



No CrossRef data available.
Article contents
Temporal concatenation for Markov decision processes
Published online by Cambridge University Press: 13 July 2021
Abstract
We propose and analyze a temporal concatenation heuristic for solving large-scale finite-horizon Markov decision processes (MDP), which divides the MDP into smaller sub-problems along the time horizon and generates an overall solution by simply concatenating the optimal solutions from these sub-problems. As a “black box” architecture, temporal concatenation works with a wide range of existing MDP algorithms. Our main results characterize the regret of temporal concatenation compared to the optimal solution. We provide upper bounds for general MDP instances, as well as a family of MDP instances in which the upper bounds are shown to be tight. Together, our results demonstrate temporal concatenation's potential of substantial speed-up at the expense of some performance degradation.
- Type
- Research Article
- Information
- Probability in the Engineering and Informational Sciences , Volume 36 , Issue 4 , October 2022 , pp. 999 - 1026
- Copyright
- Copyright © The Author(s), 2021. Published by Cambridge University Press
References
Bellman, R. (1954). The theory of dynamic programming. Bulletin of the American Mathematical Society 60(6): 503–515.CrossRefGoogle Scholar
Bhatnagar, S., Sutton, R.S., Ghavamzadeh, M., & Lee, M. (2009). Natural actor–critic algorithms. Automatica 45(11): 2471–2482.CrossRefGoogle Scholar
Bondy, J. A. & Murty, U. S. R. (1976). Graph theory with applications, vol. 290. London: MacMillan.CrossRefGoogle Scholar
Burnetas, A.N. & Katehakis, M.N. (1997). Optimal adaptive policies for Markov decision processes. Mathematics of Operations Research 22(1): 222–255.CrossRefGoogle Scholar
BYD Company. (2017). BYD battery energy storage projects. https://sg.byd.com/wp-content/uploads/2017/10/Energy-Storage-System.pdf. Accessed: 27 May 2020.Google Scholar
California ISO. CAISO market processes and products. http://www.caiso.com/market/Pages/MarketProcesses.aspx. Accessed: 27 May 2020.Google Scholar
Chen, Y. & Wang, M. (2016). Stochastic primal-dual methods and sample complexity of reinforcement learning. Preprint arXiv:1612.02516.Google Scholar
Chen, T., Li, M., Li, Y., Lin, M., Wang, N., Wang, M., Xiao, T., Xu, B., Zhang, C., & Zhang, Z.. (2015). Mxnet: A flexible and efficient machine learning library for heterogeneous distributed systems. Preprint arXiv:1512.01274.Google Scholar
Daoui, C., Abbad, M., & Tkiouat, M. (2010). Exact decomposition approaches for Markov decision processes: A survey. In Advances in Operations Research 2010. London, UK: Hindawi.Google Scholar
Dietterich, T.G. (2000). Hierarchical reinforcement learning with the MAXQ value function decomposition. Journal of Artificial Intelligence Research 13: 227–303.CrossRefGoogle Scholar
Durrett, R. (2019). Probability: theory and examples, vol. 49. Cambridge University Press.Google Scholar
Harrison, J.M. & Zeevi, A. (2004). Dynamic scheduling of a multiclass queue in the Halfin-Whitt heavy traffic regime. Operations Research 52(2): 243–257.CrossRefGoogle Scholar
Harsha, P. & Dahleh, M. (2015). Optimal management and sizing of energy storage under dynamic pricing for the efficient integration of renewable energy. IEEE Transactions on Power Systems 30(3): 1164–1181.CrossRefGoogle Scholar
Ie, E., Jain, V., Wang, J., Narvekar, S., Agarwal, R., Wu, R., Cheng, H.-T., Chandra, T. & Boutilier, C. (2019). Slateq: A tractable decomposition for reinforcement learning with recommendation sets. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence (IJCAI-19). California, USA: International Joint Conferences on Artificial Intelligence Organization, pp. 2592–2599.CrossRefGoogle Scholar
Jaksch, T., Ortner, R., & Auer, P. (2010). Near-optimal regret bounds for reinforcement learning. Journal of Machine Learning Research 11 Apr: 1563–1600.Google Scholar
Kolobov, A., Dai, P., Mausam, M., & Weld, D.S. (2012). Reverse iterative deepening for finite-horizon MDPs with large branching factors. In Twenty-Second International Conference on Automated Planning and Scheduling. Palo Alto, CA, USA: AAAI press, pp. 146–154.CrossRefGoogle Scholar
Littman, M.L., Dean, T.L. & Kaelbling, L.P. (1995). On the complexity of solving Markov decision problems. In Proceedings of the Eleventh Conference on Uncertainty in Artificial Intelligence. Burlington, MA: Morgan Kaufmann Publishers Inc., pp. 394–402.Google Scholar
Low, Y., Bickson, D., Gonzalez, J., Guestrin, C., Kyrola, A., & Hellerstein, J.M. (2012). Distributed GraphLab: A framework for machine learning and data mining in the cloud. Proceedings of the VLDB Endowment 5(8): 716–727.CrossRefGoogle Scholar
Meng, X., Bradley, J., Yavuz, B., Sparks, E., Venkataraman, S., Liu, D., Freeman, J., Tsai, D., Amde, M., Owen, S., Xin, D., Xin, R., Franklin, M., Zadeh, R., Zaharia, M., & Talwalkar, A. (2016). MLlib: Machine learning in Apache Spark. The Journal of Machine Learning Research 17(1): 1235–1241.Google Scholar
Mundhenk, M., Goldsmith, J., Lusena, C., & Allender, E. (2000). Complexity of finite-horizon Markov decision process problems. Journal of the ACM (JACM) 47(4): 681–720.CrossRefGoogle Scholar
Parr, R. & Russell, S.J. (1998). Reinforcement learning with hierarchies of machines. In Advances in neural information processing systems. Cambridge, MA: MIT press, pp. 1043–1049.Google Scholar
Puterman, M.L. (2014). Markov decision processes: Discrete stochastic dynamic programming. Hoboken, NJ, USA: John Wiley & Sons.Google Scholar
Steimle, L.N., Ahluwalia, V.S., Kamdar, C. & Denton, B.T. (2021). Decomposition methods for solving Markov decision processes with multiple models of the parameters. IISE Transactions, 1–58. doi:10.1080/24725854.2020.1869351.Google Scholar
Sucar, L.E. (2007). Parallel Markov decision processes. In Advances in Probabilistic Graphical Models. Berlin, Heidelberg: Springer, pp. 295–309.CrossRefGoogle Scholar
Talebi, M. & Maillard, O.A. (2018). Variance-aware regret bounds for undiscounted reinforcement learning in MDPs. Journal of Machine Learning Research 83: 1–36.Google Scholar
Tseng, P. (1990). Solving  $H$-horizon, stationary Markov decision problems in time proportional to $\log (H)$. Operations Research Letters 9(5): 287–297.CrossRefGoogle Scholar
$H$-horizon, stationary Markov decision problems in time proportional to $\log (H)$. Operations Research Letters 9(5): 287–297.CrossRefGoogle Scholar
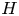 $H$-horizon, stationary Markov decision problems in time proportional to
$H$-horizon, stationary Markov decision problems in time proportional to 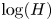 $\log (H)$. Operations Research Letters 9(5): 287–297.CrossRefGoogle Scholar
$\log (H)$. Operations Research Letters 9(5): 287–297.CrossRefGoogle ScholarWatts, D.J. & Strogatz, S.H. (1998). Collective dynamics of “small-world” networks. Nature 393(6684): 440.CrossRefGoogle ScholarPubMed