



Introduction
How can the different linguistic modalities modulate the profile of concrete concepts like space and abstract ones like time? Historically, it was suggested that Deaf children have a broader concrete thought than hearing children (Myklebust & Brutton, Reference Myklebust and Brutton1953) and that perception has a greater cognitive weight in the conceptualization of the Deaf population (Zwiebel & Mertens, Reference Zwiebel and Mertens1985). These results might suggest that sign languages inhibit abstract thinking. However, any language results from abstraction and demands abstract thinking from its users. The concreteness/abstractness distinction can be approached from different perspectives, for example, in relation to the availability of sensorimotor access to domains of experience. In the case of sign languages, many lexical items are biased toward iconicity that highlights concrete features of referents. Even more, some types of iconicity present in sign languages (Taub, Reference Taub2001), such as structure mappings, are a somewhat abstract process. Other venue of the abstractness is on how semantic relations between lexical items are organized in semantic memory. Therefore, it is hasty to conclude about the abstract thinking in Deaf population without specifying the definitions and their scope.
Borghi et al. (Reference Borghi, Binkofski, Castelfranchi, Cimatti, Scorolli and Tummolini2017) agree that all concepts are flexible, that is, context-dependent. However, concrete concepts are more stable over time and shaped more by everyday experiences, situations, and culture (Barsalou, Reference Barsalou and Neisser1987). Concrete concepts, such as CHAIR, have physical boundaries with senses that anyone can identify. These characteristics prime broader and more prolonged arrangements in the processing of concepts and their characteristics. In contrast, abstract concepts are further removed from physically identifiable referents. While both concrete and abstract concepts are associated with elements of context, the latter seems to involve more events and actions and thus evoke more complex contextual information than concrete concepts (Borghi & Binkofski, Reference Borghi and Binkofski2014; Connell & Lynott, Reference Connell and Lynott2012). Finally, Borghi et al. (Reference Borghi, Binkofski, Castelfranchi, Cimatti, Scorolli and Tummolini2017) suggest that perceptual and action information is more relevant to concrete concepts, whereas linguistic information is mostly expressed with abstract concepts. Concreteness/abstractness nuances can be explained in a gradient approach.
We opted for integrative theories to include all these types of information in a unified theoretical approach to semantics. These approaches consider sensorimotor, linguistic, and social information as relevant to the processing and characterization of both concrete and abstract concepts with different mechanisms (Borghi et al., Reference Borghi, Binkofski, Castelfranchi, Cimatti, Scorolli and Tummolini2017). Representational Pluralism (Dove, Reference Dove2009), Language and Situated Simulation (Barsalou, Reference Barsalou2008), and Words as Social Tools (Borghi & Cimatti, Reference Borghi and Cimatti2009) are examples of integrative theories.
Semantic knowledge is represented by various ways of relating concepts. As Radden and Dirven (Reference Radden and Dirven2007) suggest, the conceptual domain is the general field to which a category or frame belongs in a given situation. As an example, a frying pan belongs to the domain “cooking” when it is used to fry an egg, but to the domain “fighting” when it is used as a weapon in a domestic dispute.
Taxonomic relations are those in which concepts are organized hierarchically from the least inclusive to the most inclusive level or vice versa (i.e., “mammals” is a higher category that includes dogs, wolves, cows, and cats or “space” is higher than height and width). Concepts belonging to a taxonomically organized domain are related to each other by virtue of the characteristics they share (i.e., dogs, wolves, cows, and horses are mammals because of the presence of mammary glands which in females produce milk for feeding their young). However, taxonomic relations seem not exclusive to physical concrete features of entities as those referred to in previous examples. For example, “Cause” and “Effect” are antonymous but they do not indicate concrete features such as those of the color or the size of any object. The taxonomic organization allows for a cost-effective way of processing information, facilitating its retrieval for future applications, enabling analogies and problem-solving, and promoting the development of new knowledge (Borghi et al., Reference Borghi, Binkofski, Castelfranchi, Cimatti, Scorolli and Tummolini2017).
In contrast, the thematic organization of a domain makes it possible to relate one concept to another based on its co-occurrence in an event or situation. This organization includes spatial and temporal associations between agents, objects, and patients of an action (Borghi & Caramelli, Reference Borghi and Caramelli2003; Estes et al., Reference Estes, Golonka, Jones and Federmeier2011). Furthermore, they allow the contextual organization of experience as well as the establishment of predictions for similar future situations.
Both processes—comparison and integration—and organizations—thematic and taxonomic—are available for human minds (Borghi & Caramelli, Reference Borghi and Caramelli2003; Siegler & Shipley, Reference Siegler, Shipley, Simon and Halford1995; García Coni et al., Reference García Coni, Ison and Vivas2019). Both types of organization correspond to different cognitive mechanisms: taxonomic relations predominantly activate a process of comparison between objects and thematic relations activate a process of integration (Vivas & García Coni, Reference Vivas and García Coni2013).
The hierarchical and increasingly inclusive organization of taxonomic knowledge allows the generation of lexical pieces that are gradually far from physically identifiable referents, includes more events and actions in each lexical piece, and increases the relevance of emotional (psychophysiological reactions and associated internal states concerning the perception of objects or the evocation of previous experiences) and linguistic information to identify and interpret those lexical pieces. Lindquist (Reference Lindquist2023) suggests that emotional words, and the concepts they name, are critical in the creation of perceptions and experiences of emotions, including those that serve to represent abstract concepts. Ponari et al. (Reference Ponari, Norbury, Rotaru, Lenci and Vigliocco2018) found that children up 8–9 years old learned better abstract words such as “Agility,” “Danger,” or “Style” with emotional associations than neutral abstract words. In contrast, concrete concepts are near to physically identifiable referents, include aspects of specific events/actions, and increase the relevance of sensorimotor information. Here we suggest taking the taxonomic organization of lexical semantics as an index of an abstract construal and the thematic organization as an index of a concrete construal of domains of experience.
In linguistics, a syntagmatic relation defines the relationship between words that co-occur in the same sentence. In a word association task, syntagmatic responses are words that follow the stimulus in a syntactic sequence (e.g., COLD-outside) or words that share a thematic relationship with the stimulus (e.g., COLD-sweater, COLD-winter). Syntagmatic relations can be derived from tangible perceptual and conceptual experiences.
Likewise, a paradigmatic relation is concerned with the way words are grouped together into categories, like nouns, verbs, adjectives, etc. Paradigmatic responses represent more abstract and taxonomic linguistic relations. In repeated association mode, access to semantic relations, particularly paradigmatic ones, becomes progressively more difficult as semantic activation traverses the network (Sheng & McGregor, Reference Sheng and McGregor2010).
Besides, Deyne et al. (Reference De Deyne, Kenett, Anaki, Faust, Navarro and Jones2017) argued that word association is a unique and useful tool because it is an expression of thought. In these tasks, the demands of syntax, the morphology, and pragmatics are removed. At the moment, other authors also advocate for using word association for understanding semantic networks (Dubossarsky et al., Reference Dubossarsky, De Deyne and Hills2017; De Deyne et al., Reference De Deyne, Navarro, Perfors, Brysbaert and Storms2019; Siew et al., Reference Siew, Wulff, Beckage and Kenett2018).
Spoken and sign language
Comparative studies of the mental lexicon between spoken and sign language are scarce. Marschark et al. (Reference Marschark, Convertino, McEvoy and Masteller2004) studied the organization and use of the mental lexicon in Deaf and hearing speakers using a single-response free association task. Their results indicated a general similarity in the organization of lexical knowledge in both groups, with stronger associations between category names and exemplars for hearing speakers. Mann & Marshall (Reference Mann and Marshall2012) conducted a repeated free association task with American Sign Language (ASL) Deaf children and hearing English children. Their results showed similar patterns in the responses of Deaf subjects and monolingual English-hearing subjects. For the authors, these results suggest that language development in sign and spoken languages is governed by similar learning mechanisms, based on the development of semantic networks.
Dong and Li (Reference Dong and Li2015) indicate that bilinguals of two spoken languages tend to integrate conceptual differences between translation equivalents. However, the authors find that bilinguals display a tendency to maintain the L1 conceptual system for L1 words and to adopt the L2 conceptual system with L2 words. Additionally, the authors found that at the very early learning stageFootnote 1 of an L2 word, L2 learners are more dependent on their L1: learning an L2 is a process of integrating conceptual differences in two languages. Then if a specific Deaf-signing population remains in an early learning stage of a spoken language such as Spanish, it might be expected that the aforementioned conceptual integration is far from being.
To characterize the notion of linguistic modality (limited in our case to the sign vs. spoken contrast) in its different aspects, below we will discuss some semiotic, linguistic, psycholinguistic, and sociolinguistic differences and similarities between sign and spoken languages that can discriminate between the mental lexicon of Deaf signers and hearing speakers. In this study, the notion of language modality does not preclude the suggestion of the multimodality approach (i.e., McNeil, Reference McNeil1979; Perniss, Reference Perniss2018; Perniss & Vigliocco, Reference Perniss and Vigliocco2014). This approach considers language an integrated system with gesture and speech as components. In the following lines, when we compared language modalities, we refer to the grammar-lexical component based on conventionalized gestures for sign languages and vocalized sounds for spoken ones. It is not our aim to be exhaustive in each aspect, but only to highlight in each one some points that we understand to be of interest to the mental lexicon and its processing.
Iconicity
Within semiotic aspects, although there is a substantial number of arbitrary lexical items in sign languages, the literature considers a greater pervasiveness of iconic lexical items in sign languages than in spoken ones (Cuxac & Sallandre, Reference Cuxac, Sallandre, Pizzuto, Pietrandrea and Simone2007; Klima & Bellugi, Reference Klima and Bellugi1979; Taub, Reference Taub2001; Wilcox, Reference Wilcox2000. For a review, Perniss et al., Reference Perniss, Thompson and Vigliocco2010). Wilcox (Reference Wilcox2000, p. 123) describes iconicity as a resemblance relation between two construals: one of the real-world scenes and the other of the form of the objects of reference. The aforementioned resemblance can be understood as a structure mapping (Gentner, Reference Gentner1983; Gentner & Markman, Reference Gentner and Markman1997) because iconic items imply a comparison process between a semantic representation (i.e., past meaning) and a visual (i.e., moving hand over the shoulder front to back) or acoustic (i.e., use the word “behind” in expressions such as “The past left behind”) representation of a linguistic form (Emmorey, Reference Emmorey2014). The literature recognizes some types and degrees of iconicity in sign languages (i.e., pantomimic and perceptual) with alternative mechanisms such as indicating the shape, the size, or the proximity of the referent (Dingemanse et al. Reference Dingemanse, Blasi, Lupyan, Christiansen and Monaghan2015).
