



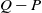
1. Introduction
Markov chain Monte Carlo (MCMC) algorithms (e.g. [Reference Brooks, Gelman, Jones and Meng6]) estimate the expected value of a function
 $f\colon S\to\mathbb{R}$
with respect to a probability distribution
$f\colon S\to\mathbb{R}$
with respect to a probability distribution
 $\pi$
on a state space S, which in this paper we assume to be finite, using an estimator such as
$\pi$
on a state space S, which in this paper we assume to be finite, using an estimator such as
 \begin{align*}\widehat{f}_N = \frac{1}{N} \sum_{k=1}^N f(X_k),\end{align*}
\begin{align*}\widehat{f}_N = \frac{1}{N} \sum_{k=1}^N f(X_k),\end{align*}
where
 $X_1,X_2,X_3,\ldots$
is a time-homogeneous Markov chain with stationary distribution
$X_1,X_2,X_3,\ldots$
is a time-homogeneous Markov chain with stationary distribution
 $\pi$
, having transition probabilities P(x, y) from state x to state y (often viewed as a matrix P).
$\pi$
, having transition probabilities P(x, y) from state x to state y (often viewed as a matrix P).
An important measure of the efficiency of this estimator is its asymptotic variance:
 \begin{equation} v(f,P) \,:\!=\, \lim_{N\to\infty} N \,\mathrm{Var}\big[\,\widehat{f}_N\big] = \lim_{N\to\infty} N \,\mathrm{Var}\Bigg[ \frac{1}{N} \sum_{i=1}^N f(X_i) \Bigg] = \lim_{N\to\infty} \frac{1}{N} \mathrm{Var}\Bigg[ \sum_{i=1}^N f(X_i) \Bigg] .\end{equation}
\begin{equation} v(f,P) \,:\!=\, \lim_{N\to\infty} N \,\mathrm{Var}\big[\,\widehat{f}_N\big] = \lim_{N\to\infty} N \,\mathrm{Var}\Bigg[ \frac{1}{N} \sum_{i=1}^N f(X_i) \Bigg] = \lim_{N\to\infty} \frac{1}{N} \mathrm{Var}\Bigg[ \sum_{i=1}^N f(X_i) \Bigg] .\end{equation}
For the irreducible Markov chains used for MCMC, the initial state of the chain does not affect the asymptotic variance, and the bias of the estimator converges to zero at rate
 $1/N$
regardless of the initial state. (In practice, an initial portion of the chain is usually simulated but not used for estimation, in order to reduce the bias in a finite-length run.)
$1/N$
regardless of the initial state. (In practice, an initial portion of the chain is usually simulated but not used for estimation, in order to reduce the bias in a finite-length run.)
If we run the chain for a large number of iterations N, we therefore expect that
 $v(f,P)/N$
will be an indication of the likely squared error of the estimate obtained. Indeed, when v( f, P) is finite, we can show (e.g. [Reference Tierney25, Theorem 5]) that a central limit theorem applies, with the distribution of
$v(f,P)/N$
will be an indication of the likely squared error of the estimate obtained. Indeed, when v( f, P) is finite, we can show (e.g. [Reference Tierney25, Theorem 5]) that a central limit theorem applies, with the distribution of
 $\big(\widehat{f}-E_{\pi}(f)\big)/\sqrt{v(f,P)/N}$
converging to N(0, 1).
$\big(\widehat{f}-E_{\pi}(f)\big)/\sqrt{v(f,P)/N}$
converging to N(0, 1).
We are therefore motivated to try to modify the chain to reduce v( f, P), ideally for all functions f. We say that one transition matrix, P, efficiency-dominates another one, Q, if
 $v(f,P) \le v(f,Q)$
for all
$v(f,P) \le v(f,Q)$
for all
 $f\colon S\to\mathbb{R}$
. Various conditions are known [Reference Geyer10, Reference Neal20, Reference Tierney25] that ensure that P efficiency-dominates Q. One of these, for reversible chains, is the Peskun-dominance condition [Reference Peskun22, Reference Tierney26] which on a finite state space is that
$f\colon S\to\mathbb{R}$
. Various conditions are known [Reference Geyer10, Reference Neal20, Reference Tierney25] that ensure that P efficiency-dominates Q. One of these, for reversible chains, is the Peskun-dominance condition [Reference Peskun22, Reference Tierney26] which on a finite state space is that
 $P(x,y) \ge Q(x,y)$
for all
$P(x,y) \ge Q(x,y)$
for all
 $x\not=y$
. This condition is widely cited and has received significant recent attention [Reference Gagnon and Maire9, Reference Li, Smith and Zhou16, Reference Zanella27], and has even been extended to non-reversible chains [Reference Andrieu and Livingstone1]. But it is a very strong condition, and P might well efficiency-dominate Q even if it does not Peskun-dominate it.
$x\not=y$
. This condition is widely cited and has received significant recent attention [Reference Gagnon and Maire9, Reference Li, Smith and Zhou16, Reference Zanella27], and has even been extended to non-reversible chains [Reference Andrieu and Livingstone1]. But it is a very strong condition, and P might well efficiency-dominate Q even if it does not Peskun-dominate it.
In this paper, we focus on reversible chains with a finite state space. We present several known equivalences of efficiency dominance, whose proofs were previously scattered in the literature, sometimes only hinted at, and sometimes based on very technical mathematical arguments. We provide complete elementary proofs of them in Sections 3, 4, and 8, using little more than simple linear algebra techniques.
In Section 5, we use these equivalences to derive new results, which can show efficiency dominance for some chains constructed by composing multiple component transition matrices, as is done for the Gibbs sampler. These results are applied to methods for improving Gibbs sampling in a companion paper [Reference Neal21]. In Section 6, we consider eigenvalue connections, and show how we can sometimes prove that a reversible chain cannot be efficiency-dominated by any other reversible chain, and also explain (Corollary 1) how antithetic MCMC can be more efficient than independent and identically distributed (i.i.d.) sampling, These results also allow an easy rederivation, in Section 7, of the fact that Peskun dominance implies efficiency dominance.
2. Background preliminaries
We assume that the state space S is finite, with
 $|S|=n$
, and let
$|S|=n$
, and let
 $\pi$
be a probability distribution on S, with
$\pi$
be a probability distribution on S, with
 $\pi(x)>0$
for all
$\pi(x)>0$
for all
 $x\in S$
and
$x\in S$
and
 $\sum_{x\in S} \pi(x) = 1$
. For functionals
$\sum_{x\in S} \pi(x) = 1$
. For functionals
 $f,g\colon S\to\mathbb{R}$
, define the
$f,g\colon S\to\mathbb{R}$
, define the
 $L^2(\pi)$
inner product by
$L^2(\pi)$
inner product by
 \begin{align*}\langle\, f, g \rangle = \sum_{x\in S} f(x) g(x) \pi(x) .\end{align*}
\begin{align*}\langle\, f, g \rangle = \sum_{x\in S} f(x) g(x) \pi(x) .\end{align*}
That is,
 $\langle\, f, g \rangle = \mathbb{E}_\pi[\,f(X) g(X)]$
. Equivalently, if we let
$\langle\, f, g \rangle = \mathbb{E}_\pi[\,f(X) g(X)]$
. Equivalently, if we let
 $S=\{1,2,\ldots,n\}$
, represent a function f by the column vector
$S=\{1,2,\ldots,n\}$
, represent a function f by the column vector
 $f=[\,f(1),\ldots,f(n)]^\top$
, and let
$f=[\,f(1),\ldots,f(n)]^\top$
, and let
 $D=\mathrm{diag}(\pi)$
be the
$D=\mathrm{diag}(\pi)$
be the
 $n \times n$
diagonal matrix with
$n \times n$
diagonal matrix with
 $\pi(1),\ldots,\pi(n)$
on the diagonal, then
$\pi(1),\ldots,\pi(n)$
on the diagonal, then
 $\langle f, g \rangle$
equals the matrix product
$\langle f, g \rangle$
equals the matrix product
 $f^\top D g$
.
$f^\top D g$
.
We aim to estimate expectations with respect to
 $\pi$
by using a time-homogeneous Markov chain
$\pi$
by using a time-homogeneous Markov chain
 $X_1,X_2,X_3,\ldots$
on S, with transition probabilities
$X_1,X_2,X_3,\ldots$
on S, with transition probabilities
 $P(x,y) = \mathbb{P}(X_{t+1}=y \mid X_t=x)$
, often written as a matrix P, for which
$P(x,y) = \mathbb{P}(X_{t+1}=y \mid X_t=x)$
, often written as a matrix P, for which
 $\pi$
is a stationary distribution (or invariant distribution):
$\pi$
is a stationary distribution (or invariant distribution):
 \begin{align*}\pi(y) = \sum_{x\in S} \pi(x) P(x,y).\end{align*}
\begin{align*}\pi(y) = \sum_{x\in S} \pi(x) P(x,y).\end{align*}
Usually,
 $\pi$
is the only stationary distribution, though we sometimes consider transition matrices that are not irreducible (see below), for which this is not true, as building blocks for other chains.
$\pi$
is the only stationary distribution, though we sometimes consider transition matrices that are not irreducible (see below), for which this is not true, as building blocks for other chains.
For
 $f\colon S\to\mathbb{R}$
, let
$f\colon S\to\mathbb{R}$
, let
 $(Pf)\colon S\to\mathbb{R}$
be the function defined by
$(Pf)\colon S\to\mathbb{R}$
be the function defined by
 \begin{align*}(Pf)(x) = \sum_{y\in S} P(x,y) f(y) .\end{align*}
\begin{align*}(Pf)(x) = \sum_{y\in S} P(x,y) f(y) .\end{align*}
Equivalently, if we represent f as a vector of its values for elements of S, then Pf is the product of the matrix P with the vector f. Another interpretation is that
 $(Pf)(x) = \mathbb{E}_P[\,f(X_{t+1})\mid X_t=x]$
, where
$(Pf)(x) = \mathbb{E}_P[\,f(X_{t+1})\mid X_t=x]$
, where
 $\mathbb{E}_P$
is expectation with respect to the transitions defined by P. We can see that
$\mathbb{E}_P$
is expectation with respect to the transitions defined by P. We can see that
 \begin{align*}\langle\, {f}, {Pg} \rangle = \sum_{x\in S} \sum_{y\in S} f(x) P(x,y) g(y) \pi(x) .\end{align*}
\begin{align*}\langle\, {f}, {Pg} \rangle = \sum_{x\in S} \sum_{y\in S} f(x) P(x,y) g(y) \pi(x) .\end{align*}
Equivalently,
 $\langle\, {f}, {Pg} \rangle$
is the matrix product
$\langle\, {f}, {Pg} \rangle$
is the matrix product
 $f^\top D P g$
. Also,
$f^\top D P g$
. Also,
 $\langle\, {f}, {Pg} \rangle = \mathbb{E}_{\pi,P}[\,f(X_t) g(X_{t+1})]$
, where
$\langle\, {f}, {Pg} \rangle = \mathbb{E}_{\pi,P}[\,f(X_t) g(X_{t+1})]$
, where
 $\mathbb{E}_{\pi,P}$
means expectation with respect to the Markov chain with initial state drawn from the stationary distribution
$\mathbb{E}_{\pi,P}$
means expectation with respect to the Markov chain with initial state drawn from the stationary distribution
 $\pi$
and proceeding according to P.
$\pi$
and proceeding according to P.
A transition matrix P is called reversible with respect to
 $\pi$
if
$\pi$
if
 $\pi(x) P(x,y) = \pi(y) P(y,x)$
for all
$\pi(x) P(x,y) = \pi(y) P(y,x)$
for all
 $x,y\in S$
. This implies that
$x,y\in S$
. This implies that
 $\pi$
is a stationary distribution for P, since
$\pi$
is a stationary distribution for P, since
 \begin{align*}\sum_x \pi(x) P(x,y) = \sum_x \pi(y) P(y,x) = \pi(y) \sum_x P(y,x) = \pi(y).\end{align*}
\begin{align*}\sum_x \pi(x) P(x,y) = \sum_x \pi(y) P(y,x) = \pi(y) \sum_x P(y,x) = \pi(y).\end{align*}
If P is reversible,
 $\langle\, {f}, {Pg} \rangle = \langle Pf, g \rangle$
for all f and g – i.e. P is self-adjoint (or Hermitian) with respect to
$\langle\, {f}, {Pg} \rangle = \langle Pf, g \rangle$
for all f and g – i.e. P is self-adjoint (or Hermitian) with respect to
 $\langle \cdot, \cdot \rangle$
. Equivalently, P is reversible with respect to
$\langle \cdot, \cdot \rangle$
. Equivalently, P is reversible with respect to
 $\pi$
if and only if DP is a symmetric matrix – i.e. DP is self-adjoint with respect to the classical dot-product. This allows us to easily verify some well-known facts about reversible Markov chains.
$\pi$
if and only if DP is a symmetric matrix – i.e. DP is self-adjoint with respect to the classical dot-product. This allows us to easily verify some well-known facts about reversible Markov chains.
Lemma 1. If P is reversible with respect to
 $\pi$
then:
$\pi$
then:
-
(i) the eigenvalues of P are real;
-
(ii) these eigenvalues can be associated with real eigenvectors;
-
(iii) if
 $\lambda_i$
and
$\lambda_j$
are eigenvalues of P with
$\lambda_i \ne \lambda_j$
, and
$v_i$
and
$v_j$
are real eigenvectors associated with
$\lambda_i$
and
$\lambda_j$
, then
$v_i^\top D v_j = 0$
, where D is the diagonal matrix with
$\pi$
on the diagonal (i.e.
$\langle {v_i}, {v_j} \rangle=0$
);
$\lambda_i$
and
$\lambda_j$
are eigenvalues of P with
$\lambda_i \ne \lambda_j$
, and
$v_i$
and
$v_j$
are real eigenvectors associated with
$\lambda_i$
and
$\lambda_j$
, then
$v_i^\top D v_j = 0$
, where D is the diagonal matrix with
$\pi$
on the diagonal (i.e.
$\langle {v_i}, {v_j} \rangle=0$
); -
(iv) all the eigenvalues of P are in
$[{-}1,1]$
.











Proof. Since DP is symmetric and D is diagonal,
 $DP=(DP)^\top=P^\top D$
.
$DP=(DP)^\top=P^\top D$
.
-
(i) If
$Pv=\lambda v$
with v non-zero, then
$\overline\lambda\overline v^\top=\overline v^\top P^\top$
, and hence
$\overline\lambda(\overline v^\top Dv)=\overline v^\top P^\top Dv=\overline v^\top DP v = \lambda(\overline v^\top Dv)$
. Since
$\overline v^\top Dv$
is non-zero (because D has positive diagonal elements), it follows that
$\overline\lambda=\lambda$
, and hence
$\lambda$
is real. -
(ii) If
$Pv=\lambda v$
, with P and
$\lambda$
real and v non-zero, then at least one of
$\mbox{Re}(v)$
and
$\mbox{Im}(v)$
is non-zero and is a real eigenvector associated with
$\lambda$
. -
(iii)
$\lambda_i(v_i^\top Dv_j)=v_i^\top P^\top Dv_j=v_i^\top DPv_j=\lambda_j(v_i^\top Dv_j)$
, which when
$\lambda_i\ne\lambda_j$
implies that
$v_i^\top Dv_j=0$
. -
(iv) Since rows of P are non-negative and sum to one, the absolute value of an element of the vector Pv can be no larger than the largest absolute value of an element of v. If
$Pv=\lambda v$
, this implies that
$|\lambda| \le 1$
, and hence
$\lambda\in[{-}1,1]$
.

















The self-adjoint property implies that P is a ‘normal operator’, which guarantees (e.g. [Reference Horn and Johnson13, Theorem 2.5.3]) the existence of an orthonormal basis,
 $v_1,v_2,\ldots,v_n$
, of eigenvectors for P, with
$v_1,v_2,\ldots,v_n$
, of eigenvectors for P, with
 $Pv_i = \lambda_i v_i$
for each i, and
$Pv_i = \lambda_i v_i$
for each i, and
 $\langle {v_i},{v_j} \rangle=\delta_{ij}$
. (In particular, this property implies that P is diagonalisable or non-defective, but it is stronger than that.) Without loss of generality, we can take
$\langle {v_i},{v_j} \rangle=\delta_{ij}$
. (In particular, this property implies that P is diagonalisable or non-defective, but it is stronger than that.) Without loss of generality, we can take
 $\lambda_1=1$
, and
$\lambda_1=1$
, and
 $v_1 = \mathbf{1} \,:\!=\, [1,1,\ldots,1]^\top$
, so that
$v_1 = \mathbf{1} \,:\!=\, [1,1,\ldots,1]^\top$
, so that
 $v_1(x) = \mathbf{1}(x) = 1$
for all
$v_1(x) = \mathbf{1}(x) = 1$
for all
 $x\in S$
, since
$x\in S$
, since
 $P \mathbf{1} = \mathbf{1}$
due to the transition probabilities in P summing to one. We can assume for convenience that all of P
′s eigenvalues (counting multiplicity) satisfy
$P \mathbf{1} = \mathbf{1}$
due to the transition probabilities in P summing to one. We can assume for convenience that all of P
′s eigenvalues (counting multiplicity) satisfy
 $\lambda_1 \ge \lambda_2 \ge \cdots \ge \lambda_n$
.
$\lambda_1 \ge \lambda_2 \ge \cdots \ge \lambda_n$
.
