


I. INTRODUCTION
Human speech is the most basic and widely used form of daily communication. Speech conveys not only linguistic information but also other factors such as speaker and emotion, all of which are essential for human interaction. Thus, speech emotion recognition (SER) is an important technology for natural human–computer interaction. There are a lot of SER applications such as voice-of-customer analysis in contact center calls [Reference Devillers, Vaudable and Chastagnol1, Reference Ando, Masumura, Kamiyama, Kobashikawa, Aono and Toda2], driver state monitoring [Reference Tawari and Trivedi3], and human-like responses in spoken dialog systems [Reference Acosta4].
SER can be categorized into two tasks: dimensional and categorical emotion recognition. Dimensional emotion recognition is the task of estimating the values of several emotion attributes present in speech [Reference Kowtha5]. Three primitive emotion attributes, i.e. valence, arousal, and dominance are commonly used [Reference Parthasarathy and Busso6]. Categorical emotion recognition is the task of identifying the speaker's emotion from among a discrete set of emotion categories [Reference Sarma, Ghahremani, Povey, Goel, Sarma and Dehak7]. The ground truth is defined as the majority of perceived emotion class as determined by multiple listeners. Comparing these two tasks, categorical emotion recognition is more suitable for most applications because it is easy to interpret. This paper aims to improve categorical emotion recognition accuracy.
A large number of SER methods have been proposed. One of the basic approaches is based on utterance-level heuristic features including the statistics of frame-level acoustic features such as fundamental frequency, power, and Mel-frequency cepstral coefficients (MFCC) as determined by a simple classifier [Reference Schuller, Batliner, Steidl and Seppi8, Reference Luengo, Navas, Hernàez and Sànchez9]. Although they can recognize several typical emotions, their performance is still far from satisfactory because emotional cues exhibit great diversity, which demands the use of hand-crafted features with simple criteria. In contrast to this approach, several recent studies have achieved remarkable improvements through the use of deep neural network (DNN)-based classifiers [Reference Han, Yu and Tashev10–Reference Neumann and Vu19]. The main advantage of DNN-based classifiers is that they can learn complex cues of emotions automatically by combining several kinds of layers. Recurrent neural network (RNN)-layers have been used to capture the contextual characteristics of utterances [Reference Mirsamadi, Barsoum and Zhang12, Reference Huang and Narayanan13]. Attention mechanism has also been employed to focus on the local characteristics of utterances [Reference Huang and Narayanan13, Reference Li, Song, McLoughlin, Guo and Dai14]. Furthermore, DNN-based models can utilize low-level features, e.g. log power-spectrogram or raw waveform, which have rich but excessively complex information that simple classifiers are unable to handle [Reference Sarma, Ghahremani, Povey, Goel, Sarma and Dehak7, Reference Tzirakis, Zhang and Schuller15].
However, SER is still a challenging task despite these advances. One of the difficulties lies in handling two types of individuality: speaker and listener dependencies. The way in which emotions are presented strongly depends on the speaker. It is reported that prosodic characteristics such as pitch and laryngealization differ among speakers [Reference Batliner and Huber20]. This is similar in emotion perceptions, and depends on age [Reference Ben-David, Gal-Rosenblum, van Lieshout and Shakuf21], gender [Reference Zhao, Ando, Takaki, Yamagishi and Kobashikawa22], and cultures [Reference Dang23] of listeners. Given these issues, speaker dependency has often been considered for SER [Reference Sethu, Epps and Ambikairajah24, Reference Kim, Park and Oh25]. However, the dependency of listeners has received little attention in SER tasks even though it influences the determination of the majority-voted emotions.
This paper presents a new SER framework based on listener-dependent (LD) models. The proposed framework aims to consider the individuality of emotional perceptions. In the training step of the proposed method, LD models are constructed so as to learn criteria for capturing the emotion recognition attributes of individual listeners. This allows the LD models to estimate the posterior probabilities of perceived emotions of specific listeners. Majority-voted emotions can be estimated by averaging these posterior probabilities as given by LD models. Inspired by domain adaptation frameworks in speech processing, three LD models are introduced: fine-tuning, auxiliary input, and sub-layer weighting. The fine-tuning method constructs as many LD models as listeners, while the remaining models cover all listeners by a single model. We also propose adaptation frameworks that allow the LD models to handle unseen listeners in the training data. Experiments on two emotional speech corpora show the individuality of listener perception and the effectiveness of the proposed approach. The main contributions of this paper are as follows:
(1) A scheme to recognize majority-voted emotions by leveraging the individuality of emotion perception is presented. To the best of our knowledge, this is the first work to take listener characteristics into consideration for SER.
(2) The performance of listener-oriented emotion perception is evaluated in addition to that of majority-voted emotion recognition. The proposed LD models show better performance than the conventional method in both metrics, which indicates that the proposed scheme is suitable for estimating not only majority-voted emotions, but also personalized emotion perception.
This paper is organized as follows. Section II introduces studies related to this work. Conventional emotion recognition is shown in Section III. The proposed framework based on LD models is shown in Section IV. Evaluation experiments are reported in Section V and the conclusion is given in Section VI.
II. RELATED WORK
A large number of emotion recognition methods have been investigated. The traditional approaches are based on utterance-level heuristic features. The statistics of frame-level acoustic features such as pitch, power, and MFCC are often used [Reference Schuller, Batliner, Steidl and Seppi8, Reference Luengo, Navas, Hernàez and Sànchez9]. However, it is difficult to create truly effective features because emotional cues exhibit great diversity. Thus, recent studies employ DNNs to learn emotion-related features automatically. The initial studies integrate frame-level emotion classifiers based on DNNs [Reference Han, Yu and Tashev10, Reference Lee and Tashev11]. Speaker emotion of individual frames are estimated by the classifiers, then integrated to evaluate utterance-level decisions by other DNN-based models such as extreme learning machines or RNNs. In recent years, end-to-end mechanisms that directly estimate utterance-level emotion from input feature sequences have been developed to allow the use of local and contextual characteristic [Reference Mirsamadi, Barsoum and Zhang12, Reference Huang and Narayanan13]. The end-to-end model consists of multiple DNN layers such as convolutional neural networks (CNNs), long short-term memory-RNNs, attention mechanisms, and fully-connected (FC) layers [Reference Sarma, Ghahremani, Povey, Goel, Sarma and Dehak7, Reference Li, Song, McLoughlin, Guo and Dai14, Reference Tzirakis, Zhang and Schuller15]. Recent works also utilize low-level inputs such as raw waveform and log power spectra in order to leverage the rich information of low-level features for estimation [Reference Satt, Rozenberg and Hoory16–Reference Neumann and Vu19]. One of the advantages of the DNN-based framework is that the model can automatically learn complex emotional cues from training data. Our proposals employ this framework to construct LD models.
Several studies have investigated speaker dependency on emotional expression. They indicate that the speaker differences significantly affect emotion representation. For example, each speaker exhibits different laryngealization and pitch characteristics [Reference Batliner and Huber20]. It has been suggested that speaker variability is a more serious factor than linguistic content [Reference Sethu, Ambikairajah and Epps26]. Therefore, a lot of speaker adaptation methods for SER have been developed. Some attempt feature-level normalization; a speaker-dependent utterance feature is transformed into its speaker-independent equivalent [Reference Sethu, Epps and Ambikairajah24]. Another approach is model-level adaptation. A speaker-independent emotion recognition model can, with a small amount of adaptation data, be adjusted to yield a speaker-dependent model [Reference Kim, Park and Oh25]. Recent studies employ multi-task learning to construct gender-dependent models without inputting speaker attributes [Reference Li, Zhao and Kawahara18, Reference Nediyanchath, Paramasivam and Yenigalla27]. Personal profiles have also been utilized to estimate speaker-dependent emotion recognition [Reference Li and Lee28]. In this paper, we do not employ speaker adaptation in order to investigate the influence of just listener dependency; it will be possible, however, to combine the proposed LD model with existing speaker adaptation methods.