Another alternative is to classify the iconicity in line with the pattern of similarity matching between an aspect of form and one of meaning. Such an approach differentiates between absolute and partial iconicity. Onomatopoeia is a case of the former and the so-called diagrammatic iconicity is a case of the latter. Diagrams offer a semantic structural correspondence between form and meaning (Dingemanse et al. Reference Dingemanse, Blasi, Lupyan, Christiansen and Monaghan2015). Padden et al. (Reference Padden, Meir, Hwang, Lepic, Seegers and Sampson2013) aimed to describe the iconicity as a shared property among groups of signs (pattern iconicity). Finally, Ortega et al. (Reference Ortega, Sümer and Özyürek2017) indicate that at the lexical level “… signs exploit a wide range of iconic depicting strategies to represent the same referent …”. Several of these strategies involve an object and the manipulation of it (i.e., handling), outlining its shape (i.e., shaping), or using a body part to represent it (i.e., instrument).
In contrast to spoken languages, the sublexical iconicity of sign languages has its potential in that the phonological pole of the signs is formed by components of the human body spatially exposed to the interlocutors (hands, torso, face, and head). This iconicity is relative to the referents involving the body motricity (the ability to move or use one’s muscles to produce movement. It is the capacity to control and coordinate the movement of one’s body and limbs) associated with actions, emotions, or the perception of concrete objects, and their eventual use as a basis for providing meanings to lexical pieces by some mapping mechanisms such as metaphors or metonymies. Furthermore, although iconicity is not absent in spoken language (Dingemanse et al., Reference Dingemanse, Blasi, Lupyan, Christiansen and Monaghan2015; Perniss et al., Reference Perniss, Thompson and Vigliocco2010), it relies mostly on internal components of the human body, not exposed to interlocutors (i.e., larynx, tongue, alveoli, etc.). Furthermore, imaginability, that is, the ease of imagining the meaning of a word (partly due to its iconicity), is a property of words/signs that correlates with the abstraction (Kousta et al., Reference Kousta, Vigliocco, Vinson, Andrews and Del Campo2011).
As suggested by Rodriguez-Cuadrado et al. (Reference Rodríguez-Cuadrado, Ojedo, Vicente-Conesa, Romero-Rivas, Sampedro and Santiago2022), iconicity relies on concreteness. The referents of concrete concepts are accessible as sensorimotor information (i.e., seen, heard), and it is possible to interact with them (see Borghi et al. (Reference Borghi, Binkofski, Castelfranchi, Cimatti, Scorolli and Tummolini2017). Speakers can use the physical appearance of these referents to guide the formation of iconic items. We share the theoretical approach (Lakoff & Johnson, Reference Lakoff and Johnson1980) that argues that the human mind gets grounded in concrete concepts and includes regular mechanisms such as conceptual metaphor and metonymy. For this approach, items for abstract concepts can become iconic to the physical appearance of those referents. Concerning the vocabulary of sign languages, this approach affords the distinction between iconic and arbitrary signs for abstract concepts (Taub, Reference Taub2001; Wilcox, Reference Wilcox2000).
A fundamental difference is that signs are better at iconically representing the concepts they denote and have their symbolic matter in space (Taub, Reference Taub2001). This is due to the high potential for semantic access based on the spatial substrate of signs and the analogy of signs with relevant sensorimotor information. Manhardt et al. (Reference Manhardt, Ozyurek, Sumer, Mulder, Karadöller and Brouwer2020) found visual attentional differences between “thinking for speaking” from “thinking for signing” during message preparation. They suggested that iconicity can mediate the link between language and human experience and guides signers’ but not speakers’ attention to visual aspects of the world. Despite the aforementioned pervasive iconicity in sign languages, Hohenberger and Leuninger (Reference Hohenberger, Leuninger, Pfau, Steinbach and Bencie2012, p. 718) point out that there is no difference in the processing of iconic and non-iconic signs between spoken and sign languages. For instance, iconicity plays no role in lexical retrieval. However, Ortega and Morgan (Reference Ortega and Morgan2015), studying the sensitization of iconic signs in the mental lexicon of hearing adults, suggested that this population (hearing speakers who do not sign) process iconic signs in the manner of gestures. Signers, on the other hand, use a different mechanism to process iconic signs. Authors such as Sehyr and Emmorey (Reference Sehyr and Emmorey2019) found that the perception of the mapping between form and meaning in ASL depends on linguistic knowledge and task. The effort to create linguistic models not based on vocal language tools, categories, terminology, and analyses has a large trajectory. Throughout most of the twentieth century, different models proposed to describe sign languages were based on a hierarchy: only the lexical units (i.e., standardized in form and meaning signs) were considered at the core of the language, while the “productive signs” (i.e., iconic constructions) were pushed to the linguistic borderline, closer to the level of gesticulation and mime (Capirci et al., Reference Capirci, Bonsignori and Di Renzo2022).
In the last decades, some scholars (i.e., Cuxac, Reference Cuxac1999; Capirci et al., Reference Capirci, Bonsignori and Di Renzo2022; Wilcox & Occhino, Reference Wilcox and Occhino2016) found in Piercian semiotics and Cognitive Linguistics theoretical frames for overcoming the hierarchical approach to language modeling. Finally, Capirci et al. (Reference Capirci, Bonsignori and Di Renzo2022) suggest a model in which signs’ different iconic, symbolic, and indexical features are detectable in the single linguistic sign. For them, the dominance of the feature will determine the different use of the linguistic unit.
Signs and lexemes
Within linguistic aspects, Johnston and Schembri (Reference Johnston and Schembri1999, p. 126) distinguish between signs and lexemes. For these authors, the latter are fully conventionalized pieces and can be stored as a lexicon of a language. The following paragraphs present some research on classifiers in sign languages as they may affect vocabulary and mental lexicon across linguistic modalities. The difference between a lexicalized sign and one with a classifier is that the latter responds to the discursive domain. That is, for example, a verb with a classifier such as “to walk” is not lexicalized in the Uruguayan Sign Language (LSU). The classifier allows the signer to modify this sign to the point of adapting the predication of the verb WALKING to the discursive interest. The signer can point with the sign to walk forward or to turn the corner to the left or the right. Schembri (Reference Schembri2003, p. 18) shows a number of difficulties in finding a description of classifiers that can be transversal between spoken and sign languages. What is relevant to the phenomenon of classifiers for this study is their presence in both linguistic modalities, the differences in the way that they operate (i.e., usually for nominals and noun phrases in the spoken language, but for verbs and verb phrases in sign language), their strong relation with discourse, the difficulties and lack of consensus in finding definitions that might satisfy what happens in both modalities and the closed character of these pieces.
For example, in Spanish, to quantify a noun such as “ganado” (Cattle), it is necessary to use a classifier that links the numeral to the noun. In this case, “cabezas de” (heads of) is a classifier between the lexical items “Tres” (Three) and “Ganado” (Cattle). The phrase “Tres ganado” (three cattle) is ungrammatical. A classifier is needed for the count of the nominal (Cattle). In sign languages, as in some Asian spoken languages such as Chinese Mandarin, classifiers are more standard (i.e., 棵 kē is a tree’s classifier). It means that the same classifiers can be used for different nouns.
For sign languages, Zwitserlood (Reference Zwitserlood, Pfau, Steinbach and Bencie2012, p. 158) described the classifiers as “… morphemes with no-specific meaning which are expressed by particular configurations of the manual articulator and which represent entities by denoting salient characteristics…”. The status of classifiers as lexical items is controversial and there are different approaches to them (see Emmorey, Reference Emmorey2003). Furthermore, studies on errors in German Sign Language (DGS) production (Leuninger et al., Reference Leuninger, Hohenberger, Waleschkowski, Carson Schütze and Ferreira2007) suggest that the bipartition of the mental lexicon into a lemma and a lexeme component seems to be valid for both language modalities (for spoken languages). For example, in Spanish and LSU, Mesa de luz (Light table) is constituted by the lemma mesa (table) and the lexeme luz (light). Finally, factors such as familiarity, phonological neighborhood, and frequency of lexical pieces are equally relevant factors with important similarities in the processing of spoken and sign languages (Carreiras et al., Reference Carreiras, Gutiérrez-Sigut, Baquero and Corina2008).
Earliness and lateness in language exposition, iconicity in early vocabulary, and early lexical development in Deaf children
Within psycholinguistic aspects, the current literature on lexical organization and development of the Deaf has three main lines of discussion relevant for a comparative perspective as this of our manuscript: the debate about (a) the role of early experience in signing for early stages of lexical development, (b) the weight of iconicity on early vocabulary, and (c) the sign advantage in early lexical development for Deaf over hearing speakers.
-
(i) Language deprivation relates to the first line of discussion because this kind of privation is understood as the lack of linguistic stimuli that are necessary for the language acquisition processes. Early exposure to a first language—in our case, a sign language, LSU, and a spoken language, Spanish—is considered a predictor of future language and cognitive outcomes. For example, Mayberry et al. (Reference Mayberry, Chen, Witcher and Klein2011) found an “age-of-acquisition effect”: more activation in the posterior visual brain regions of deaf adults exposed late to ASL and less in the anterior linguistic brain regions while viewing sentences in ASL. The opposite was true for deaf adults exposed earlier to ASL. The authors interpreted late exposure to mean that linguistic information was more likely to be processed as visual information, a much less efficient means of language processing. Additionally, Caselli et al. (Reference Caselli, Hall and Henner2020) found that language deprivation has adverse effects on phonological processing, sign recognition speed, and accuracy. In a more general scope, these authors found that the form organizes the lexicons of both spoken and sign languages, that the recognition of lexicon occurs through form-based competition, and that form-meaning mappings do not drive lexical access even when iconicity is pervasive in the lexicon.
-
(ii) Regarding early vocabulary, Meier et al. (Reference Meier, Mauk, Cheek and Moreland2008) reported that iconicity is not a major factor in children’s phonological performance of their first signs. However, studies with the adapted MacArthur-Bates Communicative Development Inventories for some sign languages (American [Caselli et al., Reference Caselli, Pyers and Lieberman2021], British [Woll et al., Reference Woll, Meurant, Sinte, Herrmann, Steinbach and Zeshan2013], and Turkish [Sumer et al., Reference Sumer, Grabitz, Küntay, Gunzelmann, Howes, Tenbrink and Davelaar2017]) show conflicting evidence. Also, Lutzenberger (Reference Lutzenberger2018) shows how iconicity plays a role in the phonological development of sign language-acquiring children. Additionally, semantic categories seem a relevant factor in organizing the early vocabulary of sign-exposed children (Chen Pichler, Reference Chen Pichler, Pfau, Steinbach and Bencie2012, p. 659).
