



Introduction
Sentences with universal quantifiers, such as ‘every’ in English, are often hard for children to process because their meaning can be highly abstract and logical. Adult native speakers of English comprehend a truth condition of a statement such as ‘Every lion is holding a balloon’ with ease; in order for this proposition to be true, every single accessible entity that can be labeled as ‘lion’ within the immediate discourse context must be holding a balloon. Since what must be evaluated is the predication’s faithfulness to the observable reality, the existence of objects that do not participate in the predicated action or state is irrelevant, i.e., must be ignored for the truth value judgment. Since Inhelder and Piaget (Reference Inhelder and Piaget1964), it has been known that children tend to comprehend sentences with a universal quantifier in a non-adult-like manner. Research on children’s comprehension errors started to reveal that there seems to be a range of sources of information that children utilize in an attempt to avoid committing comprehension errors. Studies also suggest that the erroneous comprehension of universally-quantified sentences may not necessarily be child-specific comprehension errors (Aravind et al., Reference Aravind, de Villiers, de Villiers, Lonigan, Phillips, Clancy, Landry, Swank, Assel, Taylor, Eisenberg, Spinrad and Valiente2017; Minai et al., Reference Minai, Jincho, Yamane and Mazuka2012), calling for further research on a wider range of age groups. In addition, there is a debate as to whether the prosodic property of a quantifier does or does not affect the interpretation of the proposition (Baltazani, Reference Baltazani2002; Grinstead et al., Reference Grinstead, Thorward, Ross, Maynell, Franich, Iserman and Keil2010; Miller et al., Reference Miller, Schmitt, Chang, Munn, Brugos, Clark-Cotton and Ha2005). Sensitivity to prosodic prominence develops gradually with age (Ito, Reference Ito and Matthews2014, Reference Ito, Prieto and Esteve-Gibert2018 for summary), yet the developmental trajectory for prosodic sensitivity is not attested with observations from an extended age range. Importantly, developmental data of the effect of prosody on the comprehension of a universal quantifier are yet to be provided. The present study investigates the comprehension and processing of sentences containing ‘every’ by a wide range of native English speakers, extending from school-age children to aging adults (aged 4-79 years). We combined a visual-world eye tracking paradigm with a picture-sentence verification task, such that participants’ immediate responses to prosodically emphatic or non-emphatic ‘every’ or the quantified noun can be examined together with their ultimate judgments on the truth value of the sentence.
Quantifier-spreading (Q-spreading) errors
Research to date has revealed that young children tend to exhibit comprehension errors involving a universal quantifier (e.g., ‘every’ in English). One type of error, which is of our current interest, is the Quantifier-spreading (Q-spreading) error, erroneous rejections of a true ‘every’-sentence like (1) below in a circumstance where there is an extra basket not held by anybody besides some pigs carrying a basket each (extra object contexts; see Figure 1).

Figure 1. Extra-object context sample.
A camp of accounts called the Partial Competence View claims that the Q-spreading errors reflect an aspect of children’s still-developing semantics (e.g., Drozd, Reference Drozd, Bowerman and Levinson2001; Geurts, Reference Geurts2003; Philip, Reference Philip1995), positing that children come up with non-adult-like linguistic representation of ‘every’-sentences like (1), which lead them to exhibit Q-spreading errors. For example, Philip (Reference Philip1995) claimed that child grammar allows non-adult-like reading for ‘every’-sentences like (1), as well as adult-like reading.

Accounts like this call for explanation about how children abandon the non-adult-like reading like (2), growing out of the developmental stage at which their still-developing competence leads them to implement erroneous interpretation. To date, there seems to be no compelling model that accounts for how children converge on adult grammar which excludes the erroneous reading like (2b) (Guasti, Reference Guasti2016).
An alternate camp, the Full Competence View, claims that children’s competence and semantic knowledge of a universal quantifier is adult-like (Gualmini, Reference Gualmini2004; Minai, Reference Minai2006) and comprehension errors involving a universal quantifier are consequences of factors extraneous to their linguistic knowledge (Brooks & Sekerina, Reference Brooks and Sekerina2005; Crain et al., Reference Crain, Thornton, Boster, Conway, Lillo-Martin and Woodams1996). These accounts were primarily motivated by findings revealing that rates of children’s Q-spreading errors in an extra-object context are lowered under certain referential conditions. For example, children’s judgment of ‘every’-sentences presented in an extra-object context were much more adult-like when richer pragmatics were presented. Crain et al. (Reference Crain, Thornton, Boster, Conway, Lillo-Martin and Woodams1996) utilized the Truth Value Judgment Tasks, in which an extra-object context was presented at the end of discourse context. For example, for the test sentence ‘Every skier drank a cup of apple cider’, the accompanied story ended with the scene which contains the extra objects and makes the sentence true, but in the middle of the story, an alternate outcome which would have made the sentence false was explicitly presented (e.g., some skiers considered drinking something other than apple cider, but at the end of the story, every skier drank a cup of apple cider, while there were extra cups of apple cider left). Because both truth and falsity of the test sentence are overtly contrasted, the truth value judgment of sentences becomes more felicitous, meeting the condition of plausible dissent (Crain & Thornton, Reference Crain and Thornton1998). In this modified task, 3- to 5-year-old children correctly accepted the test sentence 88% of the time. Given that elaborated discourse contexts facilitated children’s adult-like comprehension of ‘every’-sentences within extra-object contexts, children’s Q-spreading errors reported in previous studies may be stemming from impoverished contextual information, and thus the conclusions based on such errors may have underestimated children’s capability to comprehend ‘every’-sentences. Such a pragmatic proposal was recently updated in Skordos et al. (Reference Skordos, Myers and Barner2022). In addition to the plausible dissent manipulation, they further manipulated the question under discussion (QUD) that is relevant to the quantification (e.g., number of skiers who drank a cup of cider), and revealed lower rates of Q-spreading errors from children when the relevant QUD was clearly presented than when they did not get presented the relevant QUD clearly.
Some researchers focused on the visual salience of the extra object, uniquely not paired with an agent, and manipulated the extra-object pictures to attenuate their visual salience (Gouro et al., Reference Gouro, Norita, Nakajima, Ariji and Otsu2001; Sugisaki & Isobe, Reference Sugisaki, Isobe, Kim and Werle2001), e.g., including a bigger number of the extra object than the number of agent-object pairs (Sugisaki & Isobe, Reference Sugisaki, Isobe, Kim and Werle2001). Such visual manipulation also led to lower rates of children’s Q-spreading errors, suggesting that the visual salience of the extra object (which does not participate in the described event) may have been another crucial source of children’s errors in the previous studies. In a similar vein, Kiss and Zétényi (Reference Kiss and Zétényi2017) manipulated pragmatic richness of extra-object picture materials. They pointed out that typical extra visual objects which are known to elicit Q-spreading were simplistic and iconic line drawings that lack episodic details in the scene. Such visual abstraction may mislead children to reason that everything in the scene has ostensive cues to be represented as a semantically and pragmatically meaningful element in comprehending the accompanied universally-quantified sentence. In their study, Hungarian-acquiring preschool children (mean age=5;3) verified universally-quantified sentences like ‘Every child is sitting on a highchair’, accompanied either by a simplistic line drawing of children sitting on a highchair and an empty “extra” highchair with blank background, or by a photograph of children sitting in a highchair and an empty “extra” highchair at a counter table of a restaurant. Children in the latter condition returned significantly higher rates of adult-like comprehension, as was predicted by their ostension-based account.
