
84 results
Acute Fetal Metabolomic Changes in Twins Undergoing Fetoscopic Surgery for Twin-Twin Transfusion Syndrome
-
- Journal:
- Twin Research and Human Genetics , First View
- Published online by Cambridge University Press:
- 22 March 2024, pp. 1-8
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
NON-ISOMORPHIC SMOOTH COMPACTIFICATIONS OF THE MODULI SPACE OF CUBIC SURFACES
- Part of
-
- Journal:
- Nagoya Mathematical Journal , First View
- Published online by Cambridge University Press:
- 03 October 2023, pp. 1-51
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The well-studied moduli space of complex cubic surfaces has three different, but isomorphic, compact realizations: as a GIT quotient
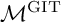 ${\mathcal {M}}^{\operatorname {GIT}}$, as a Baily–Borel compactification of a ball quotient
${\mathcal {M}}^{\operatorname {GIT}}$, as a Baily–Borel compactification of a ball quotient 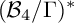 ${(\mathcal {B}_4/\Gamma )^*}$, and as a compactified K-moduli space. From all three perspectives, there is a unique boundary point corresponding to non-stable surfaces. From the GIT point of view, to deal with this point, it is natural to consider the Kirwan blowup
${(\mathcal {B}_4/\Gamma )^*}$, and as a compactified K-moduli space. From all three perspectives, there is a unique boundary point corresponding to non-stable surfaces. From the GIT point of view, to deal with this point, it is natural to consider the Kirwan blowup 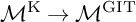 ${\mathcal {M}}^{\operatorname {K}}\rightarrow {\mathcal {M}}^{\operatorname {GIT}}$, whereas from the ball quotient point of view, it is natural to consider the toroidal compactification
${\mathcal {M}}^{\operatorname {K}}\rightarrow {\mathcal {M}}^{\operatorname {GIT}}$, whereas from the ball quotient point of view, it is natural to consider the toroidal compactification 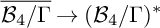 ${\overline {\mathcal {B}_4/\Gamma }}\rightarrow {(\mathcal {B}_4/\Gamma )^*}$. The spaces
${\overline {\mathcal {B}_4/\Gamma }}\rightarrow {(\mathcal {B}_4/\Gamma )^*}$. The spaces 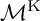 ${\mathcal {M}}^{\operatorname {K}}$ and
${\mathcal {M}}^{\operatorname {K}}$ and 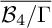 ${\overline {\mathcal {B}_4/\Gamma }}$ have the same cohomology, and it is therefore natural to ask whether they are isomorphic. Here, we show that this is in fact not the case. Indeed, we show the more refined statement that
${\overline {\mathcal {B}_4/\Gamma }}$ have the same cohomology, and it is therefore natural to ask whether they are isomorphic. Here, we show that this is in fact not the case. Indeed, we show the more refined statement that 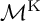 ${\mathcal {M}}^{\operatorname {K}}$ and
${\mathcal {M}}^{\operatorname {K}}$ and 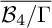 ${\overline {\mathcal {B}_4/\Gamma }}$ are equivalent in the Grothendieck ring, but not K-equivalent. Along the way, we establish a number of results and techniques for dealing with singularities and canonical classes of Kirwan blowups and toroidal compactifications of ball quotients.
${\overline {\mathcal {B}_4/\Gamma }}$ are equivalent in the Grothendieck ring, but not K-equivalent. Along the way, we establish a number of results and techniques for dealing with singularities and canonical classes of Kirwan blowups and toroidal compactifications of ball quotients.