-
(iii) Finally, the sign advantage in early lexical development grounds the assumption that the parameters of the signs develop earlier than those of spoken languages. Consequently, Deaf children can produce lexical pieces earlier than hearers and accelerate the earlier stages of language development. Some studies support these claims (Bonvillian et al., Reference Bonvillian, Orlansky, Folven, Volterra and Erting1990; Morgan & Meier, Reference Morgan and Meier2008), and others do not (Meier & Newport, Reference Meier and Newport1990).
The environment
In asymmetric cross-modal language contact contexts, the main spoken language affects the development of a minority sign language and its spaces of use may be extremely limited (i.e., in the Deaf association, in the family if the parents or siblings sign). In these contexts, sign languages are viewed as misappropriated in some situations with the devaluation of sign languages. The minority sign language speaker would be forced to be fluent in the written form of the majority oral language, with the loss of features of the minority sign language (Adam, Reference Adam, Pfau, Steinbach and Bencie2012, p. 842).
This situation might inhibit the coining of new signs for the subjects of those contexts and the interest of the Deaf community to generate a more standard use of some signs. The effects of language contact include a range of phenomena such as borrowings and loans, interference, convergence, foreign talk, code-switching, language shift, language attrition, language decline, and language death (Thomason, Reference Thomason2001).
Furthermore, cross-modal language borrowing might have an impact on the lexicon of another language. McKee et al. (Reference McKee and Wallingford2011) described the importation of spoken lexical pieces into sign languages. This importation occurs through fingerspelling, mouthing, initialized sign formations, and loan translation. Foreign forms are another alternative. They combine structural elements of two languages, sometimes by mouthing and initialized signs. Adam (Reference Adam, Pfau, Steinbach and Bencie2012, p. 847) indicates that bilingual individuals (i.e., LSU-Spanish or vice versa) are instrumental in introducing new usages and coinages from a second language to the community. Nevertheless, Plaza-Poust & Weinmeister (Reference Plaza-Pust and Weinmeister2008, in Plaza-Poust, Reference Plaza Pust, Pfau, Steinbach and Bencie2012) showed that lexical and structural borrowing between German and German Sign Language (DGS) occurs at specific developmental stages for both languages and decreases as speakers progress and become fluent. Genesse, (2002, in Plaza-Pust, Reference Plaza Pust, Pfau, Steinbach and Bencie2012) demonstrated that individual variations in sign languages showed patterns similar to those found in comparative studies between spoken languages.
Cross-modal bilingualism is a set of situations in which more than one cross-modal second language is used by all or a large set of members of a community (bilingualism) or only a select group of members of this community is bilingual (bilinguality) in a cross-modal fashion. As indicated by Adam (Reference Adam, Pfau, Steinbach and Bencie2012, p. 847), lexical borrowing “… occurs when speakers in contact with another more dominant language (i.e., a spoken language such as Spanish) perceive a gap or a need of reference to new foreign concepts in their first language (i.e., LSU)…” As a result, the lexicon of the non-dominant language expands or new lexical pieces substitute existing pieces.
The present study
Space and time are universal experience domains for human beings. They are candidates for being salient in any language and culture. The Cognitive Linguistics approach (i.e., Lakoff & Johnson, Reference Lakoff and Johnson1980) considers space as a concrete domain of experience in that the human organism is posited to have perceptual-motor access to domain-specific information (i.e., sight and touch give us sensoriomotor spatial information about how tall or short a person is). In contrast, time is regarded as an abstract domain insofar as the absence of such sensorimotor access to domain-specific information (i.e., the orange color of the skyline and the low position of the sun are by themselves spatial information perceived by sensorimotor channels, but they are used for indicating or meaning a time interval of the day). Providing these spatial insights with a temporal meaning is not part of the visual information perceptual capture.Footnote 2 As we indicated in the Introduction, there are some criteria for describing what is abstract or concrete. Then, in this study the concreteness/abstractness of space and time are domains considered as contrastive according to the criteria of access to sensoriomotor information, as it is done in the Cognitive Linguistics (Evans, Reference Evans2012) and Embodied Cognition (Wilson, Reference Wilson2002) frameworks.
This description of the concrete and the abstract has been evidenced in populations of different cultures and with verbal, non-verbal, and gesturing means. For a review, see Núñez and Cooperrider (Reference Núñez and Cooperrider2013), Bender and Beller (Reference Bender and Beller2014), and Callizo-Romero et al. (Reference Callizo-Romero, Tutnjević, Pandza, Ouellet, Kranjec, Ilić, Gu, Göksun, Chahboun, Casasanto and Santiago2020). However, the representation of space and time in spoken and sign languages presents similarities and differences whose effect on conceptualization and mental lexicon is still an open issue.
Unlike spoken languages, in sign languages, space is the substance in which linguistic production takes place. Wilcox and Martínez (Reference Wilcox and Martínez2020) suggest that the conceptualization of space in sign languages is manifested semantically and phonologically. This conceptualization gives semantic and phonological value to the space around the signer (sign space) and other locations (i.e., that of the objects to which the signer points, the location of those objects, and the movement of those objects in space) in a complex symbolic structure. This difference with spoken languages may suggest differences in linguistic modality important for the conceptualization of space and spatial memory (for the relation between spatial language and spatial memory in the Deaf population, see Karadöller et al., Reference Karadöller, Sümer, Ünal and Özyürek2022).
This research asks whether Deaf and hearing people have the same conceptual organization and construal profile (concrete vs. abstract) of the domains of time and space. Furthermore, we delve into what semantic networks can tell us about the memory processes involved in the conceptual categorization of both Deaf and hearing populations. Semantic networks show how memory describes the organization of declarative facts and knowledge in the mind (see Collins & Loftus, Reference Collins and Loftus1975). The value of this research lies in the evidence it provides about the similarities and differences of the “construal profile” of space and time mental lexicon between linguistic modalities, considering that the language modality could explain the variability of these construals. The study aimed to describe the components of the time and space domains in the Deaf-signing population of LSU and the Spanish-hearing population of Uruguay through a free word association task. It also sought to contrast the domains of interest between these two populations to explore the effects of linguistic modality on the conceptualization of the domains of time and space.
This study hypothesized that if the linguistic modality differences have effects on conceptual categorization, then there might be biases between types of categorization or construals by modality consistent with alternatives in the use of sensorimotor, linguistic, and social information. Because iconicity relies on concreteness (in which sensorimotor information becomes more relevant) and iconicity is pervasive in sign languages, Deaf signers may prefer semantic relations more sensitive to sensorimotor information and concrete construals than hearing speakers. Preferences could take the form of a bias toward concrete construals of the domains of space and time for the signer population (mostly syntagmatic responses and semantic relations of entity and situation), but not for the hearing population.
In our search for an instrument that is balanced in terms of evoking perceptual-motor, social, and linguistic information, free word association tasks seem an appropriate paradigm for a first approach (De Deyne et al., Reference De Deyne, Navarro, Collell and Perfors2021). This paradigm allows for the capture of all types of responses (syntagmatic vs. paradigmatic), all types of semantic relations (taxonomy vs. entities vs. situation vs. introspection), and all types of lexical pieces (open vs. closed). To answer our research questions, we performed what we call a repeated free word association task with dual-class (open such as nouns or verbs and closed such as conjunctions and prepositions) pieces in a concurrent domain clue format. That is, dichotomous lexical pieces as members of the same domain (e.g., ABAJO [Down] and ARRIBA [Up] for the spatial domain and PASADO [Past] and FUTURO [Future] for the temporal domain) were presented in the target concepts, in addition to filler clues. In this way, we believe it is possible to prime an intra-domain response from participants in both populations (i.e., Deaf and hearing) and to have more powerful data for between-group comparisons.
Regarding how time is expressed in sign languages, Pereiro and Soneira (Reference Pereiro and Soneira2004, pp. 65–66) suggest that time is coded by using lexical items, grammatical elements, or timelines. The authors mention three predominant timeline expressions in sign languages around the world: one perpendicular to the signer’s body, the other located in front of the signer’s body, and the last labeled as the growth line. Sign languages studied so far (Emmorey, Reference Emmorey2001) present together a wide repertoire of timeline alternatives. Bringing together the various timelines mentioned in different Sign Languages (i.e., American, Australian, British, Danish, French-Belgian, Spanish, and other three cases), Sinte (Reference Sinte, Herrmann, Steinbach and Zeshan2013) proposed a set of six unidimensional timelines and a grid labeled as a plane.
In contrast, in spoken languages, only some spatial lexical items are used with temporal value. For example, back, forward, up, and down words do (i.e., Spanish expressions such as El pasado quedó atrás “The past is behind us” makes sense but El futuro quedó a la derecha “The future left to right” does not). Instead, left and right words have no temporal value in any spoken language (Haspelmath, Reference Haspelmath1997).
This research asks whether Deaf and hearing people have the same conceptual organization and construal profile (concrete vs. abstract) of the domains of time and space. Furthermore, we delve into what semantic networks can tell us about the memory processes involved in the conceptual categorization of both Deaf and hearing populations. Semantic networks show how memory describes the organization of declarative facts and knowledge in the mind (see Collins & Loftus, Reference Collins and Loftus1975).
Method
Ethics statement
Informed consent in LSU was obtained from each of the Deaf participants and written informed consent was obtained from each of the hearing participants. This study was approved by the Human Research Ethics Committee of the Psychology Department of the Universidad de la República (Uruguay).
Openness, transparency, and reproducibility
The dataset, materials, scripts, and code application generated during the current study are available in the Open Science Framework repository at https://osf.io/5uv2f/
Population and participants
The Uruguayan Deaf community is estimated at 30,000. Belloso (Reference Belloso2009) counted 7,000 users of LSU. The closeness to Brazil and Argentina has introduced sociolinguistic variations to LSU. Parks and Williams (Reference Parks and Williams2013) have described two dialectal variations (Montevideo and Salto, near the Argentina border) but highlight a few differences between them (e.g., in number signs and the manual alphabet). In 2014, the career in LSU-Spanish interpretation and translation (“Carrera de Tecnólogo en Interpretación y Traducción LSU-español,” TUILSU) was established in Salto and Tacuarembó. This initiative strengthened contact between these two Deaf communities and another one in Tacuarembó (87 km from the Brazilian border). In 1986, “… Deaf children could receive their education in one of four special schools in Montevideo, Salto, Maldonado, or Rivera, attend special classes for Deaf students at regular schools, or a combination of these alternatives …” (Parks & Williams, Reference Parks and Williams2013). In 1987, aides for hearing teachers were incorporated in some schools. These assistants are fluent LSU Deaf signers. They support Deaf students in their curricular learning, teach them LSU, and promote awareness of Uruguayan Deaf culture among Deaf students. Today, secondary education has a bilingual and bicultural teaching model. In this system, Deaf students learn LSU as part of the curriculum. In addition, the national public education authority offers LSU instruction to Deaf students who were late exposed to LSU and hearing students. The Instituto de la Comunidad Sorda de Uruguay (Incosur) and the TUILSU offer courses for Deaf and hearing students. For more details about the Uruguayan Deaf Community, see Peluso (Reference Peluso2020, p. 63). This author notices an important process of lexical and semantic expansion and influence of Spanish in the LSU started in the last decade of the 20th century.