It has also been reported that emotion perception varies with the listener. Younger listeners tend to perceive emotions more precisely than their elders [Reference Ben-David, Gal-Rosenblum, van Lieshout and Shakuf21]. It is reported that female listeners are more sensitive to emotion than males [Reference Zhao, Ando, Takaki, Yamagishi and Kobashikawa22]. The perception also depends on culture [Reference Dang23]. Even though listener variability affects the majority decision as to emotion perception, there is little work that considers the listener in SER. One related work is soft-label / multi-label emotion recognition; it models the distribution of emotion perception of listeners [Reference Ando, Masumura, Kamiyama, Kobashikawa and Aono17, Reference Ando, Kobashikawa, Kamiyama, Masumura, Ijima and Aono29, Reference Fayek, Lech and Cavedon30], but it cannot distinguish individuals. In music emotion recognition, several studies have tackled listener-wise perception [Reference Chen, Wang, Yang and Chen31, Reference Wang, Yang, Wang and Jeng32]. However, to the best of our knowledge, this is the first work to utilize listener variability for SER.
It is considered that constructing listener-oriented emotion recognition models is strongly related to the frameworks created for domain or speaker adaptation. As mentioned with regard to speaker adaptation in emotion recognition, adaptation has two approaches: feature-based and model-based adaptation. In recent speech processing methods such as those for speech recognition and speech synthesis, model-based adaptation is dominant because it is very powerful in handling complex changes in domains or listeners. One of the common adaptation approaches is updating the parameters of a pre-trained model by using a target domain dataset [Reference Yu, Yao, Su, Li and Seide33]. Another approach is developing a recognition model that includes the domain-dependent part. Technologies along these lines such as switching domain-dependent layers [Reference Ochiai, Matsuda, Lu, Hori and Katagiri34], projections with auxiliary input [Reference Garimella, Mandal, Strom, Hoffmeister, Matsoukas and Parthasarathi35, Reference Hojo, Ijima and Mizuno36], or summation of multiple projection outputs with speaker-dependent weights [Reference Delcroix, Zmolikova, Kinoshita, Ogawa and Nakatani37] have been proposed. Inspired by these successful frameworks, our proposal yields LD emotion recognition models.
III. EMOTION RECOGNITION BY MAJORITY-VOTED MODEL
This section describes the conventional emotion recognition approach based on DNN model [Reference Li, Song, McLoughlin, Guo and Dai14, Reference Li, Zhao and Kawahara18]. In this paper, we call this model the majority-voted model because it directly models majority-voted emotion of multiple listener perceptions.
Let $\boldsymbol {X} = [ \boldsymbol {x}_{1}, \dots , \boldsymbol {x}_{T} ]$ be the acoustic features of an input utterance and $T$
be the acoustic features of an input utterance and $T$ be their total length. $C = \{1, \cdots , K\}$
be their total length. $C = \{1, \cdots , K\}$ is the set of target emotion indices, e.g. $1$
is the set of target emotion indices, e.g. $1$ means neutral and $2$
means neutral and $2$ is happy. $K$
is happy. $K$ is the total number of target emotions. The task of SER is formulated as estimating the majority-voted emotion of utterance $c \in C$
is the total number of target emotions. The task of SER is formulated as estimating the majority-voted emotion of utterance $c \in C$ from $\boldsymbol {X}$
from $\boldsymbol {X}$ ,
,

where $\hat {c}$ is the estimated majority-voted emotion. $P(c | \boldsymbol {X})$
is the estimated majority-voted emotion. $P(c | \boldsymbol {X})$ is the posterior probability indicated by the input utterance. The ground truth of majority-voted emotion $c$
is the posterior probability indicated by the input utterance. The ground truth of majority-voted emotion $c$ is defined as the dominant choice of multiple listener's perception results,
is defined as the dominant choice of multiple listener's perception results,

where $c^{(l)} \in C$ is the perceived emotion of human listener $l$
is the perceived emotion of human listener $l$ Footnote 1. $f(\cdot )$
Footnote 1. $f(\cdot )$ is a binary function of emotion presence / absence, $f(c^{(l)}=k)=1$
is a binary function of emotion presence / absence, $f(c^{(l)}=k)=1$ if $l$
if $l$ perceived the $k$
perceived the $k$ -th target emotion from the utterance, otherwise $0$
-th target emotion from the utterance, otherwise $0$ . $L$
. $L$ is a set of the listeners annotated emotion perceptions given the input utterance, where $L \subset \mathbb {L}$
is a set of the listeners annotated emotion perceptions given the input utterance, where $L \subset \mathbb {L}$ and $\mathbb {L}$
and $\mathbb {L}$ is a set of listeners in the training data. Note that the set of the listeners, $L$
is a set of listeners in the training data. Note that the set of the listeners, $L$ , can vary for each utterance in SER task.
, can vary for each utterance in SER task.
The posterior probabilities of the majority-voted emotions $\boldsymbol {y} = [P(c=1 | \boldsymbol {X}), \cdots , P(c=K | \boldsymbol {X})]^{\top }$ are evaluated by the estimation model composed of an encoder and decoder. An example of the estimation model is shown in Fig. 1. The encoder projects an arbitrary length of acoustic features $\boldsymbol {X}$
are evaluated by the estimation model composed of an encoder and decoder. An example of the estimation model is shown in Fig. 1. The encoder projects an arbitrary length of acoustic features $\boldsymbol {X}$ into a fixed-length hidden representation in order to extract context-sensitive emotional cues. It consists of CNN, Bidirectional LSTM-RNNs (BLSTM), and self-attention layers such as a structured self-attention network [Reference Lin, Feng, dos Santos, Yu, Xiang, Zhou and Bengio38]. The decoder estimates $\boldsymbol {y}$
into a fixed-length hidden representation in order to extract context-sensitive emotional cues. It consists of CNN, Bidirectional LSTM-RNNs (BLSTM), and self-attention layers such as a structured self-attention network [Reference Lin, Feng, dos Santos, Yu, Xiang, Zhou and Bengio38]. The decoder estimates $\boldsymbol {y}$ from the hidden representation. It is composed of several FC layers.
from the hidden representation. It is composed of several FC layers.
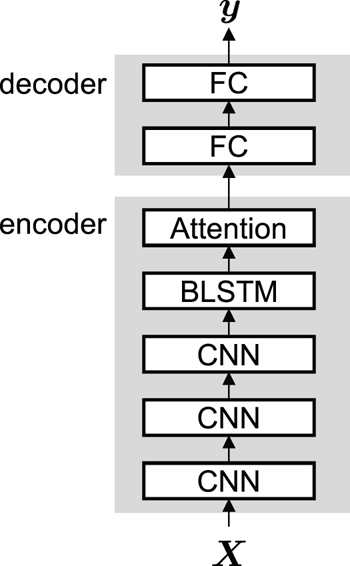
Fig. 1. An example of the conventional emotion recogntion model based on direct modeling of majority-voted emotion.
The parameters of the estimation model are optimized by stochastic gradient descent with cross entropy loss,
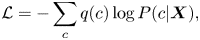
where $q(\cdot )$ is the reference distribution. $q(c=k)$
is the reference distribution. $q(c=k)$ is $1$
is $1$ if the majority-voted emotion is the $k$
if the majority-voted emotion is the $k$ -th target emotion, otherwise $0$
-th target emotion, otherwise $0$ .
.
IV. EMOTION RECOGNITION BY LD MODELS
This section proposes a majority-voted emotion recognition framework based on LD models. The key idea of our proposal is to consider the individuality of emotion perception. Every majority-voted emotion is determined from different sets of listeners in the SER task. However, the characteristics of emotional perceptions vary with the listener. Direct modeling of the majority-voted emotion will result in conflating multiple different emotion perception criteria, which may degrade estimation performance. To solve this problem, the proposed method constructs LD models to learn listener-specific emotion perception criteria.
