


1.1 Why Structure Matters
Stop. Take a moment to look around. What do you see? No matter where you are, you are likely perceiving a world consisting of things. Maybe you are reading this book in a coffee shop, and if so, you probably see people, cups, books, chairs, and so on. You see a world of objects with properties, yourself included: white cups are on wooden tables, people sitting in chairs are reading books and talking with one another. At the same time, you are a subject, responding to this world and actively bringing yourself and these objects into interrelation. And yet, the world of objects with properties that you are perceiving is but one slice of a complex reality.
What is less obvious and often taken for granted is all the relationships that come together to make this world of things a sensible, navigable reality. In the coffee shop you are unlikely to notice the complex patterns of exchanges in resources that brought the coffee to your table, the hierarchy of relationships that organizes the work roles in the coffee shop, or the stable pattern of interactions among customers coming and going that make the coffee shop a hub in the flows in so many people’s everyday lives. You take those exchanges and relationships for granted; and yet, you are embedded within them. You and the world of things you perceive are inextricably tied together through these invisible webs of flows, exchanges, and more or less stable relationships. They uphold and provide meaning for your subjectively experienced reality.
The natural and social worlds are filled with flows, exchanges, and relationships like these. By studying these largely unseen patterns, or networks, we come to understand myriad social phenomena – for example, how persons assume distinct roles, like barista, and the role relations between employees and patrons; the ways in which personal relationships form and evolve from that of employee–patron or coworkers to something more intimate, like friends or romantic partners; and how gossip spreads information across some of these role relations more than others. Many of our dearest social institutions are replete with persistent associations, such as peer groups, families, and schools. Even our casual dinner conversations can be viewed as having recognizable patterns that we interpret as either a positive bonding moment or an awkward one. These all entail social networks – that is, flows, exchanges, and relationships that exist only within human experience and behavior.
But take a moment to consider all the other phenomena that also have relational properties. Molecules are structures formed by an assortment of atomic bonds. Brains function through structures of neural connections. Ecosystems entail structures of food webs where various animals and plants consume one another, thereby creating flows of carbon and energy. The Internet is organized by links that connect web pages. Markets move in response to a system of patterned transactions. Language creates meaning by assembling a complex set of relationships between words, sentences, and grammar. These are also networks.
We cannot understand either the social or wider world without understanding relationships and the networks they form. These structures define the environments in which core scientific phenomena take place. They are not just background connections in the understanding of life, but are integral to explaining and modeling complex phenomena in accurate and meaningful ways. It is hard to imagine a discussion of brain functioning without references to brain regions and neural activity linking neurons and those regions. Likewise, it is hard to imagine studying the social aspects of life without examining actions and relationships that connect people. In short, the interconnectedness of objects is a fundamental property of the world, and makes the world possible. Regardless of the social actors or objects being connected (i.e., networked), the properties and dynamics of being interconnected are something all phenomena share. And this is what network analysis seeks to understand. Many disciplines and fields concern networks, and the specific content of these disciplines vastly differs, but it is the focus on structures and the interdependencies to which structures give rise that unites them.
1.2 What Is Structure?
If we ever get to the point of charting a whole city or a whole nation, we would have … a picture of a vast solar system of intangible structures, powerfully influencing conduct, as gravitation does in space. Such an invisible structure underlies society and has its influence in determining the conduct of society as a whole.
In the most general terms, a structure is an arrangement of related objects that form a pattern. Patterns arise everywhere, but most remain largely unseen, discernable only at a physical or conceptual distance. This is especially true of social structures, which are patterns of interactions among people, such as those envisioned in the preceding quote by Jacob Moreno, a founder of the social network approach, or our envisioning of the coffee shop at the beginning of this chapter. In trying to discern social structures, people are a bit like fish in a school: each individual perhaps sees some fleeting aspects of structure, but always from a partial, subjective viewpoint. A more objective structural understanding requires the aid of tools that allow us to see beyond our own senses and cognitive limitations. As network researchers, we are in the business of devising such tools for understanding the world. Unlike fish, people have created schools of thought (forgive the pun) dedicated to the discovery, preservation, and transmission of knowledge and tools for addressing these problems.