The Uruguayan Spanish is a variety of River plate Spanish (Argentina and Uruguay) with 3.4 million speakers. The closeness to Brazil has resulted in solid linguistic contact with Brazilian Portuguese. The early contact with the native languages of South America (i.e., Guarani) left lexical pieces in Uruguayan Spanish, such as “Che” [Yo] or “Pororo” [Pop corn]). Also, European languages such as Italian [i.e., Pibe “Kid”], Basque, Galician, or French [Liceo “Highschool”], as a result of 19th and 20th centuries migrations, have been added to Uruguayan Spanish. The Spanish language arrived in Uruguay in the 17th century.
Sixty-two participants (30 Deaf signers and 32 hearing speakers), matched in age (M = 30, SD = 8,8) and education (secondary, 36; undergraduate, 24), performed a repeated word association task in their respective languages and with semantically equivalent lexical pieces. Of the Deaf participants, 24 were Deaf by birth, 19 had Deaf family members, 18 had LSU as their language of instruction in primary school (it was their age of exposure to LSU), and 12 did so in secondary school. Hearing participants were not fluent in LSU and did not sign. At the time of recruitment, all participants—Deaf and hearing nonsigner ones—were asked if they had a neurological or psychiatric background, preferably medically documented. None of them reported having one.
Materials
Thirty-nine signs were used as clues (20 temporal clues such as AYER (Yesterday) and DESPUÉS (Later or After)), seven spatial clues such as ARRIBA (Up) and ATRAS (Back), and 12 fillers (i.e., NADAR [Swimming]). The imbalance between the temporal and space LSU clues in the materials has justifications. There are few adverbial and prepositional space signs in LSU. We included in the materials almost all the recognized (ASUR, 2007; TUILSU, 2018) LSU signs that indicate spatial and time relationships by themselves. Like other sign languages, the LSU frequently incorporates the adverbial place information in lexical pieces such as verbs but does that with time information less frequently. State verbs and those of motion with locative classifiers are clear examples in LSU, for example, “To-be-lying” and “Put-book-in-high-library-stand.” The former sign indicates the flat horizontal body position in a down space. The latter indicates the book’s carry toward the library’s upper space.
The lexical pieces with the best available semantic matching between Uruguayan Spanish and LSU were used for each clue. They were distributed in two lists (one of 20 pieces and the other of 19 pieces). For each lexical item (clue), a team of five specialists in LSU linguistics (professional interpreters and LSU teachers in Montevideo, Salto, and Tacuarembó) and Uruguayan Spanish selected the sign-word pair. The team included three native LSU Deaf signers with an intermediate level of Spanish literacy aged between 32 and 50. All were born into a hearing family and one was Deaf by birth. It also included two specialists who are native Uruguayan Spanish speakers aged between 31 and 50, who are highly fluent in LSU.
There are some cases with differences (Mañana [possible Spanish meanings: Morning or Tomorrow]—LSU Tomorrow and Tarde [possible Spanish meanings: To be late, Evening, or Afternoon]—LSU To-be-late. The aforementioned team tried to reduce these situations as much as possible. The experimental stimuli are available at Table 1 (see https://osf.io/5uv2f/). In this repository, the archives WORDLSU1.xlsx and WORDLSU2.xlsx show the list of the individual videos (available in the same repository in mpg format) of the signs used as stimuli (clues). In addition, WORDOY1.xlsx and WORDOY2.xlsx give the list of the Spanish words used as stimuli (clues) for Spanish-hearing nonsigners. The archive CLUE_KIND.xlsx lists the clues by kind (space and time vs. fillers) and adds their English translation.
Procedure
The experiment was programmed in Psychopy version 2.02.02 (Peirce, Reference Peirce2007) and conducted in a sound-attenuated room. Stimuli were presented at the center of a laptop screen (spanning 6.23o of visual angle; video and word stimuli used the entire screen). The distance between the screen and the participant was 0.80 m. A session lasted approximately 50 minutes. For Deaf participants, instructions signed in LSU were presented on the screen at the beginning of the task. Then, to help participants understand the task, they watched a pre-recorded video with signed instructions performed by a Deaf person in LSU. Following the instructions, three examples of a participant performing the task were provided. Afterward, the applicant asked participants if they had any question about the instructions. If the participant required further explanation, it was provided by the applicant in LSU for the Deaf and in Spanish for hearing nonsigners.
Deaf signer participants were asked—in LSU—to sign three LSU signs that came to mind after viewing a signed LSU clue. At the beginning of each trial, a fixation cross was presented for 500 ms. before a randomly chosen clue appeared on the screen. Each signing clue was shown twice on the screen during a 7-second video. Next, LSU participants turned slightly in their seats to be recorded by a digital video camera as they signed their three associate LSU signs.
In contrast, hearing nonsigners were asked—in Spanish—to write three Spanish words that came to mind after viewing a written Spanish clue. They typed their responses on the keyboard. In order to assure analogous timing, for hearing nonsigners, each clue written in Spanish was shown for 7 seconds on the screen. For both groups of participants, a number sequence—from 1 to 3—was used on the screen to monitor their responses. The sequence appeared on the screen as an indication to provide each one of the three associates. Both groups of participants pressed a key to advance to the next trial. Participants repeated this procedure until all trials were completed. Participants were not given a time limit. They took approximately 20 to 30 minutes to complete the task. The experimental design (textInputTest.xlsx, LEXICOLSU1.psyexp, LEXICOLSU2.psyexp, LEXICOOYUYU1.psyexp, and LEXICOOYUYU2.psyexp) is available at https://osf.io/5uv2f/
Design and translation criteria of associates provided by Deaf
First, the responses of the Deaf participants were translated into Spanish by the aforementioned team of Uruguayan Spanish and LSU specialists (see “Materials”) When necessary, this team contacted the Deaf participant to clarify their video-recorded responses. The translation procedure adjusted to the next criteria:
-
a. In several cases, it was necessary to define whether the label in Spanish refers to a single lexical item in LSU or several. It was needed to differentiate between syntagmatic compound signs, juxtaposed compound signs, and the phrases themselves. We considered that the labeling responds to the categorical function of the lexical piece in LSU. Still, using Spanish as a graphic support for writing entails specific considerations since the translatological transposition is not a one-to-one correspondence, that is, term to term. Therefore, we use the “-” when the lexical unit of meaning in LSU needs more than one word in Spanish for its correspondence. For example, the labeling FALLING-WATER instead of raining or OPEN-WINDOW as a unique label.
-
b. If it were only one lexical piece, it was not decomposed. Instead, the grammatical type of the complete piece is labeled. For example, the label JUMPING-ELASTIC-BED as a verb.
-
c. If it is not a single lexical piece, the translation team decomposed it into its components, and the grammatical type of each one was labeled. For example, the label WEEK + JESUS (holy week) was a noun for the former and the latter.
-
d. The label, in several cases, showed specifications used to maintain meaning. In those cases, we should take it as one piece. For example, the variation of signs to open depends on what is opened. For example, the labelings OPEN-THE-DOOR versus OPEN-THE-WINDOW for two different signs referred to open.
-
e. In other cases, the over-specification points to a variety of an object or situations, so the team decomposed the pieces and gave them their labels. For example, SEAT-BACK for referring to the seat at the end of the row.
-
f. In other cases, the lexical item changes its grammatical type between languages. This item is the case of non-nominalized references that remain as verbs. For the first case, we have the labels for ESTUDIAR (studying), TRABAJAR (working), BAILAR (dancing). This set of verbal vocabulary in LSU does not undergo phonological variations when used in a nominal form. These verbs go by to function as nominals but have no changes at the phonological level, only functional changes. For example, in the LSU, each one of the Spanish pairs of forms, such as ESTUDIAR-ESTUDIO (studying vs. study), TRABAJAR-TRABAJO (working vs. job), or BAILAR-BAILE (dancing vs. dance), has the same phonological form.
-
g. In sign language, the agglutinative incorporation of information is widespread into the sign. A clear example is verbs that incorporate adverbs of mood in their lexical structure by intensifying some of their phonological parameters. For example, the labeling contrasts for CORRER vs. CORRER-RAPIDO (running vs. run-fast) ESCRIBIR vs. ESCRIBIR-LENTO (writing vs. writing-slow). Table 2 shows the detailed result with the categorial function of the associates (see https://osf.io/5uv2f/). The responses of the Spanish participants were inputted directly into the laptop.
Kind of analysis and unification
Psychopy created an individual spreadsheet for each participant, assigning a line to each clue. To deal with the variability of responses, extensive work was required to ensure that associated lexical pieces conveying the same meaning were recorded identically, within, between, and across tracks, as well as across languages. It was also important to ensure that associated lexical pieces with different meanings were recorded with different labels. These recording procedures constituted a process called unification.
This data treatment involves the adjustment of most of the associated lexical pieces produced by the participants. It must be executed without altering the original content of the associates. There are at least two important reasons for unifying the meaning of the associates. Firstly, to capture regularities in the production of semantic relations related to a conceptual domain; for this purpose, the variety of spontaneous formulations of associates must be reduced. Secondly, the unification of the associated words is required in order to make correct computations. On the one hand, variables such as frequency of production (i.e., the number of participants who wrote/signed a certain associate within a specific concept) would be miscalculated if the associates were not unified within each clue. On the other hand, variables such as distinctiveness (which depends on the number of clues in which a certain associate appears) would not be calculated correctly if the associates were not unified across all tracks.
Two types of analysis were undertaken. The first was performed to describe the semantic network structures for the two populations and compare them. The second was performed to identify and label the type of semantic relations of the signs/words associated with the clue. The unification strategies—normally used when conducting a norming feature study—were different for each type of analysis. To describe the semantic network, unification aimed to capture the most conceptual core between the clues and the associates. To identify and label the type of semantic relations, the information of the clues and associates’ grammatical categories (e.g., verbs, adverbs, nouns, and adjectives) were helpful to the analysis as their conceptual core. From the perspective of Cognitive Linguistics (authors such as Langacker, Reference Langacker1987), which underpins this study, verbs imply a conceptualization of the referent as a process and nouns as an entity. That is, grammatical differences such as these represent different strategies of conceptualization.