This framework determines the posterior probability of majority-voted emotion by averaging the posterior probabilities of the LD perceived emotions,
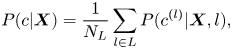
where $N_L$ is the total number of listeners $L$
is the total number of listeners $L$ . In vector representation,
. In vector representation,
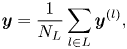
where $\boldsymbol {y}^{(l)}=[P(c^{(l)}=1|\boldsymbol {X}, l), \cdots , P(c^{(l)}=K|\boldsymbol {X}, l)]^{\top }$ is the LD posterior probability vector evaluated by the LD model.
is the LD posterior probability vector evaluated by the LD model.
In this paper, three LD models are introduced: fine-tuning, auxiliary input, and sub-layer weighting. All of them are inspired by adaptation techniques in speech processing. The proposed frameworks based on LD models are overviewed in Fig. 2.
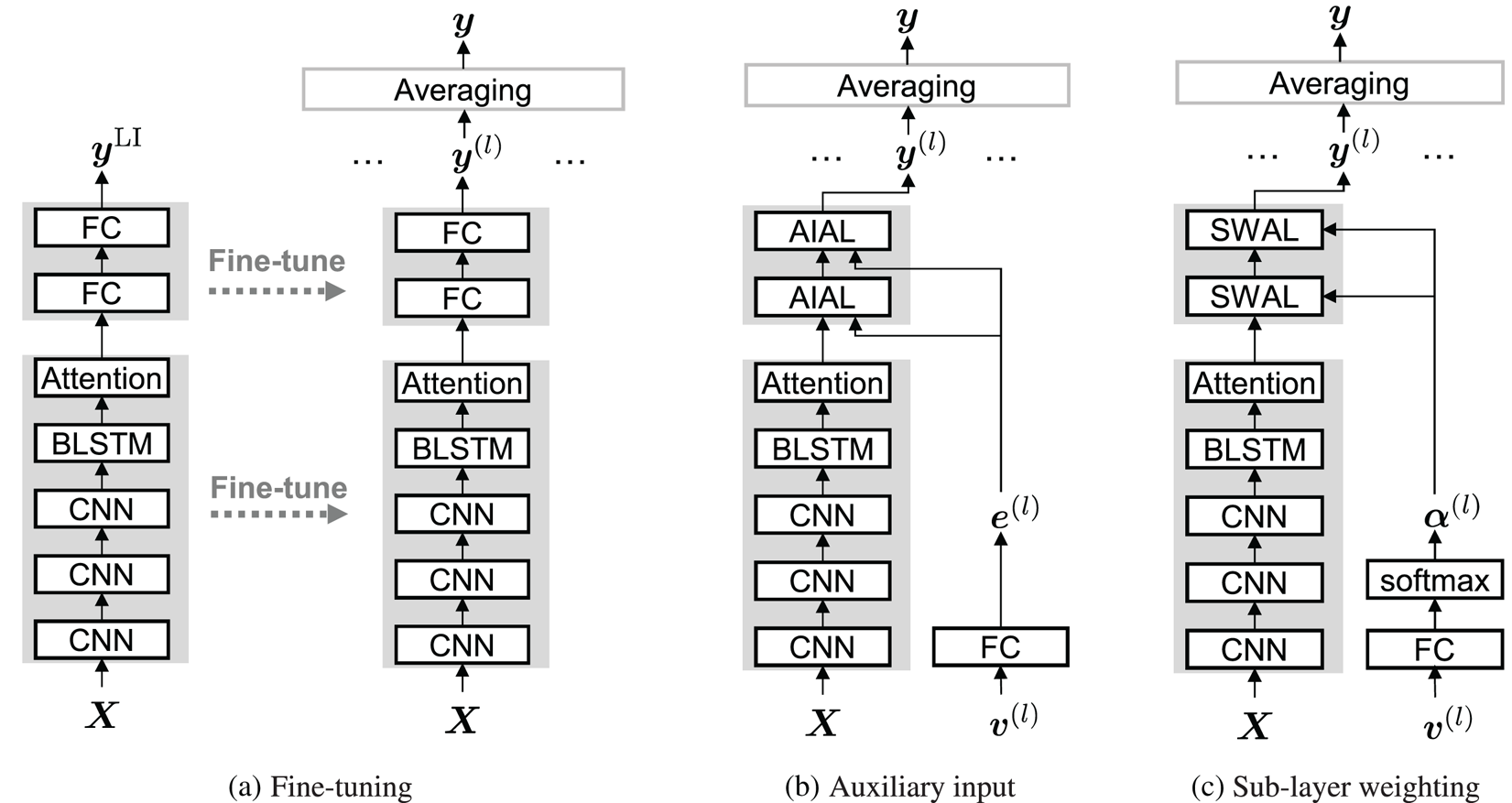
Fig. 2. Overview of the proposed majority-voted emotion recognition based on listener-dependent (LD) models. (a) Fine-tuning. (b) Auxiliary input. (c) Sub-layer weighting.
A) Model overview
1) Fine-tuning based LD model
A listener-independent (LI) model is retrained with specific listener training data to create a LD model. This is inspired by fine-tuning based domain adaptation in speech recognition [Reference Yu, Yao, Su, Li and Seide33].
Two-step training is employed. First, the LI model is trained with all utterances and their listeners in the training data. Listener-wise annotations are used for the reference distributions without distinguishing among listeners. The trained LI model outputs LI posterior probabilities $\boldsymbol {y}^{{\rm LI}}$ . Second, the LI model is retrained with a particular listener's labels and utterances. This yields as many isolated LD models as there are listeners in the training data.
. Second, the LI model is retrained with a particular listener's labels and utterances. This yields as many isolated LD models as there are listeners in the training data.
The optimization methods of LI / LD models are cross-entropy loss with LD perceived emotion, see as equation (3),

2) Auxiliary input based LD model
The second model adapts particular layers of the estimation model through the auxiliary use of listener information. This is inspired by speaker adaptation in speech recognition [Reference Garimella, Mandal, Strom, Hoffmeister, Matsoukas and Parthasarathi35] and speech synthesis [Reference Hojo, Ijima and Mizuno36].
One-hot vector of listener $l$ , $\boldsymbol {v}^{(l)}$
, $\boldsymbol {v}^{(l)}$ , is used to enhance acoustic features. $\boldsymbol {v}^{(l)}$
, is used to enhance acoustic features. $\boldsymbol {v}^{(l)}$ is projected into listener embedding vector $\boldsymbol {e}^{(l)}$
is projected into listener embedding vector $\boldsymbol {e}^{(l)}$ by an embedding layer,
by an embedding layer,
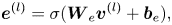
where $\boldsymbol {W}_e, \boldsymbol {b}_e$ are the parameters of the embedding layer. $\sigma$
are the parameters of the embedding layer. $\sigma$ is an activation function such as hyperbolic tangent. Then $\boldsymbol {e}^{(l)}$
is an activation function such as hyperbolic tangent. Then $\boldsymbol {e}^{(l)}$ is used as the auxiliary input of the adaptation layers, named auxiliary input-based adaptation layers (AIALs), in the decoder so as to adjust the decoder to the chosen listener,
is used as the auxiliary input of the adaptation layers, named auxiliary input-based adaptation layers (AIALs), in the decoder so as to adjust the decoder to the chosen listener,
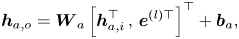
where $\boldsymbol {h}_{a, i}, \boldsymbol {h}_{a, o}$ are the input and the output of the AIAL, respectively, and $\boldsymbol {W}_a, \boldsymbol {b}_a$
are the input and the output of the AIAL, respectively, and $\boldsymbol {W}_a, \boldsymbol {b}_a$ are the parameters. Note that the embedding layer, the encoder and decoder are optimized jointly.
are the parameters. Note that the embedding layer, the encoder and decoder are optimized jointly.
The advantage of the auxiliary input based approach is that it offers greater stability than fine-tuning based models. There are two reasons for this. First, it has fewer parameters than fine-tuning based models. The fine-tuning models have to store as many encoders and decoders as there are listeners. However, auxiliary input based models share the encoder and decoder among all listeners, which suppresses the number of parameters. Second, the auxiliary input model can utilize the similarity of listeners. The fine-tuning models learn for just particular listeners. On the other hand, similar listeners will be mapped into similar latent vectors by the projection function, which reinforces the encoder's ability to learn LD emotion perception.