The network tradition is one such school of thought. It stands in contrast to more traditional schools in the social and physical sciences that use tools focusing on individual objects and their characteristics. Such individual-level approaches have dominated entire disciplines in the social sciences, such as psychology and economics. Even in the clearly less individual-centered discipline of sociology, the primary tool for understanding behavior for decades was the survey. In seeking generalizability, surveys draw random samples of individuals from populations, thereby sacrificing most of the local structures of family, friends, coworkers, neighborhoods, and communities (McPherson & Smith Reference McPherson and Smith2019). In random survey designs, the connections among respondents violate statistical assumptions of independent observations and must therefore be avoided. An independent, random sample of persons is easy to collect and analyze, but this practice comes at a cost: by divorcing the respondents from their social context, the concepts and tools of traditional survey research treat each person as an isolated entity and regard their characteristics as having reified meaning. Such data tend to yield variable-based explanations for social phenomena in which individual characteristics, like age and education, are treated as causal factors (Abbott Reference Abbott1988).
Network scholars see the interdependencies among actors (i.e., my behavior is shaped by my relationships with others) not as a complication to avoid but instead as the subject of inquiry. Within these networks – and by virtue of their links and position – individual objects derive their meaning. A person is defined by their unique position and trajectory across networks over time (Mead Reference Mead1934). By virtue of the network pattern, we also identify larger social constructs, like groups and roles. A community’s internal process is in great part reflected by the patterns of associations that define them. In effect, the network of relations is a dualistic means of discerning what it means to be both individuals and groups, and it regards their definition in a contextualized, situated light. The exact objects of interest (e.g., people, animals, or airports) can vary widely across substantive fields, as can the relations, or links, that connect them (e.g., friendship, kinship, advice, fighting, or grooming). The interconnectedness of things makes them interdependent and reactive to one another. In short, when observed over time, objects affecting one another through ties are systems.
In general, we can think of systems as falling under four main types, with very different types of objects and links (Figure 1.1).
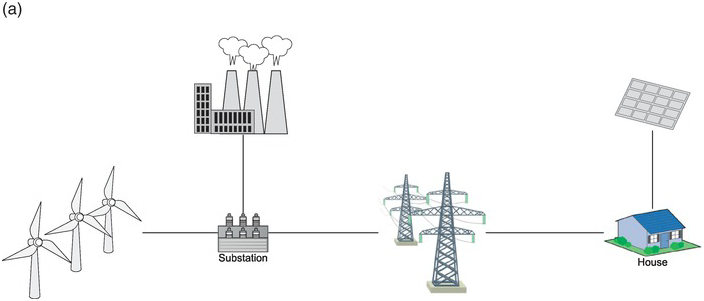
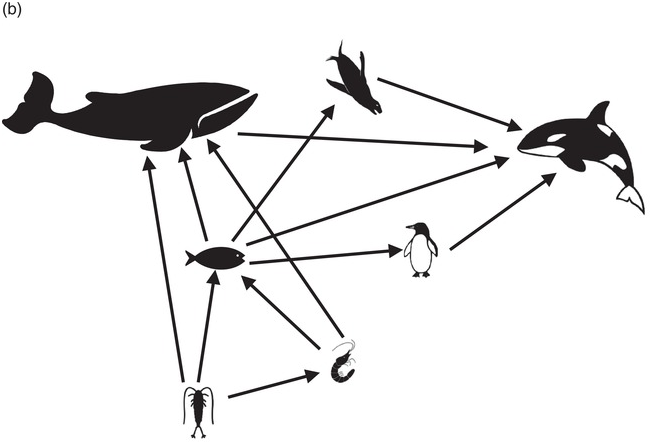
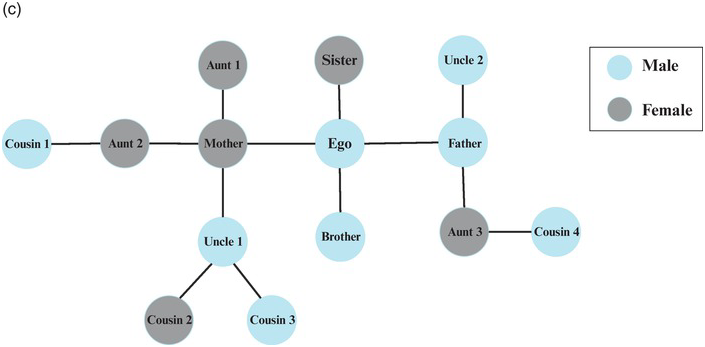
(c) Social systems (groups or larger collectivities): elements are often persons interrelated in patterns of exchange that reflect group memberships and hierarchies. These systems can vary in their differentiation and volatility. The Western European kinship system is a good example of a social system that organizes gender roles, such as being an aunt to a focal individual.
