
6 results
ESTIMATES OF DERIVATIVES OF (LOG) DENSITIES AND RELATED OBJECTS
-
- Journal:
- Econometric Theory / Volume 39 / Issue 2 / April 2023
- Published online by Cambridge University Press:
- 27 December 2021, pp. 321-356
-
- Article
-
- You have access
- Open access
- Export citation
INTEGRATED SCORE ESTIMATION
-
- Journal:
- Econometric Theory / Volume 33 / Issue 6 / December 2017
- Published online by Cambridge University Press:
- 05 December 2016, pp. 1418-1456
-
- Article
- Export citation
-
We study the properties of the integrated score estimator (ISE), which is the Laplace version of Manski’s maximum score estimator (MMSE). The ISE belongs to a class of estimators whose basic asymptotic properties were studied in Jun, Pinkse, and Wan (2015, Journal of Econometrics 187(1), 201–216). Here, we establish that the MMSE, or more precisely
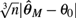 $$\root 3 \of n |\hat \theta _M - \theta _0 |$$, (locally first order) stochastically dominates the ISE under the conditions necessary for the MMSE to attain its
$$\root 3 \of n |\hat \theta _M - \theta _0 |$$, (locally first order) stochastically dominates the ISE under the conditions necessary for the MMSE to attain its 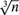 $\root 3 \of n $ convergence rate and that the ISE has the same convergence rate as Horowitz’s smoothed maximum score estimator (SMSE) under somewhat weaker conditions. An implication of the stochastic dominance result is that the confidence intervals of the MMSE are for any given coverage rate wider than those of the ISE, provided that the input parameter αn is not chosen too large. Further, we introduce an inference procedure that is not only rate adaptive as established in Jun et al. (2015), but also uniform in the choice of αn. We propose three different first order bias elimination procedures and we discuss the choice of input parameters. We develop a computational algorithm for the ISE based on the Gibbs sampler and we examine implementational issues in detail. We argue in favor of normalizing the norm of the parameter vector as opposed to fixing one of the coefficients. Finally, we evaluate the computational efficiency of the ISE and the performance of the ISE and the proposed inference procedure in an extensive Monte Carlo study.
$\root 3 \of n $ convergence rate and that the ISE has the same convergence rate as Horowitz’s smoothed maximum score estimator (SMSE) under somewhat weaker conditions. An implication of the stochastic dominance result is that the confidence intervals of the MMSE are for any given coverage rate wider than those of the ISE, provided that the input parameter αn is not chosen too large. Further, we introduce an inference procedure that is not only rate adaptive as established in Jun et al. (2015), but also uniform in the choice of αn. We propose three different first order bias elimination procedures and we discuss the choice of input parameters. We develop a computational algorithm for the ISE based on the Gibbs sampler and we examine implementational issues in detail. We argue in favor of normalizing the norm of the parameter vector as opposed to fixing one of the coefficients. Finally, we evaluate the computational efficiency of the ISE and the performance of the ISE and the proposed inference procedure in an extensive Monte Carlo study.
THE ET INTERVIEW: HERMAN BIERENS
- Part of
-
- Journal:
- Econometric Theory / Volume 29 / Issue 3 / June 2013
- Published online by Cambridge University Press:
- 14 November 2012, pp. 590-608
-
- Article
- Export citation
TESTING UNDER WEAK IDENTIFICATION WITH CONDITIONAL MOMENT RESTRICTIONS
-
- Journal:
- Econometric Theory / Volume 28 / Issue 6 / December 2012
- Published online by Cambridge University Press:
- 21 May 2012, pp. 1229-1282
-
- Article
- Export citation
EFFICIENT SEMIPARAMETRIC SEEMINGLY UNRELATED QUANTILE REGRESSION ESTIMATION
-
- Journal:
- Econometric Theory / Volume 25 / Issue 5 / October 2009
- Published online by Cambridge University Press:
- 01 October 2009, pp. 1392-1414
-
- Article
- Export citation
ADDING REGRESSORS TO OBTAIN EFFICIENCY
-
- Journal:
- Econometric Theory / Volume 25 / Issue 1 / February 2009
- Published online by Cambridge University Press:
- 01 February 2009, pp. 298-301
-
- Article
- Export citation