Note that only the decoder of the LD model is adapted to the selected listener. We consider that every listener perceives the same emotional cues from acoustic features, e.g. pitch raise / fall and fast-talking, and decision making from the emotional cues depends on listeners.
3) Sub-layer weighting based LD model
The sub-layer weighting approach combines multiple projection functions to adapt to the listener. This is inspired by context adaptive DNN proposed for source separation [Reference Delcroix, Zmolikova, Kinoshita, Ogawa and Nakatani37].
Sub-layer weighting-based adaptation layers (SWALs) are used to adapt the decoder to the selected listener. SWAL consists of multiple FC sub-layers,
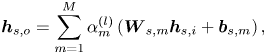
where $\boldsymbol {h}_{s, i}, \boldsymbol {h}_{s, o}$ are the input and output of the SWAL. $\boldsymbol {W}_{s,m}, \boldsymbol {b}_{s,m}$
are the input and output of the SWAL. $\boldsymbol {W}_{s,m}, \boldsymbol {b}_{s,m}$ is the parameters of the $m$
is the parameters of the $m$ -th sub-layer and $M$
-th sub-layer and $M$ is the total number of sub-layers. $\alpha _m^{(l)}$
is the total number of sub-layers. $\alpha _m^{(l)}$ is the adaptation weight associated with the selected listener,
is the adaptation weight associated with the selected listener,
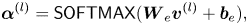
where $\boldsymbol {\alpha }^{(l)} = [\alpha _1^{(l)}, \cdots , \alpha _M^{(l)}]^{\top }$ is an adaptation weight vector determined by listener representation $\boldsymbol {v}^{(l)}$
is an adaptation weight vector determined by listener representation $\boldsymbol {v}^{(l)}$ and $\mathsf {SOFTMAX}(\cdot )$
and $\mathsf {SOFTMAX}(\cdot )$ is the softmax function. The structure of the SWAL is shown in Fig. 3. The model parameters including the embedding layer, equation (10), are jointly optimized as the auxiliary input approach.
is the softmax function. The structure of the SWAL is shown in Fig. 3. The model parameters including the embedding layer, equation (10), are jointly optimized as the auxiliary input approach.

Fig. 3. Structure of the Sub-layer Weighting-based Adaptation Layer (SWAL).
The main advantage of sub-layer weighting is that it is more expressive than auxiliary input based models. LD estimation is conducted by means of combining the perception rule of embedded listeners. However, it will require more training data than the auxiliary input-based approach because it has more parameters.
B) Adaptation to a new listener
The LD models can be directly applied to listener-closed situations, i.e. evaluation listeners are present in the training data. Although common SER tasks are listener-closed, SER in practice is listener-opened so evaluation listeners are not included in the training set. Our solution is to propose adaptation methods that allow the LD models to handle open listeners using a small amount of adaptation data.
The adaptation for the fine-tuning based LD model can be achieved by the retraining method that is the same as the second step of the flat-start training of the model. The LI model constructed by the training set is fine-tuned using the adaptation utterances of the particular listener.
The auxiliary input and sub-layer weighting based LD models adapt to a new listener to estimate the most similar listener code in the training listeners. Let $\hat {\boldsymbol {v}}^{(l)}$ and $\boldsymbol {u}^{(l)}$
and $\boldsymbol {u}^{(l)}$ be the estimated listener code and its indicator whose sizes are the same as $\boldsymbol {v}^{(l)}$
be the estimated listener code and its indicator whose sizes are the same as $\boldsymbol {v}^{(l)}$ . The initial value of $\boldsymbol {u}^{(l)}$
. The initial value of $\boldsymbol {u}^{(l)}$ is a zero vector. $\boldsymbol {u}^{(l)}$
is a zero vector. $\boldsymbol {u}^{(l)}$ is updated by backpropagating the loss of the adaptation data while freezing all the model parameters, as shown in Fig. 4. Note that the proposed adaptation does not update $\hat {\boldsymbol {v}}^{(l)}$
is updated by backpropagating the loss of the adaptation data while freezing all the model parameters, as shown in Fig. 4. Note that the proposed adaptation does not update $\hat {\boldsymbol {v}}^{(l)}$ directly so as to restrict that the sum of $\hat {\boldsymbol {v}}^{(l)}$
directly so as to restrict that the sum of $\hat {\boldsymbol {v}}^{(l)}$ to be 1 and all the dimensions to be non-negative, which is the same constraint as $\boldsymbol {v}^{(l)}$
to be 1 and all the dimensions to be non-negative, which is the same constraint as $\boldsymbol {v}^{(l)}$ in the training step. After the estimated listener vector $\hat {\boldsymbol {v}}^{(l)}$
in the training step. After the estimated listener vector $\hat {\boldsymbol {v}}^{(l)}$ is obtained from the adaptation data, it is fed to the LD models as the listener code, and the posterior probabilities of the perceived emotion of the new listener are derived. This approach is similar to those proposed in speech recognition [Reference Abdel-Hamid and Jiang39].
is obtained from the adaptation data, it is fed to the LD models as the listener code, and the posterior probabilities of the perceived emotion of the new listener are derived. This approach is similar to those proposed in speech recognition [Reference Abdel-Hamid and Jiang39].
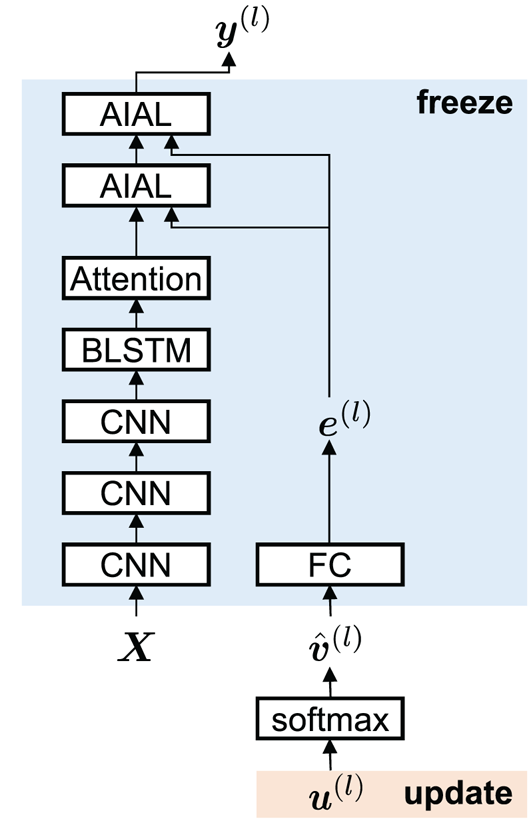
Fig. 4. Adaptation for the auxiliary input-based LD model.
V. EXPERIMENTS
We evaluated the proposed LD models in two scenarios. The first was a flat-start evaluation. The estimation models were trained from scratch and evaluated by listeners present in the training dataset, i.e. a listener-closed condition. The second was an adaptation evaluation. It was a listener-open condition; the utterances and listeners separated from the training data were used for the adaptation and evaluation data to investigate estimation performance for unseen listeners.
A) Datasets
Two large SER datasets, Interactive Emotional Dyadic Motion Capture (IEMOCAP) [Reference Busso40] and MSP-Podcast [Reference Lotfian and Busso41], were used in evaluating the proposal. IEMOCAP and MSP-Podcast contain acted and natural emotional speech, respectively. We selected four target emotions, neutral (Neu), happy (Hap), sad (Sad), and angry (Ang). All non-target emotion classes in the datasets were set as other (Oth) class.