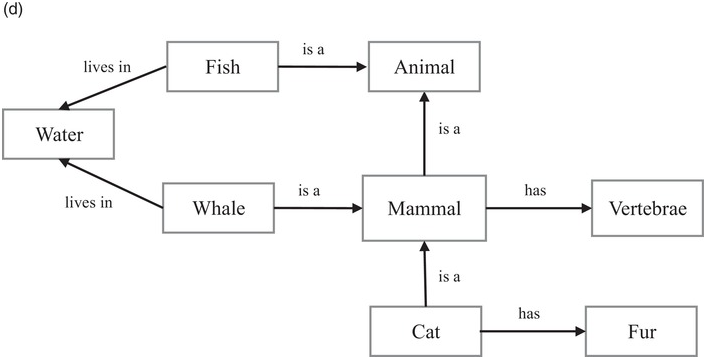
(d) Cultural systems (interrelated meanings): elements are symbols that form semiotic systems through cognitive and affective connections of similarity and difference. Networks of semantic relations can be used to depict cultural systems, such as that organizing the classification of animals as mammals.
Figure 1.1 Types of systems.
Tracing such systems can be conceptually and computationally challenging. Researchers from an array of fields have formulated conceptual and analytic tools to help us see structures and to understand their importance. In fact, since the 1940s, the field of cybernetics has been an interdisciplinary attempt to unite the sciences through the study of various systems. As with a variety of other scientific endeavors, network analysis seeks to better understand the underlying reality that our world is structured by overlapping and often complex systems.
1.3 Origins of Network Analysis
Contributions to the origins of network analysis have come from a variety of other scientific domains with diverse analytical and theoretical orientations (see Freeman Reference Freeman2004 for a detailed history). Involved fields included graph theory (Euler Reference Euler1736), sociology (Davis, Gardner, & Gardner Reference Davis, Gardner and Gardner1941; Roethlisberger, Dickson, & Wright Reference Roethlisberger, Dickson and Wright1947 [1939]; Simmel Reference Simmel1909), education (Almack Reference Almack1922), anthropology (Barnes Reference Barnes1954; Nadel Reference Nadel1957), and psychology (Heider Reference Heider1946). In the early period, most of the effort was placed on developing a set of concepts, theories of tie formation (e.g., how individuals decide to become friends), and exploratory research on small groups (N < 100). It is in this era that fundamental theories and concepts emerged. Many of these early concepts and theories will be covered in this volume.
From the 1960s to the 1990s, the field witnessed a wide assortment of concurrent interdisciplinary work on social networks (Scott Reference Scott2002), mostly in the disciplines of sociology, anthropology, and social psychology. Much of this work focused on larger samples of persons and groups (N < 2,000), such as clubs, schools, and organizations. This work used more complex methods to analyze social systems than previous work. What became known as The Harvard School is exemplary of this period and centered on the work and ideas of Harrison White, a scholar with PhDs in physics and sociology. Academics aligned with this school of thought created mathematical approaches to identifying structurally equivalent persons in graphs (Lorrain & White Reference Lorrain and White1971), techniques for revealing network positions and their interrelations as role structures (White, Boorman, & Breiger Reference White, Boorman and Breiger1976), and approaches to the study of affiliation networks – that is, ties that are based on belonging to the same groups or events (Breiger Reference Breiger1974). From this school emerged other scholars who established many of the core concepts used in network analysis today; examples include Mark Granovetter’s (Reference Granovetter1973) notions of weak ties and structural embeddedness (Reference Granovetter1985), and Peter Blau’s (Reference Blau1977) notion of structural differentiation. Much of this work extended the core ideas of the prior generation (e.g., Nadel Reference Nadel1957; Simmel Reference Simmel1909) by exploring their mathematical elaboration and operationalization using mathematical models and statistical tools. What resulted was a fruitful period in social network analysis that produced complex descriptive research on groups and their relations and introduced hypothesis testing.
