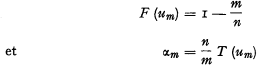4 results
A new look at Belgian aeromagnetic and gravity data through image-based display and integrated modelling techniques
-
- Journal:
- Geological Magazine / Volume 130 / Issue 5 / September 1993
- Published online by Cambridge University Press:
- 01 May 2009, pp. 583-591
-
- Article
- Export citation
Bayesian Inference in Credibility Theory
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 8 / Issue 2 / September 1975
- Published online by Cambridge University Press:
- 29 August 2014, pp. 164-174
- Print publication:
- September 1975
-
- Article
-
- You have access
- Export citation
-
In 1967, Bühlmann has shown that the credibility formula was the best linearized approximation to the exact Bayesian forecast.
His result for the credibility factor
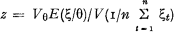 can be found back by means of some Bayesian inference techniques. Introducing a uniform prior probability density function for the credibility factor provides us with a method for estimating z, a correction term to the Bühlmann's result is obtained. It is shown how prior boundary conditions can be introduced.
can be found back by means of some Bayesian inference techniques. Introducing a uniform prior probability density function for the credibility factor provides us with a method for estimating z, a correction term to the Bühlmann's result is obtained. It is shown how prior boundary conditions can be introduced.
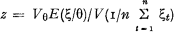 can be found back by means of some Bayesian inference techniques. Introducing a uniform prior probability density function for the credibility factor provides us with a method for estimating
can be found back by means of some Bayesian inference techniques. Introducing a uniform prior probability density function for the credibility factor provides us with a method for estimating Détermination de la Fonction de structure d'une classe de Tarif
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 7 / Issue 3 / March 1974
- Published online by Cambridge University Press:
- 29 August 2014, pp. 223-236
- Print publication:
- March 1974
-
- Article
-
- You have access
- Export citation
-
Le dépouillement statistique d'une classe de tarif hétérogène permet d'observer les fréquences relatives qi des contrats qui pendant une période de référence ont été frappés de (i — 1) sinistres.
On a:

et

Ces fréquences déterminent dans l'espace Rm un vecteur à m composantes, que nous notons:
Une base de décomposition est constituée par un éventail fini de η classes homogènes. Chaque classe homogène Ck est définie par une variable aléatoire, dont la loi de probabilité
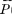 (λk) dépend du paramètre λk. Théoriquement ce paramètre peut être tout à fait général (un triplet réel p.e.); pour les applications pratiques traitées au paragraphe 4, il suffit pourtant de considérer λk comme un nombre réel.
(λk) dépend du paramètre λk. Théoriquement ce paramètre peut être tout à fait général (un triplet réel p.e.); pour les applications pratiques traitées au paragraphe 4, il suffit pourtant de considérer λk comme un nombre réel.Si Pi(λk) représente la probabilité à priori d'avoir exactement (i — 1) sinistres dans la classe Ck, nous pouvons noter
(λk) par: (p1(λk), p2(λk), … Pm(λk))On a:

et

Nous supposons que les vecteurs
(λk) sont linéairement indépendants.Résoudre l'hétérogénéité d'une classe de tarif consiste tout d'abord à choisir une base de décomposition, à représentation analytique connue, et puis à décomposer la classe de tarif par l'éventail des classes homogènes Ck de cette base.


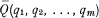
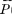 (λ
(λ

Theorie des valeurs extremes et la tarification de l'excess of loss
-
- Journal:
- ASTIN Bulletin: The Journal of the IAA / Volume 3 / Issue 2 / August 1964
- Published online by Cambridge University Press:
- 29 August 2014, pp. 163-177
- Print publication:
- August 1964
-
- Article
-
- You have access
- Export citation
-
Soit x1 ≤ x2, ≤ … ≤ xn—m + 1 ≤… ≤xn—p+1≤…≤ xn un échantillon ordonné de taille n d'une distribution dont F(x) et T(x) sont respectivement la fonction de répartition et la fonction de densité.
Nous appelons xn—m+1 la valeur de rang m de l'échantillon (x1, x2,…xn).
Pour simplifier l'écriture nous remplacerons partout l'indice n — m + I par m.
Avec cette convention nous notons la valeur caractéristique de rang m et l'intensité de rang m respectivement par um et αm [I].
Par définition on a:
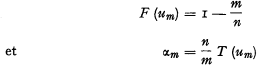
Notons enfin par Fm (x) et Tm (x) la fonction de répartition et la fonction de densité de xm pour n → ∞ et m fixe.
2.1. Avant de résumer les différents points traités dans cette note, rappelons les particularités qui caractérisent la distribution asymptotique de la plus grande valeur x1 d'un échantillon. On sait que cette distribution existe si et seulement si la fonction de répartition F(x) appartient à un des trois types suivants [2]:
a) Type I: F(x) est du type exponentiel.
Le domaine de x est illimité vers la droite et F(x) tend vers I pour x → + ∞ au moins aussi rapidement qu'une fonction exponentielle.
Tous les moments de F(x) existent.
b) Type II: F(x) est du type de Cauchy.
Le domaine de x est illiminté vers la droite.