forms, ille, have been argued to include those where “the referent has not been previously mentioned in the discourse, but is identifiable […] by virtue of a restrictive relative clause” (Hertzenberg Reference Hertzenberg2015:6). In Figure 6, we plot the probability of occurring with an NP with a relative clause for different Late Latin demonstratives.Footnote 31 We see that more than 30% of the occurrences of ille are found in a context of a noun phrase with a restrictive relative clause. The predominance of ille with a relative clause is reinforced by the fact that the demonstrative is, frequently used in this context in Classical Latin, declines in Late Latin.

Figure 6: Relative clause occurrence with different demonstratives in Latin
3.3.3 Context of equivalence 2: Relational nouns
The second context where the two analyses of the l-forms are indistinguishable with regard to the resulting truth- and felicity conditions are noun phrases with relational nouns. Specifically, following Simonenko (Reference Simonenko2014:102–109), we assume that the relational component in the LF of demonstrative determiners can be spelled out by a relational noun.Footnote 32 The LF of a demonstrative determiner with a non-relational noun is repeated in (30) from (24), and the LF with a relational noun is given in (31). The semantic type of the denotation of [R NP] is the same as the type of a relational noun such as author, <e, <e, σt > > (modulo type shifting of the first argument).
(29)
$\lsqb \kern-0.15em\lsqb {author} \rsqb \kern-0.15em\rsqb $ = λye. λxe. λs$_\sigma $. x is a unique author of y in situation s (see 20)(30) D-s [i [R NP]]
(31) D-s [i [NPrelational]]
In the presence of a relational noun, the difference between the LFs of determiners with and without a relational component (which is what, we assume, the difference between demonstrative and definite determiners boils down to) disappears. We thus propose that relational nouns are a second type of context which satisfy the Constant Entailment condition in (26) with respect to two competing lexical entries for the l-forms.
4. Predictions of the model
Assuming that the new, NP-givenness grammar, gradually took over predicts that the l-forms should have been found more and more frequently in contexts where this grammar licensed their use. Specifically, these were contexts which entailed the existence of a (maximal) individual with the nominal property. Methodologically, while it is relatively easy in synchronic elicitation to make sure that the context has the relevant properties, the task is more complex for diachronic corpus data. We therefore use a proxy solution to the problem of the lack of contextual information in Old French, based on the semantics of noun phrases. As mentioned in section 2.1.1, we divided noun phrases into four classes based on the type of entity they typically denote: abstract, mass, individual, or relational. This proxy method has the advantage of singling out classes of denotations which each have a largely uniform behaviour with respect to the property which interests us here as setting apart the two competing semantics of the l-forms: whether a relationship can be established between two individuals from the denotation of the relevant nominal, and, consequently, whether a pronoun-antecedent relation can be established.
We assume the following working definitions of the four classes, while remaining aware of the problems faced by attempts to come up with necessary and sufficient conditions for the classification (e.g., the discussions in Grimm (Reference Grimm2014), Nicolas (Reference Nicolas and Zalta2018)). Abstract nouns (Nabs) are not individuatable in the sense that relative to a situation s there normally cannot be x and y such that y≠x and 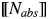 $\lsqb \kern-0.15em\lsqb {N_{abs}} \rsqb \kern-0.15em\rsqb $ (x)(s) and
$\lsqb \kern-0.15em\lsqb {N_{abs}} \rsqb \kern-0.15em\rsqb $ (x)(s) and 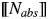 $\lsqb \kern-0.15em\lsqb {N_{abs}} \rsqb \kern-0.15em\rsqb $ (y)(s). Relative to a given situation, abstract nouns denote unique instances of the relevant abstraction (see the instantiation relation of Elbourne (Reference Elbourne2008)). Therefore, they are not normally pluralized as there cannot be groups of instances in a given situation. If they are pluralized, we consider it a case of coercion of an abstract noun into an individual-denoting noun. Using this guideline we classified event-denoting nouns such as “arrival” or “attack” as individual-denoting rather than abstract (see the discussion in Grimm (Reference Grimm2014)). Mass nouns (Nmass) are also not individuatable, which makes cumulative reference possible: if x and y verify the truth conditions of