With the advance of computing and the popularization of the Internet in the 1990s, the size and availability of network information exploded, and scholars from the fields of engineering and physics entered en masse. Social scientists now share the stage in the development of network analysis with computer scientists (e.g., Kleinberg Reference Kleinberg2000; Leskovec, Kleinberg, & Faloutsos Reference Leskovec, Kleinberg and Faloutsos2005), physicists (e.g., Barabási & Frangos Reference Barabási and Frangos2002; Newman Reference Newman2003; Watts & Strogatz Reference Watts and Strogatz1998), and statisticians (e.g., Handcock Reference Handcock, Breiger, Carley and Pattison2003; Snijders Reference Snijders2001). Network analysis now regularly uses information on large, longitudinal graphs representative of entire populations (N > 2,000) and entails information on multiple species and phenomena – from humans to dolphins, from neurons to power grids. In addition, network analyses now examine multiple types of relationships between entities in the same network – from friendships to marriage, from advice-giving to chain of command. Network analysis also continues to harness advances in software, computational power, and analytical methods to encompass even more expansive networks, such as social media interactions with even millions of observations, and to look at different ways that people relate through texts, shared activities or identities, or memberships in groups and organizations. Network studies are also going deeper into individuals’ understandings of relationships through their perceptions of their own and others’ relations. Going beyond descriptive accounts, today, a variety of structural hypotheses can be tested, and issues of causation can be explored in the context of networks. Moreover, decision processes (and algorithmic models thereof) are becoming central to our understanding of network formation (Jackson Reference Jackson, Sertel and Koray2003, Reference Jackson2008). We further discuss some of these frontiers in our concluding chapter (Chapter 16).
In sum, the history of network analysis has been marked by steady conceptual, empirical, and methodological expansion, and by a cross-disciplinary focus on relational phenomena. However, in spite of the cross-disciplinary focus, the field lacks clear integration of the many theories and analytical methods now available to scholars. Network analysis is a pastiche of methods that span different software implementations and different disciplinary views, with no clear unifying perspective. Nearly every textbook on network analysis has been written for field-specific audiences by methodologists or authors using a field-specific set of tools and software packages. Moreover, there is a lack of awareness across fields currently engaging in network research – exemplified in particular by the tendency of hard scientists to overlook prior work in the social sciences only to “rediscover” what social scientists learned long ago. Physicists like Duncan Watts missed Granovetter’s notion of bridges and weak ties in his concept of small worlds; the concept of Google’s PageRankTM rests on the same metric as Bonacich’s notion of power centrality and the Friedkin–Johnsen centrality measure (see Friedkin & Johnsen Reference Friedkin and Johnsen2014); and even high-profile publications like Scientific American reproduce findings that social scientists identified decades prior (Paulos Reference Paulos2011; cf. Feld Reference Feld1991).
We see the need for a more integrative approach to network analysis. The potential for less redundant, more fruitful collaborations is possible if researchers can integrate what increasingly appears to be a transdisciplinary perspective distinct from other scientific views. In our view, this integration requires recognition of network analysis’s social scientific origins in theory and core empirical questions, and how these remain relevant to present research agendas and methods.
1.4 Social Network Analysis as a Field-Integrative Force
To clarify our motivations in writing this book, we begin with a clear statement of how we see the aims of network analysis. In our view, network analysis aims to characterize the pattern of transactions and relationships nested in the natural and social world and to examine both their antecedents and consequences. It entails understanding how associations form larger patterns and arrangements and how those relationships shift over time. Network analysis is grounded in systematic and purposeful data collection and analysis strategies, relies heavily on the use of graphic visualizations, and employs a far-reaching set of mathematical and computational models. Network analysis also encompasses efforts to understand how deeper structural principles shape relationships and how the configurations of relationships influence phenomena of interest, such as actor behaviors and attitudes.
The brief history we have related illustrates several clear divides in the growth of a transdisciplinary perspective of network analysis. The earliest period (from the 1930s to the 1950s) was denoted by mostly theoretical and qualitative research exploring basic concepts and relating them to social theory. The second period (from the 1960s to the 1980s) saw the emergence of a set of metrics and methods further elaborating network properties and their variation. Most recently (since the 1990s), a period of massive increases in scale and computing power has enabled network comparisons and hypothesis testing about network formation to a degree not previously possible. Each age has brought shifts in the type of scholar leading the charge – from theorist, to exploratory social scientist, to hypothesis-testing physical scientists and engineers – and a disconnect across what was learned in one era after the next.