Interestingly, Q-spreading errors are not found only in young children. A recent study revealed that Dutch children continue exhibiting Q-spreading errors involving a universal quantifier until around age 9 (de Koster et al., Reference de Koster, Spenader, Hendriks, Bertolini and Kaplan2018). Other studies further showed that adult speakers also exhibited Q-spreading errors to a noticeable extent (24% of the time in Aravind et al., Reference Aravind, de Villiers, de Villiers, Lonigan, Phillips, Clancy, Landry, Swank, Assel, Taylor, Eisenberg, Spinrad and Valiente2017; 40% of the time in Minai et al., Reference Minai, Jincho, Yamane and Mazuka2012). Aravind et al. (Reference Aravind, de Villiers, de Villiers, Lonigan, Phillips, Clancy, Landry, Swank, Assel, Taylor, Eisenberg, Spinrad and Valiente2017) longitudinally investigated children’s (aged 4-7) Q-spreading errors and another type of comprehension errors known as “Underexhaustive errors”, where children incorrectly accept sentences like ‘Every pig is carrying a basket’ when there is a pig not carrying a basket. They reported that rates of Q-spreading errors increased as the children grew older, while the Underexhaustive errors decreased and diminished by age 7 (Aravind et al., Reference Aravind, de Villiers, de Villiers, Lonigan, Phillips, Clancy, Landry, Swank, Assel, Taylor, Eisenberg, Spinrad and Valiente2017). The authors concluded that the two types of errors stem from different sources; the early dominance of Underexhaustive errors may reflect children’s initial misinterpretation of ‘every’ to be a non-exhaustive plural existential quantifier, while the source of Q-spreading may not be solely inherent to grammatical factors. They claim that Q-spreading may be triggered by underinformativeness of the ‘every’-sentence used to describe the extra-object context. If there are a few pig-basket pairs and a basket that no pig is carrying, and if the sentence is assumed to narrate what is happening in the scene, ‘Every pig is carrying a basket’ only partially describes what is depicted and thus is not fully informative.
The debate between the two camps has thus far developed with a primary focus on the findings on children’s off-line comprehension/truth value judgments of universally-quantified sentences based on the extra-object contexts. With online measures of the responses to ‘every’-sentences, however, we can identify the moment when the listeners deploy their linguistic knowledge of the quantifier and when they are distracted by the referential cues, which can lure them to make Q-spreading errors. Minai et al. (Reference Minai, Jincho, Yamane and Mazuka2012) adopted a visual-world eye tracking paradigm, providing insight into online aspects of children’s quantifier comprehension. Participants performed a picture-sentence verification task, which presented universally-quantified sentences describing the extra-object pictures. When there were multiple extra objects present in the extra-object contexts, 4- and 5-year-old children split into two groups based on their response patterns: (i) those who exhibited Q-spreading errors (mean accuracy in comprehension=1.2%) (‘Q-spreaders’, henceforth), and (ii) those who were able to comprehend ‘every’-sentences in an adult-like manner (mean accuracy in comprehension= 90.6%) (‘adult-like comprehenders’, henceforth). The eye movement data revealed that the ‘Q-spreaders’ looked at the extra objects robustly often and for extended period of time, particularly before the beginning of the sentence (i.e., during a preview of 2.5 sec) and towards the end of the sentence. In contrast, the ‘adult-like comprehenders’ did not exhibit a robust increase in looks to the extra objects throughout the sentence. The children were also provided an executive function measure with Dimensional Change Card Sort task (DCCS; Zelazo, Reference Zelazo2006), where they categorized testing cards that can be sorted with respect to two dimensions (color and shape), first by one dimension (e.g., color) and then by the other dimension (e.g., shape). This task gauges individuals’ cognitive flexibility – namely, the abilities to inhibit the information no longer relevant for the present task while attending to a new dimension, and to switch attention across the dimensions. The ‘adult-like comprehenders’ performed significantly better than the ‘Q-spreaders’ for this task, revealing that children who could more flexibly switch their attention between the two association rules verified the ‘every’-sentences more correctly. Based on these findings, Minai et al. claim that Q-spreading errors may be due to their still-developing executive function, which hinders them from inhibiting excess attention to the extra object(s), ultimately leading them to a Q-spreading-based inaccurate comprehension.Footnote 1 It should be noted that the vast majority of ‘Q-spreader’ children in Minai et al. (Reference Minai, Jincho, Yamane and Mazuka2012) returned Q-spreading errors consistently, failing to change their behavior throughout the testing. Out of 21 ‘Q-spreader’ children, 19 children returned Q-spreading errors for all the four test items. This brings up a possibility that the ‘Q-spreaders’ might have exhibited a ‘perseverance’ tendency; they initially made a Q-spreading error and adhered to it all the way. Minai et al. associated the Q-spreading errors with children’s tendency to maintain the initial commitment, Attentional Inertia (Diamond & Kirkham, Reference Diamond and Kirkham2005; Kirkham et al., Reference Kirkham, Cruess and Diamond2003), together with the visual salience of the extra object(s) that drew their visual attention. Children who committed Q-spreading errors initially paid attention to the presence of the extra object(s) in the visual contexts, and interpreted the scene as the depiction of the outlining extra object(s) not paired with an animal. Once they established this perspective, they were unable to disengage themselves from it, failing to reinterpret it as the event of animals’ holding objects, i.e., the required interpretation for them to evaluate the meaning of the ‘every’-sentence. This tendency is known as ‘the kindergarten-path effect’, and has been observed in the processing of syntactically ambiguous sentences (Choi & Trueswell, Reference Choi and Trueswell2011; Snedeker & Yuan, Reference Snedeker and Yuan2008; Trueswell et al., Reference Trueswell, Sekerina, Hill and Logrip1999) as well as in discourse processing (Ito et al., Reference Ito, Jincho, Minai, Yamane and Mazuka2012). Woodard et al. (Reference Woodard, Pozzan and Trueswell2016) suggested that the ability to resolve the kindergarten-path effect may be supported by executive function. Minai et al.’s findings converge with those of Woodard et al.’s in that children’s executive function performances correlated with their successful processing of sentence meaning. Hence, previously reported children’s behavior with universally-quantified sentences may be another case in which the perseverance tendency leads to resilient response patterns within a specific task. The present study expands the age range of participants to further explore whether the inability to shift the response patterns is strictly age bound, or it persists for a longer period than previously reported.