In terms of orthonormal eigenvectors of P, any functions
 $f,g\colon S\to\mathbb{R}$
can be written as linear combinations
$f,g\colon S\to\mathbb{R}$
can be written as linear combinations
 $f = \sum_{i=1}^n a_i v_i$
and
$f = \sum_{i=1}^n a_i v_i$
and
 $g = \sum_{j=1}^n b_j v_j$
. It then follows from the orthonormality of these eigenvectors that
$g = \sum_{j=1}^n b_j v_j$
. It then follows from the orthonormality of these eigenvectors that
 \begin{align*}\langle\, f, g \rangle = \sum_i a_i b_i, \quad \langle\, {f}, {f} \rangle = \sum_i (a_i)^2, \quad \langle\, {f}, {Pg} \rangle = \sum_i a_i b_i \lambda_i, \quad \langle\, {f}, {Pf} \rangle = \sum_i (a_i)^2 \lambda_i.\end{align*}
\begin{align*}\langle\, f, g \rangle = \sum_i a_i b_i, \quad \langle\, {f}, {f} \rangle = \sum_i (a_i)^2, \quad \langle\, {f}, {Pg} \rangle = \sum_i a_i b_i \lambda_i, \quad \langle\, {f}, {Pf} \rangle = \sum_i (a_i)^2 \lambda_i.\end{align*}
In particular,
 $\langle\, {f}, {v_i} \rangle = a_i$
, so the
$\langle\, {f}, {v_i} \rangle = a_i$
, so the
 $a_i$
are the projections of f on each of the
$a_i$
are the projections of f on each of the
 $v_i$
. This shows that
$v_i$
. This shows that
 $\sum_{i=1}^n v_i v_i^\top D$
is equal to the identity matrix, since, for all f,
$\sum_{i=1}^n v_i v_i^\top D$
is equal to the identity matrix, since, for all f,
 \begin{align*}\Bigg(\sum_{i=1}^n v_i v_i^\top D\Bigg)\, f =\sum_{i=1}^n v_i \big(v_i^\top Df\big) =\sum_{i=1}^n v_i \langle {v_i}, {f} \rangle =\sum_{i=1}^n a_i v_i = f .\end{align*}
\begin{align*}\Bigg(\sum_{i=1}^n v_i v_i^\top D\Bigg)\, f =\sum_{i=1}^n v_i \big(v_i^\top Df\big) =\sum_{i=1}^n v_i \langle {v_i}, {f} \rangle =\sum_{i=1}^n a_i v_i = f .\end{align*}
Furthermore, any self-adjoint A whose eigenvalues are all zero must be the zero operator, since we can write any f as
 $f=\sum_{i=1}^n a_i v_i$
, from which it follows that
$f=\sum_{i=1}^n a_i v_i$
, from which it follows that
 $Af = \sum_{i=1}^n \lambda_i a_i v_i = 0$
.
$Af = \sum_{i=1}^n \lambda_i a_i v_i = 0$
.
A matrix A that is self-adjoint with respect to
 $\langle \cdot, \cdot \rangle$
has a spectral representation in terms of its eigenvalues and eigenvectors as
$\langle \cdot, \cdot \rangle$
has a spectral representation in terms of its eigenvalues and eigenvectors as
 $A = \sum_{i=1}^n \lambda_i v_i v_i^\top D$
. If
$A = \sum_{i=1}^n \lambda_i v_i v_i^\top D$
. If
 $h\colon\mathbb{R}\to\mathbb{R}$
we can define
$h\colon\mathbb{R}\to\mathbb{R}$
we can define
 $h(A) \,:\!=\, \sum_{i=1}^n h(\lambda_i) v_i v_i^\top D$
, which is easily seen to be self-adjoint. Using
$h(A) \,:\!=\, \sum_{i=1}^n h(\lambda_i) v_i v_i^\top D$
, which is easily seen to be self-adjoint. Using
 $h(\lambda)=1$
gives the identity matrix. We can also easily show that
$h(\lambda)=1$
gives the identity matrix. We can also easily show that
 $h_1(A)+h_2(A)=(h_1+h_2)(A)$
and
$h_1(A)+h_2(A)=(h_1+h_2)(A)$
and
 $h_1(A)h_2(A)=(h_1h_2)(A)$
, and hence (when all
$h_1(A)h_2(A)=(h_1h_2)(A)$
, and hence (when all
 $\lambda_i\ne0$
) that
$\lambda_i\ne0$
) that
 $A^{-1}=\sum_{i=1}^n \lambda_i^{-1} v_i v_i^\top D$
and (when all
$A^{-1}=\sum_{i=1}^n \lambda_i^{-1} v_i v_i^\top D$
and (when all
 $\lambda_i\ge0$
) that
$\lambda_i\ge0$
) that
 $A^{1/2}=\sum_{i=1}^n \lambda_i^{1/2} v_i v_i^\top D$
, so both of these are self-adjoint. Finally, note that if A and B are self-adjoint, so is ABA.
$A^{1/2}=\sum_{i=1}^n \lambda_i^{1/2} v_i v_i^\top D$
, so both of these are self-adjoint. Finally, note that if A and B are self-adjoint, so is ABA.
We say that P is irreducible if movement from any x to any y in S is possible via some number of transitions that have positive probability under P. An irreducible chain will have only one stationary distribution. A reversible irreducible P will have
 $\lambda_i<1$
for
$\lambda_i<1$
for
 $i\ge2$
. (As an aside, this implies that P is variance bounding, which in turn implies that v(f, P) from (1) must be finite for each f [Reference Roberts and Rosenthal23, Theorem 14].) For MCMC estimation we want our chain to be irreducible, but irreducible chains are sometimes built using transition matrices that are not irreducible – for example, by letting
$i\ge2$
. (As an aside, this implies that P is variance bounding, which in turn implies that v(f, P) from (1) must be finite for each f [Reference Roberts and Rosenthal23, Theorem 14].) For MCMC estimation we want our chain to be irreducible, but irreducible chains are sometimes built using transition matrices that are not irreducible – for example, by letting
 $P=\big(\frac12\big)P_1+\big(\frac12\big)P_2$
, where
$P=\big(\frac12\big)P_1+\big(\frac12\big)P_2$
, where
 $P_1$
and/or
$P_1$
and/or
 $P_2$
are not irreducible, but P is irreducible.
$P_2$
are not irreducible, but P is irreducible.
An irreducible P is periodic with period p if S can be partitioned into
 $p>1$
subsets
$p>1$
subsets
 $S_0,\ldots,S_{p-1}$
such that
$S_0,\ldots,S_{p-1}$
such that
 $P(x,y)=0$
if
$P(x,y)=0$
if
 $x\in S_a$
and
$x\in S_a$
and
 $y \notin S_b$
, where
$y \notin S_b$
, where
 $b=a+1\,(\mbox{mod}\,p)$
(and this is not true for any smaller p). Otherwise, P is aperiodic. An irreducible periodic chain that is reversible must have period 2, and will have
$b=a+1\,(\mbox{mod}\,p)$
(and this is not true for any smaller p). Otherwise, P is aperiodic. An irreducible periodic chain that is reversible must have period 2, and will have
 $\lambda_n=-1$
and
$\lambda_n=-1$
and
 $\lambda_i>-1$
for
$\lambda_i>-1$
for
 $i \ne n$
. A reversible aperiodic chain will have all
$i \ne n$
. A reversible aperiodic chain will have all
 $\lambda_i>-1$
.
$\lambda_i>-1$
.
Since v( f, P) as defined in (1) only involves variance, we can subtract the mean of f without affecting the asymptotic variance. Hence, we can always assume without loss of generality that
 $\pi(f)=0$
, where
$\pi(f)=0$
, where
 $\pi(f) \,:\!=\, \mathbb{E}_\pi(f) = \sum_{x\in S} f(x) \pi(x)= \langle\, {f}, {\mathbf{1}}\rangle$
. In other words, we can assume that
$\pi(f) \,:\!=\, \mathbb{E}_\pi(f) = \sum_{x\in S} f(x) \pi(x)= \langle\, {f}, {\mathbf{1}}\rangle$
. In other words, we can assume that
 $f\in L^2_0(\pi)\,:\!=\, \{f\colon\pi(f)=0,\,\pi(f^2)<\infty\}$
, where the condition that
$f\in L^2_0(\pi)\,:\!=\, \{f\colon\pi(f)=0,\,\pi(f^2)<\infty\}$
, where the condition that
 $\pi(f^2) = \mathbb{E}_\pi(f^2)$
be finite is automatically satisfied when S is finite, and hence can be ignored. Also, if
$\pi(f^2) = \mathbb{E}_\pi(f^2)$
be finite is automatically satisfied when S is finite, and hence can be ignored. Also, if
 $\pi(f) = 0$
, then
$\pi(f) = 0$
, then
 $\langle\, {f}, {\mathbf{1}}\rangle = \langle\, {f}, {v_1} \rangle= 0$
, so f is orthogonal to
$\langle\, {f}, {\mathbf{1}}\rangle = \langle\, {f}, {v_1} \rangle= 0$
, so f is orthogonal to
 $v_1$
, and hence its coefficient
$v_1$
, and hence its coefficient
 $a_1$
is zero.
$a_1$
is zero.
Next, note that
 \begin{align*}\langle\, {f}, {P^kg} \rangle = \sum_{x\in S} f(x) (P^kg)(x) \pi(x) =\sum_{x\in S} \sum_{y\in S} f(x) P^k(x,y) g(y) \pi(x) =\mathbb{E}_{\pi,P}[\,f(X_t) g(X_{t+k})],\end{align*}
\begin{align*}\langle\, {f}, {P^kg} \rangle = \sum_{x\in S} f(x) (P^kg)(x) \pi(x) =\sum_{x\in S} \sum_{y\in S} f(x) P^k(x,y) g(y) \pi(x) =\mathbb{E}_{\pi,P}[\,f(X_t) g(X_{t+k})],\end{align*}
where
 $P^k(x,y)$
is the k-step transition probability from x to y. If
$P^k(x,y)$
is the k-step transition probability from x to y. If
 $f\in L^2_0(\pi)$
(i.e. the mean of f is zero), this is the covariance of
$f\in L^2_0(\pi)$
(i.e. the mean of f is zero), this is the covariance of
 $f(X_t)$
and
$f(X_t)$
and
 $g(X_{t+k})$
when the chain is started in stationarity (and hence is the same for all t). We define the lag-k autocovariance,
$g(X_{t+k})$
when the chain is started in stationarity (and hence is the same for all t). We define the lag-k autocovariance,
 $\gamma_k$
, as
$\gamma_k$
, as
 \begin{align*}\gamma_k \,:\!=\, \mathrm{Cov}_{\pi,P}[\,f(X_t),f(X_{t+k})] \,:\!=\,\mathbb{E}_{\pi,P}[\,f(X_t) f(X_{t+k})] =\langle\, {f}, {P^kf} \rangle \qquad \mbox{for $f\in L^2_0(\pi)$}.\end{align*}
\begin{align*}\gamma_k \,:\!=\, \mathrm{Cov}_{\pi,P}[\,f(X_t),f(X_{t+k})] \,:\!=\,\mathbb{E}_{\pi,P}[\,f(X_t) f(X_{t+k})] =\langle\, {f}, {P^kf} \rangle \qquad \mbox{for $f\in L^2_0(\pi)$}.\end{align*}
If
 $f = \sum_{i=1}^n a_i v_i$
as above (with
$f = \sum_{i=1}^n a_i v_i$
as above (with
 $a_1=0$
since the mean of f is zero) then, using the orthonormality of the eigenvectors
$a_1=0$
since the mean of f is zero) then, using the orthonormality of the eigenvectors
 $v_i$
,
$v_i$
,
 \begin{align*}\gamma_k = \langle\, {f}, {P^kf} \rangle =\sum_{i=2}^n \sum_{j=2}^n \langle {a_iv_i}, {P^k(a_jv_j)}\rangle =\sum_{i=2}^n \sum_{j=2}^n \langle {a_iv_i}, {(\lambda_j)^k a_jv_j)}\rangle =\sum_{i=2}^n (a_i)^2 (\lambda_i)^k .\end{align*}
\begin{align*}\gamma_k = \langle\, {f}, {P^kf} \rangle =\sum_{i=2}^n \sum_{j=2}^n \langle {a_iv_i}, {P^k(a_jv_j)}\rangle =\sum_{i=2}^n \sum_{j=2}^n \langle {a_iv_i}, {(\lambda_j)^k a_jv_j)}\rangle =\sum_{i=2}^n (a_i)^2 (\lambda_i)^k .\end{align*}
In particular,
 $\gamma_0 = \langle\, {f}, {f} \rangle \,:\!=\, \|f\|_{L^2(\pi)} = \sum_i (a_i)^2$
. (If the state space S were not finite, we would need to require
$\gamma_0 = \langle\, {f}, {f} \rangle \,:\!=\, \|f\|_{L^2(\pi)} = \sum_i (a_i)^2$
. (If the state space S were not finite, we would need to require
 $f \in L^2(\pi)$
, but finite variance is guaranteed with a finite state space.)
$f \in L^2(\pi)$
, but finite variance is guaranteed with a finite state space.)
One particular example of a transition matrix P, useful for comparative purposes, is
 $\Pi$
, the operator corresponding to i.i.d. sampling from
$\Pi$
, the operator corresponding to i.i.d. sampling from
 $\pi$
. It is defined by
$\pi$
. It is defined by
 $\Pi(x,y) = \pi(y)$
for all
$\Pi(x,y) = \pi(y)$
for all
 $x\in S$
. This operator satisfies
$x\in S$
. This operator satisfies
 $\Pi \mathbf{1} = \mathbf{1}$
, and
$\Pi \mathbf{1} = \mathbf{1}$
, and
 $\Pi f = 0$
whenever
$\Pi f = 0$
whenever
 $\pi(f)=0$
. Hence, its eigenvalues are
$\pi(f)=0$
. Hence, its eigenvalues are
 $\lambda_1=1$
and
$\lambda_1=1$
and
 $\lambda_i=0$
for
$\lambda_i=0$
for
 $i\ne1$
.
$i\ne1$
.
3. Relating asymptotic variance to eigenvalues
In this section we consider some expressions for the asymptotic variance, v(f, P), of (1), beginning with a result relating the asymptotic variance to the eigenvalues of P. This result (as observed by [Reference Geyer10]) can be obtained (at least in the aperiodic case) as a special case of the more technical results of [Reference Kipnis and Varadhan15, (1.1)].
Proposition 1. If P is an irreducible (but possibly periodic) Markov chain on a finite state space S and is reversible with respect to
 $\pi$
, with an orthonormal basis
$\pi$
, with an orthonormal basis
 $v_1,v_2,\ldots,v_n$
of eigenvectors and corresponding eigenvalues
$v_1,v_2,\ldots,v_n$
of eigenvectors and corresponding eigenvalues
 $\lambda_1\ge\lambda_2\ge\cdots\ge\lambda_n$
, and
$\lambda_1\ge\lambda_2\ge\cdots\ge\lambda_n$
, and
 $f\in L^2_0(\pi)$
with
$f\in L^2_0(\pi)$
with
 $f=\sum_i a_i v_i$
, then the limit v(f, P) in (1) exists, and
$f=\sum_i a_i v_i$
, then the limit v(f, P) in (1) exists, and
 \begin{align*} v(f,P) = \sum_{i=2}^n (a_i)^2 + 2\sum_{i=2}^n(a_i)^2\frac{\lambda_i}{1-\lambda_i} = \sum_{i=2}^n(a_i)^2\frac{1+\lambda_i}{1-\lambda_i} . \end{align*}
\begin{align*} v(f,P) = \sum_{i=2}^n (a_i)^2 + 2\sum_{i=2}^n(a_i)^2\frac{\lambda_i}{1-\lambda_i} = \sum_{i=2}^n(a_i)^2\frac{1+\lambda_i}{1-\lambda_i} . \end{align*}
Proof. First, by expanding the square, using stationarity, and collecting like terms, we obtain the well-known result that, for
 $f\in L^2_0(\pi)$
,
$f\in L^2_0(\pi)$
,
 \begin{align*} \frac{1}{N}\mathrm{Var}\Bigg(\sum_{i=1}^N f(X_i)\Bigg) & = \frac{1}{N}\mathbb{E}_{\pi,P}\Bigg[\Bigg(\sum_{i=1}^N f(X_i)\Bigg)^{2}\Bigg] \\ & = \frac{1}{N}\Bigg(N\mathbb{E}_{\pi,P}[\,f(X_j)^2] + 2\sum_{k=1}^{N-1}(N-k)\mathbb{E}_{\pi,P}[\,f(X_j)f(X_{j+k})]\Bigg) \\ & = \gamma_0 + 2\sum_{k=1}^{N-1} \frac{N-k}{N} \gamma_k , \end{align*}
\begin{align*} \frac{1}{N}\mathrm{Var}\Bigg(\sum_{i=1}^N f(X_i)\Bigg) & = \frac{1}{N}\mathbb{E}_{\pi,P}\Bigg[\Bigg(\sum_{i=1}^N f(X_i)\Bigg)^{2}\Bigg] \\ & = \frac{1}{N}\Bigg(N\mathbb{E}_{\pi,P}[\,f(X_j)^2] + 2\sum_{k=1}^{N-1}(N-k)\mathbb{E}_{\pi,P}[\,f(X_j)f(X_{j+k})]\Bigg) \\ & = \gamma_0 + 2\sum_{k=1}^{N-1} \frac{N-k}{N} \gamma_k , \end{align*}
where
 $\gamma_k = \mathrm{Cov}_{\pi,P}[\,f(X_j),f(X_{j+k})] = \langle\, {f}, {P^kf} \rangle$
is the lag-k autocovariance in stationarity.
$\gamma_k = \mathrm{Cov}_{\pi,P}[\,f(X_j),f(X_{j+k})] = \langle\, {f}, {P^kf} \rangle$
is the lag-k autocovariance in stationarity.