In this text, we propose to integrate these views and to center the development of network concepts and methods around core questions of network structure and its formation. The key, we believe, is to tightly couple the methodological treatment with substantive questions that a researcher may hope to answer empirically. Such an approach is particularly important given the increasing availability of network data. Social networks and network thinking are more ubiquitous than ever because of the use of networking platforms like LinkedIn, Facebook, Instagram, and Twitter. Social networks are present in the endless number of forums, conversational threads, and streams of comments found on websites, online courses, and listservs. Companies, too, are awash with digital records and transactional data represented in streaming relational databases that they are not sure how to use.
In short, today research is experiencing a new empirical watershed of digitized communications, which has hastened the emergence of methodological transactionalism – that is, the capacity to empirically capture and theoretically explain interactions, which are frequently the traces of relations, observed at various levels from face-to-face encounters to global flows of goods (Kitts & Quintane Reference Kitts, Quintane, Light and Moody2020; McFarland, Diehl, & Rawlings Reference McFarland, Diehl, Rawlings and Hallinan2011). For much of the mid- to late twentieth century, the individual was a practical, reified source of information collected through surveys. Today, that information comes from digitized social transactions, and the streaming of relational information has made the individual merely a point buffeted along within rivers of transactional data.
So what is not to love for a social researcher? The trouble with much of the contemporary research on networks is that novices learn a single method, acquire a network data set (e.g., Twitter), and then without reflection apply the method to the data. This approach, like using a hammer so ubiquitously that everything comes to look like a nail, can often lead to poorly executed or inappropriate analyses given the data and research questions. Most methods appeal to a particular question or class of questions and therefore do not apply to every problem. In addition, the problem that a method was meant to address can often have little relevance to the focal phenomenon in question. For example, in studying who retweets whom, a researcher may pick up a few network ideas of social influence that were based on how individuals in small groups experience conformity pressures, using these to “make sense” of thousands of tweets among total strangers for whom the original network conformity pressures have almost no chance of actually operating. Thus, there is often a gap between technical capabilities and more conceptual understandings. And many treatments of current methods in network analysis have only widened this gap by presenting methods with little conceptual context.
In contrast, this volume offers an integrative approach to network analysis that will be useful for filling the gap between methodological sophistication and theoretical and empirical purpose. For those scholars lacking technical capabilities, this volume can fill the technical gap concerning how to do structural analysis while helping to build and develop their theoretical agendas. For those scholars with more advanced methodological skills, our approach can help to bring these technical capabilities to bear on the broader theoretical landscape to elucidate how, when, and why these methods are so vital. We will demonstrate repeatedly that what students of network analysis often think is a methodological problem is really a theory problem in disguise.
Our main conviction is that social networks are the best possible bases for illustrating intuitive examples that bring together theory and practice and thus help integrate the transdisciplinary field of network analysis. All researchers, regardless of their discipline, can relate to the social world – for example, through the common experiences of attending schools and coming of age in high school or its equivalent. Most people wanting to learn about networks share a common set of understandings and experiences rooted in tangible, if not often surprising, social network phenomena. The same cannot be said of the many other types of networks – neural networks, gene networks, and so on – that are the bases for other fields. These are vitally important areas of research, but they cannot help unify the field of network scientists; only social networks can. Social networks are historically the origins of the field, and we believe that social scientists hold a key source of knowledge that can lead the field forward into a more fully integrated transdisciplinary future.Footnote 1
1.5 Two Brief Examples
All networks comprise interdependent parts. But how do we illustrate and begin to analyze such interdependencies? A simple, yet powerful example of interdependence is easy to find in most American high schools and adolescents’ onset to sexual encounters. Figure 1.2 shows a network of sexual encounters – in this case, within a single high school in the Midwestern United States in the 1990s. Each dot is a student, and the connections represent one or more sexual encounters over the year.
