



No CrossRef data available.
Article contents
Strong convergence of an epidemic model with mixing groups
Published online by Cambridge University Press: 01 September 2023
Abstract
We consider an SIR (susceptible 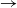 $\to$ infective
$\to$ infective 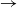 $\to$ recovered) epidemic in a closed population of size n, in which infection spreads via mixing events, comprising individuals chosen uniformly at random from the population, which occur at the points of a Poisson process. This contrasts sharply with most epidemic models, in which infection is spread purely by pairwise interaction. A sequence of epidemic processes, indexed by n, and an approximating branching process are constructed on a common probability space via embedded random walks. We show that under suitable conditions the process of infectives in the epidemic process converges almost surely to the branching process. This leads to a threshold theorem for the epidemic process, where a major outbreak is defined as one that infects at least
$\to$ recovered) epidemic in a closed population of size n, in which infection spreads via mixing events, comprising individuals chosen uniformly at random from the population, which occur at the points of a Poisson process. This contrasts sharply with most epidemic models, in which infection is spread purely by pairwise interaction. A sequence of epidemic processes, indexed by n, and an approximating branching process are constructed on a common probability space via embedded random walks. We show that under suitable conditions the process of infectives in the epidemic process converges almost surely to the branching process. This leads to a threshold theorem for the epidemic process, where a major outbreak is defined as one that infects at least 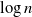 $\log n$ individuals. We show further that there exists
$\log n$ individuals. We show further that there exists 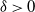 $\delta \gt 0$, depending on the model parameters, such that the probability that a major outbreak has size at least
$\delta \gt 0$, depending on the model parameters, such that the probability that a major outbreak has size at least 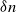 $\delta n$ tends to one as
$\delta n$ tends to one as 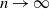 $n \to \infty$.
$n \to \infty$.
- Type
- Original Article
- Information
- Copyright
- © The Author(s), 2023. Published by Cambridge University Press on behalf of Applied Probability Trust
References
Bailey, N. T. J. (1975). The Mathematical Theory of Infectious Diseases and Its Applications, 2nd edn. Griffin, London.Google Scholar
Ball, F. (1983). The threshold behaviour of epidemic models. J. Appl. Prob. 20, 227–241.10.2307/3213797CrossRefGoogle Scholar
Ball, F. and Donnelly, P. (1995). Strong approximations for epidemic models. Stoch. Process. Appl. 55, 1–21.10.1016/0304-4149(94)00034-QCrossRefGoogle Scholar
Ball, F. and Neal, P. (2017). The asymptotic variance of the giant component of configuration model random graphs. Ann. Appl. Prob. 27, 1057–1092.10.1214/16-AAP1225CrossRefGoogle Scholar
Ball, F. and Neal, P. (2022). An epidemic model with short-lived mixing groups. J. Math. Biol. 85, article no. 63.10.1007/s00285-022-01822-3CrossRefGoogle Scholar
Ball, F. and O’Neill, P. (1994). Strong convergence of stochastic epidemics. Adv. Appl. Prob. 26, 629–655.10.2307/1427812CrossRefGoogle Scholar
Bartlett, M. S. (1955). An Introduction to Stochastic Processes. Cambridge University Press.Google Scholar
Cortez, R. (2022). SIR model with social gatherings. Preprint. Available at https://arxiv.org/abs/2203.08260.Google Scholar
Durrett, R. (2010). Probability: Theory and Examples. Cambridge University Press.10.1017/CBO9780511779398CrossRefGoogle Scholar
Ethier, S. N. and Kurtz, T. G. (1986). Markov Processes: Characterization and Convergence. John Wiley, Hoboken, NJ.10.1002/9780470316658CrossRefGoogle Scholar
Jagers, P. (1975). Branching Processes with Biological Applications. John Wiley, London.Google Scholar
Kendall, D. (1956). Deterministic and stochastic epidemics in closed populations. In Proc. 3rd Berkeley Symp. Math. Statist. Prob., Vol. IV, University of California Press, Berkeley, pp. 149–165.10.1525/9780520350717-011CrossRefGoogle Scholar
Metz, J. A. J. (1978). The epidemic in a closed population with all susceptibles equally vulnerable; some results for large susceptible populations and small initial infections. Acta Biotheoretica 27, 75–123.10.1007/BF00048405CrossRefGoogle Scholar
Nerman, O. (1981). On the Convergence of Supercritical General (C-M-J) Branching Processes. Z. Wahrscheinlichkeitsth. 57, 365–395.10.1007/BF00534830CrossRefGoogle Scholar
Newman, M. E. J. (2002). Spread of epidemic disease on networks. Phys. Rev. E 66, article no. 016128.10.1103/PhysRevE.66.016128CrossRefGoogle ScholarPubMed
Pollett, P. K. (1990). On a model for interference between searching insect parasites. J. Austral. Math. Soc. B 32, 133–150.10.1017/S0334270000008390CrossRefGoogle Scholar
Whittle, P. (1955). The outcome of a stochastic epidemic—a note on Bailey’s paper. Biometrika 42, 116–122.Google Scholar
Williams, T. (1971). An algebraic proof of the threshold theorem for the general stochastic epidemic. Adv. Appl. Prob. 3, 223.10.2307/1426166CrossRefGoogle Scholar