Now,
 $f = \sum_{i=1}^n a_i v_i$
, with
$f = \sum_{i=1}^n a_i v_i$
, with
 $a_1=0$
since
$a_1=0$
since
 $\pi(f)=0$
, so
$\pi(f)=0$
, so
 $\gamma_k = \langle\, {f}, {P^kf} \rangle = \sum_{i=2}^n (a_i)^2 (\lambda_i)^k$
and
$\gamma_k = \langle\, {f}, {P^kf} \rangle = \sum_{i=2}^n (a_i)^2 (\lambda_i)^k$
and
 $\gamma_0 = \sum_{i=2}^n (a_i)^2$
. The above then gives that
$\gamma_0 = \sum_{i=2}^n (a_i)^2$
. The above then gives that
 \begin{equation} \frac{1}{N} \mathrm{Var}\Bigg(\sum_{i=1}^N f(X_i)\Bigg) = \sum_{i=2}^n (a_i)^2 + 2\sum_{k=1}^{N-1} \frac{N-k}{N} \sum_{i=2}^n (a_i)^2 (\lambda_i)^k , \end{equation}
\begin{equation} \frac{1}{N} \mathrm{Var}\Bigg(\sum_{i=1}^N f(X_i)\Bigg) = \sum_{i=2}^n (a_i)^2 + 2\sum_{k=1}^{N-1} \frac{N-k}{N} \sum_{i=2}^n (a_i)^2 (\lambda_i)^k , \end{equation}
that is,
 \begin{align*} \frac{1}{N} \mathrm{Var}\Bigg(\sum_{i=1}^N f(X_i)\Bigg) = \sum_{i=2}^n (a_i)^2 + 2\sum_{k=1}^\infty\sum_{i=2}^n 1_{k \le N-1} \frac{N-k}{N} (a_i)^2 (\lambda_i)^k . \end{align*}
\begin{align*} \frac{1}{N} \mathrm{Var}\Bigg(\sum_{i=1}^N f(X_i)\Bigg) = \sum_{i=2}^n (a_i)^2 + 2\sum_{k=1}^\infty\sum_{i=2}^n 1_{k \le N-1} \frac{N-k}{N} (a_i)^2 (\lambda_i)^k . \end{align*}
If P is aperiodic, then
 $\Lambda \,:\!=\, \max_{i \ge 2} |\lambda_i| < 1$
, and hence
$\Lambda \,:\!=\, \max_{i \ge 2} |\lambda_i| < 1$
, and hence
 \begin{align*} \sum_{k=1}^\infty\Bigg|\sum_{i=2}^n 1_{k \le N-1} \frac{N-k}{N} (a_i)^2 (\lambda_i)^k\Bigg| & \le \sum_{k=1}^\infty\sum_{i=2}^n\bigg|1_{k \le N-1} \frac{N-k}{N} (a_i)^2 (\lambda_i)^k \bigg| \\ & \le \sum_{k=1}^\infty\sum_{i=2}^n (a_i)^2 (\Lambda)^k = \gamma_0 \frac{\Lambda D}{(1-\Lambda)}
< \infty, \end{align*}
\begin{align*} \sum_{k=1}^\infty\Bigg|\sum_{i=2}^n 1_{k \le N-1} \frac{N-k}{N} (a_i)^2 (\lambda_i)^k\Bigg| & \le \sum_{k=1}^\infty\sum_{i=2}^n\bigg|1_{k \le N-1} \frac{N-k}{N} (a_i)^2 (\lambda_i)^k \bigg| \\ & \le \sum_{k=1}^\infty\sum_{i=2}^n (a_i)^2 (\Lambda)^k = \gamma_0 \frac{\Lambda D}{(1-\Lambda)}
< \infty, \end{align*}
so the above sum is absolutely summable. This lets us exchange the limit and summations to obtain
 \begin{align*} v(f,P) & \,:\!=\, \lim_{N\to\infty} \frac{1}{N} \mathrm{Var}\Bigg(\sum_{i=1}^N f(X_i)\Bigg) \\ & = \sum_{i=2}^n (a_i)^2 + 2\sum_{i=2}^n\sum_{k=1}^\infty \lim_{N\to\infty}\bigg[1_{k \le N-1} \frac{N-k}{N} (a_i)^2 (\lambda_i)^k \bigg] \\ & = \sum_{i=2}^n (a_i)^2 + 2\sum_{i=2}^n\sum_{k=1}^\infty(a_i)^2 (\lambda_i)^k \\ & = \sum_{i=2}^n (a_i)^2 + 2\sum_{i=2}^n(a_i)^2 \frac{\lambda_i}{1-\lambda_i} = \sum_{i=2}^n(a_i)^2 \frac{1+\lambda_i}{1-\lambda_i} . \end{align*}
\begin{align*} v(f,P) & \,:\!=\, \lim_{N\to\infty} \frac{1}{N} \mathrm{Var}\Bigg(\sum_{i=1}^N f(X_i)\Bigg) \\ & = \sum_{i=2}^n (a_i)^2 + 2\sum_{i=2}^n\sum_{k=1}^\infty \lim_{N\to\infty}\bigg[1_{k \le N-1} \frac{N-k}{N} (a_i)^2 (\lambda_i)^k \bigg] \\ & = \sum_{i=2}^n (a_i)^2 + 2\sum_{i=2}^n\sum_{k=1}^\infty(a_i)^2 (\lambda_i)^k \\ & = \sum_{i=2}^n (a_i)^2 + 2\sum_{i=2}^n(a_i)^2 \frac{\lambda_i}{1-\lambda_i} = \sum_{i=2}^n(a_i)^2 \frac{1+\lambda_i}{1-\lambda_i} . \end{align*}
If P is periodic, with
 $\lambda_n=-1$
, then the above
$\lambda_n=-1$
, then the above
 $\Lambda=1$
, and
$\Lambda=1$
, and
 $\sum_{k=1}^\infty (\lambda_n)^k$
is not even defined, so the above argument does not apply. Instead, separate out the
$\sum_{k=1}^\infty (\lambda_n)^k$
is not even defined, so the above argument does not apply. Instead, separate out the
 $i=n$
term in (2) to get
$i=n$
term in (2) to get
 \begin{align*} \frac{1}{N} \mathrm{Var}\Bigg(\sum_{i=1}^N f(X_i)\Bigg) = \sum_{i=2}^n (a_i)^2 + 2\sum_{k=1}^{N-1} \frac{N-k}{N} \sum_{i=2}^{n-1} (a_i)^2 (\lambda_i)^k + 2\sum_{k=1}^{N-1} \frac{N-k}{N} (a_n)^2 ({-}1)^k . \end{align*}
\begin{align*} \frac{1}{N} \mathrm{Var}\Bigg(\sum_{i=1}^N f(X_i)\Bigg) = \sum_{i=2}^n (a_i)^2 + 2\sum_{k=1}^{N-1} \frac{N-k}{N} \sum_{i=2}^{n-1} (a_i)^2 (\lambda_i)^k + 2\sum_{k=1}^{N-1} \frac{N-k}{N} (a_n)^2 ({-}1)^k . \end{align*}
Since
 $\Gamma \,:\!=\, \max\{|\lambda_2|,|\lambda_3|,\ldots,|\lambda_{n-1}|\} < 1$
, the previous argument applies to the middle double-sum term to show that
$\Gamma \,:\!=\, \max\{|\lambda_2|,|\lambda_3|,\ldots,|\lambda_{n-1}|\} < 1$
, the previous argument applies to the middle double-sum term to show that
 \begin{align*} \lim_{N\to\infty} 2\sum_{k=1}^{N-1} \frac{N-k}{N} \sum_{i=2}^{n-1} (a_i)^2 (\lambda_i)^k = 2\sum_{i=2}^{n-1} (a_i)^2 \frac{\lambda_i}{1-\lambda_i} . \end{align*}
\begin{align*} \lim_{N\to\infty} 2\sum_{k=1}^{N-1} \frac{N-k}{N} \sum_{i=2}^{n-1} (a_i)^2 (\lambda_i)^k = 2\sum_{i=2}^{n-1} (a_i)^2 \frac{\lambda_i}{1-\lambda_i} . \end{align*}
As for the final term, writing values for k as
 $2m-1$
or 2m, we have
$2m-1$
or 2m, we have
 \begin{align*} \sum_{k=1}^{N-1} \frac{N-k}{N} ({-}1)^k & = \frac{1}{N} \sum_{m=1}^{\lfloor (N-1)/2 \rfloor}[{-}(N-2m+1)+(N-2m)] - \frac{1}{N} 1_{N\,\mathrm{odd}} \\ & = \frac{1}{N} \sum_{m=1}^{\lfloor (N-1)/2 \rfloor}[{-}1] - \frac{1}{N} 1_{N\,\mathrm{odd}} = -\frac{\lfloor (N-1)/2 \rfloor}{N} - \frac{1}{N} 1_{N\,\mathrm{odd}} , \end{align*}
\begin{align*} \sum_{k=1}^{N-1} \frac{N-k}{N} ({-}1)^k & = \frac{1}{N} \sum_{m=1}^{\lfloor (N-1)/2 \rfloor}[{-}(N-2m+1)+(N-2m)] - \frac{1}{N} 1_{N\,\mathrm{odd}} \\ & = \frac{1}{N} \sum_{m=1}^{\lfloor (N-1)/2 \rfloor}[{-}1] - \frac{1}{N} 1_{N\,\mathrm{odd}} = -\frac{\lfloor (N-1)/2 \rfloor}{N} - \frac{1}{N} 1_{N\,\mathrm{odd}} , \end{align*}
which converges as
 $N\to\infty$
to
$N\to\infty$
to
 \begin{align*}-\frac{1}{2} = \frac{-1}{1-({-}1)} = \frac{\lambda_n}{1-\lambda_n}.\end{align*}
\begin{align*}-\frac{1}{2} = \frac{-1}{1-({-}1)} = \frac{\lambda_n}{1-\lambda_n}.\end{align*}
So, we again obtain that
 \begin{align*} v(f,P) & = \lim_{N\to\infty}\frac{1}{N} \mathrm{Var}\Bigg(\sum_{i=1}^N f(X_i)\Bigg) \\ & = \sum_{i=2}^n (a_i)^2 + 2\sum_{i=2}^{n-1} (a_i)^2 \frac{\lambda_i}{1-\lambda_i} + 2(a_n)^2 \frac{\lambda_n}{1-\lambda_n} \\ & = \sum_{i=2}^n (a_i)^2 + 2\sum_{i=2}^n (a_i)^2 \frac{\lambda_i}{1-\lambda_i} = \sum_{i=2}^n (a_i)^2 \frac{1+\lambda_i}{1-\lambda_i} . \end{align*}
\begin{align*} v(f,P) & = \lim_{N\to\infty}\frac{1}{N} \mathrm{Var}\Bigg(\sum_{i=1}^N f(X_i)\Bigg) \\ & = \sum_{i=2}^n (a_i)^2 + 2\sum_{i=2}^{n-1} (a_i)^2 \frac{\lambda_i}{1-\lambda_i} + 2(a_n)^2 \frac{\lambda_n}{1-\lambda_n} \\ & = \sum_{i=2}^n (a_i)^2 + 2\sum_{i=2}^n (a_i)^2 \frac{\lambda_i}{1-\lambda_i} = \sum_{i=2}^n (a_i)^2 \frac{1+\lambda_i}{1-\lambda_i} . \end{align*}
Note that when P is periodic,
 $\lambda_n$
will be
$\lambda_n$
will be
 $-1$
and the final term in the expression for v(f, P) will be zero. Such a periodic P will have zero asymptotic variance when estimating the expectation of a function f for which
$-1$
and the final term in the expression for v(f, P) will be zero. Such a periodic P will have zero asymptotic variance when estimating the expectation of a function f for which
 $a_n$
is the only non-zero coefficient.
$a_n$
is the only non-zero coefficient.
When P is aperiodic, we can obtain from Proposition 1 the following more familiar [Reference Bartlett2, Reference Billingsley5, Reference Chan and Geyer7, Reference Häggström and Rosenthal12, Reference Huang and Mao14, Reference Tierney25] expression for v(f, P) in terms of sums of autocovariances, though it is not needed for this paper (and actually still holds without the reversibility condition [Reference Billingsley5, Theorem 20.1]).
Proposition 2. If P is a reversible, irreducible, aperiodic Markov chain on a finite state space S with stationary distribution
 $\pi$
, and
$\pi$
, and
 $f\in L^2_0(\pi)$
, then
$f\in L^2_0(\pi)$
, then
 \begin{equation*} v(f,P) = \lim_{N\to\infty} \frac{1}{N} \mathrm{Var}_\pi\Bigg(\sum_{i=1}^{N} f(X_i)\Bigg) = \gamma_0 + 2\sum_{k=1}^\infty \gamma_k , \end{equation*}
\begin{equation*} v(f,P) = \lim_{N\to\infty} \frac{1}{N} \mathrm{Var}_\pi\Bigg(\sum_{i=1}^{N} f(X_i)\Bigg) = \gamma_0 + 2\sum_{k=1}^\infty \gamma_k , \end{equation*}
where
 $\gamma_k = \mathrm{Cov}_{\pi,P}[\,f(X_t),f(X_{t+k})]$
is the lag-k autocovariance of f in stationarity.
$\gamma_k = \mathrm{Cov}_{\pi,P}[\,f(X_t),f(X_{t+k})]$
is the lag-k autocovariance of f in stationarity.
Proof. Since
 $\gamma_k = \langle\, {f}, {P^kf} \rangle$
, and as above, in the aperiodic case,
$\gamma_k = \langle\, {f}, {P^kf} \rangle$
, and as above, in the aperiodic case,
 $\Lambda \,:\!=\, \sup_{i \ge 2} |\lambda_i| < 1$
, the double-sum is again absolutely summable, and we compute directly that if
$\Lambda \,:\!=\, \sup_{i \ge 2} |\lambda_i| < 1$
, the double-sum is again absolutely summable, and we compute directly that if
 $f=\sum_i a_i v_i$
then
$f=\sum_i a_i v_i$
then
 \begin{align*}
\gamma_0 + 2\sum_{k=1}^\infty \gamma_k = \langle\, {f}, {f} \rangle + 2\sum_{k=1}^\infty \langle\, {f}, {P^kf} \rangle & = \sum_i (a_i)^2 + 2\sum_{k=1}^\infty{\sum}_i (a_i)^2 (\lambda_i)^k \\
& = \sum_i (a_i)^2 + 2\sum_i (a_i)^2\sum_{k=1}^\infty (\lambda_i)^k \\
& = \sum_i (a_i)^2 + 2\sum_i (a_i)^2 \frac{\lambda_i}{1-\lambda_i} , \end{align*}
\begin{align*}
\gamma_0 + 2\sum_{k=1}^\infty \gamma_k = \langle\, {f}, {f} \rangle + 2\sum_{k=1}^\infty \langle\, {f}, {P^kf} \rangle & = \sum_i (a_i)^2 + 2\sum_{k=1}^\infty{\sum}_i (a_i)^2 (\lambda_i)^k \\
& = \sum_i (a_i)^2 + 2\sum_i (a_i)^2\sum_{k=1}^\infty (\lambda_i)^k \\
& = \sum_i (a_i)^2 + 2\sum_i (a_i)^2 \frac{\lambda_i}{1-\lambda_i} , \end{align*}
so the result follows from Proposition 1.
Proposition 1 gives the following formula for v(f, P) (see also [Reference Mira and Geyer19, Lemma 3.2]).
Proposition 3. The asymptotic variance, v(f,P), for the functional
 $f \in L^2_0(\pi)$
using an irreducible Markov chain P which is reversible with respect to
$f \in L^2_0(\pi)$
using an irreducible Markov chain P which is reversible with respect to
 $\pi$
satisfies the equation
$\pi$
satisfies the equation
 $v(f,P) = \langle\, {f}, {f} \rangle + 2\langle\, {f}, {P(I-P)^{-1} f}\rangle$
, which we can also write as
$v(f,P) = \langle\, {f}, {f} \rangle + 2\langle\, {f}, {P(I-P)^{-1} f}\rangle$
, which we can also write as
 \begin{align*} v(f,P) = \langle\, {f}, {f} \rangle + 2\bigg\langle\, {f},{\frac{P}{I-P} f}\bigg\rangle \qquad \mathrm{or} \qquad v(f,P) = \bigg\langle\, {f}, {\frac{I+P}{I-P} f}\bigg\rangle. \end{align*}
\begin{align*} v(f,P) = \langle\, {f}, {f} \rangle + 2\bigg\langle\, {f},{\frac{P}{I-P} f}\bigg\rangle \qquad \mathrm{or} \qquad v(f,P) = \bigg\langle\, {f}, {\frac{I+P}{I-P} f}\bigg\rangle. \end{align*}
Proof. Let P have an orthonormal basis
 $v_1,v_2,\ldots,v_n$
, with eigenvalues
$v_1,v_2,\ldots,v_n$
, with eigenvalues
 $\lambda_1,\lambda_2,\ldots,\lambda_n$
, and using this basis let
$\lambda_1,\lambda_2,\ldots,\lambda_n$
, and using this basis let
 $f=\sum_i a_i v_i$
. Note that
$f=\sum_i a_i v_i$
. Note that
 $a_1=0$
, since f has mean zero, so we can ignore
$a_1=0$
, since f has mean zero, so we can ignore
 $v_1$
and
$v_1$
and
 $\lambda_1$
. Define
$\lambda_1$
. Define
 $h(\lambda) \,:\!=\, \lambda (1-\lambda)^{-1}$
. As discussed in Section 2, applying h to the eigenvalues of P will produce another self-adjoint matrix, with the same eigenvectors, which will equal
$h(\lambda) \,:\!=\, \lambda (1-\lambda)^{-1}$
. As discussed in Section 2, applying h to the eigenvalues of P will produce another self-adjoint matrix, with the same eigenvectors, which will equal
 $P(I-P)^{-1}$
. Using this, we can write
$P(I-P)^{-1}$
. Using this, we can write
 \begin{align*} \langle\, {f}, {f} \rangle + 2\langle\, {f}, {P(I-P)^{-1} f}\rangle & = \sum_i (a_i)^2 + 2\sum_i\sum_j\langle {a_i v_i}, {P(I-P)^{-1} (a_j v_j)}\rangle \\ & = \sum_i (a_i)^2 + 2\sum_i\sum_j\langle {a_i v_i}, {\lambda_j (1-\lambda_j)^{-1} (a_j v_j)}\rangle \\ & = \sum_i (a_i)^2 + 2\sum_i (a_i)^2 \lambda_i (1-\lambda_i)^{-1} , \end{align*}
\begin{align*} \langle\, {f}, {f} \rangle + 2\langle\, {f}, {P(I-P)^{-1} f}\rangle & = \sum_i (a_i)^2 + 2\sum_i\sum_j\langle {a_i v_i}, {P(I-P)^{-1} (a_j v_j)}\rangle \\ & = \sum_i (a_i)^2 + 2\sum_i\sum_j\langle {a_i v_i}, {\lambda_j (1-\lambda_j)^{-1} (a_j v_j)}\rangle \\ & = \sum_i (a_i)^2 + 2\sum_i (a_i)^2 \lambda_i (1-\lambda_i)^{-1} , \end{align*}
so the result follows from Proposition 1.
Remark 1. If we write
 $P = \sum_{i=1}^n \lambda_i v_i v_i^\top D$
, so
$P = \sum_{i=1}^n \lambda_i v_i v_i^\top D$
, so
 $I-P = \sum_{i=1}^n(1-\lambda_i)v_i v_i^\top D$
, then on
$I-P = \sum_{i=1}^n(1-\lambda_i)v_i v_i^\top D$
, then on
 $L^2_0(\pi)$
this becomes
$L^2_0(\pi)$
this becomes
 $I-P = \sum_{i=2}^n(1-\lambda_i)v_i v_i^\top D$
, so
$I-P = \sum_{i=2}^n(1-\lambda_i)v_i v_i^\top D$
, so
 $(I-P)^{-1} = \sum_{i=2}^n(1-\lambda_i)^{-1}v_i v_i^\top D$
.
$(I-P)^{-1} = \sum_{i=2}^n(1-\lambda_i)^{-1}v_i v_i^\top D$
.