Role of prosodic prominence
While visual salience is one factor that affects the way that sentences with ‘every’ are comprehended, acoustic salience may also impact how a universal quantifier and its scope are interpreted. Prosodic prominence is known to evoke contrastive interpretation of referential relationships in both adults and children (Arnold, Reference Arnold2008; Ito et al., Reference Ito, Jincho, Minai, Yamane and Mazuka2012; Ito et al., Reference Ito, Bibyk, Wagner and Speer2014; Ito & Speer, Reference Ito and Speer2008, Reference Ito, Speer, Frota, Prieto and Elordieta2011; Kurumada & Clark, Reference Kurumada and Clark2017; Weber et al., Reference Weber, Braun and Crocker2006; see Ito, Reference Ito and Matthews2014, Reference Ito, Prieto and Esteve-Gibert2018 for review). These studies have demonstrated that listeners quickly integrate the emphasized discourse entity with the visual context that informs what can be contrasted with what, and this incremental integration guides listeners’ attention in an anticipatory manner. Previously, Ito and colleagues (Ito et al., Reference Ito, Jincho, Minai, Yamane and Mazuka2012, 2014; Ito & Speer, Reference Ito and Speer2008, Reference Ito, Speer, Frota, Prieto and Elordieta2011) tested speakers of English and those of Japanese and have shown that a contrastive prosodic prominence on a prenominal modifier (such as color or size adjectives) can lead to anticipatory eye-movements to a contrastive referent set (e.g., when listening to a short discourse such as ‘Where is the pink cat? Now, where is the GREEN monkey?’, people immediately move their eyes to the cat cell that included a green cat upon hearing GREEN). Importantly, such anticipatory processing is observable because the interpretational scope of the prenominal modifier is bound to the local noun phrase that includes the modifier. Accordingly, prosodic prominence (via placement of a contrast-evoking pitch accent in English or expansion of pitch range for lexical pitch accent in Japanese) narrows the candidate referent set based on the discourse-based accessibility and leads to an anticipation of the upcoming noun.
Previous experimental work shows that prosodic prominence on existential quantifiers such as ‘some’ can largely affect the interpretation of the propositions. Miller et al. (Reference Miller, Schmitt, Chang, Munn, Brugos, Clark-Cotton and Ha2005) tested the effect of prosodic emphasis on ‘some’ with action instructions such as ‘Make some faces happy’ in 4- and 5-year-old children, as well as adults. Both groups drew smiley faces on ‘some but not all’ creatures when ‘some’ was emphasized, conveying the ‘some but not all’ interpretation known as the scalar implicature. The scalar implicature of ‘some’ was evoked much less when the emphasis was placed elsewhere (e.g., ‘happy’). Later, Grinstead et al. (Reference Grinstead, Thorward, Ross, Maynell, Franich, Iserman and Keil2010) tested the effects of vowel quality and pitch accent on the interpretation of ‘some’ in 4- to 7-year-old children and adults, using a video-narrative verification task (e.g., Video → Narrative by speaker A: ‘Some monkeys jumped over the fence.’ Question by speaker B: ‘Is that right?’). They confirmed that prosodically prominent ‘some’ generally evoked interpretations with the scalar implicature in both groups, although adults were more sensitive to the presence of contrastive accent than children, who relied more on the full vowel quality. While studies such as Kurumada and Clark (Reference Kurumada and Clark2017) and Ito et al. (Reference Ito, Jincho, Minai, Yamane and Mazuka2012) have demonstrated that preschoolers and kindergarteners are sensitive to contrastive pitch accent, children’s prosodic processing is by no means adult-like (Ito, Reference Ito, Prieto and Esteve-Gibert2018; Ito et al. Reference Ito and Matthews2014). Ito et al. (Reference Ito and Matthews2014) have shown that 10- and 11-year-old children are still much slower than adults in their responses to contrastive pitch accent (and in their recoveries from erroneous gazes). Data from participants of a wider age range would inform whether the processing speed to prosodic prominence improves with age even after puberty and during young adolescence.
Importantly, the scope of interpretation for the universal quantifier ‘every’ is much wider than that of prenominal modifiers, and thus the effect of prosodic prominence on ‘every’ may not guide the comprehension in a similar anticipatory manner. The truth value of the entire proposition must be evaluated according to whether the predication correctly describes the status or action of the referred set. When ‘every’ is prosodically emphasized (i.e., pitch-accented as in ‘EVERY pig is carrying a basket’), the referent set that is highlighted first for the referential resolution is the entities that are labeled by the immediately following head noun (pig). Once the set is identified, then the propositional truth value is evaluated based on the scene, regarding whether every member of this set is actually carrying a basket. Thus, the question to be explored in the present study is whether the contrastive accent on ‘every’ directs listeners’ attention to the agent set (and their actions), which should lead to relatively less attention to the isolated extra object and thus should lead to less Q-spreading errors. When the prosodic prominence is shifted to the head noun (e.g., ‘EVERY PIG is carrying a basket’), it evokes the contrast between emphasized entity (pig) and other entity that can potentially play the same agent role (other animal). Thus, in the absence of another potential agent, the prominence is infelicitous and useless. Nonetheless, the prominence on the subject noun may direct higher visual attention to all that could play the agent role on the display, leading to fewer looks to the extra object. That is, a prosodic prominence (and its shift) within a subject noun phrase with a universal quantifier should lead to a reduction of visual attention to the isolated object that tends to lure Q-spreading errors.
Current study
Based on the literature reviewed above, the current study explores the phenomenon of Q-spreading errors as a behavioral pattern with misguided attention allocation that can perseverate, instead of underdeveloped semantics. Q-spreading errors may persist into adulthood, bringing up a question regarding whether and to what extent older children and adolescents exhibit the same errors. While Minai et al. (Reference Minai, Jincho, Yamane and Mazuka2012) demonstrate that children who commit Q-spreading errors show perseverance to the initial occurrence of the error, the interpretation of the results is limited because children were categorized either into ‘adult-like comprehenders’ or ‘Q-spreaders’ based on their response patterns for only four test items. The current study more closely examines whether child and adult participants alter their response patterns during testing at all. In addition, the current study tests whether prosodic prominence of the universal quantifier can guide participants’ attention more straightforwardly to the set of agents (expressed by ‘every X’) and can facilitate correct interpretation of each proposition.
In the current study, participants from a wider age range (preschoolers to aging adults) verified the match/mismatch between a universally-quantified sentence (e.g., ‘Every pig is carrying a basket’ as in (1) above) and an extra-object picture (e.g., three pigs carrying a basket each, and an extra basket nobody is carrying, as in Figure 1 above), while their eye-movements were continuously monitored. We address the following three research questions: (i) Do children, adolescents and adults commit Q-spreading errors? Are Q-spreading errors strictly bound to age?; (ii) Do participants change their responses to the target ‘every’-sentences over time? When they do, how is such a change in the response patterns reflected in their eye-movements?; (iii) Are children (and adolescents/adults) able to comprehend ‘every’-sentences more accurately if the quantifier ‘every’ is emphasized? What happens if the locus of emphasis is infelicitous (e.g., ‘Every PIG is carrying a basket’, where the quantified noun is prominent)?