$\lsqb \kern-0.15em\lsqb {N_{abs}} \rsqb \kern-0.15em\rsqb $ (y)(s). Relative to a given situation, abstract nouns denote unique instances of the relevant abstraction (see the instantiation relation of Elbourne (Reference Elbourne2008)). Therefore, they are not normally pluralized as there cannot be groups of instances in a given situation. If they are pluralized, we consider it a case of coercion of an abstract noun into an individual-denoting noun. Using this guideline we classified event-denoting nouns such as “arrival” or “attack” as individual-denoting rather than abstract (see the discussion in Grimm (Reference Grimm2014)). Mass nouns (Nmass) are also not individuatable, which makes cumulative reference possible: if x and y verify the truth conditions of 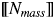 $\lsqb \kern-0.15em\lsqb {N_{mass}} \rsqb \kern-0.15em\rsqb $, then the sum x + y also does so, without the noun denoting a group individual. Again, unless coerced into individual-denoting nouns (e.g., particular quantities/vessels containing the relevant substance), they are not pluralized. Having non-individuatable denotations, both abstract and mass nouns generally do not satisfy the anti-uniqueness condition associated with demonstratives viz. the requirement that there be more than one individual with the property denoted by the NP in the relevant situation. This property makes abstract and mass nouns suitable for distinguishing the two lexical entries for the l-forms: without coercion and without a relative clause (which introduces anti-uniqueness, triggers coercion, and “obviates” the antecedent requirement for demonstratives), only l-forms with definite semantics can be used with these NPs. Individual denoting nouns are by definition individuatable. The sum of x and y, such that
$\lsqb \kern-0.15em\lsqb {N_{mass}} \rsqb \kern-0.15em\rsqb $, then the sum x + y also does so, without the noun denoting a group individual. Again, unless coerced into individual-denoting nouns (e.g., particular quantities/vessels containing the relevant substance), they are not pluralized. Having non-individuatable denotations, both abstract and mass nouns generally do not satisfy the anti-uniqueness condition associated with demonstratives viz. the requirement that there be more than one individual with the property denoted by the NP in the relevant situation. This property makes abstract and mass nouns suitable for distinguishing the two lexical entries for the l-forms: without coercion and without a relative clause (which introduces anti-uniqueness, triggers coercion, and “obviates” the antecedent requirement for demonstratives), only l-forms with definite semantics can be used with these NPs. Individual denoting nouns are by definition individuatable. The sum of x and y, such that 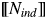 $\lsqb \kern-0.15em\lsqb {N_{ind}} \rsqb \kern-0.15em\rsqb $ (x)(s),
$\lsqb \kern-0.15em\lsqb {N_{ind}} \rsqb \kern-0.15em\rsqb $ (x)(s), 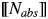 $\lsqb \kern-0.15em\lsqb {N_{abs}} \rsqb \kern-0.15em\rsqb $ (y)(s) and x≠y, becomes a group individual, and they can be pluralized. Finally, relational nouns denote individuals which have a particular relation to another individual. They can be pluralized and thus satisfy the anti-uniqueness condition. The relational component of their meaning makes relational nouns dependent on antecedent expressions introducing the relevant relatum. Thus, a distinction must be established between a direct anaphoric relation, which describes cases of referential identity between the anaphoric expression and the antecedent, and an indirect or associative anaphoric relation, describing cases where the referent of the anaphoric expression is associated with the antecedent through some stereotypical relationship (e.g., author - book).
$\lsqb \kern-0.15em\lsqb {N_{abs}} \rsqb \kern-0.15em\rsqb $ (y)(s) and x≠y, becomes a group individual, and they can be pluralized. Finally, relational nouns denote individuals which have a particular relation to another individual. They can be pluralized and thus satisfy the anti-uniqueness condition. The relational component of their meaning makes relational nouns dependent on antecedent expressions introducing the relevant relatum. Thus, a distinction must be established between a direct anaphoric relation, which describes cases of referential identity between the anaphoric expression and the antecedent, and an indirect or associative anaphoric relation, describing cases where the referent of the anaphoric expression is associated with the antecedent through some stereotypical relationship (e.g., author - book).