What about the weight of possible semantic loss caused by the unification process? We do not know the evidence for considering this situation relevant to this kind of study (norming studies) aims. McRae et al. (Reference McRae, Cree, Seidenberg and McNorgan2005) indicated that it is critical to ensure that features that differ in meaning are given distinct labels. Responses (associates) were interpreted conservatively, and the unification team verified the validity of all the interpretations. It was necessary not to alterate the feature’s names because it is unclear where to draw the line. As done by McRae et al. (Reference McRae, Cree, Seidenberg and McNorgan2005), we were as conservative as possible because understanding that the differences in feature meanings form a continuum. Then, as the same authors, it was unclear where to draw a line regarding when to create two or more features versus when to leave them alone.
Raw forms provide relevant insights for studies, such as discourse analysis which describes the meaning in some orders with a set of theoretical framings (i.e., systemic functional approach, Halliday, Reference Halliday1978) and for describing conceptualization differences by the kind of construal evoked by the lexical pieces in terms of clear distinctions such as entity vs. procedure (Langacker, Reference Langacker1987) suggested by Cognitive Linguistics approaches.
Because we claimed the participants for single words /signs associated with each clue, the Unification procedure fits lemmatization. Natural language processing and computational linguistics provide extensive literature about lemmatization for sign and spoken languages. For illustration, we refer to Kristoffersen Troelsgård (Reference Kristoffersen, Troelsgård, Granger and Paquot2010) and Hochgesang et al. (Reference Hochgesang, Crasborn, Lillo-Martin, Bono, Efthimiou, Fotinea, Hanke, Hochgesang, Kristoffersen, Mesch and Osugi2018) for sign languages.
Describing and comparing the semantic network structures
The Definition Finder test (Vivas et al., Reference Vivas, Lizarralde, Huapaya, Vivas and Comesaña2014) was used for the initial analysis by loading the data into this software. Definition Finder is a helpful tool to measure the strength of association between the associated pieces and the clue. The output allowed us: to measure the set of features around a clue as ordered by decreasing weight; to generate a degree of coincidence of the features of a concept for a given linguistic community; to know the frequency of occurrence of each trait, the order of occurrence, and the weight of each trait. The coincidence between the participants’ responses (i.e., the associate provided after a clue) is coded by normalized numerical values between 0 and 1, with 1 being the highest weight or the highest coincidence. The result is a text document for each clue with a list of associates ordered according to their weight. For example, for the Antes “Before” clue, Preparar (to prepare) is first associated with .695; Lavarse los dientes (to-brush-teeth), second, with .138, and Dormir (to sleep), third, with UNIQUE. After this procedure, the associates that are provided only one time (to sleep in the previous example) by the participants are removed because they do not generate commonality. When there are some populations in the study, as is the case, this procedure generates a text for each clue for each population.
Next, the outputs provided by the Definition Finder, n.text, were (all the texts for each clue together) processed by the Synonym Finder softwareFootnote 3 (Vivas et al., Reference Vivas, Montefinese, Bolognesi and Vivas2020) to obtain information about the similarities between the concepts. This tool uses the cosine between vectors and defines the standard n-dimensional inner product for Euclidean space to compare vectors using the angle they form with each other. The software generates a square-1 matrix mode: columns and rows refer to the same set of entities. For example, if the clues Arriba “Up” and Abajo “Down” had a numerical value of .10, then there is little overlap in the set of associates provided for the population for the concepts “Up” and “Down.” This matrix is done for each population for all the clues. At the same time, when comparing between populations, the populations’ responses are added to a single matrix. In this case, the software is fed with the text outputs of all the examined populations’ clues. For example, if the pair with the clue Arriba for Deaf population (Up-D) and that for hearing nonsigning population (Up-H) had a numerical value of 1, then there is complete overlap (identity relation) in the associates provided for both populations for this concept (Up).
Next, a hierarchical cluster analysis was carried out with the previously generated square distance matrix on the generated similarity matrix, applying Johnson’s (Reference Johnson1967) method to analyze the emerging clusters. In this software, parallel vectors represent the highest similarity (cosine of 1), and orthogonal vectors represent the highest dissimilarity (cosine of 0) (Kintsch, Reference Kintsch2000).
Finally, with the square-1 matrix generated with the examined populations together, the Netdraw routine embedded in UCINET 6 (Borgatti et al., Reference Borgatti, Everett and Freeman2002) was used to plot the clusters produced by modifying (increasing) the association level requirement. This tool allows clustering by higher cohesion (smaller distance) between subgroups and with respect to the whole and applies Multidimensional Scaling (MDS) to reduce the dimensions before plotting. The data (crude and unified for both groups) and the analysis of the network are available at https://osf.io/5uv2f/
Describing the semantic relationships
We adapted the coding instruments created by Wu and Barsalou (Reference Wu and Barsalou2009) and Wiemer-Hastings and Xu (Reference Wiemer-Hastings and Xu2005) to include closed-class linguistic pieces and concrete and abstract pieces. In line with the aforementioned coding, the adapted instrument retained its four semantic categories (Entity, Situation, Introspection, and Taxonomy) but changed subcategories and added new ones. For example, habitual actions performed by third parties with or in front of an entity were added as a subcategory of the entity category. Thus, clue-associate relationships such as STAIRS-go up can be labeled as an action to be performed (going up) by someone when being in front of STAIRS. The direction of the relationship between the clue and the associate is what is most relevant. For example, the semantic relation between the pair BACK (as space)-see is not the same as the relation SEE-back. In the former, the clue refers to a place and an activity—seeing—that can be done when being in a later space. In the latter, the clue refers to an activity—seeing—and a spatial reference to do it. Given that space is a feature of situations and that the associated—seeing—cannot have a taxonomic relation to BACK as in the case of FRONT, an alternative for encoding the semantic relation between BACK-seeing is S (Situation)-action. That is, “see” is an action to be performed when being at the back of the space. Alternatively, since “see” is an action to be performed in a situation and pointing to some place, S-loc (location) is an appropriate encoding.
We have already mentioned that when translating the signed associates to Spanish for statistical analysis, the translation team considered the grammatical category of the associates. This condition was helpful for semantic relationship analysis. The adequate forms were included in the Unification spreadsheets (i.e., in LSU there is not a noun form for “swimming” (natación) but a verb sign. Then, in the Unification spreadsheet, the translation of these pieces was the Spanish verb form (nadar)). We pursued to have both languages a single instrument for the classification of the semantic relationships between each clue and its associates by a team of judges with a deep understanding of the coding instrument. Due to the difficulty of our access to the Deaf community and the lack of sufficient time for Deaf colleagues (those that have already participated in the translation team and others) to be involved as judges, it was decided to have a team of hearing-only judges.
Four analyses of the level of agreement among judges were conducted, each with different subject groupings: all; experts only; non-experts only; and all but the most different. Because the judge’s panel did their discriminations with the translation to Spanish of the associate signs provided by the signers. With all judges, Krippendorff’s alpha yielded a value of 0.82. This value is considered an acceptable level of agreement among judges. Next, the intra-group agreement values in experts and non-experts were compared. When comparing the values of both subgroups, the non-experts showed a higher coding agreement. Considering this, it is possible that there was a difference of opinion among some of the judges and their colleagues. The all-but-the-most-different analysis was repeated six times, leaving out one judge in each iteration. The result was that the best level of agreement among judges was achieved by excluding one of the expert judges. The responses of the latter were sufficiently dissimilar that adding them to the pool of judges reduced the level of agreement. Table 3 shows the results (see https://osf.io/5uv2f/).
Criteria for registering and recording
Considering the aforementioned criteria (section Kind of analysis and unification) and this study’s use of a word association task in which participants were asked to provide a word/sign as a response, an unification team (one Deaf specialist in LSU [she participated at the translator’s team] and four hearing specialists [one of them a LSU specialist who participated at the translator’s team]) adapted the unification criteria proposed by McRae and colleagues (Reference McRae, Cree, Seidenberg and McNorgan2005) as follows:
-
1. Each noun or adjective associate was unified in gender and number according to the most frequent choice in the data (e.g., DIA [Day] was unified into DIAS [Days], which appeared most often in the raw data). Other similar cases include AMIGOS, DOCTOR, and GENTE.
-
2. Each associated verb was coded in the infinitive form (e.g., IR [Go] instead of FUIMOS [We_went]).
-
3. When it served to unify concepts across groups, conceptually overlapping associates were coded with their root lexemes. For example, ESTUDIAR [Studying] (verb) was more frequent in the Deaf population and ESTUDIO [Study] (the action of learning) was more frequent in the hearing population. Both alternatives were unified in ESTUD*. Other similar cases include the label ENFERM* for ENFERMERA and ENFERMERAS and ACAB* for ACABAR and ACABADO. A similar approach was taken with synonymous words. For example, FIESTA [Party] and FESTEJO [Celebration] were coded as FEST*, HERMOSO and HERMOSURA as HERMOS*, and DESCANSO and DESCANSAR as DESCAN*. In another case, DOS_PISOS was merged with DOS_PLANTAS [Two_floors].
-
4. Because signs and words do not always have equivalents or a sign is sometimes translated in the spoken language as an expression or a set of words, the underscore “_” has been used to indicate that the words form a single sign. This concerns the specificity of both languages and allows for conceptual correspondence between populations. In cases such as LAVARSE_LOS_DIENTES [Brushing_teeth], this lexical item occupies one associated word as LAVARSE and another as LAVARSE_LOS_DIENTES.
-
5. Where the aforementioned specificity of signs refers to common expressions among the populations, the associated ones were not split. For example, MARCHA_ATRAS [Go_back] or DOS_PLANTAS.
-
6. When participants provided sentences or phrases as responses, nouns, adjectives, verbs, and adverbs were selected as individual associates in the order in which they appear in the sentence. For example, NO PUEDO ESCRIBIR [I cannot write] was coded, first, NO [No], second, PODER [Can], and third, ESCRIBIR [Write].
-
7. In cases such as the above, articles and pronouns were ignored. For example, LAVARSE_LOS_DIENTES was coded as LAVARSE_DIENTES. It should be remembered that in the case of LSU, this was done taking into account the form of the original lexical pieces.
-
8. Clues were excluded when they were provided in the participants’ responses. The exception was when they were components of a compound lexical piece with a different semantic value. For example, for the clue SEMANA [Week], SEMANA_SANTA [Holy_week], or FIN_DE_SEMANA [Weekend].
-
9. When the clue was included in the associate, the criterion of taking only the informative part of the associate was followed. For example, for the clue DERECHA (right as spatial location or direction of movement), the associate LADO_DERECHO [Right_side] was coded as LADO [Side]. In this case, AL was removed according to criterion 6. This occurred in the Deaf but not the hearing sample.