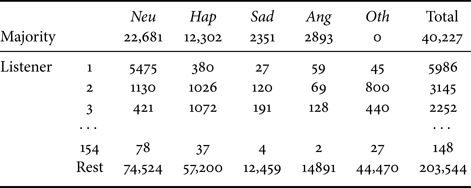
IEMOCAP contains audiovisual data of 10 skilled actors (five males and five females) in five dyadic sessions. The database consists of a total of 12 h of English utterances generated by improvised or scripted scenarios specifically written to represent the emotional expressions. As in several conventional studies [Reference Lee and Tashev11, Reference Li, Song, McLoughlin, Guo and Dai14, Reference Satt, Rozenberg and Hoory16, Reference Nediyanchath, Paramasivam and Yenigalla27, Reference Ando, Kobashikawa, Kamiyama, Masumura, Ijima and Aono29], we used only audio tracks of the improvised set since scripted data may contain undesired contextual information. There are six listeners in the corpus and every utterance was annotated by three of them. The annotated categorical emotion labels are 10: neutral, happy, sad, angry, disgusted, excited, fearful, frustrated, surprised, and other. We combine happy and excited into Hap class in accordance with conventional studies [Reference Li, Zhao and Kawahara18, Reference Neumann and Vu19]. Although listeners were allowed to give multiple emotion labels to each utterance, to evaluate listener-wise emotion perception performance we unified them so that all listeners labeled one emotion per utterance. The unification rule was to select the majority-voted emotion if it is included in the multiple annotations, otherwise the first annotation is the unique perceived emotion. The listeners who gave fewer than 500 annotations were clustered as the “rest listeners” because they provided too little information to support learning LD emotion perception characteristics. Finally, the utterances whose majority-voted emotion is one of the target emotions were used to form the evaluation dataset. The numbers of utterances are shown in Table 1. The estimation performances were compared by leave-one-speaker-out cross-validation; one speaker was used for testing, another for validation, and the other eight speakers were used for training.
Table 1. Number of utterances in IEMOCAP

MSP-Podcast contains English speech segments from podcast recordings. Collected from online audio shows, they cover a wide range of topics like entertainment, politics, sports, and so on. We used Release 1.7 which contains approximately 100 h of speaking turns. Annotations were conducted by crowdsourcing. There are 11,010 listeners and each utterance was annotated by at least three listeners (6.7 listeners per utterance on average). This dataset has two types of emotion annotations, primary and secondary emotions; we used only the primary emotions as listener-wise perceived emotions. The variety of annotated primary emotions consisted of neutral, happy, sad, angry, disgust, contempt, fear, surprise, and other. We used the utterances whose majority-voted emotions were one of the target emotions. A predetermined speaker-open subset was used in the flat-start evaluation; 8215 segments from 60 speakers for testing, 4418 segments from 44 speakers for validation, and the remaining 25,332 segments from more than 1000 speakers for training. The listeners who gave fewer than 100 annotations in the training set were clustered as “rest listeners”, same as IEMOCAP. The total numbers of emotional utterances are shown in Table 2.
Table 2. Number of utterances in MSP-Podcast
To clarify the impact of listener dependency on emotion perception, we first investigated the similarity of listener annotations. Fleiss’ and Cohen's kappa coefficients were employed as the similarity measures of the overall and the individual pairs of listeners, respectively. The coefficients were calculated through 5-class matching (4 target emotions + Oth) from only the utterances in the evaluation dataset. Cohen's kappa coefficients of the listener pairs in which both listeners annotated less than the same 20 utterances were not evaluated (‘−’ in results). Fleiss’ kappa were 0.57 in IEMOCAP and 0.35 in MSP-Podcast. There are two reasons for the lower consistency rate of MSP-Podcast. First, MSP-Podcast speech segments are completely natural, unlike IEMOCAP utterances which contained acted speech; this increased the ambiguous emotional speech in MSP-Podcast. Second, MSP-Podcast listeners will have larger diversity than those of IEMOCAP. All the listeners in IEMOCAP are students in the same university [Reference Busso40]. Cohen's kappa coefficients of IEMOCAP and MSP-Podcast listeners are shown in Fig. 5. It is shown that listener 2 showed relatively high similarity with listeners 1 and 3, while listeners 1 and 3 showed low similarity in IEMOCAP. The MSP-Podcast result showed the same property. Listener 1 showed high similarity with listeners 4, 9, 10, but low similarity with the remaining listeners. Listener 6 was similar to listeners 4 and 5. These indicate that emotion perception depends on listeners, and that there are several clusters of emotion perception criteria.
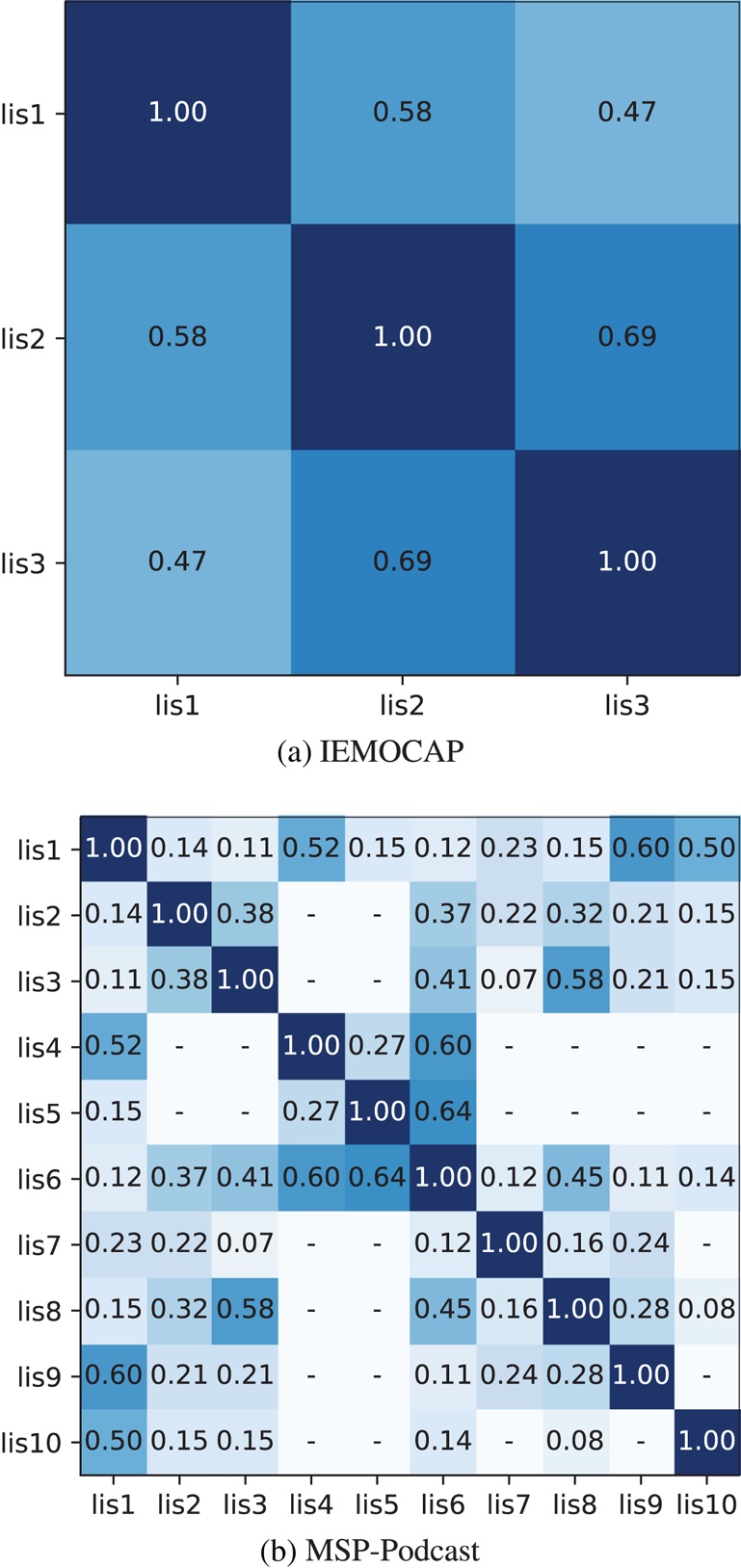
Fig. 5. Cohen's kappa coefficients of listener annotations. (a) IEMOCAP. (b) MSP-Podcast.