In Modern French or English, the use of demonstratives with relational noun phrases which relate non-identical individuals is not acceptable, as (32) shows.
(32) Je me suis acheté un livre. #Cet auteur a emporté le prix Nobel en
I me am bought a book that author has won the prize Nobel in
2015.
2015
‘I've bought a book. The/#that author won a Nobel prize in 2015.
However, Standard German (as well as some German dialects) does use determiners with anaphoric semantics in combination with relational nouns such as author, as (33) shows.Footnote 33
(33) Hans entdeckte in der Bibliothek einen Roman über den Hudson.
Hans discovered in the library a novel about DET Hudson.
Dabei fiel ihm ein, dass er vor langer Zeit einmal
In the process remembered he.DAT PART that he a long time ago once
einen Vortrag #vom/von dem Autor besucht hatte.
a lecture by.DETw/by DETs author attended had.
‘Hans discovered a novel about the Hudson in the library. In the process, he remembered that he had attended a lecture by the author a long time ago.’
Standard German, Schwarz (Reference Schwarz2009:229–230)
We assume that in the TP-grammar in Old French such uses were also available for the l-forms.
Table 11 lays out our assumptions concerning the behaviour of the four nominal classes with and without RRCs with respect to (i) the antecedent requirement, (ii) anti-uniqueness, and (iii) truth and felicity conditions introduced by the semantics of the l-forms associated with competing grammars.Footnote 34
Table 11: Noun types satisfying conditions associated with Ldef and Ldem

Our hypothesis predicts, in particular, that in contexts where the two sets of conditions may be satisfied (depending on (non)uniqueness), such as in NPs with individual-denoting and relational nouns, as well as NPs with relative clauses, the rate of use of l-forms will be greater than in contexts satisfying only one set of conditions (such as abstract and mass nouns without RRCs). Relative clauses constitute a uniquely ambivalent environment in that they, on the one hand, come with an anti-uniqueness condition, satisfying the requirement for the felicitous use of a demonstrative, and, on the other hand, help to satisfy the uniqueness condition of definite determiners by narrowing down the denotation of the noun phrase proper.
Let us, for convenience, abbreviate the probability associated with the use of the NP-givenness grammar with a definite semantics of the l-forms as P(Gr = lDef). Let us also abbreviate the probability associated with the use of the alternative TP-givenness grammar with a demonstrative semantics of the l-forms as P(Gr = lDem). Equation (34) follows from the assumption that the speakers of Old French had access only to these two grammars.
(34) P(Gr = lDem) + P(Gr = lDef) = 1
Let us also introduce the following probability abbreviations:Footnote 35
(35)
a. P(Con = max | N = Class): probability that a context entails the existence of a (maximal) individual from the denotation of the noun N of a given class (Maximality);
b. 1 − P(Con = max | N = Class): probability that a context does not entail the existence of a (maximal) individual from the denotation of the noun N of a given class (accommodating Anti-Uniqueness/Maximality);
c. P(Con =
$\exists $ant | N = Class): probability that a context entails the existence of an individual from the denotation of the noun N of a given class and introduced by a linguistic antecedent (Antecedent);d. P(Det = l-form) or P(l): probability of an l-form to be used.
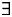
In general, the probability of an l-form being used in Old French is the sum of the probabilities of it being used within each of the competing grammars, weighted by the probability of the grammar itself. In turn, the probability of an l-form being used within a grammar corresponds to the probability of the conditions on the use of the relevant LF (definite or demonstrative) being satisfied.
We then obtain the following equations for the probability of the occurence of an l-form with a given noun class.