For the reasons given in the last paragraph of “Criteria for registering and recording”, criterion 3 was removed from the unification for labeling the type of semantic relationship.
Results
We did two kinds of analysis: the structural properties and the construals’ profile of the semantic network. First, to feature the structural properties, the first step was to compare the overall structure of the semantic networks of the two language modalities. For comparing language groups (LSU Deaf vs. Spanish-hearing nonsigners), as was our aim, it was necessary to create a quadratic squared-1 matrix with the data of both groups. Then, we measured the correlation and semantic distances between the language groups using Pearson’s correlation with the quadratic matrix. The next step was to do a clustering analysis of the matrix’s data. This step aimed to group the clues by the similarity of their features (the similarity of their associates). This procedure helps find patterns and segments in the semantic network. Finally, to add more evidence on the similarities and differences between the semantic network of the language groups, we measured the diversity of responses between these groups with an entropy analysis.
Second, we did an attribute category analysis to feature the construal’s profile. To do so, we adapted a panel coding procedure of the relation between a clue and each associate created by Wu and Barsalou (Reference Wu and Barsalou2009) for norming studies such as this one with a similar purpose. The coding tool was validated by Krippendorff’s alpha coefficient, which is a statistical measure of the agreement achieved when coding a set of units of analysis. Finally, because of the satisfactory agreement between judges, the chi-squared test was used to evaluate the significance of the differences in the semantic labels (construal’s profile) the two language groups provided.
Semantic networks analysis
Overall semantic network comparison between language modalities
The Quadratic Assignment Procedure (QAP) was used to compare the overall structure of the semantic networks of the two language modalities. This procedure can be divided into two parts. In the first part, the correlation and distance coefficients (Simple Matching, Jaccard, Goodman-Kruskal Gamma, and Hamming distance) between the cells corresponding to both matrices are calculated. In the second part, the rows and columns of a matrix are randomly (synchronously) permuted and the correlation and distances are recalculated. This second step was performed for 2,500 iterations to calculate the proportion of times a random measure is greater than or equal to that observed during the first step.
Due to the parametric nature of the measurements, Pearson’s correlation was considered the appropriate alternative to examine the level of correlation between the semantic networks of the two groups. The calculation was done with the data provided by the square-1 matrix of distance (“Describing and comparing the semantic networks structures.”) previously generated with the associate supplied by participants to each clue. This matrix displays the calculation of each clue for each group (i.e., WEEK for the Deaf group and WEEK for the hearing one). The results of Pearson’s correlation for the time and space clue-associated pairs show a minimal correlation between the two groups (p = .118). In contrast, the same statistical test for clue-associate of fillers shows a higher correlation between the two groups (p = .423). That is, only a small proportion of the variation in the semantic network of space and time domains of one group is explained by the variation in the semantic network of the other. However, for the fillers, this proportion increases over three times. The complete statistics (document NETWORK_ANALYSIS, sheet QAP_TEST) can be seen at https://osf.io/5uv2f/.
Clustering
We notice that the responses of Deaf and hearing groups were analyzed altogether (using the Square-1 matrix aforementioned) because it is a comparative study, as mentioned in the aims of the study. An adequate procedure for doing a comparative study needs to guarantee the register of the structural properties of the semantic populations in same-fashioned matrixes. Then, it is necessary to create a quadratic squared-1 matrix with the data of the matrixes of all the examined groups for doing comparisons. Thus, if the semantic networks between groups are similar, a single semantic network will have clusters with shared nodes between all the populations. The semantic network analysis was obtained by means of a matrix composed of the representations of the 39 concepts, separated according to linguistic modality (78 nodes in total). This matrix contains the semantic distances between each pair of clues, according to the distributions of their associates. To construct this matrix, those associated pieces present in at least two clues were selected. From a total of 1,179 unique associates, 110 met the above criteria (9.3 %). The semantic distances were calculated by establishing the correlation between the concepts, using the geometric technique of vector comparison in an n-dimensional Euclidean space by cosine similarity. Parallelism (cosine equals 1) represents maximum similarity, while orthogonality (cosine equals 0) represents maximum difference.
As a result of this calculation, a mode-1 square matrix was generated (Borgatti & Everett, Reference Borgatti and Everett1997), which considers the semantic distances between each pair of concepts. The final square matrix of statistical co-occurrence between the clues contains 741 associated pairs, which were obtained by multiplying 39 (number of clues) by 39, subtracting 39 (because no autocorrelation of the clues is used), and finally dividing by two, due to the symmetrical nature of the matrix. The statistics (document NETWORK_ANALYSIS, sheet COMBINED_MATRIX) can be seen at https://osf.io/5uv2f/.
To check the validity of the matrix, Johnson’s (Reference Johnson1967) method was applied to analyze the emerging clusters. Note that these pictorial representations, such as Fig. 1, are only intended to illustrate the clusters. The complete statistics on the semantic distances between pieces can be found (document NETWORK_ANALYSIS, sheet CLUSTERING) at https://osf.io/5uv2f/.
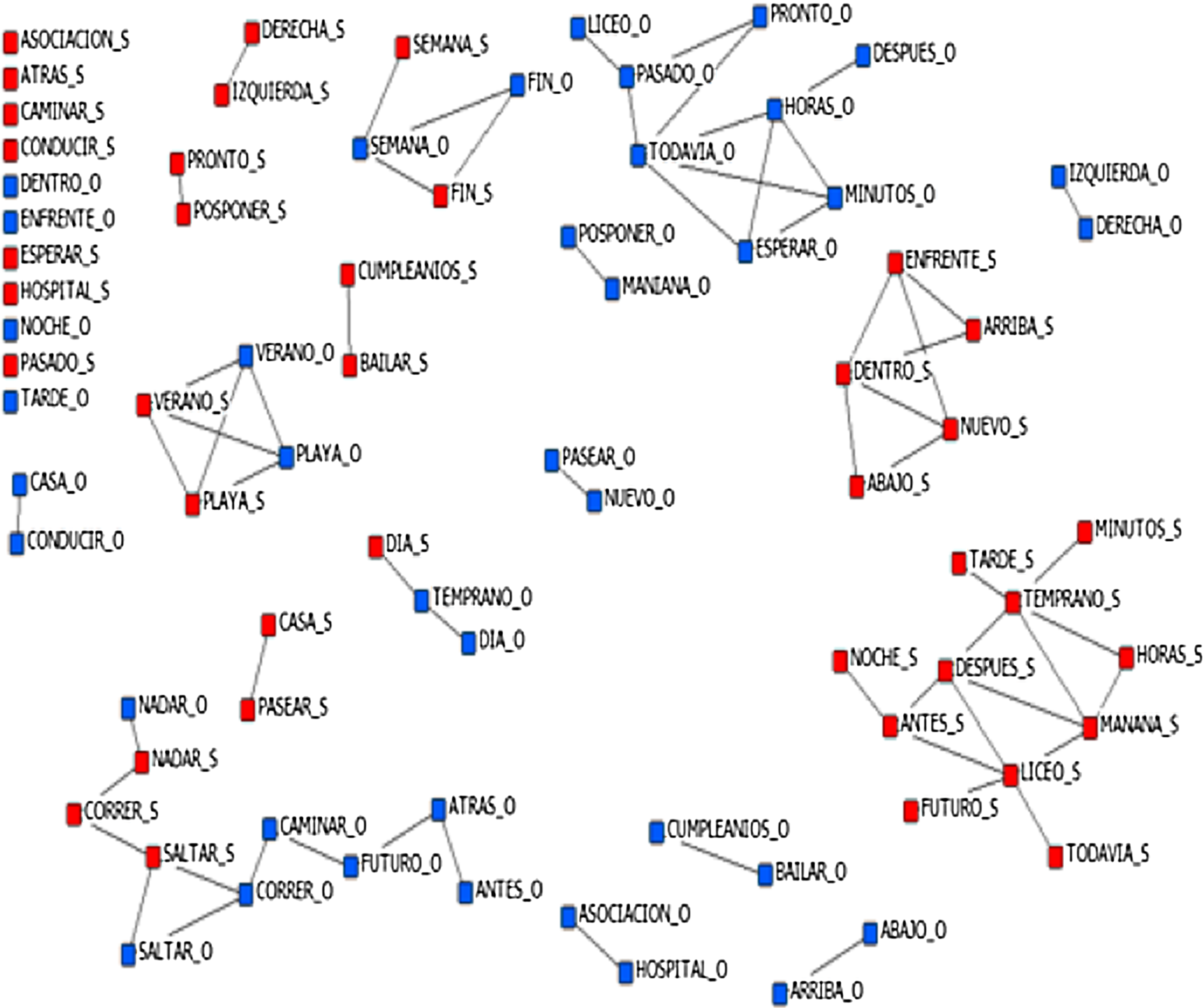
Figure 1. Cluster representation of the cosine similarity matrix, cut at r = .14.
Figure 1 illustrates the clusters. In this figure and the following paragraphs, the clues are written in Spanish and in uppercase letters; the uppercase letter following the underscore indicates the group: “O” for hearing nonsigners and “S” for Deaf. For example, FUTURO_O indicates the clue FUTURO [Future] for the hearing group. As Fig. 1 shows, there is no single cluster per domain (space or time) and closed clusters per linguistic modality (sign vs. spoken) predominate. Some clusters form unique domains. For example, DIA_S-TEMPRANO_O-DIA_O [Day_S-Early_O-Day_O] belongs to the time domain. In this case, it is the clue TEMPRANO_O that connects to the concurrent clue (DIA) of each cluster. Considering the associations between clues and associates from the cut-off point of r = .14, the first thing to note is that, for both domains (3 clues for space, 3 clues for time) and fillers (5 cases), and in both languages (3 hearing, 7 Deaf), 11 clues do not form part of any cluster. A comparison between the groups shows that this result was slightly more than twice as frequent for the deaf population as for the hearing population.
Moreover, three of the eleven clusters consist of antonymous word pairs. This result may be a product of the task design with what we call domain-concurrent pairs. This result is consistent with the findings of Zapico and Vivas (Reference Zapico and Vivas2014), who found antonymous word pairs in a study of synonymy as a type of semantic distance. It should be noted that the IZQUIERDA-DERECHA [Left-Right] dyad was recorded separately for the two groups. The rest of the dyads correspond to filler cues with no intra-group member matching (CASA_O-CONDUCIR_O [House_O-Driving_O] and CASA_S-CAMINAR_S [House_S-Walking_S]), or to filler cues with intra-group member matching (CUMPLEAÑOS_O-BAILAR_O [Birthday_O-Dancing_O] and CUMPLEAÑOS_S-BAILAR_S), or to distinct intra-group dyads. For example, POSPONER-PRONTO [Postpone-Soon] for the Deaf group and POSPONER-MAÑANA [Postpone-Tomorrow] for the hearing group. As for the hearing group, there is the main cluster combining time domain clues with LICEO [Highschool] as a filler clue.