Methods
Participants
A total of 189 participants were recruited at a lab situated in a science museum in a Midwest city. Since the participants were general visitors to the museum and were not pre-scheduled, the age and gender could not be balanced across child and adult groups. The data presented in the current study consist of responses from 143 of them (84 female, 59 male). Of these 143 participants, 35 were adults (age range 19-79, mean=44;8, sd.=16;9) and 108 were children and under-age adolescents, who required guardian’s permission for participation (age range 4-17, mean=9;74, sd.=2;96). Of these 108 youths, we grouped 65 as ‘children’ (age range 4-10, mean=7.7, sd.=1.7; 4-yo=2; 5-yo=5; 6-yo=7; 7-yo=18; 8-yo=11; 9-yo=8; 10-yo=14), and 43 as ‘adolescents’ (age range 11-17, mean=12.7, sd.=1.5: 11-yo=12; 12-yo=8; 13-yo=11; 14-yo=8; 15-yo=2; 16-yo=1; 17-yo=1). Data from 46 participants were excluded from analysis for one of the following reasons: they had vision or hearing impairment; they had other conditions that did not meet the recruitment criteria; they decided to terminate the experiment early; technical problems prevented accurate collection of data; their data was not properly recorded.
Visual stimuli
A total of 36 slides were created, 12 serving as the target items, 24 as the filler items. The 12 target slides were combined with a sentence with ‘every’ in the pre-subject position, such as ‘Every pig is carrying a basket’ as (1): a slide was divided into quadrants, three of which contained the same picture of an animal interacting with an object (e.g., a pig carrying a basket). The fourth quadrant contained only an extra object (e.g., a basket) (Figure 1). The location of the extra object was counterbalanced across the quadrants (i.e., it appeared in three items in each of the four cells).
The 24 filler items included a variety of combinations of animal and object drawings to elicit both ‘yes’ and ‘no’ responses: (i) 3 false items, where one of the four animals is interacting with a different object (Filler 1); (ii) 3 false items, with the mentioned character paired with an unmentioned object, as well as an unmentioned character paired with the mentioned object (Filler 2); (iii) 6 true items, where three same animals paired with the mentioned object and an extra object by itself (Filler 3); (iv) 4 false items where the mentioned number of agent and its predicate mismatch the scene (Filler 4); (v) 4 false items where a mentioned character paired with an unmentioned object and an unmentioned character paired with the mentioned object (Filler 5); (vi) 4 false items, where one of the three mentioned animals is paired with a wrong unmentioned object and one unmentioned animal is paired with the mentioned object (Filler 6). See Table 1 for the summary of item design.Footnote 2
Table 1. Design of the stimuli
Auditory stimuli
All the stimulus sentences were pre-recorded by a phonetically trained female native speaker of American English in three prosodic conditions using Praat (Boersma & Weenink, Reference Boersma and Weenink2023). A contrastive pitch accent or prosodic emphasis was placed either on the quantifier ‘every’ (e.g., ‘EVERY pig …’: ‘Quantifier-emphasis’ condition); or on the subject noun referring to an animal modified by the quantifier every (e.g., ‘Every PIG …’: ‘Animal-emphasis’ condition); or nowhere (‘No-emphasis’ condition). A sample audio file from each prosodic condition is provided as supplementary materials. The differences in fundamental frequency (f0) traces across the three conditions are shown in Figure 2. All filler items were also recorded in corresponding three prosodic conditions such that the prosodic variation was balanced across all items presented within each experimental session.

Figure 2. Time-normalized f0 traces of the critical stimulus sentences. The grey lines indicate the f0 trace of individual sentences and the red line is a smoothed spline average of all grey traces.
Prosody of test sentences was a within-subject factor. All participants heard 12 target sentences across three different prosodic conditions (4 items each). All 12 target items were presented in all three prosodic conditions across 3 presentation lists created with a Latin square design.
Procedure
The experiment took place in a university language laboratory situated in a science museum. Once adults and children accompanied by a legal guardian had consented, they were seated in front of a Tobii T60 eye tracking system with a sampling rate of 60Hz for continuous gaze tracking. The system was calibrated to the participant’s eyes using Clearview’s 5-point calibration procedure.
The experiment began with 2 practice trials to familiarize the participant to the task, followed by 36 experimental trials. For each trial, the picture was presented silently for 2.5 seconds, and then the auditory stimulus sentence started to play through a noise-canceling headphone set while the picture remained on the screen. After the sentence was presented, the participant was asked to decide whether the meaning of the sentence and the contents of the picture matched and verbally responded with ‘Yes’ or ‘No’.
A ‘Yes’ response indicated that they believed the sentence correctly described the picture they saw, while a ‘No’ response indicated that they thought they did not match. Each response was coded by a button press by an experimenter. When a ‘No’ response was coded, the follow-up question ‘Why?’ was presented on the screen, and the participant was told to verbally explain why they thought the sentence and picture did not match. While most of the ‘No’ responses were accompanied by a reasoning about the extra single object (note that not all participants gave oral explanations), a good number of participants switched from ‘No’ to ‘Yes’ responses (n=31). We therefore analyzed data according to the participants’ response patterns and further investigated what happened in their eye-gaze responses when they switched judgments (see below).
Analysis
For the target items, looks to the extra object cell were coded as 1 for samples of which the x- and y-coordinates fell inside that area of interest (AOI) and 0 if outside the AOI. Samples that did not have x- and y-coordinates on the screen (due to blinking, looking away, or track loss) were excluded from analysis.
A Generalized Additive model was fit to model the change in proportion of looks to the extra object in a 3 second window starting from the onset of the auditory stimulus. Stimuli sentences ranged from 1.8 – 2.5 seconds in total duration. Full models are provided in Appendix 3.
Results
Sentence-picture verification accuracy
The accuracy of sentence-picture verification was coded as 1 for correct acceptance and 0 for incorrect rejection for each of the target items for each participant. Figure 3 shows the distributions of all participants’ counts of accurate responses for each prosody condition, where the count ranged from 0 to 4 for each condition (note that the samples were jittered to be visible along both x- and y-scales). The accuracy distributions show large variability in children and adolescents, up to age 17 (Mean 59.7%, SD 43.7%). Adults were overall at ceiling (mean 95%, SD 9.3%), while some made one error out of four target items. The distribution pattern was comparable across three prosody conditions (Figure 3). A mixed effects logistic model with age (children as the reference) and prosody (No-emphasis as the reference) has revealed significant differences between children and adolescents (coef=1.71, z=7.29, p<.0001), between children and adults (coef=3.60, z=7.58, p<.0001), and between adolescents and adults (coef=1.81, z=3.80, p=.00014). No effect of prosodic emphasis and no interaction between age and prosody was found. Thus, prosodic manipulation did not differentiate off-line comprehension response patterns.

Figure 3. TVJ accuracy along with participant age by prosody condition.
Eye movement patterns
Across the critical 12 items, the proportions of the eye fixations to the extra-object AOI (as the indicator of the degree of distraction) were first calculated for each response type (‘Yes’ or ‘No’) for each age group: children (age: 4-10), adolescents (age: 11-17) and adults (age: 19-79) (Figure 4). The fixation proportion values were realigned at the beginning of each window marked by vertical lines. Within each age group x response type panel, the small n indicates the number of observations that were aggregated for creating the functions, whereas the large N indicates the number of participants who provided the responses of the given type.