Remark 2. The inverse
 $(I-P)^{-1}$
in Proposition 3 is on the restricted space
$(I-P)^{-1}$
in Proposition 3 is on the restricted space
 $L^2_0(\pi)$
of functions f with
$L^2_0(\pi)$
of functions f with
 $\pi(f)=0$
. That is,
$\pi(f)=0$
. That is,
 $(I-P)^{-1}(I-P)f = (I-P)(I-P)^{-1}f = f$
for any f in
$(I-P)^{-1}(I-P)f = (I-P)(I-P)^{-1}f = f$
for any f in
 $L^2_0(\pi)$
. By contrast,
$L^2_0(\pi)$
. By contrast,
 $I-P$
will not be invertible on the full space
$I-P$
will not be invertible on the full space
 $L^2(\pi)$
of all functions on S, since, for example,
$L^2(\pi)$
of all functions on S, since, for example,
 $(I-P)\mathbf{1}=\mathbf{1}-\mathbf{1}=\mathbf{0}$
, so if
$(I-P)\mathbf{1}=\mathbf{1}-\mathbf{1}=\mathbf{0}$
, so if
 $(I-P)^{-1}$
existed on all of
$(I-P)^{-1}$
existed on all of
 $L^2(\pi)$
then we would have the contradiction that
$L^2(\pi)$
then we would have the contradiction that
 $\mathbf{1} = (I-P)^{-1}(I-P)\mathbf{1} = (I-P)^{-1}\mathbf{0} = \mathbf{0}$
.
$\mathbf{1} = (I-P)^{-1}(I-P)\mathbf{1} = (I-P)^{-1}\mathbf{0} = \mathbf{0}$
.
4. Efficiency dominance equivalences
Combining Proposition 3 with the definition of efficiency dominance proves the following result.
Proposition 4. For reversible irreducible Markov chain transition matrices P and Q, P efficiency-dominates Q if and only if
 $\langle\,{f},{P(I-P)^{-1}f}\rangle \le \langle\,{f},{Q(I-Q)^{-1}f}\rangle$
for all
$\langle\,{f},{P(I-P)^{-1}f}\rangle \le \langle\,{f},{Q(I-Q)^{-1}f}\rangle$
for all
 $f\in L^2_0(\pi)$
, or informally if
$f\in L^2_0(\pi)$
, or informally if
 \begin{align*}\bigg\langle\, {f},{\frac{P}{I-P}\,f}\bigg\rangle \le \bigg\langle\,{f}, {\frac{Q}{I-Q}\,f}\bigg\rangle\end{align*}
\begin{align*}\bigg\langle\, {f},{\frac{P}{I-P}\,f}\bigg\rangle \le \bigg\langle\,{f}, {\frac{Q}{I-Q}\,f}\bigg\rangle\end{align*}
for all
 $f \in L^2_0(\pi)$
.
$f \in L^2_0(\pi)$
.
Next, we need the following fact.
Lemma 2. If P and Q are reversible and irreducible Markov chain transition matrices,
 $\langle\, {f} {P(I-P)^{-1}f}\rangle \le \langle\, {f}, {Q(I-Q)^{-1}f}\rangle$
for all
$\langle\, {f} {P(I-P)^{-1}f}\rangle \le \langle\, {f}, {Q(I-Q)^{-1}f}\rangle$
for all
 $f \in L^2_0(\pi)$
$f \in L^2_0(\pi)$
 $\textrm{if and only if}$
$\textrm{if and only if}$
 $\langle\,{f},{Pf}\rangle \le \langle\,{f},{Qf}\rangle$
for all
$\langle\,{f},{Pf}\rangle \le \langle\,{f},{Qf}\rangle$
for all
 $f \in L^2_0(\pi)$
.
$f \in L^2_0(\pi)$
.
Lemma 2 follows from the very technical results of [Reference Bendat and Sherman3]. It is somewhat subtle since the equivalence is only for all f at once, not for individual f; see the discussion after Lemma 7. In Section 8 we present an elementary proof. (For alternative direct proofs of Lemma 2 and related facts, see also [Reference Bhatia4, Chapter V].)
Combining Lemma 2 and Proposition 4 immediately shows the following, which is also shown in [Reference Mira and Geyer19, Theorem 4.2].
Theorem 1. For Markov chain transition matrices P and Q that are reversible and irreducible, P efficiency-dominates Q if and only if
 $\langle\,{f},{Pf}\rangle \le \langle\,{f},{Qf}\rangle$
for all
$\langle\,{f},{Pf}\rangle \le \langle\,{f},{Qf}\rangle$
for all
 $f \in L^2_0(\pi)$
, i.e.
$f \in L^2_0(\pi)$
, i.e.
 $\textrm{if and only if}$
$\textrm{if and only if}$
 $\langle\,{f},{(Q-P)f}\rangle \ge 0$
for all
$\langle\,{f},{(Q-P)f}\rangle \ge 0$
for all
 $f \in L^2_0(\pi)$
.
$f \in L^2_0(\pi)$
.
Remark 3. Here, the restriction that
 $f \in L^2_0(\pi)$
, i.e. that
$f \in L^2_0(\pi)$
, i.e. that
 $\pi(f)=0$
, can be omitted, since if
$\pi(f)=0$
, can be omitted, since if
 $c \,:\!=\, \pi(f) \not= 0$
then
$c \,:\!=\, \pi(f) \not= 0$
then
 $f=f_0+c$
where
$f=f_0+c$
where
 $\pi(f_0)=0$
, and
$\pi(f_0)=0$
, and
 $\langle\,{f},{Pf}\rangle = \langle\,{f_0+c},{P(f_0+c)}\rangle = \langle\,{f_0},{Pf_0}\rangle + c^2$
, and similarly for Q. But we do not need this fact here.
$\langle\,{f},{Pf}\rangle = \langle\,{f_0+c},{P(f_0+c)}\rangle = \langle\,{f_0},{Pf_0}\rangle + c^2$
, and similarly for Q. But we do not need this fact here.
Remark 4. Some authors (e.g. [Reference Mira and Geyer19]) say that P covariance-dominates Q if
 $\langle\, {f}, {Pf} \rangle \le \langle\, {f}, {Qf} \rangle$
for all
$\langle\, {f}, {Pf} \rangle \le \langle\, {f}, {Qf} \rangle$
for all
 $f\in L^2_0(\pi)$
, or equivalently if
$f\in L^2_0(\pi)$
, or equivalently if
 $\mathrm{Cov}_{\pi,P}[\,f(X_t), f(X_{t+1})]$
is always smaller under P than under Q. The surprising conclusion of Theorem 1 is that for reversible chains this is equivalent to efficiency dominance – i.e. to
$\mathrm{Cov}_{\pi,P}[\,f(X_t), f(X_{t+1})]$
is always smaller under P than under Q. The surprising conclusion of Theorem 1 is that for reversible chains this is equivalent to efficiency dominance – i.e. to
 $v(f,P) \le v(f,Q)$
for all
$v(f,P) \le v(f,Q)$
for all
 $f\in L^2_0(\pi)$
. So, there is no need to consider the two concepts separately.
$f\in L^2_0(\pi)$
. So, there is no need to consider the two concepts separately.
To make the condition
 $\langle\, {f},{(Q-P)f}\rangle \ge 0$
for all f more concrete, we have the following lemma.
$\langle\, {f},{(Q-P)f}\rangle \ge 0$
for all f more concrete, we have the following lemma.
Lemma 3. Any self-adjoint matrix J satisfies
 $\langle\,{f},{Jf}\rangle \ge 0$
for all f if and only if the eigenvalues of J are all non-negative, which is if and only if the eigenvalues of DJ are all non-negative, where
$\langle\,{f},{Jf}\rangle \ge 0$
for all f if and only if the eigenvalues of J are all non-negative, which is if and only if the eigenvalues of DJ are all non-negative, where
 $D=\mathrm{diag}(\pi)$
.
$D=\mathrm{diag}(\pi)$
.
Proof. Let J have an orthonormal basis of eigenvectors
 $v_1,v_2,\ldots,v_n$
as in Section 2, so any f can be written as
$v_1,v_2,\ldots,v_n$
as in Section 2, so any f can be written as
 $f = \sum_{i=1}^n a_i v_i$
. Then
$f = \sum_{i=1}^n a_i v_i$
. Then
 \begin{align*} \langle\,{f},{Jf}\rangle = \bigg\langle\,{\sum_i a_i v_i},{\sum_j a_j Jv_j}\bigg\rangle = \bigg\langle\,{\sum_i a_i v_i},{\sum_j a_j \lambda_j v_j}\bigg\rangle = \sum_i (a_i)^2 \lambda_i . \end{align*}
\begin{align*} \langle\,{f},{Jf}\rangle = \bigg\langle\,{\sum_i a_i v_i},{\sum_j a_j Jv_j}\bigg\rangle = \bigg\langle\,{\sum_i a_i v_i},{\sum_j a_j \lambda_j v_j}\bigg\rangle = \sum_i (a_i)^2 \lambda_i . \end{align*}
If each
 $\lambda_i \ge 0$
, then this expression must be
$\lambda_i \ge 0$
, then this expression must be
 $\ge 0$
. Conversely, if some
$\ge 0$
. Conversely, if some
 $\lambda_i<0$
, then choosing
$\lambda_i<0$
, then choosing
 $f=v_i$
gives
$f=v_i$
gives
 $\langle\,{f},{Jf}\rangle = \lambda_i < 0$
. This proves the first statement.
$\langle\,{f},{Jf}\rangle = \lambda_i < 0$
. This proves the first statement.
For the second statement, recall that DJ is self-adjoint with respect to the classical dot-product. Hence, by the above, the matrix product
 $f^\top DJf \ge 0$
for all f if and only if the eigenvalues of DJ are all non-negative. So, since
$f^\top DJf \ge 0$
for all f if and only if the eigenvalues of DJ are all non-negative. So, since
 $f^\top DJf = \langle\,{f},{Jf}\rangle$
, the two statements are equivalent.
$f^\top DJf = \langle\,{f},{Jf}\rangle$
, the two statements are equivalent.
Combining Lemma 3 (with J replaced by
 $Q-P$
) with Theorem 1 shows the following result.
$Q-P$
) with Theorem 1 shows the following result.
Theorem 2. If P and Q are reversible, irreducible Markov chain transitions, P efficiency-dominates Q if and only if the operator
 $Q-P$
(equivalently, the matrix
$Q-P$
(equivalently, the matrix
 $Q-P$
) has all eigenvalues non-negative, which is if and only if the matrix
$Q-P$
) has all eigenvalues non-negative, which is if and only if the matrix
 $D\,(Q-P)$
has all eigenvalues non-negative.
$D\,(Q-P)$
has all eigenvalues non-negative.
Remark 5. By Theorem 2, if
 $Q-P$
has even a single negative eigenvalue, say
$Q-P$
has even a single negative eigenvalue, say
 $(Q-P)z = -cz$
where
$(Q-P)z = -cz$
where
 $c>0$
, then there must be some
$c>0$
, then there must be some
 $f\in L^2_0(\pi)$
such that
$f\in L^2_0(\pi)$
such that
 $v(f,Q) < v(f,P)$
. By following through our proof of Lemma 2 in Section 8, it might be possible to construct such an f explicitly in terms of z and c. We leave this as an open problem.
$v(f,Q) < v(f,P)$
. By following through our proof of Lemma 2 in Section 8, it might be possible to construct such an f explicitly in terms of z and c. We leave this as an open problem.
Remark 6. It might be possible to give another alternative proof of Theorem 2 using the step-wise approach of [Reference Neal20] by writing
 $Q-P = R_1+R_2+\cdots+R_\ell$
, where each
$Q-P = R_1+R_2+\cdots+R_\ell$
, where each
 $R_i$
is of rank one (e.g.
$R_i$
is of rank one (e.g.
 $R_i=\lambda_i v_i v_i^\top D$
with
$R_i=\lambda_i v_i v_i^\top D$
with
 $\lambda_i$
and
$\lambda_i$
and
 $v_i$
an eigenvalue and eigenvector of
$v_i$
an eigenvalue and eigenvector of
 $Q-P$
). We leave this as another open problem.
$Q-P$
). We leave this as another open problem.
Theorem 2 allows us to prove the following, which helps justify the phrase ‘efficiency-dominates’ (see also [Reference Mira and Geyer19, Section 4]).
Theorem 3. Efficiency dominance is a partial order on reversible chains:
-
(i) It is reflexive: P always efficiency-dominates P.
-
(ii) It is antisymmetric: if P efficiency-dominates Q, and Q efficiency-dominates P, then
$P=Q$
. -
(iii) It is transitive: if P efficiency-dominates Q, and Q efficiency-dominates R, then P efficiency-dominates R.

Proof. Statement (i) is trivial. Statement (iii) is true because
 $v(f,P) \le v(f,Q)$
and
$v(f,P) \le v(f,Q)$
and
 $v(f,Q) \le v(f,R)$
imply
$v(f,Q) \le v(f,R)$
imply
 $v(f,P) \le v(f,R)$
. For statement (ii), Theorem 2 implies that both
$v(f,P) \le v(f,R)$
. For statement (ii), Theorem 2 implies that both
 $Q-P$
and
$Q-P$
and
 $P-Q$
have all eigenvalues non-negative, and hence their eigenvalues must all be zero, which implies (since
$P-Q$
have all eigenvalues non-negative, and hence their eigenvalues must all be zero, which implies (since
 $Q-P$
is self-adjoint) that
$Q-P$
is self-adjoint) that
 $Q-P=0$
, and hence
$Q-P=0$
, and hence
 $P=Q$
.
$P=Q$
.
Remark 7. Theorem 3(ii) does not hold if we do not assume reversibility. For example, if
 $S=\{1,2,3\}$
,
$S=\{1,2,3\}$
,
 $\pi=\mathrm{Uniform}(S)$
,
$\pi=\mathrm{Uniform}(S)$
,
 $P(1,2)=P(2,3)=P(3,1)=1$
, and
$P(1,2)=P(2,3)=P(3,1)=1$
, and
 $Q(1,3)=Q(3,2)=Q(2,1)=1$
, then
$Q(1,3)=Q(3,2)=Q(2,1)=1$
, then
 $v(f,P)=v(f,Q)=0$
for all
$v(f,P)=v(f,Q)=0$
for all
 $f\colon S\to\mathbb{R}$
, so they each (weakly) efficiency-dominate the other, but
$f\colon S\to\mathbb{R}$
, so they each (weakly) efficiency-dominate the other, but
 $P\not=Q$
.
$P\not=Q$
.
5. Efficiency dominance of combined chains
Using Theorems 1 and 2, we can now prove some new results about efficiency dominance that are useful when Markov chains are constructed by combining two or more chains.
We first consider the situation where we randomly choose to apply transitions defined either by P or by Q. For example, P might move about one region of the state space well, while Q moves about a different region well. Randomly choosing either P or Q may produce a chain that moves well over the entire state space. The following theorem says that if in this situation we can improve P to P ′, then the random combination will also be improved.
Theorem 4. Let P, P′, and Q be reversible with respect to
 $\pi$
, with P and P′ irreducible, and let
$\pi$
, with P and P′ irreducible, and let
 $0<a<1$
. Then P′ efficiency-dominates P
$0<a<1$
. Then P′ efficiency-dominates P
 $\textrm{if and only if}$
$\textrm{if and only if}$
 $aP'+(1-a)Q$
efficiency-dominates
$aP'+(1-a)Q$
efficiency-dominates
 $aP+(1-a)Q$
.
$aP+(1-a)Q$
.
Proof. Since P and P
′ are irreducible, so are
 $aP'+(1-a)Q$
and
$aP'+(1-a)Q$
and
 $aP+(1-a)Q$
. So, by Theorem 2, P′ efficiency-dominates P if and only if
$aP+(1-a)Q$
. So, by Theorem 2, P′ efficiency-dominates P if and only if
 $P-P'$
has all non-negative eigenvalues, which is clearly if and only if
$P-P'$
has all non-negative eigenvalues, which is clearly if and only if
 $a(P-P') = [aP+(1-a)Q] - [aP'+(1-a)Q]$
has all non-negative eigenvalues, which is if and only if
$a(P-P') = [aP+(1-a)Q] - [aP'+(1-a)Q]$
has all non-negative eigenvalues, which is if and only if
 $aP'+(1-a)Q$
efficiency-dominates
$aP'+(1-a)Q$
efficiency-dominates
 $aP+(1-a)Q$
.
$aP+(1-a)Q$
.
The next result applies to Markov chains built using component transition matrices that are not necessarily irreducible, such as single-variable updates in a random-scan Gibbs sampler, again showing that improving one of the components will improve the combination, assuming the combination is irreducible.
Theorem 5. Let
 $P_1,\ldots,P_{\ell}$
and
$P_1,\ldots,P_{\ell}$
and
 $P^{\prime}_1,\ldots,P^{\prime}_{\ell}$
be reversible with respect to
$P^{\prime}_1,\ldots,P^{\prime}_{\ell}$
be reversible with respect to
 $\pi$
(though not necessarily irreducible). Let
$\pi$
(though not necessarily irreducible). Let
 $a_1,\ldots,a_{\ell}$
be mixing probabilities, with
$a_1,\ldots,a_{\ell}$
be mixing probabilities, with
 $a_k>0$
and
$a_k>0$
and
 $\sum_k a_k = 1$
, and let
$\sum_k a_k = 1$
, and let
 $P = a_1 P_1 + \cdots + a_{\ell} P_{\ell}$
and
$P = a_1 P_1 + \cdots + a_{\ell} P_{\ell}$
and
 $P' = a_1 P^{\prime}_1 + \cdots + a_{\ell} P^{\prime}_{\ell}$
. Then if P and P′ are irreducible, and for each k the eigenvalues of
$P' = a_1 P^{\prime}_1 + \cdots + a_{\ell} P^{\prime}_{\ell}$
. Then if P and P′ are irreducible, and for each k the eigenvalues of
 $P_k-P^{\prime}_k$
(or of
$P_k-P^{\prime}_k$
(or of
 $D(P_k-P^{\prime}_k)$
where
$D(P_k-P^{\prime}_k)$
where
 $D=\mathrm{diag}(\pi)$
) are all non-negative, then P′ efficiency-dominates P.
$D=\mathrm{diag}(\pi)$
) are all non-negative, then P′ efficiency-dominates P.