The rest of the hearing group’s clues are either scattered in some of the aforementioned dyads or grouped in one of the other four clusters. Two of these three clusters belong to the time domain, another combines the time domain with filler clues (VERANO_O-VERANO_S-PLAYA_O-PLAYA_S [Summer-Beach]). The robustness of this cluster is relevant because each of the four clues is directly related to each of the others. This was the only cluster with an orthogonal relationship between the clues. Finally, in the last inter-group cluster, a number of clues (three of four pairs of inter-group clues; for example, NADAR_O-NADAR_S [Swimming]) representing actions are connected with FUTURO_O and with the dichotomous ATRAS_O-ANTES_O [BACK-Before].
Another criterion to assess the similarity of the grouping of clues between clusters is to check how many pairs of clues between groups (e.g., ARRIBA_S-ARRIBA_O [Up]) belong to the same cluster. In this regard, Fig. 1 shows that such synchronization occurred in 5 of 18 clusters. That is, for the pairs NADAR_S-NADAR_O, SALTAR_S-SALTAR_O, DIA_S-DIA_O, SEMANA_S-S-SEMANA_O, FIN_S-FIN_O, VERANO_S-VERANO_O, and PLAYA_S-PLAYA_O.
Entropy
The associates for each clue were summed for each language group and then their values were replaced with probabilities. To measure the diversity of responses, taking into account both the number of different associates and the probability of elicitation, normalized entropy was calculated for each probability vector corresponding to each clue, for each language group. Entropy is low when participants of the same group mention the same associates, and high when participants of the same group elicit more diverse associations. The entropy records the level of informativity in a group. For space and time clues, a Mann-Whitney test showed no significant difference in entropy between the groups. The Deaf group’s score (mean rank = 26.85, Min = 0.86, Max = 0.99) was not higher than that of the hearing group’s score (mean rank = 26.15, Min = 0.86, Max = 0.98), U = 347.000, p = .869. For the filler clues, there were no significant differences. The Deaf group’s score in the Mann-Whitney test (mean rank = 15.08, Min = 0.86, Max = 0.97) was not higher than that of the hearing group’s score (mean rank = 11.92, Min = 0.86, Max = 0.98), U = 105.000, p = .311. Of the 39 clues, 21 had higher entropy in the Deaf group and 18 in the hearing group. The complete entropy analysis is available (documents Entropy_Test.htm) at https://osf.io/5uv2f/.
Attribute category analysis
As indicated in “Describing the semantic relationships”, a tool was created, based on the coding developed by Wu and Barsalou (Reference Wu and Barsalou2009), to allow for the inclusion of closed-class linguistic pieces. This procedure was applied only to associates showing minimal overlap (i.e., at least one repetition). The coding resulting from this model was tested using a panel procedure. The analysis of the level of inter-judge agreement showed an acceptable result (Krippendorff’s alpha with a value of .82). The chi-square test showed significant differences between the two groups (Deaf and hearing) with respect to the chosen semantic categories (X 2 (3, N = 62) = 10.89, p = .012) for space and for (X 2 (3, N = 62) =41.13, p < .001) time. However, the residuals of entity for space and time and introspection for time showed a score shorter than 2 (i.e., there were no significant differences between these categories) between groups. In contrast, the residuals for introspective relations for space, and situation and taxonomy for space and time showed scores greater than 2 between groups. The residuals showed that the domain of time provided greater values (see between-groups residual scores for taxonomy and situation categories). As Fig. 2 and Table 4 (see https://osf.io/5uv2f/) show, for the two groups (Deaf vs. hearing) the domain of space was the main contributor of clue-associate pairs corresponding to the categories of entity and introspection. The situation semantic relations did not show a significant difference in the contribution of cases for each domain. Finally, the taxonomic relations, besides being predominant in hearing nonsigners, have most of their cases in the time domain. In this domain, Fig. 2 suggests that the hearing signers preferred taxonomic relations while the Deaf chose situational relations. Regarding the domain of space, the Deaf opted for situation relations whereas the hearing group opted for taxonomic relations.
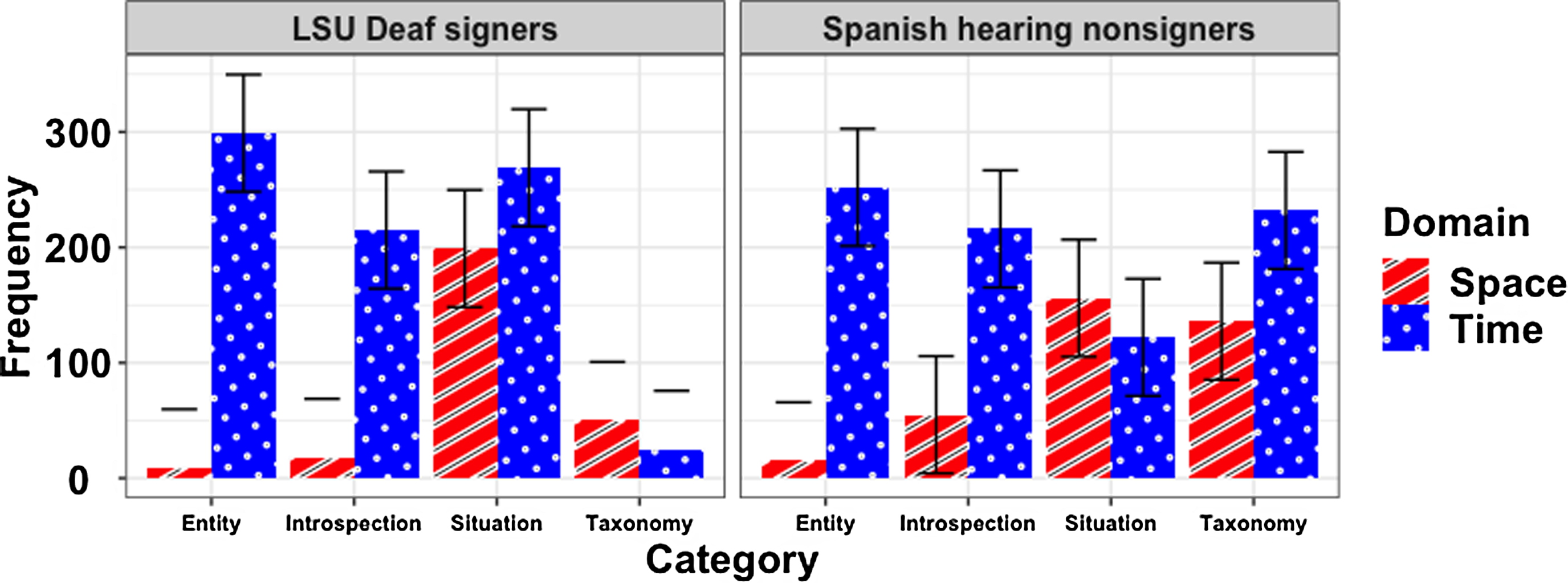
Figure 2. Distribution of responses by semantic category by group (error bars show the Standard Error of the Mean) for space and time clues.
The chi-square test only for filler clues showed significant differences between the two groups (Deaf and hearing) with respect to the chosen semantic categories (X 2 (3, N = 62) = 140.8385, p < .001). For taxonomic, entity, and introspection relationships, the residuals showed a score greater than 2 (over 3.50). For situation relationships, the residuals showed values less than 2. The situation semantic relations did not show a significant difference in the contribution of cases for each group. All the others relationships (taxonomic, entity, and introspection) showed significant between-groups differences. Hearing group preferred and taxonomic and introspection relationships but Deaf group provided more entity relationships. The complete statistics on the semantic categories between the clue-associate pairs can be found (document SEMANTIC_CATEGORY.R for Fig. 2 complementary spreadsheets [csv format], Chi_square_test_SC [htm]), and Chi_square_fillers at https://osf.io/5uv2f/.
General discussion
This study examined the similarities and differences of the conceptual organization of the domains of time and space in Deaf and hearing populations in Uruguayan society through a property list task. The relevance of this study lies in that similarities and differences found between linguistic modalities that could affect and differentiate the mental lexicon and the structure of categorization of concepts in these populations: more concrete (entity and situational) or abstract (taxonomic and introspective) organizations of these domains between the examined populations.
To explore universal possible domains of human experience, we select concepts distinguishable in their processing, that is, concepts involve sensorimotor, linguistic, and social information in different modes. Fundamentally, were chosen concepts that include the dimensions of space and time. The former is labeled concrete in cognitive literature and the latter as abstract.
The hypothesis of this study was that if the linguistic modality differences have effects on conceptual categorization, then there might be construal biases between modalities consistent with alternatives in the use of sensorimotor, linguistic, and social information. Thus, we might find differences in the types of semantic relations they showed as preferred by each population and, consequently, differences in the abstract or concrete way of conceptualizing or evoking (construal) the conceptual domains of time and space. In line with these differences, the expectation was that there would be a bias of the Deaf population toward a concrete construal because of the higher iconicity of sign languages and the link of the former to concreteness and sensorimotor information. In principle, we did not expect this bias in the hearing population. The different types of iconicity (i.e., pantomimic, perceptual, or diagrammatic), its scope (total or partial), and its complementarity with metaphoric or metonymic processes can vary the scope of the different signs to evoke situational semantic relations on other alternatives, priming a crucial element of a concrete thought. A design with a more counterbalanced set of clues might help to better measure the effect of iconicity on the observed categorization biases.
To do this, the semantic networks were reconstructed from the relationships between the properties stated for each concept. Then, we use the semantic networks to describe the memory processes and organization involved in conceptual categorization among Deaf and hearing populations.
To test these similarities and differences, a repeated free association task was chosen because this paradigm captures all types of responses (syntagmatic vs. paradigmatic), all types of semantic relations (taxonomic vs. thematics), and all types of lexical pieces (open vs. closed).
The language modality differences can be grouped into four major sets: semiotic, linguistic, psycho, and sociolinguistic. This study assumed the morphological and phonological character of space in sign languages and the absence of such a value for spoken ones. Note that the greater pervasiveness of iconicity in sign languages seems to be genuine modality difference.
We warned that concrete and abstract thinking is not exclusive to any examined populations and we dealed only with some ways of describing them. The study distinguished concreteness and abstractness on two levels: first, in function concerning the availability of sensorimotor access to domains of experience, and second, concerning how semantic relations between clue and associate show a way of organizing those domains in semantic memory.