Figure 4. Fixation proportion for the extra-object cell per response type: YES (top) or NO (bottom). Significant pairwise differences are color-shaded (Q: Quantifier-emphasis; A: Animal-emphasis; No: No emphasis).
The proportion of looks to the object was modeled using Generalized Additive models (GAMs). GAMs can model non-linear relationships over time by projecting smooths/splines estimated from the data. Two benefits of GAMs are that they can account for individual variation and auto-correlation better than polynomial models can (Winter & Wieling, Reference Winter and Wieling2016) and they provide exact time information about when curves are significantly different from one another. These differences in curves are highlighted using red boxes in Figure 4. In interpreting the results of the GAMs, coefficients cannot be directly interpreted, and p-values are only weakly informative, and thus will not be reported here. Instead, visual inspection of the modeled curves is discussed with the statistical results (Winter & Wieling, Reference Winter and Wieling2016). The data were modeled as 12 individual curves corresponding to the interactions between emphasis condition (3 levels), age group (3 levels), and trial response (2 levels). The critical trial model was built with condition, age category, and response (condAgeRESP) as the predictor. Random smooths were created for both Subject and Item as well as random smooths by condition alone and condAgeRESP respectively. See Appendix 3 for more details about the model specification.
Figure 4 demonstrates a clear difference in fixation patterns according to the response type across all age groups. Participants rarely looked at the extra object when they responded with ‘Yes’ (top), while their gazes tended to exceed the chance level of 25 % especially toward the end of the sentences when they responded with ‘No’ (bottom). Although only 21 trials were responded to with ‘No’ by adults, they were clearly accompanied by frequent looks to the extra object. These results replicate the pattern reported in Minai et al. (Reference Minai, Jincho, Yamane and Mazuka2012).
As for the effect of prosodic prominence, Figure 4 indicates interesting differences among children, adolescents, and adults. In children’s ‘Yes’ trials, the steady effect of prominence (where the significant conditional differences lasted longer than 300ms) appeared after the object noun, where the emphasis on the animal noun (e.g., PIG) elicited more looks to the extra object than the other two conditions. In adolescents, the emphasis on the animal led to the least looks to the extra object, and its reliable differences from the other two conditions appeared earlier – during ‘is -ing’. In adults’ ‘Yes’ trials, prosodic emphasis on ‘every’ and on the animal noun respectively led to more looks to the extra object as compared to the no emphasis condition, and these effects appeared even earlier – toward the end of the animal noun.
As for ‘No’ trials, both children and adolescents showed some effect of prosodic emphasis, but in the opposite direction. Children looked at the extra object more frequently when there was no prosodic emphasis as compared to the emphasis on the quantifier (EVERY) toward the end of the sentence. Adolescents, in contrast, had relatively more looks to the extra object during the subject noun phrase (from the end of EVERY into the animal noun) in both emphatic conditions as compared to no-emphatic condition. In adults, the small number of ‘No’ responses (n=21) were accompanied by a higher number of looks to the extra object without reliable conditional differences.
In sum, we observed the predicted effect of prosodic emphasis to reduce the looks to the extra object in adolescents’ ‘Yes’ trials and children’s ‘No’ trials. Adults, who dominantly responded with ‘Yes’, showed the opposite pattern – more looks to the extra object with prosodic emphasis. We will discuss the reasons for these unexpected patterns later. The timing of responses to prosodic manipulation was overall much later in children as compared to the two older groups as predicted by the general developmental trajectory of prosodic skills (Ito, Reference Ito, Prieto and Esteve-Gibert2018).
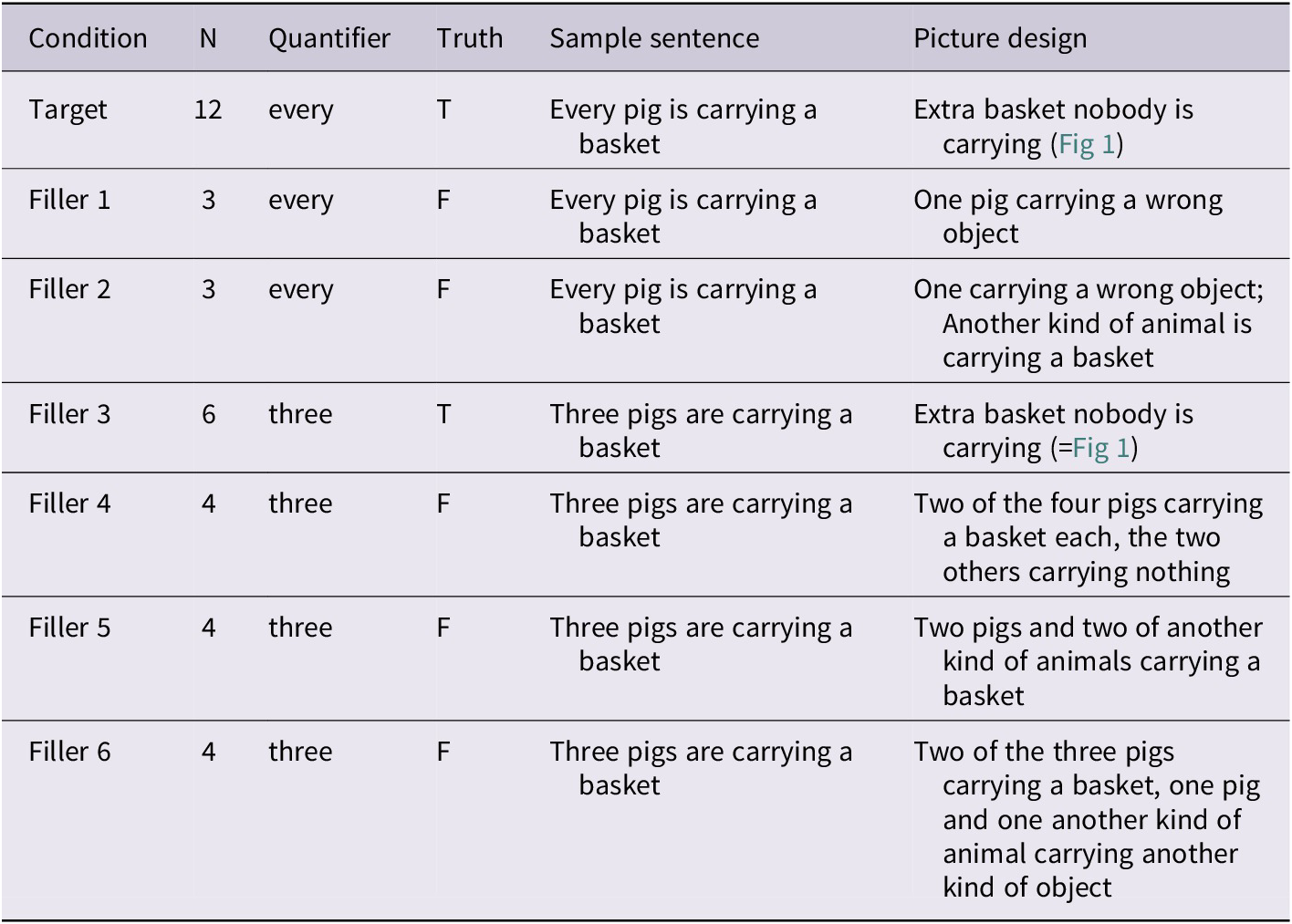
In order to test whether child and adolescent participants changed their responses during the experiment, and whether the shift in response strategy was accompanied by a shift in the gaze patterns, we looked at individual participant’s response patterns one by one and identified the ‘Switchers’ who changed the responses from ‘No’ to ‘Yes’ at one point and stayed with ‘Yes’ responses (Child: N=16, age range 6-10, mean age=8.1, mean accuracy=81.7%, SD=7.1%, Adolescent: N=14, age range 11-15, mean age=12.7, mean accuracy=85.3%, SD=5.9%), ‘Adult-like responders’ who continuously responded with ‘Yes’ (Child: N=14, age range 4-10, mean age=7.3, mean accuracy=100%, SD=0%, Adolescent: N=22, age range 11-17, mean age=12.8, mean accuracy=100%, SD=0%) and ‘Q-spreaders’ who responded with ‘No’ throughout the experiment (Child: N=25, age range 5-10, mean age=7.8, mean accuracy=0%, SD=0%, Adolescent: N=5, age range 11-14, mean age=12.3, mean accuracy=0%, SD=0%). Figure 5 plots each group’s fixation proportion functions for the first three trials (in pink) and the last three trials (in purple). The GAM for Switcher/Spreader/Adult-like participants had 2 predictors for fixation proportion to the extra object: whether the subject was a switcher or not and whether the trials being models were the first 3 or the last 3 critical trials. Random smooths were created for both Subject and Item as well as random smooths by Switcher/Spreader/Adult-like status and trial position (i.e., first 3 trials or last 3 trials).