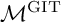
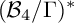
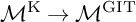
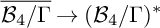
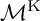
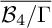
“EM Doc On Call:” A Pilot Study to Improve Interhospital Transfers in Rwanda
-
- Journal:
- Prehospital and Disaster Medicine / Volume 38 / Issue 4 / August 2023
- Published online by Cambridge University Press:
- 21 June 2023, pp. 456-462
- Print publication:
- August 2023
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Examining associations between genetic and neural risk for externalizing behaviors in adolescence and early adulthood
-
- Journal:
- Psychological Medicine / Volume 54 / Issue 2 / January 2024
- Published online by Cambridge University Press:
- 19 May 2023, pp. 267-277
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
DRAGON-Data: a platform and protocol for integrating genomic and phenotypic data across large psychiatric cohorts
-
- Journal:
- BJPsych Open / Volume 9 / Issue 2 / March 2023
- Published online by Cambridge University Press:
- 08 February 2023, e32
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Canadian Stroke Best Practice Recommendations: Acute Stroke Management, 7th Edition Practice Guidelines Update, 2022
-
- Journal:
- Canadian Journal of Neurological Sciences / Volume 51 / Issue 1 / January 2024
- Published online by Cambridge University Press:
- 19 December 2022, pp. 1-31
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Assessing the Impact of Secondary Fluorescence on X-Ray Microanalysis Results from Semiconductor Thin Films
-
- Journal:
- Microscopy and Microanalysis / Volume 28 / Issue 5 / October 2022
- Published online by Cambridge University Press:
- 25 May 2022, pp. 1472-1483
- Print publication:
- October 2022
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Simulating ice-shelf extent using damage mechanics
-
- Journal:
- Journal of Glaciology / Volume 68 / Issue 271 / October 2022
- Published online by Cambridge University Press:
- 07 March 2022, pp. 987-998
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Improving the generalizability of infant psychological research: The ManyBabies model
-
- Journal:
- Behavioral and Brain Sciences / Volume 45 / 2022
- Published online by Cambridge University Press:
- 10 February 2022, e35
-
- Article
- Export citation
Size at birth, lifecourse factors, and cognitive function in late life: findings from the MYsore study of Natal effects on Ageing and Health (MYNAH) cohort in South India
-
- Journal:
- International Psychogeriatrics / Volume 34 / Issue 4 / April 2022
- Published online by Cambridge University Press:
- 20 October 2021, pp. 353-366
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The contribution of provitamin A biofortified cassava to vitamin A intake in Nigerian pre-schoolchildren
-
- Journal:
- British Journal of Nutrition / Volume 126 / Issue 9 / 14 November 2021
- Published online by Cambridge University Press:
- 08 January 2021, pp. 1364-1372
- Print publication:
- 14 November 2021
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Reading Peer Review
- PLOS ONE and Institutional Change in Academia
-
- Published online:
- 01 January 2021
- Print publication:
- 04 February 2021
-
- Element
-
- You have access
- Open access
- HTML
- Export citation
Recreating the OSIRIS-REx slingshot manoeuvre from a network of ground-based sensors
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 37 / 2020
- Published online by Cambridge University Press:
- 27 November 2020, e049
-
- Article
-
- You have access
- HTML
- Export citation
What the COVID-19 pandemic entails for the management of patients with behavioral and psychological symptoms of dementia: experience in France
-
- Journal:
- International Psychogeriatrics / Volume 32 / Issue 11 / November 2020
- Published online by Cambridge University Press:
- 15 September 2020, pp. 1361-1364
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A culture-sensitive semi-quantitative FFQ for use among the adult population in Nairobi, Kenya: development, validity and reproducibility
-
- Journal:
- Public Health Nutrition / Volume 24 / Issue 5 / April 2021
- Published online by Cambridge University Press:
- 24 July 2020, pp. 834-844
-
- Article
-
- You have access
- HTML
- Export citation
Dental pain during repetitive transcranial magnetic stimulation
-
- Journal:
- European Psychiatry / Volume 19 / Issue 7 / November 2004
- Published online by Cambridge University Press:
- 16 April 2020, pp. 457-458
-
- Article
-
- You have access
- Export citation
Ecological release in lizard endoparasites from the Atlantic Forest, northeast of the Neotropical Region
-
- Journal:
- Parasitology / Volume 147 / Issue 4 / April 2020
- Published online by Cambridge University Press:
- 22 January 2020, pp. 491-500
-
- Article
- Export citation
Polygenic contributions to alcohol use and alcohol use disorders across population-based and clinically ascertained samples
-
- Journal:
- Psychological Medicine / Volume 51 / Issue 7 / May 2021
- Published online by Cambridge University Press:
- 20 January 2020, pp. 1147-1156
-
- Article
- Export citation
First principle study of the structural and electronic properties of Nihonium
-
- Journal:
- MRS Advances / Volume 5 / Issue 23-24 / 2020
- Published online by Cambridge University Press:
- 11 March 2020, pp. 1175-1183
- Print publication:
- 2020
-
- Article
- Export citation
Predicting hospital-onset Clostridium difficile using patient mobility data: A network approach
-
- Journal:
- Infection Control & Hospital Epidemiology / Volume 40 / Issue 12 / December 2019
- Published online by Cambridge University Press:
- 28 October 2019, pp. 1380-1386
- Print publication:
- December 2019
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