The study showed that the latter approach captures the eventual biases of a linguistic modality when the speaker population of that modality defines the most relevant attributes to identify a lexical item and its relevant semantic environment. In this sense, the study suggests that the difference between taxonomic and thematic semantic relations between the clue and its associates could be interpreted as evidence of a bias for an abstract versus a concrete construal of the domains. The expected differences in the construal of the domains of space and time between the populations are because the morphological and phonological value of space, the pervasiveness of iconicity in sign language, and the strong link between iconicity and concreteness would facilitate a concrete construal in the Deaf population.
The results suggest that the mental lexicon between the two populations (Deaf and hearing) differs significantly in several respects organization and semantic categorization. About the similitudes, entropy did neither show significant intra-group differences, nor kind of clues differences (space and time vs. fillers). Because each intra-group diversity is similar for the two compared groups (i.e., Deaf and hearing), then we suggest that there are structural similarities (i.e., clustering, betweenness, density) in the semantic networks and the organization of the tested mental lexicon between the two populations for the study. These findings are consistent with the literature that compares mental lexicon (Dubossarsky et al., Reference Dubossarsky, De Deyne and Hills2017). This literature suggests that lexical processing and lexical semantics might show important similarities with respect to mental lexical organization, retrieval, and recall. In the design of the task, antonym clues (i.e., Back vs. Front) were systematically provided for space and time clues than for filler clues. Then, this difference might facilitate more syntagmatic associates and thematic thinking for the filler clues than the space and time clues.
In the scope we know, the previous comparative norming studies between Deaf and hearing populations are scarce (Marschark et al., Reference Marschark, Convertino, McEvoy and Masteller2004). Then, comparing similar previous studies with similar pairs of populations (Deaf vs. hearing nonsigners) to understand better and weigh our results’ scope takes work. Coinciding with Marschark et al. (Reference Marschark, Convertino, McEvoy and Masteller2004), our results showed more robust taxonomic thinking (i.e., associations between category names and exemplars) in the hearing population than in the Deaf one.
If most of the Uruguayan Deaf population—there are no statistical records but the Uruguayan specialist agrees on this topic—is below or reach an early learning phase of Uruguayan Spanish (level A in CEFR), our findings seem in line with those of Dong and Li (Reference Dong and Li2015) with bilinguals of two spoken languages: in an early learning phase of a spoken language such as Spanish, it might be expected that the conceptual integration between translation equivalents of L1 (in our case LSU) and L2 (Uruguayan Spanish) is far from being.
Another antecedent of these kinds of studies was done by Karadöller et al. (Reference Karadöller, Sümer, Ünal and Özyürek2022), but in these studies, only Deaf (Turkish Sign Language) made elicited picture descriptions and the experimenters tested the subsequent recognition memory accuracy of the described pictures. Mainly, this study did not get a spatial memory but rather linguistic conceptualization of space and time.
Given the paucity of semantic norm studies to compare Deaf and hearing populations, we believe it is more appropriate to compare our results with those of populations of strongly different languages, age groups, professions, or other differentiating criteria even among hearing populations. We warn that since this study does not focus on those variables (i.e., age, profession, etc.), we do not have words on how it affects categorization of time or space. According to this criterion, like older adults and children, the Deaf group showed a greater tendency to establish thematic relations. Like young adults (García Coni et al., Reference García Coni, Comesaña, Piccolo and Vivas2020), the hearing group showed a greater tendency to taxonomic relations.
This similarity of results suggests that psycho- and sociolinguistic factors—non-controlled in this study or directly included as variables—such as language deprivation, asymmetric language contact, and bilingualism between a sign and a spoken language might influence the shape of semantic networks, as well as the semantic relations preferred by speakers. Because these aspects were non-controlled in the sample, we only briefly acknowledge that they might be relevant in further studies.
Notably, the semantic categories (taxonomy, entity, situation, and introspection) chosen by each population (Deaf vs. hearing) show different preferences between them: a bias toward an abstract construal in the hearing population and a bias toward a concrete alternative in the Deaf population. We notice that in our study, the classification of concrete and abstract refers to the pairs clue-associate (i.e., taxonomic and introspective as abstract relations and entity and situation as concrete ones). However, introspective relations might capture proprioceptive information not included in Borghi’s et al. (Reference Borghi, Binkofski, Castelfranchi, Cimatti, Scorolli and Tummolini2017) proposal. It is in line with sensorimotor one and might support concrete construal of any domain. We warn that abstractness is present in some other non-tested ways. For example, some kinds of iconicity, which are present in sign languages, such as structure mappings, are quite an abstract process.
Although we did not wonder whether Deaf signers or hearing nonsigners choose verbs, nouns, or adjective forms for providing the associates, we believe it is an interesting question because it provides—in line with the distinction between processes and entities suggested by Langacker (Reference Langacker1987)—a way for capturing differences in the conceptualization strategies of the populations of the study. We already said that distinguishing word classes in the participants’ responses was helpful to the study’s aims. When translating the associates provided by Deaf participants, we controlled the word classes of all their responses as most as possible. Then our data might be helpful for answering questions about the word classes preferred by the participants and doing intra- and between-group comparisons.
Another different criterion is the gap between oral and literate cultures. From this classification, sign language and speech corresponds to oral culture and written form of spoken languages to a literate one. Ong and John (Reference Ong and John1982) argues that in an oral culture thought and expression do not handle categorizations by abstraction or formally logical reasoning processes. We warn that not all spoken languages have a written form, and many times Deaf signers are literate in a spoken language. It means that literate Deaf and hearing writers have access to what Ong and John (Reference Ong and John1982) calls oral and literal culture and the kind of categorization and reasoning they support. Usually, taxonomic relations such as those between clue-associate pairs are based on abstract logical reasoning. These assessments are suggestive of our findings, but the design of the free word association task needs to be changed for testing a specific hypothesis for this approach.
This study can be framed within the claims of linguistic determinism (see Gumperz et al., Reference Gumperz, Levinson and Levinson1996; Hickmann, Reference Hickmann2000). For this approach, language constrains human knowledge and thought processes such as categorization, memory, and perception. Then, individuals’ thinking partially differs across linguistic communities. Would language modality be a constraining factor different from the differences between languages of the same modality? Our theoretical framing and claiming suggest iconicity as a powerful contrasting factor. This study is limited in some ways in drawing large conclusions about this. However, the results are biased in favor of partial differences in the structure of the mental lexicon and semantic relationships highlighted by each language modality. The question of whether all languages make the same ontological commitment to notions such as “entity” as opposed to notions such as “situation” (those used in our coding tool and those that inspired it) suggests that such distinctions might impact everyday language behavior and controlled experimental tasks.
Limitations and future avenues
Free associations of words are quite unpredictable. Then, the semantic networks we report here would have variations by criteria such as others we tested, including other clues, a larger group of participants, or even these same participants at another time. In consequence, our claims about the differences between the studied populations have limitations according to these warnings. These warnings aim to explore future avenues that we suggest at the last paragraph. Regarding the study’s limitations, three of the eleven dyad-shaped clusters were formed by pairs of antonymous concepts. This result may be a product of the design of concurrent pairs per domain, mainly for space and time clues. This result is consistent with the findings of Zapico and Vivas (Reference Zapico and Vivas2014), who found antonymous word pairs in a study of synonymy as a type of semantic distance. In line with previous explanations, the small sample size of our study is a crucial limitation for getting stronger conclusions. One might expect that the larger the sample, the more the semantic networks of the two groups converge (i.e., QAP and entropy test might indicate this convergence).
The categories used in the coding tool and the composition of the judging team should be critically considered. The semantic categories in that tool follow a speech-centered perspective and there were no Deaf members on the judging team. Regarding the former, creating a tool with categories fully valid for both linguistic modalities (sign and spoken) is necessary to measure the possible biases associated with the current categories accurately. Still, it remains in doubt whether, by definition, the categories (entity vs. situation vs. introspection vs. taxonomy) represent in an exclusive way speech-center thinking. Perhaps, the adaptation should focus on the subcategories and other aspects such as the analysis unit (i.e., perhaps phrases that behave partially as lexical items in a sign but not in a spoken language).
Regarding the second, applying such a tool would be the appropriate way to form teams of judges that include Deaf and hearing people in a balanced way. In turn, this would help better estimate the possible effect of the grammatical class of the clues and associated in the application of the tool on semantic relations.
A last limitation is the ability of socio-demographic variables, such as age and education, to capture differences in cognitive and linguistic development between some kind of populations. We believe that these variables can be blind tools to explore in a refined way and with a common metric the equivalence in cognitive and linguistic development between populations. As a surrogate for these measures, standardized instruments adapted to Deaf and hearing populations (i.e., MacArthur Communicative Development Inventory [Anderson & Reilly, Reference Anderson and Reilly2002] or Non-verbal intelligence tests for Deaf and hearing subjects [Snijders & Snijders-Oomen, Reference Snijders and Snijders-Oomen1959]) would be more accurate alternatives for matching the Deaf and hearing nonsigner samples in verbal fluency and abstract and spatial thinking.
Future avenues of research include expanding the sample; comparing the Deaf sample with subsamples of the Rioplatense Spanish lexicon (Vivas J. et al., Reference Vivas, Vivas, Comesaña, García Coni and Vorano2017; Cabana et al., Reference Cabana, Zugarramurdi and De Deyne2020) and other spoken-sign languages pairs such as DGS-German, CSL-Mandarin, LSE-Spanish, or ASL-English; testing bimodal bilinguals would help to find whether they follow the pattern of Deaf signers, hearing nonsigners, both, or neither. Mainly, the cross-linguistic approach might help to clarify whether the patterns that we found here are due to modality effects or artifacts of the tested specific languages (LSU and Uruguayan Spanish). Other alternatives to follow are comparing the weight of phonological similarity (word family) in clue-associative pairs, due to the greater weight of word families in the lexical structure of sign languages; comparing the proportion in the selection of open- and closed-class pieces in clue-associative pairs, due to the greater weight of word families in the lexical structure and the greater discourse profile of sign languages; and conducting similar studies in other sign languages and their spoken counterparts.
Replication package
The dataset, materials, scripts, and code application generated during the current study are available in the Open Science Framework repository at https://osf.io/5uv2f/.
Acknowledgments
The authors thank Rocío Goñi for data collection and colleagues from TUILSU, Centro de Investigación y Desarrollo de la Persona Sorda (CINDE), and Incosur for their support in inviting Uruguayan deaf people to participate as volunteers.
Financial support
This work was carried out with subsidies from the I + D 2014_73 programs of the CSIC-UdelaR and ANII-FCE 2_2016_1_27048. Both grants were awarded to Roberto Aguirre.