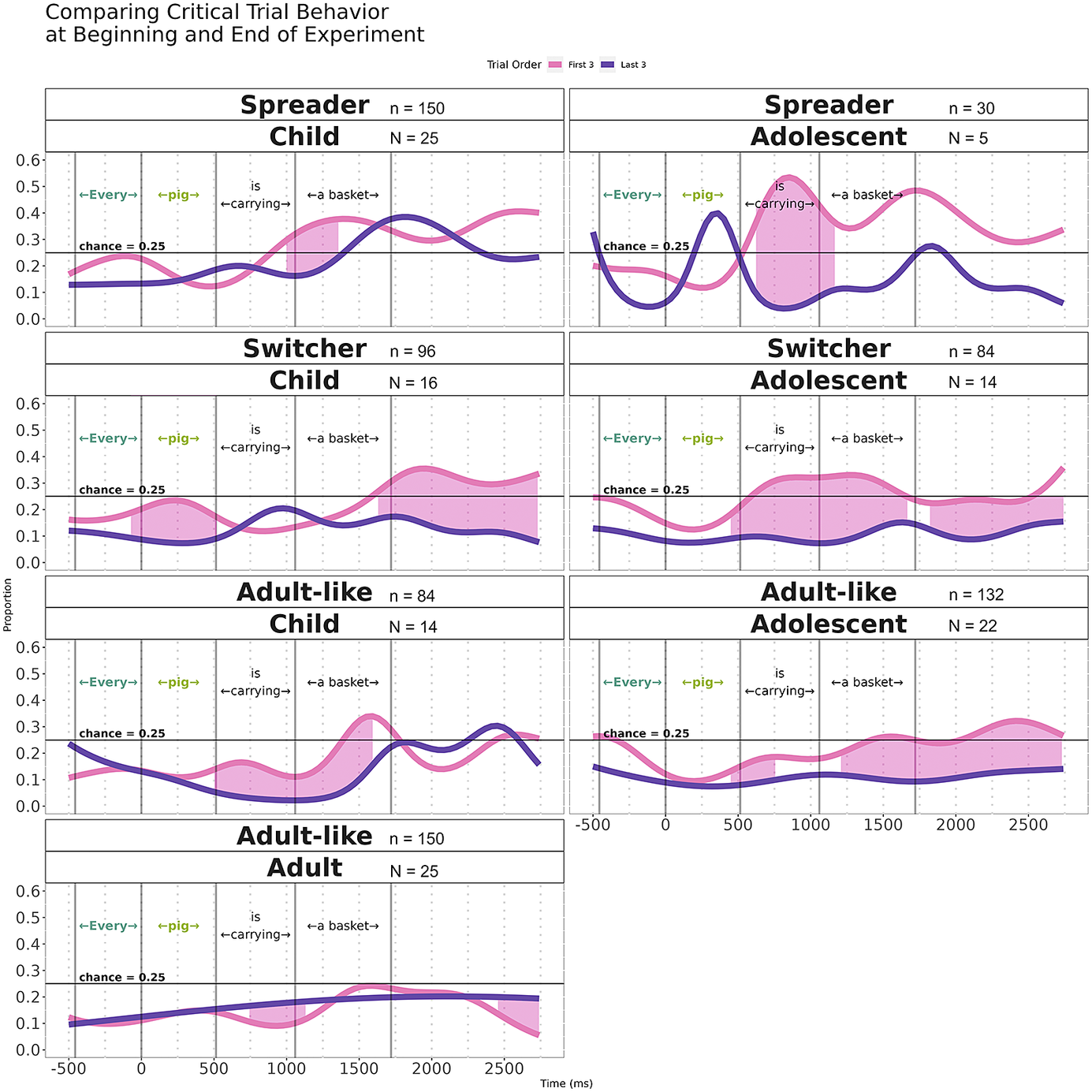
Figure 5. Fixation proportion functions for the first three (pink) and last three (purple) critical trials.
We found very interesting similarities and differences among the groups of different response patterns. First, the ‘Q-spreaders’ (Figure 5, 1st row), who kept saying ‘No’ to the critical ‘every’-sentence throughout the experiment were clearly drawn to the extra object. Child Q-spreaders showed a gradual increase in their looks to the extra object from the midpoint of the sentences in the beginning of the testing, and, even in the last trials, maintained their gazes to the object for a few hundred milliseconds after the sentence. Adolescent Q-spreaders exhibited much steeper increases in their looks to the extra object than child Q-spreaders in the early trials. In the later trials, there was a shift in their gazes away from the extra object after the animal noun but they increased again toward the end of the sentences.
The ‘Switchers’ (2nd row), who started by saying ‘No’ to the target sentences but switched (average after 3rd trial) to ‘Yes’ responses, looked at the extra object more often in the first three trials than during the last three trials. For the first three trials, the child switchers’ gazes on the extra object remained above the 25% chance level after the sentence offset, while adolescent switchers maintained relatively frequent gazes from the midpoint of the sentences. After they switched, both groups rarely looked at the extra object throughout the sentence.