(36)
a. P(l | N = abs, RRC = no) =
P(Gr = lDef) × P(Con = max | N = abs, RRC = no)
+
P(Gr = lDem) × P(Con =
$\exists $ant | N = abs, RRC = no) × (1 − P(Con = max | N = abs, RRC = no))As abstract nouns, by assumption, always satisfy maximality ( = never satisfy anti-maximality),
1 − P(Con = max | N = abs, RRC = no) = 0.
Therefore, we have:
P(l | N = abs, RRC = no) = P(Gr = lDef) × P(Con = max | N = abs, RRC = no)
b. P(l | N = abs, RRC = yes) =
P(Gr = lDef) × P(Con = max | N = abs, RRC = yes)
+
P(Gr = lDem) × P(Con = max | N = abs, RRC = yes) =
P(Con = max | N = abs, RRC = yes) × (P(Gr = lDef) + P(Gr = lDem))
As P(Gr = lDef) + P(Gr = lDem) equals 1 since there is no other grammars, we have:
P(l | N = abs, RRC = no) = P(Con = max | N = abs, RRC = yes)
c. P(l | N = abs, RRC = no) < P(l | N = abs, RRC = yes) prediction
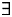
With regard to (36b), as discussed above, the presence of a relative clause obviates the antecedent requirement (associated with i in (19)) and leaves only the maximality requirement associated with D. The use of an RRC also means that the anti-maximality requirement of R (with respect to the nominal predicate) is satisfied. Therefore, the use of an l-form with either the NP- or TP-grammar equals the product of P(Con = max | N = abs, RRC = yes) and the probability of the relevant grammar, P(Gr = lDef) or P(Gr = lDem). Putting P(Con = max | N = abs, RRC = yes) outside the brackets and assuming that the sum of the two grammars equals 1, the resulting probability is P(Con = max | N = abs, RRC = yes).
From (36a) and (36b) follows an inequality in (36c). We assume that the probability to refer to the maximal individual with the relevant property is greater for an NP whose denotation is narrowed down by a relative clause than for an NP without such narrowing.Footnote 36 This assumption is based on the intuition that, by using a restrictive relative clause, speakers normally carve out a denotation that encompasses all relevant referents in a given situation.
The same reasoning applies to mass nouns, for which we also predict that the probability of occurring with an l-form is greater in the presence of a relative clause, as represented in (37c).
(37)
a. P(l N = mass, RRC = no) =
P(Gr = lDef) × P(Con = max | N = mass, RRC = no)
+
P(Gr = lDem) × P(Con =
$\exists $ant | N = mass) × (1 − P(Con = max | N = mass, RRC = no)) =P(Gr = lDef) × P(Con = max| N = mass, RRC = no)
b. P(l | N = mass, RRC = yes) =
P(Gr = lDef) × P(Con = max | N = mass, RRC = yes)
+
P(Gr = lDem) × P(Con = max | N = mass, RRC = yes) =
P(Con = max | N = mass, RRC = yes) × (P(Gr = lDef) + P(Gr = lDem)) =
P(Con = max | N = mass, RRC = yes)
c. P(l | N = mass, RRC = no) < P(l | N = mass, RRC = yes) prediction
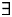
By assumption, individual-denoting NPs often take antecedents and can satisfy anti-uniqueness/maximality even without an RRC. Comparing probabilities with and without relative clauses is less straightforward in this case than it is for abstract and mass nouns. However, we can make an assumption that the probability that an NP satisfies anti-uniqueness/maximality and has an antecedent is lower than the probability that it satisfies the maximality requirement, in which case we again make the prediction that NPs with relative clauses will occur with an l-form more frequently than NPs without, as in (38c).Footnote 37
(38)
a. P(l | N = ind, RRC = no) =
P(Gr = lDef) × P(Con = max | N = ind, RRC = no)
+
P(Gr = lDem) × P(Con =
$\exists $ant | N = ind, RRC = no) × (1 − P(Con = max | N = ind, RRC = no))b. P(l | N = ind, RRC = yes) =
P(Gr = lDef) × P(Con = max | N = ind, RRC = yes)
+
P(Gr = lDem) × P(Con = max | N = ind, RRC = yes) =
P(Con = max | N = ind, RRC = yes) × (P(Gr = lDef) + P(Gr = lDem) =
P(Con = max | N = ind, RRC = yes)
c. P(l | N = ind, RRC = no) <P(l | N = ind, RRC = yes) prediction
Finally, relational nouns, by assumption, have an antecedent with the probability 1. We also assume that they can spell out R, which makes the anti-uniqueness condition irrelevant. This means that P(Gr = lDem) × P(Con =  $\exists $ant, N = rel) × (1 − P(Con = max |N = rel, RRC = no)) equals P(Gr = lDem). In the context of relational nouns, the presence of a relative clause does not remove the antecedent requirement (in contrast to its effect on other noun types). We thus predict that the probability of a relational NP without a relative clause occurring with an l-form equals that of a relational NP with an RRC, as in (39c).