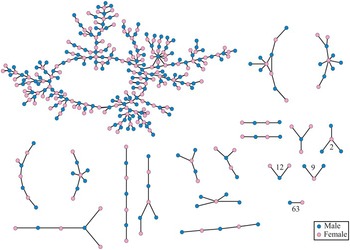
Figure 1.2 High school sexual relations network (Bearman, Moody, & Stovel Reference Bearman, Moody and Stovel2004)
The structure matters. Individuals with the same number of partners vary in important ways in their position in the larger structure. Some individuals are indirectly connected to a large portion of the network, vulnerable to a sexually transmitted disease (STD) spreading through the large branch-like structure shown at the top of the image. Others are more isolated. Thus, individuals with the same number of partners (i.e., exhibiting the same behavior) may have very different risk profiles. If the researcher wants to understand how such a structure comes about (its etiology), how it affords students different opportunities for sexual partners, and the implications for the transmission of (for example) STDs, then the overall connectivity of the structure and each individual’s position within that structure are of vital interest. The structure looks like a spanning tree because these youths mainly limited themselves to one or two romantic partners per year, mostly within the same school context. Some students more central to the network have greater access to other partners and are key players in the potential transmission of an STD within the school sex network. Clearly, taking these individuals and relationships out of context would lead to the omission of this vital information.
These structural principles can extend to other sorts of actors, such as countries. Figure 1.3 offers an illustration using three countries instead of people. The main question is whether Country C will attack Country B. From a network perspective, the answer depends not simply on the characteristics of Country C (e.g., its gross domestic product [GDP], military history, and party in power) but also on its relationship with Country A and the relationship between Country A and Country B. As shown in panel (b), Country C is in fact embedded in a larger system of relations: Country C is in a coalition with Country A, which in turn has attacked Country B. This means that Country C is allied with a country (A) that has gone to war with Country B. This may force Country C itself into a conflict with Country B (as an ally of Country A) even if B and C have no direct dispute with each other. In short, an enemy of a friend is an enemy. The behavior of Country C would be difficult to explain if one considers each country in isolation, as in panel (a).
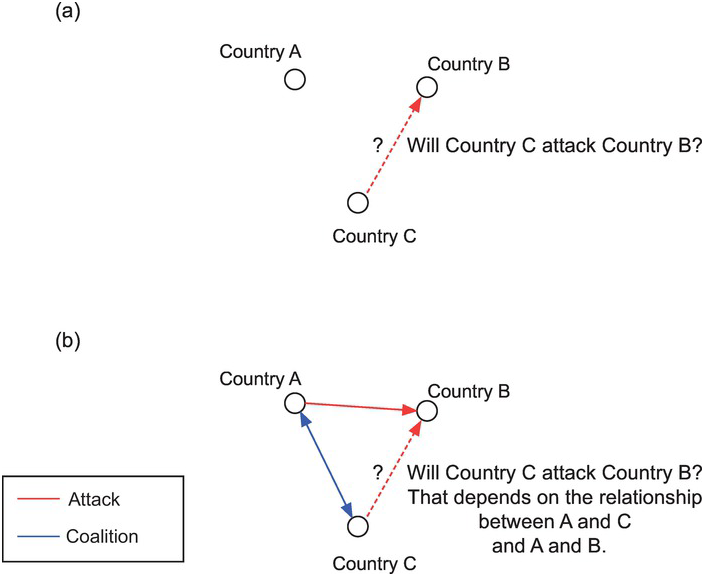
Figure 1.3 Structural forces in international relations
Hopefully, these brief examples and our discussion leading up to them has convinced you that structure matters and that social networks offer intuitive ways to begin to think about structures more broadly. But how to actually begin seeing and analyzing structures is no simple task and requires a set of tools.
1.6 Selecting the Best Tool for the Job
How should a researcher go about answering network-based questions? While there are many options, this book uses the R statistical programming language and platform to practically walk through the application of network analysis (R Core Team 2020).Footnote 2 We believe that R provides the best and most comprehensive set of tools, and becoming competent in this programming environment presents the fewest barriers for those with less coding experience. R is ideal, in part, because it avoids many of the drawbacks of other options, particularly those based on drop-down menus (i.e., point-and-click logic). Although these other packages often have a gently sloped learning curve, they make it difficult to custom-tailor the analysis to the data and research question under consideration. More importantly, they are not designed for replicability or extensibility. Accomplishing desired data transformations and routines to replicate analysis with these other packages often requires hacks involving a complicated give-and-take between a spreadsheet editor and other graphical user interface tools. This process is inefficient and error prone, and it can make diagnosing errors difficult. Moreover, these software packages are mostly stand-alone, closed-source applications, which means that building in additional functionality and creating methodological innovations are difficult, if not impossible.