Proof. Choose any
 $f\in L^2_0(\pi)$
. Since
$f\in L^2_0(\pi)$
. Since
 $P_k$
and
$P_k$
and
 $P^{\prime}_k$
are self-adjoint, we have, from Lemma 3, that
$P^{\prime}_k$
are self-adjoint, we have, from Lemma 3, that
 $\langle\,{f},{(P_k-P^{\prime}_k)f}\rangle \ge 0$
for each k. Then, by linearity,
$\langle\,{f},{(P_k-P^{\prime}_k)f}\rangle \ge 0$
for each k. Then, by linearity,
 \begin{align*} \langle\,{f},{(P-P')f}\rangle = \bigg\langle\,{f},{\sum_k a_k (P_k-P^{\prime}_k)f}\bigg\rangle = \sum_k a_k \langle\,{f},{(P_k-P^{\prime}_k)f}\rangle \ge 0 \end{align*}
\begin{align*} \langle\,{f},{(P-P')f}\rangle = \bigg\langle\,{f},{\sum_k a_k (P_k-P^{\prime}_k)f}\bigg\rangle = \sum_k a_k \langle\,{f},{(P_k-P^{\prime}_k)f}\rangle \ge 0 \end{align*}
too. Hence, by Theorem 1, P ′ efficiency-dominates P.
In the Gibbs sampling application, the state is composed of
 $\ell$
components, so that
$\ell$
components, so that
 $S = S_1 \times S_2 \times \cdots \times S_{\ell}$
, and
$S = S_1 \times S_2 \times \cdots \times S_{\ell}$
, and
 $P_k$
is the transition that samples a value for component k, independent of its current value, from its conditional distribution given the values of other components, while leaving the values of these other components unchanged. Since it leaves other components unchanged, such a
$P_k$
is the transition that samples a value for component k, independent of its current value, from its conditional distribution given the values of other components, while leaving the values of these other components unchanged. Since it leaves other components unchanged, such a
 $P_k$
will not be irreducible.
$P_k$
will not be irreducible.
 $P_k$
will be a block-diagonal matrix, in a suitable ordering of states (different for each k), with
$P_k$
will be a block-diagonal matrix, in a suitable ordering of states (different for each k), with
 $B=|S|/|S_k|$
blocks, each of size
$B=|S|/|S_k|$
blocks, each of size
 $K=|S_k|$
.
$K=|S_k|$
.
For example, suppose
 $\ell=2$
,
$\ell=2$
,
 $S_1=\{1,2\}$
,
$S_1=\{1,2\}$
,
 $S_2=\{1,2,3\}$
, and
$S_2=\{1,2,3\}$
, and
 $\pi(x)=\frac19$
except that
$\pi(x)=\frac19$
except that
 $\pi((1,2))=\frac49$
. With lexicographic ordering, the Gibbs sampling transition matrix for the second component,
$\pi((1,2))=\frac49$
. With lexicographic ordering, the Gibbs sampling transition matrix for the second component,
 $P_2$
, will be
$P_2$
, will be
 \begin{align*} P_2 = \begin{pmatrix}\begin{array}{c@{\quad}c@{\quad}c@{\quad}c@{\quad}c@{\quad}c} \frac16 & \frac46 & \frac16 & 0 & 0 & 0 \\[5pt] \frac16 & \frac46 & \frac16 & 0 & 0 & 0 \\[5pt] \frac16 & \frac46 & \frac16 & 0 & 0 & 0 \\[5pt] 0 & 0 & 0 & \frac13 & \frac13 & \frac13 \\[5pt] 0 & 0 & 0 & \frac13 & \frac13 & \frac13 \\[5pt] 0 & 0 & 0 & \frac13 & \frac13 & \frac13 \end{array} \end{pmatrix}.\end{align*}
\begin{align*} P_2 = \begin{pmatrix}\begin{array}{c@{\quad}c@{\quad}c@{\quad}c@{\quad}c@{\quad}c} \frac16 & \frac46 & \frac16 & 0 & 0 & 0 \\[5pt] \frac16 & \frac46 & \frac16 & 0 & 0 & 0 \\[5pt] \frac16 & \frac46 & \frac16 & 0 & 0 & 0 \\[5pt] 0 & 0 & 0 & \frac13 & \frac13 & \frac13 \\[5pt] 0 & 0 & 0 & \frac13 & \frac13 & \frac13 \\[5pt] 0 & 0 & 0 & \frac13 & \frac13 & \frac13 \end{array} \end{pmatrix}.\end{align*}
Each block of
 $P_k$
can be regarded as the
$P_k$
can be regarded as the
 $K\times K$
transition matrix for a Markov chain having
$K\times K$
transition matrix for a Markov chain having
 $S_k$
as its state space, which is reversible with respect to the conditional distribution on
$S_k$
as its state space, which is reversible with respect to the conditional distribution on
 $S_k$
given the values for other components associated with this block. For each block, the eigenvalues and eigenvectors of this transition matrix give rise to corresponding eigenvalues and eigenvectors of
$S_k$
given the values for other components associated with this block. For each block, the eigenvalues and eigenvectors of this transition matrix give rise to corresponding eigenvalues and eigenvectors of
 $P_k$
, after prepending and appending zeros to the eigenvector according to how many blocks precede and follow this block. If the transition matrix for each block is irreducible, there will be B eigenvalues of
$P_k$
, after prepending and appending zeros to the eigenvector according to how many blocks precede and follow this block. If the transition matrix for each block is irreducible, there will be B eigenvalues of
 $P_k$
equal to one, with eigenvectors of the form
$P_k$
equal to one, with eigenvectors of the form
 $[0,\ldots,0,1,\ldots,1,0,\ldots,0]^\top$
, which are zero except for a series of K ones corresponding to one of the blocks.
$[0,\ldots,0,1,\ldots,1,0,\ldots,0]^\top$
, which are zero except for a series of K ones corresponding to one of the blocks.
The overall transition matrix when using Gibbs sampling to update a component randomly chosen with equal probabilities will be
 $P =(1/\ell) (P_1 + \cdots + P_{\ell})$
. We can try to improve the efficiency of P by modifying one or more of the
$P =(1/\ell) (P_1 + \cdots + P_{\ell})$
. We can try to improve the efficiency of P by modifying one or more of the
 $P_k$
. An improvement to
$P_k$
. An improvement to
 $P_k$
can take the form of an improvement to one of its blocks, each of which corresponds to particular values of components of the state other than component k. With each
$P_k$
can take the form of an improvement to one of its blocks, each of which corresponds to particular values of components of the state other than component k. With each
 $P_k$
changed to
$P_k$
changed to
 $P^{\prime}_k$
, the modified overall transition matrix is
$P^{\prime}_k$
, the modified overall transition matrix is
 $P' = (1/\ell) (P^{\prime}_1+ \cdots + P^{\prime}_{\ell})$
.
$P' = (1/\ell) (P^{\prime}_1+ \cdots + P^{\prime}_{\ell})$
.
For the example above, we could try to improve P by improving
 $P_2$
, with the improvement to
$P_2$
, with the improvement to
 $P_2$
taking the form of an improvement to how the second component is changed when the first component has the value 1, as follows:
$P_2$
taking the form of an improvement to how the second component is changed when the first component has the value 1, as follows:
 \begin{align*}P^{\prime}_2 =\begin{pmatrix}\begin{array}{c@{\quad}c@{\quad}c@{\quad}c@{\quad}c@{\quad}c} 0 & 1 & 0 & 0 & 0 & 0 \\[5pt] \frac14 & \frac24 & \frac14 & 0 & 0 & 0 \\[5pt] 0 & 1 & 0 & 0 & 0 & 0 \\[5pt] 0 & 0 & 0 & \frac13 & \frac13 & \frac13 \\[5pt] 0 & 0 & 0 & \frac13 & \frac13 & \frac13 \\[5pt] 0 & 0 & 0 & \frac13 & \frac13 & \frac13 \end{array}\end{pmatrix}.\end{align*}
\begin{align*}P^{\prime}_2 =\begin{pmatrix}\begin{array}{c@{\quad}c@{\quad}c@{\quad}c@{\quad}c@{\quad}c} 0 & 1 & 0 & 0 & 0 & 0 \\[5pt] \frac14 & \frac24 & \frac14 & 0 & 0 & 0 \\[5pt] 0 & 1 & 0 & 0 & 0 & 0 \\[5pt] 0 & 0 & 0 & \frac13 & \frac13 & \frac13 \\[5pt] 0 & 0 & 0 & \frac13 & \frac13 & \frac13 \\[5pt] 0 & 0 & 0 & \frac13 & \frac13 & \frac13 \end{array}\end{pmatrix}.\end{align*}
The change to the
 $3\times3$
upper-left block still leaves it reversible with respect to the conditional distribution for the second component given the value 1 for the first component
$3\times3$
upper-left block still leaves it reversible with respect to the conditional distribution for the second component given the value 1 for the first component
 $\big($
which has probabilities of
$\big($
which has probabilities of
 $\frac16$
,
$\frac16$
,
 $\frac46$
,
$\frac46$
,
 $\frac16\big)$
, but introduces an antithetic aspect to the sampling.
$\frac16\big)$
, but introduces an antithetic aspect to the sampling.
If we leave
 $P_1$
unchanged, so
$P_1$
unchanged, so
 $P^{\prime}_1=P_1$
, Theorem 5 can be used to show that the P
′ built with this modified
$P^{\prime}_1=P_1$
, Theorem 5 can be used to show that the P
′ built with this modified
 $P^{\prime}_2$
efficiency-dominates P built with the original
$P^{\prime}_2$
efficiency-dominates P built with the original
 $P_1$
and
$P_1$
and
 $P_2$
. The difference
$P_2$
. The difference
 $P_2-P^{\prime}_2$
will also be block diagonal, and its eigenvalues will be those of the differences in the individual blocks (which are zero for blocks that have not been changed). In the example above, the one block in the upper-left that changed has difference
$P_2-P^{\prime}_2$
will also be block diagonal, and its eigenvalues will be those of the differences in the individual blocks (which are zero for blocks that have not been changed). In the example above, the one block in the upper-left that changed has difference
 \begin{align*}\begin{pmatrix}\begin{array}{c@{\quad}c@{\quad}c} \frac16 & \frac46 & \frac16 \\[5pt] \frac16 & \frac46 & \frac16 \\[5pt] \frac16 & \frac46 & \frac16 \end{array}\end{pmatrix}-\begin{pmatrix}\begin{array}{c@{\quad}c@{\quad}c} 0 & 1 & 0 \\[5pt] \frac14 & \frac24 & \frac14 \\[5pt] 0 & 1 & 0\end{array}\end{pmatrix}=\begin{pmatrix}\begin{array}{c@{\quad}c@{\quad}c} +\frac{2}{12} & -\frac{4}{12} & +\frac{2}{12} \\[5pt] -\frac{1}{12} & +\frac{2}{12} & -\frac{1}{12} \\[5pt] +\frac{2}{12} & -\frac{4}{12} & +\frac{2}{12}\end{array}\end{pmatrix}.\end{align*}
\begin{align*}\begin{pmatrix}\begin{array}{c@{\quad}c@{\quad}c} \frac16 & \frac46 & \frac16 \\[5pt] \frac16 & \frac46 & \frac16 \\[5pt] \frac16 & \frac46 & \frac16 \end{array}\end{pmatrix}-\begin{pmatrix}\begin{array}{c@{\quad}c@{\quad}c} 0 & 1 & 0 \\[5pt] \frac14 & \frac24 & \frac14 \\[5pt] 0 & 1 & 0\end{array}\end{pmatrix}=\begin{pmatrix}\begin{array}{c@{\quad}c@{\quad}c} +\frac{2}{12} & -\frac{4}{12} & +\frac{2}{12} \\[5pt] -\frac{1}{12} & +\frac{2}{12} & -\frac{1}{12} \\[5pt] +\frac{2}{12} & -\frac{4}{12} & +\frac{2}{12}\end{array}\end{pmatrix}.\end{align*}
The eigenvalues of this difference matrix are
 $\frac12$
, 0, and 0. The eigenvalues of
$\frac12$
, 0, and 0. The eigenvalues of
 $P_2-P^{\prime}_2$
will be these plus three more zeros. If
$P_2-P^{\prime}_2$
will be these plus three more zeros. If
 $P^{\prime}_1=P_1$
, Theorem 5 then guarantees that P
′ efficiency-dominates P, the original Gibbs sampling chain, since these eigenvalues are all non-negative. Note that here one cannot show efficiency dominance using Peskun dominance, since the change reduces some off-diagonal transition probabilities.
$P^{\prime}_1=P_1$
, Theorem 5 then guarantees that P
′ efficiency-dominates P, the original Gibbs sampling chain, since these eigenvalues are all non-negative. Note that here one cannot show efficiency dominance using Peskun dominance, since the change reduces some off-diagonal transition probabilities.
More generally, suppose a Gibbs sampling chain is changed by modifying one or more of the blocks of one or more of the
 $P_k$
, with the new blocks efficiency-dominating the old Gibbs sampling blocks (seen as transition matrices reversible with respect to the conditional distribution for that block). Then, by Theorem 2, the eigenvalues of the differences between the old and new blocks are all non-negative, which implies that the eigenvalues of
$P_k$
, with the new blocks efficiency-dominating the old Gibbs sampling blocks (seen as transition matrices reversible with respect to the conditional distribution for that block). Then, by Theorem 2, the eigenvalues of the differences between the old and new blocks are all non-negative, which implies that the eigenvalues of
 $P_k-P^{\prime}_k$
are all non-negative for each k, which by Theorem 5 implies that the modified chain efficiency-dominates the original Gibbs sampling chain. The practical applications of this are developed further in the companion paper [Reference Neal21].
$P_k-P^{\prime}_k$
are all non-negative for each k, which by Theorem 5 implies that the modified chain efficiency-dominates the original Gibbs sampling chain. The practical applications of this are developed further in the companion paper [Reference Neal21].
6. Efficiency dominance and eigenvalues
We now present some results relating eigenvalues of transition matrices to efficiency dominance, which can sometimes be used to show that a reversible transition matrix cannot be efficiency-dominated by any other reversible transition matrix.
Say that P eigen-dominates Q if both P and Q are reversible and the eigenvalues of P are no greater than the corresponding eigenvalues of Q – that is, when the eigenvalues of P (counting multiplicities) are written non-increasing as
 $\lambda_1 \ge \lambda_2 \ge \cdots \ge \lambda_n$
, and the eigenvalues of Q are written non-increasing as
$\lambda_1 \ge \lambda_2 \ge \cdots \ge \lambda_n$
, and the eigenvalues of Q are written non-increasing as
 $\beta_1 \ge \beta_2 \ge \cdots \ge \beta_n$
, then
$\beta_1 \ge \beta_2 \ge \cdots \ge \beta_n$
, then
 $\lambda_i \le \beta_i$
for each i. Then we have the following result (see also [Reference Mira and Geyer19, Theorem 3.3]).
$\lambda_i \le \beta_i$
for each i. Then we have the following result (see also [Reference Mira and Geyer19, Theorem 3.3]).
Proposition 5. If P and Q are irreducible and reversible with respect to
 $\pi$
, and P efficiency-dominates Q, then P eigen-dominates Q.
$\pi$
, and P efficiency-dominates Q, then P eigen-dominates Q.
Proof. By Theorem 1,
 $\langle\,{f}, {Pf}\rangle \le \langle\,{f},{Qf}\rangle$
for all
$\langle\,{f}, {Pf}\rangle \le \langle\,{f},{Qf}\rangle$
for all
 $f\in L^2_0(\pi)$
. Hence, the result follows from the ‘min-max’ characterisation of eigenvalues (e.g. [Reference Horn and Johnson13, Theorem 4.2.6]) that
$f\in L^2_0(\pi)$
. Hence, the result follows from the ‘min-max’ characterisation of eigenvalues (e.g. [Reference Horn and Johnson13, Theorem 4.2.6]) that
 \begin{align*} \lambda_i = \inf_{g_1,\ldots,g_{i-1}} \underset{\substack{{f\in L^2_0(\pi)}\\ {\langle\,{f},\,{f}\rangle=1}\\ \langle\,{f},{g_j}\rangle=0 \, \mathrm{for\,all} \, j}}{\sup} \langle\,{f},{Pf}\rangle . \end{align*}
\begin{align*} \lambda_i = \inf_{g_1,\ldots,g_{i-1}} \underset{\substack{{f\in L^2_0(\pi)}\\ {\langle\,{f},\,{f}\rangle=1}\\ \langle\,{f},{g_j}\rangle=0 \, \mathrm{for\,all} \, j}}{\sup} \langle\,{f},{Pf}\rangle . \end{align*}
Intuitively,
 $g_1,\ldots,g_{i-1}$
represent the first
$g_1,\ldots,g_{i-1}$
represent the first
 $i-1$
eigenvectors (excluding the eigenvector
$i-1$
eigenvectors (excluding the eigenvector
 $\mathbf{1}$
associated with the eigenvalue 1, since
$\mathbf{1}$
associated with the eigenvalue 1, since
 $\mathbf{1}\notin L^2_0(\pi)$
), so that the new eigenvector f will be orthogonal to them. However, since the formula is stated in terms of any vectors
$\mathbf{1}\notin L^2_0(\pi)$
), so that the new eigenvector f will be orthogonal to them. However, since the formula is stated in terms of any vectors
 $g_1,\ldots,g_{i-1}$
, the same formula applies for both P and Q, thus giving the result.
$g_1,\ldots,g_{i-1}$
, the same formula applies for both P and Q, thus giving the result.