$\exists $ant, N = rel) × (1 − P(Con = max |N = rel, RRC = no)) equals P(Gr = lDem). In the context of relational nouns, the presence of a relative clause does not remove the antecedent requirement (in contrast to its effect on other noun types). We thus predict that the probability of a relational NP without a relative clause occurring with an l-form equals that of a relational NP with an RRC, as in (39c).
(39)
a. P(l | N = rel, RRC = no) =
P(Gr = lDef) × P(Con = max | N = rel, RRC = no)
+
P(Gr = lDem)
b. P(l | N = rel, RRC = yes) =
P(Gr = lDef) × P(Con = max | N = rel, RRC = yes)
+
P(Gr = lDem)
c. P(l | N = rel, RRC = no) = P(l | N = rel, RRC = yes) prediction
More generally, a felicitously uttered relational noun is extremely likely to satisfy both the antecedent condition of the TP-grammar (being a relational noun it requires a relatum by definition) and the maximality condition of the NP-grammar. Relational nouns map their relatum most frequently to a unique individual (relevant relations are e.g., head (of), soul (of), baptism (of), husband (of) etc.). It has also been noticed for other languages that even those relational nouns that can in principle denote a one-to-many mapping (such as arm (of)), can be felicitously used with a definite determiner whenever it is immaterial which individual from the nominal denotation is chosen (e.g., Barker Reference Barker, Maienborn, von Heusinger and Portner2008). In other words, the frequency of the l-forms is predicted to stay at a certain maximum level independently of which grammar generates a given NP and thus to not undergo change over time.Footnote 38
Our prediction is formalised in (40). Here Pmax (Nrel) and Pant (Nrel) tend to 1, which means that the whole equation tends to 1 (by (34)).
(40) P(l | N = rel) =
P(Gr = lDef) × P(Con = max | N = rel) + P(Gr = lDem) × P(Con =
$\exists $ant | N = rel) =1
Finally, given that most relational nouns in our data denote functional relations (they return a unique individual related by the relevant relation to a relatum relative to any domain), the rate of l-forms in such contexts is predicted to be the highest of all, as stated in (41).
(41) P(l | N = rel) > P(l | N = mass), P(l | N = abs), P(l | N = ind) prediction
It is important to note that the inequalities in (36c), (37c), (38c), (39c) and (41) are predicted to hold independently of the specific values of the probability terms they contain.