B) Flat-start evaluation
1) Setups
Log power spectrograms were used as acoustic features. The conditions used in extracting spectrograms followed those of conventional studies [Reference Satt, Rozenberg and Hoory16, Reference Ma, Wu, Jia, Xu, Meng and Cai42]. Frame length and frame shift length were 40 and 10 ms, respectively. The window type was Hamming window. DFT length was 1600 (10 Hz grid resolution) and we used 0–4 kHz frequency range, which yielded 400-dimensional log power spectrograms. All the spectrograms were z-normalized using the mean and variance of the training dataset.
The baseline was the majority-voted emotion recognition model described in Section III. An ensemble of multiple majority-voted models with different initial parameters was also employed to compare with the proposed method that unifies several outputs of LD models. The number of ensembles was the average number of listeners per utterance, i.e. 3 and 7 in IEMOCAP and MSP-Podcast, respectively. The structure of the baseline is shown in Table 3. Each CNN layer was followed by batch normalization [Reference Ioffe and Szegedy43], rectified linear activation function, and 2$\times$ 2 max pooling layers. Early stopping was performed using development set loss as the trigger. The optimization method was Adam [Reference Kingma and Ba44] with a learning ratio of 0.0001. In the training step, inverse values of the class frequencies were used as class weights to mitigate the class imbalance problem [Reference Elkan45]. Minibatch size was 8 in IEMOCAP and 16 in MSP-Podcast evaluations. Data augmentation was performed by means of speed perturbation with speed factors of 0.9, 0.95, 1.05, and 1.1 [Reference Sarma, Ghahremani, Povey, Goel, Sarma and Dehak7]. SpecAugment [Reference Park46] was also applied with two time and frequency masking. The ensemble of multiple majority-voted models with different initial parameters was also compared because the proposed method unifies the multiple outputs of LD models. The number of ensembled models was the average number of listeners per utterance, i.e. 3 and 7 in IEMOCAP and MSP-Podcast, respectively.
2 max pooling layers. Early stopping was performed using development set loss as the trigger. The optimization method was Adam [Reference Kingma and Ba44] with a learning ratio of 0.0001. In the training step, inverse values of the class frequencies were used as class weights to mitigate the class imbalance problem [Reference Elkan45]. Minibatch size was 8 in IEMOCAP and 16 in MSP-Podcast evaluations. Data augmentation was performed by means of speed perturbation with speed factors of 0.9, 0.95, 1.05, and 1.1 [Reference Sarma, Ghahremani, Povey, Goel, Sarma and Dehak7]. SpecAugment [Reference Park46] was also applied with two time and frequency masking. The ensemble of multiple majority-voted models with different initial parameters was also compared because the proposed method unifies the multiple outputs of LD models. The number of ensembled models was the average number of listeners per utterance, i.e. 3 and 7 in IEMOCAP and MSP-Podcast, respectively.
Table 3. Network architectures of emotion recognition model
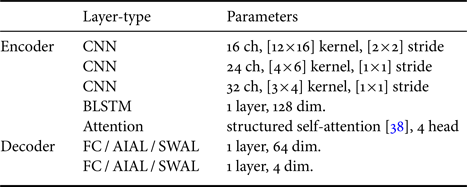
The proposals were LD models by fine-tuning, auxiliary input, and sub-layer weighting. LI model, the base model of the fine-tuning based LD model, was also compared to investigate the difference before and after fine-tuning. These model structures were the same as the baseline except for FC layers in the decoder, which were replaced with AIALs or SWALs. The numbers of listener embedding vector dimensions and sub-layers were 2, 3, 4, 8, 16 and we selected the best parameters for each dataset. The learning ratio was 0.0001 and 0.00005 in flat-start and fine-tuning, respectively. The class weights were calculated by each listener in LD model training. The other training conditions and data augmentation setup were those of the baseline. All the baseline and the proposed methods were implemented by PyTorch [Reference Paszke47]. Comparisons of the model parameters are shown in Table 4. The numbers of dimensions of listener embedding vector dimensions and sub-layers shown in the table were 4.
Table 4. Number of model parameters

Two evaluation metrics common in emotion recognition studies were employed: weighted accuracy (WA) and unweighted accuracy (UA). WA is the classification accuracy of all utterances and UA is the macro average of individual emotion class accuracies. We evaluated not only the performances of majority-voted emotion estimation but also those of listener-wise emotion recognition to investigate the capability of the proposed LD models.
2) Results
The results of majority-voted emotion estimation are shown in Table 5. The notation Majority (ens.) means the ensemble result of the majority-voted models. Comparing the two datasets, MSP-Podcast yielded lower overall accuracy than IEMOCAP. It is considered that MSP-Podcast contains natural speech with a large number of speakers, which makes it more difficult to recognize emotion than IEMOCAP, which holds acted utterances from limited speakers. The LD models showed significantly better WAs ($p\!<\!0.05$ in paired t-test) as almost the same or better UAs than the baselines on both datasets. For example, fine-tuning based LD models achieved 3.8 and 2.7% improvements from the single majority-voted model in WA and UA for IEMOCAP, 8.8 and 1.9% for MSP-Podcast. These results indicate that majority-voted emotion recognition based on LD models is more effective than the conventional majority-voted emotion modeling framework. Figs. 6 and 7 show the confusion matrices of the baseline and the auxiliary input-based LD model. Comparing numbers of the corrected samples for each emotion, Hap was improved on both IEMOCAP and MSP-Podcast, while Sad and Ang were degraded on MSP-Podcast. One possible reason for the degradation is data imbalance. These two emotions were hardly observed by some listeners, e.g. listener 154 annotated only two utterances with Ang emotion as shown in Table 2, which leads to overfitting in the LD model. Comparing the LD models, there were no significant differences ($p\!\geq \!0.05$
in paired t-test) as almost the same or better UAs than the baselines on both datasets. For example, fine-tuning based LD models achieved 3.8 and 2.7% improvements from the single majority-voted model in WA and UA for IEMOCAP, 8.8 and 1.9% for MSP-Podcast. These results indicate that majority-voted emotion recognition based on LD models is more effective than the conventional majority-voted emotion modeling framework. Figs. 6 and 7 show the confusion matrices of the baseline and the auxiliary input-based LD model. Comparing numbers of the corrected samples for each emotion, Hap was improved on both IEMOCAP and MSP-Podcast, while Sad and Ang were degraded on MSP-Podcast. One possible reason for the degradation is data imbalance. These two emotions were hardly observed by some listeners, e.g. listener 154 annotated only two utterances with Ang emotion as shown in Table 2, which leads to overfitting in the LD model. Comparing the LD models, there were no significant differences ($p\!\geq \!0.05$ ), while fine-tuning and auxiliary input were slightly better for IEMOCAP, while sub-layer weighting yielded the best WA and fine-tuning attained the best UA for MSP-Podcast. Taking the number of parameters (see Table 4) into consideration, the auxiliary input based model is suitable for all conditions, while sub-layer weighting may become better for large datasets. Note that even the LI model significantly outperformed the model ensemble baseline in MSP-Podcast ($p\!<\!0.05$
), while fine-tuning and auxiliary input were slightly better for IEMOCAP, while sub-layer weighting yielded the best WA and fine-tuning attained the best UA for MSP-Podcast. Taking the number of parameters (see Table 4) into consideration, the auxiliary input based model is suitable for all conditions, while sub-layer weighting may become better for large datasets. Note that even the LI model significantly outperformed the model ensemble baseline in MSP-Podcast ($p\!<\!0.05$ ). One possible reason is that training by listener-specific labels allows the model to learn inter-emotion similarities. For example, a set of listener-wise labels {neu, neu, hap} indicates that the speech may contain both neu and hap cues. On the other hand, its majority-voted label just indicates the speech has neu characteristics.
). One possible reason is that training by listener-specific labels allows the model to learn inter-emotion similarities. For example, a set of listener-wise labels {neu, neu, hap} indicates that the speech may contain both neu and hap cues. On the other hand, its majority-voted label just indicates the speech has neu characteristics.