In contrast, R has a vast array of powerful scripting functionality, exceptional visualization capabilities, and thousands of libraries to facilitate data management and statistical analysis. R excels in facilitating the development of new methods and approaches relative to other programming languages, while making it easy for an advanced R programmer to write interfaces to high-performance tools available in compiled languages, such as C and Java. It also interfaces with other environments (notably, Python), which is convenient for scientists and engineers who have already invested in those programming languages. Although no convention is a perfect solution, R has the added advantage of being shareware, both free to the user and open to improvements on existing techniques as well as the incorporation of techniques at the cutting edge. R also allows access to myriad other statistical methods that many network researchers will likely want to draw on in their analyses.
Obviously, no single and perfect tool exists for performing network analysis. The tutorials we offer as accompaniments to the following chapters are meant to be adaptable to a number of research interests and to set the practical foundation for the conceptual material we present in respective chapters. We believe that having a common research tool such as R is also a basis for integrating the field as researchers across disciplines and for building a shared language and repository for generic structural analyses.
1.7 Outline of the Book and User’s Guide
This book is the result of a collaboration among four social network scholars with distinct but overlapping areas of expertise. Rawlings has developed a number of ways to interrelate social structures with mental structures (e.g., attitudes, beliefs, tastes) using social network theories and methods. Smith has published work on social networks and health, methodological issues in network sampling and missing data, and has extensive experience in developing network methods in R. Both Moody and McFarland have published extensively on social networks, with particular strengths in building tools for better understanding dynamic social networks. Moody has additional strengths in social diffusion models and cohesion. McFarland has applied network methods extensively in educational and organizational settings. Together, the four of us have more than sixty combined years of experience teaching social network analysis at the undergraduate and graduate levels. We have sought to distill that collective experience into this volume.
The book can be many things for many different people. It is primarily offered as a research tutorial, offering students the opportunity to develop and answer questions that exemplary social network scholars ask when studying social phenomena. The book’s orientation is to introduce methods of social network analysis in a theoretically grounded fashion; it does not cover mathematical modeling and simulation except when necessary. We hope to take the reader through every step necessary to answer core questions and to learn how to evaluate and interpret empirical results. The material can be tailored for more general or specific goals. For the network scholar who is already familiar with network theory and methods but wants to become more proficient at R, the research tutorials afford an opportunity to move firmly into this new programming environment in a way that is more theoretically grounded than many other texts. Instructors of graduate or undergraduate courses might rely on the book in its entirety or instead choose portions that are appropriate to cover conceptual and empirical applications or laboratory work as the course requires.
Each chapter contains several elements: (1) identify core research questions; (2) relate the influential texts and their concerns bearing on these questions; (3) postulate an appropriate plan of analysis; (4) choose the appropriate methods (and compare them); and (5) interpret the results, their quality, and how to present them as findings. The text offers concrete examples – many from contexts most readers have experienced firsthand (e.g., classrooms) – with real data. The tutorials are available on the web at: https://inarwhal.github.io/NetworkAnalysisR-book/.
We divide the book into three main sections. Part I focuses on structural thinking, introducing the main concepts of network analysis, identifying the key visual and mathematical abstractions that form its core, and discussing issues of data collection. Parts II and III cover two, often interrelated, analytic goals of network analysis. The first, presented in Part II, concerns using a number of exploratory techniques to see structures at various levels and degrees of abstraction. In particular, we help the reader develop connectionist and positional perspectives on network structures. Part III concerns making structural predictions using a variety of more dynamic, longitudinal, and explanatory models.
No textbook can cover every method, and we have made some painful but necessary omissions. We therefore end each chapter, except for the conclusion, with a short list of works that will expand on some of the core ideas developed in the chapter, either by building depth or extending to detailed areas that are beyond the scope of the chapter itself. The universe of works we could include is vast, so any such lists are necessarily incomplete and idiosyncratic, but we hope these serve as useful jumping-off points for readers. In addition, given the rapid development of the field, it is likely that new techniques are currently being developed that could surely join those presented in the final sections of Part III. We hope to include such exciting new work in future editions.