5. Results
In order to test the predictions, we needed to track the use of l-forms separately for each of the four noun types with and without relative clauses. Instead of limiting our data to core argument positions only, as in section 2, this time we took into consideration all NPs regardless of their syntactic function, excluding, however, vocative NPs, NPs with quantifiers other than tout ‘all’ and NPs with conventional address nouns such as monseigneur (‘sir’). We created six binary variables for each determiner type, as described in section 3.1. We then fit logistic regression models (as in (12)) to eight data subsets corresponding to the four noun classes with and without relative clauses. These models are plotted in Figures 7–14, where POSS stands for prenominal possessives (e.g., mon ‘my.OBL.M.SG’, mes ‘my.NOM.M.SG’ etc.); PART – for the so-called partitive determiners, that is, de, possibly followed by or amalgamated with li, le, la, les (du/dou, de la, des); INDEF – for the forms un(s), une(s); DEM – for demonstratives of the c-paradigm ((i)cist, (i)cil, ce etc.) and DEF – for li/le/la/les. The bars at the x values 1120 and 1180 correspond to the data from Le voyage de saint Brendan and the Lais de Marie de France, respectively.Footnote 39

Figure 7: Regression models for different determiners with abstract nouns without RRC

Figure 8: Regression models for different determiners with abstract nouns with RRC

Figure 9: Regression models for different determiners with mass nouns without RRC

Figure 10: Regression models for different determiners with mass nouns with RRC

Figure 11: Regression models for different determiners with individual nouns without RRC

Figure 12: Regression models for different determiners with individual nouns with RRC

Figure 13: Regression models for different determiners with relational nouns without RRC

Figure 14: Regression models for different determiners with relational nouns with RRC
It is easy to see that predictions (36c), (37c), and (38c) are fulfilled: the rate of the l-forms (solid black line) is higher in NPs with relative clauses than in those without. It is difficult to evaluate prediction (39c) because of the scarcity of occurrences of relational nouns with RRC. Finally, prediction (41) is also verified: the rate of l-forms is highest in NPs with relational nouns, at least with respect to NPs without a restrictive relative clause.
The plots above show the evolution of different determiners separately. We argued, however, that these evolutions are not independent developments. They testify to a more general replacement of the TP-givenness grammar by the NP-givenness grammar, which required the use of existential presupposition triggers at the level of noun phrases. We also proposed that the principal difference between the two grammars is the semantics of the l-forms and possessive pronouns. To track the spread of the new grammar, we therefore combine the l-forms and possessive morphemes together and fit a logistic regression model to this new hybrid variable we call Grammar with values TP and NP. Parameter estimates are given in Table 12. The hybrid variable in question codes all noun phrases with either an l-form or a possessive determiner as NP-Grammar, while noun phrases with any other determiners or without any determiners are coded as TP-Grammar. By hypothesis, the new NP-grammar is characterised by a new semantics for these two categories of determiners (l-forms and possessives). We therefore approximate the progress of the NP grammar by focusing on the changes in the rates of use of these determiners.
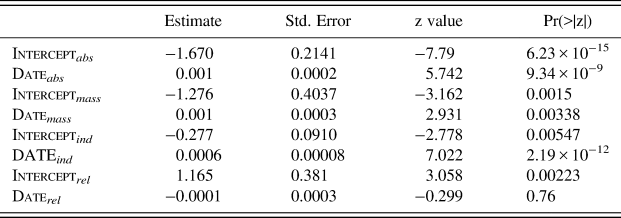
Table 12: Parameter estimates of the grammar competition model
Of course, both the l-forms and prenominal possessives can be generated by either of the two grammars. However, we make a crucial (and at the same time straightforward) assumption that within a grammar this happens at a constant rate due to the assumed constancy of pragmatic factors governing determiner use (e.g., in a given grammar, demonstratives are used at a stable rate). Therefore, any detected diachronic changes in the frequencies of these determiners are due to the changes in the frequencies of the use of the grammars generating corresponding utterances, because all other factors influencing the use of these determiners are assumed to be constant. That is, what we identify in our approximation model as the probabilities of the TP- and NP-grammars correspond, strictly speaking, to the following. The approximated probability of the TP-grammar corresponds to the frequency of the “true” TP-grammar minus the frequency of the l-forms and possessives within that grammar. Correspondingly, the approximated probability of the NP-grammar corresponds to the frequency of the “true” NP-grammar plus the probability of the l-forms and possessives in the true TP-grammar. This is formalized in (42). Since the difference between the “true” and the approximated probability is the same for both grammars and does not change over time, we assume that we can innocuously ignore it.