The converse of Proposition 5 does not hold, contrary to a claim in [Reference Mira18, Theorem 2]. For example, suppose the state space is
 $S=\{1,2,3\}$
. Let
$S=\{1,2,3\}$
. Let
 $e=0.05$
, and let
$e=0.05$
, and let
 \begin{align*}P =\begin{pmatrix}\begin{array}{c@{\quad}c@{\quad}c} \frac{1}{2} & \frac{1}{2} & 0 \\[5pt] \frac{1}{2} & \frac{1}{2}-e & e \\[5pt] 0 & e & 1-e \end{array}\end{pmatrix}, \quad Q =\begin{pmatrix} \begin{array}{c@{\quad}c@{\quad}c} 1-e & e & 0 \\[5pt] e & \frac{1}{2}-e & \frac{1}{2} \\[5pt] 0 & \frac{1}{2} & \frac{1}{2}\end{array}\end{pmatrix}, \quad R =\begin{pmatrix}\begin{array}{c@{\quad}c@{\quad}c} 1-e & e & 0 \\[5pt] e & \frac{1}{2} & \frac{1}{2}-e \\[5pt] 0 & \frac{1}{2}-e & \frac{1}{2}+e\end{array}\end{pmatrix}. \end{align*}
\begin{align*}P =\begin{pmatrix}\begin{array}{c@{\quad}c@{\quad}c} \frac{1}{2} & \frac{1}{2} & 0 \\[5pt] \frac{1}{2} & \frac{1}{2}-e & e \\[5pt] 0 & e & 1-e \end{array}\end{pmatrix}, \quad Q =\begin{pmatrix} \begin{array}{c@{\quad}c@{\quad}c} 1-e & e & 0 \\[5pt] e & \frac{1}{2}-e & \frac{1}{2} \\[5pt] 0 & \frac{1}{2} & \frac{1}{2}\end{array}\end{pmatrix}, \quad R =\begin{pmatrix}\begin{array}{c@{\quad}c@{\quad}c} 1-e & e & 0 \\[5pt] e & \frac{1}{2} & \frac{1}{2}-e \\[5pt] 0 & \frac{1}{2}-e & \frac{1}{2}+e\end{array}\end{pmatrix}. \end{align*}
These all are reversible with respect to
 $\pi = \mathrm{Uniform}(S)$
, and are irreducible and aperiodic. We can see that P eigen-dominates Q (and vice versa), since P and Q are equivalent upon swapping states 1 and 3, and so have the same eigenvalues, which are equal (to four decimal places) to 1,
$\pi = \mathrm{Uniform}(S)$
, and are irreducible and aperiodic. We can see that P eigen-dominates Q (and vice versa), since P and Q are equivalent upon swapping states 1 and 3, and so have the same eigenvalues, which are equal (to four decimal places) to 1,
 $0.9270$
,
$0.9270$
,
 $-0.0270$
. However, P does not efficiency-dominate Q, since
$-0.0270$
. However, P does not efficiency-dominate Q, since
 $Q-P$
has eigenvalues
$Q-P$
has eigenvalues
 $0.7794$
, 0,
$0.7794$
, 0,
 $-0.7794$
which are not all non-negative. (Nor does Q efficiency-dominate P, analogously.)
$-0.7794$
which are not all non-negative. (Nor does Q efficiency-dominate P, analogously.)
Intuitively, in this example, Q moves easily between states 2 and 3, but only infrequently to or from state 1, while P moves easily between states 1 and 2 but not to or from state 3. Hence, if, for example,
 $f(1)=2$
,
$f(1)=2$
,
 $f(2)=1$
, and
$f(2)=1$
, and
 $f(3)=3$
, so that
$f(3)=3$
, so that
 $f(1)=\frac{1}{2}[\,f(2)+f(3)]$
, then
$f(1)=\frac{1}{2}[\,f(2)+f(3)]$
, then
 $v(f,Q) < v(f,P)$
, since Q moving slowly between
$v(f,Q) < v(f,P)$
, since Q moving slowly between
 $\{1\}$
and
$\{1\}$
and
 $\{2,3\}$
doesn’t matter, but P moving slowly between
$\{2,3\}$
doesn’t matter, but P moving slowly between
 $\{1,2\}$
and
$\{1,2\}$
and
 $\{3\}$
does matter.
$\{3\}$
does matter.
R is a slight modification to Q that has two smaller off-diagonal elements, and hence is Peskun-dominated (and efficiency-dominated) by Q. Its eigenvalues are 1,
 $0.9272$
,
$0.9272$
,
 $0.0728$
, the latter two of which are strictly larger than those of P, so P eigen-dominates R. But the eigenvalues of
$0.0728$
, the latter two of which are strictly larger than those of P, so P eigen-dominates R. But the eigenvalues of
 $R-P$
are
$R-P$
are
 $0.7865$
, 0,
$0.7865$
, 0,
 $-0.6865$
, which are not all non-negative, so P does not efficiency-dominate R, despite strictly eigen-dominating it.
$-0.6865$
, which are not all non-negative, so P does not efficiency-dominate R, despite strictly eigen-dominating it.
However, the next result is in a sense a converse of Proposition 5 for the special case where all of the non-trivial eigenvalues for P are smaller than all of those for Q.
Theorem 6. Let P and Q be irreducible and reversible with respect to
 $\pi$
, with eigenvalues
$\pi$
, with eigenvalues
 $1 = \lambda_1 \ge \lambda_2 \ge \lambda_3 \ge \cdots \ge \lambda_n$
for P and
$1 = \lambda_1 \ge \lambda_2 \ge \lambda_3 \ge \cdots \ge \lambda_n$
for P and
 $1 = \beta_1 \ge \beta_2 \ge \beta_3 \ge \cdots \ge \beta_n$
for Q (counting multiplicities). Suppose
$1 = \beta_1 \ge \beta_2 \ge \beta_3 \ge \cdots \ge \beta_n$
for Q (counting multiplicities). Suppose
 $\max_{i \ge 2} \lambda_i \le \min_{i \ge 2} \beta_i$
, i.e.
$\max_{i \ge 2} \lambda_i \le \min_{i \ge 2} \beta_i$
, i.e.
 $\lambda_2 \le \beta_n$
, i.e.
$\lambda_2 \le \beta_n$
, i.e.
 $\lambda_i \le \beta_j$
for any
$\lambda_i \le \beta_j$
for any
 $i,j \ge 2$
. Then P efficiency-dominates Q.
$i,j \ge 2$
. Then P efficiency-dominates Q.
Proof. Let a be the maximum eigenvalue of P restricted to
 $L^2_0(\pi)$
, and let b be the minimum eigenvalue of Q restricted to
$L^2_0(\pi)$
, and let b be the minimum eigenvalue of Q restricted to
 $L^2_0(\pi)$
, which for both P and Q will exclude the eigenvalue of 1 associated with
$L^2_0(\pi)$
, which for both P and Q will exclude the eigenvalue of 1 associated with
 $\mathbf{1}$
. The assumptions imply that
$\mathbf{1}$
. The assumptions imply that
 $a \le b$
. But the ‘min-max’ characterisation of eigenvalues (described in the proof of Proposition 5) applied to the largest eigenvalue on
$a \le b$
. But the ‘min-max’ characterisation of eigenvalues (described in the proof of Proposition 5) applied to the largest eigenvalue on
 $L^2_0(\pi)$
(i.e. excluding the eigenvalue 1), implies that
$L^2_0(\pi)$
(i.e. excluding the eigenvalue 1), implies that
 \begin{align*} a = \underset{\substack{{f\in L^2_0(\pi)}\\ \langle\,{f},\,{f}\rangle=1}}{\sup} \langle\,{f},{Pf}\rangle . \end{align*}
\begin{align*} a = \underset{\substack{{f\in L^2_0(\pi)}\\ \langle\,{f},\,{f}\rangle=1}}{\sup} \langle\,{f},{Pf}\rangle . \end{align*}
Also, since
 $-b$
is the largest eigenvalue of
$-b$
is the largest eigenvalue of
 $-Q$
,
$-Q$
,
 \begin{align*} b = -\underset{\substack{{f\in L^2_0(\pi)}\\ \langle\,{f},\,{f}\rangle=1}}{\sup} \langle\,{f},{-Qf}\rangle = \underset{\substack{{f\in L^2_0(\pi)}\\ \langle\,{f},\,{f}\rangle=1}}{\inf} \langle\,{f},{Qf}\rangle . \end{align*}
\begin{align*} b = -\underset{\substack{{f\in L^2_0(\pi)}\\ \langle\,{f},\,{f}\rangle=1}}{\sup} \langle\,{f},{-Qf}\rangle = \underset{\substack{{f\in L^2_0(\pi)}\\ \langle\,{f},\,{f}\rangle=1}}{\inf} \langle\,{f},{Qf}\rangle . \end{align*}
Since
 $a \le b$
, this implies that
$a \le b$
, this implies that
 $\langle\,{f},{Pf}\rangle \le \langle\,{f},{Qf}\rangle$
for any
$\langle\,{f},{Pf}\rangle \le \langle\,{f},{Qf}\rangle$
for any
 $f\in L^2_0(\pi)$
with
$f\in L^2_0(\pi)$
with
 $\langle\,{f},{f}\rangle=1$
, and hence (by linearity) for any
$\langle\,{f},{f}\rangle=1$
, and hence (by linearity) for any
 $f \in L^2_0(\pi)$
. It then follows from Theorem 1 that P efficiency-dominates Q.
$f \in L^2_0(\pi)$
. It then follows from Theorem 1 that P efficiency-dominates Q.
A chain is called ‘antithetic’ (cf. [Reference Green and Han11]) if all its eigenvalues (except
 $\lambda_1=1$
) are non-positive, with at least one negative. Our next result shows that such antithetic samplers always efficiency-dominate i.i.d. sampling.
$\lambda_1=1$
) are non-positive, with at least one negative. Our next result shows that such antithetic samplers always efficiency-dominate i.i.d. sampling.
Corollary 1. If P is irreducible and reversible with respect to
 $\pi$
, and has eigenvalues
$\pi$
, and has eigenvalues
 $\lambda_1=1$
and
$\lambda_1=1$
and
 $\lambda_2,\lambda_3,\ldots,\lambda_n \le 0$
, then P efficiency-dominates
$\lambda_2,\lambda_3,\ldots,\lambda_n \le 0$
, then P efficiency-dominates
 $\Pi$
(the operator corresponding to i.i.d. sampling from
$\Pi$
(the operator corresponding to i.i.d. sampling from
 $\pi$
).
$\pi$
).
Proof. By assumption,
 $\max_{i \ge 2} \lambda_i \le 0$
. Also, if
$\max_{i \ge 2} \lambda_i \le 0$
. Also, if
 $1 = \beta_1 \ge \beta_2 \ge \beta_3 \ge \cdots \ge \beta_n$
are the eigenvalues for
$1 = \beta_1 \ge \beta_2 \ge \beta_3 \ge \cdots \ge \beta_n$
are the eigenvalues for
 $\Pi$
, then
$\Pi$
, then
 $\beta_i=0$
for all
$\beta_i=0$
for all
 $i \ge 2$
, so
$i \ge 2$
, so
 $\min_{i \ge 2} \beta_i = 0$
. Hence,
$\min_{i \ge 2} \beta_i = 0$
. Hence,
 $\max_{i \ge 2} \lambda_i \le \min_{i \ge 2} \beta_i$
. The result then follows from Theorem 6.
$\max_{i \ge 2} \lambda_i \le \min_{i \ge 2} \beta_i$
. The result then follows from Theorem 6.
Remark 8. Theorem 1 of [Reference Frigessi, Hwang and Younes8] shows that if
 $\pi_{\min} = \min_x \pi(x)$
, the maximum eigenvalue (other than
$\pi_{\min} = \min_x \pi(x)$
, the maximum eigenvalue (other than
 $\lambda_1$
) of a transition matrix reversible with respect to
$\lambda_1$
) of a transition matrix reversible with respect to
 $\pi$
must be greater than or equal to
$\pi$
must be greater than or equal to
 $-\pi_{\min}/(1-\pi_{\min})$
, which must be greater than or equal to
$-\pi_{\min}/(1-\pi_{\min})$
, which must be greater than or equal to
 $-1/(n-1)$
since
$-1/(n-1)$
since
 $\pi_{\min} \le 1/n$
. Now, if
$\pi_{\min} \le 1/n$
. Now, if
 $f = v_i$
where
$f = v_i$
where
 $\lambda_i \ge -1/(n-1)$
, then Proposition 1 gives
$\lambda_i \ge -1/(n-1)$
, then Proposition 1 gives
 $v(f,P) = (1+\lambda_i)/(1-\lambda_i) \ge (n-2)/n$
, which for large n is only slightly smaller than
$v(f,P) = (1+\lambda_i)/(1-\lambda_i) \ge (n-2)/n$
, which for large n is only slightly smaller than
 $v(f,\Pi) = (1+0)/(1-0) = 1$
. On the other hand, we can still have e.g.
$v(f,\Pi) = (1+0)/(1-0) = 1$
. On the other hand, we can still have e.g.
 $\lambda_1=1$
,
$\lambda_1=1$
,
 $\lambda_n=-1$
, and all the other
$\lambda_n=-1$
, and all the other
 $\lambda_i=0$
, and then if
$\lambda_i=0$
, and then if
 $f = v_n$
then
$f = v_n$
then
 $v(f,P) = (1+({-}1))/(1-({-}1)) = 0/2 = 0$
, which is significantly less than
$v(f,P) = (1+({-}1))/(1-({-}1)) = 0/2 = 0$
, which is significantly less than
 $v(f,\Pi) = 1$
. Hence, the improvement in Corollary 1 could be large for some functions f, but small for some others.
$v(f,\Pi) = 1$
. Hence, the improvement in Corollary 1 could be large for some functions f, but small for some others.
Since practical interest focuses on whether or not some chain, P, efficiency-dominates another chain, Q, Proposition 5 is perhaps most useful in its contrapositive form – if P and Q are reversible, and P does not eigen-dominate Q, then P does not efficiency-dominate Q. That is, if Q has at least one eigenvalue less than the corresponding eigenvalue of P, then P does not efficiency-dominate Q. If both chains have an eigenvalue less than the corresponding eigenvalue of the other chain, then neither efficiency-dominates the other.
But what if two different chains have exactly the same ordered set of eigenvalues – that is, they both eigen-dominate the other? In that case, neither efficiency-dominates the other. To show that, we first prove a result about strict trace comparisons.
Theorem 7. If P and Q are both irreducible transitions matrices, reversible with respect to
 $\pi$
, P efficiency-dominates Q, and
$\pi$
, P efficiency-dominates Q, and
 $P \ne Q$
, then
$P \ne Q$
, then
 $\mathrm{trace}(P)<\mathrm{trace}(Q)$
, i.e. the trace (or equivalently the sum of eigenvalues) of P is strictly smaller than that of Q.
$\mathrm{trace}(P)<\mathrm{trace}(Q)$
, i.e. the trace (or equivalently the sum of eigenvalues) of P is strictly smaller than that of Q.
Proof. By Theorem 2, if P efficiency-dominates Q, then
 $Q-P$
has no negative eigenvalues. And it cannot have all zero eigenvalues, since then
$Q-P$
has no negative eigenvalues. And it cannot have all zero eigenvalues, since then
 $Q-P=0$
(since
$Q-P=0$
(since
 $Q-P$
is self-adjoint), contradicting the premise that
$Q-P$
is self-adjoint), contradicting the premise that
 $P \ne Q$
. So,
$P \ne Q$
. So,
 $Q-P$
has at least one positive eigenvalue and no negative eigenvalues, and hence the sum of eigenvalues of
$Q-P$
has at least one positive eigenvalue and no negative eigenvalues, and hence the sum of eigenvalues of
 $Q-P$
is strictly positive. But the sum of the eigenvalues of a matrix is equal to its trace [Reference Horn and Johnson13, p. 51], so this is equivalent to
$Q-P$
is strictly positive. But the sum of the eigenvalues of a matrix is equal to its trace [Reference Horn and Johnson13, p. 51], so this is equivalent to
 $\mathrm{trace}(Q-P)>0$
. Since trace is linear, this implies that
$\mathrm{trace}(Q-P)>0$
. Since trace is linear, this implies that
 $\mathrm{trace}(Q)-\mathrm{trace}(P) > 0$
, and hence
$\mathrm{trace}(Q)-\mathrm{trace}(P) > 0$
, and hence
 $\mathrm{trace}(P)<\mathrm{trace}(Q)$
.
$\mathrm{trace}(P)<\mathrm{trace}(Q)$
.
Corollary 2. If P and Q are both irreducible transitions matrices, reversible with respect to
 $\pi$
, the eigenvalues (counting multiplicity) for both are identical, and
$\pi$
, the eigenvalues (counting multiplicity) for both are identical, and
 $P \ne Q$
, then P does not efficiency-dominate Q, and Q does not efficiency-dominate P.
$P \ne Q$
, then P does not efficiency-dominate Q, and Q does not efficiency-dominate P.
Proof. If P and Q have identical eigenvalues, then
 $\mathrm{trace}(P) = \mathrm{trace}(Q)$
, so this follows immediately from Theorem 7.
$\mathrm{trace}(P) = \mathrm{trace}(Q)$
, so this follows immediately from Theorem 7.
We next present a lemma about minimal values of
 $\mathrm{trace}(P)$
.
$\mathrm{trace}(P)$
.
Lemma 4. For any transition matrix P on a finite state space S, for which
 $\pi$
is a stationary distribution, the sum of the diagonal elements of P – that is,
$\pi$
is a stationary distribution, the sum of the diagonal elements of P – that is,
 $\mathrm{trace}(P)$
– must be at least
$\mathrm{trace}(P)$
– must be at least
 $\max(0, (2\pi_{\max}-1)/\pi_{\max})$
, where
$\max(0, (2\pi_{\max}-1)/\pi_{\max})$
, where
 $\pi_{\max}=\max_x \pi(x)$
. Furthermore, any P attaining this minimum value will have at most one non-zero value on its diagonal, and any such non-zero diagonal value will be for a state
$\pi_{\max}=\max_x \pi(x)$
. Furthermore, any P attaining this minimum value will have at most one non-zero value on its diagonal, and any such non-zero diagonal value will be for a state
 $x^*$
for which
$x^*$
for which
 $\pi(x^*)=\pi_{\max} > \frac12$
.
$\pi(x^*)=\pi_{\max} > \frac12$
.
Proof. The statement is trivial when
 $\pi_{\max} \le \frac12$
, since the lower limit on
$\pi_{\max} \le \frac12$
, since the lower limit on
 $\mathrm{trace}(P)$
is then zero, and any such P has all zeros on the diagonal. Otherwise, if
$\mathrm{trace}(P)$
is then zero, and any such P has all zeros on the diagonal. Otherwise, if
 $x^*$
is such that
$x^*$
is such that
 $\pi(x^*)=\pi_{\max} > \frac12$
, then stationarity implies that
$\pi(x^*)=\pi_{\max} > \frac12$
, then stationarity implies that
 \begin{align*} \pi_{\max} = \pi(x^*) = \sum_{x\in S} \pi(x) P(x,x^*) & = \pi(x^*)P(x^*,x^*) + \sum_{x\in S,\,x\ne x^*}\pi(x)P(x,x^*) \\ & \le \pi(x^*)P(x^*,x^*) + \sum_{x\in S,\, x\ne x^*}\pi(x) \\ & = \pi(x^*)P(x^*,x^*) + (1-\pi(x^*)) \\ & = \pi_{\max}P(x^*,x^*) + (1 - \pi_{\max}) . \end{align*}
\begin{align*} \pi_{\max} = \pi(x^*) = \sum_{x\in S} \pi(x) P(x,x^*) & = \pi(x^*)P(x^*,x^*) + \sum_{x\in S,\,x\ne x^*}\pi(x)P(x,x^*) \\ & \le \pi(x^*)P(x^*,x^*) + \sum_{x\in S,\, x\ne x^*}\pi(x) \\ & = \pi(x^*)P(x^*,x^*) + (1-\pi(x^*)) \\ & = \pi_{\max}P(x^*,x^*) + (1 - \pi_{\max}) . \end{align*}
It follows that
 $P(x^*,x^*) \ge (2\pi_{\max}-1)/\pi_{\max}$
, and hence
$P(x^*,x^*) \ge (2\pi_{\max}-1)/\pi_{\max}$
, and hence
 $\mathrm{trace}(P) \ge \max(0, (2\pi_{\max}-1)/\pi_{\max})$
. Furthermore, if
$\mathrm{trace}(P) \ge \max(0, (2\pi_{\max}-1)/\pi_{\max})$
. Furthermore, if
 $\mathrm{trace}(P)=\max(0, (2\pi_{\max}-1)/\pi_{\max})$
, then
$\mathrm{trace}(P)=\max(0, (2\pi_{\max}-1)/\pi_{\max})$
, then
 $\mathrm{trace}(P)=P(x^*,x^*)$
, and hence all other values on the diagonal of P must be zero.