Both child and adolescent ‘Adult-like responders’, who correctly verified the target ‘every’-sentence throughout the experiment (3rd row), showed a shift in gaze patterns like the ‘Switchers’: in the first three trials, they looked more at the extra object toward and beyond the end of the sentence, though they looked at it much less in the last trials. This contrasts with real adults, who consistently responded ‘Yes’, who did not show any difference in the level of looks to the extra object between the first three and the last three trials. Note that the level of looks to the extra object for the last three trials was actually higher in adults than in child and adolescent ‘Switchers’ and ‘Adult-like responders’. This difference is interesting, as it suggests that children and adolescents who responded ‘Yes’ throughout the experiment may have inhibited the urge to say ‘No’ despite their initial attention to the extra object. Once they ‘figured out’ the game, however, both ‘Switchers’ and ‘Adult-like responders’ rarely looked at the extra object, as if they had determined not to look at it. Adults may have kept browsing around the slides more freely or less strategically, while they could correctly verify the target ‘every’-sentences throughout the experiment.
Discussion
One of the goals of the current study is to fill the gap in the range of ages that have not yet been well investigated regarding universal quantifier comprehension. To our knowledge, the current study is the first to include a wide range of the age groups in a single-study setting, spanning preschool childhood, adolescence, and adulthood. Our data revealed that adolescents, on par with preschoolers, also exhibited a dichotomous split among individuals into those who commit Q-spreading errors and those who can avoid those errors consistently. The dichotomous split according to the sentence verification accuracy well corresponded to the eye-gaze patterns, replicating the findings of Minai et al. (Reference Minai, Jincho, Yamane and Mazuka2012) where Q-spreading errors were accompanied by frequent looks to the extra object. The current study demonstrates that the processing and comprehension of the universal quantifier ‘every’ may not be uniformly adult-like until 14-years of age (Figure 3). While we did not obtain sufficient observations of the adults’ ‘No’ responses for projection of representative fixation proportion functions, adults did return a total of 21 ‘No’ responses accompanied by relatively frequent looks to the extra object. These findings are consistent with previous reports on adults’ errors (Aravind et al., Reference Aravind, de Villiers, de Villiers, Lonigan, Phillips, Clancy, Landry, Swank, Assel, Taylor, Eisenberg, Spinrad and Valiente2017; Minai et al., Reference Minai, Jincho, Yamane and Mazuka2012). Since our samplings could not be balanced across all sub-age groups, our current data cannot speak to the potential effect of aging on universal quantifier comprehension. Investigation of the relationship between age-related cognitive decay and the ability to allocate attention to achieve correct interpretation of universal quantifiers remains an important topic to explore in future research.
The current findings confirmed the resilience of the Q-spreading errors, but what do our data reveal about the mechanism behind such errors? On the assumption of a strong nativism positing steady grammatical knowledge throughout childhood and adulthood (e.g., Crain et al., Reference Crain, Thornton, Boster, Conway, Lillo-Martin and Woodams1996), Q-spreading errors across a wider age range would support the Full Competence View, if we could attribute their errors to a single source that is outside the deficient grammar. Minai et al. (Reference Minai, Jincho, Yamane and Mazuka2012), for example, demonstrated a correlation among Q-spreading, increased gazes to the extra object and low performance in DCCS – a non-linguistic executive function task that gauged participants’ cognitive flexibility. Unlike Minai et al. (Reference Minai, Jincho, Yamane and Mazuka2012), the current study with museum visitors could not include a task that could additionally provide the information about participants’ general attention control. Hence, while the present gaze patterns are sufficiently informative for speculating about the time course of information processing that led to the errors, we cannot test the effect of participants’ non-linguistic cognitive flexibility on their comprehension of sentences with a universal quantifier. Thus, our results cannot solely support the Full Competence view.
Nonetheless, our findings are consistent with some proposals under the Full Competence view. First, note that the participants had 2.5 sec silent preview time before they heard the sentence in each trial. This preview time must have been sufficient for participants to obtain a gist of each scene (Henderson & Ferreira, Reference Henderson, Ferreira, Henderson and Ferreira2004). While the extra object must have stood out being the only cell that did not contain the animal, participants’ gazes were directed more to the other cells that included an animal, which resulted in the lower-than-chance level gaze to the extra object at the beginning of the sentence (Figure 4). The increase in the looks to the extra object appeared toward the end of the sentence in all groups’ ‘No’ trials (Figure 4) and in child and adolescent participants’ initial trials regardless of their responses (Figure 5). Importantly, once attention was drawn to the extra object, it remained at a high level especially after the label for the object was mentioned in the sentence-final position. Thus, the looks to the extra object did not seem to be driven independently of the sentence processing: instead, they were triggered by the explicit mention of the object. What is particularly interesting is that children and adolescents diverged in their behavior after the initial few trials. Those who kept paying attention to the extra object seemed to adopt the Symmetrical Response strategy (Philip, Reference Philip1995), where the presence of the extra object, which makes exhaustive animal-object pairing incomplete, was judged as the evidence against the verification of the universally quantified sentence. This generally echoes the view of Minai et al. (Reference Minai, Jincho, Yamane and Mazuka2012), where looks to the extra object accompanying Q-spreading errors were interpreted as the indicator of failing to disengage from reasoning based on the presence of the extra object.
As for the shift in the processing strategies, the present data may suggest important differences among children, adolescents, and adults in their non-linguistic cognitive abilities. Although more than a third of child/adolescent participants (N=36) correctly verified all the target sentences just like most adults (‘Adult-like responders’), their gaze patterns were very different from those of adults. While adults did not change the level of attention to the extra object throughout the experiment and maintained it at the lower-than-chance level overall, the ‘Adult-like responders’ paid a lot more attention to the extra object during the initial trials. Assuming the link between the attention to the distractor object and the Q-spreading errors, the discrepancy between the eye-gaze patterns and the sentence verification accuracy in the ‘Adult-like responders’ indicates that those young participants had to inhibit the extra object and the associated Symmetrical Response before answering with ‘Yes’. The gaze patterns of the ‘Switchers’ were very similar: they started with frequent looks to the extra object yet ended the session with rare looks to this distractor. The difference between them is that the ‘Switchers’ failed to inhibit the Symmetrical Response initially, while the ‘Adult-like responders’ seemed to better control the urge and let their semantic knowledge guide their responses from the beginning.
Another interesting similarity between the two young groups is that they kept the looks to the extra object at much lower than the chance level toward the end of the experiment, which was also lower than the level of adults. The current data therefore suggest that children and adolescents may have been more strategic than adults during a visual stimuli integration task. Our current data do not show elaborate inhibition effort in adults, who may have been able to rely on their established grammatical knowledge in verifying the universally quantified sentences. With the current data, we cannot determine whether the distinctively reduced attention to the extra object in child and adolescent ‘Adult-like’ responders and ‘Switchers’ reflected their conscious task-driven heuristic to prevent errors. Future studies may perhaps test the agility of task-oriented heuristics with gradient manipulation of visual as well as discourse salience of distractor objects.