Table 5. Estimation accuracies of the majority-voted emotions. Bold means the highest accuracy.

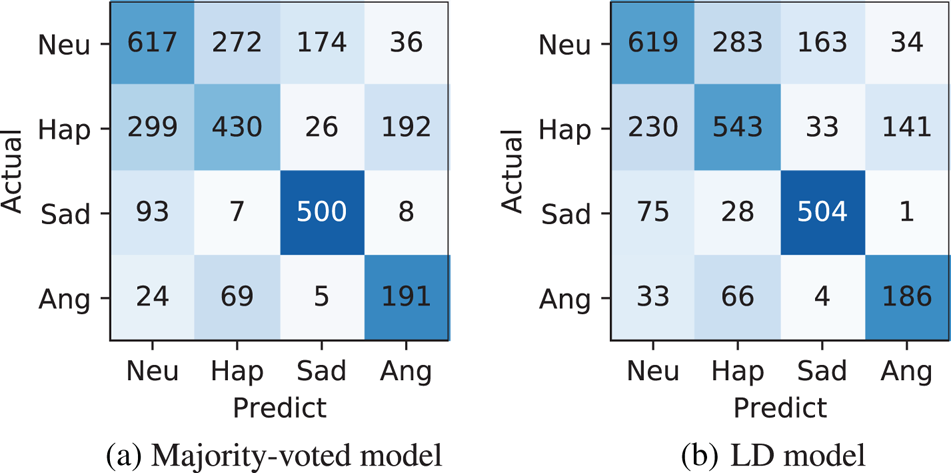
Fig. 6. Confusion matrices for IEMOCAP. (a) Majority-voted model. (b) LD model
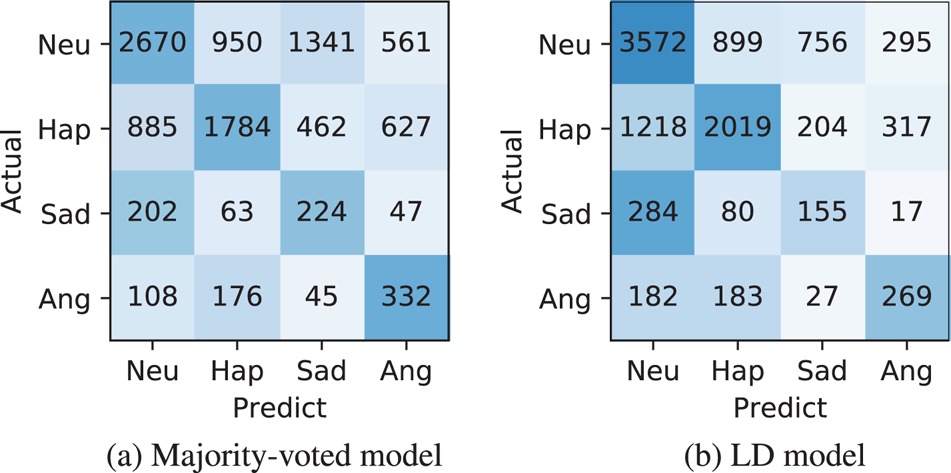
Fig. 7. Confusion matrices for MSP-Podcast. (a) Majority-voted model. (b) LD model.
Macro-averages of listener-wise emotion recognition performances are shown in Table 6. In this evaluation, WA / UAs of all the listeners except for “rest listeners” were averaged to compare overall performance. Table 6 represents that all LD models showed better performance than the baseline. The improvements were significant in MSP-Podcast ($p\!<\!0.05$ in paired t-test), while not in IEMOCAP. It is considered that IEMOCAP has only three listeners, which is too few samples for a paired t-test. Note that there are no significances among the three proposed LD models. The matrices of listener-wise WA with LD models are also shown in Fig. 8. All the LD models were constructed by fine-tuning. Comparing the matrices to Fig. 5, the evaluations of high similarity listener pairs tend to show relatively high WAs. For example, LD models of listeners 1, 4, 9, 10 showed higher WAs than the remaining LD models for listener 1 evaluation data. These results indicate that LD models can accurately learn LD emotion perception characteristics. Note that there are several listeners in which the listener-mismatched LD model showed better WAs than the listener-matched model. One possible reason is the difference in the amount of training data in listeners. For example, listener 1 has several times of training data compared with other listeners, which yields a better emotion perception model in spite of listener-mismatched conditions.
in paired t-test), while not in IEMOCAP. It is considered that IEMOCAP has only three listeners, which is too few samples for a paired t-test. Note that there are no significances among the three proposed LD models. The matrices of listener-wise WA with LD models are also shown in Fig. 8. All the LD models were constructed by fine-tuning. Comparing the matrices to Fig. 5, the evaluations of high similarity listener pairs tend to show relatively high WAs. For example, LD models of listeners 1, 4, 9, 10 showed higher WAs than the remaining LD models for listener 1 evaluation data. These results indicate that LD models can accurately learn LD emotion perception characteristics. Note that there are several listeners in which the listener-mismatched LD model showed better WAs than the listener-matched model. One possible reason is the difference in the amount of training data in listeners. For example, listener 1 has several times of training data compared with other listeners, which yields a better emotion perception model in spite of listener-mismatched conditions.
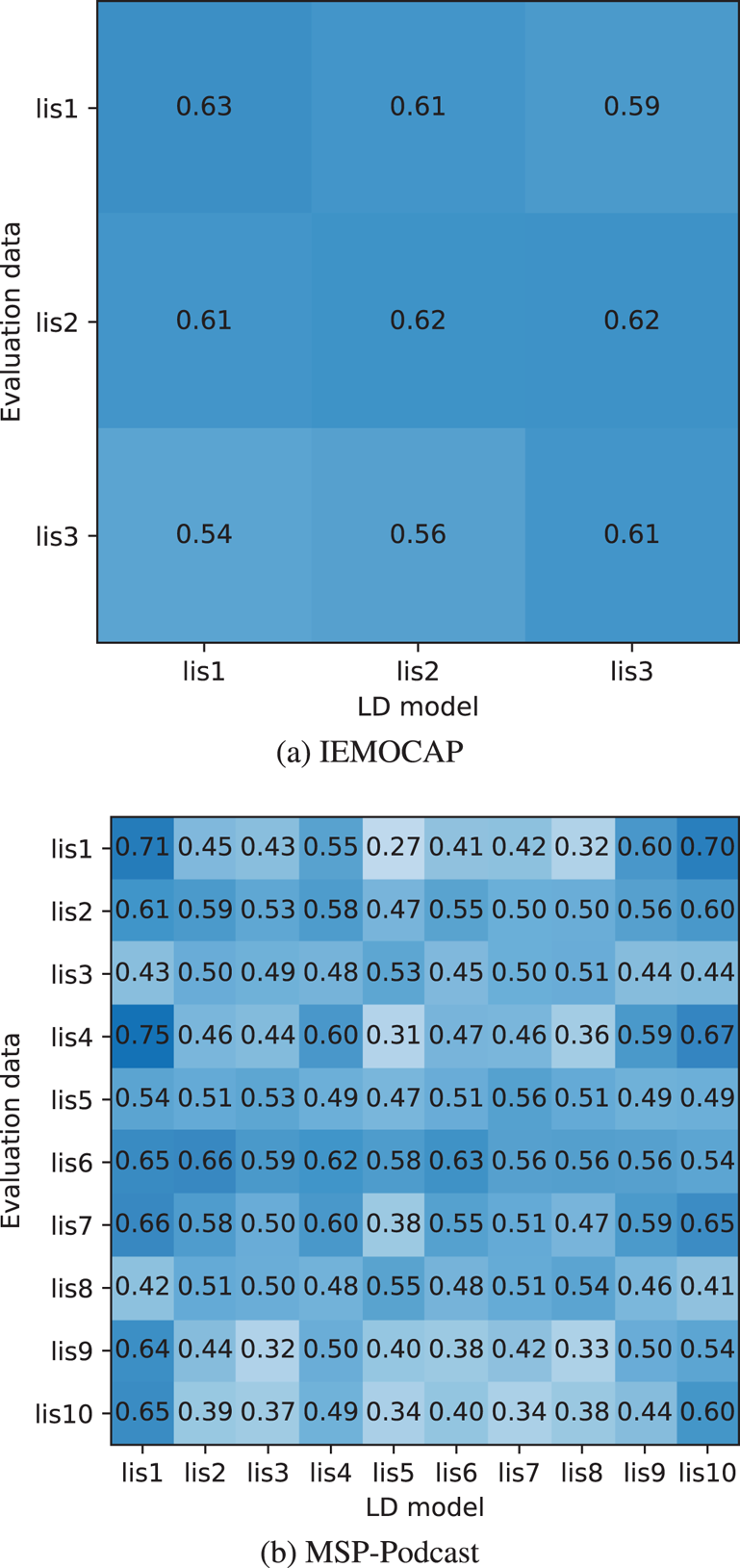
Fig. 8. WAs of listener-wise emotion recognitions with LD models. (a) IEMOCAP. (b) MSP-Podcast.