$\mathrm{trace}(P)=P(x^*,x^*)$
, and hence all other values on the diagonal of P must be zero.
Remark 9. For any
 $\pi$
, the minimum value of
$\pi$
, the minimum value of
 $\mathrm{trace}(P)$
in Lemma 4 is attainable, and can indeed be attained by a P that is reversible. Several methods for constructing such a P are discussed in the companion paper [Reference Neal21], including, for example, the ‘shifted tower’ method of [Reference Suwa24], which produces a reversible P when the shift is by
$\mathrm{trace}(P)$
in Lemma 4 is attainable, and can indeed be attained by a P that is reversible. Several methods for constructing such a P are discussed in the companion paper [Reference Neal21], including, for example, the ‘shifted tower’ method of [Reference Suwa24], which produces a reversible P when the shift is by
 $\frac12$
.
$\frac12$
.
We can now state a criterion for a reversible chain to not be efficiency-dominated by any other reversible chain.
Theorem 8. If P is the transition matrix for an irreducible Markov chain on a finite state space that is reversible with respect to
 $\pi$
, and the sum of the eigenvalues of P (equivalently, the trace of P) equals
$\pi$
, and the sum of the eigenvalues of P (equivalently, the trace of P) equals
 $\max(0, (2\pi_{\max}-1)/\pi_{\max})$
, where
$\max(0, (2\pi_{\max}-1)/\pi_{\max})$
, where
 $\pi_{\max}=\max_x \pi(x)$
, then no other reversible chain can efficiency-dominate P.
$\pi_{\max}=\max_x \pi(x)$
, then no other reversible chain can efficiency-dominate P.
Proof. A reversible chain, Q, not equal to P, that efficiency-dominates P must, by Theorem 7, have
 $\mathrm{trace}(Q) < \mathrm{trace}(P)$
. But by Lemma 4,
$\mathrm{trace}(Q) < \mathrm{trace}(P)$
. But by Lemma 4,
 $\mathrm{trace}(P)$
is as small as possible, so there can be no reversible Q that efficiency-dominates P.
$\mathrm{trace}(P)$
is as small as possible, so there can be no reversible Q that efficiency-dominates P.
As an example of how this theorem can be applied, if the state space is
 $S=\{1,2,3\}$
, with
$S=\{1,2,3\}$
, with
 $\pi(1)=\pi(2)=\frac15$
and
$\pi(1)=\pi(2)=\frac15$
and
 $\pi(3)=\frac35$
, for which
$\pi(3)=\frac35$
, for which
 $\pi_{\max}=\frac35$
, then the transition matrix
$\pi_{\max}=\frac35$
, then the transition matrix
 \begin{align*}P_1 =\begin{pmatrix}\begin{array}{c@{\quad}c@{\quad}c} 0 & 0 & 1 \\[5pt] 0 & 0 & 1 \\[5pt] \frac13 & \frac13 & \frac13\end{array}\end{pmatrix}\end{align*}
\begin{align*}P_1 =\begin{pmatrix}\begin{array}{c@{\quad}c@{\quad}c} 0 & 0 & 1 \\[5pt] 0 & 0 & 1 \\[5pt] \frac13 & \frac13 & \frac13\end{array}\end{pmatrix}\end{align*}
is reversible with respect to
 $\pi$
, and has eigenvalues 1, 0,
$\pi$
, and has eigenvalues 1, 0,
 $-\frac23$
, which sum to
$-\frac23$
, which sum to
 $\frac13$
(the trace). By Theorem 8,
$\frac13$
(the trace). By Theorem 8,
 $P_1$
cannot be efficiency-dominated by any other reversible transition matrix, since its sum of eigenvalues is equal to
$P_1$
cannot be efficiency-dominated by any other reversible transition matrix, since its sum of eigenvalues is equal to
 $(2\pi_{\max}-1)/\pi_{\max}$
.
$(2\pi_{\max}-1)/\pi_{\max}$
.
On the other hand, consider the following transition matrix, reversible with respect to the same
 $\pi$
:
$\pi$
:
 \begin{align*}P_2 =\begin{pmatrix}\begin{array}{c@{\quad}c@{\quad}c} 0 & \frac14 & \frac34 \\[5pt] \frac14 & 0 & \frac34 \\[5pt] \frac14 & \frac14 & \frac12\end{array}\end{pmatrix}.\end{align*}
\begin{align*}P_2 =\begin{pmatrix}\begin{array}{c@{\quad}c@{\quad}c} 0 & \frac14 & \frac34 \\[5pt] \frac14 & 0 & \frac34 \\[5pt] \frac14 & \frac14 & \frac12\end{array}\end{pmatrix}.\end{align*}
 $P_2$
has eigenvalues 1,
$P_2$
has eigenvalues 1,
 $-\frac14$
,
$-\frac14$
,
 $-\frac14$
, which sum to
$-\frac14$
, which sum to
 $\frac12$
, greater than
$\frac12$
, greater than
 $(2\pi_{\max}-1)/\pi_{\max}$
, so Theorem 8 does not apply. However,
$(2\pi_{\max}-1)/\pi_{\max}$
, so Theorem 8 does not apply. However,
 $P_2$
is an instance of a transition matrix constructed according to a procedure in [Reference Frigessi, Hwang and Younes8, Theorem 1], which was proved to have the property that the transition matrix produced has the smallest possible value for
$P_2$
is an instance of a transition matrix constructed according to a procedure in [Reference Frigessi, Hwang and Younes8, Theorem 1], which was proved to have the property that the transition matrix produced has the smallest possible value for
 $\lambda_2$
, and subject to having that value for
$\lambda_2$
, and subject to having that value for
 $\lambda_2$
, the smallest possible value for
$\lambda_2$
, the smallest possible value for
 $\lambda_3$
, etc. We can therefore again conclude from Proposition 5 and Corollary 2 that no other reversible chain can efficiency-dominate
$\lambda_3$
, etc. We can therefore again conclude from Proposition 5 and Corollary 2 that no other reversible chain can efficiency-dominate
 $P_2$
.
$P_2$
.
It’s easy to see that any reversible P with at least two non-zero diagonal elements, say P(x, x) and P(y, y), can be efficiency-dominated by a chain Q that is the same as P except that these diagonal elements are reduced, allowing Q(x, y) and Q(y, x) to be greater than P(x, y) and P(y, x), so that Q Peskun-dominates P. Theorem 8 shows that some reversible P in which only a single diagonal element is non-zero cannot be efficiency-dominated by any other reversible chain. We know of no examples of a reversible P with only one non-zero diagonal element that is dominated by another reversible chain, but we do not have a proof that this is impossible. This leads to the following open problem: Does there exists a reversible P with only one non-zero diagonal element that is efficiency-dominated by some other reversible chain?
7. Rederiving Peskun’s theorem
Recall that P Peskun-dominates Q if
 $P(x,y) \ge Q(x,y)$
for all
$P(x,y) \ge Q(x,y)$
for all
 $x\not=y$
– i.e. that
$x\not=y$
– i.e. that
 $Q-P$
has all non-positive entries off the diagonal (and hence also that
$Q-P$
has all non-positive entries off the diagonal (and hence also that
 $Q-P$
has all non-negative entries on the diagonal). It is known through several complicated proofs [Reference Neal20, Reference Peskun22, Reference Tierney26] that if P Peskun-dominates Q, then P efficiency-dominates Q. We will see here that once Theorem 2 has been established, this fact can be shown easily.
$Q-P$
has all non-negative entries on the diagonal). It is known through several complicated proofs [Reference Neal20, Reference Peskun22, Reference Tierney26] that if P Peskun-dominates Q, then P efficiency-dominates Q. We will see here that once Theorem 2 has been established, this fact can be shown easily.
Proposition 6. If P and Q are irreducible, and both are reversible with respect to some
 $\pi$
, and P Peskun-dominates Q, then P efficiency-dominates Q.
$\pi$
, and P Peskun-dominates Q, then P efficiency-dominates Q.
To prove Proposition 6, we begin with a simple eigenvalue lemma.
Lemma 5. If Z is an
 $n \times n$
matrix with
$n \times n$
matrix with
 $z_{ii} \ge 0$
and
$z_{ii} \ge 0$
and
 $z_{ij} \le 0$
for all
$z_{ij} \le 0$
for all
 $i\not=j$
, and row-sums
$i\not=j$
, and row-sums
 $\sum_j z_{ij} = 0$
for all i, then all eigenvalues of Z must be non-negative.
$\sum_j z_{ij} = 0$
for all i, then all eigenvalues of Z must be non-negative.
Proof. Suppose
 $Zv=\lambda v$
. Find the index j which maximizes
$Zv=\lambda v$
. Find the index j which maximizes
 $|v_j|$
, i.e. such that
$|v_j|$
, i.e. such that
 $|v_j| \ge |v_k|$
for all k. We can assume
$|v_j| \ge |v_k|$
for all k. We can assume
 $v_j > 0$
(if not, replace v by
$v_j > 0$
(if not, replace v by
 $-v$
), so
$-v$
), so
 $v_j \ge |v_k|$
for all k. Then
$v_j \ge |v_k|$
for all k. Then
 \begin{align*} \lambda v_j = (Zv)_j = \sum_i z_{ji} v_i = z_{jj} v_j + \sum_{i \not= j} z_{ji} v_i & \ge z_{jj} v_j - \sum_{i \not= j} |z_{ji}| |v_i| \\ & \ge z_{jj} v_j - \sum_{i \not= j} |z_{ji}| v_j \\ & = v_j \Bigg( z_{jj} + \sum_{i \not= j} z_{ji} \Bigg) = v_j (0) = 0 . \end{align*}
\begin{align*} \lambda v_j = (Zv)_j = \sum_i z_{ji} v_i = z_{jj} v_j + \sum_{i \not= j} z_{ji} v_i & \ge z_{jj} v_j - \sum_{i \not= j} |z_{ji}| |v_i| \\ & \ge z_{jj} v_j - \sum_{i \not= j} |z_{ji}| v_j \\ & = v_j \Bigg( z_{jj} + \sum_{i \not= j} z_{ji} \Bigg) = v_j (0) = 0 . \end{align*}
So,
 $\lambda v_j \ge 0$
. Hence, since
$\lambda v_j \ge 0$
. Hence, since
 $v_j>0$
, we must have
$v_j>0$
, we must have
 $\lambda \ge 0$
.
$\lambda \ge 0$
.
Proof of Proposition 6. Let
 $Z=Q-P$
. Since P Peskun-dominates Q,
$Z=Q-P$
. Since P Peskun-dominates Q,
 $z_{ii} = Q(i,i) - P(i,i) \ge 0$
and
$z_{ii} = Q(i,i) - P(i,i) \ge 0$
and
 $z_{ij} = Q(i,j) - P(i,j) \le 0$
for all
$z_{ij} = Q(i,j) - P(i,j) \le 0$
for all
 $i\not=j$
. Also,
$i\not=j$
. Also,
 $\sum_j z_{ij} = \sum_j P(i,j) - \sum_j Q(i,j) = 1 - 1 = 0$
. Hence, by Lemma 5,
$\sum_j z_{ij} = \sum_j P(i,j) - \sum_j Q(i,j) = 1 - 1 = 0$
. Hence, by Lemma 5,
 $Z=Q-P$
has all eigenvalues non-negative. Hence, by Theorem 2, P efficiency-dominates Q.
$Z=Q-P$
has all eigenvalues non-negative. Hence, by Theorem 2, P efficiency-dominates Q.
Remark 10. Proposition 6 can also be proved by transforming Q into P one step at a time, in the sequence
 $Q,Q',Q'',\ldots,P$
, with each matrix in the sequence efficiency-dominating the previous matrix. At each step, say from Q
′ to Q
′′, two of the off-diagonal transition probabilities that differ between Q and P, say those involving states x and y, will be increased from Q(x, y) to P(x, y) and from Q(y, x) to P(y, x), while Q
′′(x, x) and Q
′′(y, y) will decrease compared to Q
′(x, x) and Q
′(y, y). The difference
$Q,Q',Q'',\ldots,P$
, with each matrix in the sequence efficiency-dominating the previous matrix. At each step, say from Q
′ to Q
′′, two of the off-diagonal transition probabilities that differ between Q and P, say those involving states x and y, will be increased from Q(x, y) to P(x, y) and from Q(y, x) to P(y, x), while Q
′′(x, x) and Q
′′(y, y) will decrease compared to Q
′(x, x) and Q
′(y, y). The difference
 $Q'-Q''$
will be zero except for a
$Q'-Q''$
will be zero except for a
 $2 \times 2$
submatrix involving states x and y, which will have the form
$2 \times 2$
submatrix involving states x and y, which will have the form
 \begin{align*}\begin{pmatrix} a &\quad -a \\ -b &\quad b \end{pmatrix}\end{align*}
\begin{align*}\begin{pmatrix} a &\quad -a \\ -b &\quad b \end{pmatrix}\end{align*}
for some
 $a,b>0$
, which has non-negative eigenvalues of 0 and
$a,b>0$
, which has non-negative eigenvalues of 0 and
 $a+b$
. Hence, by Theorem 2, Q′′ efficiency-dominates Q
′. Since this will be true for all the steps from Q to P, transitivity (see Theorem 3(iii)) implies that P efficiency-dominates Q.
$a+b$
. Hence, by Theorem 2, Q′′ efficiency-dominates Q
′. Since this will be true for all the steps from Q to P, transitivity (see Theorem 3(iii)) implies that P efficiency-dominates Q.
Note that the converse to Proposition 6 is false. For example, let
 $S=\{1,2,3\}$
, and
$S=\{1,2,3\}$
, and
 \begin{align*}P =\begin{pmatrix}\begin{array}{c@{\quad}c@{\quad}c} 0 & \frac12 & \frac12 \\[5pt] 1 & 0 & 0 \\[5pt] 1 & 0 & 0\end{array}\end{pmatrix}, \qquad Q =\begin{pmatrix} \begin{array}{c@{\quad}c@{\quad}c} \frac12 & \frac14 & \frac14 \\[5pt] \frac12 & \frac14 & \frac14 \\[5pt] \frac12 & \frac14 & \frac14\end{array}\end{pmatrix}, \qquad Q-P =\begin{pmatrix} \begin{array}{c@{\quad}c@{\quad}c} +\frac12 & -\frac14 & -\frac14 \\[5pt] -\frac12 & +\frac14 & +\frac14 \\[5pt] -\frac12 & +\frac14 & +\frac14\end{array}\end{pmatrix} .\end{align*}
\begin{align*}P =\begin{pmatrix}\begin{array}{c@{\quad}c@{\quad}c} 0 & \frac12 & \frac12 \\[5pt] 1 & 0 & 0 \\[5pt] 1 & 0 & 0\end{array}\end{pmatrix}, \qquad Q =\begin{pmatrix} \begin{array}{c@{\quad}c@{\quad}c} \frac12 & \frac14 & \frac14 \\[5pt] \frac12 & \frac14 & \frac14 \\[5pt] \frac12 & \frac14 & \frac14\end{array}\end{pmatrix}, \qquad Q-P =\begin{pmatrix} \begin{array}{c@{\quad}c@{\quad}c} +\frac12 & -\frac14 & -\frac14 \\[5pt] -\frac12 & +\frac14 & +\frac14 \\[5pt] -\frac12 & +\frac14 & +\frac14\end{array}\end{pmatrix} .\end{align*}
Here, P does not Peskun-dominate Q, since, for example,
 $Q(2,3)=\frac14 > 0 = P(2,3)$
. However, the eigenvalues of
$Q(2,3)=\frac14 > 0 = P(2,3)$
. However, the eigenvalues of
 $Q-P$
are 1,0,0, all of which are non-negative, so P does efficiency-dominate Q. Furthermore, Theorem 3(ii) implies that P is strictly better than Q – there is some f for which
$Q-P$
are 1,0,0, all of which are non-negative, so P does efficiency-dominate Q. Furthermore, Theorem 3(ii) implies that P is strictly better than Q – there is some f for which
 $v(f,P)<v(f,Q)$
. (For example, the indicator function for the first state, which has asymptotic variance zero using P, and asymptotic variance
$v(f,P)<v(f,Q)$
. (For example, the indicator function for the first state, which has asymptotic variance zero using P, and asymptotic variance
 $\frac14$
using Q.) Peskun dominance therefore does not capture all instances of efficiency dominance that we are interested in, which motivates our investigation here.
$\frac14$
using Q.) Peskun dominance therefore does not capture all instances of efficiency dominance that we are interested in, which motivates our investigation here.
We should note, however, that all our results concern only reversible chains. Non-reversible chains are often used, either in a deliberate attempt to improve performance (see [Reference Neal20]), or somewhat accidentally, as a result of combining methods sequentially rather than by random selection. Extensions of Peskun ordering to non-reversible chains are considered in [Reference Andrieu and Livingstone1].
8. Elementary proof of Lemma 2
We conclude by presenting the promised elementary proof of Lemma 2, which states the surprising fact that, for any reversible irreducible transition matrices P and Q,
 $\langle\, {f}, {Pf} \rangle \le \langle\, {f}, {Qf} \rangle$
for all f if and only if
$\langle\, {f}, {Pf} \rangle \le \langle\, {f}, {Qf} \rangle$
for all f if and only if
 $\langle\, {f} {P(I-P)^{-1}f}\rangle \le \langle\, {f}, {Q(I-Q)^{-1}f}\rangle$
for all f.