(42)
a. Approximated P(Gr = TP) = True P(Gr = TP) −P(l, poss | Gr = TP)
b. Approximated P(Gr = NP) = True P(Gr = NP) + P(l, poss | Gr = TP)
The first global observation we get from Figure 15 and Table 12 is that the developments for abstract, mass, and individual nouns are essentially parallel: the probability of the NP-grammar grows at very similar rates, as shown by the coefficient estimates of the predictor DATE in the three cases.Footnote 40 In contrast, the regression line slope for relational nouns is essentially parallel to the x-axis. Looking at the coefficient estimate for relational nouns in Table 12 (-0.0001), we see that it is indistinguishable from zero (p = 0.76 and the interval around the coefficient defined by the standard error includes 0), meaning that the probability of an l-form in this context does not change over time. This comes very close to the prediction we spelled out in (40) that P(l) with these nouns tends to 1.Footnote 41 Recall that the prediction is based on an assumption that relational nouns are a special type of context which almost always licenses the use of the l-forms with respect to both grammars. Therefore, we cannot observe the rise of the new grammar in this context.

Figure 15: Regression models for grammar competition for four noun types
The parallelism of the developments in the case of abstract, mass, and individual nouns makes a case for a constant rate effect (CRE, cf. Kroch (Reference Kroch1989) and much work since), which states that a grammatical change spreads at the same rate in different grammatical contexts, where rate corresponds to the coefficient of the time variable.Footnote 42 The only context which does not fit this generalization are relational nouns. We argued, however, that this is a special context which (almost) always satisfies the requirements of both grammars, so that it is impossible to notice the replacement of one grammar by another.
6. Conclusions
This article argued that the rise of the l-forms in Old French is due to pragmatico-semantic rather than morpho-syntactic factors and is the result of the gradual shift from a demonstrative to a definite meaning. We have proposed a model of the spread of the l-forms in Old French that assumes a competition between grammars with a demonstrative-like and a definite-like analysis of these forms. We spelled out a number of predictions that the model makes concerning the relative spread of the l-forms in various contexts based on our assumptions about the truth and felicity conditions associated with a definite vs. demonstrative analysis. We then showed that the predictions regarding the relative probability of finding an l-form in a given context are borne out by the corpus data. We identified two potential contexts of semantic shift on the grounds that the demonstrative and the definite analysis are not distinguishable in these contexts with respect to truth or felicity conditions: functional relational nouns and noun phrases with relative clauses.
The performance of the model we spelled out suggests that this is a fruitful approach for tackling the problem of inconsistent or mixed distribution, which seems to characterize emerging determiners in a number of medieval European languages. A typological historical comparison is a natural extension of this study. This can be extended onto a number of other stages of European languages, such as Old Hungarian, where, according to Egedi (Reference Egedi and Kiss2014:58), “the article and the distal demonstrative look identical, share a phrase-initial prenominal position, and even overlap functionally (e.g., in anaphoric use)”.
While this study offers a model that predicts relative rates of determiner spread, it does not say anything concerning absolute rates and does not directly address the question of what made the probability of the new NP-giveness Grammar increase. Such a model could potentially be implemented as a variational learning model of the type proposed by Yang (Reference Yang2002), which would require identifying contexts of success and failure for each of the competing grammatical options. We analysed the spread of the l-forms and possessives as a consequence of a more general change consisting of a new way of marking existential presupposition, namely, by means of determiners rather than by word order and/or prosodic means. While we have not offered direct evidence in favour of the hypothesis that the spread of grammatical markers associated with existential presupposition was related to the decline of information structure-driven word orders, we can already present some suggestive data. In Figure 16 we plotted the spread of the NP-givenness Grammar together with the decline of the OV Grammar, where Grammar is a binary variable with value VO for (S)VO orders and OV for all other word order permutations.

Figure 16: Spread of NP-givenness Grammar and VO Grammar
The figure suggests that the two changes, at the general clause level and at the level of NP determination, are at least contemporary. More work needs to be done to find evidence for causality.