Table 6. Macro-average of estimation accuracies of the listener-dependent perceived emotions. Bold means the highest accuracy.

C) Adaptation evaluation
1) Setups
We resegmented MSP-Podcast evaluation subsets to create an utterance and listener open dataset. First, the utterances contained only “rest listeners” were selected from the original training, validation, and testing dataset as the open data candidates. Second, the listeners who annotated more than two utterances with each target emotion and 30 utterances in total of the candidates were selected as the open listeners. Finally, the utterances that had one or more open listeners in the candidates were regarded as the open dataset, while the remaining candidates were returned to the original training, validation, and test sets. We selected 24 listeners with 1080 utterances for the open dataset. The average number of utterances per listener was 42.8. Note that we did not use IEMOCAP in the adaptation evaluation because no open utterances were available.
The baseline method was the majority-voted emotion recognition model without adaptation. It was trained by the resegmented training and validation set. The proposed was the auxiliary input-based LD model with adaptation. The LD model was trained by the resegmented training and validation set first, then adapted to the specific listener in the open set with adaptation data. five-fold cross-validation was used in the LD model adaptation; 80% of the open dataset was used for adaptation and the rest 20% was for the evaluation. To evaluate the performance of the listener code estimation alone, we also ran a comparison with the auxiliary input-based LD model in the oracle condition in which the one-hot listener code that showed the highest geometric mean of WA and UA was selected for each open listeners. We used the same LD model in adaptation and oracle conditions. For the adaptation, the minibatch size was the same as the amount of listener-wise utterances in the adaptation set. The learning rate was 0.05. Earlystopping was not used and the adaptation was stopped at 30 epochs.
Evaluation metrics were macro-averages of the listener-wise WAs and UAs. Note that we did not evaluate the performance of the majority-voted emotion recognition because the majority-voted emotions were not open; the listeners of the utterances in the open dataset were almost “rest listeners” who included in the training subset and the majority-voted emotions were mostly determined by them.
2) Results
The macro-average of listener-wise WAs and UAs are shown in Table 7. Relative to the baseline, the auxiliary input-based LD model with adaptation achieved significantly better WA ($p\!<\!0.05$ in paired t-test) with the same level of UA ($p\!>\!0.05$
in paired t-test) with the same level of UA ($p\!>\!0.05$ ). Furthermore, the oracle of the auxiliary model showed very high WA and UA ($p<0.05$
). Furthermore, the oracle of the auxiliary model showed very high WA and UA ($p<0.05$ compared with the auxiliary model with adaptation). These indicate that the auxiliary model is capable of LD emotion recognition and the proposed adaptation is effective for unseen listeners, while there is room for improvement to estimate better listener code from a limited adaptation set. The same trend is present in the examples of the listener-wise WAs and UAs shown in Fig. 9. The LD model with adaptation showed the same or better performances than the majority model for all listeners, and the auxiliary model in the oracle setup greatly outperformed the adapted model for some listeners such as listener B.
compared with the auxiliary model with adaptation). These indicate that the auxiliary model is capable of LD emotion recognition and the proposed adaptation is effective for unseen listeners, while there is room for improvement to estimate better listener code from a limited adaptation set. The same trend is present in the examples of the listener-wise WAs and UAs shown in Fig. 9. The LD model with adaptation showed the same or better performances than the majority model for all listeners, and the auxiliary model in the oracle setup greatly outperformed the adapted model for some listeners such as listener B.
Table 7. Macro-average of WAs and UAs in listener-open dataset


Fig. 9. WA for each listeners in open dataset.
Tables 6 and 7 show that the auxiliary model with oracle evaluation in the open set attained higher accuracies than those with listener-closed training in the test set. One possibility is that there are some listeners who gave noisy annotations, which degrades estimation performance even in listener-closed conditions. It has been reported that there are several noisy annotators in crowdsourced data like MSP-Podcast [Reference Lotfian and Busso48].
VI. Conclusion
This paper proposed an emotion recognition framework based on LD emotion perception models. The conventional approach ignores the individuality of emotional perception. The key idea of the proposal lies in constructing LD models that account for individuality. Three LD models were introduced: fine-tuning, auxiliary input, and sub-layer weighting. The last two models can adapt to a wide range of listeners with limited model parameters. Experiments on two large emotion speech corpora revealed that emotion perception depends on listeners and that the proposed framework outperformed the conventional method by means of leveraging listener dependencies in majority-voted emotion recognition. Furthermore, the proposed LD models attained higher accuracies in listener-wise emotion recognition, which indicates that the LD models were successful in learning the individuality of emotion perception.
Future work includes investigating the effectiveness of the proposed approach in other languages and cultures, improving the adaptation framework to unseen listeners, and combining the LD models with the speaker adaptation frameworks.
Atsushi Ando received the B.E. and M.E. degrees from Nagoya University, Nagoya, Japan, in 2011 and 2013, respectively. Since joining Nippon Telegraph and Telephone Corporation (NTT) in 2013, he has been engaged in research on speech recognition and non-/para-linguistic information processing. He received the Awaya Kiyoshi Science Promotion Award from the Acoustic Society of Japan (ASJ) in 2019. He is a member of ASJ, the Institute of Electronics, Information and Communication Engineers (IEICE), and the International Speech Communication Association (ISCA).
Takeshi Mori received the B.E. and the M.E. degrees from Tokyo Institute of Technology in 1994 and 1996 and the D.E. degree from University of Tsukuba in 2007, respectively. Since joining NTT in 1996, he has been engaged in research on speech and audio processing algorithms. He is a member of the IEEE, ASJ, and IEICE.
Satoshi Kobashikawa received the B.E., M.E., and Ph.D. degrees from the University of Tokyo, Tokyo, Japan, in 2000, 2002, and 2013, respectively. Since joining NTT in 2002, he has been engaged in research on speech recognition and spoken language processing. He received the Kiyasu Special Industrial Achievement Award in 2011 from IPSJ, the 58th Maejima Hisoka Award from the Tsushinbunka Assocsiation in 2012, and the 54th Sato Paper Award from ASJ in 2013. He is a member of ASJ, IPSJ, IEICE, and ISCA.
Tomoki Toda received the B.E. degree from Nagoya University, Japan, in 1999 and the M.E. and D.E. degrees from the Nara Institute of Science and Technology (NAIST), Japan, in 2001 and 2003, respectively. He was a Research Fellow of the Japan Society for the Promotion of Science, from 2003 to 2005. He was then an Assistant Professor, from 2005 to 2011, and an Associate Professor, from 2011 to 2015, at NAIST. Since 2015, he has been a Professor with the Information Technology Center, Nagoya University. He received more than 15 article/achievement awards, including the IEEE SPS 2009 Young Author Best Paper Award and the 2013 EURASIP-ISCA Best Paper Award (Speech Communication Journal). His research interest includes statistical approaches to sound media information processing.


















 Open access
Open access