$\langle\, {f} {P(I-P)^{-1}f}\rangle \le \langle\, {f}, {Q(I-Q)^{-1}f}\rangle$
for all f.
As observed in [Reference Mira and Geyer19, pp. 16–17], this proposition follows from the more general result of [Reference Bendat and Sherman3, p. 60], using results in [Reference Löwner17], which states that that if
 $h(x) = (ax+b)/(cx+d)$
where
$h(x) = (ax+b)/(cx+d)$
where
 $ad-bc>0$
, and J and K are any two self-adjoint operators with spectrum contained in
$ad-bc>0$
, and J and K are any two self-adjoint operators with spectrum contained in
 $({-}\infty,-d/c)$
or in
$({-}\infty,-d/c)$
or in
 $({-}d/c,\infty)$
, then if
$({-}d/c,\infty)$
, then if
 $\langle\, {f},{Jf}\rangle \le \langle\, {f},{Kf}\rangle$
for all f, then also
$\langle\, {f},{Jf}\rangle \le \langle\, {f},{Kf}\rangle$
for all f, then also
 $\langle\, {f},{h(J)f}\rangle \le \langle\, {f}, {h(K)f}\rangle$
for all f. In particular, choosing
$\langle\, {f},{h(J)f}\rangle \le \langle\, {f}, {h(K)f}\rangle$
for all f. In particular, choosing
 $a=d=1$
,
$a=d=1$
,
 $b=0$
, and
$b=0$
, and
 $c=-1$
gives
$c=-1$
gives
 $h(J) = J / (I-J)$
, so if
$h(J) = J / (I-J)$
, so if
 $\langle\, {f},{Jf}\rangle \le \langle\, {f},{Kf}\rangle$
for all f then
$\langle\, {f},{Jf}\rangle \le \langle\, {f},{Kf}\rangle$
for all f then
 $\langle\, {f},{J / (I-J) f}\rangle \le \langle\, {f},{K / (I-K)\rangle f}$
for all f. Conversely, choosing
$\langle\, {f},{J / (I-J) f}\rangle \le \langle\, {f},{K / (I-K)\rangle f}$
for all f. Conversely, choosing
 $a=c=d=1$
and
$a=c=d=1$
and
 $b=0$
gives
$b=0$
gives
 $h(J / (I-J)) = J$
, so if
$h(J / (I-J)) = J$
, so if
 $\langle\, {f},{J / (I-J) f}\rangle \le \langle\, {f},{K / (I-K)\rangle f}$
for all f then
$\langle\, {f},{J / (I-J) f}\rangle \le \langle\, {f},{K / (I-K)\rangle f}$
for all f then
 $\langle\, {f},{Jf}\rangle \le \langle\, {f},{Kf}\rangle$
for all f, finishing the proof.
$\langle\, {f},{Jf}\rangle \le \langle\, {f},{Kf}\rangle$
for all f, finishing the proof.
However, the proof in [Reference Bendat and Sherman3] is very technical, requiring analytic continuations of transition functions into the complex plane. Instead, we now present an elementary proof of Lemma 2. (See also [Reference Bhatia4, Chapter V].) We begin with some lemmas about operators on a finite vector space
 $\mathcal{V}$
, e.g.
$\mathcal{V}$
, e.g.
 $\mathcal{V}=L^2_0(\pi)$
.
$\mathcal{V}=L^2_0(\pi)$
.
Lemma 6. If X,Y,Z are operators on a finite vector space
 $\mathcal{V}$
, with Z self-adjoint, and
$\mathcal{V}$
, with Z self-adjoint, and
 $\langle\, {f},{Xf}\rangle \le \langle\, {f},{Yf}\rangle$
for all
$\langle\, {f},{Xf}\rangle \le \langle\, {f},{Yf}\rangle$
for all
 $f\in\mathcal{V}$
, then
$f\in\mathcal{V}$
, then
 $\langle\, {f},{ZXZf}\rangle \le \langle\, {f},{ZYZf}\rangle$
for all
$\langle\, {f},{ZXZf}\rangle \le \langle\, {f},{ZYZf}\rangle$
for all
 $f\in\mathcal{V}$
.
$f\in\mathcal{V}$
.
Proof. Since Z is self-adjoint, making the substitution
 $g=Zf$
gives
$g=Zf$
gives
 $\langle\, {f},{ZXZf}\rangle = \langle {Zf},{XZf}\rangle = \langle {g},{Xg}\rangle \le \langle {g},{Yg}\rangle = \langle {Zf},{YZf}\rangle = \langle\, {f},{ZYZf}\rangle$
.
$\langle\, {f},{ZXZf}\rangle = \langle {Zf},{XZf}\rangle = \langle {g},{Xg}\rangle \le \langle {g},{Yg}\rangle = \langle {Zf},{YZf}\rangle = \langle\, {f},{ZYZf}\rangle$
.
Next, say a self-adjoint matrix J is strictly positive if
 $\langle\, {f},{Jf}\rangle > 0$
for all non-zero
$\langle\, {f},{Jf}\rangle > 0$
for all non-zero
 $f\in\mathcal{V}$
. Since
$f\in\mathcal{V}$
. Since
 $\langle\, {f},{Jf}\rangle = \sum_i (a_i)^2 \lambda_i$
(see Section 2), this is equivalent to J having all eigenvalues positive.
$\langle\, {f},{Jf}\rangle = \sum_i (a_i)^2 \lambda_i$
(see Section 2), this is equivalent to J having all eigenvalues positive.
Lemma 7. If J and K are strictly positive self-adjoint operators on a finite vector space
 $\mathcal{V}$
, and
$\mathcal{V}$
, and
 $\langle\, {f},{Jf}\rangle \le \langle\, {f},{Kf}\rangle$
for all
$\langle\, {f},{Jf}\rangle \le \langle\, {f},{Kf}\rangle$
for all
 $f\in\mathcal{V}$
, then
$f\in\mathcal{V}$
, then
 $\langle\, {f},{J^{-1}f}\rangle \ge \langle\, {f},{K^{-1}f}\rangle$
for all
$\langle\, {f},{J^{-1}f}\rangle \ge \langle\, {f},{K^{-1}f}\rangle$
for all
 $f\in\mathcal{V}$
.
$f\in\mathcal{V}$
.
Proof. Note (see Section 2) that
 $K^{-1/2}$
and
$K^{-1/2}$
and
 $K^{-1/2}JK^{-1/2}$
are self-adjoint, and have eigenvalues that are positive, since J and K are strictly positive. Applying Lemma 6 with
$K^{-1/2}JK^{-1/2}$
are self-adjoint, and have eigenvalues that are positive, since J and K are strictly positive. Applying Lemma 6 with
 $X=J$
,
$X=J$
,
 $Y=K$
, and
$Y=K$
, and
 $Z=K^{-1/2}$
then gives, for all
$Z=K^{-1/2}$
then gives, for all
 $f\in\mathcal{V}$
,
$f\in\mathcal{V}$
,
 \begin{align*} \langle\, {f},{K^{-1/2}JK^{-1/2}f}\rangle \le \langle\, {f},{K^{-1/2}KK^{-1/2}f}\rangle = \langle\, {f},{If}\rangle = \langle\, {f}, {f} \rangle . \end{align*}
\begin{align*} \langle\, {f},{K^{-1/2}JK^{-1/2}f}\rangle \le \langle\, {f},{K^{-1/2}KK^{-1/2}f}\rangle = \langle\, {f},{If}\rangle = \langle\, {f}, {f} \rangle . \end{align*}
It follows that all the eigenvalues of
 $K^{-1/2}JK^{-1/2}$
are in (0,1] (since
$K^{-1/2}JK^{-1/2}$
are in (0,1] (since
 $\langle {v},{Av}\rangle\le \langle {v},{v}\rangle$
and
$\langle {v},{Av}\rangle\le \langle {v},{v}\rangle$
and
 $Av=\lambda v$
with
$Av=\lambda v$
with
 $v\ne0$
imply
$v\ne0$
imply
 $\lambda\le 1$
). Hence, its inverse
$\lambda\le 1$
). Hence, its inverse
 $( K^{-1/2}JK^{-1/2})^{-1}$
has eigenvalues all
$( K^{-1/2}JK^{-1/2})^{-1}$
has eigenvalues all
 $\ge 1$
, so
$\ge 1$
, so
 $\langle\, {f},{( K^{-1/2}JK^{-1/2})^{-1}f} \rangle \ge \langle\, {f},{If}\rangle$
, and therefore
$\langle\, {f},{( K^{-1/2}JK^{-1/2})^{-1}f} \rangle \ge \langle\, {f},{If}\rangle$
, and therefore
 \begin{align*} \langle\, {f},{If}\rangle \le \langle\, {f},{( K^{-1/2}JK^{-1/2})^{-1}f}\rangle = \langle\, {f},{K^{1/2}J^{-1}K^{1/2}f}\rangle . \end{align*}
\begin{align*} \langle\, {f},{If}\rangle \le \langle\, {f},{( K^{-1/2}JK^{-1/2})^{-1}f}\rangle = \langle\, {f},{K^{1/2}J^{-1}K^{1/2}f}\rangle . \end{align*}
Then, applying Lemma 6 again with
 $X=I$
,
$X=I$
,
 $Y=K^{1/2}J^{-1}K^{1/2}$
, and
$Y=K^{1/2}J^{-1}K^{1/2}$
, and
 $Z=K^{-1/2}$
gives
$Z=K^{-1/2}$
gives
 \begin{align*} \langle\, {f},{K^{-1/2}IK^{-1/2}f}\rangle \le \langle\, {f},{K^{-1/2}(K^{1/2}J^{-1}K^{1/2})K^{-1/2}f}\rangle . \end{align*}
\begin{align*} \langle\, {f},{K^{-1/2}IK^{-1/2}f}\rangle \le \langle\, {f},{K^{-1/2}(K^{1/2}J^{-1}K^{1/2})K^{-1/2}f}\rangle . \end{align*}
That is,
 $\langle\, {f},{K^{-1}f}\rangle \le \langle\, {f},{J^{-1}f}\rangle$
for all
$\langle\, {f},{K^{-1}f}\rangle \le \langle\, {f},{J^{-1}f}\rangle$
for all
 $f\in\mathcal{V}$
, giving the result.
$f\in\mathcal{V}$
, giving the result.
We emphasise that the equivalence in Lemma 7 is only for all f at once, not for individual f. For example, if
 $J=I$
,
$J=I$
,
 $K=\mathrm{diag}(5,{\frac{1}{4}})$
, and
$K=\mathrm{diag}(5,{\frac{1}{4}})$
, and
 $f=(1,1)$
, then
$f=(1,1)$
, then
 $\langle\, {f},{Jf}\rangle = 2 \le 5 + {\frac{1}{4}} = \langle\, {f},{Kf}\rangle$
, but
$\langle\, {f},{Jf}\rangle = 2 \le 5 + {\frac{1}{4}} = \langle\, {f},{Kf}\rangle$
, but
 $\langle\, {f},{J^{-1}f}\rangle = 2 \not\ge {\frac{1}{5}} + 4 = \langle\, {f},{K^{-1}f}\rangle$
. This illustrates why the proofs of Lemmas 7 and 2 are not as straightforward as might be thought.
$\langle\, {f},{J^{-1}f}\rangle = 2 \not\ge {\frac{1}{5}} + 4 = \langle\, {f},{K^{-1}f}\rangle$
. This illustrates why the proofs of Lemmas 7 and 2 are not as straightforward as might be thought.
Remark 11. Lemma 7 can be partially proven more directly. If
 $f=\sum_i a_i v_i$
, Jensen’s inequality gives
$f=\sum_i a_i v_i$
, Jensen’s inequality gives
 $\big(\sum_i(a_i)^2\lambda_i\big)^{-1} \le \sum_i(a_i)^2(\lambda_i)^{-1}$
, so we always have
$\big(\sum_i(a_i)^2\lambda_i\big)^{-1} \le \sum_i(a_i)^2(\lambda_i)^{-1}$
, so we always have
 $1 / \langle\, {f},{Jf}\rangle \le \langle\, {f},{J^{-1}f}\rangle$
. Hence, if
$1 / \langle\, {f},{Jf}\rangle \le \langle\, {f},{J^{-1}f}\rangle$
. Hence, if
 $\langle\, {f},{Jf}\rangle \le \langle\, {f},{Kf}\rangle$
, then
$\langle\, {f},{Jf}\rangle \le \langle\, {f},{Kf}\rangle$
, then
 $\langle\, {f},{J^{-1}f}\rangle \ge 1 / \langle\, {f},{Kf}\rangle$
. If f is an eigenvector of K, then
$\langle\, {f},{J^{-1}f}\rangle \ge 1 / \langle\, {f},{Kf}\rangle$
. If f is an eigenvector of K, then
 $\langle\, {f},{K^{-1}f}\rangle = 1 / \langle\, {f},{Kf}\rangle$
, so this shows directly that
$\langle\, {f},{K^{-1}f}\rangle = 1 / \langle\, {f},{Kf}\rangle$
, so this shows directly that
 $\langle\, {f},{J^{-1}f}\rangle \ge \langle\, {f},{K^{-1}f}\rangle$
. However, it is unclear how to extend this argument to other f.
$\langle\, {f},{J^{-1}f}\rangle \ge \langle\, {f},{K^{-1}f}\rangle$
. However, it is unclear how to extend this argument to other f.
Applying Lemma 7 twice gives a (stronger) two-way equivalence.
Lemma 8. If J and K are strictly positive self-adjoint operators on a finite vector space
 $\mathcal{V}$
, then
$\mathcal{V}$
, then
 $\langle\, {f},{Jf}\rangle \le \langle\, {f},{Kf}\rangle$
for all
$\langle\, {f},{Jf}\rangle \le \langle\, {f},{Kf}\rangle$
for all
 $f\in\mathcal{V}$
if and only if
$f\in\mathcal{V}$
if and only if
 $\langle\, {f},{J^{-1}f}\rangle \ge \langle\, {f},{K^{-1}f}\rangle$
for all
$\langle\, {f},{J^{-1}f}\rangle \ge \langle\, {f},{K^{-1}f}\rangle$
for all
 $f\in\mathcal{V}$
.
$f\in\mathcal{V}$
.
Proof. The forward implication is Lemma 7, and the reverse implication follows from Lemma 7 by replacing J with
 $K^{-1}$
and replacing K with
$K^{-1}$
and replacing K with
 $J^{-1}$
.
$J^{-1}$
.
Using Lemma 8, we easily obtain the following proof.
Proof of Lemma 2. Recall that we can restrict to
 $f\in L^2_0(\pi)$
, so
$f\in L^2_0(\pi)$
, so
 $\pi(f)=0$
, and f is orthogonal to the eigenvector corresponding to eigenvalue 1. On that restricted subspace, the eigenvalues of P and Q are contained in
$\pi(f)=0$
, and f is orthogonal to the eigenvector corresponding to eigenvalue 1. On that restricted subspace, the eigenvalues of P and Q are contained in
 $[{-}1,1)$
. Hence, the eigenvalues of
$[{-}1,1)$
. Hence, the eigenvalues of
 $I-P$
and
$I-P$
and
 $I-Q$
are contained in (0,2], and in particular are all strictly positive. So,
$I-Q$
are contained in (0,2], and in particular are all strictly positive. So,
 $I-P$
and
$I-P$
and
 $I-Q$
are strictly positive self-adjoint operators.
$I-Q$
are strictly positive self-adjoint operators.
Now,
 $\langle\, {f}, {Pf} \rangle \le \langle\, {f}, {Qf} \rangle$
for all
$\langle\, {f}, {Pf} \rangle \le \langle\, {f}, {Qf} \rangle$
for all
 $f \in L^2_0(\pi)$
is equivalent to
$f \in L^2_0(\pi)$
is equivalent to
 \begin{align*} \langle\, {f}, {(I-P)f} \rangle = \langle\, {f}, {f} \rangle-\langle\, {f}, {Pf} \rangle \ge \langle\, {f}, {f} \rangle - \langle\, {f}, {Qf} \rangle = \langle\, {f}, {(I-Q)f} \rangle \end{align*}
\begin{align*} \langle\, {f}, {(I-P)f} \rangle = \langle\, {f}, {f} \rangle-\langle\, {f}, {Pf} \rangle \ge \langle\, {f}, {f} \rangle - \langle\, {f}, {Qf} \rangle = \langle\, {f}, {(I-Q)f} \rangle \end{align*}
for all
 $f \in L^2_0(\pi)$
. Then, by Lemma 8 with
$f \in L^2_0(\pi)$
. Then, by Lemma 8 with
 $J = I-Q$
and
$J = I-Q$
and
 $K = I-P$
, this is equivalent to
$K = I-P$
, this is equivalent to
 $\langle\, {f},{(I-P)^{-1}f}\rangle \le \langle\,{f},{(I-Q)^{-1}f}\rangle$
for all
$\langle\, {f},{(I-P)^{-1}f}\rangle \le \langle\,{f},{(I-Q)^{-1}f}\rangle$
for all
 $f \in L^2_0(\pi)$
. Since
$f \in L^2_0(\pi)$
. Since
 $(I-P)^{-1} = P(I-P)^{-1} + (I-P)(I-P)^{-1} = P(I-P)^{-1} + I$
and similarly
$(I-P)^{-1} = P(I-P)^{-1} + (I-P)(I-P)^{-1} = P(I-P)^{-1} + I$
and similarly
 $(I-Q)^{-1} = Q(I-Q)^{-1} + I$
, this latter is equivalent to
$(I-Q)^{-1} = Q(I-Q)^{-1} + I$
, this latter is equivalent to
 $\langle\, {f} {P(I-P)^{-1}f}\rangle \le \langle\, {f}, {Q(I-Q)^{-1}f}\rangle$
for all
$\langle\, {f} {P(I-P)^{-1}f}\rangle \le \langle\, {f}, {Q(I-Q)^{-1}f}\rangle$
for all
 $f \in L^2_0(\pi)$
, which completes the proof.
$f \in L^2_0(\pi)$
, which completes the proof.
Acknowledgements
We are very grateful to Heydar Radjavi for the proof of Lemma 7 herein, and thank Rajendra Bhatia, Gareth Roberts, Daniel Rosenthal, and Peter Rosenthal for several very helpful discussions about eigenvalues. We thank the anonymous referee for a number of useful suggestions which helped to improve the paper.
Funding information
This work was partially supported by NSERC of Canada.
Competing interests
There were no competing interests to declare which arose during the preparation or publication process of this article.
