

Contents
Research Article
GEOGRAPHIC RATEMAKING WITH SPATIAL EMBEDDINGS
-
- Published online by Cambridge University Press:
- 04 October 2021, pp. 1-31
-
- Article
- Export citation
JOINT MODELING OF CLAIM FREQUENCIES AND BEHAVIORAL SIGNALS IN MOTOR INSURANCE
-
- Published online by Cambridge University Press:
- 07 October 2021, pp. 33-54
-
- Article
- Export citation
DISCRIMINATION-FREE INSURANCE PRICING
-
- Published online by Cambridge University Press:
- 07 October 2021, pp. 55-89
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
JOINT MODEL PREDICTION AND APPLICATION TO INDIVIDUAL-LEVEL LOSS RESERVING
-
- Published online by Cambridge University Press:
- 05 November 2021, pp. 91-116
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A COLLECTIVE RESERVING MODEL WITH CLAIM OPENNESS
-
- Published online by Cambridge University Press:
- 03 December 2021, pp. 117-143
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
MULTIVARIATE COMPOSITE COPULAS
-
- Published online by Cambridge University Press:
- 03 November 2021, pp. 145-184
-
- Article
- Export citation
ON THE
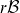 $r\mathcal{B}$ELL FAMILY OF DISTRIBUTIONS WITH ACTUARIAL APPLICATIONS
$r\mathcal{B}$ELL FAMILY OF DISTRIBUTIONS WITH ACTUARIAL APPLICATIONS
-
- Published online by Cambridge University Press:
- 18 May 2021, pp. 185-210
-
- Article
- Export citation
-
In this paper, a new three-parameter discrete family of distributions, the
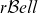 $r{\mathcal B}ell$ family, is introduced. The family is based on series expansion of the r-Bell polynomials. The proposed model generalises the classical Poisson and the recently proposed Bell and Bell–Touchard distributions. It exhibits interesting stochastic properties. Its probabilities can be computed by a recursive formula that allows us to calculate the probability function of the amount of aggregate claims in the collective risk model in terms of an integral equation. Univariate and bivariate regression models are presented. The former regression model is used to explain the number of out-of-use claims in an automobile insurance portfolio, by showing a good out-of-sample performance. The latter is used to describe the number of out-of-use and parking claims jointly. This family provides an alternative to other traditionally used distributions to describe count data such as the negative binomial and Poisson-inverse Gaussian models.
$r{\mathcal B}ell$ family, is introduced. The family is based on series expansion of the r-Bell polynomials. The proposed model generalises the classical Poisson and the recently proposed Bell and Bell–Touchard distributions. It exhibits interesting stochastic properties. Its probabilities can be computed by a recursive formula that allows us to calculate the probability function of the amount of aggregate claims in the collective risk model in terms of an integral equation. Univariate and bivariate regression models are presented. The former regression model is used to explain the number of out-of-use claims in an automobile insurance portfolio, by showing a good out-of-sample performance. The latter is used to describe the number of out-of-use and parking claims jointly. This family provides an alternative to other traditionally used distributions to describe count data such as the negative binomial and Poisson-inverse Gaussian models.
INSURANCE VALUATION: A TWO-STEP GENERALISED REGRESSION APPROACH
-
- Published online by Cambridge University Press:
- 03 December 2021, pp. 211-245
-
- Article
- Export citation
A GROUP REGULARISATION APPROACH FOR CONSTRUCTING GENERALISED AGE-PERIOD-COHORT MORTALITY PROJECTION MODELS
-
- Published online by Cambridge University Press:
- 09 November 2021, pp. 247-289
-
- Article
- Export citation
COMPUTATION OF BONUS IN MULTI-STATE LIFE INSURANCE
-
- Published online by Cambridge University Press:
- 14 December 2021, pp. 291-331
-
- Article
- Export citation
POINT AND INTERVAL FORECASTS OF DEATH RATES USING NEURAL NETWORKS
-
- Published online by Cambridge University Press:
- 03 December 2021, pp. 333-360
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Corrigendum
MULTIVARIATE COMPOSITE COPULAS – CORRIGENDUM
-
- Published online by Cambridge University Press:
- 24 January 2022, p. 361
-
- Article
-
- You have access
- HTML
- Export citation
Front Cover (OFC, IFC) and matter
ASB volume 52 issue 1 Cover and Front matter
-
- Published online by Cambridge University Press:
- 24 January 2022, pp. f1-f2
-
- Article
-
- You have access
- Export citation
Back Cover (IBC, OBC) and matter
ASB volume 52 issue 1 Cover and Back matter
-
- Published online by Cambridge University Press:
- 24 January 2022, pp. b1-b3
-
- Article
-
- You have access
- Export citation