Importantly, Q-spreading errors accompanied by increased looks to the extra object are not inconsistent with a Partial Competence view, which attributes errors to individuals’ failure to restrict a domain of quantification (e.g., Drozd & van Loosbroek, Reference Drozd, van Loosbroek and van Geenhoven2006). Such an account argues that children, when presented with ‘Evert pig is carrying a basket’ with a slide like Figure 1, would assume that all objects in the scene participate in the described event. An anonymous reviewer suggested examining a condition where the fourth (extra) object is not the basket but an alternate object. While the current study lacks such a condition, we followed the reviewer’s suggestion and examined the filler (iii) items which presented the slides like the targets with the numeral quantifier ‘three’ instead of ‘every’. While children returned errors about 14% of the time (‘No’ n=54; ‘Yes’ n=336’), adolescents and adults showed nearly ceiling responses (adolescents: ‘No’ n=8, ‘Yes’ n=250; adults: ‘No’ n=3, ‘Yes’ n=207: See Figure 6 for the gaze patterns for ‘Yes’ and ‘No’ trials across groups; the filler trial GAM model was built with condition, age category, and response (condAgeRESP) as the predictor. Random smooths were created for both Subject and Item as well as random smooths by condition alone and condAgeRESP respectively.). Thus, the proportions of incorrect rejections were much lower than for the target trials especially in children and adolescents. This may indicate that their knowledge of numeral quantifiers might be more developed than for universal quantifiers. Alternately, it may reflect the difference in the level of ambiguity in the inherent semantics: ‘three’ designates the concrete numerosity equaling 3, which can be confirmed by the presence of the three pigs. ‘Every’, in contrast, renders universality that would evoke including all elements in the scene. Interestingly, the gaze patterns of ‘No’ trials (although less smooth than the target trials due to fewer numbers of observations) replicated the tendency with more frequent looks to the extra object. Thus, the presence of an extra object may misguide the comprehension of quantified sentences, while its degree may interact with the interpretational ambiguity (or the level of knowledge) of quantifier semantics.
Figure 6. Fixation proportion for the extra-object cell for filler sentences containing a numeral quantifier instead of a universal quantifier (e.g., ‘Three pigs are carrying a basket’).
As for the effect of prosodic prominence, the present data revealed interesting similarities and differences across age groups. To our surprise, prosodic prominence on either the universal quantifier ‘every’ or on the following head noun often led to an increase in the looks to the extra object in all groups, despite the visual layout of the slides that made the former felicitous, and the latter infelicitous. This was unexpected especially because the object noun (e.g., basket) was prosodically attenuated in the sentence-final position, produced at the bottom of the speaker’s pitch range across all conditions (Figure 2). It was predicted that the felicitous emphasis (e.g., ‘EVERY pig …’) would evoke higher attention to the entity set referred to by the universally-quantified noun phrase (e.g., every entity x, such that x is a pig), and the emphasis on the noun would also direct participants’ attention to the labeled set (pigs) especially in the absence of the potential contrastive entity (other animals) on the display. The present data exhibit the patterns opposite to these predictions. Although the general effect of prosodic prominence seemed rather detrimental leading to higher attention to the visual distractor, the data confirmed the age-related differences in the timing of prosodic processing (Ito, Reference Ito, Prieto and Esteve-Gibert2018; Ito et al., Reference Ito, Jincho, Minai, Yamane and Mazuka2012, Reference Ito and Matthews2014).
Before discussing the age-related difference in detail, we must point out that the unexpected effect of prosodic prominence may have been, at least partially, an artifact of the current experimental design. As described earlier, the present study included various combinations of visual stimuli with differently quantified sentences to elicit both ‘Yes’ and ‘No’ responses. Among the 24 fillers, only 6 items had the display where a single object was shown in one of the four cells. The rest had either 2 of 2 different animals (4), 3 same and 1 different animal (7), or all the same animal appearing in the quadrants (7). Thus, exactly half of the total of 36 items presented the slide in which all four quadrant cells were occupied with an animal. This may have primed the looks to the extra-object cell upon hearing the prosodic emphasis on either ‘every’ or on the noun: participants may have sent their eyes to make sure that the potentially contrastive animal entity was not there with the object.
With respect to the timing of eye-gaze responses, adults were swift in shifting their attention to the extra object: in both conditions that involved prosodic emphasis, they showed relatively frequent looks to the extra object immediately after the subject NP, yet this confirmational eye-movement was rather short-lived and they maintained less-than-chance level attention throughout the sentence. The quick check with a gaze shift did not affect their sentence verification. Adolescents showed least looks to the extra object when the animal was emphasized, and this prosodic effect appeared a few hundred milliseconds later than adults. Child participants had relatively more looks to the extra object in both emphatic conditions, which appeared toward the end of the sentence. In the ‘No’ trials, adolescents showed relatively higher number of looks to the extra object due to either emphasis within the subject noun phrase, whereas children showed the opposite effect of prosody toward the end of the sentence.
Taken together, prosodic prominence within the quantified subject noun, of which the validity of projected contrast can be evaluated only with the truth value of the predicate, can be distracting to all age groups. While the timings of prosodic effects seem to confirm the gradual development of prosodic sensitivity (Ito, Reference Ito, Prieto and Esteve-Gibert2018; Ito et al., Reference Ito, Jincho, Minai, Yamane and Mazuka2012), the lack of consistent direction of prosodic effect across age groups suggests that prosodic emphasis was not particularly helpful for comprehending the universally-quantified sentences in a visual context that did not clarify the set of alternatives. It would be interesting to test the responses to prosodic prominence when the 4th cell is occupied by a contrastive animal (e.g., three cells contain a pig carrying a basket, and the 4th cell contains a horse carrying a basket). There, truth status of the sentence ‘EVERY pig …’ or ‘Every PIG …’ would remain the same yet the prominence on the noun, which evokes the contrast between the animals, may lead to a higher number of Q-spreading errors. Such results would further demonstrate how dynamically prosody can impact the interpretation of universal quantifiers according to referential context.
Conclusion and future research
Recent research on the comprehension of universal quantifier ‘every’ has been exploring how general cognitive function can influence the pragmatic implementation of grammatical knowledge in children. The current study recruited participants from the general public of the widest age range (4-79) and confirmed that Q-spreading errors persist in adolescence and adulthood. The data confirmed the previously reported link between the excessive attention to visual distractor and Q-spreading errors (e.g., Minai et al., Reference Minai, Jincho, Yamane and Mazuka2012) and add novel findings about the shift of attention in children and adolescents, which was not required in adults whose steady grammatical knowledge can be applied with less cognitive effort. Prosodic prominence in universally quantified sentences can be distracting without a visual context that endorses the contrastive interpretation. Future research may further investigate the effect of aging on Q-spreading errors and the interaction of prosody and visual context that modulates the discourse salience of error-prompting entities.
Supplementary material
The supplementary material for this article can be found at http://doi.org/10.1017/S0305000923000533.
Acknowledgments
We would like to thank the Language Sciences Research Lab at the Ohio State University and the Center of Science and Industry (COSI) for their support for recruiting and testing participants. We would also like to thank Laurie Maynell who recorded all the auditory stimuli for this study.










 Open access
Open access